
Apache Mesos — это централизованная отказоустойчивая система управления кластером. Она разработана для распределенных компьютерных сред c целью обеспечения изоляции ресурсов и удобного управления кластерами подчиненных узлов (mesos slaves). Это новый эффективный способ управления серверной инфраструктурой, но и, как любое техническое решение, не "серебряная пуля".
В некотором смысле суть его работы противоположная уже традиционной виртуализации — вместо деления физической машины на кучу виртуальных, Mesos предлагает их объединять в одно целое, в единый виртуальный ресурс.
Mesos распределяет ресурсы CPU и памяти в кластере для задач в похожей манере, как ядро ??Linux выделяет ресурсы железа между локальными процессами.
Представим себе, что есть необходимость выполнить различные типы задач. Для этого можно выделить отдельные виртуальные машины (отдельный кластер) для каждого типа. Эти виртуальные машины, вероятно, не будут полностью загруженными и некоторое время будут простаивать, то есть не будут работать с максимальной эффективностью. Если же все виртуальные машины для всех задач объединить в единый кластер, мы можем повысить эффективность использования ресурсов и параллельно с тем повысить скорость их выполнения (в случае если задачи краткосрочные или виртуальные машины не загружены полностью все время). Следующий рисунок, надеюсь, прояснит сказанное:
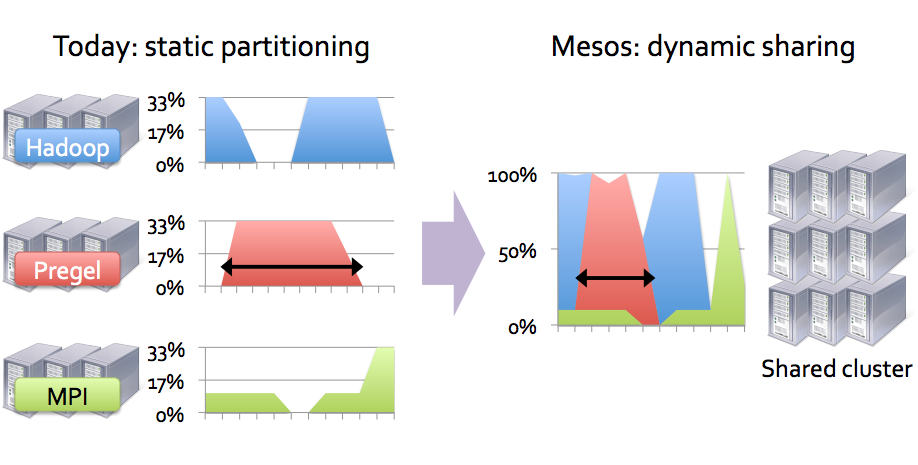
Но это далеко не все. Кластер Mesos (с фреймворком к нему) способен пересоздавать отдельные ресурсы, в случае их падения, масштабировать ресурсы вручную или автоматически при определенных условиях и т.п.
Пройдемся по компонентам Mesos-кластера.
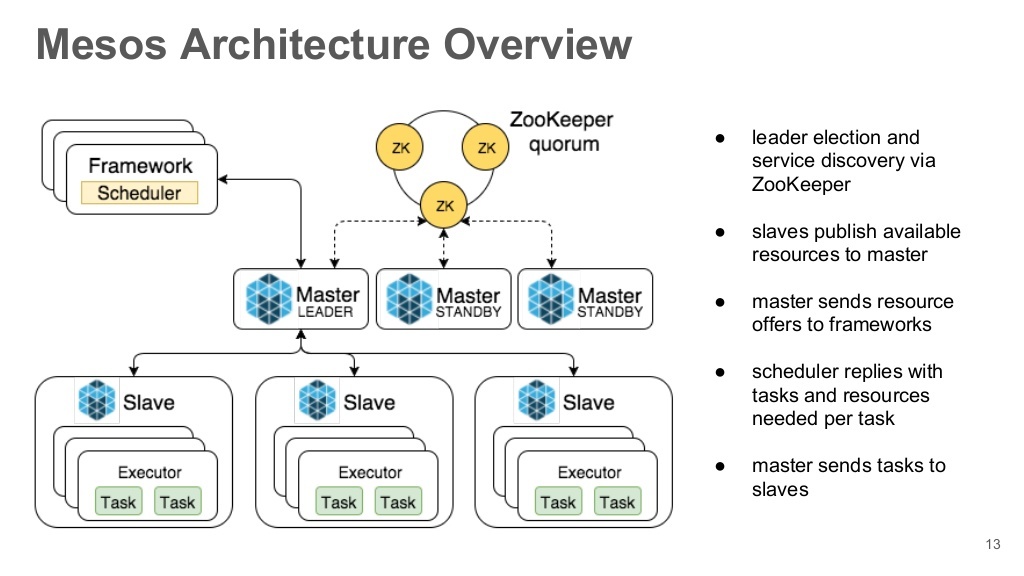
Mesos Masters
Главные контролирующие серверы кластера. Собственно они и отвечают за предоставление ресурсов, распределения задач между действующими Mesos-слейвами. Для обеспечения высокого уровня доступности их должно быть несколько и желательно нечетное количество, но конечно больше 1. Это обусловлено уровнем кворума. Активным мастером (лидером) в определенный момент времени может быть только один сервер.
Mesos Slaves
Сервисы (узлы), предоставляющие мощности для выполнения задач. Задачи могут выполняться как в собственных Mesos-контейнерах, так и в Docker.
Frameworks
Сам Mesos — это только "сердце" кластера, он предоставляет только среду для работы (выполнения) задач. Всю логику запуска задач, мониторинг их работы, масштабирование и т.п. выполняют фреймворки. По аналогии с Linux, это такая init/upstart-система для запуска процессов. Мы будем рассматривать работу фреймворка Marathon, который предназначен больше для запуска постоянных задач (долгосрочная работа серверов и т.п.) или краткосрочных. Для запуска задач по графику стоит воспользоваться другим фреймворком — Chronos (по аналогии с cron).
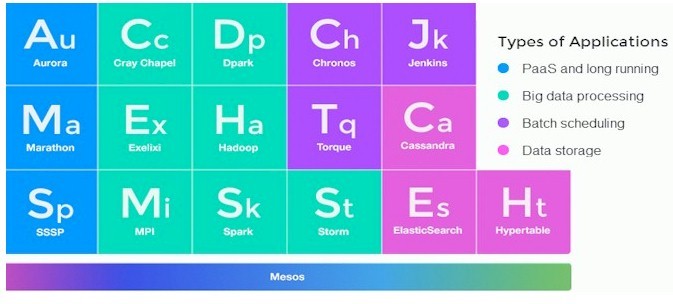
В общем, фреймворков достаточно большое количество и вот самые известные среди них:
Aurora (умеет как запускать задачи по графику, так и запускать долгосрочные задачи). Разработка компании Twitter.
Hadoop
Jenkins
Spark
Torque
ZooKeeper
Демон, отвечающий за координацию Mesos Masters узлов. Он проводит выборы мастера при наличии кворума. Другие узлы кластера получают адрес текущего мастера запросом на группу zookeeper нод типа zk://master-node1:2138,master-node2:2138,master-node3:2138/mesos. Mesos Slaves, в свою очередь, также подключаются только к текущему мастеру, используя аналогичный запрос. В нашем туториале, они тоже будут устанавливатся на ноды с Mesos-мастерами, но могут также жить и отдельно.
Эта статья будет скорее практической: повторяя за мной вы тоже на выходе сможете получить рабочий Mesos-кластер.
Для будущих узлов я выбрал следующие адреса:
mesos-master1 10.0.3.11
mesos-master2 10.0.3.12
mesos-master3 10.0.3.13
---
mesos-slave1 10.0.3.51
mesos-slave2 10.0.3.52
mesos-slave3 10.0.3.53Т.е. 3 мастера и 3 слейва. На мастерах также будет находиться фреймворк Marathon, который, по желанию, можно разместить на отдельном узле.
На этапе тестирования лучше выбирать виртуальные машины, работающие на платформах аппаратной виртуализации (VirtualBox, XEN, KVM), ведь, скажем, установить Docker в LXC контейнер пока не очень возможно или затруднительно. Docker мы будем использовать для изоляции задач, запущенных на Mesos слейвах.
Таким образом, имея 6 готовых серверов (виртуальных машин) с Ubuntu 14.04, мы готовы к бою.
MESOS MASTERS / MARATHON INSTALLATION
Выполняем полностью аналогичные действия на всех 3-х Mesos мастер-серверах.
apt-get install software-properties-commonДобавляем Mesos / Marathon-репозитории:
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E56151BF
DISTRO=$(lsb_release -is | tr '[:upper:]' '[:lower:]')
CODENAME=$(lsb_release -cs)
echo "deb http://repos.mesosphere.com/${DISTRO} ${CODENAME} main" | sudo tee /etc/apt/sources.list.d/mesosphere.listMesos и Marathon требуют Java-машину для работы. Поэтому установим последнюю от Oracle:
add-apt-repository ppa:webupd8team/java
apt-get update
apt-get install oracle-java8-installerПроверим работает ли Java:
java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)Хотя, кажется, OpenJDK также подходит.
На каждый из будущих мастеров проинсталлируем Mesos и Marathon:
apt-get -y install mesos marathonМежду прочим, фреймворк Marathon написан на Scala.
По зависимостям также будет установлено Zookeeper. Укажем ему адреса наших мастер нод:
vim /etc/mesos/zk
zk://10.0.3.11:2181,10.0.3.12:2181,10.0.3.13:2181/mesos2181 — порт на котором работает Zookeeper.
Для каждой ноды мастера выберем уникальный ID:
vim /etc/zookeeper/conf/myid
1Для второго и третьего сервера я выбрал 2 и 3 соответственно. Номера можно выбирать от 1 до 255.
Редактируем /etc/zookeeper/conf/zoo.cfg:
vim /etc/zookeeper/conf/zoo.cfg
server.1 = 10.0.3.11:2888:3888
server.2 = 10.0.3.12:2888:3888
server.3 = 10.0.3.13:2888:38881,2,3 — ID, что мы указали в /etc/zookeeper/conf/myid каждого сервера.
2888 — порт, использующий Zookeeper для коммуникаций с выбранным мастером, а 3888 — для проведения новых выборов, если с действующим мастером что-то случилось.
Переходим к настройке кворума. Кворум — это минимальное количество рабочих узлов, которое требуется для выбора нового лидера. Эта опция необходима для предотвращения Split-brain кластера. Представим себе, что кластер состоит только из 2-х серверов с кворумом 1. В таком случае только наличие 1 рабочего сервера достаточно для выбора нового лидера: собственно каждый сервер может сам выбрать себе лидером. В случае падения одного из серверов такое поведение более чем логично. Однако, что будет, когда только сетевое соединение между ними нарушится? Правильно: вероятный вариант, когда каждый из серверов будет по очереди перетягивать на себя основной трафик. В случае, если же такой кластер состоит из баз — то возможна вообще потеря эталонных данных и будет даже не понятно с чего восстанавливаться.
Итак, наличие 3-х серверов — это минимум для обеспечения высокой доступности. Значение кворума в таком случае — 2. Если только один сервер перестанет быть доступным — остальные 2 смогут кого-то выбрать между собой. Если же два сервера испытывают поломки или узлы не видят друг друга в сети — группа, для сохранности данных, вообще не будет проводить избрание нового мастера до достижения необходимого кворума (появления одного из серверов в сети).
Почему не имеет особого смысла выбирать 4 (четное количество) серверов? Потому что в таком случае, как и в случае с 3-мя серверами, только отсутствие одного сервера некритична для работы кластера: падение второго сервера будет фатальной для кластера по причине возможного Split-brain. Но в случае 5 серверов (и уровня кворума 3) уже падения 2 серверов не критично. Вот так. Так что лучше всего выбирать кластеры с 5 и более узлов, а то кто знает, что может произойти во время технического обслуживания на одном из них.
В случае, если Zookeeper будет вынесен отдельно, Mesos-мастеров может быть любое, в т.ч. и парное, количество.
Указываем одинаковый уровень кворума для мастеров:
echo "2" > /etc/mesos-master/quorumУказываем IP соответственно для каждого узла:
echo 10.0.3.11 | tee /etc/mesos-master/ipЕсли у серверов отсутствует доменнейм — копируем IP-адрес для использования его в качестве имени хоста:
cp /etc/mesos-master/ip /etc/mesos-master/hostnameАналогично для 10.0.3.12 и 10.0.3.13.
