Наверно, в мире данных нет подобного феномена настолько неоднозначного понимания того, что же такое Hadoop. Ни один подобный продукт не окутан таким большим количеством мифов, легенд, а главное непонимания со стороны пользователей. Не менее загадочным и противоречивым является термин "Big Data", который иногда хочется писать желтым шрифтом(спасибо маркетологам), а произносить с особым пафосом. Об этих двух понятиях — Hadoop и Big Data я бы хотел поделиться с сообществом, а возможно и развести небольшой холивар.
Возможно статья кого-то обидит, кого-то улыбнет, но я надеюсь, что не оставит никого равнодушным.

Демонстрация Hadoop пользователям
Начнем с истоков.
Первая половина 2000х, Google: мы сделали отличный инструмент — молоток, он хорошо забивает гвозди. Этот молоток состоит из ручки и бойка, но только мы с вами им не поделимся.
2006 год, Дуг Кайтинг: привет, народ, я тут сделал такой же молоток, как у Google и он действительно хорошо забивает гвозди, к слову сказать, я тут попробовал забивать им небольшие шурупы и вы не поверите, он более-менее справился с этим.
2010 год, Пол 30 лет: Парни, молоток работает, даже больше, он отлично забивает болты. Конечно, отверстие надо немного подготовить, но инструмент очень перспективный.
2012 год, Пол 32 года: Оказывается молотком можно рубить деревья, конечно, это немного дольше, чем топором, но он, мать его, работает! И за все за это мы не заплатили ни копейки Так же мы хотим построить с помощью молотка небольшой дом. Пожелайте нам удачи.
2013 год, Дуг: Мы оснастили молоток лазерным прицелом — теперь можно его метать, встроенный нож позволит вам более эффективно рубить деревья. Все бесплатно, все ради людей.
2015 год, Дэн, 25 лет: я кошу траву молотком… каждый день. Это немного сложно, но мне, черт возьми, нравится, мне нравится работать руками!
Если действительно разобраться и копнуть немного глубже, то Google, а потом и Дуг сделали инструмент(и далеко не идеальный, как призналось Google, спустя несколько лет), для решения конкретного класса задач — построение поискового индекса.
Инструмент получился неплохим, но есть одна проблема, в прочем, обо всем по порядку.
В начале 2012 года начался агрессивный тренд — "эпоха big data".
Именно с этого момента начали появляться бесполезные статьи и даже книги в стиле "Как стать big data company" или "Большие данные решают все". Ни одна из конференций больше не обходилась без рассуждений о том, "с какого терабайта начиналась big data" и повторяющихся историй о том, как "одна компания была почти на грани дефолта, но таки перешла на большие данные и она просто порвала рынок". Вся это пустая болтовня подкармливалась грамотным маркетингом от компаний, которые продавали поддержку на все это — спонсировались хакатоны, семинары и много-много всего.
В конечном итоге у большого количества людей сложилась конкретная картина мира, в которой традиционные решения — это медленно, это дорого, да и как минимум, это больше не модно.
Прошло уже много лет, но до сих пор я вижу обсуждения и статьи с заголовками "Map Reduce: first steps" или "Big Data: What Does it Really Mean?" на профессиональных ресурсах.
Hadoop как средство для индексирования
И так, что же все-таки такое Hadoop? В общих словах это файловая система HDFS и набор инструментов для обработки данных.
Все же этот блог технический, позволю себе вот такую вот картинку:
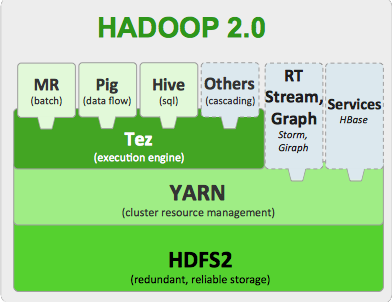
Компоненты Hadoop 2
Все это размазано по кластеру из "дешевого железа" и по мнению маркетологов должно в мановение ока завалить вас деньгами, которые будут приносить "большие данные".
Крупные интернет-компании, например Yahoo, в свое время, оценили Hadoop, как средство обработки больших объемов информации. Используя MapReduce, они могли строить поисковые индексы на кластерах из тысяч машин.
Надо сказать, тогда это было действительно прорывом — Open Source продукт умеет решать задачи такого класса и все это бесплатно. Yahoo сделало ставку на то, что возможно в будущем им бы не пришлось выращивать специалистов, а набирать со стороны уже готовых.
Но я не знаю когда первая обезьяна спустилась с дерева, взяла палку и начала использовать MapReduce для аналитики данных, но факт остается фактом, MapReduce начал реально появляться там, где это совершенно не нужно.
Hadoop MapReduce как средство для аналитики
Если у вас одна большая таблица, например, логи пользователей, то MR с натяжкой мог бы сгодиться для подсчета количества строк или уникальных записей. Но у этого фреймворка были фундаментальные недостатки:
Каждый шаг MapReduce порождает большую нагрузку на диски, что замедляет общую работу. Результаты работы каждого этапа сбрасываются на диск.
Инициализация "воркеров" занимает относительно большое время, что приводит к большим задержкам, даже для простых запросов.
Число "маперов" и "редьюсеров" постоянно во время выполнения, ресурсы делятся между этими группами процессов и если, например, маперы уже прекратили свою работу, то ресурсы редьюсерам уже не освободятся.
Все это более-менее эффективно работает на простых запросах. Операции JOIN больших таблиц будут работать крайне не эффективно — нагрузка на сеть.
Не смотря на весь этот комплекс проблем, MapReduce заслужил большую популярность в области анализа данных. Когда новички начинают свое знакомство с Hadoop, первое что они видят — MapReduce, "ну ок" — говорят они, — "надо изучать". По факту инструмент для аналитики бесполезен, но маркетинг сыграл злую шутку с MR. Интерес пользователей не только не угасает, но и подпитывается новичками(я пишу эту статью в июне 2016).
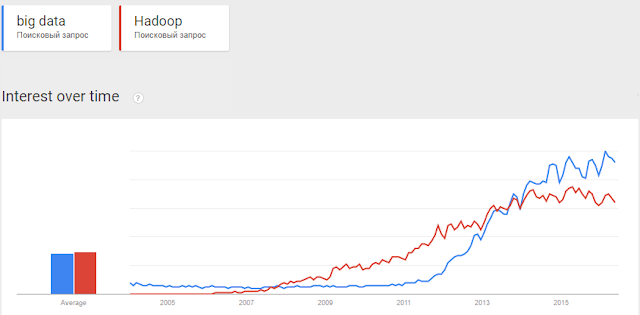
Для анализа заинтересованности в технологии со стороны бизнеса я решил использовать HeadHunter.ru как основную площадку поиска предложений по работе.
И еще можно встретить такие интересные вакансии на HH.ru по ключевым словам MapReduce:

На момент написания статьи было 30 вакансий только в Москве, и это от уважаемых и успешных фирм. Сразу скажу, что я не анализировал глубоко эти предложения, но позитивная динамика все же имеется, около года назад подобных предложений было больше.
Конечно, люди размещавшие вакансию могли просто написать, что попало и, возможно, HeadHunter это не лучшее средство для подобной аналитки, но более подходящих инструментов измерения заинтересованности бизнеса я найти не смог.
Spark как средство для аналитики
Конечно, умные люди сразу поняли, что c MR ловить нечего и придумали Spark, который кстати так же живет под крылом ASF. Spark — это MR на стероидах и как говорят разработчики быстрее MapReduce в более чем 100 раз.
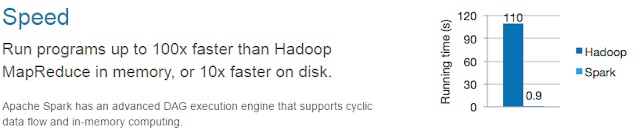
Сферический Spark в вакууме быстрее MapReduce
Spark хорош тем, что лишен перечисленных недостатков MR.
Но мы уже выходим на другой уровень и недостатки снова появляются:
Хардкод и усердный код на Java превращает простые запросы в месиво, которое невозможно будет читать в будущем. Поддержка SQL пока слабая.
Нет стоимостной оптимизации. С этой проблемой можно столкнуться при соединении таблиц.
Spark не понимает, как данные лежат в HDFS. Это хоть и MPP-система, но при соединении больших таблиц возникает ситуация, когда соединяемые данные находятся на разных узлах, что приводит к нагрузке на сеть.
Хотя в целом Spark штука годная, но возможно его убьет рынок труда, так как искать дорогих специалистов на Java или Scala, которые будут хардкодить вам аналитику очень и очень тяжело, особенно если вы no-name-company(произносить с особым пафосом, если работаете в такой).
Так же вместе со Spark зародилось интересное решение — Spark Streaming и, возможно, это будет действительно таким "долгоиграющим" решением.
Spark штука простая, надежная и его можно развернуть без Hadoop.
Поживем увидим.
Предложение по вакансиями немного лучше чем по MapReduce, они более зрелые и похоже их писали плюс-минус понимающие люди

Количество подобных предложений — 56 штук.

