 Джеф Ходжес в своем прекрасном посте «Заметки о распределенных системах для новичков» рекомендует использовать САР теорему для критики найденных решений. Многие, похоже, восприняли этот совет слишком близко к сердцу, описывая свои системы как «СР» (согласованность данных, но без постоянной доступности при сетевой распределенности), «АР» (доступность без согласованного состояния при сетевой распределенности), или иногда «СА» (означает «Я всё ещё не читал статью Коды (Coda Hale) почти 5-летней давности»).
Джеф Ходжес в своем прекрасном посте «Заметки о распределенных системах для новичков» рекомендует использовать САР теорему для критики найденных решений. Многие, похоже, восприняли этот совет слишком близко к сердцу, описывая свои системы как «СР» (согласованность данных, но без постоянной доступности при сетевой распределенности), «АР» (доступность без согласованного состояния при сетевой распределенности), или иногда «СА» (означает «Я всё ещё не читал статью Коды (Coda Hale) почти 5-летней давности»).Я согласен со всеми пунктами статьи кроме того, что касается САР теоремы. Она слишком всё упрощает и слишком многие понимают её неверно для того, чтобы использовать для определения характеристик системы. Так что я прошу перестать ссылаться на САР теорему, говорить о ней и дать ей уже спокойно уйти на покой. Вместо неё мы должны использовать более точную терминологию для обсуждения различных компромиссов.
(Да, я понимаю всю иронию написания целой статьи по теме того, о чём призываю не писать других вообще. Но, как минимум, у меня будет ссылка, которую я смогу давать интересующимся, когда меня будут спрашивать, почему я не одобряю обсуждение САР теоремы. Также, я хочу извиниться, если статья вам покажется слишком напыщенной, но эта напыщенность опирается на множество ссылок.)
САР использует слишком узкое определение
Если вы хотите ссылаться на САР как на теорему (а не на расплывчатый концепт в маркетинговых материалах к вашей базе данных), вы должны быть точны. Математика требует точности. Доказательство сохраняется только если вы вкладывается в слова, то же самое значение, что было использовано при доказательстве. И оно опирается на очень точные определения:
- Согласованность (Consistency) в САР на самом деле означает линеаризуемость, что является (и очень сильным) принципом согласованности. В частности, это не имеет ничего общего с «С» из ACID, даже если эта С так же означает «согласованность». Я на пальцах объясню, что такое линеаризуемость чуть позже.
- Доступность (Availability) в САР определено как «каждый запрос, полученный работающим узлом [базой данных] в системе должен приводить к ответу [не содержащему ошибок]». Недостаточно чтобы некоторые узлы могли обработать запрос: любой работающий узел должен быть способен обработать запрос. Множество так называемых «высокодоступных» (high abailability), т.е. с низким уровнем простоя, систем в реальности не отвечают определению доступности.
- Устойчивость к разделению (Partition tolerance) ужасное название – в общих словах означает что вы для связи используете асинхронную сеть, которая может терять или задерживать сообщения. Интернет и все датацентры обладают этим свойством, так что в реальности у вас нет выбора в этом контексте.
Еще хочу заметить, что САР теорема описывает не просто любую старую систему, но систему очень определенной модели:
- Модель системы в пространстве САР это единый узел\счетчик (register) чтения-записи – и всё. Например, ничего не говорится о транзакциях, которые затрагивают несколько объектов. Они просто за пределами условий теоремы, до тех пор, пока вы не ужмете каким-то образом те объекты до единого объекта.
- Единственный тип сбоя о котором упоминает САР теорема – сетевое разделение, т.е. узлы остаются активны, но сеть между некоторыми из них не работает. Такой вид ошибки так или иначе происходит, но это не единственная вещь, которая может пойти не так: узлы могут быть сломаны или в перезагрузке, может закончиться место на диске, можете поймать баг в ПО, и тд и тп. В процессе создания распределенной системы вам надо иметь ввиду гораздо больший спектр возможных ошибок и компромиссов, к которым они ведут. Слишком сильная фокусировка на САР теореме ведет к игнорированию других важных проблем.
- Более того, САР теорема ничего не говорит о латентности, которая беспокоит большинство разработчиков гораздо больше, нежели доступность. Фактически, САР-совместимые системы могут быть сколь угодно медленными и всё равно называться «доступными». Если доводить всё до крайности, я уверен, что ваши пользователи не будут склонны называть вашу систему «доступной», если для получения веб-страницы потребуется минуты 2.
Если ваше определение совпадает с формальным значением терминов в САР теореме, тогда она подходит вам. Но если вы даёте другое определение терминам согласованности и доступности, то нельзя ожидать того, что САР теорема применима к вам. Конечно, это не значит, что путем переопределения значений вы внезапно сможете сделать невозможные вещи! Просто вы не можете руководствоваться САР теоремой и использовать ее для аргументации в поддержку вашей точки зрения.
