Публикую перевод моей статьи из блога ГитЛаба про то как начать использовать CI. Остальные переводы гитлабовских постов можно найти в блоге компании Softmart.
Представим на секунду, что вы не знаете ничего о концепции непрерывной интеграции (Continuous Integration — CI) и для чего она нужна. Или вы всё это забыли. В любом случае, начнем с основ.
Представьте, что вы работаете над проектом, в котором вся кодовая база состоит из двух текстовых файлов. Более того, очень важно, чтобы при конкатенации этих файлов в результате всегда получалась фраза "Hello world." Если это условие не выполняется, вся команда лишается месячной зарплаты. Да, все настолько серьезно.

Один ответственный разработчик написал небольшой скрипт, который нужно запускать перед каждой отправкой кода заказчикам. Скрипт нетривиален:
cat file1.txt file2.txt | grep -q "Hello world"Проблема в том, что в команде десять разработчиков, а человеческий фактор еще никто не отменял.
Неделю назад один новичок забыл запустить скрипт перед отправкой кода, в результате чего трое заказчиков получили поломанные сборки. Хотелось бы в дальнейшем избежать подобного, так что вы решаете положить конец этой проблеме раз и навсегда. К счастью, ваш код уже находится на GitLab, а вы помните про встроенную CI-систему. К тому же, на конференции вы слышали, что CI используется для тестирования...
Запуск первого теста в CI