А теперь несколько мифов о Hadoop и BigData
Миф 1. Hadoop — это бесплатно
В наши дни мы использует очень много OpenSource продуктов и даже не задумываемся о том, почему мы за них не платим. Конечно, бесплатный сыр бывает только в мышеловке и платить, в конце концов, приходится, особенно за Hadoop.
Hadoop и все что с ним связано, активно позиционируется маркетологами под флагами бесплатности, мира и братства. Но в действительности, использовать собственную сборку Hadoop рискнут не многие — продукт достаточно сырой и до сих пор многими непонятный.
Компании придется нанимать дорогих специалистов, при этом задачи они будут решать дольше и усерднее. В конце концов вместо того, что бы решать задачи обработки данных, сотрудники будут решать проблемы латания дыр в сыром софте и построению костылей.
Конечно, речь не касается других зрелых OpenSource продуктов, типа MySQL, Postgres и т.п., которые активно используются в боевых системах, но даже тут, множество компаний пользуется платной профессиональной поддержкой.
Прежде чем решать, нужен ли вам бесплатный продукт, посчитайте, так ли он бесплатен. Возможно, с вашими задачами по сбору зерна с полей, с одинаковым успехом справится и вчерашний студент на современном комбайне и группа дорогих Java-кодеров, с бесплатными молотками-серпами.
Ок, Hadoop, это не бесплатно, допустим, но Hadoop работает на дешевом железе! И снова мимо. Hadoop хоть и работает на дешевом железе, для быстрого и надежного решения задач вам все равно потребуются нормальные сервера — на "десктопах" это работать не будет. Для годной работы Hadoop потребуется железо такого же класса, как и для работы любых других аналитических MPP-систем. По рекомендации Cloudera в
зависимости от задач необходимо:
- 2 CPU c 4-8-16 Ядрами
- 12-24 JBOD дисков
- 64-512GB of RAM
- 10 Gbit Net
Прошу заметить, что RAID отсутствует, но избыточность Hadoop на уровне софта требует примерно такого же количества дисков.
Миф 2. Hadoop для обработки неструктурированной информации.
Другой не менее примечательный миф говорит нам о том, что "Hadoop необходим для обработки неструктурированной информации", а такой неструктурированной информацией как раз и является Big Data :-). Но давайте разберемся сначала, что же такое неструктурированная информация.
Таблицы — это точно структурированная информация, это бесспорно.
А вот JSON, XML, YAM — называют полу-структурированной информацией.
Но и такие форматы имеют структуру, только не такую явную как структура таблиц.
Другая актуальная тема — логи, по мнению популяризаторов BigData — не имеют структуры.

На самом деле структура есть, логи вполне себе нормально записываются в таблицы и обрабатываются без MapReduce
Твиттер:

На самом деле, структура есть почти у всех данных, которые нам могут пригодиться. Она может быть разрозненная, не удобная для обработки, но она есть.
Даже такие данные, например, видео или аудио информация могут быть представлены в виде виде структуры которую можно распределить на большое количество серверов и обрабатывать.
Видео-файлы:

Скорее всего, там, где вы работаете, нет неструктурированной информации. И ваша информация может быть разрозненной и "грязной", но какая-то структура у нее все равно имеется. В таком случае, у вас действительно проблемы и нужно решать в первую очередь их.
Конечно, есть информация, которую нельзя эффективно "размазать" по большому кластеру, например генетическая информация или огромный файловый архив, но таких кейсов чрезвычайно мало и для "бизнес-аналитики" они не интересны, такие задачи решаются другими средствами совершенно на другом уровне(если знаете, расскажите).
Если вы знаете какие-то действительно неструктурированные источники информации, которые нельзя просто так обработать в распределенном кластере, пожалуйста, пишите в комментариях.
Миф 3. Любая проблема решается через технологии Big Data
Еще один интересный термин навязанный обществу — "технологии Big Data". Конечно, никакого логического определения того, что такое Big Data конечно нет, тем более нет определения "технологий Big Data".
Принято считать, что все, что связано с Hadoop — это "технологии Big Data"

