Готовясь летом к этой презентации, я решил изучить некоторые части исходного кода PostgreSQL на C. Я запустил очень простой запрос select и наблюдал, что Постгрес с ним делает, с помощью LLDB, отладчика C. Как Постгрес понял мой запрос? Как он нашел данные, которые я искал?

Этот пост — неформальный журнал моего путешествия через внутренности PostgreSQL. Я опишу пройденный мной путь и то, что я видел в процессе. Я использую серию простых концептуальных диаграмм, чтобы объяснить, как Постгрес выполнил мой запрос. В случае, если вы понимаете C, я также оставлю вам несколько ориентиров и указателей, которые вы можете поискать, если вдруг решите покопаться во внутренностях Постгреса.
Исходный код PostgreSQL восхитил меня. Он оказался чистым, хорошо задокументированным и простым для понимания. Узнайте сами, как Постгрес работает изнутри, присоединившись ко мне в путешествии в глубины инструмента, которым вы пользуетесь каждый день.
В поисках Капитана Немо
Вот пример запроса из первой половины моей презентации. Мы будем следовать за Постгресом, пока он ищет Капитана Немо:

Найти одно единственное имя в текстовом столбце должно быть достаточно просто, не так ли? Мы будем крепко держаться за этот запрос select, исследуя внутренности Постгреса, как глубоководные ныряльщики держатся за верёвку, чтобы найти путь обратно на поверхность.
Картина в целом
Что Постгрес делает с этой SQL строкой? Как он понимает, что мы имеем в виду? Как он узнаёт, какие данные мы ищем?
Постгрес обрабатывает каждую SQL команду, которую мы ему отправляем, в четыре шага.

Сначала PostgreSQL производит синтаксический анализ (“парсинг”) нашего SQL запроса и конвертирует его в ряд хранимых в памяти структур данных языка C — дерево синтаксического анализа (parse tree). Далее Постгрес анализирует и переписывает наш запрос, оптимизируя и упрощая его с помощью серии сложных алгоритмов. После этого он генерирует план для поиска наших данных. Словно человек с обсессивно-компульсивным расстройством, который не выйдет из дома, пока его портфель не будет тщательно упакован, Постгрес не запустит наш запрос, пока у него не будет плана. Наконец, Postgres выполняет наш запрос. В этой презентации я вкратце коснусь первых трёх шагов, после чего сосредоточусь на последнем: исполнении запроса.
Функция C внутри Постгреса, которая выполняет этот четырехступенчатый процесс, называется exec_simple_query. Вы можете найти ссылку на неё ниже вместе с трассировкой LLDB, которая показывает детали того, когда именно и как Постгрес вызывает exec_simple_query.

