
Пытливый читатель наверняка уже знаком с принципиально новой архитектурой процессоров — мультиклеточной; а если не знает, сможет бегло ознакомиться в нашей статье. Архитектура настолько непохожа на традиционные, что создание компилятора привычных языков программирования становится проблемой, с которой разработчики безуспешно борются многие годы.
Немного истории
С начала основания компании "Мультиклет" в 2010 велась разработка нескольких типов компиляторов для мультиклеточной архитектуры:
- С первым процессором Multiclet P1 в 2012 году был разработан в составе программного обеспечения компилятор С89 на базе LCC. Одновременно велась разработка первого варианта собственного компилятора, приостановленная ввиду изначально сложного нереализуемого замысла.
Как уже неоднократно указывалось во многих статьях на данную тему, а также признавалось самими разработчиками компании, компилятор на базе LCC имеет ряд существенных недостатков: поддержка лишь языка С89, отсутствие каких-либо оптимизаций.
Впоследствии данный компилятор был адаптирован для поддержки нового процессора Multiclet R1 (2015 г.), система команд которого была значительно расширена, но компилятор этого не учитывал.
Принимая во внимание эти недостатки, руководство компании в 2012 году собрало группу программистов, которым была поставлена задача разработать новый компилятор С99, лишённый указанных недостатков. - Изучив имеющиеся компиляторы (фреймворки для разработки компиляторов) с открытым исходным кодом (GCC и LLVM), было вынесено спорное и категоричное решение: ничего из имеющегося на сегодняшний день для мультиклеточной архитектуры не подходит и необходимо разрабатывать практически с нуля второй вариант своего компилятора.
 И начались три года разработки, которые закончились осенью 2015 года тем, что разработка собственного компилятора была вновь отложена по финансовым соображениям. Требуемые ресурсы превысили финансовые возможности, что при отсутствии какой-либо грантовой или бюджетной поддержки не позволило отвлекать ресурсы на теоретические работы.
И начались три года разработки, которые закончились осенью 2015 года тем, что разработка собственного компилятора была вновь отложена по финансовым соображениям. Требуемые ресурсы превысили финансовые возможности, что при отсутствии какой-либо грантовой или бюджетной поддержки не позволило отвлекать ресурсы на теоретические работы.
- Той же осенью 2015 года было принято решение попробовать разработать компилятор для процессора Multiclet R1 на базе фреймворка LLVM. И вот группа разработчиков в двинулась по этому интересному и захватывающему пути.
Немного деталей
Основная работа заключалась в написании бэкенда компилятора, который
преобразует промежуточное представление LLVM в ассемблерный код для
мультиклеточного процессора Multiclet R1. Это значит, что уже можно пробовать компилировать программы, написанные на любом LLVM языке, надо только указать, чтобы их компиляторы на выходе давали LLVM IR биткод или ассемблер. Затем получившийся файл подавать на вход данного бэкенда.
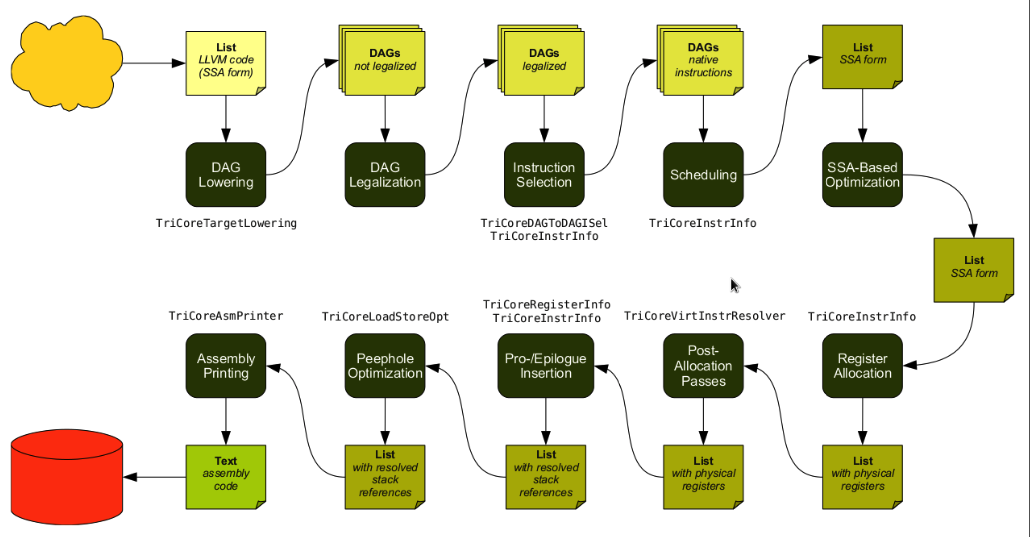
В общих словах при разработке бекенда были выполнены следующие действия:
- Описание целевой архитектуры с использованием абстрактных интерфейсов, а также специализированного языка TableGen, предназначенного для описания общей информации, используемой в LLVM на разных стадиях компиляции (*.td файлы)
1.1. Описание характеристик целевой машины (производный класс от TargetMachine, DataLayout, Multiclet.td)
1.2. Описание набора регистров целевой машины, (производный класс от TargetRegisterInfo, MulticletRegisterInfo.td). На данном этапе сразу проявилась ориентированность фреймворка LLVM на генерацию кода для регистровых машин, к которым по сути мультиклеточные процессоры не относятся. Встал вопрос как описать коммутатор, используемый для обмена результатами между инструкциями. После непродолжительных размышлений было принято решение считать ячейки коммутатора регистрами с ограниченным временем жизни, т. е. значения таких регистров актуальны только в пределах одного базового блока, который в свою очередь является параграфом, и, более того, их актуальность в пределах одного базового блока зависит от области видимости результатов, предоставляемой коммутатором. Забегая вперёд, можно сразу сказать, что подобное решение приводит к необходимость писать свой аллокатор регистров.
1.3. Описание набора инструкций, поддерживаемых целевой машиной (производный класс от TargetInstrInfo, MulticletTargetInstrFormats.td, MulticletTargetInstrInfo.td) - Описание процесса выборки и преобразования инструкций промежуточного представления LLVM IR, представленного в виде направленного ациклического графа (DAG), в соответствующие инструкции, явно поддерживаемые целевой машиной (производный класс от TargetLowering, производный класс от SelectionDAGISel). При реализации данного этапа выявилась необходимость специальной обработки инструкций, которые отображаются в инструкции setXX целевой машины. Дело в том, что инструкции setXX установки значения регистра (НЕ ячейки коммутатора) фактически выполняются по завершению параграфа, т. е., в предположении, что параграф есть базовый блок, по завершению базового блока, поэтому данные инструкции должны разбивать базовый блок. Данное поведение было реализовано при помощи специальных обработчиков (Instruction Emitting Hooks), которые вызываются при генерации инструкции, класса TargetLowering, в частности EmitInstrWithCustomInserter.
- Далее, непосредственно перед аллокацией регистров, было добавлено два прохода, которые отражают специфику мультиклеточной архитектуры:
3.1. Анализ и модификация инструкций передачи управления. Дело в том, что в мультиклеточной архитектуре фактически имеются лишь инструкции установки адреса следующего выполняемого параграфа (хотя они и названы, весьма неудачно, jmp и jXX), а сама передача управления осуществляется по окончанию текущего параграфа. Поэтому на данном проходе, во-первых, в базовый блок, в котором отсутствует инструкция передачи управления (в этом случае предполагается, что выполняется следующий расположенный в памяти базовый блок), добавляется инструкция безусловной передачи управления на следующий базовый блок, а во-вторых, в базовом блоке, в котором имеется одна условная инструкция передачи управления, непосредственно за которой следует одна безусловная инструкция передачи управления, безусловная инструкция передачи управления заменяется на условную инструкцию передачи управления с противоположным условием.
3.2. Анализ инструкций чтения из памяти и записи в память. Так как в мультиклеточной архитектуре выполнение инструкций неупорядоченно, то в одном базовом блоке в общем случае недопустимо выполнение двух инструкций записи по одному и тому же адресу, а также выполнение инструкции чтения по адресу, по которому ранее могла быть (а могла ещё и не быть) выполнена инструкция записи. - Фреймворк LLVM предоставляет следующий набор аллокаторов регистров: fast, basic, greedy, pbqp. В виду особенностей (наличие коммутатора) мультиклеточной архитектуры из представленных выше аллокаторов правильный ассемблерный код может быть сгенерирован только при использовании fast аллокатора, который распределяет регистры на уровне базовых блоков, что в рамках принятой концепции "базовый блок есть параграф" и необходимо. Так как fast аллокатор является аллокатором по умолчанию для сборок с поддержкой возможности отладки, он не осуществляет никаких оптимизаций. Для устранения данного факта был разработан свой собственный аллокатор multiclet, который также содержит некоторые дополнительные архитектурно-зависимые оптимизации.
- Реализация вставки пролога/эпилога функции (производный класс от TargetFrameLowering).
- Далее, непосредственно перед выводом ассемблерного кода, было добавлено два прохода, которые отражают специфику мультиклеточной архитектуры:
6.1. Оптимизация расположения инструкций передачи управления. Так как в мультиклеточной архитектуре инструкции передачи управления фактически являются инструкциями установки адреса, по которому по окончании базового блока (параграфа) будет необходимо передать управление, то на данном проходе мы перемещаем такие инструкции (по возможности) как можно ближе к началу базового блока.
6.2. Устранение ссылок на результаты ранее выполненных инструкций, которые выходят за границу области видимости результатов, предоставляемых коммутатором.
На сегодняшний день данный проход выполняет очень простую обработку подобных ссылок, которая заключается в добавлении инструкции move в необходимую позицию последовательности инструкций. В некоторых случаях такая тривиальная обработка может закончиться неудачно, что приведёт к аварийному завершению программы (компилятора). - Реализация прохода эмиссии кода (вывода ассемблерного кода).
