 Современные нейросети для успешного обучения требуют обучающие датасеты большого размера. Они не умеют что-то понимать с одного примера. Это затрудняет их использование в тех областях, где больших датасетов не создано. В то же время, человеку нередко бывает достаточно пары частных примеров, чтобы сделать глубокое обобщение. Предлагаю поговорить о том, что уже имеется по этой проблеме, и что из нейрофизиологии можно было бы (наверное) использовать для улучшения ситуации.
Современные нейросети для успешного обучения требуют обучающие датасеты большого размера. Они не умеют что-то понимать с одного примера. Это затрудняет их использование в тех областях, где больших датасетов не создано. В то же время, человеку нередко бывает достаточно пары частных примеров, чтобы сделать глубокое обобщение. Предлагаю поговорить о том, что уже имеется по этой проблеме, и что из нейрофизиологии можно было бы (наверное) использовать для улучшения ситуации.В чем проблема
Обобщать по маленькому количеству семплов современным сетям мешает переобучение (overfitting). Оно заключается в том, что когда образцов мало, а предметная область сложная (т.е. для её описания нужно много параметров), то сеть вместо глубокого обобщения запоминает частные случаи. В результате на обучающей выборке она показывает хорошие результаты, а на тестовой плохие, так как там другие частные случаи. Проблема тем больше, чем больше параметров у сети (проклятие размерности), и чем меньше обучающих семплов.
Есть, как минимум, три мейнстримых подхода к решению проблемы:
1) Регуляризация. Суть обычно в том, чтобы заставлять сеть во время обучения минимизировать паразитные ко-адаптации нейронов к друг другу. К примеру, пусть нейроны некоторого слоя научились распознавать длинные уши, и их активация совпадала с меткой «кролик». Есть соблазн выставить высокий вес для этого признака и другие особо не искать. Будет «длинные уши -> кролик», и всё. Чтобы уменьшить вероятность переоценки частных признаков, можно во время обучения некоторые нейроны временно исключать из процесса ( и тем самым дизаблить для сети часть выученных признаков, провоцируя ее на поиск новых) и т.д.
2) Архитектурные хитрости. Чтобы побороть проклятие размерности на уровне одного нейрона, можно конструировать сеть таким образом, чтоб у нейронов не было много синапсов. Например, первые слои классификатора картинок делают не полносвязными, а сверточными (где каждый нейрон смотрит лишь на часть картины).
3) Transfer learning (перенос знаний). Это когда фичи, извлеченные на одном датасете или задаче, переиспользуют, чтобы ускорить/улучшить обучение на другом. Простой вариант — когда нижние слои берут от уже обученной на большом датасете сети, а сверху приделывают не обученные слои. В самом деле, если нейрону надо научиться распознавать экзотических животных, то его задача упростится, если ему дадут в подчинение таких нейронов, которые уже “знают” уши, носы, глаза. Это лучше, чем искать закономерности в голых градиентах.
Но, пожалуй, самый многообещающий вариант (на мой взгляд) — это внутренний transfer learning.
Пусть в датасете есть редкая категория. Например, много фотографий животных вообще, но мало конкретно фотографий леопардов. Сеть не сможет с нуля по нескольким семплам вытащить универсальное признаковое описание леопарда. Но если было много фоток тигров и львов, то сеть знает нужные признаки для них. Если она теперь откуда-то узнает, что леопард, тигр и лев — объекты одного класса(кошки), то часть описания тигров/львов можно трансфернуть леопарду. Перепутать его с пятнистым диваном станет сложнее, потому что хоть у дивана есть характерные пятна леопарда, но других признаков кошачих нет.
Задача про внутренний трансфер знаний адресуется в state-of-art, но считать ее решенной, кажется, пока рано. Она разбивается на две подзадачи: во-первых, сеть должна догадаться, что редкая метка (леопард) может быть частным случаем кошек. Во-вторых, зная, что леопард частный случай кошки, нужно внутри сети “законнектить” базовые признаки кошек к леопарду. Даже если решить только вторую подзадачу, обучение сетей упростится. Можно будет сделать так:
- учим сетку на большом датасете про современных животных
- говорим, что мамонт это как бы слон, но с шерстью и бивнями
- вуаля, ни одного семпла с мамонтом не показывали, а она уже умеет угадывать его на картинках
К сожалению, пока нейросети этого скорее не умеют, чем умеют. Но зато это прекрасно умеет мозг. И поэтому я предлагаю немного покопаться в его биологии на предмет поиска подсказок, как он это делает.
Connectome Rewiring (перепроводка коннектома)
Коннектом это карта соединений нейронов в сеть. Сегодняшние алгоритмы обучения сводятся к изменению весов соединений, но не карты. А алгоритм мозга включает в себя систематическое перемоделирование самой карты.
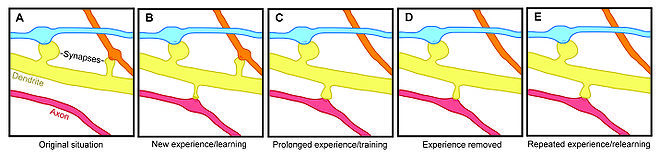
Показательный эксперимент. Крысу дрессируют совершать некое движение передними лапами. Находят в ее коре репрезентацию лап и смотрят на маркеры процессов, связанных с синапсами. И замечают, грубо, три фазы обучения. В первой фазе (только начали дрессировку) локальная сеть генерирует новые соединения. Во второй фазе навык улучшается, а соединения уничтожаются — как часть новых, так и часть старых. В третьей фазе навык уже установлен и не изменяется, а количество соединений в стало примерно таким, каким было до начала обучения. Но теперь это другая схема «проводки». В частности, увеличилось представление передних лап за счет новых горизонтальных связей в коре у этого региона.
На первый взгляд, это принципиально не отличается от того, как бекпроп занулял бы веса синапсов. Синапс стал весить ноль — его как бы не стало в карте. Снова набрал вес — появился в ней. Но есть одно но. Если наша искусственная сеть, обучающаяся бекпропом, не является абсолютно полносвязной (а она не является, иначе проклятие размерности), то нет возможности быстро пробросить сильную связь между нейронами, не соединенными общим ребром. А для one-shot обучения быстрота построения новых ассоциаций желательна. Если нейрон А всегда соединен только с нейронами Б, В, и Г, то он вынужден искать связь только между этими признаками. Задавая неполносвязный коннектом без возможности добавлять новые связи, мы, по сути, делаем сильное предположение, что предметная область может быть эффективно представлена вот таким-то конкретным графом связей между ее сущностями. Или его подграфом. А если нет? Например, предметная область содержит скрытые взаимосвязи а-ля «курица-яйцо», а у нас на графе плохо с реккурентностью…
В общем, не знаю кому как — а мне вот эта штука про генерацию локальных соединений и последующий отбор лучших из них напоминает нашу работу с гипотезами.