Линеаризуемость
В случае, если вы не знакомы с линеаризуемостью (в смысле «целостностью» в контексте САР), позвольте мне кратко рассказать об этом. Формальное определение не то чтобы очень понятное, но ключевая идея, если по-простому, такая:
Если операция В началась после успешного завершения операции А, тогда операция В должна видеть состояние системы в момент завершении А или же в новом состоянии.
Для большей наглядности, можете себе представить следующую ситуацию, в которой система не будет линеаризуемой. Смотрите диаграмму ниже (эдакое превью на мою еще невыпущенную книгу):
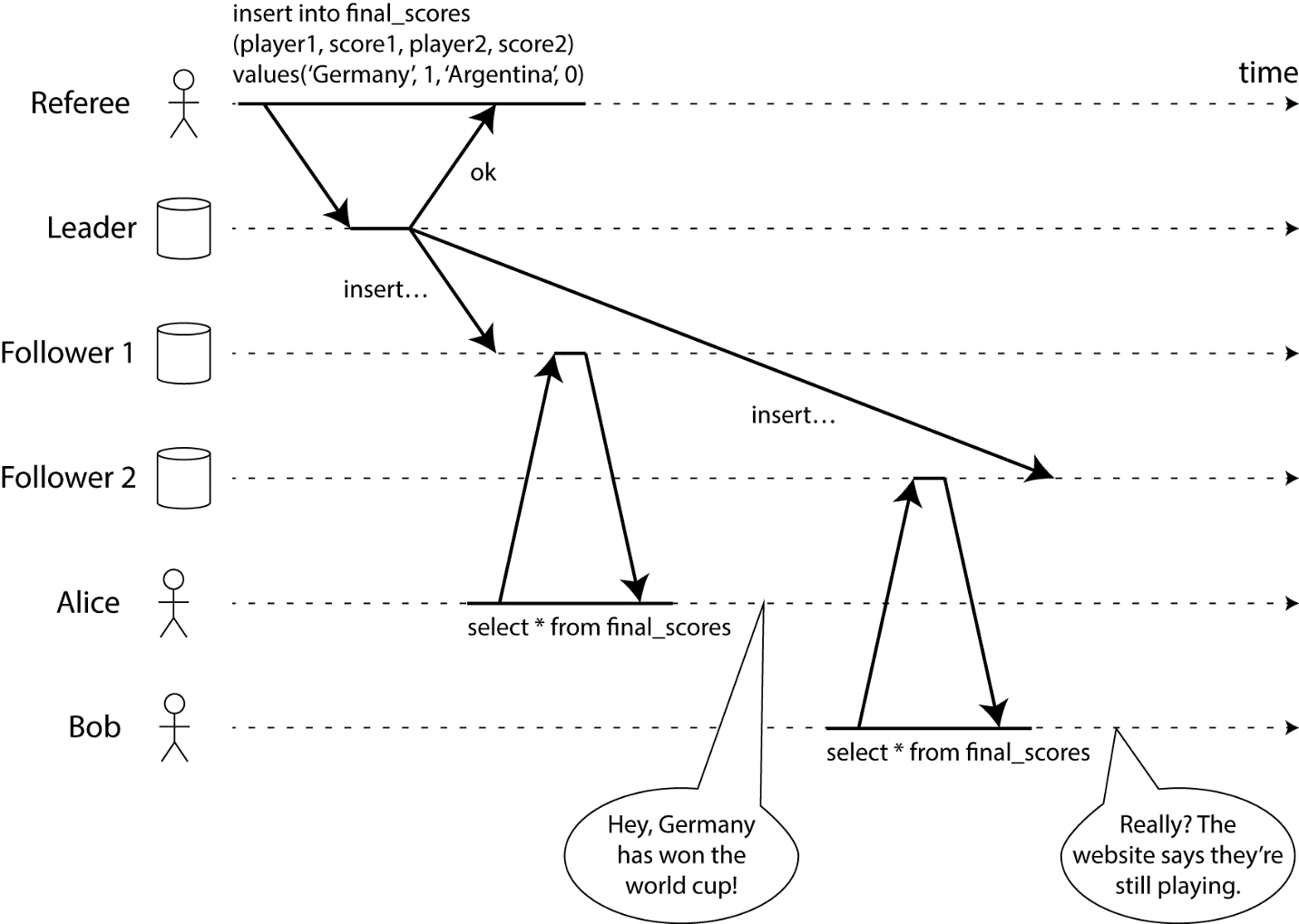
Диаграмма иллюстрирует следующую ситуацию: Боб и Алиса находятся в одной комнате, оба проверяют свои телефоны, чтобы проверить результаты финальной игры на чемпионате мира по футболу 2014 года. Сразу после того, как счет был объявлен, Алиса обновляет страницу, видит победителя и радостно сообщает об этом Бобу. Он тут же жмет Обновить на своем телефоне, но его запрос попадает на реплицированную базу, которая слегка лагает, поэтому его телефон говорит, что игра всё ещё идет.