Набор изменений, внесённых во фронтенд, был значительно меньше: добавлена мультиклеточная архитектура в качестве поддерживаемой целевой машины.
В результате проведённой работы был заложен хороший фундамент для развития компилятора для мультиклеточных процессоров на базе LLVM. Другими словами, разработка данного компилятора находится чуть дальше начальной стадии, о чём свидетельствует следующий неполный список недоработок текущей версии компилятора:
- Отсутствует полноценная поддержка 64-х разрядной целочисленной арифметики.
- отсутствует поддержка векторных инструкций, которые в ограниченном наборе поддерживаются процессором Multiclet R1.
- Архитектурно-зависимые оптимизации на стороне бэкенда находятся в зачаточном состоянии (реализованы лишь очевидные оптимизации).
- Компилятор не учитывает всех возможных аппаратных ошибок процессора Multiclet R1 (вообще учёт и обход таких ошибок хочется сделать на стороне ассемблера, чтобы компилятор верхнего уровня был, по возможности, освобождён от решения данной задачи, а также не повторять один и тот же код в различных компиляторах верхнего уровня, если таковых имеется несколько (у нас есть компилятор C89 на базе lcc)).
- Отсутствует стандартная библиотека языка C, математическая библиотека и др.
- Отсутствует возможность генерации позиционно независимого кода (-fPIC), весь генерируемый код является статическим.
- Отсутствует генерация отладочной информации.
- Реакция компилятора на использование в исходном коде программы атрибутов (attribute) и ассемблерных вставок не известна, так как тесты такого кода не проводились (возможно в некоторых случаях произойдёт аварийное завершение работы компилятора).
Представленный компилятор можно скачать на официальном сайте компании здесь.
Задать все вопросы можно на форуме.
О текущих результатах
С помощью текущей версии компилятора были скомпилированы различные короткие программы на языке C, которые были в основном использованы для тестирования, A Lightweight TCP/IP stack версии 1.4.1, тест Coremark.
Результат выполнения теста Coremark для Multiclet R1 составляет 0.56 Coremark/MHz, что почти в два раза лучше, чем тест Coremark, для компиляции которого использовался компилятор
C89 на базе LCC.
Конечно, результат 0.56 Coremark/MHz ещё далёк от желаемых 2-3 единиц. Во-первых, это связано с отсутствием хороших архитектурно-зависимых оптимизаций в представленной версии компилятора, и, во-вторых, с неоптимальностью некоторых
аппаратных блоков данной конкретной реализации процессора Multiclet R1, которые плохо адаптированы для выполнения последовательных (плохо распараллеливаемых) алгоритмов, которых в Coremark не так уж и мало.
Сравнительная таблица показателей CoreMark
| Multiclet P1 (lcc compiler) | Multiclet R1 (lcc compiler) | Multiclet R1 (llvm compiler) | 985BE91T Миландр ARM Cortex-M3 | STM32F4x ARM Cortex-M4 | RX62N Renesas | WIPS proAptive RTL FPGA prototype | Intel Core i7-2760QM CPU@2.40GHz | |
|---|---|---|---|---|---|---|---|---|
| Тактовая частота, МГц | 80 | 100 | 100 | 80 | 168 | 100 | 31 | 2400 |
| Общий показатель CoreMark | 24.49 | 24.95 | 56.45 | 117.6 | 501.85 | 311.54 | 137.10 | 85151.68 |
| CoreMark/MHz | 0.31 | 0.25 | 0.56 | 1.47 | 2.98 | 3.12 | 4.42 | 35.48 |
Для оценки архитектур параллельных процессоров более целесообразно использование ассемблерных программ, учитывающих все особенности архитектуры и реализующих параллельные алгоритмы. Рассмотрим пару примеров.
Пример реализации на ассемблере алгоритма подсчёта популяции единичных бит в 512-ти разрядном операнде, быстродействие которого на процессоре Multiclet R1 сравнимо с аналогичным показателем на процессоре Intel Core i7.
.data
.p2align 3
work_result:
.space 8, 0
tmp:
.long 0
.text
.alias value1 GPR0
.alias value2 GPR1
.alias value3 GPR2
.alias value4 GPR3
.alias value5 GPR4
.alias value6 GPR5
.alias value7 GPR6
.alias value8 GPR7
.alias result IR0
init:
jmp init_timer
setl #result, 0x0
b1 := getb 0x0
b2 := getb @b1 + 1
b3 := getb @b1 + 2
b4 := getb @b1 + 3
b5 := getb @b1 + 4
b6 := getb @b1 + 5
b7 := getb @b1 + 6
b8 := getb @b1 + 7
s2 := slll @b2, 8
s3 := slll @b3, 16
s4 := slll @b4, 24
s6 := slll @b6, 8
s7 := slll @b7, 16
s8 := slll @b8, 24
v1 := andl @b1, 0x000000FF
v2 := andl @s2, 0x0000FF00
v3 := andl @s3, 0x00FF0000
v4 := andl @s4, 0xFF000000
v5 := andl @b5, 0x000000FF
v6 := andl @s6, 0x0000FF00
v7 := andl @s7, 0x00FF0000
v8 := andl @s8, 0xFF000000
r1_16 := orl @v1, @v2
r2_16 := orl @v3, @v4
r3_16 := orl @v5, @v6
r4_16 := orl @v7, @v8
r1_32 := orl @r1_16, @r2_16
r2_32 := orl @r3_16, @r4_16
r64 := patch @r1_32, @r2_32
setq #value1, @r64
setq #value2, @r64
setq #value3, @r64
setq #value4, @r64
setq #value5, @r64
setq #value6, @r64
setq #value7, @r64
setq #value8, @r64
complete
init_timer:
jmp init_timer_2
wrl @0, 0xC0010018; TIM0_CR0
complete
init_timer_2:
jmp init_timer_3
getl 10 - 1
getl 0xFFFFFFFF
wrl @2, 0xC0010004; TIM0_PSCPER
wrl @2, 0xC0010014; TIM0_CNTPER0
complete
init_timer_3:
getl 0x03
wrl @1, 0xC0010018; TIM0_CR0
jmp start_popcnt512
complete
start_popcnt512:
jmp new_popcnt512_reg
rdl 0xC0010010; TIM0_CNTVAL0
wrdl @1, tmp
complete
new_popcnt512_reg:
val1 := getl #value1
val2 := getl #value2
val3 := getl #value3
val4 := getl #value4
val5 := getl #value5
val6 := getl #value6
val7 := getl #value7
val8 := getl #value8
val9 := pack @0, #value1
val10 := pack @0, #value2
val11 := pack @0, #value3
val12 := pack @0, #value4
val13 := pack @0, #value5
val14 := pack @0, #value6
val15 := pack @0, #value7
val16 := pack @0, #value8
s1_1 := slrl @val1, 1
s1_2 := slrl @val2, 1
s1_3 := slrl @val3, 1
s1_4 := slrl @val4, 1
s1_5 := slrl @val5, 1
s1_6 := slrl @val6, 1
s1_7 := slrl @val7, 1
s1_8 := slrl @val8, 1
s1_9 := slrl @val9, 1
s1_10 := slrl @val10, 1
s1_11 := slrl @val11, 1
s1_12 := slrl @val12, 1
s1_13 := slrl @val13, 1
s1_14 := slrl @val14, 1
s1_15 := slrl @val15, 1
s1_16 := slrl @val16, 1
s2_1 := andl @s1_1, 0x55555555
s2_2 := andl @s1_2, 0x55555555
s2_3 := andl @s1_3, 0x55555555
s2_4 := andl @s1_4, 0x55555555
s2_5 := andl @s1_5, 0x55555555
s2_6 := andl @s1_6, 0x55555555
s2_7 := andl @s1_7, 0x55555555
s2_8 := andl @s1_8, 0x55555555