Когда мы столкнулись с чем-то новым, то обычно делаем грубые предположения, чем бы это могло быть вызвано. Потом отбрасываем не подтвердившиеся.
Когда делать гипотезу?
Для биологического нейрона обычно выделяют два состояния: Up и Down. В обоих состояниях потенциал в соме ниже порога, т.е. не достаточен для генерации спайков, и нейрон молчит. Но важно то, что спайк скорее сгенерируется из Up-состояния, чем из Down, поэтому Up-нейрон еще называют пред-возбужденным.
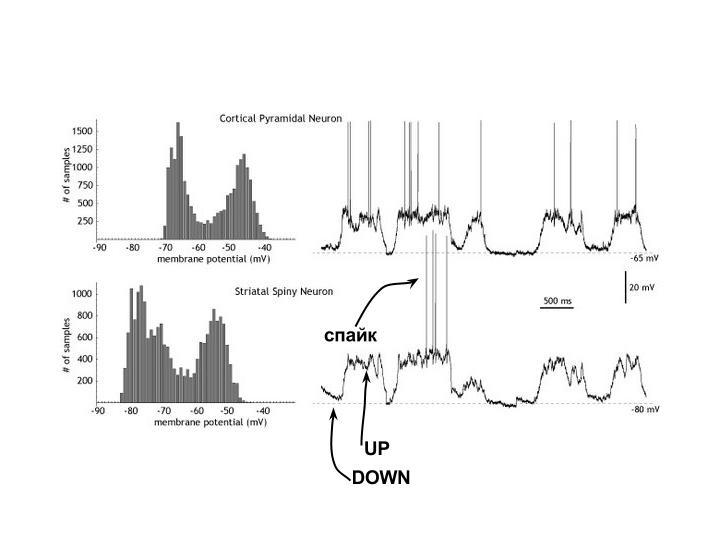
Гистограмма сбоку на рисунке показывает, насколько не равновероятны разные значения потенциала. Четко выделяются два «излюбленных» — оба подпороговые.
Когда прямой (feedforward) сигнал распространяется по сети биологических нейронов, то он порождает как активированные (т.е. стреляющие спайками), так и пред-возбужденные нейроны.
Есть мнение, что множество пред-возбужденных нейронов представляют собой возможные варианты развития событий из данного контекста. То есть если мы раньше видели кролика в клетке, и сейчас видим клетку, то можно пред-активировать нейроны кролика, даже если он спрятался, и прямо сейчас мы его не видим. Если в следующее мгновение кролик выглянет, то мы не будем удивлены. Следуя этой гипотезе, если в следующий момент feedforward-сигнал не активирует ни один из текущего множества Up-нейронов, то это будет эквивалентно несбывшимся ожиданиям. Если активируется кто-то из Down-нейронов, то — возникновению чего-то неожиданного. И то, и то назовем условно WTF-моментами. Чем больше их возникает, тем, видимо, хуже модель, и ее надо модифицировать. Эта мера могла бы сгодиться как часть оптимизируемой функции.
На основе этих пре-активированных нейронов и перемоделирования коннектома, само собой напрашивается experiment-driven обучение. Ученые показали, что дети-дошкольники склонны спонтанно изобретать информативные эксперименты во время игр: если ребенок хоть раз видит, что АБВГ ->X и БВГ->X, то он делает вывод, что A не влияет на Х, и, более того, он склонен ставить эксперимент по изолированию влияния Б, В, и Г на Х по отдельности. Т.е. дальше он исключает из контекста Б, и смотрит, как меняется Х. Серия таких экспериментов приводит к появлению детерминированной модели зависимостей между сущностями а-ля «изменение А точно влечет изменение Х».
Внутри нейросети подобная штука, имхо, могла бы выглядеть как-то так:

Правда, чтобы это заработало, нейроны должны реагировать не на само наличие фичи в feedforward-сигнале, а на ее появление/изменение. И тут самое время вспомнить, что…
… сетчатка передает не сцену, а изменения сцены
Подробнее тут. Спайк-трейны (последовательности спайков) показывают бОльшую корреляцию по отношению произошедшему изменению на сцене, чем к ее предыдущему или новому состоянию. Сетчатка в этом не одинока. Если положить руку на шершавую поверхность и не двигать, то шершавость «исчезает». Это проявление более общего свойства нейронов адаптироваться к статике. Если куча нейронов предпочитает ярко реагированть именно на изменения чего-то во времени, то от этого должен быть какой-то профит, так?
И он, видимо, заключается вот в чем. В соседних фреймах реалистичного видео обычно есть объекты, которые претерпевают небольшие изменения, в то время как все остальное в кадре можно назвать статичным фоном:
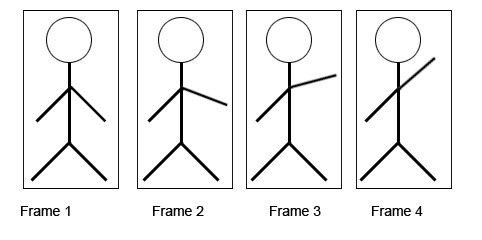
Такие последовательности фреймов называют когерентными, и успешно используют [0][1] для обучения разреженных автоэнкодеров. Задача автоэнкодера — «вытащить» инварианты из предметной области. Выделить то, что остается устойчивым к трансформациям. Собака остается собакой, хоть повернет голову, хоть вильнет хвостом. Изменения на когерентных фреймах — как раз, обычно, и есть трансформации некоторого инварианта. Отсюда и профит в том, чтобы отделять изменняющееся от статичного — так инварианты будут выучиваться быстрее.
Если представить инвариант (собаку) как совокупность переменных (порода, текущая поза, цвет шерсти), а трансформации — как изменения значений этих переменных, то между когерентными фреймами меняются значения не всех переменных сразу. Какие-то зафиксированы, а какие-то меняются, причем меняются не вдруг, а постепенно. Это можно использовать. В самом деле, мозг не просто находит инварианты — он умеет «проматывать» внутри себя цепочки их трансформаций, уменьшая или увеличивая шаг дискретизации. Если мы увидели танцора сначала в одной позе А, а потом в другой позе Б, то мы можем представить анимацию, переводящую его из А в Б.

