
Введение.
На той неделе darkk описал свой подход к проблеме распознавания состояния моста(сведён/разведён).
Алгоритм, описанный в статье, использовал методы компьютерного зрения для извлечения признаков из картинок и скармливал их логистической регрессии для получения оценки вероятности того, что мост сведён.
В комментариях я попросил выложить картинки, чтобы можно было и самому поиграться. darkk на просьбу откликнулся, за что ему большое спасибо.
В последние несколько лет сильную популярность обрели нейронные сети, как алгоритм, который умудряется в автоматическом режиме извлекать признаки из данных и обрабатывать их, причём делается это настолько просто с точки зрения того, кто пишет код и достигается такая высокая точность, что во многих задачах (~5% от всех задач в машинном обучении) они рвут конкурентов на британский флаг с таким отрывом, что другие алгоритмы уже даже и не рассматриваются. Одно из этих успешных для нейронных сетей направлений — работа с изображениями. После убедительной победы свёрточных нейронных сетей на соревновании ImageNet в 2012 году публика в академических и не очень кругах возбудилась настолько, что научные результаты, а также програмные продукты в этом направлении появляются чуть ли не каждый день. И, как результат, использовать нейронные сети во многих случаях стало очень просто и они превратились из "модно и молодёжно" в обыкновенный инструмент, которым пользуются специалисты по машинному обучению, да и просто все желающие.
Постановка задачи.
darkk выложил изображения моста Александра Невского в Санкт-Петербурге. 30k+ в поднятом положении, 30k+ в опущенном, 9k+ в промежуточном положении.
Задача, которую мы пытаемся решить: по изображениям со статической камеры, которая направлена на мост Александра Невского в различное время дня, ночи и времени года определить вероятность того, что мост принадлежит к классам (поднят/опущен/процессе). Я буду работать с классами поднят/опущен из тех соображений, что именно это важно с практической точки зрения.
Нейронные сети могут решать достаточно сложные задачи с изображениями, шумными данными, в условиях, когда данных для тренировки очень немного и прочей экзотикой(Например вот эта задача про отвлекающихся водителей или вот эта про сегментацию нервов. Но! Задача классификации на сбалансированных даннных, когда этих данных хватает и объект классификации практически не меняется — для нейронных сетей, да и вообще для задач машинного обученя — это где-то между просто и очень просто, что darkk и продемонстрировал, используя достаточно простой и интерпретируемый подход комбинации компьютерного зрения и машинного обучения.
Задача, которую я постараюсь решить, — это оценить, что нейронные сети могут предложить по данному вопросу.
Подготовка данных.
Не смотря на то, что нейронные сети достатоно устойчивы к шуму, тем не менее слегка почистить данные — это никогда не помешает. В данном случае — это обрезать картинку так, чтобы там было по максимуму моста и по минимуму всего остального.
Было во так:

А стало вот так:

Также надо разделить данные на три части:
- train
- validation
- test
train — 19 мая — 17 июля
validation — 18, 19, 20 июля
test — 21, 22, 23 июля
Собственно, на этом подготовка изображений закончилась. Пытаться вычленять линии, углы, какие-то другие признаки не надо.
Тренировка модели.
Определяем простую свёрточную сеть в которой свёрточные слои извлекают признаки, а последний слой по ним пытается ответить на наш вопрос.
(Я буду использовать пакет Keras с Theano в качестве backend просто потому что это дёшево и сердито.)
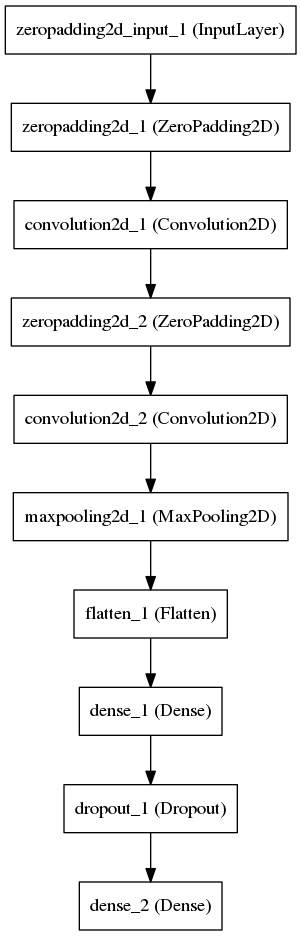
У нас достаточно простая задача, простая структура сети с малым числом свободных параметров, поэтому сеть замечательно сходится. Все картинки можно засунуть в память, но, не хочется, так что тренировать будем считывая картинки с диска порциями.
Тренировочный процес выглядит как-то вот так:
Using Theano backend.
Using gpu device 0: GeForce GTX 980 Ti (CNMeM is disabled, cuDNN 5103)
Found 59834 images belonging to 2 classes.
Found 6339 images belonging to 2 classes.
[2016-08-06 14:26:48.878313] Creating model
Epoch 1/10
59834/59834 [==============================] - 54s - loss: 0.1785 - acc: 0.9528 - val_loss: 0.0623 - val_acc: 0.9882
Epoch 2/10
59834/59834 [==============================] - 53s - loss: 0.0400 - acc: 0.9869 - val_loss: 0.0375 - val_acc: 0.9880
Epoch 3/10
59834/59834 [==============================] - 53s - loss: 0.0320 - acc: 0.9870 - val_loss: 0.0281 - val_acc: 0.9883
Epoch 4/10
59834/59834 [==============================] - 53s - loss: 0.0273 - acc: 0.9875 - val_loss: 0.0225 - val_acc: 0.9886
Epoch 5/10
59834/59834 [==============================] - 53s - loss: 0.0228 - acc: 0.9896 - val_loss: 0.0182 - val_acc: 0.9915
Epoch 6/10
59834/59834 [==============================] - 53s - loss: 0.0189 - acc: 0.9921 - val_loss: 0.0142 - val_acc: 0.9961
Epoch 7/10
59834/59834 [==============================] - 53s - loss: 0.0158 - acc: 0.9941 - val_loss: 0.0129 - val_acc: 0.9940
Epoch 8/10
59834/59834 [==============================] - 53s - loss: 0.0137 - acc: 0.9953 - val_loss: 0.0108 - val_acc: 0.9964
Epoch 9/10
59834/59834 [==============================] - 53s - loss: 0.0118 - acc: 0.9963 - val_loss: 0.0094 - val_acc: 0.9979
Epoch 10/10
59834/59834 [==============================] - 53s - loss: 0.0111 - acc: 0.9964 - val_loss: 0.0083 - val_acc: 0.9975
[2016-08-06 14:35:46.666799] Saving model
[2016-08-06 14:35:46.809798] Saving history
[2016-08-06 14:35:46.810558] Evaluating on test set
Found 6393 images belonging to 2 classes.
[0.014433901176242065, 0.99405599874863126]
...Или на картинках:

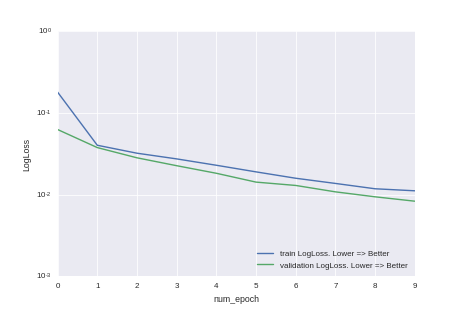
Видно, что мы не дотренировали и точность модели можно повысить, просто увеличив время тренировки. Но, как любят говорить в университах нерадивые преподаватели — это домашнее задание для желающих.
Оценка точности предсказания
Численная
Оценка точности будет производится на данных за 21-23 июля.
accuracy_score = 0.994
roc_auc_score = 0.985
log_loss_score = 0.014
Визуальная