s2_9 := andl @s1_9, 0x55555555
s2_10 := andl @s1_10, 0x55555555
s2_11 := andl @s1_11, 0x55555555
s2_12 := andl @s1_12, 0x55555555
s2_13 := andl @s1_13, 0x55555555
s2_14 := andl @s1_14, 0x55555555
s2_15 := andl @s1_15, 0x55555555
s2_16 := andl @s1_16, 0x55555555
s3_1 := subl @val1, @s2_1
s3_2 := subl @val2, @s2_2
s3_3 := subl @val3, @s2_3
s3_4 := subl @val4, @s2_4
s3_5 := subl @val5, @s2_5
s3_6 := subl @val6, @s2_6
s3_7 := subl @val7, @s2_7
s3_8 := subl @val8, @s2_8
s3_9 := subl @val9, @s2_9
s3_10 := subl @val10, @s2_10
s3_11 := subl @val11, @s2_11
s3_12 := subl @val12, @s2_12
s3_13 := subl @val13, @s2_13
s3_14 := subl @val14, @s2_14
s3_15 := subl @val15, @s2_15
s3_16 := subl @val16, @s2_16
s4_1 := andl @s3_1, 0x33333333
s4_2 := andl @s3_2, 0x33333333
s4_3 := andl @s3_3, 0x33333333
s4_4 := andl @s3_4, 0x33333333
s4_5 := andl @s3_5, 0x33333333
s4_6 := andl @s3_6, 0x33333333
s4_7 := andl @s3_7, 0x33333333
s4_8 := andl @s3_8, 0x33333333
s4_9 := andl @s3_9, 0x33333333
s4_10 := andl @s3_10, 0x33333333
s4_11 := andl @s3_11, 0x33333333
s4_12 := andl @s3_12, 0x33333333
s4_13 := andl @s3_13, 0x33333333
s4_14 := andl @s3_14, 0x33333333
s4_15 := andl @s3_15, 0x33333333
s4_16 := andl @s3_16, 0x33333333
s5_1 := slrl @s3_1, 2
s5_2 := slrl @s3_2, 2
s5_3 := slrl @s3_3, 2
s5_4 := slrl @s3_4, 2
s5_5 := slrl @s3_5, 2
s5_6 := slrl @s3_6, 2
s5_7 := slrl @s3_7, 2
s5_8 := slrl @s3_8, 2
s5_9 := slrl @s3_9, 2
s5_10 := slrl @s3_10, 2
s5_11 := slrl @s3_11, 2
s5_12 := slrl @s3_12, 2
s5_13 := slrl @s3_13, 2
s5_14 := slrl @s3_14, 2
s5_15 := slrl @s3_15, 2
s5_16 := slrl @s3_16, 2
s6_1 := andl @s5_1, 0x33333333
s6_2 := andl @s5_2, 0x33333333
s6_3 := andl @s5_3, 0x33333333
s6_4 := andl @s5_4, 0x33333333
s6_5 := andl @s5_5, 0x33333333
s6_6 := andl @s5_6, 0x33333333
s6_7 := andl @s5_7, 0x33333333
s6_8 := andl @s5_8, 0x33333333
s6_9 := andl @s5_9, 0x33333333
s6_10 := andl @s5_10, 0x33333333
s6_11 := andl @s5_11, 0x33333333
s6_12 := andl @s5_12, 0x33333333
s6_13 := andl @s5_13, 0x33333333
s6_14 := andl @s5_14, 0x33333333
s6_15 := andl @s5_15, 0x33333333
s6_16 := andl @s5_16, 0x33333333
s7_1 := addl @s4_1, @s6_1
s7_2 := addl @s4_2, @s6_2
s7_3 := addl @s4_3, @s6_3
s7_4 := addl @s4_4, @s6_4
s7_5 := addl @s4_5, @s6_5
s7_6 := addl @s4_6, @s6_6
s7_7 := addl @s4_7, @s6_7
s7_8 := addl @s4_8, @s6_8
s7_9 := addl @s4_9, @s6_9
s7_10 := addl @s4_10, @s6_10
s7_11 := addl @s4_11, @s6_11
s7_12 := addl @s4_12, @s6_12
s7_13 := addl @s4_13, @s6_13
s7_14 := addl @s4_14, @s6_14
s7_15 := addl @s4_15, @s6_15
s7_16 := addl @s4_16, @s6_16
s8_1 := slrl @s7_1, 4
s8_2 := slrl @s7_2, 4
s8_3 := slrl @s7_3, 4
s8_4 := slrl @s7_4, 4
s8_5 := slrl @s7_5, 4
s8_6 := slrl @s7_6, 4
s8_7 := slrl @s7_7, 4
s8_8 := slrl @s7_8, 4
s8_9 := slrl @s7_9, 4
s8_10 := slrl @s7_10, 4
s8_11 := slrl @s7_11, 4
s8_12 := slrl @s7_12, 4
s8_13 := slrl @s7_13, 4
s8_14 := slrl @s7_14, 4
s8_15 := slrl @s7_15, 4
s8_16 := slrl @s7_16, 4
s9_1 := addl @s7_1, @s8_1
s9_2 := addl @s7_2, @s8_2
s9_3 := addl @s7_3, @s8_3
s9_4 := addl @s7_4, @s8_4
s9_5 := addl @s7_5, @s8_5
s9_6 := addl @s7_6, @s8_6
s9_7 := addl @s7_7, @s8_7
s9_8 := addl @s7_8, @s8_8
s9_9 := addl @s7_9, @s8_9
s9_10 := addl @s7_10, @s8_10
s9_11 := addl @s7_11, @s8_11
s9_12 := addl @s7_12, @s8_12
s9_13 := addl @s7_13, @s8_13
s9_14 := addl @s7_14, @s8_14
s9_15 := addl @s7_15, @s8_15
s9_16 := addl @s7_16, @s8_16
s10_1 := andl @s9_1, 0xF0F0F0F
s10_2 := andl @s9_2, 0xF0F0F0F
s10_3 := andl @s9_3, 0xF0F0F0F
s10_4 := andl @s9_4, 0xF0F0F0F
s10_5 := andl @s9_5, 0xF0F0F0F
s10_6 := andl @s9_6, 0xF0F0F0F
s10_7 := andl @s9_7, 0xF0F0F0F
s10_8 := andl @s9_8, 0xF0F0F0F
s10_9 := andl @s9_9, 0xF0F0F0F
s10_10 := andl @s9_10, 0xF0F0F0F
s10_11 := andl @s9_11, 0xF0F0F0F
s10_12 := andl @s9_12, 0xF0F0F0F
s10_13 := andl @s9_13, 0xF0F0F0F
s10_14 := andl @s9_14, 0xF0F0F0F
s10_15 := andl @s9_15, 0xF0F0F0F
s10_16 := andl @s9_16, 0xF0F0F0F
s11_1 := mull @s10_1, 0x1010101
s11_2 := mull @s10_2, 0x1010101
s11_3 := mull @s10_3, 0x1010101
s11_4 := mull @s10_4, 0x1010101
s11_5 := mull @s10_5, 0x1010101
s11_6 := mull @s10_6, 0x1010101
s11_7 := mull @s10_7, 0x1010101
s11_8 := mull @s10_8, 0x1010101
s11_9 := mull @s10_9, 0x1010101
s11_10 := mull @s10_10, 0x1010101
s11_11 := mull @s10_11, 0x1010101
s11_12 := mull @s10_12, 0x1010101
s11_13 := mull @s10_13, 0x1010101
s11_14 := mull @s10_14, 0x1010101
s11_15 := mull @s10_15, 0x1010101
s11_16 := mull @s10_16, 0x1010101
s12_1 := slrl @s11_1, 24
s12_2 := slrl @s11_2, 24
s12_3 := slrl @s11_3, 24
s12_4 := slrl @s11_4, 24
s12_5 := slrl @s11_5, 24
s12_6 := slrl @s11_6, 24
s12_7 := slrl @s11_7, 24
s12_8 := slrl @s11_8, 24
s12_9 := slrl @s11_9, 24
s12_10 := slrl @s11_10, 24
s12_11 := slrl @s11_11, 24
s12_12 := slrl @s11_12, 24
s12_13 := slrl @s11_13, 24
s12_14 := slrl @s11_14, 24
s12_15 := slrl @s11_15, 24
s12_16 := slrl @s11_16, 24
sum1 := addl @s12_1, @s12_2
sum2 := addl @s12_3, @s12_4
sum3 := addl @s12_5, @s12_6
sum4 := addl @s12_7, @s12_8
sum5 := addl @s12_9, @s12_10
sum6 := addl @s12_11, @s12_12
sum7 := addl @s12_13, @s12_14
sum8 := addl @s12_15, @s12_16
sum9 := addl @sum1, @sum2
sum10 := addl @sum3, @sum4
sum11 := addl @sum5, @sum6
sum12 := addl @sum7, @sum8
sum13 := addl @sum9, @sum10
sum14 := addl @sum11, @sum12
sum15 := addl @sum13, @sum14
setl #result, @sum15
jmp stop_popcnt512
complete
stop_popcnt512:
jmp save_result
rdl 0xC0010010; TIM0_CNTVAL0
rdl tmp
subl @1, @2
wrdl @1, work_result
complete
save_result:
jmp uart_init
getl #result
wrdl @1, work_result + 4
complete
uart_init:
jmp uart_print
altport := getl 0xFFFFFFFF
control := getl 0x00000003; rx, tx enable
bitrate := getl 0x34;
wrdl @control, 0xC0000108
wrdl @altport, 0xC00F0218
wrdl @bitrate, 0xC000010C
setl #GPR0, 8
complete
uart_print:
count := getl #GPR0
je @count, stop
jne @count, uart_wait
setl #GPR0, #GPR0, -1
complete
uart_wait:
st := rddl 0xC0000104
andl @st, 2
je @1, uart_wait
jne @2, uart_print_data
complete
uart_print_data:
jmp uart_print
data := rdq work_result
n_data := slrq @data, 8
wrq @n_data, work_result
wrdb @data, 0xC0000100
complete
stop:
getl 0x0
completeДанная реализация выполняет указанный алгоритм примерно за 90 тактов.