Но Hadoop и все что с ним связано, очень хорошо замаскированный, аккуратный суперфункциональный швейцарский нож-молоток. Им можно рубить деревья, косить траву, забивать болты. Он справляется со всеми задачами, но вот только когда дело доходит до решения конкретной задачи, особенно когда нужно сделать это качественно, такой швейцарский нож-молоток только усложнит вам жизнь.
Impala, Dill, Kudu — новые игроки
Конечно, еще более умные люди, чем все остальные, посмотрели на весь этот бардак и решили создать свой лунапарк.
Три зверька Impala, Drill и Kudu появились примерно одновременно и не совсем давно.
Это такие же МРР-движки поверх HDFS как Spark и MR, но разница между ними такая же, как между едой и закуской — огромная. Продукты так же находятся под крылом, многоуважаемого ASF. В принципе, всеми тремя проектами можно пользоваться уже сейчас, не смотря что они на стадии так называемой "инкубации".
Кстати, Impala и Kudu находятся под крылом Cloudera, а Drill вышел из компании Dremio.
Из всего зверинца я бы выделил Apache Kudu как самый интересный инструмент из представленных с четким и зрелым roadmap.
Преимущества Kudu следующие:
Kudu понимает, как лежат данные в HDFS и понимает как их правильно класть в HDFS, чтобы оптимизировать будущие запросы. Директива distributed by.
Только SQL и никакого хардкода.
Из явных недостатков можно выделить отсутствие Cost-based оптимизатора, но это лечится и возможно в будущих релизах мы Kudu предстанет во всей красе. Все эти 3 продукта плюс-минус примерно одинаковые, по этому, рассмотрим архитектуру на примере Apache Impala:
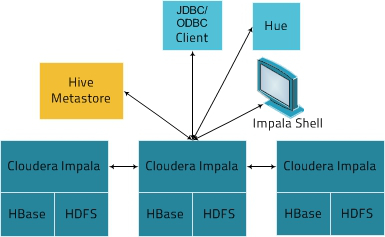
Как мы видим, имеются экземпляры СУБД — Impala, которые уже работает с данными на своей конкретной ноде. При подключении клиента к одному из узлов он становится управляющим. Архитектура достаточно похожа на Vertica, Teradata(верхнеуровнево и очень приближенно). Основная задача при работе с такими системами сводится к тому, чтобы правильно "размазать" данные по кластеру, чтобы в дальнейшем эффективно с ними работать.
При всех своих достоинствах, разработчики пиарят свои системы как "федеравтивные", то есть: берем таблицу Kuda, связываем ее с плоским файлом, все это смешиваем с Postgres и приправляем MySQL. То есть у нас появляется возможность работать с гетерогенными источниками как с обычными таблицами или нереляционными структурами(JSON) как с таблицами. Но у такого подхода есть своя цена — оптимизатор не понимает статистику внешних источников, так же такие внешние таблицы становятся узким горлышком при выполнении запросов, так как, по сути, работают в "один поток".
Другой важный момент — необходимость HDFS. HDFS в такой архитектуре превращается в бесполезный аппендикс, который только усложняет работу системы — лишний слой абстракции, который имеет свои накладные расходы. Так же, HDFS может быть развернута поверх не совсем эффективных или не правильно настроенных файловых систем, что может привести к фрагментации файлов данных и потери производительности.
Конечно, HDFS можно использовать как помойку всего и вся, скидывая в нее все нужное и ненужное. Такой подход последнее время называется "Data Lake", но не стоит забывать, что анализировать неподготовленные данные будет сложнее в будущем. Последователи такого подхода аргументируют преимущества тем, что данные, возможно, и не придется анализировать, следовательно, нет необходимости тратить времени на их подготовку. В общем, решать, по какому пути идти, все же, вам.
Никаких предложений по работе и интересов компаний в сторону Kudu-подобных продуктов нет, а зря.
Немного маркетинга
Вы, наверно, заметили явный тренд в сторону того, что весь этот цирк в области аналитики данных движется в сторону традиционных аналитических MPP-систем (Teradata, Vertica, GPDB и т.п.).
Все аналитические MPP-системы развиваются в одном направлении, только при этом две разные группы идут к этому с разных сторон.
Первая группа — идет по пути "шардирования" традиционных SQL СУБД.
Вторая группа — идет по родословной от MR и HDFS.
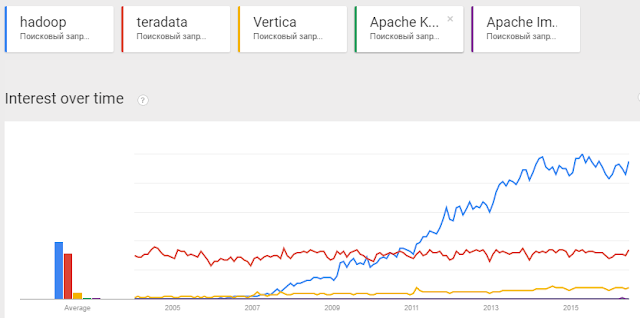
Пользователи проявляют интерес к слову Hadoop
Лавинообразный рост Hadoop конечно обусловлен очень грамотным маркетингом со стороны компаний, продающих эти решения.
Компании смогли вырастить в умах людей идею того, что Hadoop бесплатен, он прост и быстр и легок, а еще… нет бога кроме Hadoop.
Напор был таким сильным, что даже Teradata не смогла совладать с собой и вместо того, что бы самой формировать рынок, начала продавать решения на базе Hadoop и нанимать специалистов. Не говоря уже о других игроках рынка, которые дружно родили поделия под названием "AnyDumbSoft Big Data Edition", в большинстве случаев использующие стандартные коннекторы к HDFS.
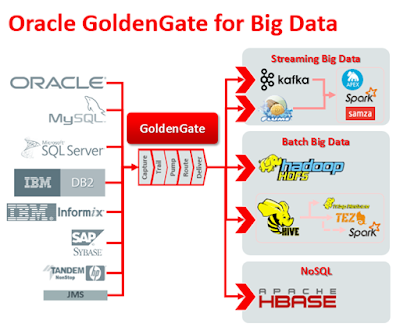
Тренду поддался даже Oracle, выпустивший "Big data appliance" или "Golden Gate for Big data". Первый продукт — это просто готовая железка с "золотым" CDH от Cloudera, а в продукт номер два просто добавлены Java-коннекторы для Kafka(брокер сообщений), HBase и остального зоопарка. Сделать это мог любой пользователь самостоятельно.
Big Data больного человека
К сожалению, это тренд, это мейнстрим, который сметет любую стабильную компанию, если она рискнет пойти против течения. Кстати, я отчасти тоже рискую быть закиданным помидорами, освещая данную тему.
Apache HAWQ (Pivotal HDB).
Pivotal пошел дальше всех. Они взяли традиционный Greenplum и натянули его на HDFS. Весь движок обработки данных остался за Postgres, но сами файлы данных хранятся в HDFS. Какой-то практической целесообразности в этом мало.
Вы получаете в распоряжение такой же Greenplum, с более сложным администрированием, но продают вам его и рекламируют как Hadoop.
Apache HAWQ очень похож на Apache Kudu.
Cloudera Distributed Hadoop
Cloudera одна из первых компаний начавших монетизировать Hadoop и именно там работает Дуг, который изобрел Hadoop.
Cloudera в отличие от других игроков, не подстраивается под рынок, а сама делает его. Грамотный пиар и маркетинг позволили ей завоевать достаточно лакомый кусочек рынка — сейчас в списке клиентов более 100 крупных и известных компаний.
В отличие от других подобных компаний, Cloudera не просто продает зоопарк из уже готовых компонентов, но и сама активно участвует в их разработке.
По цене CDH выходит немного дешевле Vertica/Greenplum.
Но несмотря на большое количество историй успеха на сайте Cloudera, есть одна маленькая проблема — Kuda, Impala — немного сырые, продукты на стадии инкубации. Даже когда они созреют, этим системам нужно будет пройти долгий путь, чтобы обрасти всем необходимым функционалом Vertica или хотя бы Greenplum, а это не год и не два, пока же CDH можно оставить для хипстеров.
Так же надо отдать должное маркетологам Cloudera, сумевшим встряхнуть рынок.
Будущее Hadoop
Позволю себе пованговать и представить, что будет со стеком Hadoop через 5 лет.
MapReduce будет использоваться только в очень ограниченном количестве задач, проект скорее всего выпилят из общего стека, либо о нем забудут.
Появятся первые дистрибутивы CDH уже с частичным отказом от использования HDFS. В таком случае, файлы таблиц будут храниться на обычной файловой системе, но у нас будет небольшая помойка для хранения сырых данных.
Можно провести аналогию с Flex Zone в Vertica — свалка, в которую можно кидать все что угодно и обрабатывать далее по мере необходимости или забывать.
На самом деле иметь такую помойку не только удобно, но мы будем просто вынуждены иметь ее. Объемы дискового пространства растут непропорционально быстро по сравнению с производительностью процессоров. Когда количество узлов в кластере увеличивают в целях производительности мы увеличиваем и объем дискового пространства(больше необходимого). В следствие чего, всегда будет большое количество незанятого дискового пространства, в котором удобно хранить данные к которым обращение будет либо очень редкое, либо мы к ним не обратимся никогда.
Зоопарк имени Hadoop вряд ли оправдает кредит доверия, который предоставили ему пользователи, но надеюсь, что не уйдет с рынка.
Хотя бы, из интересов конкуренции.