Настраиваем фреймворк Marathon. Создадим директорию для конфигурационных файлов и скопируем в нее хостнейм:
mkdir -p /etc/marathon/conf
cp /etc/mesos-master/hostname /etc/marathon/confСкопируем для Marathon настройки Zookeeper:
cp /etc/mesos/zk /etc/marathon/conf/master
cp /etc/marathon/conf/master /etc/marathon/conf/zkПоследние несколько отредактируем:
vim /etc/marathon/conf/zk
zk://10.0.3.11:2181,10.0.3.12:2181,10.0.3.13:2181/marathonИ наконец запрещаем загрузки демону mesos-slave на мастерах:
echo manual | sudo tee /etc/init/mesos-slave.override
stop mesos-slaveПерезапускаем сервисы на всех узлах:
restart mesos-master
restart marathonОткроем веб-панель Mesos на порту 5050:
В случае, если лидером был избран другой сервер, состоится переадресация на другой сервер:
Marathon имеет приятный темный интерфейс и работает он на порту 8080:

MESOS SLAVES INSTALLATION
Как и для установки Mesos-мастеров, добавим репозитории и установим необходимые пакеты:
apt-get install software-properties-common
apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E56151BF
DISTRO=$(lsb_release -is | tr '[:upper:]' '[:lower:]')
CODENAME=$(lsb_release -cs)
echo "deb http://repos.mesosphere.com/${DISTRO} ${CODENAME} main" | tee /etc/apt/sources.list.d/mesosphere.list
add-apt-repository ppa:webupd8team/java
apt-get update
apt-get install oracle-java8-installerПроверяем коректно ли была установлена Java:
java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)Необходимо также запретить запуск процессов Zookeeper и Mesos-master, т.к. они здесь не нужны:
echo manual | sudo tee /etc/init/zookeeper.override
echo manual | sudo tee /etc/init/mesos-master.override
stop zookeeper
stop mesos-masterУкажем домены и IP-адреса для слейва:
echo 10.0.3.51 | tee /etc/mesos-slave/ip
cp /etc/mesos-slave/ip /etc/mesos-slave/hostnameАналогичное действие также необходимо выполнить для 10.0.3.52 и 10.0.3.53 (конечно, с отдельным адресом для каждого сервера).
И описать все мастера в /etc/mesos/zk:
vim /etc/mesos/zk
zk://10.0.3.11:2181,10.0.3.12:2181,10.0.3.13:2181/mesosСлейв будут время от времени опрашивать Zookeeper на предмет текущего лидера и подключаться к нему, предоставляя свои ресурсы.
Во время запуска слейва, может возникнуть следующая ошибка:
Failed to create a containerizer: Could not create MesosContainerizer:
Failed to create launcher: Failed to create Linux launcher: Failed to mount
cgroups hierarchy at '/sys/fs/cgroup/freezer': 'freezer' is already
attached to another hierarchyВ таком случае нужно внести изменения в /etc/default/mesos-slave:
vim /etc/default/mesos-slave
...
MESOS_LAUNCHER=posix
...И запустить mesos-slave снова:
start mesos-slaveЕсли все будет выполнено верно, Слейвы подключатся в качестве ресурсов для текущего лидера:

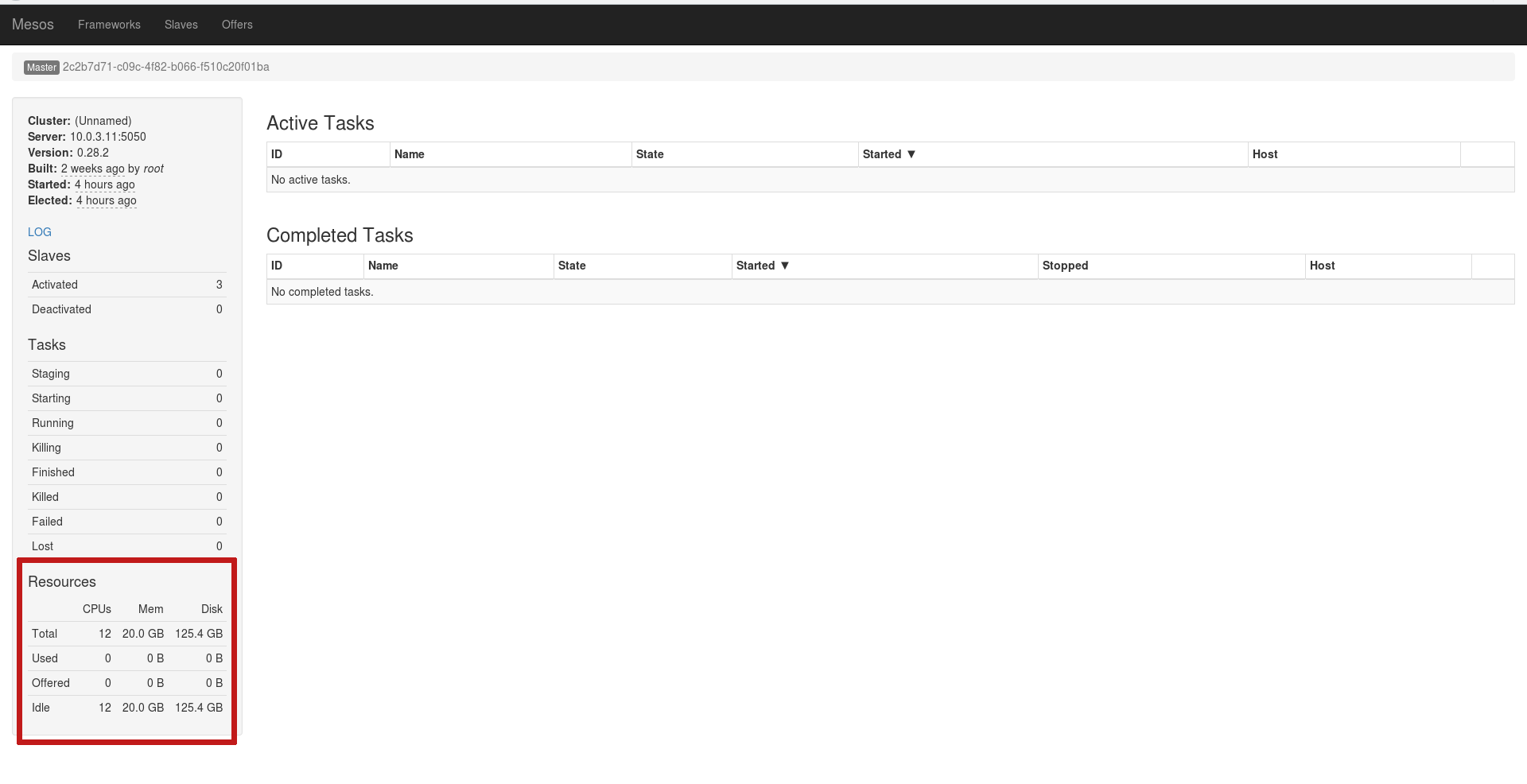
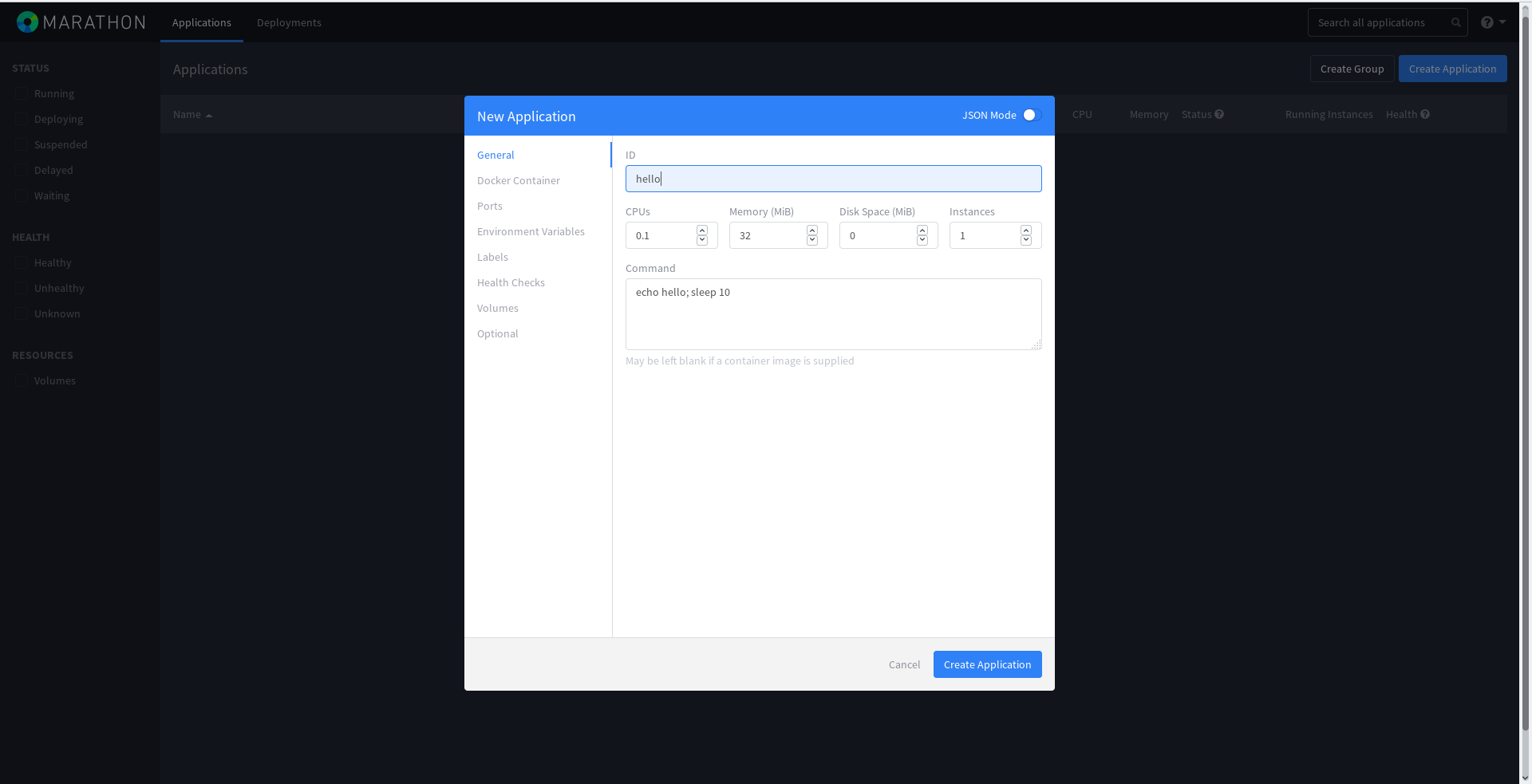
Кластер готов! Запустим какую-то задачу на Marathon. Для этого откроем Marathon на любом мастер-узле, нажмем синюю кнопку Create Application и введем все как на рисунке:
Задача начала выполняться:
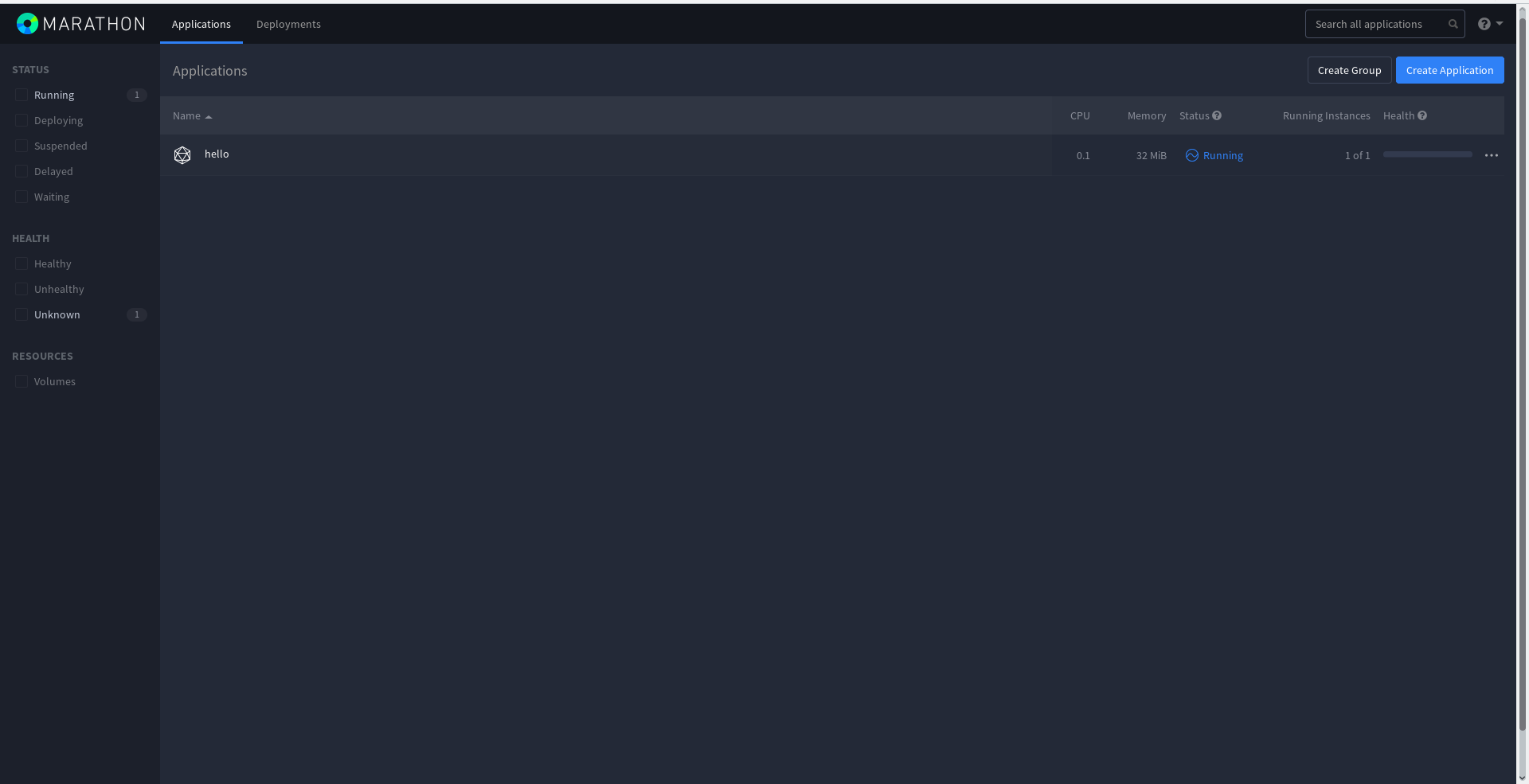
В веб-панели Mesos сразу появится активная задача, которую поставил фреймворк, и история завершенных задач. Дело в том, что эта задача будет завершаться и начинаться снова, ведь она краткосрочная. Именно поэтому в Completed Tasks будет приведен полный листинг всех старых задач:

Эту же задачу можно выполнить используя API Marathon, описав ее в формате JSON:
cd /tmp
vim hello2.json
{
"id": "hello2",
"cmd": "echo hello; sleep 10",
"mem": 16,
"cpus": 0.1,
"instances": 1,
"disk": 0.0,
"ports": [0]
}curl -i -H 'Content-Type: application/json' -d@hello2.json 10.0.3.11:8080/v2/apps
HTTP/1.1 201 Created
Date: Tue, 21 Jun 2016 14:21:31 GMT
X-Marathon-Leader: http://10.0.3.11:8080
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: 0
Location: http://10.0.3.11:8080/v2/apps/hello2
Content-Type: application/json; qs=2
Transfer-Encoding: chunked
Server: Jetty(9.3.z-SNAPSHOT)
{"id":"/hello2","cmd":"echo hello; sleep 10","args":null,"user":null,"env":{},"instances":1,"cpus":0.1,"mem":16,"disk":0,"executor":"","constraints":[],"uris":[],"fetch":[],"storeUrls":[],"ports":[0],"portDefinitions":[{"port":0,"protocol":"tcp","labels":{}}],"requirePorts":false,"backoffSeconds":1,"backoffFactor":1.15,"maxLaunchDelaySeconds":3600,"container":null,"healthChecks":[],"readinessChecks":[],"dependencies":[],"upgradeStrategy":{"minimumHealthCapacity":1,"maximumOverCapacity":1},"labels":{},"acceptedResourceRoles":null,"ipAddress":null,"version":"2016-06-21T14:21:31.665Z","residency":null,"tasksStaged":0,"tasksRunning":0,"tasksHealthy":0,"tasksUnhealthy":0,"deployments":[{"id":"13bea032-9120-45e7-b082-c7d3b7d0ad01"}],"tasks":[]}% В этом (и предыдущем) примере, будет выводиться hello, потом задержка в 10 секунд и все это по кругу. Задаче будет выделено 16МБ памяти и 0.1 CPU.