Для сравнения рассмотрим эквивалентный код на языке C
#include "timer.h"
#include "mc-stdio.h"
#include "serial.h"
#define B1 0
#define B2 1
#define B3 2
#define B4 3
#define B5 4
#define B6 5
#define B7 6
#define B8 7
unsigned int countBits(unsigned int x)
{
x = x - ((x >> 1) & 0x55555555);
x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
x = x + (x >> 4);
x &= 0xF0F0F0F;
return (x * 0x01010101) >> 24;
}
void init(unsigned int *v, int cnt)
{
unsigned int v1 = ((B1 & 0xFF) << 0) | ((B2 & 0xFF) << 8)
| ((B3 & 0xFF) << 16) | ((B4 & 0xFF) << 24);
unsigned int v2 = ((B5 & 0xFF) << 0) | ((B6 & 0xFF) << 8)
| ((B7 & 0xFF) << 16) | ((B8 & 0xFF) << 24);
for (int i = 0; i < cnt; i += 2)
{
v[i] = v1;
v[i+1] = v2;
}
}
#define SIZE 16
int main(int argc, char *argv[])
{
init_system_timer(TIM0, 0x03, 0xffffffff, 10);
SER_init();
unsigned int res = 0;
unsigned int v[SIZE];
init(v, SIZE);
uint32_t start = get_system_ticks(TIM0);
for (int i = 0; i < SIZE; ++i)
res += countBits(v[i]);
uint32_t stop = get_system_ticks(TIM0);
mc_uprintf(0, "ticks count = 0x%X\nbits_count = %u", start - stop, res);
return res;
}Для компиляции необходимо выполнить следующую команду:
clang -target multiclet -O2 -S test_popcnt.c -o test_popcnt.s -I<PATH_TO_INCL_DIR>
.text
.file "test_popcnt.c"
.globl countBits
.type countBits,@function
countBits:
SR2 := rdl #IR7, 4
SR3 := rdl #IR7
jmp @SR3
SR4 := slrl @SR2, 1
SR5 := andl @SR4, 1431655765
SR4 := subsl @SR2, @SR5
SR2 := andl @SR4, 858993459
SR5 := slrl @SR4, 2
SR4 := andl @SR5, 858993459
SR5 := addsl @SR4, @SR2
SR2 := slrl @SR5, 4
SR4 := addsl @SR2, @SR5
SR2 := andl @SR4, 252645135
SR4 := mulsl @SR2, 16843009
SR2 := slrl @SR4, 24
setq #GPR7, @SR2
complete
.Lfunc_end0:
.size countBits, .Lfunc_end0-countBits
.globl init
.type init,@function
init:
jmp LBB1_1
setl #IR7, #IR7, -16
complete
LBB1_1:
SR2 := rdl #IR7, 24
SR3 := ltsl @SR2, 1
je @SR3, LBB1_2
jne @SR3, LBB1_3
complete
LBB1_2:
jmp LBB1_4
SR2 := rdl #IR7, 20
SR3 := addsl @SR2, 4
wrq @SR3, #IR7, 8
wrq @0, #IR7
complete
LBB1_4:
SR2 := getl 50462976
SR3 := getl 117835012
SR4 := rdl #IR7, 24
SR5 := rdq #IR7
SR6 := rdq #IR7, 8
SR7 := addsl @SR6, -4
wrl @SR3, @SR6
SR3 := addsl @SR6, 8
SR6 := addsl @SR5, 2
wrl @SR2, @SR7
SR2 := ltsl @SR6, @SR4
je @SR2, LBB1_3
jne @SR2, LBB1_4
wrq @SR3, #IR7, 8
wrq @SR6, #IR7
complete
LBB1_3:
SR2 := rdl #IR7, 16
jmp @SR2
setl #IR7, #IR7, 16
complete
.Lfunc_end1:
.size init, .Lfunc_end1-init
.globl main
.type main,@function
main:
jmp LBB2_1
setl #IR7, #IR7, -128
complete
LBB2_1:
jmp init_system_timer
SR2 := getl 10
SR3 := getl -1
SR4 := getl 3
SR5 := getl -1073676288
SR6 := getl LBB2_2
wrl @SR2, #IR7, 16
wrl @SR3, #IR7, 12
wrl @SR4, #IR7, 8
wrl @SR5, #IR7, 4
wrl @SR6, #IR7
complete
LBB2_2:
jmp SER_init
SR2 := getl LBB2_3
wrl @SR2, #IR7
complete
LBB2_3:
jmp get_system_ticks
SR2 := getl -1073676288
SR3 := getl 50462976
SR4 := getl 117835012
SR5 := getl LBB2_4
wrl @SR3, #IR7, 64
wrl @SR4, #IR7, 68
wrl @SR3, #IR7, 72
wrl @SR4, #IR7, 76
wrl @SR3, #IR7, 80
wrl @SR4, #IR7, 84
wrl @SR3, #IR7, 88
wrl @SR4, #IR7, 92
wrl @SR3, #IR7, 96
wrl @SR4, #IR7, 100
wrl @SR3, #IR7, 104
wrl @SR4, #IR7, 108
wrl @SR3, #IR7, 112
wrl @SR4, #IR7, 116
wrl @SR3, #IR7, 120
wrl @SR4, #IR7, 124
wrl @SR2, #IR7, 4
wrl @SR5, #IR7
complete
LBB2_4:
jmp LBB2_8
SR2 := getl 4
SR3 := getq #GPR7
SR4 := exal #IR7, 64
wrq @SR2, #IR7, 56
wrq @SR2, #IR7, 48
wrq @SR3, #IR7, 40
wrq @SR4, #IR7, 24
complete
LBB2_8:
SR2 := rdq #IR7, 24
SR3 := rdq #IR7, 48
SR4 := rdq #IR7, 56
SR5 := addsl @SR2, @SR4
SR2 := addsl @SR4, 4
SR4 := rdl @SR5
SR5 := xorl @SR2, 64
jne @SR5, LBB2_8
je @SR5, LBB2_5
wrq @SR2, #IR7, 56
SR2 := slrl @SR4, 1
SR6 := andl @SR2, 1431655765
SR2 := subsl @SR4, @SR6
SR4 := andl @SR2, 858993459
SR6 := slrl @SR2, 2
SR2 := andl @SR6, 858993459
SR6 := addsl @SR2, @SR4
SR2 := slrl @SR6, 4
SR4 := addsl @SR2, @SR6
SR2 := andl @SR4, 252645135
SR4 := mulsl @SR2, 16843009
SR2 := slrl @SR4, 24
SR4 := addsl @SR2, @SR3
wrq @SR4, #IR7, 48
wrq @SR4, #IR7, 32
complete
LBB2_5:
jmp get_system_ticks
SR2 := getl -1073676288
SR3 := getl LBB2_6
wrl @SR2, #IR7, 4
wrl @SR3, #IR7
complete
LBB2_6:
jmp mc_uprintf
SR2 := rdq #IR7, 40
SR3 := rdq #IR7, 32
SR4 := getq #GPR7
SR5 := getl .L.str
wrl @0, #IR7, 4
SR6 := getl LBB2_7
SR7 := subsl @SR2, @SR4
wrl @SR5, #IR7, 8
wrl @SR3, #IR7, 16
wrl @SR6, #IR7
wrl @SR7, #IR7, 12
complete
LBB2_7:
SR2 := rdq #IR7, 32
setq #GPR7, @SR2
SR2 := rdl #IR7, 128
jmp @SR2
setl #IR7, #IR7, 128
complete
.Lfunc_end2:
.size main, .Lfunc_end2-main
.type .L.str,@object
.section .rodata.str1.1,"aMS",@progbits,1
.L.str:
.asciz "ticks count = 0x%X\nbits_count = %u"
.size .L.str, 35Данная реализация выполняет указанный алгоритм примерно за 950 тактов, что более, чем в 10 раз хуже ассемблерной версии.
Приведём сводную таблицу результатов (количество тактов на один цикл расчёта 32-х бит)
| Алгоритм | Multiclet R1 © | Multiclet R1 (ASM) | Pentium Dual Core 5700 3.0GHz | Intel Core i7-4700HQ@2400 |
|---|---|---|---|---|
| BitHacks | 59.4 | 5.0 | 9.5 | 4.7 |
Одним из наиболее презентативных алгоритмов является БПФ. При этом, для исключения технологических факторов, оценка должна проводится в тактах, затрачиваемых на решение данной задачи, также необходимо учитывать количество операций выполняемых за один такт и их особенности (количество данных формируемых SIMD операцией может составлять два и более).