Чтобы такое стало возможным, мозгу неплохо бы иметь что-то вроде упорядоченных карт, как постепенно меняются значения известных ему переменных. Тут на ум приходит картинка, которую знает, пожалуй, каждый, кто интересовался мозгом — карта направление-специфичности в зрительной коре V1:

Она представляет собой композицию «вертушек». В центре вертушки находятся нейроны, отвечающие на все углы наклона, и их можно рассмотреть как общее обращение к переменной «наклон». А в остальном карта устроена так, что рядом с наклоном в 90 окажутся, скажем, 85 и 95, но никогда не 0. То есть, нейроны расставлены так, чтоб переменная вдоль вертушки варьировалась плавно. Говорят, что формирования похожей структуры можно добиться картами Кохонена.
Гипотезы и непротиворечивость модели
Еще одно гипотетическое достоинство карт-вертушек, посвященных одной переменной, может быть в возможности реализации принципа логического исключения.

Есть переменная «тип животного», и у нее есть значения «утка», «кролик» и т.д. Если нейросеть выстроила верную модель предметной области, то переменная должна принимать только одно значение для одного животного единовременно. Быть одновременно белым и кроликом можно, а уткой и кроликом нет. Если очередная гипотеза, добавляемая в модель, для одного животного активирует одновременно два значения переменной «тип животного», то в модели противоречие. Это немного похоже на то, как мы ставим мысленные эксперименты.
Карта значений переменной и one-shot обучение
Ну так вот… зачем городить огород про эти самые карты, переменные и добавление новых синапсов. Представьте, что сеть не знает, что такое кролик. И имеется всего одна видяшка с одним рыжим кроликом, чтобы обучиться (реалистичные условия для детей). Если в нейросети уже сформировалась карта-вертушка цветов (т.е. как вышеописанная, только про цвет), то, увидев, что сейчас распознался рыжий цвет, можно одним ходом сделать обобщение, что кролики бывают разных цветов. Ведь, в самом деле, в центре вертушки рядом с рыжим нейроном есть нейрон, который отвечает за все цвета сразу. Достаточно пробросить новый синапс от него к «нейрону кролика» или вроде того. Это будет эквивалентно гипотезе «кролики могут быть разных цветов», и она будет сделана по всего одному(!) кролику.
Нужно теперь уточнить, как сеть догадается, что рыжая область это нечто целое и входит в состав кролика.
Группирующие клетки
Выше описывался способ, как сеть могла бы делать «гипотезы», пробрасывая между нейронами новые синапсы. Но с биологической точки зрения, все-таки, этот процесс не такой уж быстрый. За секунду новый синапс не нарастишь. А мы можем формировать некоторые гипотезы очень быстро. Увидели, например, смущенного кота и рассыпанный корм — и сразу готова гипотеза что случилось.

У биологических нейронов есть одна интересная особенность. Они склонны синхронизировать и десинхронизировать свою активность при помощи манипуляций с фазами колебаний. И вот этот механизм уже работает гораздо быстрей. Он (согласно текущей теории в нейрофизиологии) является основой быстрого связывания отдельных фич в единое целое. К примеру, пусть несколько нейронов отвечали каждый за распознавание маленькой черточки. А черточки оказались принадлежащими одному контуру. Тогда найдется группирующая клетка (G-cell) в вышестоящей нейросети, которая в данном конкретном контексте начнет работать как своего рода синхронизатор. Она им будет посылать спайки в качестве обратной связи и поддерживать их синхронность. Если далее на сцене произошло какое-то изменение, и стало выгодно одну из черточек рассматривать как входящую в другой контур, то вышестоящая сеть рассинхронизирует эту черточку от старого контура.