Вывод запущенных задач можно наблюдать, нажав на ссылку Sandbox в последней колонке основной панели действующего Mesos-мастера:
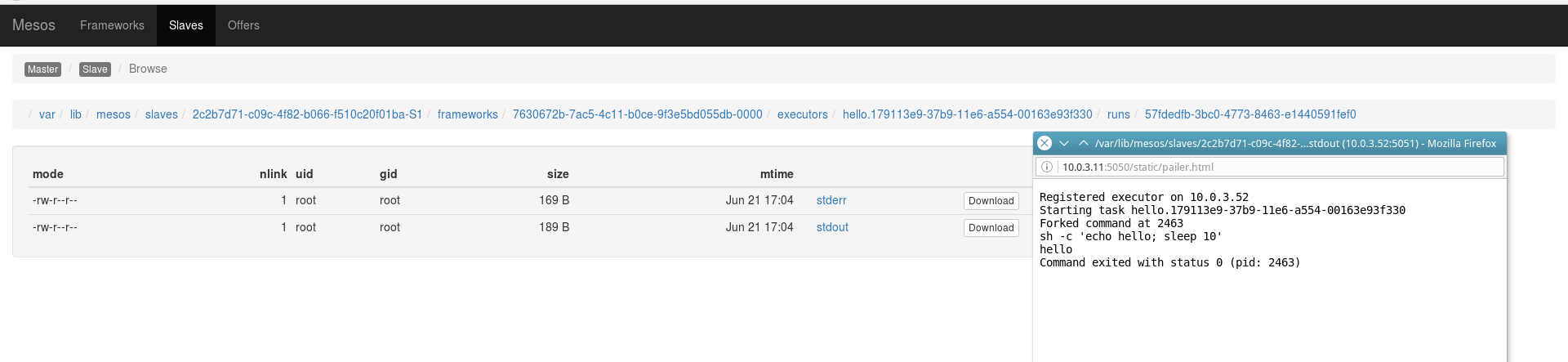
DOCKER
Для лучшего уровня изоляции и дополнительных возможностей в Mesos была интегрирована поддержка Docker. Кто с ним не знаком — советую предварительно сделать это.
С активацией Docker в Mesos также особо нет ничего сложного. Сначала необходимо проинсталлировать сам Docker на всех слейвах кластера:
apt-get install apt-transport-https ca-certificates
apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
echo "deb https://apt.dockerproject.org/repo ubuntu-precise main" | tee /etc/apt/sources.list.d/docker.list
apt-get update
apt-get install docker-engineДля проверки корректности установки запустим тестовый контейнер hello-world:
docker run hello-worldУказываем новый тип контейнеризации для Mesos Slaves:
echo "docker,mesos" | sudo tee /etc/mesos-slave/containerizersСоздание нового контейнера, обаза которого еще нет в локальном кэше, может занять больше времени. Поэтому поднимем значение таймаута регистрации нового контейнера в фреймворка:
echo "5mins" | sudo tee /etc/mesos-slave/executor_registration_timeoutНу и, как обычно, перегрузим сервис после подобных изменений:
service mesos-slave restartСоздадим новую задачу в Marathon и запустим ее в Docker-контейнере. JSON будет выглядеть следующим образом:
vim /tmp/Docker.json
{
"container": {
"type": "DOCKER",
"docker": {
"image": "libmesos/ubuntu"
}
},
"id": "ubuntu",
"cpus": 0.5,
"mem": 128,
"uris": [],
"cmd": "while sleep 10; do date -u +%T; done"
}То есть в контейнере будет запущен вечный цикл while с выводом текущей даты. Несложно, правда?
Docker.json можно прямо влить через веб-панель Marathon, активировав переключатель JSON при создании новой задачи:
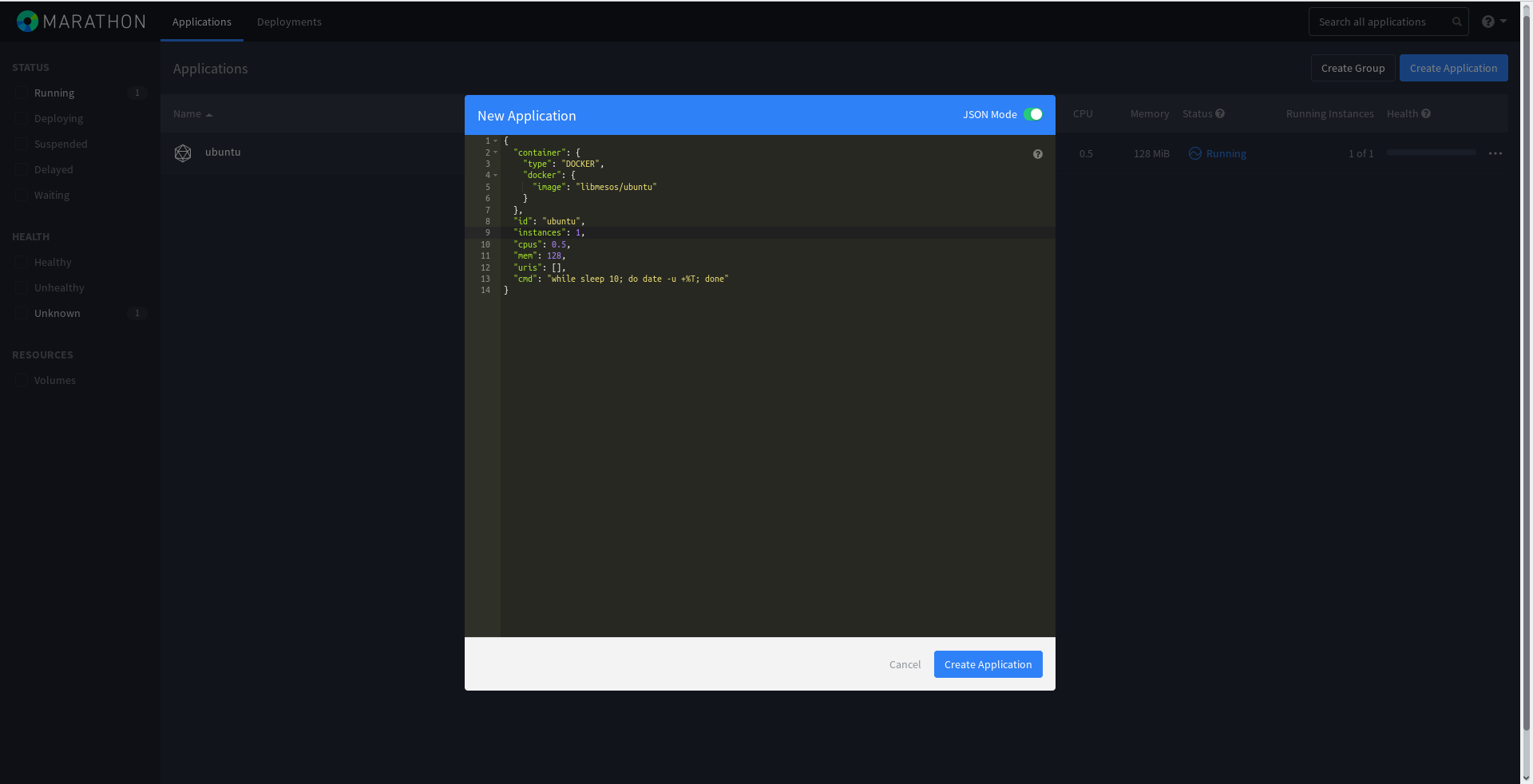
Или по желанию ввести данные в отдельные поля:

Через некоторое время, в зависимости от скорости интернет-соединения, контейнер будет запущен. Существование его можно наблюдать на Mesos-слейве, который получил задачу на выполнение:
root@mesos-slave1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
81f39fc7474a libmesos/ubuntu "/bin/sh -c 'while sl" 2 minutes ago Up 2 minutes mesos-4e1e9267-ecf7-4b98-848b-f9a7a30ad209-S2.5c1831a6-f856-48f9-aea2-74e5cb5f067f
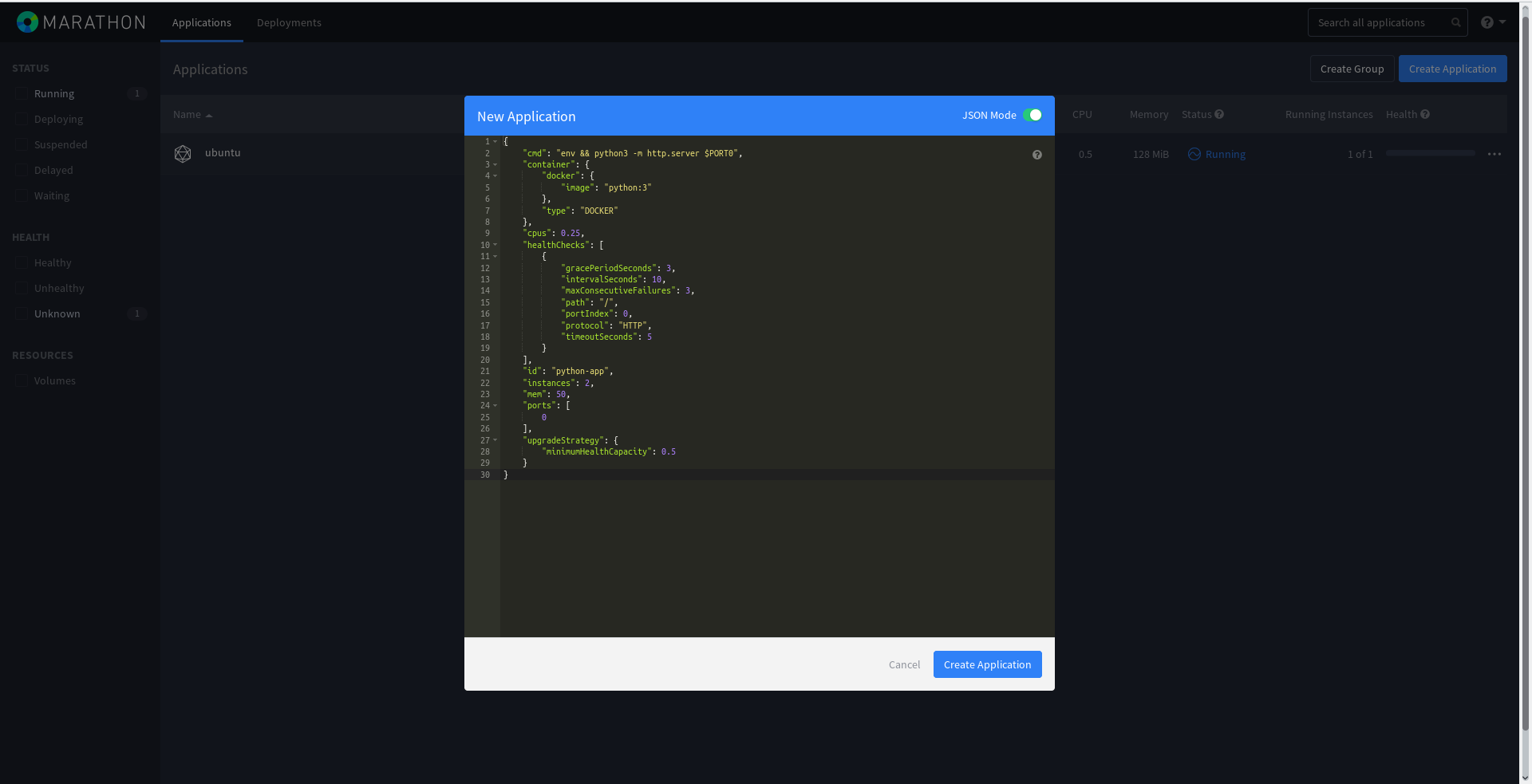
root@mesos-slave1:~# Создадим немного более сложную задачу Marathon, уже с healthcheck-ми. В случае неудовлетворительной проверки работы контейнера, последний будет пересоздан фреймворком:
{
"cmd": "env && python3 -m http.server $PORT0",
"container": {
"docker": {
"image": "python:3"
},
"type": "DOCKER"
},
"cpus": 0.25,
"healthChecks": [
{
"gracePeriodSeconds": 3,
"intervalSeconds": 10,
"maxConsecutiveFailures": 3,
"path": "/",
"portIndex": 0,
"protocol": "HTTP",
"timeoutSeconds": 5
}
],
"id": "python-app",
"instances": 2,
"mem": 50,
"ports": [
0
],
"upgradeStrategy": {
"minimumHealthCapacity": 0.5
}
}Теперь будет запущено целых два инстанса python-app, то есть 2 веб-сервера Python с перебросом порта.