Будут ли у Hadoop проблемы через 5 лет?
Что будет со Spark? Возможно, многие будут использовать его как движок для распределенной предобработки и подготовки данных в реальном времени — Spark Streaming, но и эта ниша тоже активно занимается другими игроками (Storm, производители ETL)
Будущее Vertica, Greenplum.
Vertica будет полировать свою интеграцию с HDFS, наращивать функционал и Vertica скорее всего не пойдет в OpenSource — сейчас продукт и так хорошо продается.
Greenpum сделает свой аналог Flex Zone, путем слияния кода с HAWQ, либо сам станет non-HDFS частью HAWQ, в конце концов, кого-то мы потеряем.
Каких то новых игроков на рынке аналитических MPP-систем, скорее всего, ожидать не придется. Открытие исходников Greenplum ставит целесообразность использования таких СУБД как Postgres-XL, как минимум, под сомнение.
Принципиальных изменений архитектуры в этих продуктах мы вряд ли увидим, изменения будут в улучшении имеющегося функционала.
Будущее Postgres-XL и подобных
Postgres-XL могла бы быть прекрасным MPP инструментом для аналитики больших объемов данных, если бы немного бы отошла от всего того, что дал ей Postgres. К сожалению СУБД не умеет работать с Column Store-таблицами, в ней нет нормального синтаксиса для управления партициями, а так же она имеет стандартный оптимизатор Postgres со всеми вытекающими.
Например, в Greenplum есть cost-based оптимизатор, заточенный для аналитических запросов. Это та штука, без которой жизнь аналитика и разработчика очень сильно усложнится.
Но ставить крест на таком замечательном продукте тоже не стоит, Postgres развивается, в 9.6 уже появилась многопоточность и, возможно, умельцы прикрутят Column Store и GPORCA в Postgres-XL.
Будущее Teradata, Netezza, SAP и подобных
В любом случае рынок аналитических систем будет расти и в любом случае клиенты на эти продукты будут. Будут эти решения продавать на полях для гольфа или на конференциях "Big Data — технология будущего" я не знаю.
Но скорее всего, этим игрокам придется уйти от текущей бизнес-модели программно-аппаратных средств и взглянуть в сторону Only-Software-продуктов.
Запрыгнуть в призрачный поезд "Big Data" у них не получится, но это и не нужно, ибо поезд мнимый и они отчасти сами его и придумали.
Будущее Redshift, BigQuery и облачных сервисов для аналитики
На первый взгляд, облачные сервисы выглядят очень и очень привлекательно: не нужно заморачиваться покупкой оборудования и лицензиями. Подразумевается, что при желании можно будет с легкостью отказаться от сервиса или перейти в другой.
С другой стороны, аналитика — проект долгосрочный, а разрабатывать аналитическое хранилище, абстрагируясь от конкретной технологии очень и очень сложно. Поэтому в будущем перейти безболезненно из одного облачного хранилища в другое будет сложно.
Клиенты у таких игроков точно будут, но очень специфичные — стартапы и небольшие компании.
Резюме: Я не коснулся большого количества продуктов из зверинца ASF, которые продают под соусом Big Data (Storm, Sqoop и т.п.), так как пока к ним мало интереса как с моей стороны, так и рынка в целом. Поэтому, буду рад любым комментариям, касаемым этих продуктов.
Также я не коснулся темы кликстрим-аналитики, которая набирает обороты. Надеюсь, опишу это в следующих статьях.
Второе резюме: Сложно не пойти на поводу у "творцов" рынка при выборе решений в области обработки и анализа данных. До сих пор пыль не осела и мы еще будем сталкиваться с компаниями, продающими "счастье" и мы будем сталкиваться с продуктами, позиционируемыми как "универсальное лекарство" от Big Data головного мозга.
Я постарался показать, куда развивается Hadoop, да и вся индустрия обработки данных. Попытался развеять несколько мифов прод Big Data и постарался представить в каком направлении будет развиваться вся область. Надеюсь, получилось — узнаем об этом уже через несколько лет.
В конце концов, рынок развивается и становится более доступным для потребителя, появляются новые продукты, появляются новые либо перерождаются старые технологии.
Комментарии (69)

dim_s
22.06.2016 10:17Я вот не понимаю, Mongo DB имеющая множество инструментов для MapReduce, хорошо масштабируемая и уже не относится к миру BigData? Почему в статьях когда рассказывают про bigdata редко встретишь упоминание этой бд?

yusman
22.06.2016 11:04Я не знаток Монги, но могу предложить, что все, что продается там под соусом MapReduce — это не MapReduce.
Это просто распределенные вычисления(извиняюсь за каламбур, но не каждое распределенное вычисление — это MapReduce)

zim32
22.06.2016 11:08Я так понимаю разница в том что монго это bjson — т.е. «полу»-стркуткурированные данные, а в хадупе у вас есть к примеру вся библиотека конгресса США в виде одного файла, по частям на нодах, и потом воркерами и прочими зверьками вы достаете то что вам нужно. Т.к. хадуб на уровень структурированности данных ниже чем монго.
Raw data --> Hadoop --> Semi-Structured Data --> Mongo --> Aggregated Data

0x0FFF
22.06.2016 11:31На официальном сайте есть этому объяснение: https://www.mongodb.com/big-data-explained
Вся эта статья про аналитические системы, а MongoDB — это т.н. «operational» система. Обычно она всплывает в контексте обсуждения Cassandra, HBase и подобных систем этого класса

ArisChik
23.06.2016 10:23Есть кстати такой зверек как Marklogic, которого многие маркетологи позиционируют как монгу для Биг Даты

Regis
23.06.2016 12:38-1В монге в режиме «на запись» работает только один узел системы. Так что более-менее мастабируется она на относительно небольших объемах.
Да и в целом Mongo держится в первую очередь на маркетинге. Для многих задач, которые пытаются решать с Mongo зачастую больше подошел бы PostgreSQL его JSONB.dim_s
23.06.2016 12:46Многие ORM и ActiveRecord не поддерживают эти возможности из постгреса, что уже отбивает все желание пользоваться этим.