.alias IRBASE 8
.alias IR0 8
.alias IR1 9
.alias IR2 10
.alias IR3 11
.alias IR4 12
.alias IRMASK01234 ((1 << (IR0 - IRBASE)) | (1 << (IR1 - IRBASE)) | (1 << (IR2 - IRBASE)) | (1 << (IR3 - IRBASE)) | (1 << (IR4 - IRBASE)))
.alias IRMASK04 ((1 << (IR0 - IRBASE)) | (1 << (IR4 - IRBASE)))
.syntax V1
.data
ticks:
.long 0
.align 8
W:
; Re(z), Im(z)
.float 0f1.000000000000000000000000, 0f-0.000000000000000000000000, 0f0.999698817729949951171875, 0f-0.024541229009628295898438, 0f0.998795449733734130859375, 0f-0.049067676067352294921875, 0f0.997290432453155517578125, 0f-0.073564566671848297119141, 0f0.995184719562530517578125, 0f-0.098017141222953796386719, 0f0.992479562759399414062500, 0f-0.122410677373409271240234, 0f0.989176511764526367187500, 0f-0.146730467677116394042969, 0f0.985277652740478515625000, 0f-0.170961901545524597167969, 0f0.980785250663757324218750, 0f-0.195090323686599731445312, 0f0.975702106952667236328125, 0f-0.219101235270500183105469, 0f0.970031261444091796875000, 0f-0.242980197072029113769531, 0f0.963776051998138427734375, 0f-0.266712784767150878906250, 0f0.956940352916717529296875, 0f-0.290284663438796997070312, 0f0.949528157711029052734375, 0f-0.313681751489639282226562, 0f0.941544055938720703125000, 0f-0.336889863014221191406250, 0f0.932992815971374511718750, 0f-0.359895050525665283203125, 0f0.923879504203796386718750, 0f-0.382683455944061279296875, 0f0.914209723472595214843750, 0f-0.405241340398788452148438, 0f0.903989315032958984375000, 0f-0.427555084228515625000000, 0f0.893224298954010009765625, 0f-0.449611335992813110351562, 0f0.881921231746673583984375, 0f-0.471396744251251220703125, 0f0.870086967945098876953125, 0f-0.492898225784301757812500, 0f0.857728600502014160156250, 0f-0.514102756977081298828125, 0f0.844853579998016357421875, 0f-0.534997642040252685546875, 0f0.831469595432281494140625, 0f-0.555570244789123535156250, 0f0.817584812641143798828125, 0f-0.575808227062225341796875, 0f0.803207516670227050781250, 0f-0.595699310302734375000000, 0f0.788346409797668457031250, 0f-0.615231633186340332031250, 0f0.773010432720184326171875, 0f-0.634393334388732910156250, 0f0.757208824157714843750000, 0f-0.653172850608825683593750, 0f0.740951120853424072265625, 0f-0.671558976173400878906250, 0f0.724247097969055175781250, 0f-0.689540565013885498046875, 0f0.707106769084930419921875, 0f-0.707106769084930419921875, 0f0.689540505409240722656250, 0f-0.724247097969055175781250, 0f0.671558916568756103515625, 0f-0.740951180458068847656250, 0f0.653172791004180908203125, 0f-0.757208883762359619140625, 0f0.634393274784088134765625, 0f-0.773010432720184326171875, 0f0.615231573581695556640625, 0f-0.788346409797668457031250, 0f0.595699310302734375000000, 0f-0.803207516670227050781250, 0f0.575808167457580566406250, 0f-0.817584812641143798828125, 0f0.555570185184478759765625, 0f-0.831469655036926269531250, 0f0.534997642040252685546875, 0f-0.844853579998016357421875, 0f0.514102697372436523437500, 0f-0.857728660106658935546875, 0f0.492898195981979370117188, 0f-0.870086967945098876953125, 0f0.471396654844284057617188, 0f-0.881921291351318359375000, 0f0.449611306190490722656250, 0f-0.893224298954010009765625, 0f0.427555114030838012695312, 0f-0.903989315032958984375000, 0f0.405241280794143676757812, 0f-0.914209783077239990234375, 0f0.382683426141738891601562, 0f-0.923879504203796386718750, 0f0.359894961118698120117188, 0f-0.932992815971374511718750, 0f0.336889833211898803710938, 0f-0.941544055938720703125000, 0f0.313681662082672119140625, 0f-0.949528217315673828125000, 0f0.290284633636474609375000, 0f-0.956940352916717529296875, 0f0.266712754964828491210938, 0f-0.963776051998138427734375, 0f0.242980122566223144531250, 0f-0.970031261444091796875000, 0f0.219101220369338989257812, 0f-0.975702106952667236328125, 0f0.195090234279632568359375, 0f-0.980785310268402099609375, 0f0.170961856842041015625000, 0f-0.985277652740478515625000, 0f0.146730497479438781738281, 0f-0.989176511764526367187500, 0f0.122410625219345092773438, 0f-0.992479562759399414062500, 0f0.098017133772373199462891, 0f-0.995184719562530517578125, 0f0.073564492166042327880859, 0f-0.997290432453155517578125, 0f0.049067649990320205688477, 0f-0.998795449733734130859375, 0f0.024541135877370834350586, 0f-0.999698817729949951171875, 0f-0.000000043711388286737929, 0f-1.000000000000000000000000, 0f-0.024541223421692848205566, 0f-0.999698817729949951171875, 0f-0.049067739397287368774414, 0f-0.998795449733734130859375, 0f-0.073564574122428894042969, 0f-0.997290432453155517578125, 0f-0.098017223179340362548828, 0f-0.995184719562530517578125, 0f-0.122410707175731658935547, 0f-0.992479503154754638671875, 0f-0.146730571985244750976562, 0f-0.989176511764526367187500, 0f-0.170961946249008178710938, 0f-0.985277652740478515625000, 0f-0.195090323686599731445312, 0f-0.980785250663757324218750, 0f-0.219101309776306152343750, 0f-0.975702106952667236328125, 0f-0.242980197072029113769531, 0f-0.970031261444091796875000, 0f-0.266712844371795654296875, 0f-0.963776051998138427734375, 0f-0.290284723043441772460938, 0f-0.956940293312072753906250, 0f-0.313681721687316894531250, 0f-0.949528157711029052734375, 0f-0.336889922618865966796875, 0f-0.941544055938720703125000, 0f-0.359895050525665283203125, 0f-0.932992815971374511718750, 0f-0.382683515548706054687500, 0f-0.923879504203796386718750, 0f-0.405241340398788452148438, 0f-0.914209723472595214843750, 0f-0.427555084228515625000000, 0f-0.903989315032958984375000, 0f-0.449611365795135498046875, 0f-0.893224298954010009765625, 0f-0.471396833658218383789062, 0f-0.881921231746673583984375, 0f-0.492898166179656982421875, 0f-0.870087027549743652343750, 0f-0.514102756977081298828125, 0f-0.857728600502014160156250, 0f-0.534997701644897460937500, 0f-0.844853520393371582031250, 0f-0.555570363998413085937500, 0f-0.831469535827636718750000, 0f-0.575808167457580566406250, 0f-0.817584812641143798828125, 0f-0.595699369907379150390625, 0f-0.803207516670227050781250, 0f-0.615231692790985107421875, 0f-0.788346350193023681640625, 0f-0.634393274784088134765625, 0f-0.773010492324829101562500, 0f-0.653172850608825683593750, 0f-0.757208824157714843750000, 0f-0.671559035778045654296875, 0f-0.740951061248779296875000, 0f-0.689540684223175048828125, 0f-0.724246978759765625000000, 0f-0.707106769084930419921875, 0f-0.707106769084930419921875, 0f-0.724247157573699951171875, 0f-0.689540505409240722656250, 0f-0.740951240062713623046875, 0f-0.671558856964111328125000, 0f-0.757208824157714843750000, 0f-0.653172850608825683593750, 0f-0.773010492324829101562500, 0f-0.634393274784088134765625, 0f-0.788346469402313232421875, 0f-0.615231513977050781250000, 0f-0.803207635879516601562500, 0f-0.595699131488800048828125, 0f-0.817584812641143798828125, 0f-0.575808167457580566406250, 0f-0.831469655036926269531250, 0f-0.555570185184478759765625, 0f-0.844853639602661132812500, 0f-0.534997463226318359375000, 0f-0.857728600502014160156250, 0f-0.514102756977081298828125, 0f-0.870087027549743652343750, 0f-0.492898136377334594726562, 0f-0.881921350955963134765625, 0f-0.471396625041961669921875, 0f-0.893224298954010009765625, 0f-0.449611365795135498046875, 0f-0.903989315032958984375000, 0f-0.427555054426193237304688, 0f-0.914209783077239990234375, 0f-0.405241221189498901367188, 0f-0.923879623413085937500000, 0f-0.382683277130126953125000, 0f-0.932992815971374511718750, 0f-0.359895050525665283203125, 0f-0.941544115543365478515625, 0f-0.336889803409576416015625, 0f-0.949528217315673828125000, 0f-0.313681602478027343750000, 0f-0.956940352916717529296875, 0f-0.290284723043441772460938, 0f-0.963776051998138427734375, 0f-0.266712725162506103515625, 0f-0.970031261444091796875000, 0f-0.242980077862739562988281, 0f-0.975702166557312011718750, 0f-0.219101071357727050781250, 0f-0.980785310268402099609375, 0f-0.195090308785438537597656, 0f-0.985277652740478515625000, 0f-0.170961812138557434082031, 0f-0.989176511764526367187500, 0f-0.146730333566665649414062, 0f-0.992479503154754638671875, 0f-0.122410699725151062011719, 0f-0.995184719562530517578125, 0f-0.098017096519470214843750, 0f-0.997290492057800292968750, 0f-0.073564447462558746337891, 0f-0.998795449733734130859375, 0f-0.049067486077547073364258, 0f-0.999698817729949951171875, 0f-0.024541210383176803588867