exec_simple_query
view on postgresql.org
Синтаксический анализ
Как Постгрес понимает SQL строку, которую мы ему отправили? Как он находит смысл в ключевых словах и выражениях SQL нашего запроса select? Через процесс под названием синтаксический анализ (парсинг). Постгрес конвертирует нашу SQL строку во внутреннюю структуру данных, которую он понимает — дерево синтаксического анализа.
Оказывается, Постгрес использует ту же технологию парсинга, что и Ruby, а именно — генератор синтаксического анализатора под названием Bison. Bison работает во время процесса сборки постгреса и генерирует код парсера на основании ряда грамматических правил. Сгенерированный код парсера — это то, что работает внутри Постгреса, когда мы отправляем ему SQL команды. Каждое грамматическое правило вызывается, когда сгенерированный парсер находит соответствующий паттерн или синтаксис в строке SQL и вставляет новую структуру памяти C в дерево синтаксического анализа.
Сегодня я не буду тратить время на детальное объяснение того, как работает алгоритм парсинга. Если вам интересны подобные темы, то советую почитать мою книгу Ruby Under a Microscope. В первой главе я подробно рассматриваю пример алгоритма синтаксического анализа LALR, используемого Bison и Ruby. Постгрес парсит SQL запрос абсолютно таким же образом.
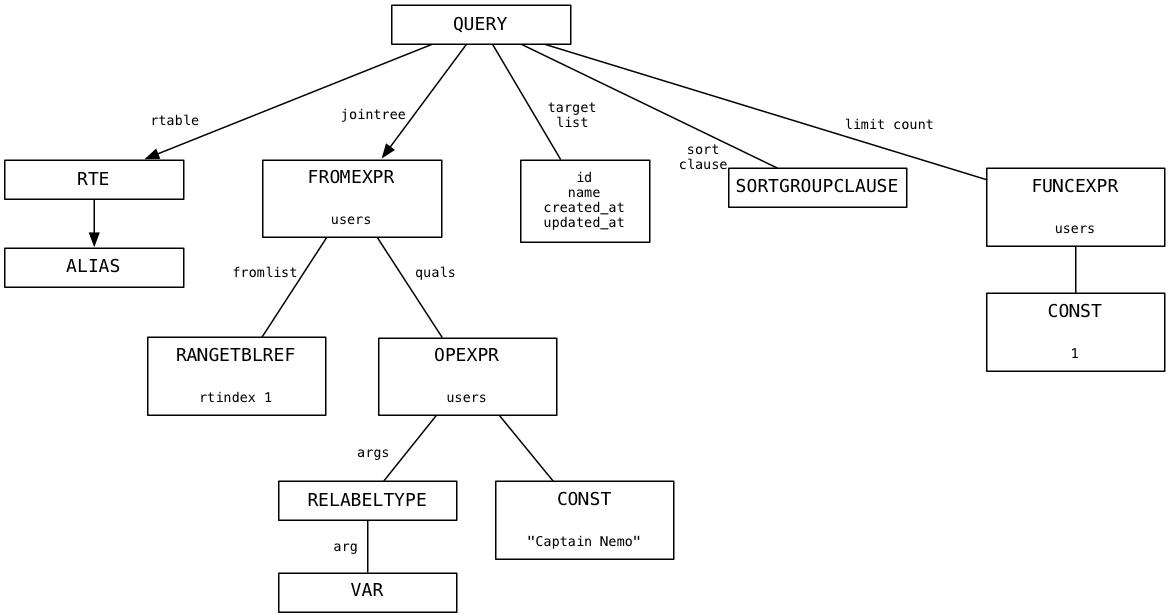
Используя LLDB и активировав некоторый логирующий код C, я наблюдал, как парсер Постгреса создал следующее дерево синтаксического анализа для нашего запроса по поиску Капитана Немо:

На вершине находится узел, представляющий полный SQL запрос, а ниже расположены дочерние узлы или ветки, которые представляют разные куски синтаксиса SQL запроса: целевой список (список столбцов), условие from (список таблиц), условие where, порядок сортировки и количество записей.
Если вы хотите узнать больше о том, как Постгрес парсит SQL запросы, проследуйте за порядком исполнения от exec_simple_query через другую функцию C под названием pg_parse_query.
pg_parse_query
view on postgresql.org
Как вы видите, в исходном коде Постгреса много полезных и подробных комментариев, которые не только объясняют, что происходит, но и указывают на важные проектные решения.
Вся работа псу под хвост
Дерево синтаксического анализа выше скорее всего показалось вам знакомым — это почти в точности то же абстрактное синтаксическое дерево (AST), за созданием которого в ActiveRecord мы наблюдали ранее. Вспомните первую часть презентации: ActiveRecord сгенерировал наш запрос select про Капитана Немо, когда мы выполнили вот этот запрос на Ruby:

Мы видели, что ActiveRecord создал внутреннее представление AST, когда мы вызвали такие методы, как where и first. Позже (смотрите второй пост) мы наблюдали за тем, как gem Arel сконвертировал AST в наш пример запроса select с помощью алгоритма, основанного на паттерне visitor.
Если подумать, очень иронично, что первое, что Постгрес делает с вашим SQL запросом — конвертирует его из строки обратно в AST. Процесс парсинга в Постгресе отменяет всё, что ActiveRecord делал до этого, вся тяжелая работа, которую проделал gem Arel, прошла даром! Единственной причиной для создания SQL строки было обращение к Постгресу по сети. Но как только Постгрес получил запрос, он переконвертировал его обратно в AST, что является гораздо более удобным и полезным способом представления запросов.
Узнав это, вы можете спросить: а нет ли лучшего способа? Нет ли другого способа концептуально объяснить Постгресу, какие данные нам нужны без написания SQL запроса? Без изучения сложного языка SQL или дополнительных накладных расходов из-за использования ActiveRecord и Arel? Кажется чудовищной тратой времени идти таким долгим путём, создавая SQL строку из AST только для того, чтобы снова сконвертировать её обратно в AST. Может, стоит использовать вместо этого NoSQL решение?
Конечно, AST, используемый Постгресом, сильно отличается от AST, используемого ActiveRecord. В ActiveRecord AST состоит из объектов Ruby, а в Постгресе — из серии хранимых в памяти структур языка C. Идея одна, но реализация очень разная.
Анализ и перезапись
Как только Постгрес сгенерировал дерево синтаксического анализа, он конвертирует его в другое дерево, используя другой набор узлов. Оно известно как дерево запроса. Вернувшись к функции C exec_simple_query, вы можете увидеть, что далее вызывается другая функция C — pg_analyze_and_rewrite.
pg_analyze_and_rewrite
view on postgresql.org

