 В комментариях к публикации Почему Go превосходит посредственность, один из хабраюзеров предложил в качестве примера написать алгоритм поиска по списку недействительных паспортов.
В комментариях к публикации Почему Go превосходит посредственность, один из хабраюзеров предложил в качестве примера написать алгоритм поиска по списку недействительных паспортов.Одним из условий задачи было — не использовать для этой цели СУБД. Также решение должно по минимуму использовать память, место на диске и ЦП.
К своему удивлению обнаружил, что большинство комментаторов предлагали всё же использовать СУБД, несмотря на то, что решение, использующее стандартные базы данных будет весьма громоздким (кроме того, что для самих данных нужно использовать минимум 5 байт на запись, так ещё и почти столько же места на индексы).
Имея опыт работы над бинарными базами для Sypex Geo, я решил попробовать набросать формат бинарного файла и алгоритм поиска по нему.
Анализ данных
Первым делом, для того, чтобы создать специальный формат файла нужно проанализировать сами данные.
Исходные данные представляют собой CSV файл, в котором находится список недействительных паспортов (серия и номер, разделены запятой), по заданию нас интересуют только российские паспорта (4 цифры серия и 6 цифр номер).
В bz2 архиве этот список занимает 359 МБ, в распакованном виде 1,13 ГБ. Около 102 млн записей. Я загрузил данные в MySQL (там есть удобная загрузка CSV файла с помощью LOAD DATA), и уже в нём провел анализ данных. Без индексов таблица со следующей структурой завесила на 680 МБ.
CREATE TABLE `pass` (
`seria` SMALLINT(5) UNSIGNED NOT NULL,
`num` MEDIUMINT(8) UNSIGNED NOT NULL
) ENGINE=MyISAM ROW_FORMAT=FIXEDЕсли добавить индекс по столбцу num, занято будет 1,5 ГБ, а если сделать индекс по двум столбцам, то уже будет 1,7 ГБ.
Выяснилось, что:
- Для одной серии может быть до 600 000 номеров.
- В то время, как для одного номера максимум 200 серий.
Отсюда делаем вывод, что искать сразу по номеру более выгодно, так как это сильно сократит дальнейший поиск. Значит, делаем индекс по номеру паспорта.
Создаем свой формат
Наш бинарный файл будет состоять из двух частей, первая часть будет представлять собой индекс, в котором будет постоянное количество элементов, а именно миллион значений от 000 000 до 999 999. Каждый элемент индекса занимает 4 байта и содержит смещение во второй части файла, где расположены списки серий для соответствующего номера. Сами серии хранятся во второй части файла в виде двухбайтовых значений. Количество элементов в списке серий для определенного номера – это разница смещений (Искомый номер) и (Искомый номер + 1).
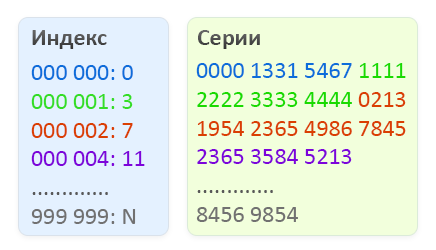
Схематическое отображение структуры бинарного файла для поиска недействительных паспортов.
Чтобы узнать, есть ли паспорт в списке недействительных, нужно произвести следующие простейшие действия.
Для примера возьмем номер 2365 000002.
- По номеру паспорта определяем смещение в индексе, для этого номер умножаем на 4 (размер элемента индекса). 4 * 000002 = 8 байт (красный блок на рисунке)
- Выполняем смещение и читаем 2 элемента индекса (2*4 байт), чтобы знать начало списка серий и конец. Преобразуем их в 2 десятеричных 32-битных числа. В нашем случае получается 7 и 11 (для наглядности отображения, показаны не смещения в байтах, а 1 единица смещения = 1 серия)
- Читаем данные по смещению начала списка серий до конца списка серий искомого номера, помним, что серии записываются 2 байтами.
- Теперь ищем среди двухбайтовых последовательностей нужную нам серию.
- Если нашли – паспорт недействителен, иначе – в базе недействительных не значится.
Поскольку серий для каждого номера не больше 200, можно искать серию простым перебором. Для ускорения процесса можно использовать бинарный поиск, предварительно отсортировав серии. Но о всяких дополнительных оптимизациях, наверное, в другой публикации напишу, если будет интересно.
А теперь тестирование
Для примера набросал пару тестовых скриптиков на PHP. Один для конвертации CSV файла в наш бинарный формат. Второй для поиска нужного паспорта. Архив со скриптами можно скачать здесь.
Также сравним полученное решение с вариантом, в котором данные в MySQL. Данные хранятся на SSD (в случае с хранением на HDD показатели будут хуже), кроме того на сервере достаточно памяти чтобы кэшировать все таблицы в памяти, т.е. самый оптимальный для MySQL вариант.
Тестирование проводилось на любимой тестовой площадке — Vultr. Любимая потому, что можно быстро поднять мощную VPS-ку с почасовой оплатой и хранение снапшотов бесплатное (т.е. можно удалять, а потом, когда нужно быстро восстанавливать тестовое окружение).
Для VPS выбран план 6 CPU, 8 ГБ, 150 ГБ SSD, MariaDB 10.1.16, PHP 7.0.9.
Итак, к цифрам
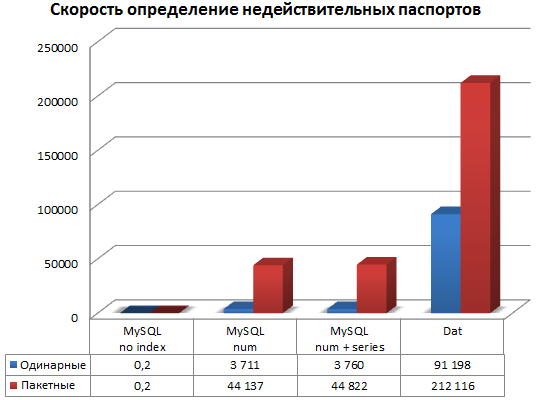
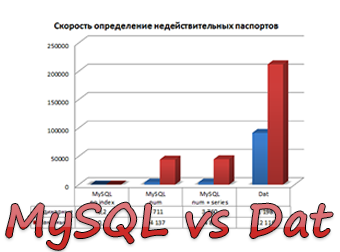
Для каждого типа хранения данных проверили два режима: одинарный режим (когда открытие файла и коннект к БД делается для каждого номера) и пакетный режим (открытие файла и коннект к БД однократные).
| DAT-файл | MySQL без индексов |
MySQL индекс по номерам |
MySQL индекс по номерам и сериям |
|
| Размер БД (включая индекс) | 198 МБ | 680 МБ | 1,5 ГБ | 1,7 ГБ |
| Размер индекса | 4 МБ | 0 МБ | 893 МБ | 1,07 ГБ |
| Загрузка CSV в БД (мм: сс) | 3:54* | 0:31 | 3:38 | 3:42 |
| Скорость поиска одинарная (п/сек) | 91 198 | 0,2** | 3 711 | 3 760 |
| Скорость поиска пакетная (п/сек) | 212 116 | 0,2 | 44 137 | 44 822 |
** Для всех методов осуществлялся прогон по 300 тысячам паспортов, кроме MySQL без индекса, так как, там на поиск одного паспорта уходит до 10 секунд.
Выводы
Как видим по результатам тестирования, кастомное решение заточенное под нужную задачу, может работать значительно быстрее, чем СУБД общего назначения, кроме того формат в 7-8 раз компактнее, чем таблица в MySQL.
А сам скрипт для поиска по файлу занимает меньше 10 строк (без комментов).
$pass = '0307,000000'; // Искомый паспорт
$fn = fopen('passports.dat', 'rb');
// Осуществляем поиск
// Конвертируем серию в 2-байтовый формат, лучше это сделать один раз, чем конвертировать списки серий
$seria = pack('n', substr($pass, 0, 4));
$num = substr($pass, 5);
// Смещаемся к искомому номеру в индексе
fseek($fn, $num * 4);
// Читаем по 2 смещения по 4 байта
$seek = unpack('Nbegin/Nend', fread($fn, 8));
// Читаем серии по найденным смещениям
fseek($fn, $seek['begin']);
$series = fread($fn, $seek['end'] - $seek['begin']);
// Поиск в списке серий
echo ($pos = strpos($series, $seria)) !== false && $pos % 2 == 0 ? 'INVALID' : 'VALID';P.S. скрипт естественно максимально упрощен, и предназначен для учебных целей, а не для продакшена (но это касается не столько алгоритма, сколько обработки ошибок).
Приветствуется переводы на другие языки программирования, можно будет померяться :)
Комментарии (48)