Если бы Алиса и Боб обновили страницу в телефоне одновременно, было бы не удивительно, что они получили разные результаты, потому что они не знают в какое именно время были обработаны их запросы. Однако Боб знает, что он обновляет страницу (инициирует запрос) после того, как услышал восклицание Алисы о финальном счете и, таким образом, он ожидает что его данные будут как минимум с той же давностью, что и у Алисы. Тот факт, что он получил протухший результат запроса является нарушением линеаризации.
Знание о том, что запрос Боба произошел строго после запроса Алисы (что они не были одновременными) основывается на том, что Боб услышал результат запроса от Алисы через другой канал связи (в нашем случае вербально). Если бы Боб не услышал результата от Алисы, что игра окончилась, тогда бы он не знал о том, что его результат устарел.
Когда вы проектируете базу данных, вы не можете знать какие типы каналов общения будут у клиента. Получается, что, если вы хотите предоставить линеаризацию (САР-согласованность) в своей базе, вы должны сделать так, чтобы все думали, что есть только единственная копия данных, даже если их может быть много (реплицированные данные, кэш) в самых разных местах.
Весьма дорого и проблематично предоставить гарантии линеаризуемости, потому что это требует большого числа координационных операций. Даже CPU в вашем компьютере не предоставляет линеаризованный доступ к оперативной памяти! Для получения линеаризуемости в современных CPU необходимо использовать memory barrier инструкции. И даже протестировать линеаризуемость системы очень даже не просто.
САР-доступность
Поговорим немного о том, нужно ли жертвовать линеаризованностью или доступностью в случае с сетевым разделением.
Допустим у нас есть копии базы данных в двух разных датацентрах. Конкретный метод репликации в данном случае неважен – это может быть single-leader (master/slave), multi-leader (master/master) или quorum-based репликация (Dynamo-style). Общий смысл репликации в том, чтобы при изменении данных в одном датацентре они отображались в другом. Представим, что клиенты связанны только с одним датацентром и должно быть еще одно соединение между датацентрами для реплицирования данных.
Теперь пусть соединение между ДЦ было прервано – это то, что мы подразумеваем под сетевым разделением. Что тогда случится?
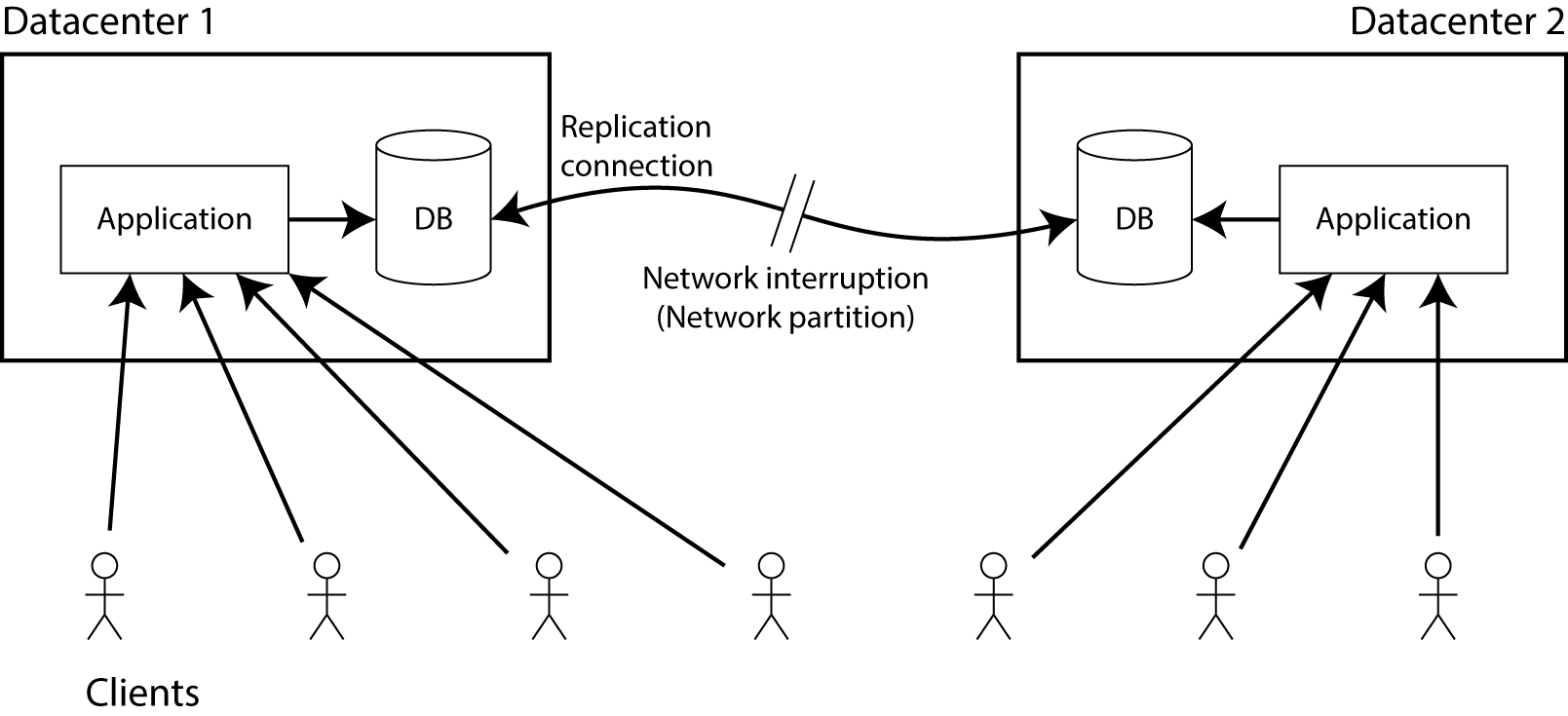
Очевидно, что вы можете выбрать один из двух вариантов:
- Приложение продолжает работать и позволяет запись в базу данных, оно полностью доступно для обоих датацентров. Но так как связь между ДЦ прервана, все изменения в одном ДЦ не будут доступны в другом. Это нарушает линеаризуемость (в терминах предыдущего примера, Алиса может быть отнесена к ДЦ1, а Боб к ДЦ2).
- Если вы не хотите терять линеаризуемость, вы должны быть уверены, что вы осуществляете всё чтение и запись в одном датацентре, который вы можете называть ведущим. В другом ДЦ, данные которого не могут быть в актуальном состоянии из-за потери соединения, база данных должна прекратить обслуживать клиентов на чтение и запись до восстановления синхронизации. Так как зависимая база данных во втором ДЦ не может обрабатывать запросы, то она не САР-доступна.
