Как чуден и глубок русский курлык
— Генератор постов
Обработка естественного языка (natural language processing, NLP) — тема, на мой взгляд, очень интересная. Во-первых, задачи тут чисто алгоритмические: на вход принимаем совершенно примитивный объект, строчку, а извлечь пытаемся вложенный в него смысл (ну или хотя бы частичку смысла). Во-вторых, необязательно быть профессиональным лингвистом, чтобы решать эти задачи: достаточно знать родной язык на более-менее приличном уровне и любить его.
А ещё с небольшими затратами можно сделать какого-нибудь бестолкового чат-бота — или, как вот я, генератор постов на основе того, что вы писали на своей страничке в соцсети. Возможно, кто-то из вас уже видел это приложение — оно довольно глупое, чаще всего выдает бессмысленный и бессвязный текст, но изредка всё же дает повод улыбнуться.
Бессвязность текстов в нынешней версии «Генератора» вызвана тем, что на самом деле никакого анализа он производить не умеет. Просто в одних случаях «предсказывает» продолжение предложения по собранным биграммам, а в других — заменяет в готовом предложении некоторые слова на другие, которые заканчиваются похоже. Вот и вся начинка.
Конечно, хочется сделать что-нибудь поинтереснее. Беда в том, что модные сейчас нейросети не очень-то применимы здесь: им нужно много ресурсов, большую обучающую выборку, а в браузере у пользователя соцсети всего этого нет. Поэтому я решил изучить вопрос работы с текстами с помощью алгоритмов. К сожалению, готовых инструментов для работы с русским языком на JavaScript найти не удалось, и я решил сделать свой маленький велосипед.

Az
Свою библиотеку я назвал Az. С одной стороны — это первая буква кириллицы, «азъ», и в то же время первая и последняя буквы латиницы. Сразу дам все ссылки:
— GitHub;
— Документация: либо на гитхабе же, либо на Doclets.io;
— Демо.
Установить библиотеку вы можете как из npm, так и из bower (в обоих местах она имеет название az). На свой страх и риск — она ещё не покрыта полностью тестами и до выхода первой версии (который произойдет скоро, я надеюсь) у неё могут измениться публичные API. Лицензия: MIT.
На данный момент библиотека умеет две вещи: токенизацию и анализ морфологии. В некотором отдаленном будущем (но не в первой версии) предполагается реализовать синтаксический анализ и извлечение смыслов из предложений.
Az.Tokens
Суть токенизации очень проста: как я упоминал выше, на входе мы принимаем строку — а на выходе получаем «токены», группы символов, которые (вероятно) являются отдельными сущностями в этой строке.
Обычно для этой цели используется что-нибудь типа одного вызова split по простой регулярке, но мне этого показалось мало. Например, если разделить строку по пробелам, мы потеряем сами пробелы — иногда это удобно, но не всегда. Ещё хуже, если мы захотим предварительно разбить строку по точкам, вопросительным и восклицательным знакам (надеясь выделить так предложения): мало того, что теряются конкретные знаки препинания, так ещё и точки на самом деле не всегда завершают предложения. А потом мы понимаем, что в реальных текстах могут встретиться, скажем, ссылки (и точки в них точно никакого отношения к пунктуации не имеют) и регулярка становится совсем страшной.
Az предлагает свое, не-деструктивное, решение этой задачи. Гарантируется, что после токенизации каждый символ будет принадлежать некоторому токену и только одному. Пробелы, переводы строк и прочие невидимые символы объединяются в один тип токенов, слова — в другой, пунктуация — в третий. Если все токены склеить вместе — получится в точности исходная строка.
При этом токенизатор достаточно умен, чтобы понимать, что дефис, обрамленный пробелами — это знак препинания (вероятно, на его месте подразумевалось тире), а прижатый хотя бы с одной стороны к слову — часть самого слова. Или что «habrahabr.ru» — это ссылка, а «mail@example.com» — это, вероятно, емэйл (да, полная поддержка соответствующего RFC не гарантируется). #hashtag — это хэштег, user — упоминание.
И наконец — раз уж RegExp'ы для этой цели использовать не стоит — Az.Tokens умеет парсить HTML (а заодно — вики и Markdown). Точнее говоря, никакой древовидной структуры на выходе не будет, но все теги будут выделены в свои токены. Для тегов <script> и <style> сделано дополнительное исключение: их содержимое превратится в один большой токен (вы же не собирались разбивать на слова свои скрипты?).
А вот и пример обработки Markdown-разметки:

Обратите внимание, скобки в одних случаях превращаются в пунктуацию (светло-синие прямоугольники), а в других — в Markdown-разметку (показана зеленым цветом).
Естественно, отфильтровать ненужные токены (например, выбросить теги и пробелы) элементарно. И конечно же, все эти странные фичи отключаются отдельными флажками в опциях токенизатора.
Az.Morph
После того, как текст разбит на слова (с помощью Az.Tokens или любым другим образом), из них можно попытаться извлечь морфологические атрибуты — граммемы. Граммемой может быть часть речи, род или падеж — у таких граммем есть значения, которые сами по себе являются граммемами, только «булевыми» (например, мужской род, творительный падеж). «Булевые» граммемы могут и не относиться к какой-то родительской граммеме, а присутствовать сами по себе, как флаги — скажем, помета устаревшее или возвратный (глагол).
Полный список граммем можно найти на странице проекта OpenCorpora. Почти все используемые библиотекой значения соответствуют обозначениям этого проекта. Кроме того, для анализа используется словарь OpenCorpora, упакованный в специальном формате, но об этом ниже. Вообще создатели проекта OpenCorpora большие молодцы и я вам рекомендую не только ознакомиться с ним, но и принять участие в коллаборативной разметке корпуса — это также поможет и другим опенсорсным проектам.
Каждый конкретный набор граммем у слова называется тегом. Всевозможных тегов значительно меньше, чем слов — поэтому они пронумерованы и хранятся в отдельном файле. Чтобы уметь склонять слова (а Az.Morph это тоже умеет), нужно как-то уметь менять их теги. Для этого существуют парадигмы слов: они ставят в соответствие тегам определенные префиксы и суффиксы (то есть один и тот же тег в разных парадигмах имеет разные пары префикс+суффикс). Зная парадигму слова, достаточно «откусить» от него префикс и суффикс, соответствующие текущему тегу, и добавить префикс/суффикс того тега, в который мы его хотим перевести. Как и тегов, парадигм в русском языке относительно немного — это позволяет в словаре хранить для каждого слова только пару индексов: номер парадигмы и номер тега в ней.
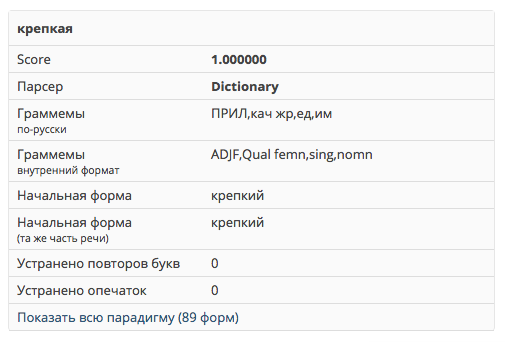
Вот пример: слово «крепкая» имеет тег, по-русски кратко обозначаемый как «ПРИЛ, кач жр, ед, им» — то есть это качественное прилагательное женского рода единственного числа в именительном падеже. Этому тегу (в той парадигме, которой принадлежит слово «крепкая»), соответствует пустой префикс и суффикс «-кая». Предположим, мы хотим получить из этого слова его сравнительную степень, да ещё и не обычную, а особую, с префиксом «по-»: «КОМП, кач сравн2». У неё в этой парадигме, как нетрудно догадаться, префикс «по-» и суффикс «-че». Отрезаем «-кая», добавляем «по-» и «-че» — получаем искомую форму «покрепче».
NB. Как можно заметить, под префиксами и суффиксами тут понимаются не лингвистические термины, а просто подстроки, находящиеся в начале/конце слов.
Такое вот относительно сумбурное изложение внутреннего механизма склонений в Az.Morph. По сути эта часть библиотеки — порт замечательного морфологического анализатора pymorphy2 за авторством kmike (на Хабре была пара статей об этой библиотеке). Кроме самого анализатора, рекомендую ознакомиться с его документацией — там много полезной информации, которая полностью применима и к Az тоже. Кроме того, Az использует формат словарей, аналогичный словарям pymorphy2, за исключением небольших деталей (которые позволили сделать словарь на 25% компактнее). По этой причине, увы, самостоятельно собрать их не получится — но в будущем такая возможность, конечно, появится.