После пары минут, потраченных на поиск и чтение документации, оказывается, что все что нужно сделать — это добавить две строчки кода в файл .gitlab-ci.yml:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'Добавляем, коммитим — и ура! Сборка успешна!
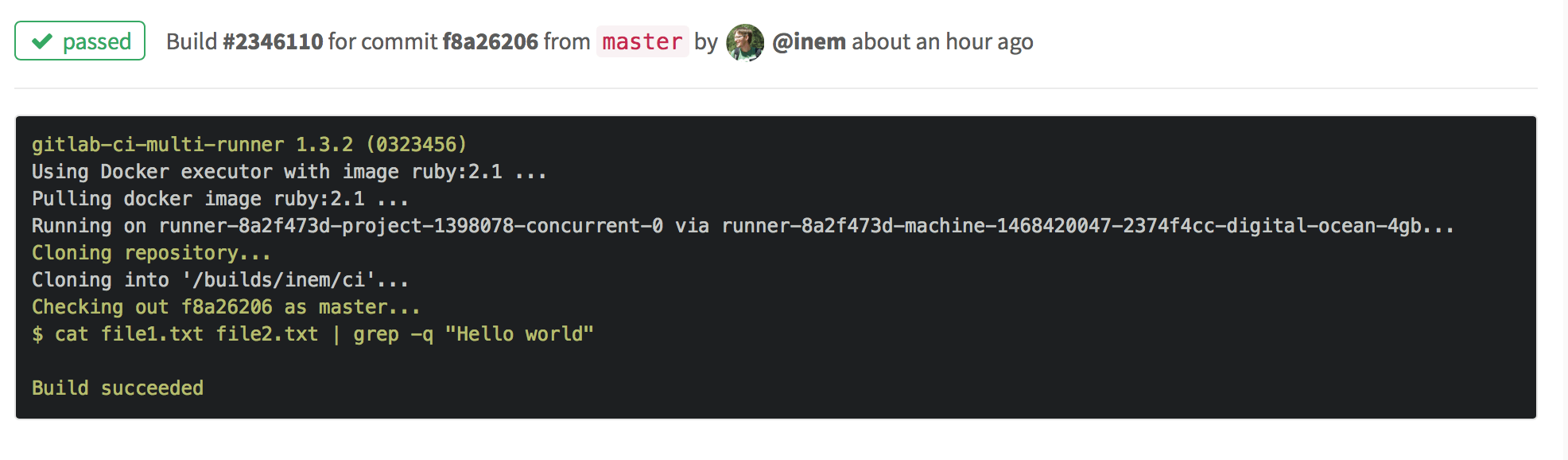
Поменяем во втором файле "world" на "Africa" и посмотрим, что получится:
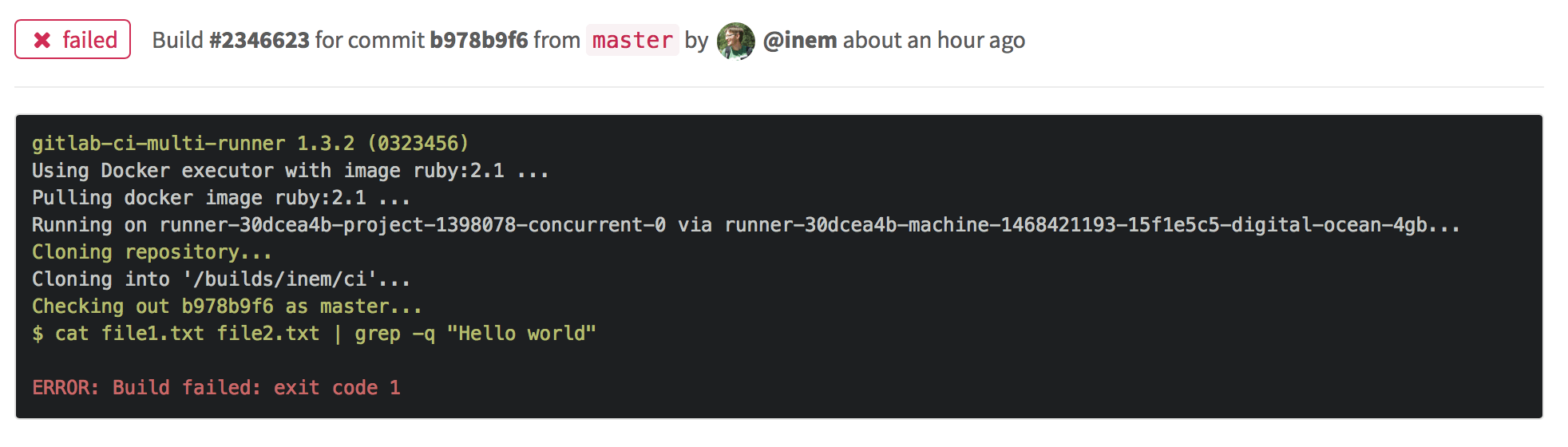
Сборка неудачна, как и ожидалось.
Итак, у нас теперь есть автоматизированные тесты. GitLab CI будет запускать наш тестовый скрипт при каждом пуше нового кода в репозиторий.
Возможность загрузки результатов сборки
Следующим бизнес-требованием является архивация кода перед отправкой заказчикам. Почему бы не автоматизировать и его?
Все, что для этого нужно сделать — определить еще одну задачу для CI. Назовем ее "package":
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > package.gzВ результате появляется вторая вкладка
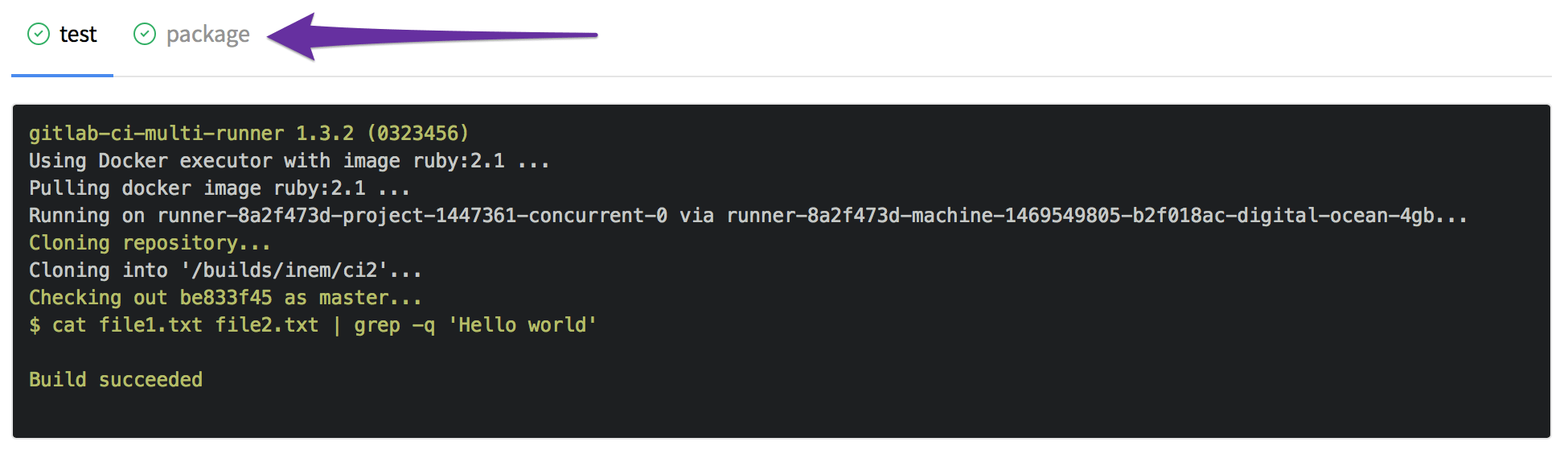
Однако мы забыли уточнить, что новый файл является артефактом сборки, что позволит его скачивать. Это легко поправить, добавив раздел artifacts:
test:
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gzПроверяем… Все на месте:
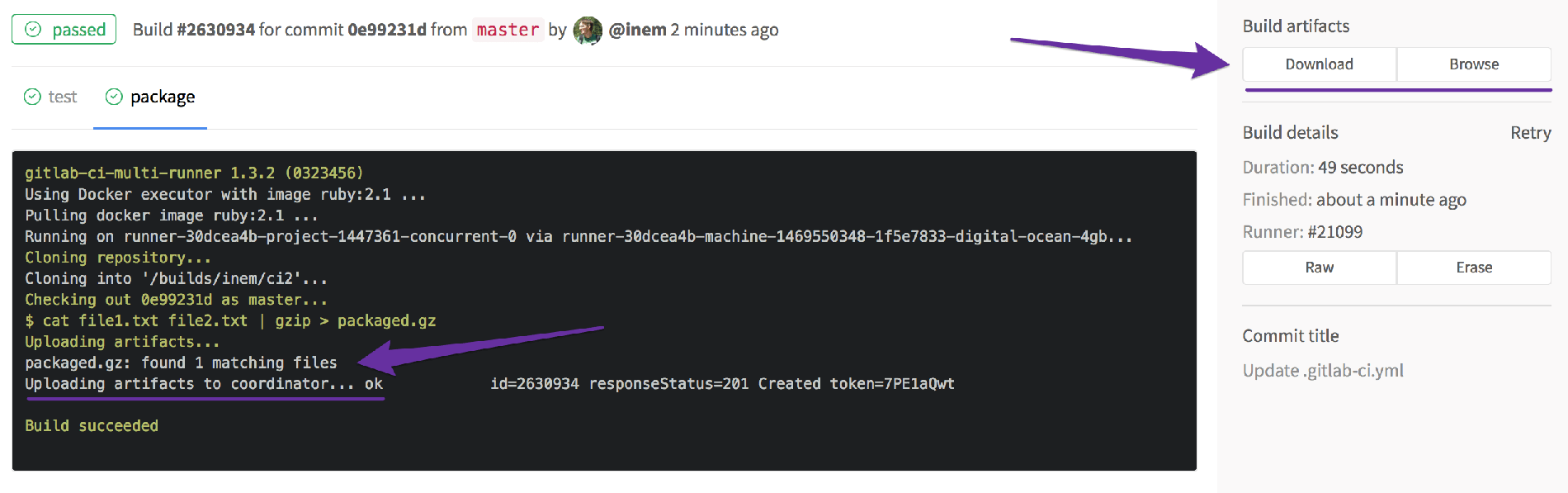
Отлично! Однако, осталась одна проблема: задачи выполняются параллельно, а нам не нужно архивировать наше приложение в случаях, когда тест не пройден.
Последовательное выполнение задач
Задача 'package' должна выполняться только при успешном прохождении тестов. Определим порядок выполнения задач путем введения стадий (stages):
stages:
- test
- package
test:
stage: test
script: cat file1.txt file2.txt | grep -q 'Hello world'
package:
stage: package
script: cat file1.txt file2.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gzДолжно сработать.
Также не стоит забывать о том, что компиляция (которой в нашем случае является конкатенация файлов) занимает время, поэтому не стоит проводить ее дважды. Введем отдельную стадию для компиляции:
stages:
- compile
- test
- package
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
package:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gzПосмотрим на получившиеся артефакты:

Скачивание файла "compile" нам ни к чему, поэтому ограничим длительность жизни временных артефактов 20 минутами:
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutesИтоговая функциональность конфига впечатляет:
- Есть три последовательных стадии: компиляция, тестирование и архивация приложения.
- Результат стадии компиляции передается на последующие стадии, то есть приложение компилируется только однажды (что ускоряет рабочий процесс).
- Архивированная версия приложения хранится в артефактах сборки для дальнейшего использования.