youlose
11.08.2016 10:10+1Предлагаю файлик bench.php из архива посмотреть, там автор на каждый запрос делает соединение к базе данных =)
Даже не знаю как это можно прокомментировать… 30+ лет вроде бы автору…youlose
11.08.2016 10:18Хмммм, невнимательно прочитал статью, но «пакетного» поиска в том файле нет.
Там в статье на которую вы ссылаетесь (надо было дать статью на ветку обсуждений) файлик в 1Gb, говорят. Если БД сможет его прожевать, то даже с переподключением будет быстрее работать, чем перечитывание этого файла для каждого запроса поиска. Что именно вы хотели доказать?
zapimir
11.08.2016 15:32-1Что-то у вас плохо с внимательностью. У меня БД была с кучей памяти, она могла всё включая данные и индексы положить в память, но тут чисто алгоритмически мой вариант на порядок проще. Мне в индексе вообще не нужен поиск, так как я сразу по номеру определяю смещение, а MySQL нужно сначала найти нужный элемент индекса (да он не перебором всего индекса делается, но это существенно медленнее, чем сделать один fseek). Да банально сравните размер индекса в моем варианте 4 МБ и у MySQL 900 МБ.
Если бы еще на Си тестил, то разница скорее всего еще больше была.youlose
11.08.2016 16:07Да, я теперь внимательно прочитал + перечитал ветку первоначальную. Я почему-то решил что вы загружаете файл и делаете индекс на лету каждый раз, а вы сгенерировали более простой индекс и манипулируете только им. И я наконец понял суть того что вы хотели донести своим примером.
vilgeforce
11.08.2016 10:42+1Осталось подождать пока тот же кодес перепишут на С и посмотреть на производительность…
zapimir
11.08.2016 15:32-1Ну на Go тоже было бы интересно.
vilgeforce
11.08.2016 15:33Думаю, вылизанный кодес на сях уделает всех :-)
zapimir
11.08.2016 15:35Скорее всего, но интересна разница. Хотя в данном случае, думаю будет сильно упираться в файловую систему, и от языка меньше зависеть.

