
Современные маршрутизаторы обрабатывают по несколько миллионов пакетов в секунду, работают с несколькими FV таблицами маршрутизации, позволяют реализовать огромное количество сервисов. Различные вендоры используют разный подход к построению оборудования. В данной статье не будет огромного количества выводов. Сегодня поговорим об архитектуре оборудования Juniper.
Маршрутизаторы можно разделить на два больших класса — маршрутизаторы, в которых в форвардинге пакетов участвует CPU -то есть имеют software-based архитектуру (например Cisco 7200) и маршрутизаторы, в которых форвардинг пакетов производится аппаратно (на ASIC или FPGA) без непосредственного участия CPU — hardware-based (например Cisco 65/76). У каждого из данного классов оборудования есть свои плюсы и минусы. Софтварные маршрутизаторы естественно очень дешевые, например флагман Миктотик ccr1072-1g-8s стоит чуть более 200 тысяч рублей а имеет заявленную вендором производительность выше чем у Juniper MX80, который стоит порядка 1М рублей. К тому же в таких роутерах проще реализовать различный функционал добавлением той или иной функции в новую версию софта. Но как говорится в бочке меда есть и ложка дегтя — софтварные решения не могут похвастаться высокой производительностью (для примера можно сравнить 72 и 76 Циски).
Тот же вышеупомянутый Микротик при навешивании на его интерфейсы порядка 25 фильтров теряет в производительности почти в 20 раз (кому интересно, можно посмотреть тут), в то время как тот же MX80 реализует выполнение фильтров аппаратно, что позволяет ему не терять в производительности. Еще одним жирным минусом софтоварных решений является то, что CPU обрабатывает и control plane и участвует в обработке data plane одновременно. Если, к примеру, загрузка процессора в следствии высокой утилизации интерфейсов поднимется до критического значения (у разных моделей по разному — для кого то 80 процентов норма, кто то при 35 уже захлебывается — свичи Nokia при загрузке 33-35 процентов по 2-3 секунды думают после введения команды или нажатия на tab), то control plane может начать рассыпаться.
Маршрутизаторы Juniper относятся к hardware-based решениям. Помимо вышесказанного, маршрутизаторы Juniper имеют раздельный control и data plane, о чем мы поговорим чуть позже.
Немного поговорим о софте: JunOS OS
JunOS OS — это FreeBSD, которую переработали инженеры Juniper. JunOS, в отличии от IOS (не IOS XR) имеет модульную архитектуру — состоит из ядра и процессов, которые отвечают только за свою отдельную функцию. Под каждый процесс выделяется часть памяти. Что это нам дает? Если у нас ломается какой то из процессов, предположим процесс, отвечающий за vrrp, то он не тянет за собой все остальные процессы и тот же rpd или ppmd процессы будут работать. Естественно для отказоустойчивого оборудования это огромный плюс.
Примечание: Если посмотреть на тот же IOS XR, то он, в отличии от первоначальной IOS, тоже построен по модульной схеме.
Итак, одним из самых важных элементов JunOS OS является ядро, как и у FreeBSD оно монолитное. Плюсы и минусы монолитного ядра мы рассматривать здесь не будем, если кому интересно то можно почитать например на википедии. Ядро выполняет базовые функции ОС — управление процессами и взаимодействие между ними, за разделение доступа процессов к памяти, процессору и другим ресурсам RE. За остальные функции — управление оборудованием, маршрутизацию, мониторинг состояния железа и т.д. отвечают специальные процессы (daemons), которые стартуют при загрузке системы.
Если какой-то из процессов при загрузке не может запуститься по каким либо причинам, то он будет перезапущен. Если перезапуск не приведет к положительному результату, то информация о проблеме с данным процессом будет сгенерирована в лог для того, что бы инженеры могли разобраться с причиной возникновения проблемы и пофиксить ее.
В JunOS OS очень много различных процессов, поэтому мы разберем самые важные из них:
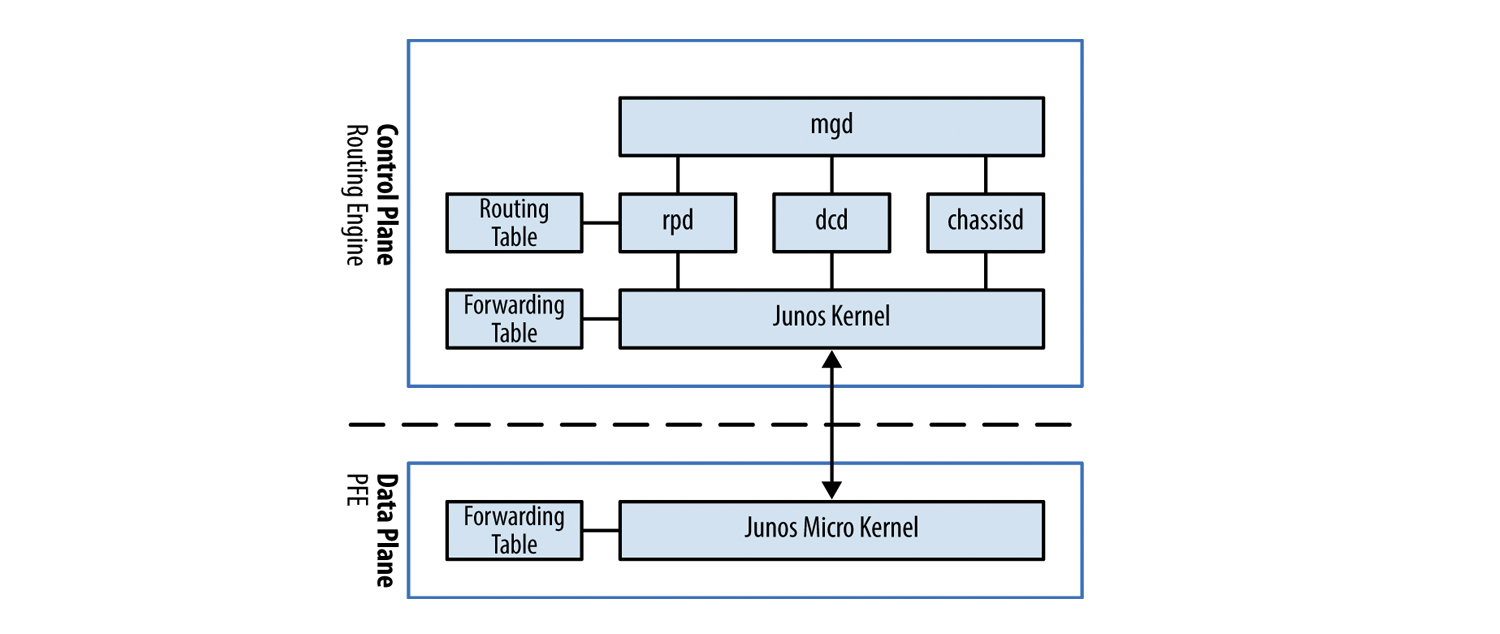
mgd — management daemon. Данный процесс отвечает за управление оборудованием и другими процессами, CLI является его клиентом. Именно благодаря mgd мы можем пользоваться такими функциями, как rollback, private conguration mode, выводить часть конфигурации в inacive или применять apply-группы.