Добавим его также через веб-панель Marathon:
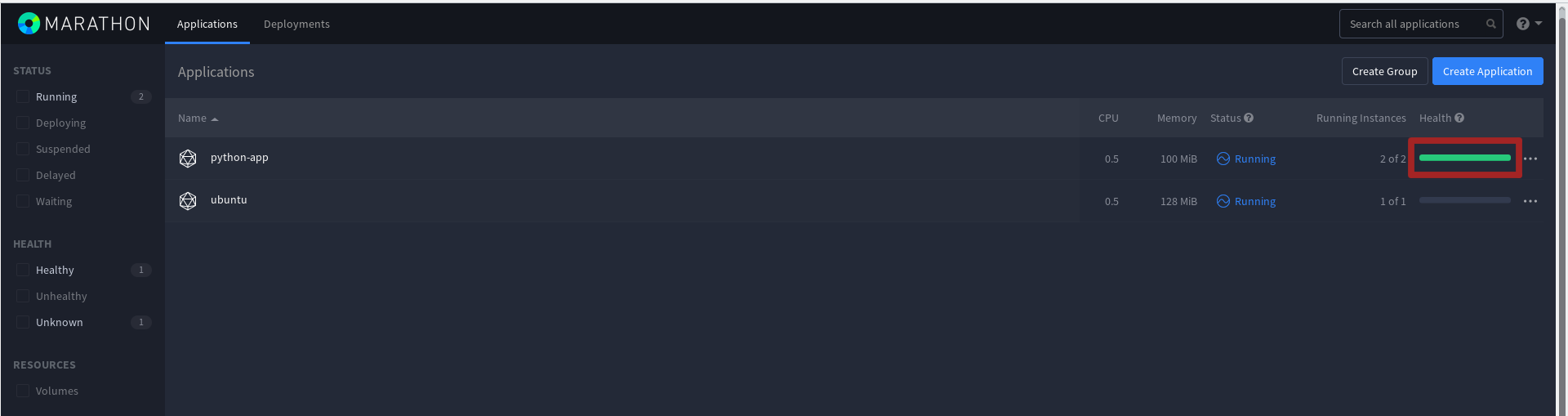
Теперь в панели Marathon можем наблюдать, что появились проверки работы инстанса:
На Mesos-мастере появились новые долгосрочные задачи:
Можно также увидеть какой фреймворк поставил их на выполнение:
Однако как узнать порт, который назначен для новых веб-серверов Python? Есть несколько способов и один из них — запрос к API Marathon:
curl -X GET -H "Content-Type: application/json" 10.0.3.12:8080/v2/tasks | python -m json.tool
...
{
...
{
"appId": "/python-app",
"healthCheckResults": [
{
"alive": true,
"consecutiveFailures": 0,
"firstSuccess": "2016-06-24T10:35:20.785Z",
"lastFailure": null,
"lastFailureCause": null,
"lastSuccess": "2016-06-24T12:53:31.372Z",
"taskId": "python-app.53d6ccef-39f7-11e6-a2b6-0800272ca725"
}
],
"host": "10.0.3.51",
"id": "python-app.53d6ccef-39f7-11e6-a2b6-0800272ca725",
"ipAddresses": [
{
"ipAddress": "10.0.3.51",
"protocol": "IPv4"
}
],
"ports": [
31319
],
"servicePorts": [
10001
],
"slaveId": "4e1e9267-ecf7-4b98-848b-f9a7a30ad209-S2",
"stagedAt": "2016-06-24T10:35:10.767Z",
"startedAt": "2016-06-24T10:35:11.788Z",
"version": "2016-06-24T10:35:10.702Z"
},
{
"appId": "/python-app",
"healthCheckResults": [
{
"alive": true,
"consecutiveFailures": 0,
"firstSuccess": "2016-06-24T10:35:20.789Z",
"lastFailure": null,
"lastFailureCause": null,
"lastSuccess": "2016-06-24T12:53:31.371Z",
"taskId": "python-app.53d6a5de-39f7-11e6-a2b6-0800272ca725"
}
],
"host": "10.0.3.52",
"id": "python-app.53d6a5de-39f7-11e6-a2b6-0800272ca725",
"ipAddresses": [
{
"ipAddress": "10.0.3.52",
"protocol": "IPv4"
}
],
"ports": [
31307
],
"servicePorts": [
10001
],
"slaveId": "4e1e9267-ecf7-4b98-848b-f9a7a30ad209-S2",
"stagedAt": "2016-06-24T10:35:10.766Z",
"startedAt": "2016-06-24T10:35:11.784Z",
"version": "2016-06-24T10:35:10.702Z"
}
]
}По адресам http://10.0.3.52:31307 и http://10.0.3.51:31319 новоиспеченные сервера и будут ждать подключений:
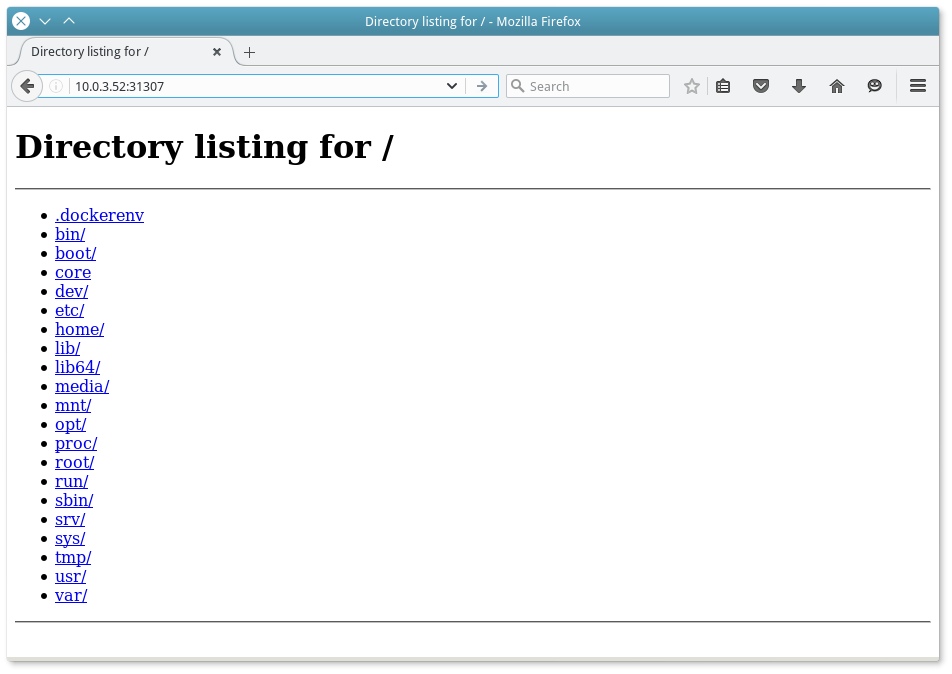
Аналогично номера портов можно узнать в панеле Marathon.
Новые контейнеры на конечных хостах:
root@mesos-slave1:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d5e439d61456 python:3 "/bin/sh -c 'env && p" 2 hours ago Up 2 hours mesos-4e1e9267-ecf7-4b98-848b-f9a7a30ad209-S2.150ac995-bf3c-4ecc-a79c-afc1c617afe2
...
root@mesos-slave2:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1fa55f8cb759 python:3 "/bin/sh -c 'env && p" 2 hours ago Up 2 hours mesos-4e1e9267-ecf7-4b98-848b-f9a7a30ad209-S2.9392fec2-23c1-4c05-a576-60e9350b9b20
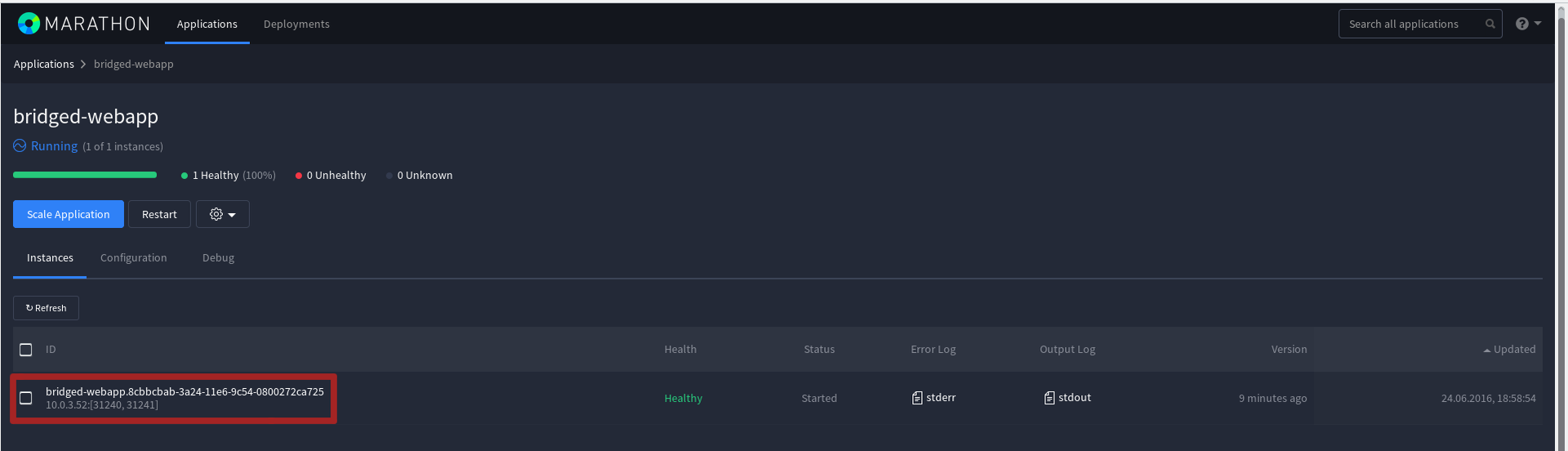
...Есть также возможность указывать статические порты для каждого нового задания Marathon. Это реализуется за счет режима Bridget Network Mode. Корректный JSON для создания задачи будет иметь следующий вид:
{
"id": "bridged-webapp",
"cmd": "python3 -m http.server 8080",
"cpus": 0.5,
"mem": 64,
"disk": 0,
"instances": 1,
"container": {
"type": "DOCKER",
"volumes": [],
"docker": {
"image": "python:3",
"network": "BRIDGE",
"portMappings": [
{
"containerPort": 8080,
"hostPort": 31240,
"servicePort": 9000,
"protocol": "tcp",
"labels": {}
},
{
"containerPort": 161,
"hostPort": 31241,
"servicePort": 10000,
"protocol": "udp",
"labels": {}
}
],
"privileged": false,
"parameters": [],
"forcePullImage": false
}
},
"healthChecks": [
{
"path": "/",
"protocol": "HTTP",
"portIndex": 0,
"gracePeriodSeconds": 5,
"intervalSeconds": 20,
"timeoutSeconds": 20,
"maxConsecutiveFailures": 3,
"ignoreHttp1xx": false
}
],
"portDefinitions": [
{
"port": 9000,
"protocol": "tcp",
"labels": {}
},
{
"port": 10000,
"protocol": "tcp",
"labels": {}
}
]
}Поэтому tcp-порт контейнера 8080 (containerPort) будет переадресован в порт 31240 (hostPort) на слейв-машине. Аналогично с udp — 161-й в 31241. Конечно, именно в этом случае, причин делать переадресацию udp совсем нет и эта возможность приведена только для примера.