Если не вдаваться в подробности, процесс анализа и перезаписи применяет ряд сложных алгоритмов и эвристик в попытке оптимизировать и упростить ваш SQL запрос. Если вы выполнили сложный запрос select с вложенными запросами и множеством inner и outer join, то простор для оптимизации огромен. Вполне возможно, что у Постгреса получится уменьшить количество вложенных запросов или объединений, чтобы произвести более простой запрос, который будет выполняться быстрее.
Для нашего простого запроса select pg_analyze_and_rewrite создал вот такое дерево запроса:
Не буду притворяться, что понимаю детально алгоритмы, стоящие за pg_analyze_and_rewrite. Я просто заметил, что для нашего примера дерево запроса очень похоже на дерево синтаксического анализа. Это значит, что запрос select был настолько простым, что Постгрес не смог сделать его ещё проще.
План
Последнее, что Посгрес делает прежде, чем начать выполнять наш запрос, — создаёт план. Этот процесс включает в себя создание третьего дерева узлов, которые представляют собой список инструкций для Постгреса. Вот дерево плана для нашего запроса select:
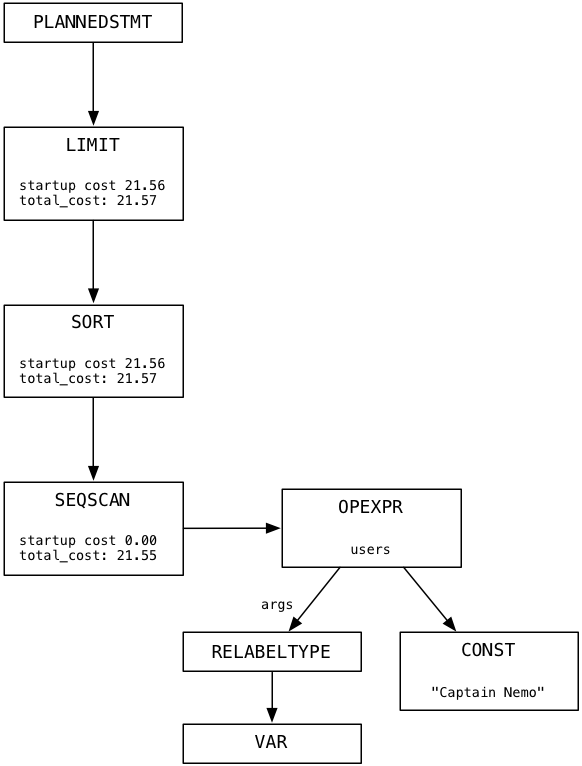
Представьте, что каждый узел в дереве плана — это какой-то станок или работник. Дерево плана напоминает трубопровод данных или ленту конвейера на фабрике. В моём простом примере у дерева всего одна ветвь. Каждый узел дерева плана берет данные из вывода нижележащего узла, обрабатывает их и возвращает результат в качестве исходных данных для узла выше. В следующем параграфе мы проследим за Постгресом в то время как он будет выполнять план.
Функция C, которая начинает процесс планирования запроса, называется pg_plan_queries.
pg_plan_queries
view on postgresql.org

Обратите внимание на значения startup_cost и total_cost в каждом узле. Постгрес использует эти значения, чтобы оценить, сколько времени потребуется на выполнение плана. Вам не нужно использовать отладчик C, чтобы увидеть план исполнения вашего запроса. Просто добавьте в начало запроса команду SQL EXPLAIN. Вот так:

Это отличный способ понять, что Постгрес внутренне проделывает с одним из ваших запросов и почему он может быть медленным или неэффективным, несмотря на сложные алгоритмы планирования в pg_plan_queries.
Выполнение узла плана Limit
К этому моменту Постгрес подверг вашу SQL строку синтаксическому анализу и конвертировал её обратно в AST. Затем он её оптимизировал и переписал, вероятно, упростив. После этого Постгрес написал план, которому будет следовать, чтобы найти и вернуть данные, которые вы ищете. И наконец, настало время Постгресу выполнить ваш запрос! Как он это сделает? Следуя плану, конечно же!
Давайте начнём с верха дерева плана и будем двигаться вниз. Если пропустить корневой узел, то первый работник, которого Постгрес использует для нашего запроса о Капитане Немо, называется Limit. Узел Limit, как вы могли догадаться, выполняет команду SQL LIMIT, которая ограничивает результат определённым количеством записей. Также этот узел плана выполняет команду OFFSET, которая инициирует окно с набором результатов, начиная с указанной строки.

При первом вызове узла Limit Постгрес вычисляет, какими должны быть значения limit и offset, поскольку они могут быть привязаны к результату некоторого динамического расчета. В нашем примере offset равен 0, а limit — 1.
Далее узел плана Limit многократно вызывает субплан — в нашем случае это Sort — пока он не достигнет значения offset:

В нашем примере offset равен нулю, так что этот цикл загрузит первое значение данных и прекратит итерацию. Потом Постгрес вернёт последнее значение данных, загруженное из субплана, вызывавшему или вышестоящему плану. Для нас это будет то самое первое значение из субплана.
Наконец, когда Постгрес продолжит вызывать узел Limit, он станет передавать значения данных из субплана по одному:
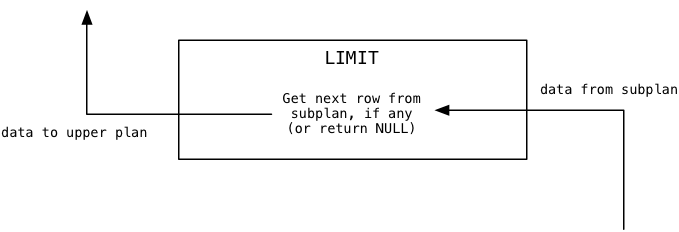
Поскольку в нашем примере limit равен 1, Limit сразу вернет NULL, показывая вышестоящему плану, что доступных данных больше нет.
Постгрес выполняет узел Limit с помощью кода из файла под названием nodeLimit.с
ExecLimit
view on postgresql.org
Вы можете увидеть, что исходный код Постгреса использует такие слова, как tuple (набор значений, по одному из каждого столбца) и subplan. В этом примере субплан — это узел Sort, который расположен в плане под Limit.
Выполнение узла плана Sort
Откуда берутся значения данных, которые отфильтровывает Limit? Из узла Sort, расположенного под Limit в дереве плана. Sort загружает значения данных из своего субплана и возвращает их вызывающему узлу Limit. Вот что Sort делает, когда узел Limit вызывает его в первый раз, чтобы получить первое значение данных:

Как видите, Sort функционирует совсем не так, как Limit. Он сразу загружает все доступные данные из субплана в буфер прежде, чем что-либо возвращать. Затем он сортирует буфер с помощью алгоритма Quicksort и, наконец, возвращает первое отсортированное значение.
Для второго и последующих вызовов Sort просто возвращает дополнительные значения из отсортированного буфера, и ему больше не требуется снова вызывать субплан:

Узел плана Sort выполняется функцией C под названием ExecSort:
ExecSort
view on postgresql.org
Выполнение узла плана SeqScan
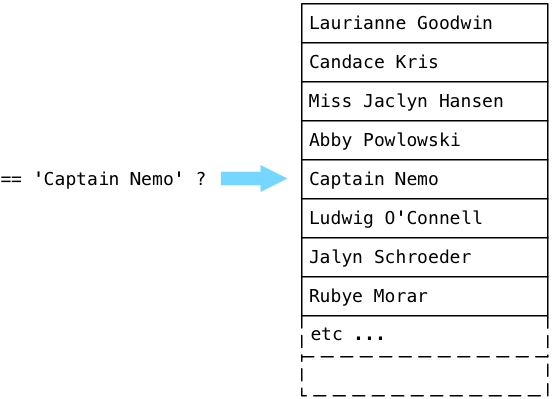
Откуда ExecSort берет значения? Из своего сублана — узла SeqScan, расположенного в самом низу дерева плана. SeqScan расшифровывается как последовательное сканирование (sequential scan), что подразумевает просмотр всех значений в таблице и возврат значений, которые соответствуют заданному фильтру. Чтобы понять, как сканирование работает с нашим фильтром, давайте представим таблицу пользователей, заполненную вымышленными именами, и попробуем найти в ней Капитана Немо.