dсd — Device control daemon. Данный процесс отвечает за конфигурацию интерфейсов. Именно он позволяет нам сконфигурировать несуществующий интерфейс. Данный демон передаст в routing socket информацию о сконфигурированном интерфейсе, что бы rpd впоследствии смог добавить маршрут в таблицу маршрутизации.
К примеру когда мы вводим команду:
set interfaces xe-0/0/0 unit 0 family inet address 10.0.0.1/30
то dcd передает в routing socket значения IFD, IFL, IFF и IFA, маску сети, бродкатный адрес.
IFD — interface device — физический порт на маршрутизаторе (xe-0/0/0);
IFL — interface logical — номер логического интерфейса (unit 0);
IFF — interface family — семейство адресов (family inet);
IFA — interface address — сам адрес (10.0.0.1).

chassisd — chassis daemon. Один из самых важных процессов в JunOS. Именно он отвечает за мониторинг состояния всех компонентов маршрутизатора (от напряжения на различных узлах маршрутизатора до скорости вращения вентиляторов). В случае каких либо проблем данный демон отключит плату или/и маршрутизатор во избежании поломки или передаст информацию о проблеме alarmd/craftd демонам, а они в свою очередь, сгенерируют сообщения в лог и включат какой либо индикатор craft-панеле маршрутизатора.
rpd — routing protocol daemon. Данный процесс отвечает за все протоколы маршрутизации, от rip до bgp. Он отвечает за поддержание соседства между устройствами и обмен между ними маршрутной информацией, выбор лучшего маршрута, составление таблиц маршрутизации и таблицы форвардинга, которая используется непосредственно для продвижения пакетов.
Примечание: у rpd есть помощник ppmd, процесс, который отвечает за генерацию и прием периодических сообщений — например протокола BFD. К нему мы вернемся в следующей статье, когда будем говорить об отказоустойчивости оборудования Juniper.
Другие процессы мы рассматривать не будем, если интересно, то список всех процессов с кратким описанием JunOS представлен тут. Естественно описания процессов на английском языке.
Теперь рассмотрим из чего же состоит маршрутизатор Juniper (рассматривать будем на примере MX серии):
И так, маршрутизаторы Juniper состоят из нескольких основных частей:
— RE (routing engine)
— PFE (packet forwarding engine)
— SCB (Switch and Control Board)
— Midplane

Естественно, маршрутизатор не сможет работать без блока вентиляторов или например блоков питания. Но данные части выполняют строго определенную функцию и не являются интеллектуальными устройствами.
Рассмотрим назначение и состав каждого элемента отдельно.
Routing Engine
RE — является мозгом маршрутизатора. Он отвечает за работу протоколов маршрутизации (поддержание соседства, обмен маршрутной информацией, выбор лучшего маршрута и т.д.); за управление маршрутизатором; за сбор и хранение статистики по интерфейсам, сбор логов и хранение необходимых фалов.
Спецификации RE можно посмотреть на сайте Juniper.
В JunOS очень мощным инструментом является политики, но так как в подавляющем большинстве случаев политики связаны с протоколами маршрутизации — что принимаем, что анонсируем — то и исполняются они на RE. Так же RE обрабатывает пакеты, обработку которых нельзя (либо очень сложно) реализовать в железе — это IP пакеты с опциями, mpls фреймы с меткой 1, ICMP запросы к маршрутизатору, управление по telnet или ssh.
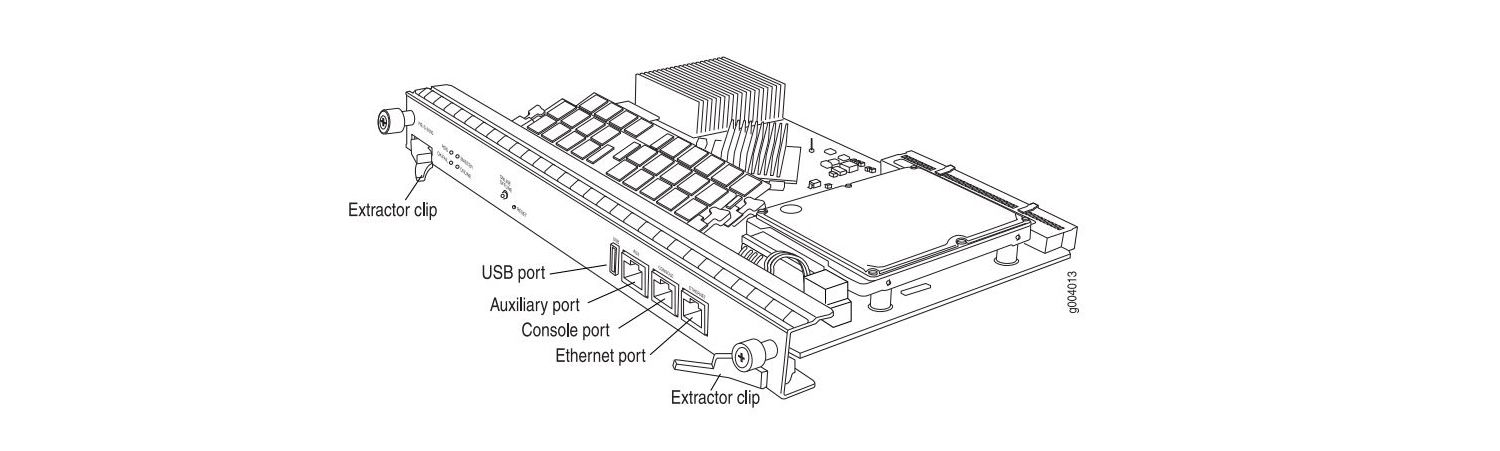
По сути RE является полноценным сервером, который имеет CPU, RAM, HDD/SSD, Ethernet port, USB port и т. д. Зачем нужен CPU и RAM я думаю пояснять не надо, назначение остальных компонентов необходимо пояснить:
Routing Engine 0 REV 06 740-031116 9009103533 RE-S-1800x4
ad0 3831 MB UGB30SFA4000T1 SFA4000T1 0000079B Compact Flash
ad1 30533 MB UGB94ARF32H0S3-KC UNIGEN-478612-001183 Disk 1
usb0 (addr 1) EHCI root hub 0 Intel uhub0
usb0 (addr 2) product 0x0020 32 vendor 0x8087 uhub1
DIMM 0 SGX55N72N2SS2SA-BB DIE REV-52 PCB REV-54 MFR ID-ce80
DIMM 0 SGX55N72N2SS2SA-BB DIE REV-52 PCB REV-54 MFR ID-ce80
DIMM 0 SGX55N72N2SS2SA-BB DIE REV-52 PCB REV-54 MFR ID-ce80
DIMM 0 SGX55N72N2SS2SA-BB DIE REV-52 PCB REV-54 MFR ID-ce80CF card — карта памяти. Данная карта предназначена для хранения актуальной конфигурации и используемой версии JunOS OS.