bizobj
22.06.2016 10:40+2Спасибо за взвешенный подход. А то «все кругом говорят о Hadoop» как о единственной панацее, да ещё и бесплатной. И опять мы сталкиваемся с агрессивным маркетингом на реальной и актуальной потребности бизнеса проводить предметную аналитику по конкретным проблемам на основе накопленных данных.
vais
22.06.2016 10:57+3Согласен с автором.
Хадуп очень избыточен, пример:
Нужно перебрасывать данные из 7 таблиц на postgreSQL в одну таблицу на mssql.
Решение в котором ключевую роль играет Хадуп:
Новые данные в онлайн режиме подбираются из postgreSQL неким самописным сервисом, летят в logstash от туда в kafka
из кафки, спарк стримингом грузим данные в hive,
а из hive данные забираются каждый день информатикой и льются в MSsql
итоговая цепочка
postgresql->.net service-> logstash -> kafka ->spark streaming -> hive — > Informatica -> MSSql
И в качестве плана Б был реализован поток на информатике (За 1 день)
postgresql -> IPC -> MSSql
Да хадуп бесплатен, да не нужно платить немалые деньги за лицензию oracle, Informatica ETL
Но стоит ли оно того?yusman
22.06.2016 11:06Спасибо, есть и большое количество OpenSource ETL, например Pentaho, Talend. Для семи табличек можно было обойтись без Informatica PowerCenter/
vais
22.06.2016 17:34+1Банковский сектор,… у нас много табличек =) Informatica ETL — устоявшееся решение, для трансфера данных из одной БД в другую. Но за наводку на Pentaho, Talend спасибо. Мы посмотрим.
Gokudera
22.06.2016 16:51Изи задачка и без «Informatica ETL»
Один селект, один инсерт (что-то кроме — хранимые процедуры) и немного кода на джаве.
Если подшаманить немного с мэпингом полей и конфигами впринципе вот вам и решение более общей задачи. Не знаю как Informatica ETL, а данный подход позволял передавать over 1млн «абстрактных» записей между базами меньше чем за минуту.yusman
22.06.2016 18:26Надо понимать, что «немного кода на Java», в реальности выливается в сложности:
1. Как обрабатывать исключения, зависания, утечки памяти и т.п.?
2. Логирования ошибок соединенения, загрузки и т.п…
3. Изменение модели данных источника и применика
4. Ковертация типов данных, между различными СУБД, работа с теми же самыми датами.
Тут же уже все давно придумано и, конечно, можно написать свой велосипед, но использовать уже готовые инструменты или фреймворки все же намного проще, благо, существует большое количество OpenSource проектов.Ivan22
23.06.2016 08:40а все-таки, зачем с вашей схеме хадуп? Я бы забирал данные напрямую из реплик постгреса.
vikarti
22.06.2016 10:58вот вспоминается почему то два примера более менее известных когда компании сами описывали архитектуру:
— CCP Games. основной массив данных чуть более терабайта. С ним работает кластер из ~100 машин к которым цепляются клиентский софт (и клиенты будут очень довольны если будут лаги). Непосредственно сервер БД — 2 мощных IBM x86 сервера на которых...Windows и MSSQL(!). а проблему с тем чтобы все летало — решили RAMSAN'ами (аппаратный RAMdisk на сколько надо терабайт)
— Linden Labs. данных в сумме — под половину эксабайта. часть — блобы, часть более менее структурированные данные. Куча раздельных кластеров MySQL (структурированные данные там достаточно просто шардировались) а блобы… сначала на хранилках isilon systems а затем… выгрузили на S3(все равно реальную работу с теми блобами делает обычно клиент, которому надо их скачать и желательно побыстрее а S3 это лучще обеспечивает)
Norgat
22.06.2016 11:08А что можете сказать про storm.apache.org?
yusman
22.06.2016 11:16Тоже самое, что и для Spark Streaming, все же потоковые вычисления не совсем то, о чем я хотел рассказать.
Думаю, определенную нишу эти продукты найдут.
Но опять же, нужно каждый раз думать, необходимо ли использовать этот инструмент
Как уже писал уважаемый vais в комментарии выше, цепочка из такого зоопарка выглядит как минимум… кхм… странной:
postgresql->.net service-> logstash -> kafka ->spark streaming -> hive — > Informatica -> MSSql
ffriend
22.06.2016 11:13+3Ну давайте по пунткам:
Hadoop как средство для индексирования
Hadoop вырос из Nutch, который вырос из Lucene. Но к моменту формирования Hadoop как отдельного проекта ASF (а тем более к моменту, когда он стал проектом верхнего уровня), Hadoop уже был вполне самостоятельным продуктом, вышедшим далеко за пределы индексирования текста.
Миф 1. Hadoop — это бесплатно
Софт — бесплатно, цена железа остаётся, и я пока не встречал менеджеров, которые это не понимали. Но цена софта тоже имеет значение: у нас, например, одна только лицензия на Vertica стоит больше чем лизинг серверов Hadoop и стоимость фулл-тайм администратора для него. Мы используем и то, и другое, для разных задач, потому что в одних случаях дешевле решать задачу одним способом, в другом — другим.
Миф 2. Hadoop для обработки неструктурированной информации.
Ок, задача: классифицировать 10Тб сообщений пользователей на Facebook. Опробовать статистические методы: наивный Байесовский классификатор, логистическая регрессия, машина опорных векторов. Покажите как это сделать на Vertica, Teradata или что вам больше нравится, а потом сравним это с реализацией на Hadoop/Spark.
По цене CDH выходит немного дешевле Vertica/Greenplum.
Да, например бесплатно. С поправкой на железо, конечно, но про это я уже сказал.
Все это более-менее эффективно работает на простых запросах.
Ага, поэтому мы сейчас переписываем уже почти загнувшееся решение на Redshift/Vertica на Spark/SparkSQL.
Vertica будет полировать свою интеграцию с HDFS
Полировать — это сильно сказано. Когда мы последний раз пытались написать свой (!) ридер паркетовский файлов из HDFS с помощью Vertica UDF, внезапно оказалось, что Vertica вообще не умеет парсить бинарные данные и пытается перевести из "битой" кодировки в "нормальный UTF-8". Бинарные данные в UTF-8, ага.
В общем, вы явно либо не поняли сути технологического стека Hadoop, либо просто не хотите слазить с SQL-ориентированных задач. Увы, не всё в мире сводится к JOIN-у двух таблиц.yusman
22.06.2016 11:42+4Софт — бесплатно
Открою для вас горькую правду — ничего бесплатного в нашем мире нет. Используя CDH или Hortonworks, вы должны купить подписку на поддержку, которая, кстати, не бесплатная.
Если вы собираете свой дистриубутив Hadoop, то да — это бесплатно, но вы уйдете с проекта, кто это все поддерживать будет если оно сломается??
Опробовать статистические методы
Все это есть в любой аналитической МРР системе, в том же Greenplum — библиотека MadLib, умеет делать очень много и на SQL-подобном языке.
просто не хотите слазить с SQL-ориентированных задач. Увы, не всё в мире сводится к JOIN-у двух таблиц.
Согласен, не все так категорично, но перед тем как эти две таблички связать, необходимо провести много работы и не обязательно для этого использовать инструменты из зоопарка Hadoop.ffriend
22.06.2016 12:22+1Открою для вас горькую правду — ничего бесплатного в нашем мире нет. Используя CDH или Hortonworks, вы должны купить подписку на поддержку, которая, кстати, не бесплатная.
Нет, не должны. За деньги вы можете получить версию с парой дополнительных фич и да, поддержку, но и абсолютно бесплатной community edition обычно хватает за глаза.
Все это есть в любой аналитической МРР системе, в том же Greenplum — библиотека MadLib, умеет делать очень много и на SQL-подобном языке.
Так покажите мне, как конкретно решить эту задачу на Greenplum. Я не спорю, что вы сможете через трёхэтажный неэффективный запрос вы сможете сделать наивный Байсовский классификатор, может быть даже реализуете безумную логистическую регрессию, SVM — уже маловероятно. А на Spark я это (и много гораздо более сложных вещей) сделаю в пару строк кода. Смысл в том, что в отличие от SQL баз данных, Hadoop позволяет использовать любой кастомный код, строить любые статистические модели, вызывать любые сторонние API, сохранять состояние, отсылать метрики процесса и многое многое другое. Вы же увидели только SQL составляющу Hadoop и пытаетесь доказать, что все компании страдают ерундой, разворачивая себе Hadoop кластер вместо SQL СУБД.
Согласен, не все так категорично, но перед тем как эти две таблички связать, необходимо провести много работы и не обязательно для этого использовать инструменты из зоопарка Hadoop.
Естественно, и никто чисто на Hadoop не завязывается. Просто в инфраструктуре Hadoop много новых полезных инструментов таких как Spark, Storm, Kafka, GraphX, HBase и т.д., которые могут крутиться на одном и том же кластере и хорошо интегрированы друг с другом. Это удобно, но я пока не видел ни одной компании, которая бы замыкалась только на Hadoop и не использовала другие инструменты (в т.ч. классические SQL базы данных).

vdmitriyev
22.06.2016 12:33yusman
Статья у вас конечно очень холивартная, но благодаря ей породилось очень много интересных комментариев.
MADLib почти единственный продукт подобного рода, который позволяте использовать машинное обучение в MPP DBMS (и пока поддерживает только PostgeSQL ориентированные движки баз данных). Если знаете другие примеры подобный библиотек работающих «поверх» MPP RDBMS (ну или MPP с ACID), мы было бы очень интересно на них посмотреть.
ffriend
К вашему комментарию по поводу анализа 10 Тб. У Teradata есть продукт в портфолио под названием «Teradata Aster Database», который собственно и позволяет делать большинство из ктого что привел в пример ffriend, и как раз таки на базе MapReduce парадигмы. Но помимо MR, там есть еще много интересного — анализ логов из коробки, интеграция с много чем (аля HDFS), App Center, что облегчает доступ простым пользователям к результатам анализа и т.д… И да, это этот софт не бесплатный и порой весьма капризный, но тем не менее в качестве примера-альтернативы для озвученных задач весьма подходит. И да, я не имею никакого отношения к компании.ffriend
22.06.2016 13:27Продукт интересный, согласен, но я всё-таки задачи для примера привёл, чтобы показать, что SQL базы обычно не умеют. Для Teradata можно найти кучу других примеров (например, меня сразу смутило, что из general purpose языков, судя по всему, поддерживается только R и только через межпроцессорное взаимодействие, весь продукт недоступен шикорому кругу open source разработчиков, что замедляет развитие и т.д.). И точно так же можно назвать кучу недостатков для любого продукта из инфраструктуры Hadoop. Но нельзя говорить, что весь кипеш вокруг Hadoop и big data — это исключительно работа маркетологов: для формирования текущего рынка были вполне обоснованные исторически предпосылки со вполне конкретной выгодой.
vdmitriyev
22.06.2016 19:25Я с вами полностью согласен по поводу того, что термин не полностью придуман маркетологами. Но термин таит очень много опасностей в использовании для «неподготовленных», много раз в этом убеждался.
SQL не умеет из коробки «делать» машинное обучение, но если долго мучатся — можно в итоге что-то да и реализовать, но про переносимость между разными реализациями стандарта SQL (то есть по факту между разными базами данных) и про производительность я умолчу. И в целом использовать специально нацеленные фрейморки (аля MADlib )всегда лучше.
В Teradata Aster можно вроде как реализовывать задачи запускаемые непосредственно в самой базе либо на Java, либо на C/С++, про R как раз-таки не уверен. А если использовать обычный поток stdin/stdout, то тогда возмжно в приципе использовать любой язык, котрый удобно, главное чтобы он запускался на каждой машине в кластере (это я про аналог Hadoop Streaming).ffriend
23.06.2016 01:04В Teradata Aster можно вроде как реализовывать задачи запускаемые непосредственно в самой базе либо на Java, либо на C/С++, про R как раз-таки не уверен.
Про R у них прямо на сайте написано, так что я так понял, что это основной аналитический инструмент у них.
В остальном да, согласен — термин перегретый, часто рождает мифы и слухи. Но и статьи вроде этой не помогают: автор явно пристрастен к SQL базам данных, поэтому я и пытаюсь показать примеры, где SQL сильно проигрывает.
yusman
22.06.2016 21:43Насколько я знаю, в большинстве коммерческих аналитических МРР-системах имеется в той или иной мере поддержка ML и предиктивной аналитики, в той же Aster или Vertica это имеется. Другое дело насколько эта поддержка удовлетворяет вашим потребностям. Например, в Vertica работа с ML по функционалу и подходу очень напоминает MadLib.
ffriend
23.06.2016 00:54Другое дело насколько эта поддержка удовлетворяет вашим потребностям.
Вот именно поэтому я и попросил привести решение озвученный задач на любой из названных СУБД. Если вы считаете, что большинство или хотя бы какая-то одна БД позволяет сделать озвученные задачи, пожалуйста, приведите пример.
А я потом приведу пример, как это делается в Spark, хоть со встроенным MLlib, хоть с использованием сторонних библиотек и их алгоритмов. И вот тогда уже можно будет предметно обсудить, стоит ли Hadoop своей славы или нет.