Как я уже упомянул, основные словари хранятся в хитром формате DAWG (в вики есть статья о directed acyclic word graph, как об абстрактной структуре данных, но о конкретной реализации информации мало). Реализуя его поддержку в JS, я оценил фичу pymorphy2, позволяющую при поиске слова сразу проверять вариант с «ё» вместо «е» — это не дает особых потерь в производительности из-за того, что при спуске по префиксному дереву легко обойти ветви, соответствующие обеим буквам. Но мне этого показалось мало и я аналогичным образом добавил возможность нечеткого поиска слов с опечатками (то есть можно задать максимальное расстояние Дамерау-Левенштейна, на котором должно находиться искомое слово от заданного). Кроме того, можно находить «растянутые» слова — по запросам «гоооол» или «го-о-о-ол» найдется словарное «гол». Разумеется, эти особенности тоже опциональны: если вы работаете в «тепличных условиях», с грамотными, вычитанными текстами — поиск опечаток стоит запретить. А вот для написанных пользователями записей это может быть весьма актуально. В планах — заодно ловить и наиболее распространенные ошибки, не являющиеся опечатками.
Как видите, по заданному слову библиотека может вернуть разные варианты разбора из словаря. И это связано не только с опечатками: классический пример грамматической омонимии — слово «стали», которое может оказаться формой как существительного «сталь», так и глагола «стать». Чтобы решить однозначно (снять омонимию) — нужно смотреть на контекст, на соседние слова. Az.Morph этого пока не умеет (да и задача эта уже не для морфологического модуля), поэтому вернет оба варианта.
Более того: даже если в словаре не нашлось ничего подходящего, библиотека применит эвристики (называемые предсказателями или парсерами), которые смогут предположить, как слово склоняется — например, по его окончанию. Тут бы вставить весёлую историю с башорга про анализатор, считающий слово «кровать» глаголом, да одна беда — оно, конечно же, есть в словаре, и только как существительное :)
Впрочем, у меня нашлись свои курьёзы. Например, у слова «философски» среди прочих вариантов нашлись некие «филососки» (с исправленной опечаткой). Но удивительнее всего оказалось, что слово «мемас» стабильно разбирается как глагол (!), инфинитив у которого — «мемасти» (!!!). Не сразу получается понять, как такое вообще возможно — но такую же парадигму имеет, например, слово «пасти». Ну и формы типы «мемасём», «мемасёмте», «мемасённый», «мемасено», «мемасши», по-моему, прекрасны.
Несмотря на эти странности, обычно результаты оказываются довольно адекватными. Этому способствует то, что (как и в pymorphy2) каждому варианту присваивается оценка «правдоподобия» и они сортируются по убыванию этой оценки. Так что если делаете алгоритм побыстрее — можно брать первый вариант разбора, а если хочется точности — стоит перебрать все.
Производительность
Что касается скорости, то в целом тут всё не очень радужно. Либа писалась без упора на этот фактор. Предполагается, что приложениям на JS (особенно браузерным) реже приходится сталкиваться с особенно большими объемами данных. Если хочется быстро анализировать массивные коллекции документов — стоит уделить внимание pymorphy2 (особенно его оптимизированной версии, использующей реализацию на C для работы со словарем).
По моим грубым замерам, конкретные цифры (в браузере Chrome) примерно таковы:
- Токенизация: 0.7–1.0 млн символов в секунду
- Морфология без опечаток: 210 слов в секунду
- Морфология с опечатками: 180 слов в секунду
Впрочем, серьёзных бенчмарков пока не проводилось. Кроме того, библиотеке недостает тестов — поэтому приглашаю погонять её на упомянутой выше демке. Надеюсь, ваша помощь приблизит релиз первой версии :)
Дальнейшие планы
Главный пункт в roadmap библиотеки — эксперименты с синтаксическим анализом. Имея варианты разбора каждого слова в предложении, можно строить более сложные гипотезы об их взаимосвязях. Насколько мне известно, в опенсорсе таких инструментов совсем немного. Тем сложнее и интереснее будет думать над этой задачей.
Кроме того, не снимается вопрос оптимизации — JS вряд ли сможет угнаться за кодом на C, но что-то улучшить наверняка можно.
Другие планы, упомянутые в статье: инструмент для самостоятельной сборки словарей, поиск слов с ошибками (т.е., скажем, чтобы для слов на «т(ь)ся» возвращался вариант и с мягким знаком, и без, а синтаксический анализатор выбирал бы правильный).
И, разумеется, я открыт вашим идеям, предложениям, багрепортам, форкам и пулреквестам.
Комментарии (29)