ad0 3831 MB UGB30SFA4000T1 SFA4000T1 0000079B Compact FlashHDD/SSD — жесткий или твердотельный накопитель. Данный носитель предназначен для хранения логов и файлов.
ad1 30533 MB UGB94ARF32H0S3-KC UNIGEN-478612-001183 Disk 1USB-port. Данный порт предназначен для подключения внешнего носителя, используется например для загрузки и восстановлении системы. Порядок загрузки JunOS имеет следующий вид: сначала CF-card, далее HDD/SSD и в последнюю очередь USB-flash disk. На некоторых RE есть два USB порта, к примеру на RE MX104.
Ethernet-port. Назначение это порта — управление маршрутизатором. Как правило на RE не один, а целых три порта:
— ethernet
— console
— AUX
Ethernet — порт используется для управления оборудованием (out-of-band management). Данный порт помечается в системе как fxp0.
Если воспользоваться командой show interfaces terse, то помимо интерфейса fxp0, можно увидеть и интерфейсы em0 и em1. Эти интерфейсы предназначены для связи RE с остальными элементами маршрутизатора (сервисные карты, линейные карты).
{master}
bormoglotx@test-mx480> show interfaces terse | match em
Interface Admin Link Proto Local Remote
demux0 up up
em0 up up
em0.0 up up inet 10.0.0.4/8
em1 up up
em1.0 up up inet 10.0.0.4/8 Интерфейс fxp0 не всегда используется — как видите на тестовом маршрутизаторе fxp0 интерфейс в down, так как в данный порт не подключен патчкорд, о чем свидетельствует предупреждение:
{master}
bormoglotx@test-mx480> show interfaces terse | match fxp
fxp0 up down
{master}
bormoglotx@test-mx480> show chassis alarms
2 alarms currently active
Alarm time Class Description
2011-01-14 12:32:38 MSK Major Host 0 fxp0 : Ethernet Link Down
2011-01-14 12:32:38 MSK Major Host 1 fxp0 : Ethernet Link DownConsole — порт предназначен для консольного доступа.
Auxulary — вспомогательный порт. По сути является подобием console порта, но имеет существенное отличие: если вы подключитесь к маршрутизатору в консольный порт во время загрузки, то увидите лог загрузки JunOS OS. Auxulary порт в момент загрузки ОС не доступен, доступ к оборудованию вы получите только после загрузки маршрутизатора. К тому же с помощью данного порта можно подключиться к другому устройству в консольный порт.
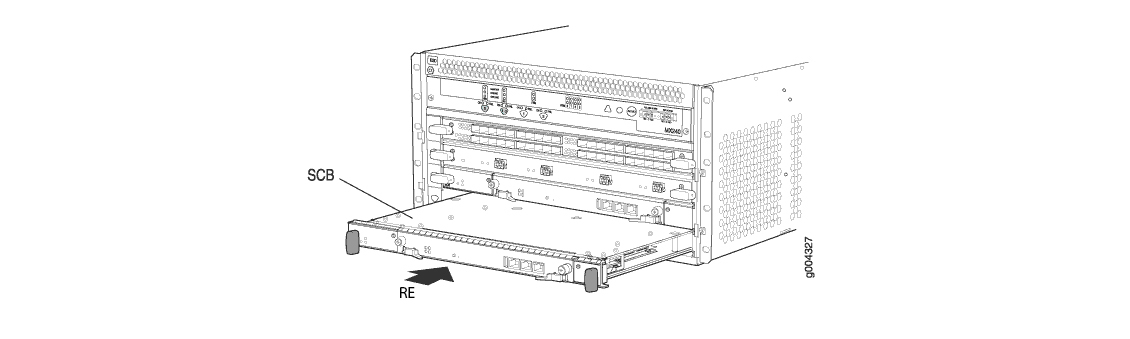
На маршрутизатора серии MX (за исключением младшей линейки MX5-MX80), RE устанавливается в фабрику коммутации (SCB — о ней будет ниже). Как правило для высокой отказоустойчивости RE устанавливают по два — одни мастер, второй бекап (как это работает будет описано в следующей статье). Если RE в данный момент является мастером, то он не поддерживает горячую замену (точнее сказать вы можете его вытащить и вставить “на живую”, но если у вас не настроен GRES/GR или GRES/NSR — вы получите потерю трафика). А вот бекапный RE поддерживает горячую замену.
В процессе работы вы можете перейти с мастер RE на бекапный. Хранящиеся на жестком диске файлы между RE не синхронизируются и при удалении или добавлении файла на жесткий диск одного RE, вы не удаляете или не добавляете файл на второй RE. Это стоит учитывать например при обновлении софта (может быть что на одном из RE места нет, когда на втором его полно и т. д.).