ascrus
22.06.2016 14:48+1Полировать — это сильно сказано. Когда мы последний раз пытались написать свой (!) ридер паркетовский файлов из HDFS с помощью Vertica UDF, внезапно оказалось, что Vertica вообще не умеет парсить бинарные данные и пытается перевести из «битой» кодировки в «нормальный UTF-8». Бинарные данные в UTF-8, ага.
Поправлю Вас. Вертика поддерживает ORC и PARQUET, пример прямо с доки:
=> CREATE EXTERNAL TABLE tableName (columns) AS COPY FROM path ORC; => CREATE EXTERNAL TABLE tableName (columns) AS COPY FROM path PARQUET;ffriend
23.06.2016 00:56О, значит, наконец, допилили. А вы случайно не пользовали? Как оно вообще, стабильно? Быстро? Для нас сейчас не суперактуально, но на будущее хотелось бы знать.
ascrus
23.06.2016 01:28Да, все работает. Не спорю, давно надо было сделать эти форматы, без них работа с HDFS не имеет смысла.
kozian
23.06.2016 14:15Полностью согласен, жаль кармы для голосования нет.
Хотя основной посыл — что MapReduce подходит не для всего, и вокруг BigData много маркетинга — верен, автор не смог описать раздел между задачами, или сознательно перегибал в сторону. Статья слишком однобока.
0x0FFF
22.06.2016 11:27+4Хорошая статья, спасибо! Приятно, что есть еще специалисты, способные разделять реальность и маркетинг
В целом направление мысли верное, но есть некоторые фактические ошибки:
- если, например, маперы уже прекратили свою работу, то ресурсы редьюсерам уже не освободятся — на самом деле освободятся. Даже если у вас YARN настроен на возможность выполнения только одного таска единовременно (один маппер или один редюсер), вы сможете выполнить задачу в 1000 мапперов и столько же редюсеров. Конечно, работать они при этом будут последовательно
- Spark не понимает, как данные лежат в HDFS. Это хоть и MPP-система — Spark не MPP, это тот же Batch Processing, что и MapReduce. Задача обработки данных разбивается на таски и они выполняются асинхронно, промежуточные данные сбрасываются на диск
- Spark Streaming и, возможно, это будет действительно таким «долгоиграющим» решением — Как раз у Spark Streaming наиболее сильные конкуренты — Apache Storm, Apache Heron, Apache Flink, да и та же Kafka c Kafka Streams. Конкурировать micro-batch подходу Spark Streaming с «честным» streaming в вышеназванных системах будет очень проблематично
- Impala, Drill и Kudu… это такие же МРР-движки поверх HDFS как Spark и MR — Kudu не имеет зависимости от HDFS, это как раз более быстрая замена HDFS для обработки табличных данных с поддержкой update (в отличии от HDFS). И, конечно, она не имеет отношения к MPP
- Apache HAWQ… они взяли традиционный Greenplum и натянули его на HDFS… какой-то практической целесообразности в этом мало. — по сути это ответ рынку. MPP over Hadoop востребована (посмотрите на те же Hive и Impala), вот Pivotal и выпустил этот продукт. К слову сказать, среди решений его класса он является наиболее быстрым и продвинутым в плане поддержки SQL, но как и любое связанное с Hadoop решение является сложным в сопровождении
- Появятся первые дистрибутивы CDH уже с частичным отказом от использования HDFS — уже появились, ведь Kudu — это не HDFS
Greenpum сделает свой аналог Flex Zone, путем слияния кода с HAWQ, либо сам станет non-HDFS частью HAWQ, в конце концов, кого-то мы потеряем — на самом деле я поднимал этот вопрос перед руководством практически сразу после форка HAWQ от GPDB, но такой цели нет. Сейчас же их ветки ушли чересчур далеко друг от друга и я не вижу возможности их слияния в будущем. Скорее GPDB расширит функционал для нативной поддержки HDFS таблиц, да и только.
В свое время я тоже писал и про Kudu, и про неструктурированные данные, и про перспективы Big Data, и про перспективы Spark. В целом же я рекомендую вам писать статьи на английском — это даст охват аудитории в 10 раз выше и возможность дискуссии с интересными специалистами (как, например, мой спор с одним из создателей Spark в комментариях к этой статье)yusman
22.06.2016 14:50Алексей, во-первых, вам большой респект за HAWQ (активно слежу за этим проектом)
Spark не MPP, это тот же Batch Processing
Понятие МРР я восринимаю буквально — массивно-параллельный процессинг.
Да, понятие МРР тесно закрепилось за конкретными СУБД(Vertica, GPDB, Teradata и т.д.), но технически MapReduce, Kudu, Spark и т.д. тоже является МРР-системой с распределенной архитектурой.
Kudu не имеет зависимости от HDFS, это как раз более быстрая замена HDFS
Хм… на главной же странице Kudu: A new addition to the open source Apache Hadoop ecosystem, Apache Kudu (incubating) completes Hadoop's storage layer to enable fast analytics on fast data.
Возможно это очередной маркетинговый булшит, покапаюсь глубже в этой теме.
MPP over Hadoop востребована
А чем именно обуслевлена данная востребованность? Популярностью Hadoop или реальными потребностями рынка?0x0FFF
22.06.2016 15:37Не согласен с вами касательно MPP. Основная идея MPP как раз в том, что она массивно-параллельная, то есть много процессов параллельно выполняют одну и ту же задачу над разными данными. MapReduce и подобные подходы не являются MPP, т.к. в этих системах нет гарантии параллельного выполнения задач, это системы пакетной обработки данных. По сути это «data parallelism» против «task parallelism» — первый параллельно обрабатывает одни и те же данные набором процессоров, а второй разбивает задачу на независимые «таски» и назначает их свободным процессорам по мере их доступности и глобальных приоритетов
Про Kudu — да, прочитайте их публикацию
Лично я считаю, что популярность Hadoop обусловлена потребностью рынка и маркетингом. А когда начинается использование Hadoop, все «корпоративные» клиенты хотят иметь к нему SQL-интерфейс, при этом быстрый и с транзакциями — вот и потребность
Ivan22
22.06.2016 14:51Вопрос на счет HAWQ. Где он может быть полезен если он по факту медленнее Greenplum-a. Да еще и его таблицы не совместимы с hive. Ну и GP уже давно умеет external таблицами юзать hdfs файлы, или HIVE external tables. Что уже позволяет в реальных проектах юзать выгрузку/загрузку данных между hdfs и gp.
0x0FFF
22.06.2016 15:06+1HAWQ 2.0 нативно поддерживает чтение таблиц, объявленных в Hive Metastore, без плясок с бубном вроде внешних таблиц. А скоро будет поддерживать и их создание
Да, вы правы, GPDB уже умеет многое. В то же время HAWQ работает поверх Hadoop и интегрируется с YARN, что позволяет ему более удачно вписаться в Hadoop-кластер, а вот GPDB требует для своей работы отдельный кластер и немного другую организацию дисков
kapustor
22.06.2016 17:57+1Алексей, есть ли данные о разнице в производительности запросов на native-hawq-таблицах и hive-таблицах?
0x0FFF
22.06.2016 18:05К сожалению, таких данных у меня нет. Но ожидаемо, что запросы к Hive-таблицам будут медленнее. Нативные таблицы парсятся кодом HAWQ (написанным на C), а для обращения к Hive таблицам нужно поднимать Java-десериализаторы, соответствующие формату хранения, что довольно долго.
Но Apache HAWQ — это open source, и вы свободно можете протестировать его и самостоятельно увидеть разницу в производительности
Ivan22
23.06.2016 08:45+1И сразу же второй вопрос, а как они живут вдвоем на одном кластере? хок и хадуп? Не будет ли проблем с ресурсами. В пиковые моменты один другому не мешает? Ибо разделение на разные кластеры это вообще неплохой паттерн. А как раз другая организац\ дисков — это есть оптимизация vs универсализм.
0x0FFF
23.06.2016 09:54+1Apache HAWQ интегрирован с YARN, то есть глобальный менеджер ресурсов в кластере будет и HAWQ не сможет забрать себе всё. Но нужно понимать, что YARN управляет только квотами на память и CPU, то есть IO может стать узким местом. Еще стоит учесть, что совмещать на одном кластере аналитические и транзакционные системы — моветон. То есть HAWQ + Sqoop + Flume + Spark будут вместе жить нормально, а вот HAWQ + HBase — уже не очень
tomzarubin
24.06.2016 11:50+1Простите, и у вас есть неточность, как минимум,— 1.
Задача обработки данных разбивается на таски и они выполняются асинхронно, промежуточные данные сбрасываются на диск
Это не совсем так. Писать в диск промежутки на Sparke— дурной тон.
Кусок слайда из курса Беркли по Spark
0x0FFF
24.06.2016 12:56+1Советую вам ориентироваться не на презентации, а на код
Вот оригинальный комментарий из кода менеджера shuffle в Spark:
/** * In sort-based shuffle, incoming records are sorted according to their target partition ids, then * written to a single map output file. Reducers fetch contiguous regions of this file in order to * read their portion of the map output. In cases where the map output data is too large to fit in * memory, sorted subsets of the output can are spilled to disk and those on-disk files are merged * to produce the final output file. */
Если по коду, то здесь происходит запись на диск, которая вызывается отсюда, в свою очередь вызывается отсюда, объявляется здесь и вызывается тут. Это наиболее актуальная имплементация, т.н. Tungsten, а вот более старая
Как я и говорил, специалистов, способные разделять реальность и маркетинг, не так уж много.
И да, в презентации говорится про «storage»: они имеют в виду возможность Spark кэшировать данные, а не то, что во время shuffle он не сбрасывает данные на дискtomzarubin
24.06.2016 14:14Т.е., вы хотите сказать, что, если:
— вы используете в 1строке кода transformation, в следующей строке action, то Spark запишет результат transormation на HDD, который будет использовать в action?
— нет варианта, при котором любые transformation и action не будут задействовать HDD, кроме случаев, где это явно указано в коде?0x0FFF
24.06.2016 14:27+1— Нет, я так не говорю. Количество записей на диск не зависит от количества трансормаций, оно зависит от количества shuffle. Каждый раз, когда Spark производит shuffle, все данные приземляются на диск. У вас может быть одна трансформация join, которая будет исполнена в виде reduce-side join, и оба участвующих RDD будут перераспределены (shuffle) по кластеру перед join'ом. А может быть трансформация «filter», которая всегда пайплайнится с другими трансформациями, и соответственно никакого приземления данных на диск не будет
— Нет, такого варианта нет. Данные во время shuffle всегда приземляются на диск. По-другому асинхронное выполнение тасков работать и не может