AStek
15.06.2016 23:30Я как-то пробывал писать что-то похожее на scala. Тоже по мотивам pymorphy.
Так вот. Самой сложной частью для меня оказалась реализация структуры DAWG для хранения словарей.
Так и не смог этого сделать. Использовал два префиксных дерева.
Как вы это обходили?AStek
15.06.2016 23:43Порылся в исходниках и нашел. Я не самый большой спец по JS но вышлядит красиво. Теперь есть что курить чтоб переписать на scala) Ато раньше попадались версии только на С\С++, а они были не очень удобными для изучения.

deNULL
15.06.2016 23:52Скажу по секрету — до конца в формат у меня так и не удалось вникнуть :)
Точнее, там все понятно, кроме центральной части — спуска к следующей вершине дерева:
DAWG.prototype.followByte = function(c, index) { var o = offset(this.units[index]); var nextIndex = (index ^ o ^ (c & 0xFF)) & PRECISION_MASK; if (label(this.units[nextIndex]) != (c & 0xFF)) { return MISSING; } return nextIndex; }
Ну то есть, эээ, тут делается xor текущего индекса вершины с куском значения, лежащего в ней, а потом xor с символом, в который мы переходим… Wat?
В общем, я эту магию практически «дословно» переписал с питона и она магическим же образом заработала. К счастью, самая сложная часть в DAWG — это построение словаря, а в библиотеке это не нужно, нужно только уметь его читать.

Antelle
15.06.2016 23:50В AOT вот есть английский и немецкий, не планируете добавление других языков?
deNULL
16.06.2016 00:03Пока что нет: хочется хорошо уметь работать с одним языком, чем средненько со многими. Ряд моментов в коде привязан к специфичным особенностям русского — как минимум предсказатели слов точно. Наверняка для более распространенных языков уже существуют толковые решения.
Если поддержка в какой-то момент и появится, то начнется это, скорее всего, с родственных русскому языков — например, как в pymorphy2, с украинского.

vanyamasnuha
16.06.2016 00:03Для украинского или английского языка сложно приспособить?
deNULL
16.06.2016 00:20Для английского весьма сложно. Нужно уметь собирать словарь из какого-нибудь другого источника, написать свои предсказатели для неизвестных слов. Для украинского проще — например, pymorphy2 умеет, но для этого все равно надо как минимум собрать отдельный словарь, а инструмент для этого ещё не выложен в открытый доступ.
Поддержка других языка пока не в самом высоком приоритете.
(Конечно, Az.Tokens более универсален и уже сейчас адекватно должен дробить тексты на языках, использующих кириллицу или латиницу)

staticlab
16.06.2016 00:03+1Отличная работа, молодец! А почему не стали писать на ES6/TS? Код был бы короче и чище.
deNULL
16.06.2016 00:27+2Ну я и ES5 не считаю таким уж длинным и грязным.
Библиотека не слишком большая, не хотелось добавлять необходимость её транспайлить при сборке. Сейчас можно смело подключить прямо исходники (в демке они так и подключены) и экспериментировать с кодом «вживую», без дополнительных инструментов.
Ладно, признаю, я просто старомоден :)
Bhudh
16.06.2016 01:55+1Извините за оффтопик, но зачем тут первая картинка?
deNULL
16.06.2016 01:56Иллюстрация к тому, откуда взялось название библиотеки.
Bhudh
16.06.2016 01:57+1Очень плохая и псевдонаучная иллюстрация. К русскому языку и его истории отношения не имеет.
Полуркайте «Ахиневич».deNULL
16.06.2016 03:18Беда. Уже и случайную картинку из гуглопоиска нельзя взять, не задев мракобесие какое-нибудь (хотя почва тут, конечно, благодатная).
Ладно, заменил картинку иллюстрацией из Википедии. Надеюсь, с ней ничего ужасного ни у кого не ассоциируется.Bhudh
16.06.2016 03:35Кроме персонажа по имени «Аметист-палач» ничего ужасного :)
Но это уже мои лично-семейные ассоциации.
Главное, чтоб на ангела борцы с религиями не набижали.

WarFollowsMe
16.06.2016 14:58А покажите первоначальный вариант, пожалуйста. Ну или каким запросом искать.
deNULL
16.06.2016 14:59Ничего криминального, на первый взгляд.

Bhudh
16.06.2016 19:04Зато на второй взгляд выковыриваются варианты букв, сделанные отдельными буквами, лигатура от, сделанная отдельной буквой, странные названия для букв кириллицы и, наконец, шедевр: буква ?, которая использовалась ранее в интернете при html-изданиях летописей в те далёкие годы, когда найти в кириллических кодировках ? или ? было проблематично (а ? и вовсе отсутствовала вместе с Уникодом), а сунуть их в текст как-то надо было, вот и заменяли на латинскую лигатуру.
Но нашлись альтернативные умы, которые решили, что «так в древнесловянском и было» и сотворили сию «Буквицу».