Packet Forwarding Engine
Если RE является мозгом маршрутизатора, то PFE руками и ногами. Именно через PFE обрабатывает весь трафик, включая и трафик управления (если управление производится не через console или management порт на самом RE). PFE состоит из программируемых чипов, которые позволяют производить аппаратано:
— поиск next-hop;
— выполнять ip/mpls/mac lookup;
— применять QoS;
— применять полисеры;
— применять фильтрацию;
— тyннелирование.
PFE установлен на интерфейсной карте. Есть платы с 1-м, 2-мя или 4-мя PFE, каждый PFE обслуживает только свою группу интерфейсов и взаимодействует с другими PFE через SCB. В составе интерфейсной карты есть CPU, который управляет всеми PFE. Связь между PFE и RE производится через встроенный в плату SCB гигабитный свич.
Примечание: все интерфейсные карты поддерживают горячую замену.
Мы рассмотрим состав PFE на примере Trio чипсета. Логически чипсет состоит из нескольких блоков:

Memory and Buffering block — данный блок обеспечивает взаимодействие между всеми другими блоками. В обычных платах (без индекса Q) выполняет и функции блока очередей (естественно в более урезанно варианте), а в платах с большой емкостью выполняет функцию блока интерфейсов.
Lookup block — многоядерный чип, который выполняет ip или mpls lookup, производит изменение заголовков пакета, применение фильтров, шейперов, QoS. Именно данный блок является сердцем PFE. Блок работает с заголовками пакетов и может анализировать заголовки размером до 256 байт (что позволяет реализовать различные сервисы, типа защиты от DDOS).
Interface block – данный блок присутствует на платах с малой пропускной способностью и выполняет функцию предварительной классификации входящих пакетов. Если данный блок отсутствует, то эту функцию выполняет блок буферизации.
Dense Queuing block – блок расширенных очередей. Представлен на платах с индексом Q и позволяет реализовать H-QoS. При отсутствии данного блока его функции(естественно в урезанном формате) ложатся на блок буферизации.
Аппаратно данные блоки представлены следующими чипами:
Buffering – MQ (Memory and Quering) или XM (расширенная версия данного чипа)
Lookup block – LU (Lookup Unit) или XL (расширенная версия)
Interface block - IX
Quereing – QX или XQ (расширенная версия)
Блоки связаны между собой HSL2 линками, что позволяет им быстро обмениваться данными.
На рынке существует большой выбор линейных карт MPC, от MPC1 до MPC9E.
Полный список всех линейных карт представлен на сайте Juniper. Версии отличаются количеством установленных PFE (MPC1 — 1 PFE, MPC2 — 2 PFE, MPC3E — 1 PFE но расширенной версии). Сами же PFE, установленные в данные платы отличаются по версиям установленных чипов (стандартный или расширенный) и количеством установленных чипов (например карта MPC4E использует два PFE, в котором установлено по 4 LU блока). Конечно, помимо улучшения установленных чипов и их количества, изменяется и количество памяти SRAM/DRAM, иначе пакеты просто некуда будет буферизировать. Максимальное количество PFE на одной плате 4, всего может быть 1, 2 или 4 PFE в составе одной линенйной карты.
Switch and Control Board
Но пропускная способность маршрутизатора в целом зависит не только от PFE, еще одним важным звеном является SCB. Иногда именно эта плата может стать узким местом. Данная плата отвечает за коммутацию пакетов между различными PFE и связность между RE и PFE. Ко всему прочему RE устанавливается в SCB. Если данная плата не содержит мастер RE, то она поддерживает горячую замену (потерю трафика можно получить, если карты работают в режиме без резервирования 3+0).
В составе SCB есть три главных компонента: две фабрики коммутации и встроенный гигабитный свич. Поговорим о каждом по отдельности.
Встроенный гигабитный свичпредназначен для организации связи между всеми элементами маршрутизатора. У каждой платы в составе MX-маршрутизатора есть два гигабитных внутренних интерфейса (в выводе выше были представлены два em интерфейса на RE), которыми они подключаются к двум свичам (один на основной, второй на резервный SCB). Именно через этот интерфейс происходит передача информации между RE и PFE (и между RE). Если PFE принимает пакет, который должен быть обработан в RE, то именно через этот гигабитный линк пакет передается в RE, через него же происходит передача например forwarding table от RE к PFE или обратная передача значений счетчиков с интерфейсов от PFE к RE. На SCB есть гигабитный внешний интерфейс, через который можно подключиться к любой из установленных плат.

Из вывода ниже видно, что у нас установлены две линейные карты в слот 0 и 1:
{master}
bormoglotx@test-mx480> show chassis fpc
Temp CPU Utilization (%) Memory Utilization (%)
Slot State (C) Total Interrupt DRAM (MB) Heap Buffer
0 Online 26 10 0 2048 15 16
1 Online 25 14 1 2048 15 24
2 Empty
3 Empty
4 Empty
5 EmptyТеперь если посмотреть на состояние линков встроенного свича, видно, что 0 и 1 линк подключены к линейным картам 0 и 1, а 12 и 13 к RE1 и RE0.
{master}
bormoglotx@test-mx480> show chassis ethernet-switch
Displaying summary for switch 0
Link is good on GE port 0 connected to device: FPC0
Speed is 1000Mb
Duplex is full
Autonegotiate is Enabled
Flow Control TX is Disabled
Flow Control RX is Disabled
Link is good on GE port 1 connected to device: FPC1
Speed is 1000Mb
Duplex is full
Autonegotiate is Enabled
Flow Control TX is Disabled
Flow Control RX is Disabled
Link is down on GE port 2 connected to device: FPC2
Link is down on GE port 3 connected to device: FPC3
Link is down on GE port 4 connected to device: FPC4
Link is down on GE port 5 connected to device: FPC5
Link is down on GE port 6 connected to device: FPC6
Link is down on GE port 7 connected to device: FPC7
Link is down on GE port 8 connected to device: FPC8
Link is down on GE port 9 connected to device: FPC9
Link is down on GE port 10 connected to device: FPC10
Link is down on GE port 11 connected to device: FPC11
Link is good on GE port 12 connected to device: Other RE
Speed is 1000Mb
Duplex is full
Autonegotiate is Enabled
Flow Control TX is Disabled
Flow Control RX is Disabled
Link is good on GE port 13 connected to device: RE-GigE
Speed is 1000Mb
Duplex is full
Autonegotiate is Enabled
Flow Control TX is Disabled
Flow Control RX is Disabled
Link is down on GE port 14 connected to device: Debug-GigEФабрика коммутации (Switch fabric)
Фабрика коммутации предназначена для передачи трафика между PFE. Она соединяет все PFE в full mesh топологию. В настоящее время существует три поколения SCB: SCB, SCBE и SCBE2. Данные платы отличаются по пропускной способности. По данным с сайта производителя SCB поддерживает пропускную способность не менее 120Гбитс на слот, SCBE — 160Гбитс и SCBE2 — 340Гбитс на слот. Данные платы построены на чипе SF(SCB) и XF (SCBE, SCBE2).