Зелёная линия — то, что отмечено на картинках.
Синяя линия — бегущее среднее по предыдущим 20 предсказаниям.
Что осталось за кадром.
Почему при тренировке модели точность на val лучше, чем на train. Ответ: => потому что на train — эта точность с dropout, а на val — нет
Почему выбрана именно такая архитектура модели. Ответ => Хочется сказать: "Но это же очевидно!", но правильный ответ, наверно, всё-таки — читаем конспект лекций на http://cs231n.github.io/, смотрим серию лекций на https://www.youtube.com/watch?v=PlhFWT7vAEw и гоняем соревнования на kaggle.com пока не прийдёт озарение в виде ответа:"Эта архитектура выбрана потому что она работает на очень похожих задачах типа MNIST"
На каких картинках модель даёт ошибку. Ответ: => Я глянул одним глазом — это те картинки, где и человек не отличит просто потому что камера не работала. Возможно там есть адекватные изображения, на которых модель даёт ошибку, но это требует более вдумчивого анализа.
Где взять код, от всего вышеописанного? Ответ => https://github.com/ternaus/spb_bridges
Будет ли модель работать на других мостах? Ответ => не исключено, но кто его знает, надо пробовать.
А если бы задача стояла так: По изображениям моста Александра Невского создать модель для предсказания разведения Литейного моста, вы бы действовали так же? Ответ => Нет. У них различная система подъёма, так что там надо было смотреть на данные, пробовать и думать. Вопрос про правильной cross validation стоял бы очень остро. В общем это была бы интересная задача.
А если не обрезать изображение, так чтобы остался только мост, то задача стала бы сильно сложнее? Ответ => Стала бы, но не сильно.
А что если делать классификацию не на два класса (сведён/разведён), а на три (сведён/разведён/в движении)? Ответ => Если классифицировать на три класса, то получим оценку принадлежности к одному из трёх классов. Но надо менять несколько строк в файле, который делит данные на части, и одну в определении модели. => Домашнее задание для энтузиастов.
Пример сложной задачи, на которой надо мозг сломать, чтобы заставить модель хорошо работать => Ответ: Вот прямо сейчас я закончу текст, причешу github c кодом. и начну думать о сегментации нервов на изображениях.
Где взять сами картинки с мостами? Ответ: => Это к darkk
- Сколько нужно нейронов, чтобы узнать, разведён ли мост Александра Невского? Ответ: => И один нейрон, то есть логистическая регрессия выдаст замечательный результат.
Послесловие.
Это действительно очень простая задача для нейронных сетей на данном этапе развития этого направления в машинном обучении. Причём тут даже и не нейронные сети, а и более простые алгоритмы будут работать на ура. Премущество нейронных сетей в том, что они работают в режиме автоматического извлечения признаков, при наличии большого количества шума, и на некоторых типах данных, например, при работе с изображениями выдают точность на уровне State Of The Art. И данным текстом с приложенным кодом я попытался развеять мнение, что работать с нейронными сетями очень сложно. Нет это не так. Работать с нейронными сетями так чтобы они показывали хорошую точность на сложных задачах — это сложно, но очень многие задачи к этой категории не относятся и порог вхождения в эту область не такой высокий, как может показаться после прочтения новостей на популярных ресурсах.
Комментарии (30)

Meklon
07.08.2016 13:55+2Спасибо за пост. Ради интереса пошел смотреть код для seaborn, но как-то крайне странно он выглядит. Вообще на Python не похоже. Не претендую, впрочем на профессионализм, конечно. Я чисто прикладные вещи пишу для научных задач.
Например, вот софт для анализа гистохимии по фотографиям. Нужно все же попробовать самые простые нейросети. Часто нужно искать сложные структуры на срезах, которые обычной пороговой сегментацией не вытащить.

ELEKTRO_YAR
07.08.2016 14:41Хорошая статья, правда мост тут скорее как пример использования, так как задача с мостом вполне решаема без нейросетей средствами OpenCV.

jinxal
07.08.2016 15:16Как-то это нелогично: писать нейронку, изучать theano, юзать сuda, обсчитывать всё на видяхе — никто не будет это делать, когда простые алгоритмы на питоне в несколько строк решат эту задачу быстрее и со схожей точностью.
Хорошо для повышения навыка работы с нейронками, но не для первого изучения — все-таки MNIST гораздо эффективнее и интереснее для этого.
darkk
07.08.2016 20:14+1MNIST — скучно. И дело не в том, что я живу в Питере и мне эта боль с разводными мостами близка — я поговорил с товарищем, который учится в ШАДе, он теперь тоже озадачен тем, чтоб найти красивую и не суперсложную задачу из "реального мира", которую можно решить методами машинного обучения :)