Какие образы Docker лучше использовать
Прогресс налицо. Однако, несмотря на наши усилия, сборка до сих пор проходит медленно. Взглянем на логи:
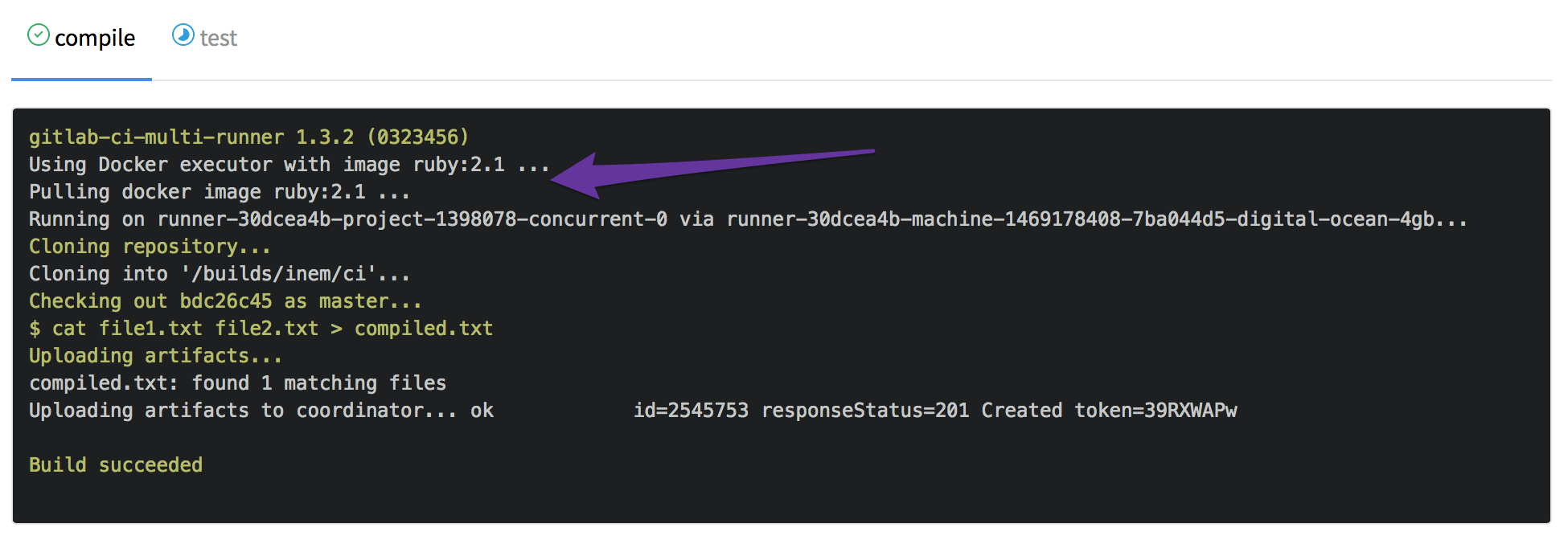
Что, простите? Ruby 2.1?
Зачем тут вообще Ruby? А затем, что GitLab.com использует образы Docker для запуска сборок, а по умолчанию для этого используется образ ruby:2.1. Само собой, в этом образе содержится множество пакетов, которые нам ни к чему. Спросив помощи у гугла, узнаем, что существует образ alpine, который представляет собой практически «голый» образ Linux.
Для того, чтобы использовать этот образ, добавим image: alpine в .gitlab-ci.yml.
Благодаря этому время сборки сокращается почти на три минуты:

А вообще, в свободном доступе находится довольно много разных образов, так что можно без проблем подобрать один для нашего стека. Главное — помнить о том, что лучше подходят образы, не содержащие дополнительной функциональности — такой подход минимизирует время скачивания.
Работа со сложными сценариями
Теперь представим, что у нас появился новый заказчик, который хочет, чтобы вместо .gz архива наше приложение поставлялось в виде образа .iso. Поскольку весь процесс сборки реализован через CI, все, что нам нужно сделать — добавить еще одну задачу. Образы ISO создаются с помощью команды mkisofs. В итоге конфигурационный файл должен выглядеть следующим образом:
image: alpine
stages:
- compile
- test
- package
# ... задания "compile" и "test" в данном примере пропущены ради краткости
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
script:
- mkisofs -o ./packaged.iso ./compiled.txt
artifacts:
paths:
- packaged.isoОбратите внимание на то, что названия задач не обязательно должны быть одинаковыми. Более того, в таком случае параллельное выполнение задач на одной стадии было бы невозможным. Так что относитесь к одинаковым названиям задач и стадий как к совпадению.