Примечание: Хоть SCBE2 и предоставляет нам пропускную способность 340 Гбитс/слот, не стоит забывать о количестве PFE на плате и количество обслуживаемых каждым PFE интерфейсов. Если для примера взять плату MPC4E 8x10GE+2x100GE, то общая пропускная способность данной платы равна 280 Гбит/с. Но так как на ней установлены только два расширенных PFE (пропускная способность 130Гбит/с), то пропускная способность данной платы равна 2x130Гбит/с= 260Гбит/с. Тут важно появляется концепция WAN-групп. Интерфейсы объединяются в группы. На данной плате два встроенных PIC: на одном 8х10GE интерфейсов и на втором на 2x100GE. Для PFE они объединены в WAN группы 0 и 1 (8х10GE — группа 0, 2x100GE — группа 1). Первый PFE обслуживает первые 4GE интерфейса из группы 0 и первый 100GE интерфейс из группы 1. Аналогично и для PFE1. То есть один PFE обслуживает 140Гбит/с, но имеет пропускную способность 130Гбит/с. Итого мы получаем, что все порты, кроме двух 10GE могут работать на скорости интерфейса.
Логически схема подключения PFE к SCB выглядит так:
Для MX960

Для MX240/480
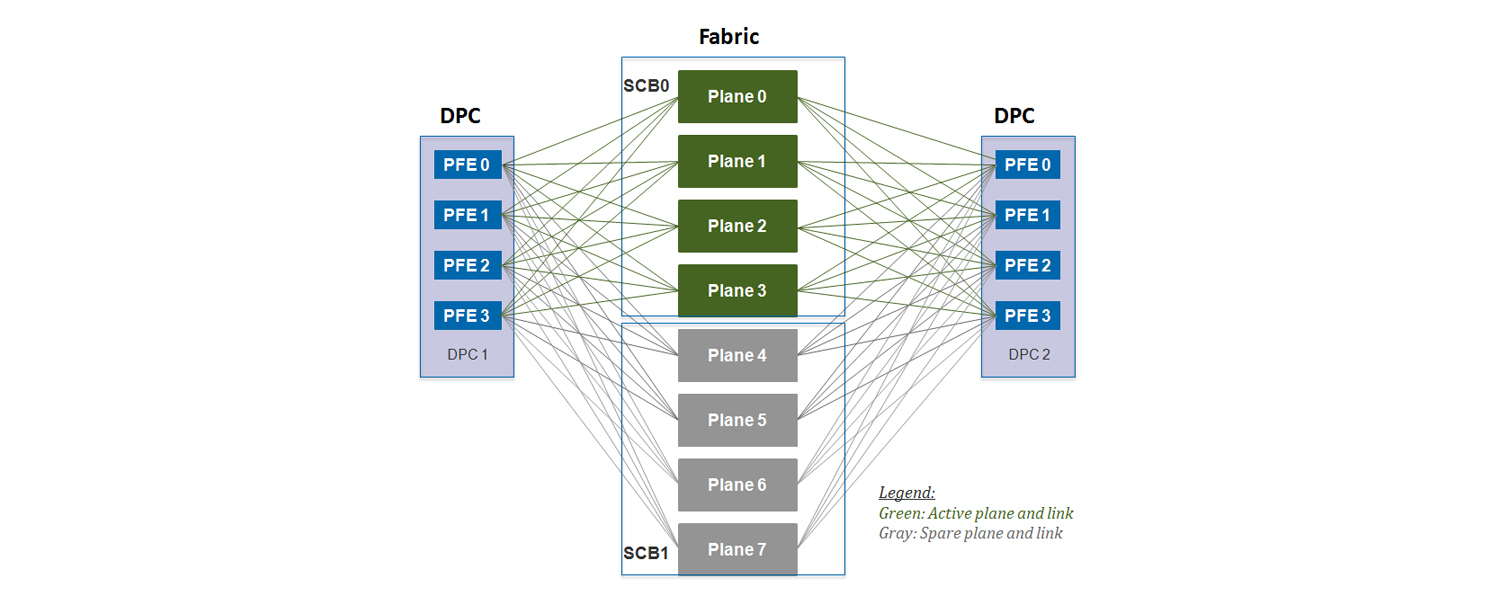
Как видно из рисунков каждая SCB разделена на plane-ы. Что же такое plane? Почему, если SCB вставить в mx480 у нас будет 4 плейна, но если эту же плату вставить в MX960, то у нас будет всего два плейна? Что бы это понять, надо представить фабрику коммутации как коммутатор с N-ым количеством портов. Сколько же портов должно быть? Максимальное количество PFE на карту равно 4-м. Теперь посчитаем сколько портов нужно:

Итак, получается, что максимально возможное количество PFE — 48. Значит одна фабрика коммутации должна иметь 48 портов для создания полносвязной топологии между всем PFE. Выходит, что если мы устанавливаем SCB в MX960, то все 48 интерфейсов задействованы (могу быть задействованы), но если мы вставим плату в MX480, то нам понадобится только 24 порта из 48 — значит 24 порта будут простаивать. (Если взять MX240 — то тут соотношение будет еще больше). Поэтому было введено понятие плейна. Одни плейн — это виртуальный свич, который обеспечивает полносвязную топологию между всеми PFE. Надеюсь, теперь понятно, почему одна фабрика коммутации при установке в MX960 имеет только один плейн, а в MX480/240 уже два. Так как на одной SCB две фабрики коммутации, то получаем, что одна плата обеспечивает 2 плейна для MX960 и 4 плейна на MX480/240. В итоге, с учетом резервирования получаем вот такое количество плейнов:

Как видно из вывода ниже на MX960 мы имеем 6 плейнов:
{master}
bormoglotx@test-mx960> show chassis fabric plane-location
------------Fabric Plane Locations-------------
Plane 0 Control Board 0
Plane 1 Control Board 0
Plane 2 Control Board 1
Plane 3 Control Board 1
Plane 4 Control Board 2
Plane 5 Control Board 2Но только 4-ре плейна в данный момент активны: а 2 плейна с SCB3 предназанчены для повышения отказоустройчивости (2+1)
{master}
bormoglotx@test-mx960> show chassis fabric summary
Plane State Uptime
0 Online 543 days, 13 hours, 34 minutes, 24 seconds
1 Online 543 days, 13 hours, 34 minutes, 23 seconds
2 Online 543 days, 13 hours, 34 minutes, 23 seconds
3 Online 543 days, 13 hours, 34 minutes, 23 seconds