Fesor
12.08.2016 00:26Я бы хотел с Rust разницу глянуть. По идее там разница будет не такой значительной.

mafia8
14.08.2016 23:28Также на ассемблере, алгоритм оптимизировать с учётом особенностей работы с накопителями разных типов (диски, ssd).
vilgeforce
15.08.2016 00:28Ну было бы интересно посмотреть на асмовый кодес оптимизированный под SSD, да еще и уделывающий сишный…
m0xf
11.08.2016 11:29В чём смысл разделения на серию\номер? Можно хранить как одно число, это позволит немного упростить код.
zapimir
11.08.2016 15:34Смысл в компактности, по отдельности они занимают 5 байт, в виде одного числа 8 байт (просто 5 байтных чисел нет, ни в одной базе, ни в языках программирования). Да и повторяющихся серий значительно больше, чем повторяющихся номеров.

yuris5
11.08.2016 12:53+1Если уж сказали в заголовке про «бинарное», то и задачу следовало бы решать на уровне битов.
То есть, создаем битовое поле с размерностью [9999 999999] бит, в котором у недействительных паспортов биты инверсные.
При практической реализации для такого поля применимо прозрачное сжатие данных.
На а поиск сводится к поиску бита в данном поле.zapimir
12.08.2016 06:27Не путайте бинарный (двоичный) файл и битовую карту. По сути бинарный файл, это не текстовый файл, данные в который записываются в определенном формате.
Битовая карта для всех вариантов паспортов не очень подходит из-за размеров, она будет размером почти в 1,2 ГБ. Да можно сжать, но это замедляет работу.
D_T
11.08.2016 15:03Упаковал в такую структуру: каждая серия в виде биткарты (125 кб), при сохранении пакуется deflate
Файл:
1. Индекс серий, т.е. 10000 смещений где какая серия начинается
2. Сами биткарты.
Размер файла получился 25 Мб
Соответственно проверка — извлекаем биткарту нужной серии, распаковываем и проверяем бит соответствующий номеру.
Можно не паковать, тогда скорость проверки будет максимальна (два чтения) но размер 125 кб * кол-во серий, Сколько серий упоминается точно не помню, вроде ~5000, если так, то 625 Мб. Архиватором наверно пожмется до тех же 25 Мб
Если места на диске не жалко, то можно сразу занять 1,25 Гб (одна большая биткарта под все номера) и проверка будет в одно чтение одного байта.