Постгрес начинает с первой записи в таблице (которая в исходном коде Постгреса называется relation) и запускает булевы выражения из дерева плана. Проще говоря, Постгрес задаёт вопрос: «Это Капитан Немо?» Поскольку Laurianne Goodwin — это не Капитан Немо, Постгрес переходит к следующей записи.

Нет, Candace — это тоже не Капитан Немо. Постгрес продолжает:
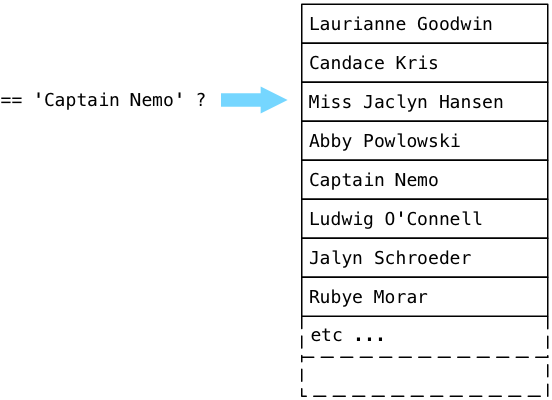
… и в конце концов находит Капитана Немо!
Постгрес выполняет узел SeqScan, используя функцию C под названием ExecSeqScan.
ExecSeqScan
view on postgresql.org
Что мы делаем не так?
Вот мы и дошли до конца! Мы проследовали за простым запросом select по всему пути через внутренности Постгреса и увидели, как он подвергся синтаксическому анализу, был переписан, спланирован и, наконец, выполнен. После выполнения многих тысяч строк кода на C Постгрес нашёл данные, которые мы искали! Теперь всё, что ему осталось сделать — это вернуть строку Капитана Немо обратно в наше приложение Rails, и ActiveRecord сможет создать объект Ruby. Наконец-то мы можем вернуться на поверхность нашего приложения.
Но Постгрес не останавливается! Вместо того, чтобы просто вернуть данные, он продолжает сканировать таблицу пользователей, хотя мы уже нашли Капитана Немо:

Что же происходит? Почему Постгрес тратит своё время, продолжая искать, несмотря на то, что уже нашёл необходимые данные?
Ответ лежит в дереве плана, в узле Sort. Вспомните, что для сортировки всех пользователей ExecSort сначала загружает все значения в буфер, многократно вызывая субплан, пока значения не закончатся. Это значит, что ExecSeqScan будет продолжать сканировать до конца таблицы, пока не соберет всех подходящих пользователей. Если бы наша таблица содержала тысячи или даже миллионы записей (представьте, что мы работаем в Facebook или Twitter), ExecSeqScan пришлось бы повторять цикл для всех записей пользователей и выполнять сравнение для каждой из них. Очевидно, что это медленно и неэффективно, и мы будем всё больше замедляться по мере того, как в таблицу будут добавляться новые записи пользователей.
Если у нас есть всего одна запись о Капитане Немо, ExecSort «отсортирует» только эту подходящую запись, а ExecLimit пропустит её через свой фильтр offset/limit… но лишь после того, как ExecSeqScan пройдётся по всем именам.
В следующий раз
Как же решить эту проблему? Что делать, если для выполнения наших SQL запросов по таблице пользователей требуется всё больше и больше времени? Ответ прост: мы создаём индекс.
В следующем и последнем посте этой серии мы научимся создавать в Постгресе индексы и избегать использования ExecSeqScan. Но самое главное — я покажу вам, как выглядит индекс в Постгресе: как он работает и почему он ускоряет такие запросы, как этот.
Комментарии (24)