MESOS-DNS
Очевидно, что доступ по IP-адресам не совсем удобен. Более того, слейв, на котором будет запущен каждый следующий контейнер с задачей, будет избираться случайным образом. Поэтому было бы совсем не лишним иметь возможность автоматически привязывать к контейнерам DNS-имена.
С этим может помочь Mesos-DNS. Это DNS-сервер для Mesos-кластера, который использует API Mesos-мастера для получения имен запущенных задач и IP-адресов слейвов, на которых запущены задачи.
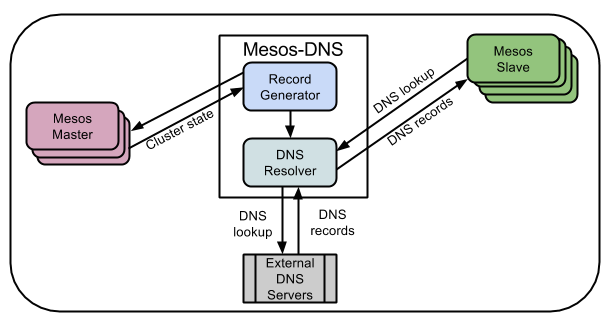
Имя домена по умолчанию будет формироваться следующим образом: имя задачи в Mesos +.marathon.mesos. MESOS-DNS будет обслуживать только эту зону — все остальные будут перенаправляться на стандартный DNS-сервер.
Mesos-DNS написан на языке Go и распространяется в виде готового скомпилированного бинарного файла. Для которого в идеале необходимо написать init или systemd скрипт (в зависимости от версии дистрибутива), однако готовые рекомендации есть в сети https://github.com/mesosphere/mesos-dns-pkg/tree/master/common.
Для тестирования Mesos-DNS я создал отдельный сервер с адресом 10.0.3.60, хотя с таким же успехом его можно создать в контейнере с помощью Marathon.
Загружаем на новый сервер последний релиз Mesos-DNS в директорию /usr/sbin и переименовываем бинарник:
cd /usr/sbin
wget https://github.com/mesosphere/mesos-dns/releases/download/v0.5.2/mesos-dns-v0.5.2-linux-amd64
mv mesos-dns-v0.5.2-linux-amd64 mesos-dns
chmod +x mesos-dnsСоздаем конфигурационный файл:
vim /etc/mesos-dns/config.json
{
"zk": "zk://10.0.3.11:2181,10.0.3.12:2181,10.0.3.13:2181/mesos",
"masters": ["10.0.3.11:5050","10.0.3.12:5050","10.0.3.13:5050"],
"refreshSeconds": 60,
"ttl": 60,
"domain": "mesos",
"port": 53,
"resolvers": ["8.8.8.8","8.8.4.4"],
"timeout": 5,
"email": "root.mesos-dns.mesos"
}То есть Mesos-DNS с помощью запроса на Zookeeper (zk) будет узнавать информацию о действующем мастере и опрашивать его с частотой раз в минуту (refreshSeconds). В случае запроса всех остальных доменов кроме зоны mesos — запросы будут переадресованы на DNS-серверы Google (параметр resolvers). Работать сервис будет на стандартном 53 порту, как и любой другой DNS-сервер.
Параметр masters не обязателен. Сначала Mesos-DNS будет искать лидера, используя запрос на Zookeeper сервера и, если они не доступны, будет проходиться по списку серверов, указанных в masters.
Вот хорошая статья, которая описывает все возможные варианты опций http://mesosphere.github.io/mesos-dns/docs/configuration-parameters.html
Этого достаточно, поэтому запускаем Mesos-DNS:
/usr/sbin/mesos-dns -config=/etc/mesos-dns/config.json
2016/07/01 11:58:23 Connected to 10.0.3.11:2181
2016/07/01 11:58:23 Authenticated: id=96155239082295306, timeout=40000Конечно, также ко всем нодам кластера Mesos (и других нод с которых будет производится доступ к сервисам в контейнерах) стоит добавить адрес сервера Mesos-DNS в качестве основного в /etc/resolv.conf, на первую позицию:
vim /etc/resolv.conf
nameserver 10.0.3.60
nameserver 8.8.8.8
nameserver 8.8.4.4После изменения resolv.conf, стоит убедиться, что все имена резовляться именно через 10.0.3.60:
dig i.ua
; <<>> DiG 9.9.5-3ubuntu0.8-Ubuntu <<>> i.ua
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 24579
;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;i.ua. IN A
;; ANSWER SECTION:
i.ua. 2403 IN A 91.198.36.14
;; Query time: 58 msec
;; SERVER: 10.0.3.60#53(10.0.3.60)
;; WHEN: Mon Jun 27 16:20:12 CEST 2016
;; MSG SIZE rcvd: 49Для демонстрации работы Mesos-DNS запустим через Marathon следующую задачу:
cat nginx.json
{
"id": "nginx",
"container": {
"type": "DOCKER",
"docker": {
"image": "nginx:1.7.7",
"network": "HOST"
}
},
"instances": 1,
"cpus": 0.1,
"mem": 60,
"constraints": [
[
"hostname",
"UNIQUE"
]
]
}
curl -X POST -H "Content-Type: application/json" http://10.0.3.11:8080/v2/apps -d@nginx.jsonЭта задача установит контейнер с Nginx, а Mesos-DNS зарегистрирует для него имя nginx.marathon.mesos:
dig +short nginx.marathon.mesos
10.0.3.53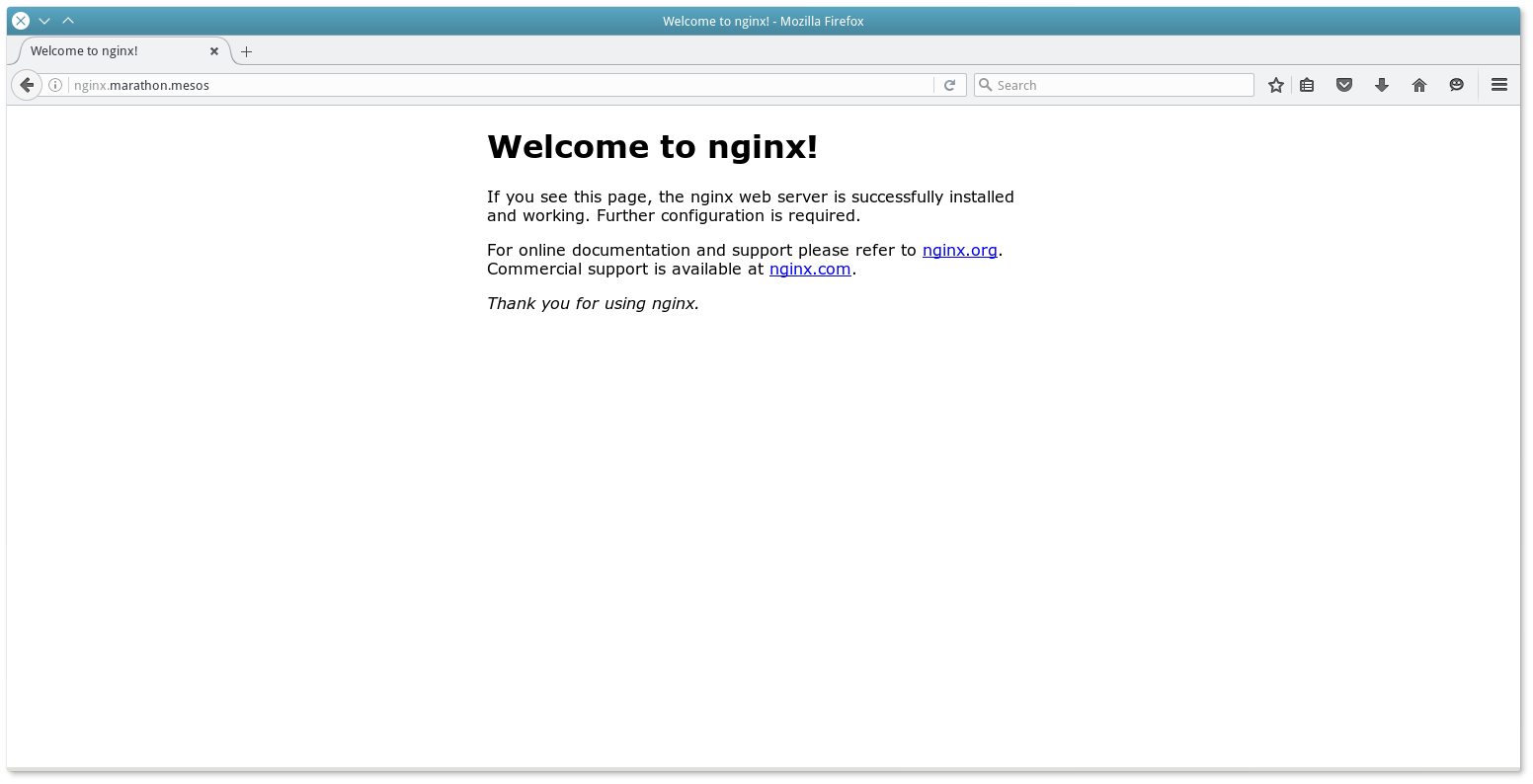
При масштабировании задачи nginx (то есть при создании дополнительных инстансов), Mesos-DNS распознает это и создаст дополнительные A-записи для того же домена:
dig +short nginx.marathon.mesos
10.0.3.53
10.0.3.51Таким образом будет работать балансировка между двумя нодами на уровне DNS.
Стоит заметить, что Mesos-DNS, кроме А-записей, также создает SRV-запись в DNS для каждой задачи (контейнера). SRV-запись связывает название сервиса и хостнейм-IP-порт на котором он доступен. Проверим SRV-запись для задачи nginx, что мы запустили раньше (не масштабируемой до двух инстансов):
dig _nginx._tcp.marathon.mesos SRV
; <<>> DiG 9.9.5-3ubuntu0.8-Ubuntu <<>> _nginx._tcp.marathon.mesos SRV
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 11956
;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; QUESTION SECTION:
;_nginx._tcp.marathon.mesos. IN SRV
;; ANSWER SECTION:
_nginx._tcp.marathon.mesos. 60 IN SRV 0 0 31514 nginx-9g7b9-s0.marathon.mesos.
;; ADDITIONAL SECTION:
nginx-9g7b9-s0.marathon.mesos. 60 IN A 10.0.3.51
;; Query time: 2 msec
;; SERVER: 10.0.3.60#53(10.0.3.60)
;; WHEN: Fri Jul 01 12:03:37 CEST 2016
;; MSG SIZE rcvd: 124Для того, чтобы не вносить изменения в настройки resolv.conf каждого сервера — можно внести изменения к внутреннему DNS инфраструктуры. В случае Bind9 эти изменения будут выглядеть так:
vim /etc/bind/named.conf.local
zone "mesos" {
type forward;
forward only;
forwarders { 192.168.0.100 port 8053; };
};А в конфиге Mesos-DNS (представим, что он сейчас по адресу 192.168.0.100) следует внести следующие изменения:
vim /etc/mesos-dns/config.json
...
"externalon": false,
"port": 8053,
..."externalon": false указывает на то, что Mesos-DNS имеет право отказывать в обслуживанию запросам, которые пришли не с доменов mesos.
После внесенных изменений необходимо перегрузить Bind и Mesos-DNS.
Mesos-DNS также имеет API https://docs.mesosphere.com/1.7/usage/service-discovery/mesos-dns/http-interface/, который может помочь в решении задач автоматизации.
Mesos-DNS, кроме создания записей для работающих задач, автоматически создает записи (A и SRV) также для Mesos Slaves, Mesos Masters (и отдельно для лидера среди них), фреймворков. Все для нашего с вами удобства.
MARATHON-LB
Несмотря на преимущества, в Mesos-DNS также есть и определенные ограничения, среди которых:
- DNS не делает привязки к портам на которых работают сервисы в контейнерах. Их нужно или выбирать статически при постановке задачи (следить за их использованием может быть не такой уж и простой задачей) или каждый раз узнавать новый порт через Marathon для доступа к конечным ресурсам. Mesos-DNS умеет генерировать также SRV-записи в DNS (с указанием конечного хостнейму и порта), однако «из коробки» с этим умеют работать далеко не все программы.
- DNS не имеет быстрого failover (функция переключения на резервный узел).
- Записи в локальных DNS-кэшах могут храниться достаточно долго (как минимум время TTL). Хотя сам Mesos-DNS опрашивает Mesos Master API довольно часто.
- Отсутствуют Health-check проверки сервисов в конечных контейнерах. То есть, в случае нескольких инстансов, падение одного из них останется незамеченным для Mesos-DNS до полного его пересоздание фреймворком Marathon.
- Некоторые программы и библиотеки не работают корректно с несколькими A-записями, что накладывает серьезные ограничения на масштабирование задач.
То есть большинство проблем возникают вследствие самой природы DNS.