yusman
11.08.2016 15:40+1Статья хоть и интересная, но ее можно было бы назвать «Сравнение велосипеда и автомобиля.» Смотрите, велосипед не надо заправлять и он может ехать быстрее чем машина по лесу!
Но велосипед и авто решают разные задачи.
В любом случае велосипед не даст вам конкурентного доступа, масштабирования и т.д., изменения данных без блокировок и много много другого.
Считаю, что такое сравнение хоть и интересное, но не корректное. Делать категоричные вывод точно не стоит.zapimir
11.08.2016 17:41Вообще, статья о том, что гвозди можно и микроскопом забивать, но можно и более узкоспециализированным инструментом.
А в чем проблема с конкурентным доступом к файлу только на чтение, который обновляется в лучшем случае раз в день? Зачем в данном случае изменять данные без блокировок? Сгенерил новую базу, перевел симлинк на новый файл, или вы предлагаете еще искать изменения в CSV файле, чтобы добавить в MySQL только их? Кроме того базы заливались с помощью LOAD DATA в пустую таблицу, добавление данных с помощью INSERT будет заметно медленнее.
Кроме того, вы забываете, что MySQL был в идеальных условиях, на мощном тестовом сервере с кучей оперативки, и никаких обращений к нему кроме тестовых, а что будет когда таблицы будут вываливаться из кэша?

el777
11.08.2016 16:51Очень хорошо начали с анализа данных и построения индекса по сериям вручную. Но закончили чтением километровой строки и поиском в ней данных. Вроде бы да — до 200 серий на один номер, поэтому не так страшно. Но можно еще улучшить. Серия — это число от 0000 до 9999, можно сделать один массив размером в 10000 / 8 = 1250 байт. Каждый бит в массиве соответствует своей серии. Проверка паспорта — проверка бита.
Этот массив будет очень сильно разреженным. Его хорошо сожмет zlib. Такие сжатые куски и держать в файле на диске. При чтении нужно будет считать очень мало данных и быстро на лету разжать.
Если не связываться с битовыми картами. То записываем все серии в виде 16-битных чисел, сортируем и с помощью деления пополам (bisect) очень быстро за логарифмическое время находим нужное. Можно использоват стандартный модуль, можно даже руками сделать: проверили первое число на вхождение, проверили последнее, затем прыжок в середину массива, опять смотрим больше-меньше и прыжок в нужную часть.zapimir
11.08.2016 17:44Да можно, и это планировалось во второй статье «оптимизация». Тут хотелось показать, что даже такой примитивный код — работает очень быстро. Если я начну сразу писать про бинарный поиск или битовые карты, то это усложнит статью для новичков.
el777
11.08.2016 19:25Вот тут немного странное место:
// Поиск в списке серий echo ($pos = strpos($series, $seria)) !== false && $pos % 2 == 0 ? 'INVALID' : 'VALID';
Представьте, что вы ищете серию 1234, и в списке серий есть такие:
0012 3400 1234
Если я верно помню php, то будет найдено первое вхождение подстроки 1234, но поскольку оно не на границе, то паспорт будет считаться валидным, а следующее вхождение серии проверено не будет.zapimir
11.08.2016 22:36Там выручает, то что первый байт не полностью заполняется и таких коллизий не встречается. Но это упрощенное место, в следующей части буду про оптимизации писать, там будет бинарный поиск.
kotenkovandrey
11.08.2016 23:43Взбрела мне глупая мысль в голову.
А что если использовать номер паспорта и серию как индекс байта в файле, и проверять байт по индексу 1 или 0
9999999999 / 8 / 1024 / 1024 / 1024 = 1.164 гигабайта — размер файла для всех возможных паспортов.
А если возвращаться к Вашему примеру, то файл можно делать только для действительных паспортов. размер файла в байтах равен серии и номеру последнего. Если в запросе серия и номер больше файла, то паспорт недействителен. Ну а если меньше, то номер и серию делим на 8, получаем индекс байта и читаем из файла, позицию бита получаем из остатка от деления. Значение бита и будет действителен ли паспорт или нет.zapimir
12.08.2016 00:19Ну да, тут основная проблема, что возможных паспортов на 2 порядка больше, чем недействительных, плюс сильно неравномерное распределение, Есть серии для которых около 600 тысяч номеров, почти половина серий, для которых меньше 100 номеров. Всего серий используется 3043.