4 Spare 543 days, 13 hours, 34 minutes, 22 seconds
5 Spare 543 days, 13 hours, 34 minutes, 22 seconds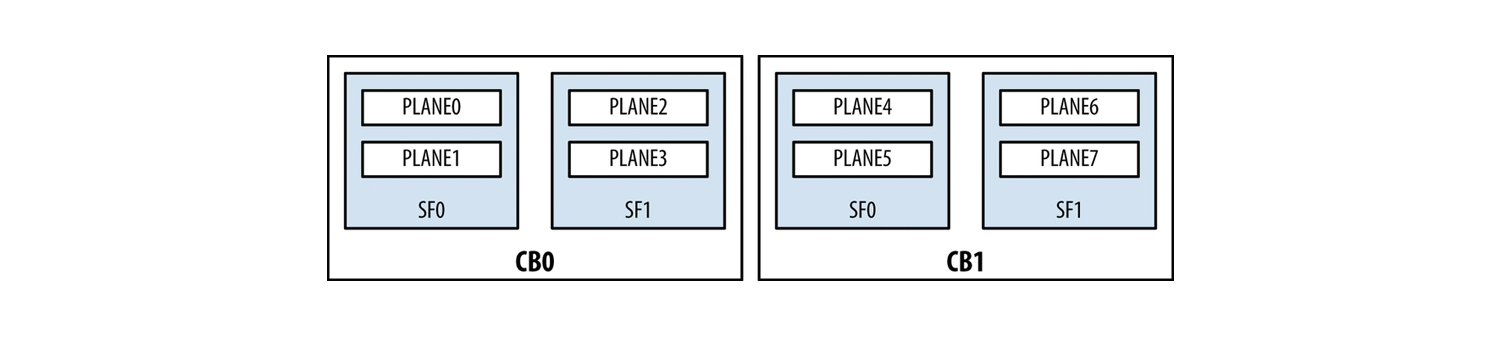
Примечание: может быть что все 6 плейнов будут онлайн, что необходимо, если пропускной способности 2-х SCB не хватает для обслуживания всех установленных карт. Тогда резервирования не будет (3+0).
Для MX480 и MX240 выоды выглядят несколько иначе:
{master}
bormoglotx@test-mx480> show chassis fabric plane-location
------------Fabric Plane Locations-------------
Plane 0 Control Board 0
Plane 1 Control Board 0
Plane 2 Control Board 0
Plane 3 Control Board 0
Plane 4 Control Board 1
Plane 5 Control Board 1
Plane 6 Control Board 1
Plane 7 Control Board 1Мы видим 8 плейнов на 2-х картах. Тут используется резервирование 1+1, поэтому только 4 плейна в онлайн.
{master}
bormoglotx@test-mx480> show chassis fabric summary
Plane State Uptime
0 Online 698 days, 2 hours, 17 minutes, 31 seconds
1 Online 698 days, 2 hours, 17 minutes, 26 seconds
2 Online 698 days, 2 hours, 17 minutes, 26 seconds
3 Online 698 days, 2 hours, 17 minutes, 20 seconds
4 Spare 698 days, 2 hours, 17 minutes, 20 seconds
5 Spare 698 days, 2 hours, 17 minutes, 15 seconds
6 Spare 698 days, 2 hours, 17 minutes, 14 seconds
7 Spare 698 days, 2 hours, 17 minutes, 9 secondsMidplane
Midplane установлен на задней стенке шасси и обеспечивает электрическую связность между всеми платами и подачу питания на каждый элемент маршрутизатора от блоков питания.
MX80
Отдельно хотелось бы сказать о младшей линейке MX5-MX80. В данной линейке представлены 4 маршрутизатора — MX5, MX10, MX40 и MX80. Аппаратно это полностью идентичные маршрутизаторы, то есть начинка у них всех как у MX80, различия только в цвете (они серые на манер MX104) и шильдике. В любой момент, купив лицензию, вы можете превратить MX5 в MX80, так как порты и функции заблокированы программно. Данная практика есть у многих производителей, например так же поступает Cisco с их ASR или Huawei.
Сам же MX80 отличается от своих старших братьев. В силу своей архитектуры он имеет встроенный PFE на базе Trio чипсета (имеет один MQ, один QX и одни LU блок) и встроенный RE. Так как функция SCB теперь свелась бы к созданию линка между RE и PFE, то от него, как от отдельной платы SCB разработчик отказался. Грубо говоря, MX80 — это линейная карта и RE, собранные в двухюнитовый корпус. Естественно данный маршрутизатор не имеет механизмов повышенной отказоустойчивости, но и стоимость его на много ниже, чем у его ближайшего брата MX240.
Хотелось бы добавить, что маршрутизаторы Juniper серии MX не умеют «из коробки» делать например NAT. Для этих целей существует специальные сервисные платы Multiservices DPC (MS-DPC), которые могут вставлять в любой из слотов, предназначенных для линейных карт (есть ограничения по количеству карт на одну коробку). MS-DPC могут обеспечивать следующие сервисы:
— NAT (во всех его видах);
— Session border control (SBC);
— Deep packet inspection (DPI);
— Функции межсетевого экрана.
Сервисные карты поддерживают все маршрутизаторы MX серии (включая и MX80 — слот под специальную карту есть на тыльной стороне маршрутизатора). О данных картах можно почитать на сайте производителя.