facha
22.06.2016 11:30Столько неточностей и голословных утверждений в статье это специально чтоб было о чем похоливарить?
Google, а потом и Дуг сделали инструмент(и далеко не идеальный, как призналось Google, спустя несколько лет), для решения конкретного класса задач — построение поискового индекса.
Круг задач решаемых с помошью MapReduce довольно широк. Намного шире задачи построения поискового индекса. Например, весь SQL можно реализовать с помошью MapReduce. Уже немало.
Число «маперов» и «редьюсеров» постоянно во время выполнения, ресурсы делятся между этими группами процессов и если, например, маперы уже прекратили свою работу, то ресурсы редьюсерам уже не освободятся.
Неверно.
По факту инструмент для аналитики бесполезен
Это было про MapReduce. Какое-то голословное утверждение. Во времена, когда появился MapReduce, количество памяти в серверах было сравнительно небольшим, и для аналитики на недорогом железе не было ничего лучше.
Хардкод и усердный код на Java превращает простые запросы в месиво, которое невозможно будет читать в будущем.
Это точно про Spark?
Поддержка SQL пока слабая.
Достаточная. Смотря с чем сравнивать.
Spark не понимает, как данные лежат в HDFS.
Spark понимает, как данные лежат в HDFS.
Это хоть и MPP-система
Это не MPP-система
На самом деле, структура есть почти у всех данных, которые нам могут пригодиться
Текст, например, очень слабо структурирован.
Это такие же МРР-движки поверх HDFS как Spark и MR
Kudu — хранилище данных, а не МРР-движок
Kudu понимает, как лежат данные в HDFS
Неверно. Kudu вообще не использует HDFS.
Только SQL и никакого хардкода.
Неверно. В нативном API Kudu нет SQL.
Все эти 3 продукта плюс-минус примерно одинаковые
Это про Kudu, Impala и Drill. Нет. Kudu — хранилище данных, Impala и Drill МРР-движки
Apache HAWQ очень похож на Apache Kudu
Еще раз повторюсь. Kudu к MPP-движкам никакого отношения не имеет.
Cloudera Distributed Hadoop
Cloudera Hadoop Distribution
CDH можно оставить для хипстеров
Список хипстеров прилагается — http://www.cloudera.com/customers.html
Shamov
22.06.2016 14:35+1Определение Big Data очень простое. Это такие данные, в отношении которых трудно представить, как делается бэкап.
Windws
22.06.2016 15:24+1Хорошая статья, спасибо автору! На самом деле так и есть, термин Big Data сильно раздут. На мой взгляд, Hadoop очень хорошо подходит для хранения старых (архивных) данных и работы с ними время от времени, так называемый Data Lake.
Системы MPP (Teradata, Vertica, Greenplum и т.д.) все-таки предназначены для хранения и обработки больших объемов данных и для использования в ежедневных процессах, например для построения отчетности, проведения анализ предметных областей, создания моделей для принятия решений. Для меня все-таки СУБД MPP и Hadoop это немного разные вещи.Ivan22
23.06.2016 08:49Очень жду возможности репликации из хадупа в MPP субд.
yusman
23.06.2016 10:49А расскажите, пожалуйста, зачем?
Ivan22
24.06.2016 12:19сейчас дефакто стандарт в аналитике — MPP аналитическая субд (terradata, greenplum, exadata, vertica etc) на которую смотрят аналитики и bi системы, поверх хадупа для хранения грязного стейджинга.
И приходится гонять террабайты данных из хадупа в субд всякими обходными маневрами. Для реляционных источников всегда рулила и сейчас рулит репликация — как самый удобный и быстрый способ получения данных в нашу MPP систему.
ArisChik
22.06.2016 18:27+1Интересная статья «против тренда».
Примечательно, что «родоначальники» всего этого зоопарка (Google) давно уже тихонько отошли от дел и спокойно пилят свои уникальные БД (как транзакционные, так и аналитические) и файловые системы (Фейсбук пошел еще дальше и запилил свою файловую систему только для картинок), а остальные этого просто не замечают.
Примечательно, что в «хороших» университетах (из Ivy League, например) в серьезный академический оборот попал только Spark, при чем без привязки к Hadoop.
Но Big Data рынок это такая себе система с обратной связью: по итогам 2015 года, «Big Data специалисты» получали в США практически больше всех (уступив только DevOps) и это позволяет им зарабатывать, по сути, легкие деньги, и они, не желая терять такую жизнь, подключаются к маркетингу компаний, рассказывая на каждом углу каждому встречному, как они решают «Big Data проблемы» и рубят бабло, создают кучу персональных блогов и книжек и, как итог, привлекают еще больше внимания и ажиотажа.
На фоне всего этого удивляет, что такие вещи как графовые базы данных (которые уже начал использовать Амазон, к примеру), проходят мимо рынка.
P.S. На самом деле весь этот зоопарк выстрелил по 1-й простой причине: возможность запускать любой рандомный код (на Python, Java, Scala) для анализа данных.
ascrus
23.06.2016 00:33+1Статья вполне в тему кстати. Вчера был на OSP форуме по BigData. Не смотря на тучу клевых технологий и очень интересной информации, из выступающих только двое докладчиков назвали объемы своих «BigData» в проде. У СБ Контура в HBase 1 тб, а у классического OLTP на базе Ред БД у приставов крутится ряд БД, соединенных обычным App сервером под 100 тб. Из личного опыта так же — у нас на вполне себе обычной релляционной Vertica крутятся базы по 75 тб и у моих друзей в Штатах и более объемом на Терадате, а мне каждый раз с секретным видом сообщают о том, что на очередном NoSQL или Hadoop у кого то есть база аж 20-30 тб :) Кстати помимо распределенности, аналитических функций и прочих очень полезных мегавещей есть один больной нюанс, о котором забывают любители новых технологий. Это тупо оптимизация и администрирование сверх больших объемов данных. На Вертике, ГП или Терадате выглядит все это вполне себе культурненько, а про HDFS и NoSQL столько чудесных историй слышал при больших объемах, так сказать «нюансы» :)
P.S. Кстати потопчусь по графовым базам, вспоминая опять же вчерашний форум по Бигдате. Есть круг применения у них клевый, но аналитика упаси господь в этот круг не входит. Показали мне вчера на презе по OrientDB как круто в него CDR можно грузить и быстро по абоненту находить его номера, используемые БС и звонки. Запустил я в голове простой запрос за полгода выдать всех абонентов, у которых ежедневно звонков выходило менее, чем на 2 минуты, пробежался по графам БД презы и завис… пробежать все это по графам жесть жестяная, а строить на каждый чих рассчитываемую витрину, это места на дисках не напасешься и скорости записи потеряешь. Как бы в таблицах CDR в сутки у не слишком большого оператора лямов 200 записей прибывает минимум, за полгода для рангового анализа объемы неплохие так получаются.
kuaw26
23.06.2016 06:50+1А что скажете про Apache Ignite?
Есть интеграция со Spark & Hadoop.
Есть SQL поверх NoSql данных.
Есть IGFS — in-memory реализация HDFS, которая может как сама по себе работать, так и проксировать / кешировать HDFS.
Ну и MapReduce тоже есть и всякое еще сверху.