.text
// системный таймер
init_timer:
setl #ST0PRDR, 0xFFFFFFFF
setl #ST0CR, 0x1
jmp start
complete
start:
jmp L1;
setl #PSW, 0x00000040; Чтение и запись идут параллельно
getl 0x000007C0;
patch @1, 0x00000000;
setq #IR0, @1;
getl 0x0001001F;
patch @1, 0x00000000;
setq #IR4, @1;
complete;
L1:
irm IRMASK04
exa #IR4;
je @1, L2;
jne @2, L1;
rdc #IR0, x + 0 * 8; x0
rdc #IR0, x + 2 * 8; x2
rdc #IR0, x + 4 * 8; x4
rdc #IR0, x + 6 * 8; x6
rdc #IR0, x + 1 * 8; x1
rdc #IR0, x + 3 * 8; x3
rdc #IR0, x + 5 * 8; x5
rdc #IR0, x + 7 * 8; x7
rdc W + 64 * 8; W4_1
addc @9, @5; x0=x0+x1
subc @10, @6; x1=x0-x1
addc @10, @6; x2=x2+x3
subc @11, @7; x3=x2-x3
addc @11, @7; x4=x4+x5
subc @12, @8; x5=x4-x5
addc @12, @8; x6=x6+x7
subc @13, @9; x7=x6-x7
mulc @9, @5; W4_1*x3
mulc @10, @2; W4_1*x7
addc @10, @8; x0=x0+x2
addc @10, @3; x1=x1+W4_1*x3
subc @12, @10; x2=x0-x2
subc @12, @5; x3=x1-W4_1*x3
addc @10, @8; x4=x4+x6
addc @10, @6; x5=x5+W4_1*x7
subc @12, @10; x6=x4-x6
subc @12, @8; x7=x5-W4_1*x7
wrc @8, #IR0, x + 0 * 8;
wrc @8, #IR0, x + 1 * 8;
wrc @8, #IR0, x + 2 * 8;
wrc @8, #IR0, x + 3 * 8;
wrc @8, #IR0, x + 4 * 8;
wrc @8, #IR0, x + 5 * 8;
wrc @8, #IR0, x + 6 * 8;
wrc @8, #IR0, x + 7 * 8;
complete
L2:
jmp L3;
getl 0x00000718;
patch @1, 0x00000000;
setq #IR0, @1;
getl 0x00000300;
patch @1, W;
setq #IR1, @1;
getl 0x00000180;
patch @1, W;
setq #IR2, @1;
getl 0x000000C0;
patch @1, W;
setq #IR3, @1;
getl 0x0001001F;
patch @1, 0x00000000;
setq #IR4, @1;
complete;
L3:
irm IRMASK01234
exa #IR4;
je @1, L4;
jne @2, L3;
rdc #IR1; W8_i
rdc #IR0, x + 4 * 8; x1
rdc #IR0, x + 12 * 8; x3
rdc #IR0, x + 20 * 8; x5
rdc #IR0, x + 28 * 8; x7
mulc @5, @4; W8_i*x1
mulc @6, @4; W8_i*x3
mulc @7, @4; W8_i*x5
mulc @8, @4; W8_i*x7
rdc #IR0, x + 0 * 8; x0
rdc #IR0, x + 8 * 8; x2
rdc #IR0, x + 16 * 8; x4
rdc #IR0, x + 24 * 8; x6
addc @3, @7; x2=x2+W8_i*x3
subc @4, @8; x3=x2-W8_i*x3
addc @3, @7; x6=x6+W8_i*x7
subc @4, @8; x7=x6-W8_i*x7
addc @8, @12; x0=x0+W8_i*x1
subc @9, @13; x1=x0-W8_i*x1
addc @8, @12; x4=x4+W8_i*x5
subc @9, @13; x5=x4-W8_i*x5
rdc #IR2; W16_i
rdc #IR2, 0x0200; W16_j
mulc @2, @10; W16_i*x2
mulc @2, @10; W16_j*x3
mulc @4, @10; W16_i*x6
mulc @4, @10; W16_j*x7
addc @8, @2; x4=x4+W16_i*x6
addc @8, @2; x5=x5+W16_j*x7
subc @10, @4; x6=x4-W16_i*x6
subc @10, @4; x7=x5-W16_j*x7
addc @14, @8; x0=x0+W16_i*x2
addc @14, @8; x1=x1+W16_j*x3
subc @16, @10; x2=x0-W16_i*x2
subc @16, @10; x3=x1-W16_j*x3
mulc @8, #IR3; W32*x4
mulc @8, #IR3, 0x0100; W32*x5
mulc @8, #IR3, 0x0200; W32*x6
mulc @8, #IR3, 0x0300; W32*x7
addc @8, @4; x0=x0+W*x4
addc @8, @4; x1=x1+W*x5
addc @8, @4; x2=x2+W*x6
addc @8, @4; x3=x3+W*x7
subc @12, @8; x4=x0-W*x4
subc @12, @8; x5=x1-W*x5
subc @12, @8; x6=x2-W*x6
subc @12, @8; x7=x3-W*x7
wrc @8, #IR0, x + 0 * 8;
wrc @8, #IR0, x + 4 * 8;
wrc @8, #IR0, x + 8 * 8;
wrc @8, #IR0, x + 12 * 8;
wrc @8, #IR0, x + 16 * 8;
wrc @8, #IR0, x + 20 * 8;
wrc @8, #IR0, x + 24 * 8;
wrc @8, #IR0, x + 28 * 8;
complete
L4:
jmp L5;
getl 0x000000F8;
patch @1, 0x00000000;
setq #IR0, @1;
getl 0x000003E0;
patch @1, W;
setq #IR1, @1;
getl 0x000001F0;
patch @1, W;
setq #IR2, @1;
getl 0x000000F8;
patch @1, W;
setq #IR3, @1;
getl 0x0001001F;
patch @1, 0x00000000;
setq #IR4, @1;
complete;
L5:
irm IRMASK01234
exa #IR4;
je @1, stop;
jne @2, L5;
rdc #IR1; W32_i
rdc #IR0, x + 32 * 8; x1
rdc #IR0, x + 96 * 8; x3
rdc #IR0, x + 160 * 8; x5
rdc #IR0, x + 224 * 8; x7
mulc @5, @4; W32_i*x1
mulc @6, @4; W32_i*x3
mulc @7, @4; W32_i*x5
mulc @8, @4; W32_i*x7
rdc #IR0, x + 0 * 8; x0
rdc #IR0, x + 64 * 8; x2
rdc #IR0, x + 128 * 8; x4
rdc #IR0, x + 192 * 8; x6
addc @3, @7; x2=x2+W32_i*x3
subc @4, @8; x3=x2-W32_i*x3
addc @3, @7; x6=x6+W32_i*x7
subc @4, @8; x7=x6-W32_i*x7
addc @8, @12; x0=x0+W32_i*x1
subc @9, @13; x1=x0-W32_i*x1
addc @8, @12; x4=x4+W32_i*x5
subc @9, @13; x5=x4-W32_i*x5
rdc #IR2; W64_i
rdc #IR2, 0x0200; W64_j
mulc @2, @10; W64_i*x2
mulc @2, @10; W64_j*x3
mulc @4, @10; W64_i*x6
mulc @4, @10; W64_j*x7
addc @8, @2; x4=x4+W64_i*x6
addc @8, @2; x5=x5+W64_j*x7
subc @10, @4; x6=x4-W64_i*x6
subc @10, @4; x7=x5-W64_j*x7
addc @14, @8; x0=x0+W64_i*x2
addc @14, @8; x1=x1+W64_j*x3
subc @16, @10; x2=x0-W64_i*x2
subc @16, @10; x3=x1-W64_j*x3
mulc @8, #IR3; W128_i*x4
mulc @8, #IR3, 0x0100; W128_j*x5
mulc @8, #IR3, 0x0200; W128_k*x6
mulc @8, #IR3, 0x0300; W128_l*x7
addc @8, @4; x0=x0+W128_i*x4
addc @8, @4; x1=x1+W128_j*x5
addc @8, @4; x2=x2+W128_k*x6
addc @8, @4; x3=x3+W128_l*x7
subc @12, @8; x4=x0-W128_i*x4
subc @12, @8; x5=x1-W128_j*x5
subc @12, @8; x6=x2-W128_k*x6
subc @12, @8; x7=x3-W128_l*x7
wrc @8, #IR0, x + 0 * 8;
wrc @8, #IR0, x + 32 * 8;
wrc @8, #IR0, x + 64 * 8;
wrc @8, #IR0, x + 96 * 8;
wrc @8, #IR0, x + 128 * 8;
wrc @8, #IR0, x + 160 * 8;
wrc @8, #IR0, x + 192 * 8;
wrc @8, #IR0, x + 224 * 8;
complete
stop:
jmp uart_init
getl #ST0VAL
wrdl @1, ticks
complete
.syntax V2
uart_init:
jmp uart_print
altport := getl 0xFFFFFFFF
control := getl 0x00000003; rx, tx enable
bitrate := getl 0x34;
wrdl @control, 0xC0000108
wrdl @altport, 0xC00F0218
wrdl @bitrate, 0xC000010C
setl #GPR0, 32
complete
uart_print:
count := getl #GPR0
je @count, finish
jne @count, uart_wait
setl #GPR0, #GPR0, -8
complete
uart_wait:
st := rddl 0xC0000104
andl @st, 2
je @1, uart_wait
jne @2, uart_print_data
complete
uart_print_data:
jmp uart_print
data := rdl ticks
slrl @data, #GPR0
wrdb @1, 0xC0000100
complete
finish:
getl 0;
completeСравнение результатов выполнения комплексного БПФ с плавающей запятой одинарной точности на 256 точек:
| Количество операций | Количество тактов | Количество операций за такт | Наличие комплексных / SIMD операций | |
|---|---|---|---|---|
| Multiclet R1, Мультиклет | 9400 | 2350 | 4 | комплексные |
| 1967ВН034, Миландр | 10872 | 1812 | 6 | SIMD |
| Процессоры семейства С66х, TI | 14256 | 1782 | 8 | комплексные |
| ADSP-TS201S, Analog Devices | 22272 | 1928 | 24 | SIMD |
Приведенные результаты показывают, что мультиклеточная архитектура более эффективно реализует параллелизм. Наиболее отчетливо это видно при сравнении с процессорами семейства С66х, которые также как и мультиклеточный процессор имеют команды комплексной арифметики, выполняемые в потоке за такт.
Из представленных примеров на ассемблере видно, что мультиклеточная архитектура позволяет достичь намного лучших результатов, поэтому мы считаем, что есть перспектива совершенствования компилятора.
В настоящее время компилятор успешно используется для портирования наработанного программного обеспечения на мультиклеточные процессоры по контрактам с российскими и зарубежными компаниями-заказчиками.
Приглашаем всех желающих, энтузиастов мультиклеточной архитектуры принять участие в тестировании компилятора на форуме.
UPD: Исправлена опечатка в таблице результатов БПФ: в количество тактов у ADSP-TS201S вернули потерянную тысячу тактов.
Комментарии (36)

potan
07.06.2016 15:18-4Почему сразу C/C++? На LLVM сделано много более полезных языков — например Rust (особенно для встраиваемых систем).

snizovtsev
07.06.2016 15:50Так сделали же бэкэнд LLVM, фронтэнд может быть хоть Rust, если я правильно понимаю. И как бы не был Rust хорош, кому нужен процессор (на позицию аналога, а не революции, как квантовые вычисления), для которого нужно переписывать весь софт на новом ЯП? К тому же Rust скорее конкурент C++, а не C.
potan
07.06.2016 17:24-2Для встраиваемых систем повторно использовать софт не всегда получается, значительная часть пишется заново.
Переход C++ -> Rust сложнее, чем C -> Rust. На Rust можно программировать как на C, только безопасно, а плюсовикам придется сильно менять свои привычки.
RPG18
07.06.2016 18:27+2Как понимаю, они хотят создать процессор общего назначения, а при наличие компилятора Си можно портировать NetBSD, Linux и любую другую ОС.

GenadyIvanovich
08.06.2016 10:14+1Ага. И кучу другого, уже написанного, софта.
Всё-таки Rust и прочие Haskell — пока больше экзотика «для ценителей». Да, и как у него с эффективностью использования ресурсов? А с низкоуровневым доступом к аппаратуре? Как бы не получилось так, что, чтобы общаться с железом, нужна спец.библиотека, написанная на… Си.