Именно для устранения этих недостатков стартовал подпроект Marathon-lb. Marathon-lb — это скрипт на языке Python, который опрашивает Marathon API и на основе полученных данных (адрес Mesos-слейва, на котором физически находится контейнер и порт работы сервиса) создает конфигурационный файл HAproxy и делает reload его процесса.
Однако стоит отметить, что Marathon-lb работает только с Marathon, в отличие от Mesos-DNS. Поэтому в случае другого фреймворка нужно будет искать другие программные решения.

На рисунке изображено балансирование запросов двумя пулами балансировщиков — Internal (для доступов с внутренней сети) и External (для доступов из сети Internet). Балансировщик (кроме ELB) — это HAproxy и Marathon-lb. ELB — это балансировщик в инфраструктуре Amazon AWS.
Для настройки Marathon-lb я использовал отдельную виртуальную машину с адресом 10.0.3.61. В официальной документации также приведены варианты запуска Marathon-lb в docker-контейнере, в качестве задачи, запущенной с Marathon
Настройка Marathon-lb и HAproxy проходит довольно не сложно. Нужен последний стабильный релиз HAproxy и для Ubuntu 14.04 это версия 1.6:
apt-get install software-properties-common
add-apt-repository ppa:vbernat/haproxy-1.6
apt-get update
apt-get install haproxyЗагружаем код проекта Marathon-lb:
mkdir /marathon-lb/
cd /marathon-lb/
git clone https://github.com/mesosphere/marathon-lb .Установим необходимые для работы python-пакеты:
apt install python3-pip
pip install -r requirements.txtГенерируем ключи, которые требует по-умолчанию marathon-lb:
cd /etc/ssl
openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes
cat key.pem >> mesosphere.com.pem
cat cert.pem >> mesosphere.com.pemВыполняем первый запуск marathon-lb:
/marathon-lb/marathon_lb.py --marathon http://my_marathon_ip:8080 --group internalЕсли не возникло серьезных ошибок — можно переходить к созданию задачи в Marathon:
{
"id": "nginx-internal",
"container": {
"type": "DOCKER",
"docker": {
"image": "nginx:1.7.7",
"network": "BRIDGE",
"portMappings": [
{ "hostPort": 0, "containerPort": 80, "servicePort": 10001 }
],
"forcePullImage":true
}
},
"instances": 1,
"cpus": 0.1,
"mem": 65,
"healthChecks": [{
"protocol": "HTTP",
"path": "/",
"portIndex": 0,
"timeoutSeconds": 10,
"gracePeriodSeconds": 10,
"intervalSeconds": 2,
"maxConsecutiveFailures": 10
}],
"labels":{
"HAPROXY_GROUP":"internal"
}
}Сразу после перехода задачи в режим Running, опросим Marathon:
/marathon-lb/marathon_lb.py --marathon http://10.0.3.11:8080 --group internal
marathon_lb: fetching apps
marathon_lb: GET http://10.0.3.11:8080/v2/apps?embed=apps.tasks
marathon_lb: got apps ['/nginx-internal']
marathon_lb: setting default value for HAPROXY_BACKEND_REDIRECT_HTTP_TO_HTTPS
...
marathon_lb: setting default value for HAPROXY_BACKEND_HTTP_HEALTHCHECK_OPTIONS
marathon_lb: generating config
marathon_lb: HAProxy dir is /etc/haproxy
marathon_lb: configuring app /nginx-internal
marathon_lb: frontend at *:10001 with backend nginx-internal_10001
marathon_lb: adding virtual host for app with id /nginx-internal
marathon_lb: backend server 10.0.3.52:31187 on 10.0.3.52
marathon_lb: reading running config from /etc/haproxy/haproxy.cfg
marathon_lb: running config is different from generated config - reloading
marathon_lb: writing config to temp file /tmp/tmp02nxplxl
marathon_lb: checking config with command: ['haproxy', '-f', '/tmp/tmp02nxplxl', '-c']
Configuration file is valid
marathon_lb: moving temp file /tmp/tmp02nxplxl to /etc/haproxy/haproxy.cfg
marathon_lb: No reload command provided, trying to find out how to reload the configuration
marathon_lb: we seem to be running on a sysvinit based system
marathon_lb: reloading using /etc/init.d/haproxy reload
* Reloading haproxy haproxy
marathon_lb: reload finished, took 0.02593827247619629 secondsНазвание группы должно совпадать с ярлыком "HAPROXY_GROUP" в поставленной задаче. Это сделано для возможности использовать несколько балансировщиков, которые будут обслуживать разные группы.
С последнего вывода видим в haproxy.cfg было добавлено проксирование из порта 10001 в адрес 10.0.3.52:31187.
И HAproxy действительно открыл соответствующий порт:
root@mesos-lb# netstat -tulpn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
...
tcp 0 0 0.0.0.0:10001 0.0.0.0:* LISTEN 10285/haproxy
...Конфигурация haproxy.cfg теперь выглядит так:
cat /etc/haproxy/haproxy.cfg
...
frontend nginx-internal_10001
bind *:10001
mode http
use_backend nginx-internal_10001
backend nginx-internal_10001
balance roundrobin
mode http
option forwardfor
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
option httpchk GET /
timeout check 10s
server 10_0_3_52_31187 10.0.3.52:31187 check inter 2s fall 11Соответственно, если будет 2 инстанса в задаче на Marathon — то будет и 2 адреса в бэкенде:
nginx-internal_10001
```.
<img src="https://habrastorage.org/files/eb5/96b/34e/eb596b34eb814db4b6b46f4b6fcb683e.png"/>
Но опять таки, помнить и использовать номер порта соединения - не самая лучшая затея. Поэтому идеальный вариант - это использование <b>virtual host mapping</b> для HAproxy. Суть этого всего в том, что в зависимости от запрошенного домена в HAproxy, будет происходить переадресация на конечный слейв и порт к нему.
Поставим еще одну задачу для того чтобы проверить все это в деле:
```bash
{
"Id": "nginx-external",
"Container" {
"Type": "DOCKER",
"Docker" {
"Image": "nginx: 1.7.7",
"Network": "BRIDGE",
"PortMappings": [
{ "HostPort": 0, "containerPort": 80, "servicePort" 10000}
],
"ForcePullImage": true
}
}
"Instances": 1,
"Cpus": 0.1,
"Mem": 65,
"HealthChecks": [{
"Protocol": "HTTP",
"Path": "/",
"PortIndex": 0,
"TimeoutSeconds": 10
"GracePeriodSeconds": 10
"IntervalSeconds": 2,
"MaxConsecutiveFailures": 10
}],
"Labels" {
"HAPROXY_GROUP": "external",
"HAPROXY_0_VHOST": "nginx.external.com"
}
}Итак, мы добавили дополнительный ярлык "HAPROXY_0_VHOST" с указанием домена, который должен проксировать HAproxy.
Выждав минуту, запускаем marathon_lb.py:
/marathon-lb/marathon_lb.py --marathon Http://10.0.3.11:8080 --group external
marathon_lb: fetching apps
marathon_lb: GET http://10.0.3.11:8080/v2/apps?embed=apps.tasks
marathon_lb: got apps [ '/ nginx-internal', '/ nginx-external']
marathon_lb: setting default value for HAPROXY_HTTP_FRONTEND_ACL_WITH_AUTH
...
marathon_lb: generating config
marathon_lb: HAProxy dir is / etc / haproxy
marathon_lb: configuring app / nginx-external
marathon_lb: frontend at * 10000 with backend nginx-external_10000
marathon_lb: adding virtual host for app with hostname nginx.external.com
marathon_lb: adding virtual host for app with id / nginx-external
marathon_lb: backend server 10.0.3.53:31980 on 10.0.3.53
marathon_lb: reading running config from /etc/haproxy/haproxy.cfg
marathon_lb: running config is different from generated config - reloading
marathon_lb: writing config to temp file / tmp / tmpcqyorq8x
marathon_lb: checking config with command: [ 'haproxy "," -f "," / tmp / tmpcqyorq8x "," -c']
Configuration file is valid
marathon_lb: moving temp file / tmp / tmpcqyorq8x to /etc/haproxy/haproxy.cfg
marathon_lb: No reload command provided, trying to find out how to reload the configuration
marathon_lb: we seem to be running on a sysvinit based system
marathon_lb: reloading using /etc/init.d/haproxy reload
* Reloading haproxy haproxy
marathon_lb: reload finished, took 0.02756667137145996 secondsИ проверим конфигурационный файл HAproxy:
cat /etc/haproxy/haproxy.cfg
...
frontend marathon_http_in
bind * 80
mode http
acl host_nginx_external_com_nginx-external hdr (host) -i nginx.external.com
use_backend nginx-external_10000 if host_nginx_external_com_nginx-external
frontend marathon_http_appid_in
bind *: 9091
mode http
acl app__nginx-external hdr (x-marathon-app-id) -i / nginx-external
use_backend nginx-external_10000 if app__nginx-external
frontend marathon_https_in
bind * 443 ssl crt /etc/ssl/mesosphere.com.pem
mode http
use_backend nginx-external_10000 if {ssl_fc_sni nginx.external.com}
frontend nginx-external_10000
bind * 10000
mode http
use_backend nginx-external_10000
backend nginx-external_10000
balance roundrobin
mode http
option forwardfor
http-request set-header X-Forwarded-Port% [dst_port]
http-request add-header X-Forwarded-Proto https if {ssl_fc}
option httpchk GET /
timeout check 10s
server 10_0_3_53_31980 10.0.3.53:31980 check inter 2s fall 11Поэтому теперь, если будет запрошен домен nginx.external.com, который предварительно необходимо привязать к серверу HAproxy, запрос будет переадресован на порт и хост задачи на Mesos слейве.
Проверим результат в браузере:
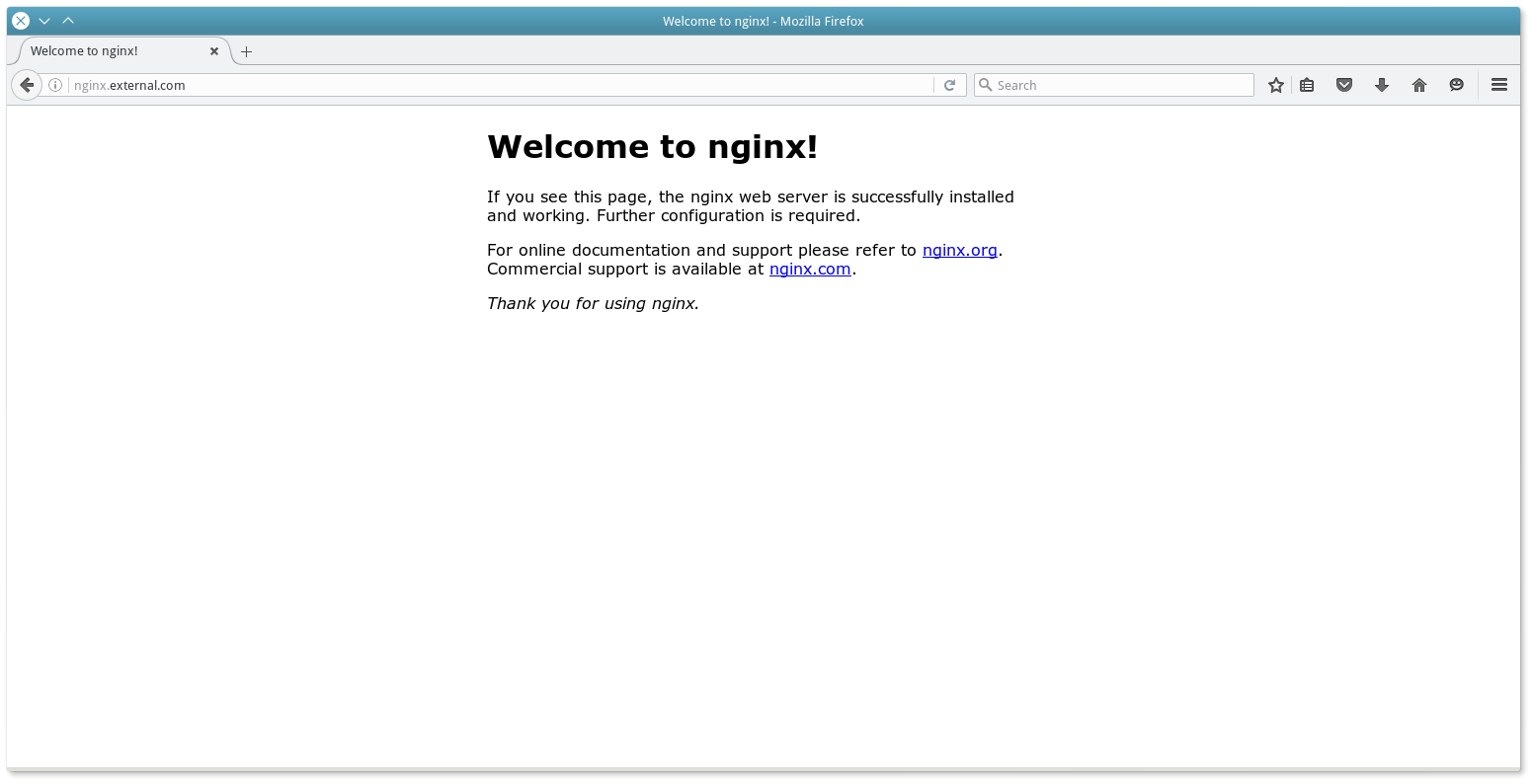
Ярлыки HAproxy также отражаются в Marathon:

Кроме этого, Marathon-lb поддерживает настройки SSL для HAproxy, sticky SSL, а данные для построения haproxy.cfg вообще можно получать не по опросу Marathon по API, а подпиской на Event Bus и т.п.