Путешествие пакета по внутреннему миру Juniper MX
по мотивам книги This Week: An Expert Packet Walkthrough on the MX Series 3D
Мы разобрались из чего состоит маршрутизатор, но как же происходит передача пакета с одно интерфейса на другой? Как будет обрабатываться пакет зависит от его типа:
— транзитный пакет, входящий и исходящий интерфейс на одном PFE;
— транзитный пакет, входящий и исходящий интерфейс на разных PFE;
— пакет, обработка которого будет производиться на CPU RE;
— пакет, обработка которого будет производиться на CPU интерфейсной карты;
— пакет, сгенерированный CPU RE;
— пакет, сгенерированный CPU PFE.
Мы разберем наиболее сложный случай, когда транзитный пакет имеет входящий интерфейс в зоне ответственности одного PFE, а исходящий — другого.
Итак, пакет принят на входящем интерфейсе. Пакет попадает на MAC контроллер, который по сути является прослойкой между физическим уровнем и канальным (подуровень MAC). Данный контроллер связывает между собой физический интерфейс и PFE. Одной из важных функций контроллера является проверка контрольной суммы полученного фрейма (если сумма посчитанная сумма не соответствует указанной в FCS, то пакет дропается.
Далее в работу включается Trio чипсет. Если у нас плата с малой пропускной способностью ( к примеру двадцать гигабитных портов), то в составе PFE будет присутствовать интерфейсный блок (IX chip). Данный блок производит предварительную классификацию пакетов. Данная классификация является очень грубой, так как имеет только три класса на каждый интерфейс — real time (RT), best effort (BE) и control. К последнему классу относится трафик управления (протоколы маршрутизации, vrrp и т.д.). Если же у нас более емкая плата (к примеру 16-ть десяток), то данного блока на плате не будет. Поэтому задача интерфейсного блока ложится на блок буферизации.
Блок буферизации состоит из нескольких блоков (их функции будем рассматривать по мере продвижения пакета). После предварительной классификации пакет попадает в WAN input block. Данный блок связывает все остальные блоки меду собой и отвечает за сегментацию полученного пакета с последующей буферизацией и отделение заголовка для отправки его в Lookup блок. Теперь подробнее. Попав в данный блок, от пакета отделяется заголовок, который помещается в специальный контейнер — parcel, а оставшаяся часть пакета буферизируется в быстрой памяти OnChip memory (SRAM).
Parcel представляет собой контейнер размером от 256 до 320 байт. Чаше всего длина пакета равна 256 байтам. Если на WI блок попал пакет, размер которого менее или равен 320 байтам, то данный пакет полностью помещается в parcel. Если же пакет имеет размер более 320 байт, то от пакета отделяются первые 256 байт, а остальная часть пакета буферизируется в OnChip-memory (SRAM).
Parcel, при передаче от блока буферизации в lookup блок имеет специальный заголовок M2L (MQ to LU), в котором указывается номер класса (к которому данный пакет был отнесен при предварительной классификации). Сразу встает вопрос — зачем делить пакет на две части и генерировать parcel? Не проще ли использовать исходный пакет? В таком случае внутри чипсета будет ходить слишком большой объем данных (например от блока буферизации к lookup блоку и обратно). Возникнут сложности с буферизацией пакетов между элементами чипсета и увеличится нагрузка на соединения между ними. В нашем же случае содержимое пакета хранится в буфере, в то время как parcel проходит обработку в остальных блоках чипсета.
Примечание: блоку WI неизвестно какие и сколько заголовков в полученном пакете. Отделяя 256 байт, вместе с заголовками в parcel будут помещаться часть данных. Изменениям подвергаются только заголовки, сами данные пользователя не изменяются.
Подведем краткий итог — в данный момент наш входящий пакет разбит на две части: заголовок помещен в parcel и отправлен в lookup блок (точнее сказать первые 256 байт пакета), а остальная часть помещена в буфер (SRAM).
Двигаемся дальше. Lookup блок является многоядерным чипом и состоит из нескольких PPE — packet processor engine и имеет специальную память RLDRAM, в которой и хранится таблица форвардинга. Lookup блок производит балансировку входящих данных по всем имеющимcя в его составе PPE. Получив parcel, lookup блок отправляет parcel на PPE (предварительно сняв с него M2L заголовок), где начинается его обработка (в данном случае можно сказать обработка заголовка исходного пакета).
Сначала маршрутизатор для IPv4 пакетов проверяет контрольную сумму (вспоминаем, что в IPv6 поле с контрольной суммой отсутствует), если контрольная сумма, указанная в пакете и сумма, посчитанная самим PPE не совпадают, то пакет дропается. (Сам Lookup блок не дропает пакеты, он их помечает и отправляет в блок буферизации, который уже будет производить дроп пакета). Если контрольная сумма верна, то обработка заголовка продолжается: производится применение фильтров (firewall filters), ограничений скорости (policers), класcификация трафика по DSCP/EXP (трафик может раскрашиваться согласно конфигурации администратора или переписывать поля DSCP/EXP), поиск next-hop, выполняет RPF check, в случае использования LAG или ECMP высчитывается хеш для определения исходящего интерфейса. В конечном итоге исходный заголовок пакета, который находился в parcel, подвергается изменениям (обязательно меняется поле ttl и пересчитывается контрольная сумма ipv4 заголовка), и parcel отправляется обратно в блок буферизации. К parcel добавляется новый заголовок L2M (LU to MQ), в котором содержится номер очереди, в которую должен встать пакет.
Очередь может быть в сторону фабрики коммутации или в сторону выходного интерфейса. В нашем случае выходной интерфейс находится в зоне ответственности другого PFE, поэтому в L2M заголовке указан номер очереди на отправку в сторону фабрики коммутации.
Когда исходящий интерфейс находится на другом PFE, помимо L2M заголовка появляется еще одни заголовок – FAB. Данный заголовок несет информацию о классе пакета, приоритете сброса и ID next-hop. Эта информация необходима для постановки пакета в очередь в сторону фабрики коммутации а так же Lookup блоку удаленного PFE (в противном случае PFE пришлось бы снова производить поиск next-hop и т.д.).