Кстати, это по сути доказательство САР теоремы. В примере используются два ДЦ, но все может быть применено и к одному ДЦ, так как сетевые проблемы могут быть внутри тоже. Просто я подумал, что пример с двумя ДЦ более простой и наглядный.
Заметьте что в нашей условно «недоступной» ситуации во втором варианте, мы вполне успешно можем обрабатывать запросы в одном из ДЦ. Так что если система построена с упором на линеаризуемость (т.е. не САР-доступна), то это не обязательно означает что сетевая разделенность автоматически ведет к простою приложения. Если вы сможете перевести всех клиентов на использование ведущего ДЦ, клиенты не заметят падения вообще.
Доступность (availability) на практике не то чтобы ссылается на САР-доступность. Доступность вашего приложения скорее всего измеряется в SLA (например, 99,9% правильных запросов должны возвращать результат в течении 1 секунды), но такое соглашение может быть реализовано в системах CAP-доступных и САР-недоступных.
На практике, системы расположенные во многих ДЦ часто разрабатываются с учетом асинхронной репликации и выходит что они нелинеаризованные. Однако причиной такого выбора чаще всего является латентность сети самой по себе, а не только из-за повышения устойчивости датацентров и падучести сети.
Многие системы ни линеаризуемые, ни САР-доступные
Как же создавать системы с учетом строгих определений в САР-теореме для целостности (линеаризованности) и доступности?
Например, возьмите любую БД с репликацией и одним ведущим (single leader), что является стандартной настройкой для большинства реляционных баз данных. В такой конфигурации клиент не может писать в базу, если он отделен от ведущего. Даже если клиент может читать из копий (read-only recplica), тот факт, что он не может писать данные означает что любая настройка с единым ведущим не САР-доступна. И неважно, что такие системы часто позиционируются как «системы с высокой доступностью».
Если репликация с одним ведущим не САР-доступна, то делает ли это её «СР»? Погодите, не так быстро! Если вы разрешите приложению читать с реплик, а реплики асинхронные (по умолчанию для большинства БД), тогда зависимая БД может быть слегка устаревшей во время чтения. В этом случае чтение будет не линеаризованным, т.е. не CAP-согласованным.
Более того, базы данных с уровнем изоляции snapshot/MVCC намеренно нелинеаризованны, потому что требование линеаризации уменьшит количество одновременно выполняющихся операций (concurrency). Например, PostgreSQL SSI дает сериализуемость, но не линеаризуемость, с Оракл такая же ситуация. Только потому что база данных маркирована как ACID не означает, что БД удовлетворяет определению согласованности\непротиворечивости в CAP теореме.
Получается что эти системы ни CAP-согласованы, ни САР-доступны. Они ни «СР», ни «АР», они просто «Р», чтобы это ни значило. Да, формулировка «две из трех» позволяет вам выбрать только одну опцию из трех, или даже ни одной!