ternaus
07.08.2016 20:16Безусловно заморачиваться с установкой библиотек(cuda, theano, keras) и штудировать туториалы по keras чисто для этой задачи с мостами, резона нет. Тем более, что шутдироваться будет как раз примеры по MNIST. И данную задачу я рассмотрел как пример.
Но!
- Для меня нейронные сети это один из стандартных инструментов и на написание кода, который, собственно, и отвечает за нейронные сети ушло минут 15. А пытаться разбираться с тем как призаки извлекать из изображений вручную, у меня бы ушло гораздо больше времени просто потому, что это не очень знакомая для меня тема(Я знаю теорию, но не использую их на практике по работе или для соревнований на kaggle.com). А у кого-то наоборот, они уже знают эти методы, но не большого опыта разботы с нейронными сетями. Поэтому для кого-то «дёшево и сердито» — это несколько строк на питоне, а для кого-то это вбросить всё в нейронную сеть и дать ей самой разобраться.
- Если задачу усложнить и дать 20 мостов, для которых изображения с 1000 камер, и камеры ещё и движутся вышеописанный код, практически не изменится, потому что признаки излекаются автоматически. А вот методы, где признаки извлекаются вручную из несколько строк на питоне скорее всего превратятся во что-то большое злое.
В общем под разные задачи — разные инструменты. И в данной задаче можно запросто справится и без нейронных сетей. Да и классический PCA для извлечения признаков с последующим применением SVM тоже скорее всего замечательно сработает.
gogolgrind
07.08.2016 15:43А как была выбрана именно эта архитектура СNN? И что делает ZeroPadding cлой?
ternaus
07.08.2016 20:29- ZeroPadding добавляет нули по краям изображения.
- Какая архитектура для этой задачи будет хорошо работать? => пачка слоёв которые отвечают за извлечение признаков. Часто это бутерброд из ZeroPadding => Convolution => MaxPool, за которыми следует бутерброд из Dense и Dropout, которые по этим извлечённым признакам и пытаются ответить на вопрос(в нашем случае это разведён мост или нет).
- На практике, я просто взял сеть с которой работал последние пару месяцев, и упростил, утоньшив бутерброды слоёв описанные выше.
andrrrrr
07.08.2016 19:56замечал несколько раз что онлайн камеры могут не только выключаться, но и смещаться, поворачиваться.
эта сеть находит мост на картинке? или её нужно сразу давать только мост и ничего более?darkk
07.08.2016 20:01более простые алгоритмы будут работать на ура
Ох. Спасибо, я б точно не дождался, если б прогон одного цила обучение-валидация занимал 10 минут на GPU (которого у меня нет). Простым задачам — простые решения. :)
Стоит мне, конечно, посмотреть и по этой теме какой-нибудь курс и книжку и освежить понимание топологий, т.к., кажется, тут что-то сложнее MLP. А не только кроп+параметры подбирать на валидации, сидя в обнимку с бокалом сидра и ноутом на коленке =)
Что-то я промазал тредом и написал ответ вместо комментария. Видать, сидр хороший. :)
ternaus
07.08.2016 21:28+1Исходные картинки обрезались вручную. И в данной задаче это нормально, потому что камера не смещается, не поворачивается. Если бы камера поворачивалась:
Подход 1:
Скармливать сети необрезанные картинки и дать сети разобраться самой к чему => могут быть проблемы со сходимостью и итоговой точностью. (В этой задаче скорее всего проблем не будет, но надо прверять)
Подход 2, двуступенчатый:
- Вручную отметить координаты моста на нескольких картинках.(100+) Для этого есть специальные инстументы, которые этот процесс упрощают.
- Натренировать сеть, которая будет находить мост на картинках (Задача локализации)
- Натренировать вторую сеть, которая будет классифицировать состояние моста по найденным на предыдущем шаге мостам(Задача классификации)
Какой подход выбрать? Надо пробовать оба. Скорее всего первый будет хорошо работать и заморачиваться на двуступенчатую схему не надо. Хотя бывают задачи, где только второй способ будет давать адекватную точность. Пример: классификация китов по фотографиям с вертолёта, где воды на картинке много, кита мало, все фотографии с различных углов и высот, да и киты статично ну позируют. И ко всему прочему фотографий мало.
darkk
07.08.2016 20:10потому что камера не работала
Я в телеграмном боте выкидываю jpeg-и, где нет баннера с камеры (видеопоток развалился). Благо, баннер статичный и определяется тривиальной маской.
Lutece
07.08.2016 20:29И даже действительно применив к задаче нейросети, на вопрос из заголовка вы повторяете шутку из статьи darkk? А ведь вопрос размера сети (количества нейронов) действительно интересный и малоосвещённый.
ternaus
07.08.2016 20:33Про один нейрон — это не шутка. Неросеть с одним нейроном это логистическая регрессия. darkk и использовал логистическую регрессию.
То есть оценка снизу — один.
Оценка сверху — чёрт его знает. Сеть с 10^8 нейронами я для этой задачи создать смогу так что она не будет оверфитить. Наверно можно и больше. Но зачем?
Название я выбрал похожее на название поста darkk чтобы подчеркнуть преемственность.ternaus
07.08.2016 20:54+1Поправка.
Про оценку сверху не то сказал. Обычно, когда говорят про нейронные сети говорят про число весов — потому, что их количество важно в силу того, что именно они являются свободными параметрами, которые надо натренировать. То есть оценка сверху не 10^8 нейронов, что очень много, а 10^8 весов, что тоже очень много, но осязаемо. Так что в если мерить сложность сеть в нейронах — пусть будет: «Я могу для это задачи нарисовать сеть с 10^4 нейронами и которая не будет на этой задаче оверфитить.» (При большем числе она у меня в пямять GPU не влезет.)
Lutece
07.08.2016 21:04Логистическая регрессия не составляла всё решение, поэтому ни вопрос, ни ответ там не мог быть серьёзным. Возможно, и без Canny взвешенной суммы пикселей как-то хватило бы, вот тогда была бы нижняя оценка, но мы этого пока не знаем.
ternaus
07.08.2016 21:10Спасибо. Это я не учёл. На неделе дойдут руки и я проверю как логистическая регрессия будет работать на самих изображениях, без Canny.