AUTOSCALING
Тот, кто работал с платформой Amazon AWS, знает эту прекрасную возможность увеличивать или уменьшать количество виртуальных машин в зависимости от нагрузки. Mesos Cluster также имеет такую ??функцию.
Первый вариант реализации — это marathon-autoscale. Скрипт по API Marathon может следить за использованием CPU/памяти задачи и поднимать количество инстансов в зависисмости от заданных условий.
Другой, более интеллектуальный, — marathon-lb-autoscale. Этот вариант основан на опросе Marathon-lb сервиса. В случае превышения определенного уровня запросов в единицу времени — скрипт будет поднимать количество инстансов задачи в Marathon.
Ну вот и все. Надеюсь вы не устали читать все это. Конечно же, в статье могут быть неточности — поэтому небезразличные могут написать об этом в комментариях.
Эта же статья на украинском языке http://blog.ipeacocks.info/2016/06/mesos-cluster-management.html
Ссылки:
Getting Stated
https://www.digitalocean.com/community/tutorials/how-to-configure-a-production-ready-mesosphere-cluster-on-ubuntu-14-04
https://open.mesosphere.com/advanced-course/introduction/
https://open.mesosphere.com/getting-started/install/
http://iankent.uk/blog/a-quick-introduction-to-apache-mesos/
http://frankhinek.com/tag/mesos/
https://mesosphere.github.io/marathon/docs/service-discovery-load-balancing.html
https://mesosphere.github.io/marathon/
https://mesosphere.github.io/marathon/docs/ports.html
https://beingasysadmin.wordpress.com/2014/06/27/managing-docker-clusters-using-mesos-and-marathon/
http://mesos.readthedocs.io/en/latest/
Docker
http://mesos.apache.org/documentation/latest/containerizer/#Composing
http://mesos.apache.org/documentation/latest/docker-containerizer/
https://mesosphere.github.io/marathon/docs/native-docker.html
Mesos-DNS
https://tech.plista.com/devops/mesos-dns/
http://programmableinfrastructure.com/guides/service-discovery/mesos-dns-haproxy-marathon/
http://mesosphere.github.io/mesos-dns/docs/tutorial-systemd.html
http://mesosphere.github.io/mesos-dns/docs/configuration-parameters.html
https://mesosphere.github.io/mesos-dns/docs/tutorial.html
https://mesosphere.github.io/mesos-dns/docs/tutorial-forward.html
https://github.com/mesosphere/mesos-dns
Marathon-lb
https://mesosphere.com/blog/2015/12/04/dcos-marathon-lb/
https://mesosphere.com/blog/2015/12/13/service-discovery-and-load-balancing-with-dcos-and-marathon-lb-part-2/
https://docs.mesosphere.com/1.7/usage/service-discovery/marathon-lb/
https://github.com/mesosphere/marathon-lb
https://dcos.io/docs/1.7/usage/service-discovery/marathon-lb/usage/
Autoscaling
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/cpu-memory/
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/requests-second/
https://github.com/mesosphere/marathon-autoscale
Other
https://clusterhq.com/2016/04/15/resilient-riak-mesos/
https://github.com/CiscoCloud/mesos-consul/blob/master/README.md#comparisons-to-other-discovery-software
http://programmableinfrastructure.com/guides/load-balancing/traefik/
https://opensource.com/business/14/8/interview-chris-aniszczyk-twitter-apache-mesos
http://www.slideshare.net/akirillov/data-processing-platforms-architectures-with-spark-mesos-akka-cassandra-and-kafka
http://www.slideshare.net/mesosphere/scaling-like-twitter-with-apache-mesos
http://www.slideshare.net/subicura/mesos-on-coreos
https://www.youtube.com/watch?v=RciM1U_zltM
http://www.slideshare.net/JuliaMateo1/deploying-a-dockerized-distributed-application-in-mesossos-and-marathon/
http://mesos.readthedocs.io/en/latest/
Docker
http://mesos.apache.org/documentation/latest/containerizer/#Composing
http://mesos.apache.org/documentation/latest/docker-containerizer/
https://mesosphere.github.io/marathon/docs/native-docker.html
Mesos-DNS
https://tech.plista.com/devops/mesos-dns/
http://programmableinfrastructure.com/guides/service-discovery/mesos-dns-haproxy-marathon/
http://mesosphere.github.io/mesos-dns/docs/tutorial-systemd.html
http://mesosphere.github.io/mesos-dns/docs/configuration-parameters.html
https://mesosphere.github.io/mesos-dns/docs/tutorial.html
https://mesosphere.github.io/mesos-dns/docs/tutorial-forward.html
https://github.com/mesosphere/mesos-dns
Marathon-lb
https://mesosphere.com/blog/2015/12/04/dcos-marathon-lb/
https://mesosphere.com/blog/2015/12/13/service-discovery-and-load-balancing-with-dcos-and-marathon-lb-part-2/
https://docs.mesosphere.com/1.7/usage/service-discovery/marathon-lb/
https://github.com/mesosphere/marathon-lb
https://dcos.io/docs/1.7/usage/service-discovery/marathon-lb/usage/
Autoscaling
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/cpu-memory/
https://docs.mesosphere.com/1.7/usage/tutorials/autoscaling/requests-second/
https://github.com/mesosphere/marathon-autoscale
Other
https://clusterhq.com/2016/04/15/resilient-riak-mesos/
https://github.com/CiscoCloud/mesos-consul/blob/master/README.md#comparisons-to-other-discovery-software
http://programmableinfrastructure.com/guides/load-balancing/traefik/
https://opensource.com/business/14/8/interview-chris-aniszczyk-twitter-apache-mesos
http://www.slideshare.net/akirillov/data-processing-platforms-architectures-with-spark-mesos-akka-cassandra-and-kafka
http://www.slideshare.net/mesosphere/scaling-like-twitter-with-apache-mesos
http://www.slideshare.net/subicura/mesos-on-coreos
https://www.youtube.com/watch?v=RciM1U_zltM
http://www.slideshare.net/JuliaMateo1/deploying-a-dockerized-distributed-application-in-mesos
Комментарии (32)

grossws
31.08.2016 13:22+2apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E56151BF
Не используйте short gpg key id и другим не советуйте. Дешевые коллизии на них получили ещё в 2011 году. Сейчас коллизия получается за 4 секунды https://evil32.com/.

arzonus
31.08.2016 14:00Спасибо за статью!
Скажите пожалуйста, используете ли Mesos+Marathon в продакшене?
Ipeacocks
31.08.2016 14:01Да, используем. Но в основном для stateless-сервисов. Базы как и раньше живут на отдельных виртуалках.
arzonus
31.08.2016 14:17А были ли какие нибудь проблемы? Что происходит в случае падения слейва? Маратон поднимает их на других слейвах?
Смотрели в сторону kubernetes?
Имел неприятный опыт от попытки использования Маратона. В azure есть шаблон Mesos+Marathon, которые поднимает машинки и устаналивает. Попытался поднимать контейнеры в Маратоне, ничего не происходило к сожалению.Ipeacocks
31.08.2016 22:08>> А были ли какие нибудь проблемы?
Ну проблемы всегда есть, очень зависит от конечного сервиса, который хотите загнать в контейнер. Плюс, кластер, который сейчас есть у нас проде — не моя затея и я не все знаю.
>> Что происходит в случае падения слейва? Маратон поднимает их на других слейвах?
Да, все так. И даже падение одного из мастеров не приводит к даунтайму.
>> Смотрели в сторону kubernetes?
Особо нет. Знаю только что мультимастер в kubernetes появился совсем недавно.
Попробуйте все повторить по этой статье — уверен, у вас получится :)

kristoferrobin
31.08.2016 20:29а на dcos не пробовали переезжать?
Ipeacocks
31.08.2016 22:09Нет, не пробовали. Да и я не являюсь создателем того кластера, что работает у нас.
Но dcos выглядит неплохо, я должен сказать.

RicoX
31.08.2016 21:06Интересный продукт, если знаете пара вопросов:
1) Что происходит с запущенными процессами при внезапной смерти slave ноды? Процессы перезапустятся на других нодах?
2) Есть ли живая миграция процессов между нодами, скажем нода один сильно загружена а ноды 2 и 3 простаивают, переедут ли процессы автоматом с более нагруженной ноды на менее нагруженную или хотя-бы ручная миграция?
3) Есть ли поддержка механизма fencing/stonith, если например одна из нод, мастер или слейв перезапустилась и после перезапуска работает криво и мешает работе всего кластера, произойдет ли ее принудительно отключение от кластера?
4) Есть ли поддержка изменяемых контейнеров (OpenVZ/LXC), а не только Docker, если да то как обеспечивается сохранность внутренних процессов и данных при крахе ноды, есть лик акая-либо кластерная FS в основе?
5) Сроден предыдущему, для баз данных как-то обеспечивается сохранность данных при выходе из строя одного из узлов? Если мы запустим несколько баз в режиме собственной репликации, можно ли их привязать к конкретным нодам, чтоб запускались только на них?Ipeacocks
31.08.2016 22:35>> Что происходит с запущенными процессами при внезапной смерти slave ноды? Процессы перезапустятся на других нодах?
Да, на других рабочих слейвах. Но при условии, что на нем есть необходимые мощности. Иначе, деплой на Марафоне будет висеть в Waiting состоянии.
>> Есть ли живая миграция процессов между нодами, скажем нода один сильно загружена а ноды 2 и 3 простаивают, переедут ли процессы автоматом с более нагруженной ноды на менее нагруженную или хотя-бы ручная миграция?
Каждому процессу выделяется определенное к-во памяти, и цпу. В случае, если хард ввесь роздан, новые контейнеры (задачи в Марафоне) не будут создаваться (будут висеть в состоянии Waiting) и начнут создаваться только при добавлении дополнительного слейва. Кластер, который будет выбран для каждого следующего контейнера выбирается достаточно случайным образом. Конечно же, если вы хотите высокой доступности — то следует иметь как минимум 2 ноды (на вторую будут переезжать контейнеры первого слейва, в случае ее поломки. Но не нужно забывать, что на втором должны быть мощностя для сервисов с первого слейва). Если вы сразу выделите 3 слейва — то сервисы разойдуться по них достаточно равномерно.
>> 3) Есть ли поддержка механизма fencing/stonith, если например одна из нод, мастер или слейв перезапустилась и после перезапуска работает криво и мешает работе всего кластера, произойдет ли ее принудительно отключение от кластера?
В моем понимании, да, есть. Если падает лидер среди мастеров и потом он же появляется — то возврата назад только по этой причине не будет. Со слейвами все аналогично. Слейв падает — контейнеры расходятся по слейвам, что живы и при появлении старого слейва они уже возвращаться не будут. На появившемся слейве будут пускаться новые задачи Марафона.
>> 4) Есть ли поддержка изменяемых контейнеров (OpenVZ/LXC), а не только Docker, если да то как обеспечивается сохранность внутренних процессов и данных при крахе ноды, есть лик акая-либо кластерная FS в основе?
Насколько я знаю, нет. Да и они не особо нужны, потому что Докер как раз чудесно ложится в парадигму микросервисов и Месоса. Ну т.е. если слейв упадет, то с OpenVZ/LXC миграция данных никак и не произойдет. Т.е. как раз при пересоздании Докер-контейнера мы ничего не потеряем, т.к. наш сервис stateless.
В случае, если вы хотите запускать базы — то есть варианты с отдельным стореджом (Flocker), который будет подключаться к новому контейнеру, в случае падения старого. Ну а образы, которыми управляет Флокер, будут лежать на какой-то кластерной ФС типа Ceph.
>> 5) Сроден предыдущему, для баз данных как-то обеспечивается сохранность данных при выходе из строя одного из узлов? Если мы запустим несколько баз в режиме собственной репликации, можно ли их привязать к конкретным нодам, чтоб запускались только на них?
Как я говорил, есть Флокер, который может при пересоздании контейнера привязывать новому старые данные, что лежат на какой-то кластерной ФС. Но подробностей с репликациями я вам не подскажу. Но думаю с реляционными базами, которые следят за позициями при репликациях, может быть не легко. Я в общем, не все знаю.RicoX
01.09.2016 08:38Спасибо за развернутый ответ, пара неясностей осталась.
>>Если вы сразу выделите 3 слейва — то сервисы разойдуться по них достаточно равномерно.
Вопрос не как они расходятся при запуске, с этим обычно нет проблем ни у одной кластерной системы, но представим ситуацию мы запустили много процессов, они успешно разошлись по нодам, но в какой-то момент часть из них успешно завершилась и возникает ситуация, что одна нода загружена в полку, а остальные простаивают, вот для такой ситуации живая миграция очень необходима.
>>Иначе, деплой на Марафоне будет висеть в Waiting состоянии.