А что насчет «NoSQL»? Для примера можно взять MongoDB: она имеет одного ведущего на шард (по крайней мере так предполагается, если это не режим split-brain), так что учитывая все сказанное выше, уже нет САР-доступности. И Кайл (Kyle) недавно показал, что это позволяет делать нелинеаризованное чтение даже при самом высоком уровне настроек согласованности, так что САР-согласованности нет так же.
Производные от Dynamo, такие как Riak, Cassandra и Voldemort, часто зовутся «АР» потому что оптимизированы для высокого уровня доступности? Ну, это зависит от ваших настроек. Если в реплики можно писать и читать данные (R=W=1) – они действительно CAP-available. Однако, если чтение и запись осуществляются кворумом (R+W>N) и у вас разделение по сети, клиенты находящиеся на стороне меньшинства не могут достучаться до кворума, получается что кворум операции так же не САР-доступны (как минимум временно, пока база данных не поднимет дополнительные реплики на стороне меньшинства).
Порой вы можете встречаться с людьми, которые утверждают что чтение и запись на основе кворума гарантирует линеаризацию, но я думаю это будет не очень умно полагаться на это – хрупкая комбинация фич, таких как sloppy quorums и чтение с восстановлением (read repair) могут привести к хрупкой грани, когда
Все упомянутые системы не плохие: люди успешно используют их в боевом окружении. Однако, до сих пор мы не смогли строго определить из как «AP» или «CP», в том числе потому что это зависит от определенной операции или конфигурации, или потому что система не удовлетворяет строгому определению непротиворечивости или доступности в САР-теореме.
Реальный пример: ZooKeeper
Что насчет ZooKeeper? Эта система использует алгоритм соглашений, поэтому многие сходятся во мнении что это чистый пример предпочтения согласованности над доступностью (т.е. «СР система»).
Однако, если вы посмотрите в документацию, там четко сказано, что ZooKeeper по умолчанию не предоставляет линеаризованного чтения. Каждый клиент подключен к одной из нод, и когда вы хотите начать чтение, вы видите данные только с вашей ноды, даже если есть обновленные данные на соседних нодах. Это позволяет читать данные гораздо быстрее, чем в случае необходимости сбора кворума или опрашивать лидера для каждого чтения, но это так же означает что ZooKeeper по умолчанию не отвечает требованиям САР теоремы по непротиворечивости.
Вообще сделать линеаризованное чтение в ZooKeeper возможно используя sync перед командой чтения. Это не поведение по умолчанию, потому что получаем просадку по производительности. Команда sync используется, но не всё время.
Что насчет доступности в ZooKeeper? Что ж, ZK требует решение большинства для достижения соглашения для записи данных. Если у вас есть разделение на большинство и меньшинство нод, то большинство будет функционировать как прежде, однако ноды оставшиеся в меньшинстве не смогут обрабатывать запросы на запись, несмотря на то, что все они исправны. Получается, функция записи в ZK не САР-доступна в разделенном (partition) режиме функционирования (даже с учетом того, что большинство нод может записывать данные).
Чтобы добавить во всё это еще больше веселья, в версии ZooKeeper 3.4.0 добавили режим только для чтения, в котором ноды, оставшиеся в меньшинстве могут продолжать обслуживать запросы чтения – кворум не требуется! Т.е. режим для чтения является САР-доступным. Таким образом, ZK по умолчанию не является ни САР-согласованным («СР»), ни САР-доступным («АР») – это реально просто «Р». Впрочем, вы можете сделать систему «СР» используя метод sync, и только для операции чтения система «AP», если включить верные опции.
Но вот что раздражает: называть ZooKeeper «не согласованной» системой, просто потому что она нелинеаризуемая по умолчанию – действительно ужасная интерпретация фич. ZK на самом деле дает великолепную степень непротиворечивости! Он поддерживает atomic broadcast совместно с гарантированной casual consistency – что более сильное условие, чем read your writes, monotonic reads и consistent prefix reads вместе взятые. Документация говорит, что система дает последовательную непротиворечивость, но это недооценка самих себя, потому что ZooKeeper гарантирует более сильное определение, чем последовательная непротиворечивость.
СР/АР: ложная дихотомия
Тот обстоятельство, что мы не смогли однозначно классифицировать даже одно хранилище как «АР» или «СР» должно наводить на определенные мысли: это просто неподходящие определения для описываемых систем.
Я уверен, что мы должны прекратить пытаться определить различные хранилища в категории «АР» или «СР» потому, что:
- В рамках одно приложения может существовать несколько разных операций с различными характеристиками согласованности данных.
- Множество систем не отвечают определению согласованности и доступности в рамках САР-теоремы. Однако я никогда не слышал, чтобы кто-то называл свою систему просто «Р», наверно потому что это плохо звучит. Но это не плохо – это может быть идеально спланированная архитектура, которая просто не попадает в категории СР/АР.