dolphin4ik
16.06.2016 09:52думаю было бы неплохо добавить параметр «силы слова» и «эмоциональной окраски» или эмоционального вектора. Грубо говоря — удивление, вопрос, злость и т.д.
deNULL
16.06.2016 15:06Было бы неплохо, конечно. Трудности возникают в отсутствии такой информации в OpenCorpora и других общедоступных базах.
Если кому-то известны открытые ресурсы, из которых подобные вещи можно было бы почерпнуть — буду благодарен.

ornic
16.06.2016 09:52Очень хотелось посмотреть как раз на морфоразбор, а он на все подряд говорит
Результаты разбора
Нет вариантов
Может это как-то связано с
opera dev console logaz.js:2 GET http://denull.github.io/Az.js/dicts/words.dawg 502 ()load @ az.js:2DAWG.load @ az.dawg.js:3Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.dawg.js:2 Uncaught RangeError: Offset is outside the bounds of the DataViewDAWG.fromArrayBuffer @ az.dawg.js:2(anonymous function) @ az.dawg.js:3xhr.onload @ az.js:2XMLHttpRequest.send (async)load @ az.js:2DAWG.load @ az.dawg.js:3Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.js:2 GET http://denull.github.io/Az.js/dicts/prediction-suffixes-0.dawg 502 ()load @ az.js:2DAWG.load @ az.dawg.js:3(anonymous function) @ az.morph.js:39Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.dawg.js:2 Uncaught RangeError: Offset is outside the bounds of the DataViewDAWG.fromArrayBuffer @ az.dawg.js:2(anonymous function) @ az.dawg.js:3xhr.onload @ az.js:2XMLHttpRequest.send (async)load @ az.js:2DAWG.load @ az.dawg.js:3(anonymous function) @ az.morph.js:39Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.js:2 GET http://denull.github.io/Az.js/dicts/p_t_given_w.intdawg 502 ()load @ az.js:2DAWG.load @ az.dawg.js:3Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.dawg.js:2 Uncaught RangeError: Offset is outside the bounds of the DataViewDAWG.fromArrayBuffer @ az.dawg.js:2(anonymous function) @ az.dawg.js:3xhr.onload @ az.js:2XMLHttpRequest.send (async)load @ az.js:2DAWG.load @ az.dawg.js:3Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.js:2 GET http://denull.github.io/Az.js/dicts/prediction-suffixes-1.dawg 502 ()load @ az.js:2DAWG.load @ az.dawg.js:3(anonymous function) @ az.morph.js:39Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.dawg.js:2 Uncaught RangeError: Offset is outside the bounds of the DataViewDAWG.fromArrayBuffer @ az.dawg.js:2(anonymous function) @ az.dawg.js:3xhr.onload @ az.js:2XMLHttpRequest.send (async)load @ az.js:2DAWG.load @ az.dawg.js:3(anonymous function) @ az.morph.js:39Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.js:2 GET http://denull.github.io/Az.js/dicts/paradigms.array 502 ()load @ az.js:2Morph.init @ az.morph.js:39(anonymous function) @ (index):117
az.morph.js:39 Uncaught RangeError: byte length of Uint16Array should be a multiple of 2chel-icon
16.06.2016 16:08Здорово, конечно. Биг дата. Словарь в монгоДБ. Рутину на ядра, чтоб распараллелить подзадачи.
А вот еще можно парсить/анализировать арифметические задачи, их сюжет. И выводить на экран соответствующу формулу решения. Стоить попробовать.
Zenitchik
Ух ты ж ё-моё. Позавчера подумал, что надо написать такую хреновину. Теперь с нуля писать не стану. :)
deNULL
Форкайте на здоровье :)
mpakep
Вместе с извлечением смысла из предложений будет интересен и обратный процесс. Формирование предложений из полученного смысла. В какой стадии данная часть проекта? Сразу приходит на ум масса областей в которых можно было бы применить подобную разработку.
deNULL
Пока в нулевой: только-только довёл до ума морфологию.
По поводу смыслов меня уже заранее немного беспокоит тот факт, что нынешний словарь (словарь OpenCorpora) не содержит никакой семантической информации. Сейчас при разборе нельзя даже узнать идентификатор разобранного слова в словаре (не говоря о том, что этим идентификаторам хорошо бы быть векторами, полученными из word2vec, например...).
А ещё, кстати, валентность глаголов не помешает собрать откуда-нибудь — как-то мало словарей такую информацию содержат, к сожалению.
Neftedollar
Есть ли typescript definition?
deNULL
Пока нет. В исходниках есть JSDoc-комменты — я думаю, можно пройтись по ним и довольно быстро написать.