java_lamer
28.06.2016 12:37Почему при анализе и перезаписе он не выкинул сортировку, как явно не нужную при limit 1
rdruzyagin
28.06.2016 12:39+1Ответ кроется в следующем абзаце:
Как видите, Sort функционирует совсем не так, как Limit. Он сразу загружает все доступные данные из субплана в буфер прежде, чем что-либо возвращать. Затем он сортирует буфер с помощью алгоритма Quicksort и, наконец, возвращает первое отсортированное значение.
Весь блок данных будет отсортирован, а потом Limit из него уже будет подтягивать нужное количество. Сортировка не является ненужной, т.к. в посгресе таблицы не имеют какого-то неявного по-умолчанию установленного порядка хранения записей.java_lamer
28.06.2016 12:49+1да, извиняюсь, поспешил не учел, что могут быть другие записи с таким именем и нам нужно вернуть именно с наименьшим id

ploop
28.06.2016 17:47Кстати, а что будет быстрее (правильнее)
классическое
select * from table where id = (select max(id) from table)или
select * from table order by id limit 1
rdruzyagin
28.06.2016 17:57Я думаю что второй вариант, т.к. при наличии индекса у вас будет единичный index scan.
В первом случае, вам надо сделать index scan для поиска максимального элемента во вложенном запросе, а потом еще index lookup для выборки нужного ряда.ploop
28.06.2016 18:00+1Второй вариант ещё удобен при наличии громоздких условий.
Завтра смогу протестировать на разных (больших) таблицах, если кому интересно, с индексами и без.ploop
29.06.2016 08:26Итак, две таблицы
t1 — 10556080 записей
t2 — 5864255 записей
1) Индексированные поля
select * from t1 where id = (select max(id) from t1) -- 12ms select * from t1 order by id desc limit 1 -- 12ms select * from t2 where id = (select max(id) from t2) -- 12ms select * from t2 order by id desc limit 1 -- 12ms
Засечь разницу не удалось, выполняется моментально
2) Неиндексированные поля
select * from t1 where summa = (select max(summa) from t1) -- 5206ms select * from t1 order by summa desc limit 1 -- 2159ms select * from t2 where summa = (select max(summa) from t2) -- 4990ms select * from t2 order by summa desc limit 1 -- 2240ms
Прирост в ~50%
Логика понятна.rdruzyagin
29.06.2016 08:31Explain analyze более показателен будет в данном случае, я думаю. «Голое» время выполнения мало о чем говорит.
ploop
29.06.2016 09:01Да, конечно. В том же порядке
1) С индексом
EXPLAIN ANALYZE select * from t1 where id = (select max(id) from t1) ------------------ Index Scan using t1_pkey on t1 (cost=0.09..9.52 rows=1 width=136) (actual time=0.100..0.102 rows=1 loops=1) Index Cond: ((id)::bigint = $1) InitPlan 2 (returns $1) -> Result (cost=0.08..0.09 rows=1 width=0) (actual time=0.084..0.085 rows=1 loops=1) InitPlan 1 (returns $0) -> Limit (cost=0.00..0.08 rows=1 width=8) (actual time=0.078..0.080 rows=1 loops=1) -> Index Scan Backward using t1_pkey on t1 (cost=0.00..885209.13 rows=10556080 width=8) (actual time=0.075..0.075 rows=1 loops=1) Index Cond: ((id)::bigint IS NOT NULL) Total runtime: 0.179 ms
EXPLAIN ANALYZE select * from t1 order by id desc limit 1 ------------------ Limit (cost=0.00..0.08 rows=1 width=136) (actual time=0.028..0.029 rows=1 loops=1) -> Index Scan Backward using t1_pkey on t1 (cost=0.00..858818.93 rows=10556080 width=136) (actual time=0.024..0.024 rows=1 loops=1) Total runtime: 0.120 ms
2) без
EXPLAIN ANALYZE select * from t1 where summa = (select max(summa) from t1) ------------------ Seq Scan on t1 (cost=279653.01..559306.01 rows=948 width=136) (actual time=14349.590..14431.243 rows=1 loops=1) Filter: (summa = $0) InitPlan 1 (returns $0) -> Aggregate (cost=279653.00..279653.01 rows=1 width=6) (actual time=12237.067..12237.068 rows=1 loops=1) -> Seq Scan on t1 (cost=0.00..253262.80 rows=10556080 width=6) (actual time=0.003..5837.878 rows=10556080 loops=1) Total runtime: 14431.325 ms
EXPLAIN ANALYZE select * from t1 order by summa desc limit 1 ------------------ Limit (cost=306043.20..306043.20 rows=1 width=136) (actual time=11477.247..11477.248 rows=1 loops=1) -> Sort (cost=306043.20..332433.40 rows=10556080 width=136) (actual time=11477.245..11477.245 rows=1 loops=1) Sort Key: summa Sort Method: top-N heapsort Memory: 25kB -> Seq Scan on t1 (cost=0.00..253262.80 rows=10556080 width=136) (actual time=0.008..5866.153 rows=10556080 loops=1) Total runtime: 11477.302 ms