- Даже если большинство ПО не попадают точно в упомянутые категории, люди все равно стараются втиснуть его в одну из категорий, и получается, что неизбежно меняется смысл «согласованности» или «доступности» к тому, что они хотят под этим понимать. К сожалению, если значение слов меняется – САР теорема больше не может применятся, и разделение на СР/АР не имеет значения.
- Огромное количество нюансов теряется при попытке втиснуть систему в одну из двух категорий. Существует огромное количество аспектов касательно устойчивости к сбоям, латентности, простоты модели программирования, взаимодействия и так далее, что может быть использовано в проектировании распределенных систем. Физически невозможно закодировать все эти нюансы в одном бите информации. Например, даже ZooKeeper поддерживает «AP» в режиме только для чтения, и этот режим дает возможность читать записи в том же самом порядке как они были записаны – это гораздо сильнее, чем «АР» в таких системах как Riak или Cassandra – так что было бы нелепо складывать их в одну кучу.
- Даже Эрик Брюэр (Eric Brewer) признает, что САР вводит в заблуждение и слишком всё упрощает. В 2000 году было важно начать обсуждение компромиссов в распределенных системах, и это сработало. Не было намерения создать какой-то прорывной формальный документ или строгую классификацию схем для хранилищ данных. 15 лет спустя у нас появился гораздо более богатый набор инструментов с разными подходами к обеспечению целостности данных и защитой к ошибкам. САР сделала свою задачу и теперь время двигаться дальше.
Учитесь думать самостоятельно
Если «СР» и «АР» не подходят для описания и критики систем, что следует использовать взамен? Не думаю, что у меня есть единственный правильный ответ. Многие люди провели немало времени напряжено размышляя о проблемах распределенных систем, и предложили терминологию и модели, которые сейчас нам помогают понять проблемы. Чтобы узнать большое об этих идеях вам надо самостоятельно покопаться в литературе:
- Хорошей отправной точкой будет статья Дуга Терри где он разъясняет различия между разными уровнями частичной согласованности используя бейсбол для примера. Очень легко читается и понимается, даже если вы (так же, как и я) не американец и ничего не понимаете в бейсболе.
- Если вы хотите узнать побольше про модели транзакционной изоляции (что не то же самое что и согласованность в распределенных репликах, но близко), мой маленький проект Hermitage может помочь.
- Связь между согласованностью реплик, транзакциями и доступностью исследована Питером Баилисом (Peter Bailis). Документ так же объясняет значение иерархии уровней согласованности которые так любит показывать Кайл Кингсбери (Kyle Kingsbury).
- Когда вы всё это прочитаете, вы будете готовы копнуть глубже. Я перелопатил кучу ссылок и документов для этого поста – почитайте их, эксперты уже отлично описали многие вещи для вас.
- В качестве последнего довода, если вы не можете читать первоисточники, я предлагаю вам взглянуть на мою книгу, которая содержит и суммирует наиболее важные идеи в удобном виде. Видите, я старался очень сильно не сделать из поста рекламную речь.
- Если вас заинтересовала тема ZooKeeper и вы хотите обратить на него более детальный взгляд, то Flavio Junqueira и Benjamin Reed написали хорошую книгу.
Независимо от того, какой путь изучения вы выберете, я призываю вас сохранять любопытство и терпение – это непросто. Но вы будете вознаграждены, потому что вы будете понимать причины компромиссов и сможете определить какой тип архитектуры нужен в вашем конкретном случае. Но чтобы вы ни делали, прекратите говорить о «СР» и «АР», потому что это не имеет смысла.
Комментарии (22)

0x0FFF
18.05.2015 12:03+4Статья поднимает правильные вопросы, но формулировка идеи чересчур широка. «Забудьте САР теорему как более не актуальную» — сразу же вспоминается институт, где фраза «забудьте всё, чему вас учили в школе» была расхожей, а также первые дни на работе, где часто можно было слышать «забудьте все, чему вас учили раньше».
Это неправильно, и CAP теорема в своё время послужила основанием для обширных исследований и подтолкнула развитие распределенных систем обработки данных. Также введенная ей концепция BASE стала основой для многих реальных систем.
То, что CAP-теорема кем-то неверно трактуется еще не значит, что она более не актуальна. Это равносильно высказыванию «теорема Пифагора более не актуальна» после появления неевклидовой геометрии
KlonD90
18.05.2015 13:11+1Проблема CAP теоремы в том что она ничего по сути не может сказать о базе данных. Это сейчас по большей части маркетинг чушь, типа способы позиционирования себя на рынке для тех кто не в курсе. Ну и CAP теорема эта слишком поверхностна чтоб хоть как-то охарактеризовать базу данных, потому как современные БД не вписываются в нее на таком лобовом уровне. Весь смысл в том чтобы отказаться от CAP теоремы как от способа хоть как-то описывать базы данных в современном мире.