Singapura
07.08.2016 20:33А какой язык используется в этих процессах, и в перспективе будет использоваться?
ternaus
07.08.2016 20:41+1И использую python. Есть актуальные библиотеки под R, C++
В перспективе знаю, но пусть будет python, потому что у всех основных библиотек кроме Torch, есть его поддержка.
Но вообще это не очень важно. При работе с нейронными сетями задача не как код под это дело написать, а как задачу поставить, как данные подготовить, какую архитектуру сети и функцию потерь выбрать и как именно тренировать — а это общие задачи, которые от языка хоть и зависят, но не сильно.Singapura
09.08.2016 14:07-1MS к этому, явно готовится к «глобализации» собирая народ в ".NET" и в Windows 10, в связи с этим вопрос: .NET-платформа по возможностям далека от темы «Машинного обучения»?
Singapura
09.08.2016 21:36Сори, я начинающий :) Наслышан про «R» и группу языков ".NET", поэтому любопытствую… Тема мне интересна.
grossws
А почему не рандомизация и разбиение в нужном соотношении? Оно же в таком виде получается смещённое по всякой погоде и т. п.
NotDead
Арр не могу найти статью, к сожалению, недавно читал. есть гибрид OLED и квантовых точек без ЖК слоя, там органику люминесцирующую, заменили на кремниевую, устранив главную точку деградации OLED.
ternaus
То, что accuracy на train ниже чем на validation — это следствие использования dropout для регуляризации.
ternaus
darkk
Частично как раз интересность в том, что освещение постоянно меняется (и будет меняться как минимум до 22 декабря), поэтому может быть плохо предсказывать "прошлое", обучаясь на данных из "будущего". По крайней мере на простой линейной модели я попадал на эту граблю.
ternaus
Были бы данные и за осень я бы может и по-другому делил. Чисто случайное разделение мне в этой задаче не нравится. Смежные картинки в train/val/test — это плохо и неправильно.
Скорее всего делил бы по дням. Не последовательно, как в посте, а случайным образом.
darkk
Были б данные за осень — я б не просыпался ночью с мыслью о том, не надо ли online-дообучение доделать к роботу :-)
К сожалению, архивы живут на железках, к которым камеры подключены непосредственно, и канал там довольно слабый — поэтому архивных данных мне не доступно. По сети их не вытянуть, и с HDD не дойти.
Но, кажется, это лучшее, что доступно.