Ну, и, кроме того, имея нормально работающий бэкенд, мы (почти) автоматически получаем поддержку всего зоопарка языков, знакомых LLVM.
GenadyIvanovich
10.06.2016 10:35+3Вот сейчас пришёл коллега, и говорит, что скомпилировал и запустил на отладочной плате Rust-пример, мигающий лампочками.
Так что не всё так плохо.



Ramzeska
07.06.2016 15:21-3Скомпилируйте на этом проце майнер биткоина или етериума и с финансированием разработок все проблемы разом отпадут )
VaalKIA
07.06.2016 21:33Не знаю, за что вас минусанули (наверное за отпавшие проблемы). На самом деле я предлагал реализовать майнер, это же хороший тест, куча платформ имеет рейтиг в майнинге биткоинов и по сути это аналог рейтингу в шифровании. Только биткоины привлекают гораздо больше внимания чем само шифрование. Популяризация необычным архитекутрам всегда нужна.
VaalKIA
07.06.2016 21:50+3Прекрасная статья, хорошо представленый материал. Надесюь, что годовой провал в работе с общественностью закончился, и Мультиклет мы регулряно будем видеть на Хабре.
Пара замечаний: не надо напирать на задачу подсчёта битов, Интел делает это одной коммандой, используйте везде конкретное название алгоритма и одного раза (в скобочках) достаточно, — его суть.
По таблице БПФ не понял логики: про SIMD пнятно, типа слишком тяжёлые и узкоспециализированные комаманды — нечего на них смотреть.
Про c66x… Мультиклет 10 000 операций сделал за 2 000 тактов (грубо), c66x 15 000 распараллелил так, что выполнялись всего за 1 500 тактов. Как, по мне, так вывод, что c66x параллелит гораздо лучше, но набор комманд хуже, поскольку ассемблерный листинг больше.
Говорят, lazarus можно подключить к LLVM, неужели на Дельфи под Мультиклет получится? :-)
Halt
07.06.2016 21:56+1Говорят, lazarus можно подключить к LLVM, неужели на Дельфи под Мультиклет получится? :-)
Если FPC умеет генерировать IR код, и его call convention не является каким-то экзотическим (скорее всего pascal, либо же stdcall) то да, думаю можно.
GenadyIvanovich
08.06.2016 10:23C66х для решения той же задачи потребовалось в полтора раза больше операций (читай: «электричества»); при этом, имея в два раза больше исполнительный устройств, справился с задачей он всего на 30% быстрее.
А, поскольку это — VLIW, то получается, что «параллелит лучше» не процессор, а компилятор, с его неограниченными ресурсами и вИдением всей программы.VaalKIA
08.06.2016 14:29-1Наиболее отчетливо это видно
По таблице — не видно, поскольку там нет упоминаний про исполнителные устройства.
Количество операций ровнять с эелектричеством — не стоит, есть архитектуры CISC и RISC, что как бы уже само намекает о бесполезности такого сравнения.
А говоря об эффективности, именно в этом месте статьи, вообще говорится не о вычислительных ресурсах на Вт, а оэффективно реализует параллелизм
. Пока что останусь при своём мнении, по цифрам изделие от TI выглядит более выгодно.
Что же касается количества инструкций, то, например z80 не имеет инструкции умножения и в сравнении, количество инструкций на алгоритм будет больше, но понятно, что здесь речь скорее не о архитектуре, а о развитости набора комманд. Поэтому, если цифрой 15 000 операций хотели сказать что-то конкретное об архитектуре процессора, то надо изложить это более подробно, самой цифры не достаточно, нужен анализ.GenadyIvanovich
09.06.2016 07:58По таблице — не видно, поскольку там нет упоминаний про исполнителные устройства.
Молчаливо предполагается, что оносовпадаеткоррелирует с числом операций, исполняемых за такт.VaalKIA
09.06.2016 11:58-1В таком контексте — есть смысл, но всё же стоит это добавить к статье. Однако, есть такая вещь как конвеер, который позволяет «накладывать» инструкции друг на друга и, хотя, по идее быстрее чем за такт на каждую на нём не получится, суперскаляры имеют несколько конвееров, а для эмулирующих CISC, так называемых decoupled RISC архитектур (те же x86), над одной инструкцией вполне себе работают несколько конвееров и пол такта на инструкцию это у них норма. Я уже не говорю о том, что конвееры могут быть специализированными и работать на разных частотах (могу гнать), например для FP (совсем недавно это вообще был сопроцессор) и для целочисленных операций.
GenadyIvanovich
09.06.2016 11:42Речь идёт о конкретной аппаратной реализации совершенно новой архитектуры, причём о второй реализации, и тот факт, что мы уже сравниваемся с монстрами, имеющими 30+ лет опыта в разработке DSP и десятки (сотни?) реализаций в кремнии, вселяет оптимизм. Более того, уже сейчас видны пути повышения производительности следующего процессора в разы.
VaalKIA
09.06.2016 12:04-1Тогда ответьте мне на вашем форуме (или здесь) на эту тему:
http://multiclet.com/community/boards/3/topics/1633
Я уже созрел что бы вложить тысяч 20 на хобби, а Мультиклет обещает много интереснейшего и перспективного опыта.
Кстати, я уже упоминал о краудрафтинге, но вы упорно не хотите им заниматься, я думаю, что не одинок в том. что с удовольствием дал бы деньги вперёд под ещё не выпущенный процессор, если, к примеру. там появился бы MMU и подождал месяцев 6.GenadyIvanovich
10.06.2016 08:11Наш опыт краудфандинга на kickstarter с проектом устройства криптозащиты Key_P1 на процессоре Multiclet P1 (которое не есть теория, а реально продается) показал, что технически сложные устройства массово средств не собирают, а ресурсы уходят в раскрутку сайта kickstarter. Тем более, такие комплектующие, как новый микропроцессор:). Шансы собрать тысячу энтузиастов по 20 тр для его выпуска равны нулю. Более реальным сегодня мы видим путь IPO (initial public offer) под проект настольного суперкомпьютера.
VaalKIA
12.06.2016 00:10Ну хорошо, проведите опрос на хабре хотя бы, сколько человек готовы внести предоплату, это-то можно сделать?

Randl
08.06.2016 08:32+1Блин, это же так круто — писать бекэнд под новую архитектуру…
А исходников нет?
Из тестов можно еще ГПСЧ погонять например.
GenadyIvanovich
08.06.2016 10:18+3Никакого секрета из исходников мы не делаем: пишите в личку, вышлем без проблем.
С Гитхабом вопрос порешаем в ближайшее время.
Sergei2405
08.06.2016 18:47+1А откуда взяты данные для FFT256 для ADSP-TS201S
Сам разработчик заявляет что порядка 2000 тактов нужно
http://www.analog.com/media/en/technical-documentation/application-notes/EE-218.pdf
Так же хотелось бы поподробней причины провала.
Во-первых, это связано с отсутствием хороших архитектурно-зависимых оптимизаций в представленной версии компилятора
Где именно простои, как планируете их исправлять (в железе, в компиляторе)?
во-вторых, с неоптимальностью некоторых
аппаратных блоков данной конкретной реализации процессора Multiclet R1, которые плохо адаптированы для выполнения последовательных
Приведенные в сравнении конкуренты это одно-алушные (в большинстве) процессоры, а у вас как минимум 4 клетки.
Какая производительность на одной клетке?GenadyIvanovich
09.06.2016 11:51Сам разработчик заявляет что порядка 2000 тактов нужно
Да, вы правы: в исходную таблицу вкралась опечатка, и тысячу тактов потеряли. Должно быть 1928.
Так же хотелось бы поподробней причины провала.
Поясните, пожалуйста, о чём речь в вопросе?
Где именно простои, как планируете их исправлять (в железе, в компиляторе)?
По нашим очень грубым оценкам, в задачах типа CoreMark ожидать от компилятора улучшения в 1,5...2 раза не стоит, речь, скорее, может идти о 20...30%. Пример с popcnt в этом смысле, скорее, исключение, показывающее, что всякие «низкоуровневые» критичные к производительности вещи, типа FFT и FIR/IIR, на Си писать не стоит; поэтому основной прирост производительности мы планируем получить доработкой аппаратной части. Тем более, сейчас отчётливо видны недостатки данной конкретной аппаратной реализации, устранив которые, мы рассчитываем в следующей ревизии процессора ускориться в 4,5...5 раз.
Приведенные в сравнении конкуренты это одно-алушные (в большинстве) процессоры, а у вас как минимум 4 клетки.
Здесь нас подстерегает один очень коварный момент: да, у конкурентов АЛУ одно, но оно содержит несколько исполнительных устройств, каждое из которых может за такт исполнять несколько инструкций. Более того, умножитель у них не входит а АЛУ, а стоит рядышком, и в «количество АЛУ» вклад не вносит. У нас же каждая клетка устроена более примитивно, а необходимый параллелизм достигается числом клеток.
Поэтому более корректно сравнивать не число АЛУ, а количество операций, которое процессор может выполнить за такт.
Какая производительность на одной клетке?
Если наш FFT задумает исполняться на одной клетке, у него на это уйдёт 6008 тактов. При этом он освободит три другие клетки, которые, используя свойство динамической реконфигурации, мы прямо «на ходу» сможем параллельно направить на решение ещё трёх разных задач. Более того, так же, «на ходу» можем, при необходимости, решать задачу и на двух, и на трёх клетках.VaalKIA
09.06.2016 12:34Здесь нас подстерегает один очень коварный момент: да, у конкурентов АЛУ одно, но оно содержит несколько исполнительных устройств, каждое из которых может за такт исполнять несколько инструкций. Более того, умножитель у них не входит а АЛУ, а стоит рядышком, и в «количество АЛУ» вклад не вносит. У нас же каждая клетка устроена более примитивно, а необходимый параллелизм достигается числом клеток.