f1inx
12.08.2016 15:37Именно так и надо решать эту задачу.
Для экономии места можно кластеризовать файл с битовой маской присутствия. Хотя в нормальных OS итак поддерживаются sparse файлы и реальный занимаемый объем на FS будет значительно меньше.
Если сделать mmap на этот 1.164GiB файлик или считать его в память то скорость проверки будет на порядки большей чем любое другое решение.

caballero
12.08.2016 12:08С академической точки зрения — интересно и полезно для обучения навыков програмирования.
С практической, учитывая нынешнюю копеечную стоимость железа (если сравнивать со стоимостью оплаты разработчика), извиняюсь за тавтологию — непрактично.
Кроме того на практике файл еще и обновлять часто бы пришлось — новые номера, ликвидированные старые и т.д.

DjPhoeniX
13.08.2016 15:41А как вы обошли проблему с буквенными сериями? Там зоопарк того, что не кодируется в 2 байта (и вообще в число) — «06ОД», «23АГ», «8ЕР5», «X-АН»…
Мало того, ещё и формат записи разный — встречаются и «6-ОД» и «06ОД».zapimir
14.08.2016 23:32Никак, в первоначальной задаче, речь о паспортах вида 4 + 6 цифр, поэтому не заморачивался. Но если понадобится, можно такие серии особым образом кодировать, а в начале списка серий, указывать количество двухбайтовых серий и остальных.
safinaskar
17.08.2016 17:04+2Ааааа! Я придумал, как находить бесплатную рабочую силу для решения разнообразных задач. Допустим, нужно научиться быстро проверять действительность паспорта. Ну или что-нибудь ещё. Пишем, скажем, плохое решение на некоем языке X (ну или вообще ничего не пишем). Затем вклиниваемся в холивар «X vs Y» и говорим там: «Есть такая-то задача, нужно минимизировать CPU, базы данных использовать нельзя, я написал на X, получилось плохо. А если бы написал на Y, получилось бы лучше. Значит, X сосёт». Можно придумать другие варианты. В результате начинается срач, люди начинают сами бесплатно выкладывать свои решения на разных языках, ещё стараются друг друга переплюнуть, строго соблюдают поставленные условия («никаких БД»), считают такты и пр. Каждый стремится доказать превосходство своего языка. В результате мы получаем много хороших решений на разных языках и остаётся только выбрать :)
Пинг chemistmail :)zapimir
18.08.2016 23:22Вы не поверите, но есть люди которые программируют for fun, а не только кодят «за еду» :) Кто-то разгадывает кроссворды или играется в онлайн игрушки, кто-то пишет небольшие программки на интересную ему тему.

chemistmail
18.08.2016 21:44Да ладно, прочитал по диагонали. Алгоритм так и не увидел.
Могу другую задачку подкинуть, повеселее.
chemistmail
18.08.2016 21:54Есть SET размер, Word32 * 255 (1095216660225), по сути битовый массив
Нужно:
1) его хранить, и место имеет очень большое значение
2) функция set :: i -> SET -> SET, 90% операций
3) функция get :: i -> SET -> Bool
4) функция size :: SET -> n, сколько всего записей в этом set
5) AND, OR, в общем полный спектр логических операций :: OP -> SET -> SET -> SET
6) конвертация в список, или в массив :: SET -> [i]
7) создание из списка :: [i] -> SET
А паспорта уже не интересны.
hdfan2
А зачем вся эта свистопляска с номерами и сериями? Просто собрать из них 10-значный номер, по ним индексировать и искать.
yusman
И не забыть сделать реверсивный индекс — будет работать быстрее.
boodda
По-моему можно просто сделать 1 колонку с 10-значным номером PRIMARY KEY без индексов
yusman
При создании PK всегда создается индекс, происходит это не явно.
С номерами паспортов проблема в том, левая часть последовательности чисел меняется реже чем правая(как с номерами телефонов +7915 и т.д. ), что приводит к несбалансированности бинарного дерева индекса. В таких случаях идеально использовать реверсивный индекс.
zapimir
Ради интереса сделал таблицу с одной колонкой с 10-значным номером и PRIMARY KEY, в итоге таблица получилась 2,4 ГБ.
zapimir
Ну просто сделать, что оно работало конечно можно, только места это занимать будет ещё больше. А работать еще и медленее
Для 10-значного номера вы какой тип данных предлагаете BigInt? Т.е. 8 байт, вместо 5 байт. Также в индексе будут 8 байтные значение вместо 3 байтных.