VVit1
28.06.2016 13:45А нельзя подробней раскрыть тему дерева AST у постгреса?
Нет ли в природе каких изысканий на тему чтобы с клиента задавать сразу готовое дерево такого запроса сериализованного каким-либо образом. Простая его распаковка на СУБД кроме некоторого ускорения за счет исключения процедуры парсинга еще может дать некоторое упрощение процедуры составления запроса в случае механической генерации кода SQL и повышения гибкости, т.к. процесс генерации такого «человекочитаемого» SQL для обращения к СУБД это прокрустово ложе с весьма ограниченными выразительными способностями относительно того что можно сравнительно просто представить прямо в ASТ.rdruzyagin
28.06.2016 15:23+4Для раскрытия темы нужен целый отдельный цикл материалов, думается мне :)
А вообще, это еще одна затея из разряда как творчески выстрелить себе в ногу. И базе данных тоже заодно. Насколько мне известно, еще никто не придумал решений на тему передачи AST напрямую в СУБД. Дерево тоже ведь надо кодировать в какой-то формат для передачи и на принимающей стороне (внутри СУБД) преобразовывать во внутренние структуры языка Си, которые используются для хранения деревьев. Это тоже накладные расходы. Фактически — обучить базу еще одной формальной грамматике. Полученное AST все равно надо гонять через реврайт и оптимизатор, т.к. не факт что ваше нагенеренное дерево будет высокопроизводительным вариантом.
В общем, все это — очень большие заморочки с неоднозначным «профитом».

robert_ayrapetyan
28.06.2016 17:47Поверьте, это абсолютно бесполезная затея. Как раз SQL и есть «человекочитаемое» с «выразительными способностями», дерево AST без спец.знаний не построишь. С точки зрения экономии ресурсов — вы не сэкономите на спичках, вся фаза до execution редко занимает более пары мс.
VVit1
29.06.2016 12:34-1Мысль была даже не в экономии на спичках, а что часто приходится заниматься «ручной» генерацией кода SQL по каким либо действиям пользователя из ГУЯ.
В этом случае конструкции SQL быстро начинают становиться многоэтажными а средств для выражения каких-то действий катастрофически не хватать, т.е. так ты как-бы понимаешь, что выполнить ту плюшку при вот таком условии для СУБД не проблема, просто в SQL нет синтаксиса для их совместного употребления.
Но даже немного «обозрев» сложность парсера SQL быстро приходишь к выводу что построение такой «альтернативной» системы передачи команд… действительно имеет мало шансов быть реализованной во что-нить полезное и работающее.rdruzyagin
29.06.2016 12:40+1Так сложность в том, что вам не хватает выразительности SQL или средств, генерирующих итоговый SQL?
В первое мне трудно поверить, имея за плечами многолетний опыт разгребания многоэтажных «портянок», в которых порой такую неочевидную ахинею умудряются записать, что просто поражаешься)Ivan22
30.06.2016 10:07А еще я представил себе DBA, такого сидящего в своей уютной каморке, попивающего
спиртчай и смотрящего в логи профайлера!!! для отлова запросов тяжело грузящих его сервак. И что. Что он увидит??? Дерево AST?

AlexeyTokar
05.07.2016 15:53Очень странно, что Постгрес не использует оптимизацию по отсечению результатов с limit при сканировании, что выглядит логично.
MySQL, к примеру, использует: http://dev.mysql.com/doc/refman/5.7/en/limit-optimization.htmlAlexeyTokar
05.07.2016 16:00Вот еще интересные наблюдения, как LIMIT 1 наоборот убивает производительность: http://datamangling.com/2014/01/17/limit-1-and-performance-in-a-postgres-query/
Ivan22
05.07.2016 17:47Постгрес использует оптимизацию по отсечению результатов с limit при сканировании

ilyaplot
Спасибо за отличный материал. Без понимания того, как оно работает изнутри не получится полностью оптимизировать свою бд. Жду продолжения.