0x0FFF
18.05.2015 13:34+3Не совсем согласен с термином «база данных», скорее теорема все-таки говорит о системах обработки данных в общем. Тот же Zookeeper базой данных можно назвать с большой натяжкой.
Сам автор статьи говорит, что он не знает, что лучше использовать для классификации систем обработки данных. С моей точки зрения CAP теорема тем не менее в этом смысле очень хороша, если её правильно использовать. Не «наша система является AP» или «наша система является CP», а «проблема консистентности в нашей системе решается так ...», «проблема доступности в нашей системе решается так ...» — как общее направление рассуждений о характере распределенной системы. Сам автор теоремы убеждает избегать категоричности в классификации систем

owniumo
18.05.2015 12:51+4Я совсем даже не сварщик, но архитекторы систем должны, по-моему, быть достаточно флегматичными, чтобы не купиться на столь кричащий заголовок.
А для новичков материала горы и категоричность
Забудьте, Прекратите характеризовать
не нужна, как подметил 0x0FFF.
Но чтобы вы ни делали, прекратите.
Вот ещё, апрельское (eng):
lvh — Distributed Systems 101 — PyCon 2015:
A very brief introduction to the theory and practice of distributed systems.

man4j
19.05.2015 18:47Про базы данных, которые нелинеаризованны, я что-то не очень понял (

Duduka
19.05.2015 19:21Видимо, транзакции теперь тотально запрещены на планете Земля.
0x0FFF
20.05.2015 10:53+2Представьте таблицу «table» с одним полем «a», значение которого «1». И такую последовательность действий:
- Транзакция1 — начало
- Транзакция1 — select a from table
- Транзакция2 — начало
- Транзакция2 — select a from table
- Транзакция1 — update table set a = 2 (значение посчитано во внешней системе как результат select'а + 1)
- Транзакция1 — commit
- Транзакция2 — update table set a = 2 (значение посчитано во внешней системе как результат select'а + 1)
- Транзакция2 — commit
Есть разные уровни изоляции транзакций, и разные модели консистентности (на видео выше их указано 16). Даже если вы выберете serializable, в том же mysql это serializable* (то есть не совсем serializable) и от проблемы указанного выше примера не защитит. В Oracle есть serializable*, который по сути RR, а совсем не serializable. В MS SQL ситуация аналогична, и их serializable* от проблемы в моем примере не защитит. В postgresql есть честный serializable, но эта честность не бесплатна — вторая транзакция при попытке commit упадет с ошибкой, и рестартовать её уже проблема вашего приложения. Также есть разница между serializability, lineralizability и strict serializability (см. здесь и здесь). Если просто, то serializability гарантирует, что «существует» порядок последовательного выполнения транзакций, выполняемых параллельно. Lineralizability же также гарантирует, то этот порядок соответствует порядку инициации транзакций (раньше стартовала — раньше выполнена).Duduka
20.05.2015 12:50САР — то тут причем? первый коммит должен пройти, второй должен упасть, если Вы требуете тотальной консистентности [ а вот если первый не прошел, то второй может(а не должен) пройти ] (strict consistency), если полная блокировка всей базы не столь принципиальна, можно условия ослабить(и записать любой), но теорема, то тут причем.
Я согласен, что ее применяют не к месту. Исхожу из того, что она всего лишь завуалированная констатация факта, что нельзя сделать быструю, надежную и дешевую систему, чем-то прийдется жертвовать. И когда проектируют систему, то указывают _последовательность_ приоритетов в ее реализации, но дальше… оценивать реализацию системы по соответствию ее заявленым приоритетам, а не свойствам — глупость.
RPG18
20.05.2015 13:04А причем тут транзакции? Как понимаю на картинке master-slave репликация, и изменения тупо еще не поступили на Folower 2.
Duduka
20.05.2015 13:20??? если требовать полной консистентности (С в САР-теореме), то транзакции не могут нормально завершиться если нет подтверждения с обоих (или вернее — всех серверов, поэтому и такие глюки и задержки). А то, что нет такой системы (в топике объясняется почему), которая этот режим реализует — это другой разговор.
Хочется «С» — жди всех соединений, и пусть все остальные отдыхают. Хочется «А» — не надейтесь на согласованность.RPG18
20.05.2015 13:55Это вы описываете синхронную репликацию.
Duduka
20.05.2015 14:06-1А какую должен описать?(транзакцию, а репликация это если разработчик так ее реализует)
RPG18
20.05.2015 14:25Транзакция и репликация это две отдельные темы, т.к. репликация может быть синхронной или асинхронной.
В случае асинхронной утверждениепервый коммит должен пройти, второй должен упасть:
ложно.Duduka
20.05.2015 14:55Последняя фраза моего комментария на который вы отписались (Это вы описываете синхронную репликацию.) как раз это и говорит.