(на картинке: гипотетическая схема с G-cells и двумя контурами во входном изображении).
И хоть это звучит довольно сложно, но суть не такая уж сложная: если распознанные фичи проявили признаки общей судьбы (а именно — были рядом или изменялись вместе), то их надо синхронизировать по фазе внутри осцилляции. Иначе — назначить им разные фазы. Пожалуй, это можно перенести в искусственные сети без добавления спайков и осцилляторов. Похоже, что суть здесь в простом динамическом назначении активному нейрону номера группы, в которую он входит прямо сейчас. Это равносильно очень быстрой гипотезе о том, что нейроны внутри группы (вернее, то что они распознали) связаны общей судьбой внутри контекста.
Семантическое расстояние и fast mapping
Если мы видим рассыпанную еду (А) и смущенного кота (В), то возможно это кот рассыпал еду (В->А). А возможно, здесь поработала скрытая переменная — пришла собака, рассыпала еду, смутила кота и ушла (C->А & C->B). Могут быть разные объяснения, почему две переменные оказались в одном контексте:
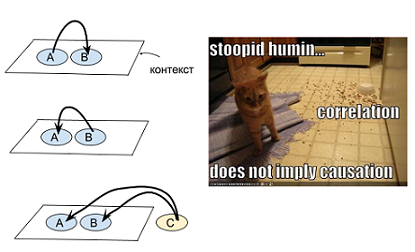
Если допустить (как одну из гипотез), что к наблюдению АВ привело некоторое С, то его логично взять из контекстной окрестности АВ. Т.е. в упомянутом случае мы заподозрим скорее собаку, чем Титаник — потому что Титаник никогда не встречался в одном контексте с сущностями “корм”, “рассыпан”, “животное”, “кухня”.

Объединение сущностей в контексты помогло бы точнее строить первую, грубую гипотезу (которая fast mapping). В пользу того, что в коре существует подобная семантическая карта, говорит, например, маппинг слов и соотвествующей им активности на fMRI:

Apartment, bedroom, rented, lived и впрямь обычно вместе ходят.
P.S.: А что вы думаете о проблеме из заголовка?
Distributed processing and temporal codes in neuronal networks Cogn Neurodyn., 2009
Spike Synchrony Reveals Emergence of Proto-Objects in Visual CortexThe Journal of Neuroscience, 2015
Six principles of visual cortical dynamics Front. Syst. Neurosci., 2010
Discriminative Transfer Learning with Tree-based Priors NIPS, 2013
Dropout: A Simple Way to Prevent Neural Networks from OverfittingJournal of Machine Learning Research, 2014
Spine plasticity in the motor cortex Current Opinion in Neurobiology, 2010
Predicted contextual modulation varies with distance from pinwheel centers in the orientation preference map Scientific Reports, 2011
Reducing Overfitting in Deep Networks by Decorrelating Representations ICLR 2016
Self-taught learning of a deep invariant representation for visual tracking via temporal slowness principle Pattern Recognition, 2015
Experience-dependent structural synaptic plasticity in the mammalian brain Nature Reviews Neuroscience, 2009
Word Learning in a Domestic Dog: Evidence for «Fast Mapping» Science, 2004
A model of the formation of a self-organized cortical representation of color IBM Research
Комментарии (15)
Idot
31.05.2016 07:20Имхо, лучше обучать на 3D-видео, чтобы Нейронная Сеть знала, что котик это просто цветная группа пикселей, а трёхмерный мяукающий объект.

Dark_Daiver
31.05.2016 08:42Вот только фотографий котиков на несколько порядков больше чем «3D-видео» с котиками


nikitysh
01.06.2016 08:18а можете подкинуть ресурсы, на которых можно почитать, начиная с азов, про устройство и работу мозга, описанных в данной статье.
Yane
01.06.2016 09:05Насчет именно азов neuroscience, онлайновые ресурсы врядли смогу подсказать, потому что в свое время азы изучались по бумажному учебнику. Но, возможно, подойдет scholarpedia.
nikitysh
01.06.2016 10:59не обязательно онлайн ресурс, книги тоже подойдут :)