То, есть нельзя указать опционально, что процессы должны запускаться всегда и при любой загрузке, но в случае отсутствия свободных ресурсов, занятые ресурсы перераспределяются пропорционально указанным в них настройкам. То-есть если одному процессу мы дали в настройках 4 ядра и 12 гиг памяти а второму дали 2 ядра и 4 гига, а у нас есть скажем всего 4 ядра и 8 гиг, то процессы все равно должны запуститься оба, но первый возьмет 3 ядра и 6 гигов, а второй оставшиеся? Часто некоторые процессы требуют много ресурсов очень эпизодически в остальное время они им не нужны и нет смысла их жестко бронировать за процессом.
>> Докер как раз чудесно ложится в парадигму микросервисов и Месоса
Не всегда, иногда микросервис требует более полного воссоздания окружения, когда в один контейнер мы запихиваем несколько процессов вместе с их взаимосвязью, плюс имеем изменяемую ФС (не все сервисы умеют писать все свои изменения в БД) на время работы контейнера, так как нам нужно чтоб он сохранял свое состояние после перезапуска, бывает что возможностей докера без костылей для этого не хватает, а тот-же OVZ или LXC прекрасно с этим справляются.Ipeacocks
01.09.2016 14:11>>> но представим ситуацию мы запустили много процессов, они успешно разошлись по нодам, но в какой-то момент часть из них успешно завершилась и возникает ситуация, что одна нода загружена в полку, а остальные простаивают, вот для такой ситуации живая миграция очень необходима.
одна нода не загружена так чтобы это мешало работе других контейнеров (задач) на этой же ноде. В Месосе нет овершаринга ресурсов, т.е. роздается только то количество мощностей, которое есть. То что прям вы спрашиваете — не факт, что возможно и я не совсем понимаю зачем это нужно. Если вы захотите убрать работающий слейв — то при наличии мощностей на других слейвах — они туда и мигрируют.
>>Иначе, деплой на Марафоне будет висеть в Waiting состоянии.
То, есть нельзя указать опционально, что процессы должны запускаться всегда и при любой загрузке, но в случае отсутствия свободных ресурсов, занятые ресурсы перераспределяются пропорционально указанным в них настройкам. То-есть если одному процессу мы дали в настройках 4 ядра и 12 гиг памяти а второму дали 2 ядра и 4 гига, а у нас есть скажем всего 4 ядра и 8 гиг, то процессы все равно должны запуститься оба, но первый возьмет 3 ядра и 6 гигов, а второй оставшиеся? Часто некоторые процессы требуют много ресурсов очень эпизодически в остальное время они им не нужны и нет смысла их жестко бронировать за процессом.
Как я это все понимаю, нет, нельзя. Но я могу что-то не знать. По-дефолту это так.
>>> Не всегда, иногда микросервис требует более полного воссоздания окружения
Значит ваш докерфайл должен описывать вот это все и сетапаться со всем необходимым. Все дополнительные данные должны копироваться в новый контейнер или же монтироваться и перетаскиваться каким-то флокером, в случае падения контейнера.
>>> бывает что возможностей докера без костылей для этого не хватает, а тот-же OVZ или LXC прекрасно с этим справляются.
Опишите конкретный кейс.kristoferrobin
01.09.2016 14:55>>>Как я это все понимаю, нет, нельзя. Но я могу что-то не знать. По-дефолту это так.
разумеется что нельзя, логично же — почти всем нодам нельзя стартовать с меньшими ресурсами, потому если указано что ноде надо 8гб, то ей надо 8 гб и стартовать ее с 6 нельзя.
если эпизодически нужны ресурсы это называется autoscale — https://github.com/mesosphere/marathon-autoscale
в общем если коротко — выделяя ресурсов на ноду в марафоне больше, чем ему надо, в расчете на эпизодическую нагрузку, вы явно что-то не так делаете в плане архитектуры приложения. лучше 2 ноды по 4 гб чем 1 на 8. а еще лучше 3 по 2RicoX
01.09.2016 17:53Из живого примера что пришло на ум. Биллинг ISP:
1) Демона самой биллинг системы
2) Mysql база данных
3) Redis база данных
4) Nginx+HHVM
5) Radius сервер
6) Около 10 демонов шлюзов для взаимодействия с платежными терминалами типа киви.
7) ERP интегрированная с ядром биллинга, в ней же тикетсистема с собственной базой, десятком демонов (связь с телефонией, 1С и т.п.) при этом обновления для ERP части выходят примерно раз в неделю.
Коротче штук 30 процессов которые логично держать в рамках единого контейнера и бэкапить целиком, а не по частям, для воссоздания образа всей системы на определенный момент времени в случаи краха. В докер в теории можно все это засунуть, сторадж под mysql, сторадж под редис, стораджу для логов работы скриптов и радиуса, остальное каждый процесс в свой контейнер, но поддерживать это все и восстановить на определенный момент времени — это будет ад.
По поводу эпизодической нагрузки, есть контейнеры выполняющие например суточный, месячный годовой рассчеты бухгалтерии, соответственно суточный грузит систему около 40 минут в сутки, остальное время почти не нагружает, месячный около 7 часов в месяц и так далее, то-есть ресурсы нужны эпизодически, но сразу много, разделить на несколько процессов это не выйдет, так как единый процесс производит рассчеты и генерацию отчетов. Для того же OVZ это не проблема, он может динамически управлять ресурсами в процентном соотношении от доступных, что намного удобней и логичней чем статическая привязка к определенным параметрам, коротче задачи не девопс, по этому докер — как сову на глобус местами натягивать, можно, но усложняет обслуживание вместо упрощения.kristoferrobin
01.09.2016 18:02+2да ну, зачем сюда мезос+марафон? мезос с марафоном крут когда на него деплоят микросервисы, вот тут он себя показывает. пихать в него такую систему поиметь головную боль на ровном месте, имхо.
у нас на нем живет куча микросервисов на Java 8+ Vert.х, у которых в качестве кеша hazelcast, бд Cassandra, а вертксовый эвентбас подружен с Confluent(он же допиленный Kafka) и вся эта хрень логгируется в graylog2, тобишь ориентировано все на кластеризациюRicoX
01.09.2016 18:30Потому что это все и еще куча различных систем ща живет в кластере на OpenVZ с ядром 2.6 который и прекрасно работает, в смысле выпадение любой из нод не сказывается на жизни системы, в качестве ФС — Ceph. Но есть такая неприятность, что новые версии ОС не поддерживаются в OpenVZ прошлого поколения, а вот с OpenVZ 7 есть ряд косяков, они перешли на prlctl вместо vzctl, который кусок кода virtuozzo и большая часть необходимого функционала теперь не доступна, хотите функционал — купите virtuozzo (ценообразование там либо под откаты либо просто не вменяемо дорого), иначе в системе нет даже банальных бэкапов. Вот и стоим перед проблемой, на что нам мигрировать пол сотни контейнеров в OVZ, если считать в докерах, то будет пару тысяч процессов, причем не очешуеть обслуживать все это и поддерживать. Для девопса — выбор докера очевиден, а вот для продакшина предпочтительней полноценные контейнеры с ОС внутри и сохранением состояния, пока что в поиске.
Ipeacocks
01.09.2016 23:13Без разделения всего на отдельные части нет никакого смысла юзать Mesos или Kubernetes. Тут как раз суть в том, что каждый контейнер имеет только необходимый минимум: отдельно нджинкс, отдельно база, отдельно ПХП. Все комуникации в основном происходят по сетевому стеку. Если же вы хотите жить по-старому — то почему не что-то типа Proxmox-a?
Ну т.е. я не говорю о том, что Месос необходим всем, это вовсе не так. Я говорю о том, что это немного другой способ организации инфраструктуры программ.RicoX
02.09.2016 08:28то почему не что-то типа Proxmox-a
С радостью бы, но ProxMox 3 уже не поддерживается и имеет тот же OVZ c ядром 2.6, казалось бы выбор Proxmox 4, который перешел на LXC, но тут загвозтка в стабильности, которой просто нет, мы пару недель гоняли его на тестовом кластере — это просто ужасно, без преувеличений, на данный момент он не готов для продакшина, может и допилят через пару лет, но пока вот так https://habrahabr.ru/post/278877/ итого пока выбор выглядит очень не радостно: Proxmox 4 — не стабилен, OVZ 7 — не достаточно базовых возможностей, урезано много основного, чтоб подстегнуть к покупке Virtuozzo 7, который распространяется по подписке с платой за каждый контейнер и сам по себе дорогой, тестовый кластер на всего 3 ноды и 20 контейнеров нам посчитали в 540$ в месяц, причем на данный момент это только зарелизившийся продукт без комьюнити. Да еще есть LXD — на данный момент не умеет живую миграцию, но вроди как обещают скоро допилить, может что упустил, но вся контейниризация уходит в сторону докера, вот и испытываю муки выбора, просматривая все более-менее похожее с попыткой хотя-бы мысленно адаптировать под мои задачи.kristoferrobin
02.09.2016 08:56ну тут из того что я знаю ближе всего coreos, полноценная ос и работать можно с серверами как с контейнерами
Ipeacocks
02.09.2016 13:05Вероятно тогда вам стоит ждать стабилизации кода-фич LXC. Или же переходить на Proxmox + KVM
RicoX
02.09.2016 14:02KVM дает лишний оверхед, в плане виртуалок вариантов море, у нас есть кластер на сфере и вся виртуализация там, тут именно контейнеры нужны, вот и ждем стабилизации, попутно подбирая другие варианты, может что подойдет.
Ipeacocks
02.09.2016 14:27Ну имхо конечно, LXC я в проде не использовал, но OpenVZ как раз был самой доделанной контейнеризацией. Посидите тогда еще намного на старом OpenVZ, и ждите стабилизации.
RicoX
02.09.2016 14:37Так и делаем, OVZ по стабильности очень хорошо допиленный продукт, пока использование новых ОС стоит не очень остро — будем сидеть на нем, там где требуются новые версии ОС, пока будем виртуалить на сфере и ждать когда один из вариантов контейнеризации ОС на современных ядрах будет более-менее стабилен. OVZ 7 тоже в принципе не плох, в плане скорости работы очень понравился, но вот насильное впихивание в него кусков от коммерческого продукта не пошло на пользу проекту, т.к. теперь это не самостоятельный продукт, а демо-версия virtuozzo, которая не годится для продакшина. На докер и производные пытались перейти несколько раз уже, но никак идеология один процесс — один контейнер не ложится на нашу структуру.
Ipeacocks
02.09.2016 15:35А что конкретно не так в OVZ 7? Что испортили?
RicoX
02.09.2016 20:19Бэкапы есть только в платной версии — это самое критичное, остальное скорее придирки, управление кластером есть только в платной версии и то в стадии разработки, система миграции из старого в новый OVZ можно считать не работает, она есть но я в качестве теста пытался перенести с 10 контейнеров, 9 не переехали корректно и требовали ручной допилки, живая миграция только для платного их же стораджа. Вообще сравнение есть тут https://openvz.org/Comparison
Ipeacocks
02.09.2016 19:26Ну и КВМ не такой уж и оверхед дает. И плюс контейнеры не дают такого же уровня безопасности. Но контейнеры значительно удобней админить, это да.
RicoX
02.09.2016 20:23Если мы раздаем контейнеры всему миру, аля VDS, то нас это парит, если мы используем только внутри своей инфраструктуры где безопасность обеспечивается на уровне самого гипервизора плюс отдельная защита периметра, то нет особой разницы КВМ или ОВЗ, главное удобство админства, тут контейнерам нет равных. Виртуалки тоже используем, но тут есть где развернуться, в принципе возможности сферы покрывают все необходимые задачи и в КВМ просто нет нужды, хотя на других проектах использовал и КВМ с виртио дровами вполне неплохая производительность.
kristoferrobin
01.09.2016 09:10+1мы реляционные субд(постгрес) менеджим в рамках persistent volume'ов(http://mesos.apache.org/documentation/latest/persistent-volume/), пока полет нормальный. а под этими volume'мами просто гластер. в конфиге контейнера в марафоне указать что конкретно этот контейнер работает с этим разделом и все.
не то чтобы фанат реляционных субд в докере, но в такой связке пока проблем не былоRicoX
01.09.2016 10:18Интересный вариант, надо попробовать на стенде погонять по стабильности, а то ценовая политика Virtuozzo 7 меня крайне огорчает, так что с OpenVZ придется куда-то уходить, вот ищу вариант куда с наименьшим геморроем в плане миграции.
kristoferrobin
01.09.2016 10:26есть жеж coreos(https://coreos.com), интересная штука. инстанс рестартует ~ 10 секунд, работает нормально, fleet(https://coreos.com/fleet/docs/latest/launching-containers-fleet.html) вообще изумительная вещь, если научиться готовить. мы юзаем coreos, поверх dc/os с марафоном, сервис дискавери через vip(https://docs.mesosphere.com/1.7/usage/service-discovery/virtual-ip-addresses/) — работает супер, есть идея заморочиться с rkt и flannel и заменить dc/os вообще, но подкупает коробочность, допиливать по минимуму приходится.
стабильность зависит от кол-ва инстансов, оно же мажется. будет нормально ресурсов для подхвата — оно впринципе неубиваемо
celebrate
Спасибо, интересная статья!