0x0FFF
20.05.2015 13:38CAP не причем, я ответил на комментарий касающийся параграфа статьи, в котором содержится утверждение, что базы данных не линерализованны. И это действительно так, я показал пример

Throwable
20.05.2015 13:58Вы не правы. В Вашем примере вторая транзакция откатится даже на минимальном уровне (READ_UNCOMMITED). От потерянного обновления защищают все уровни. Говоря иначе, транзакция устанавливает «write-locks» на измененные ею данные, которые также проверяются при записи в других параллельных транзакциях. Проблема как раз с «read-locks»: т.к. 90% операций — чтение, то для быстродействия на разных уровнях ими пренебрегают для быстродействия. Для полностью Serializable уровня необходимы read-блокировки, который каждый реализует как может: кто блокирует таблицу целиком (H2, Derby), Mysql, кажется, просто добавляет в каждый SELECT… FOR UPDATE..., но в целом всегда очень неэффективно.
В современных базах на смену write-блокоровкам пришел более эффективный контроль версий (MVCC), на основе которого очень просто и сразу реализуется т.н. Snapshot-изоляция, которая лежит между Serializable и Repeatable read. Многие производители (Oracle) тупо называют ее Serializable, тогда как другие (MsSQL, Postgres, DB2) имеют специально отдельный уровень для Serializable.
А вот пример, который не выполнится при Serializable, но прокатит при Snapshot (т.н. write skew). У клиента в банке два счета. По контракту его суммарный баланс на всех счетах не должен быть отрицательным, тогда как на любом из счетов он может быть негативный. Пусть на обоих счетах лежат по 50 енотов (A=50, B=50). И на оба счета приходят одновременно две транзакции на 100 енотов (X=100, Y=100):
T1:
select A, B
if (A+B-X < 0) fail
else update A = A-X
T2:
select B, A
if (A+B-Y < 0) fail
else update B = B-Y
Поскольку для параллельных T1 и T2 A+B=100, и записываемые данные не пересекаются, то в результате на обоих счетах у клиента будет по -50 енотов. Эта проблема и многие схожие легко решаются при помощи ручной блокировки (pessimistic lock). Поэтому в большинстве приложений хватает READ_COMMITED уровня, установленного по умолчанию плюс ручное отслеживание схожих ситуаций.0x0FFF
20.05.2015 14:18Вы не правы. Потерянное обновление — это если бы команда была «update test set a = a + 1;» в обоих транзакциях, и действительно от неё защищают все уровни изоляции транзакций. Тут вопрос в том, что новое значение для a вычислено во внешней системе, и мой пример выполнится везде, кроме PostgreSQL в режиме serializable, вы можете проверить
Throwable
20.05.2015 18:23Сорри! Действительно! Пару лет назад делал похожие тесты, и вторая транзакция реально откатывалась! Попробовал сейчас повторить — обе коммитаются! Более того, даже если в H2 поставить serializable уровень, обе транзакции прокатывают! Надо будет найти те исходники и посмотреть в чем дело.
Throwable
Интересно. Я всегда считал, что CAP — это некий общий принцип, который не вдается в частности организации системы, а его интерпретация немножко другая.
Availability — это именно обработка запроса с минимальной задержкой, нежели просто доступность данных. В распределенной системе невозможно одновременно Consistency и Availability по причине того, что для «C» необходим координированный доступ к данным (через блокировки или MVCC), которые в распределенной среде занимают большое время (необходим ответ от всех затронутых нодов). То есть для чтения либо жертвуем «А» и ждем, когда коммитнется транзакция, либо жертвуем «C» и читаем неполные данные (при асинхронной репликации).
Если CAP затрагивает только аспект сетевого fault tolerance, но не latency, то она действительно очень ограничена.
P.S. как я понял, линеаризируемость — это перевод «serializable»?
VioletTape Автор
Я вот тоже до недавнего времени считал, что это общий принцип. Но наткнувшись на статью и почитав ссылки из нее, я понял, что это не так. Я так впечатлился, что решил перевести, потому что это очень важно.
Нет, «линеаризуемость» это не «сериализуемость», это совсем разные термины по статье.
Сериализация представляет собой процесс преобразования объекта в поток байтов для хранения объекта или передачи его в память, базу данных или файл. Ее основное назначение — сохранить состояние объекта для того, чтобы иметь возможность воссоздать его при необходимости. В то время как линеаризация это сохранение строго исторического порядка записей\запросов как они приходили в систему. В каком-то частном случае это может быть одно и то же.
Про Availability в статье тоже есть. И вы правы, что сейчас это относится больше к SLA и измеряется в процентах и по сути является latency.
Throwable
Тут небольшая путаница с терминами. Описанное понятие линеаризируемости очень похоже на «serializable» уровень изоляции из ACID.
gridem
Линеаризуемость и сериализуемость — разные понятия.
Линеаризуемость — изменения применяются практически мгновенно.
Сериализуемость — результат получается из некоторой последовательности транзакций.
Подробнее здесь