Поэтому более корректно сравнивать не число АЛУ, а количество операций, которое процессор может выполнить за такт.
Вам надо более аргументированно высказывать эту позицию, особенно рисуя таблицы сравнений, возможно это даже тянет на статью.
Вообще говоря, иногда просто тянет стукнуть кулаком по столу — врут что компилятор оптимизирует код под конкретный процессор, пусть «перекомпилирует сразу в микрокод», не насилуйте компилятор. Но тут же вспоминаешь про VLIW, который именно это и решает и понимаешь, что это совсем не то, что тебе нужно, потому что делает супер быстрыми твои собственные программы и очень неэффективными уже в следующей ревизии процессора, те что нельзя перекомпильнуть (то есть, все остальные, если мы не о OpenSource).
Поэтому мне импонирует, что в Мультиклет нет ещё одной прокладки между ISA и исполнением программы, то есть компилятору доступны «сами конвееры» и вроде как даже это особенность архитектуры.
мы планируем получить доработкой аппаратной части. Тем более, сейчас отчётливо видны недостатки данной конкретной аппаратной реализации, устранив которые, мы рассчитываем в следующей ревизии процессора ускориться в 4,5...5 раз.
Только один вопрос: куда слать бабло, которое побеждает зло?krufter
10.06.2016 11:31-1Я бы предложил идти по плану:
1) 2017 — оптимизированная реализация ядра
2) 2018 — разработка Мультиклет с RapidIO
3) Статья о масштабируемости и сравнение с https://geektimes.ru/company/dronk/blog/277084/
GenadyIvanovich
10.06.2016 10:48-1Что касается представленной версии компилятора, то причины не очень хороших результатов тестов Coremark и popcnt, в основном, заключаются в отсутствии оптимизации циклов с учётом возможностей архитектуры, а именно, применения таких методов оптимизации, как раскрутка цикла, распараллеливание цикла, векторизация цикла.
krufter
10.06.2016 09:34Приятно видеть, что появилась новая статья теперь уже правда не в моем исполнении). Давно к вам не заходил, но выражаю тут бурные овации Михаилу за то, что сделал компилятор llvm примерно за полгода, не имея до этого опыта работы с llvm. Наверное это хорошо, когда один и тот же человек написал ассемблер, линкер, редактор связей, загрузчик, конверторы, компилятор llvm, это скорее плюс к надежности и скорости.
Чтобы у большинства пользователей было представление о производительности, рассмотрим ядро Cortex-M4. На данном ядре сделаны очень популярные процессоры stm32f4, процессоры фирмы nxp и многие другие. В сообществе nxp приводятся следующие результаты https://community.nxp.com/thread/327833 нас интересует строчка
— arm_cfft_radix2_f32 — 327.0 us; // real float32_t 256
С учетом процессора для теста на частоте 120 МГц получим на такт 8,3 нс. Далее 327000/8,3 = 39398 тактов.
У приведенных в статье процессоров эта процедура идет примерно в 20 раз быстрее. Для Мультиклет R1 смотрю не стали заморачиваться и оптимизировать реализацию FFT256, просто скомпилировали, что написано для P1. Для R1 мне обещали по временному распределению и с учетом новых команд 1500 тактов вместо 2350.
Но вообще изначально, чтобы где ни писалось и не говорилось мультиклеточная архитектура задумывалась как общего назначения, т.е. на последовательных операциях Мультиклет должен быть как минимум равен Cortex M4 и другим процессорам, а на распараллеливаемых операциях быть быстрее во много раз.
Стоит отличать архитектуру процессора и её реализацию, так как реализовать всё, что задумано, процесс не быстрый. R1 — вторая реализация, P1 — первая. Разница между ними не ступенька, а наверно пара этажей. И тем не менее у разработчиков Мультиклета есть целый список, часть которого опубликована на форуме, что нужно сделать для получения того же coremark или другого лапшеобразно витееватого кода как у Cortex M4 и при этом достигнув увеличения производительности на параллельном исполнении и выйгрыша в энергопотреблении.
Итак, что же нужно для полного воплощения мультиклеточной архитектуры в реальность:
1) 9 месяцев работы исключительно над ядром
2) 3 месяца на топологию, выпуск кристаллов и корпусирование их на фабрике
3) Думаю 30-40 млн руб. должно хватить по моим конечно же субъективным оценкам
Я бы посоветовал руководству Мультиклета первым шагом сделать на базе процессора R1 хорошую реализацию архитектуры, предоставив разработчикам достаточное количество времени без формата «должно быть готово полгода назад», формат «готово вчера» подойдет. А уже затем переходить к разработке больших вычислительных систем.
Желаю Мультиклету и другим отечественным разработчикам удачи и надеюсь увидеть новые статьи, и сам надеюсь найти время на публикацию своей новой статьи.Sergei2405
10.06.2016 13:32+32) 3 месяца на топологию, выпуск кристаллов и корпусирование их на фабрике
1. Непонятно почему Мультиклет с таким упорством печет кристаллы, которые никому не нужны?
Оба варианта P1 и R1 гарантированно влазят не в самые большие FPGA. А для специалистов более чем достаточными являются данные по производительности в числе тактов на задачу полученные на FPGA прототипах. А максимальную частоту на FPGA так же можно экстраполировать на частоту ASIC. Но при этом цикл внесения изменений/исправлений на пару порядков быстрей.
2. Непонятны попытки сделать компилятор своими силами, при условии наличия как минимум 2-х специализирующихся на этом команд в России? Не хорошо считать чужие деньги и при всем уважении к полученному результату, но мне кажется на зарплату ушло больше чем просили бы профи. И результат у профи был бы лучше и за меньший срок.
3. Непонятно почему остановились на FFT256, есть еще классические 1К и 64К точечные преобразования, Они возможно показывают совсем другие результаты и не в лучшую сторону, так как не «влазят» во внутреннюю память кристалла (а в FPGA влезли бы....)
4. Непонятно как будут вести себя более чем 4 клетки в кристалле. Или как они же 4 шт будут решать разные задачи
Если наш FFT задумает исполняться на одной клетке, у него на это уйдёт 6008 тактов. При этом он освободит три другие клетки, которые, используя свойство динамической реконфигурации, мы прямо «на ходу» сможем параллельно направить на решение ещё трёх разных задач. Более того, так же, «на ходу» можем, при необходимости, решать задачу и на двух, и на трёх клетках.
Это же можно прям сейчас сделать? Покажите (докажите), что при решении разных задач на клетках выборка из памяти программ не будет узким местом?
Мое виденье Мультиклета было что это обычный процессор, для которого верхний уровень параллелизма (уровень не связанных функций и задач) реализуется на уровне компилятора, как для обычных многоядерных процессоров, а низкий уровень параллелизма (уровень вычисления логический функций итп) реализуется аппаратно на уровне клеток, которые сами «ищут» те инструкции которые могут быть выполнены. Но вы опять таки FFT пишите на ассемблере (параллелите вручную), и чем это отличается от классических DSP процессоров не ясно. Вообщем создается впечатление, что есть какие то фундаментальные проблемы в архитектуре.
AKudinov
10.06.2016 15:50-21. Нет, не влезают. Вообще никак.
3. Разумеется, если данные приходится тащить снаружи, производительность резко падает. 1К-точечное влезет точно. Оптимизируем 256-точечное, сделаем из него 1К-точечное, и прогоним. Но не сразу.
не «влазят» во внутреннюю память кристалла (а в FPGA влезли бы....)
Насчёт памяти FPGA утверждение очень спорное.
4.Непонятно как будут вести себя более чем 4 клетки в кристалле. Или как они же 4 шт будут решать разные задачи
Конкретизируйте, пожалуйста, что именно вам не понятно? В статье по ссылке тов. krufter подробно описывал, как работает реконфигурация.
Это же можно прям сейчас сделать?
Без проблем. Берёте отладку с ЭрОдин, берёте пример, запускаете.
Покажите (докажите), что при решении разных задач на клетках выборка из памяти программ не будет узким местом?
Не будет, и обеспечивается это структурой памяти программ. Она, мало того, что разбита на восемь вертикальных столбцов по 32 бита шириной каждый, так ещё и по длине разделена на четыре равных банка. С независимым доступом к каждому столбцу каждого банка. Так что достаточно, чтобы задачи находились в разных банках, и проблем не будет. Более того, память данных разделена аналогичным образом.
Но вы опять таки FFT пишите на ассемблере
Это нормальная практика.
параллелите вручную
Покажите, где это? Вас смущает то, что циклы частично развёрнуты вручную? Ну так это просто помогает процессору извлекать необходимый параллелизм.
и чем это отличается от классических DSP процессоров не ясно
Под «классическими», видимо, следует понимать VLIW? Так у них весь параллелизм извлекается компилятором под конкретный кристалл. И уже ни шага в сторону не сделать, двоичный код на другом процессоре не запустить, VaalKIA выше высказывался на эту тему. О том, чтобы запустить вторую (третью, четвёртую) задачу на простаивающих устройствах, лучше не думать. И о реконфигурации на ходу — даже не мечтать.
napa3um
Мультиклеточная архитектура процессора, на мой взгляд, очень близка к ныне модной реактивной и data-driven программным архитектурам. Возможно, эффективный компилятор для такого процессора должен работать не только на уровне инструкций компилируемого языка, но и на уровне семантики каких-нибудь библиотек для реактивного и data-driven программирования (например, повторяя API http://reactivex.io/ или https://facebook.github.io/relay/). Можно представить себе это как код на «классическом» языке программирования, в котором программист ссылается на потоки данных, которые (вместе со всеми преобразованиями) декларативно описаны в виде какой-нибудь XML/JSON-схемы (или декларативный язык сразу встроен в «классический» язык в стиле LINQ).