Sergunka
23.06.2016 08:23+22015 год, Дэн, 25 лет: я кошу траву молотком… каждый день. Это немного сложно, но мне, черт возьми, нравится, мне нравится работать руками!
Офигено смешная шутка завтра переведу индюкам из нашего тима — интересно поймут всю глубину иронии… Автор, Вы шутку сами придумали или подсмотрели у кого-то?
tomzarubin
24.06.2016 10:19Spark— это не только Java и Scala, но и Python и R. Тут даже Java лишняя становится, в последнее время тренд на «продакшн» код на Scala, EDA—Scala, Python, очень экзотично пока на R.
drazumovskiy
27.06.2016 11:45Интересно почему решения типа BigQuery или RedShift отнесены к небольшим компаниям или стартапам? Мы как раз небольшая компания с фокусом на аналитике данных. Используем BigQuery, хотим перейти на RedShift.
Когда и почему мы должны задуматься над уходом в Enterprise решения, типа Teradata?yusman
27.06.2016 12:28Возможно и никогда. Если вас всё устраивает по цене и производительности, то не надо уходить с облака.
Считайте и исследуйте этот вопрос самостоятельно. Если вы аналитическая компания, то для вас данные — это ваш хлеб. Я просто не могу дать вам совет в стиле «Если вы перевалите за XX ТБ — срочно переходите на Y». Очень много зависит от вашей специфики.
Опять же, крупные банки, фин. организации и т.д. врядли будут доверять свои данные левым компаниям, при том, что выигрыша по цене может даже и не быть, либо он будет минимальным — надо считать.
drazumovskiy
27.06.2016 13:00Одна из причин, чтобы уйти как минимум от Google BigQuery — это нестабильность платформы. Когда компания продает аналитику, то BigQuery становится mission critical частью ее архитектуры. Инструмент BigQuery еще неизвестно когда выйдет в стабильный режим работы, и получается что вчера отчеты считались быстро и правильно, а сегодня медленно и неправильно. Ребята из BQ вообще любят смелые эксперименты на Production.
В этом плане RedShift вызывает больше доверия, поскольку у пользователя остается больше контроля над средой. С другой стороны и трудоемкость поддержки пропорционально растет.

Ivan22
Интересная статья.
«Появятся первые дистрибутивы CDH уже с частичным отказом от использования HDFS». А можно описать плюсы и минусы такого решения??
yusman
Спасибо. Из плюсов
1. Убираем лишний слой абстракции над файловой системой, позволяющий выстрелить в ногу. Пример, под Hadoop лежит «еще одна» файловая система, приводящая к фрагментации и рандому при чтении.
2. Если у вас нормальные, структурированные данные — вам не нужен HDFS, это лишние издержки.
Из минусов — лишаемся возможности развести помойку разрозненных данных на HDFS)))
poxu
А какую файловую систему используют в таком случае?
ffriend
WAT?? Поясните, пожалуйста, о какой фрагментации и рандомном чтении идёт речь?
Расскажите, как, например, Vertica, справляется с real-time аналитикой? Я отвечу за вас: плохо. А вот, например, Druid, хранящий абсолютно структурированные данные на HDFS, делает это вполне эффективно. А всё потому, что HDFS и Hadoop вообще предоставляют более низкоуровневые инструменты и гораздо более широкие возможности, чем любая отдельно взятая SQL СУБД.
ascrus
Отлично справляется. У нас пару клиентов за бугром, кто в реалтайме считает клики в банерных сетях прямо на Вертике. У них задержка более 0.3 сек на ответ запросу уже считается ужасом ужасным :)
ffriend
Расскажите use case, мы тоже считаем в т.ч. и клики, но 0.3 для вертики, честно говоря, звучит фантастически.
CKA304HUK
Справедливаости ради, Druid не хранит горячие данные на hdfs. Горячие данные он хранит под собой, сливая на hdfs (или s3, или ceph...) исторические свертки.
ffriend
Т.е. на распределённую файловую систему, которая в данном случае является необходимостью, а не "лишними издержками" :)
CKA304HUK
Поставте s3 api на любое абстрактное хранилище, хоть полку c дисками — эффект будет тот же. HDFS тут сугубо потому, что «так тут повелось». Нужно просто много надежного места для хранения истории, распределнность этого хранилища не очень важна. В конечном счете, если мы говорим о realtime — все, что не висит в памяти, напрямую из application или косвенно как object store — не есть realtime, ибо (относительно памяти) медленно.
P.S. Те же примеры, проскакивающие тут в комментриях «у меня на вертике за 0.1» — это не про условную вертику, а про многослойную архитектуру хранения. Терабайты оперативной памяти, ssd cache, infiniband, вот это вот все… Ну или не такие страшные слова — просто горячих данных (относительно) немного. Чудес то не бывает.
ffriend
Это всё понятно, вопрос был в том, нужен ли HDFS, если все данные — структурированые. Я привёл пример того, где абсолютно структирированные данные пишутся на HDFS, а не в RDBMS, потому что RDBMS не даёт нужного уровня абстракции и контроля.
Real-time — понятие относительное. Например, Википедия говорит нам, что
На практике же всё определяется ожиданиями клиента: если клиент загружает 3Гб данных и видит по ним аналитику через 15 минут, 13 из которых заливался файл, то для него это всё ещё "real-time".
CKA304HUK
С замечаниями согласен.
Но хотелось бы отметить, что в дискуссиях по поводу «хранения (слабо) структурирванных данных» стороны очень часто (не сознательно) меняют контекст. Веть действительно, если у вас есть данные, уже разложенные для rdbms, то складывать их на абстракный hdfs для того, чтобы бегать по ним абстрактным drill'ом может быть избыточно…