napa3um
01.06.2016 11:07+1http://royallib.com/book/hyubel_devid/glaz_mozg_zrenie.html
Книжка старая, но актуальная, все «новости» нейронаук отлично ложатся поверх этого фундамента.
Yane
01.06.2016 12:43+2nikitysh мне сначала попался один русский учебник, и он меня сильно разочаровал. После этого было решено (мб поспешно) русские учебники не рассматривать. Поэтому была куплена вот эта книжка. Моя оценка 7 из 10, вцелом ок. Вот эта еще должна быть неплохоая. Если выбирать сейчас -то выбрала бы что-то еще новее, типа этого. Neuroscience развивается, кажется, чуть медленнее, чем deep learning, но тоже далеко не стоит на месте. На амазоне отличная коллекция учебников, но стоят они гм… дороговато. Большинство в пиратском инете не находятся, но кое-что бывает.
napa3um
Человек (раз уж вы пытаетесь провести аналогии именно с человеческим мышлением), скорее, не по причине особого устройства своего мозга умеет делать обобщения по скудным частным примерам, а, скорее, по причине особого устройства (информационной) культуры, в которой этот мозг развивался. Человеческий интеллект имеет прежде всего социальную и коммуникативную (языковую) природу, нейроны тут вторичны (субстрат для эволюционирующих информационных процессов). Три частных примера в целевой задаче для человека могут усилиться миллиардами примеров из прошлого жизненного опыта и миллиардами аналогичных задач. Если продолжать аналогию, то вы пытаетесь заставить младенца назвать увиденное животное, при этом младенца никто никогда не обучал языку, и его только что вывели из комы (т.е., вы пытаетесь объяснить некоторые аспекты высшей психической деятельности исключительно нейронами, причём, их самой примитивной и «статичной» версией — персептронами Розенблатта).
khim
Младенец? Какой нафиг младенец. Тут пытаются какую-то губку леопарда научить отлавливать.
Младенцы же демонстрируют чудесные свойства которые однозначто говорят о том, что у них есть довольно сложные, но «незавершённые» системы, которые готовы «воспринять» картинку определённого вида.
Вполне возможно что это всё работает примерно как и предлагается в статье: «врождённая сеть» натренирована на триллионах примеров (за миллионы лет эволюции) «намертво», а к ней «сбоку» (сверху, справа, слева) пристоена «свеженькая» податливая сеть. Как именно эти участки взаимодействуют — вопрос очень интересный, но тот факт, что младенец устроен именно так — это несомненный факт. Анатомический, если что. Старая кора, новая кора и т.д. — это как раз вот об этом.
P.S. Тот факт, что компьютернае системы начинают напоминать человека всё больше и больше по «логическому строению» радует и пугает одновременно…
napa3um
Моё замечание было о том, что высшую психическую деятельность не получится свести к одним лишь нейронам, понадобится более абстрактная интеграционная теория, в которой нейронный субстрат будет лишь набором условий и возможностей для протекания информационных процессов.
Если продолжать ваш комментарий, то я говорю о том, что за старой корой выросла более динамичная новая, а за ней — ещё гораздо более динамичные культура и речь, из которых происходит человеческое абстрактное (символьное) мышление.
palexab
Это несомненно так. Нейроны — это субстрат, аппаратное обеспечение. Но гораздо более гибкое чем существующие технические системы включая и искусственные нейронные сети. В частности потому, что это железо, которое может менять, свою архитектуру как минимум локально (перестройка связей).
А на этапе первичного развития даже глобально (известны случаи восстановления почти всех высших функций (хотя и не до конца) при потере маленьким ребенком одного полушария коры).
pleha
Все же проще предствлять все как софт. Просто более глубокого уровня архитектуры.
Понятно же, что ДНК подвержены внешним влияниям. В семье музыкантов у ребенка легче проявляются задатки к творчеству и так далее.
А дальше уже не удивительно сколько всего закодировано там и передается по наследству из поколений.
http://www.hopkinsmedicine.org/news/media/releases/neurons_constantly_rewrite_their_dna
napa3um
Юному музыканту добиться успеха родительские гены помогают в гораздо меньшей степени, чем их мемы.
valplo
Нейроны — это соматические клетки, изменения в их ДНК никак не могут повлиять на детей. У музыкантов — во-первых мемы, во-вторых неприобретенные генетические задатки.