Далее, Lookup блок передает parcel, L2M и FAB заголовки обратно в блок буферизации. Эти данные попадают в блок LI – lookup input блок (субблок блока буферизации), который помещает FAB и parcel в OffChip memory (DRAM) и переносит относящийся к ним сегмент исходного пакета из OnChip в OffChip memory, а указатель на расположение этих данных в OffChip memory ставится в очередь на отправку в сторону фабрики коммутации.
Передача данных на уделенный PFE производится по схеме запрос-ответ. Сначала исходящий PFE отправляет удаленному PFE запрос на передачу данных. После получения согласия на прием данных от удаленного PFE, исходящий PFE начинает передавать данные производя балансировку по всем линкам в сторону фабрики коммутации. Данные через фабрику коммутации передаются в виде J-cell (64-байтные ячейки). Перед тем как начать передачу, исходящий PFE разбивает хранящийся в OffChip memory пакет, parcel и FAB на J-cell и прикрепляет к ним заголовок. В заголовке содержится информация об исходящем PFE, о PFE назначения (PFE ID), номер последовательности (что бы удаленный PFE мог заново собрать из данной последовательности исходный пакет и контрольная сумма. Передачу потока J-cell в фабрику коммутации производит Fabric output блок. Перед отправкой каждой ячейки, FO отправляет запрос на передачу и только после получения ответа начинает передачу. Этот механизм предназначен для предотвращения перегрузки фабрики коммутации (передача не будет вестись, пока не будет получен ответ на запрос).
Мы разобрались, какой путь проходит пакет от входящего интерфейса до фабрики коммутации. Теперь перейдем ко второй части – от фабрики коммутации к исходящему интерфейсу, поэтому будем говорить уже об исходящем PFE.
PFE имеет Fabric input блок, именно он получает J-cell из фабрики коммутации. FI производится обратную сборку parcel, FAB и остальной части пакета из J-cell, после чего parcel, FAB и M2L заголовки отправляются в lookup блок, а оставшаяся часть исходного пакета записывается в OffChip memory.
Lookup блок из FAB узнает ID next-hop, анализируя заголовок пакета в parcel и по arp записи выясняет реальный адрес next-hop, после чего создает новый L2 заголовок, при необходимости добавляет vlan-tag (или два тега), навешивает mpls метку (метки). Естественно, исходящий Lookup блок применяет правила QOS, filters, policers и т. д. и может так же внести изменения в заголовок исходящего пакета. После этих манипуляций, Lookup блок создает новый L2M заголовок, в котором указывает, в какую очередь должен встать пакет, и отправляет parcel и L2M заголовок в блок буферизации.
От Lookup блока parcel и L2M заголовок попадают в LI (lookup input) субблок блока буферизации, который пересылает parcel в OffChip memory (где уже хранится остальная часть пакета), а указатель на них ставит в очередь на отправку в интерфейсу. В какую очередь поставить данный пакет указано в L2M заголовке, полученном от lookup блока.
Как только походит очередь на отправку пакета в сеть, Wan output (WO) блок забирает Parcel и оставшуюся часть пакета из OffChip memory, собирает их в одни пакет и отправляет на контроллер исходящего интерфейса. Контроллер производит подсчет контрольной суммы пакета и отправляет его в сеть.
Для пакетов, направленных к/от RE, обработка будет несколько иначе — вместо отправки в сторону фабрики коммутации пакет будет вставать в очередь к CPU линейной карты, где к пакету снова будут применены фильтры и полисеры, и только потом пакет будет отправлен на RE через внутренний гигабитный свич.
Если есть какие то дополнения, прошу писать в личку. Спасибо за внимание!
Комментарии (14)

redfenix
15.08.2016 04:10Отличная статья, спасибо. Было бы так же интересно услышать про карты предыдущего поколения DPCe так как они до сих пор еще входу и ограничения при совместном использовании с MPC

Bormoglotx
15.08.2016 09:39+1Здравствуйте. Платы DPC построены на старом чипе I-CHIP (такой стоит в М-серии), естественно данный чипсет имеет меньшую производительность. Данные платы не поддерживаются фабрикой коммутации SCBE2.
При установке различных плат (DPC и MPC) в одно шасси (если используется не SCBE2), то проблем быть не должно.
При работе составе одного шасси с фабрикой SCB платы DPC поддерживают работу 2+1, но если в это же шасси добавить плату MPC, то фабрики переключатся в работу в режиме 3+0.
Ну и не менее важным является то, что платы DPC уже не поддерживаются вендором.

evg_krsk
15.08.2016 04:28А как далеко от MX-ов отстоят другие железки джунипера? Скажем, можно ли применить данные статьй, например к старшим SRX-ам?
Bormoglotx
15.08.2016 08:41Это смотря на сколько глубоко копать. Если по архитектуре софта и железа, то она будет сходной — то тот же SRX5800 имеет и SCB и RE и интерфейсные карты, и их назанчение будут такими же, как описано в статье.
Но если разбираться с работой SRX по обработке пакета — то разница буде большой, так как SRX, в отличии от М/Т/МХ серии работает с потоками и сессиями (как это свойственно фаерволу), в то время как М/Т/МХ серия скаждым пакетом индивидуально.

AllTheThingsUndone
15.08.2016 12:39Весь хардкор Давида Руа из параграфа «Путешествие пакета по внутреннему миру Juniper MX» выпилил. Эх…
This Week: An Expert Packet Walkthrough on the MX Series 3D

strib
15.08.2016 18:37Спасибо, очень интересно.
Легкий офтопик, Вы пишете про то что:«свичи Nokia при загрузке 33-35 процентов по 2-3 секунды думают после введения команды или нажатия на tab». Это про линейку ныне находящуюся в веденииу Coriant или про свежее приобретение в лице Alcatel-Lucent?

mickvav
А роутинг-демон не разделён на отдельные процессы, как в quagga? Если нет, почему?
hobbyte
Если правильно помню, зависит от настройки: virtual-router или routing-instance.
Bormoglotx
Здравствуйте. Отдельного демона, как в quagga в Junos вы не встретите, то есть вы не увидите отдельно isisd или ospfd. Работу всех протоколов контролирует исколючительно rpd. А вот rpd процессов может быть несоклько если вы используете logical-systems: на кажду logical-systems запускается одельный rpd.
tgz
Потому что в juniper не умеют делать быстрый IPC между процессами и все начинает тормозить. :)