А тем временем сборка не удалась:

Проблема в том, что конманда mkisofs не входит в состав образа alpine, так что нужно установить ее отдельно.
Установка дполнительного ПО
На сайте Alpine Linux указано, что mkisofs входит в состав пакетов xorriso и cdrkit. Для установки пакета нужно выполнить следующие команды:
echo "ipv6" >> /etc/modules # включить поддержку сети
apk update # обновить список пакетов
apk add xorriso # установить пакетВсе это — тоже валидные команды CI. Полный список команд в разделе script должен выглядеть следующим образом:
script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
- mkisofs -o ./packaged.iso ./compiled.txtС другой стороны, семантически более корректно выполнять команды, ответственные за установку пакетов до раздела script, а именно в разделе before_script. При размещении этого раздела в верхнем уровне файла конфигурации, его команды будут выполнены раньше всех задач. Однако в нашем случае достаточно выполнить before_script раньше одной определенной задачи.
Итоговая версия .gitlab-ci.yml:
image: alpine
stages:
- compile
- test
- package
compile:
stage: compile
script: cat file1.txt file2.txt > compiled.txt
artifacts:
paths:
- compiled.txt
expire_in: 20 minutes
test:
stage: test
script: cat compiled.txt | grep -q 'Hello world'
pack-gz:
stage: package
script: cat compiled.txt | gzip > packaged.gz
artifacts:
paths:
- packaged.gz
pack-iso:
stage: package
before_script:
- echo "ipv6" >> /etc/modules
- apk update
- apk add xorriso
script:
- mkisofs -o ./packaged.iso ./compiled.txt
artifacts:
paths:
- packaged.isoА ведь мы только что создали конвейер! У нас есть три последовательные стадии, при этом задачи pack-gz и pack-iso стадии package выполняются параллельно:

Подводя итоги
В этой статье приведены далеко не все возможности GitLab CI, однако пока что остановимся на этом. Надеемся вам понравился этот небольшой рассказ. Приведенные в нем примеры были намеренно тривиальными — это было сделано для того, чтобы наглядно показать принципы работы CI не отвлекаясь на незнакомые технологии. Давайте подытожим изученное:
- Для того, чтобы передать выполнение определенной работы в GitLab CI, нужно определить одну или более задач в
.gitlab-ci.yml. - Задачам должны быть присвоены названия, советуем делать их осмысленными, чтобы потом самим не запутаться.
- В каждой задаче содержится набор правил и инструкций для GitLab CI, определяющийся ключевыми словами.
- Задачи могут выполняться последовательно, параллельно, либо вы можете задать свой собственный порядок выполнения, создав конвейер.
- Существует возможность передавать файлы между заданиями и сохранять их как артефакты сборки для последующего скачивания через интерфейс.
В последнем разделе этой статьи приведен более формализованный список терминов и ключевых слов, использованных в данном примере, а также ссылки на подробные описания функциональности GitLab CI.
Описания ключевых слов и ссылки на документацию
| Ключевое слово/термин | Описание |
|---|---|
| .gitlab-ci.yml | Конфигурационный файл, в котором содержатся все определения сборки проекта |
| script | Определяет исполняемый shell-скрипт |
| before_script | Определяет команды, которые выполняются перед всеми заданиями |
| image | Определяет используемый Docker-образ |
| stage | Определяет стадию конвейера (test по умолчанию) |
| artifacts | Определяет список артефактов сборки |
| artifacts:expire_in | Используется для удаления загруженных артефактов по истечению определенного промежутка времени |
| pipeline | Конвейер — набор сборок, которые выполняются стадиями |
Также обратите внимание на другие примеры работы с GitLab CI:
- Migrating from Jenkins to GitLab CI
- Decreasing build time from 8 minutes 33 seconds to just 10 seconds
(Автор перевода — sgnl_05)
Комментарии (17)

past
07.09.2016 12:43Подскажите, можно ли иметь единый .gitlab-ci.yml для всех веток?

ivanych
07.09.2016 13:19Так это же просто файл в репозитории. Он одинаковый во всех ветках. Как он может быть разным? Если только Вы специально измените его в конкретной ветке, но зачем это делать, если Вам как-раз надо, чтобы он был одинаковым.
past
07.09.2016 14:32+1И еще вопрос, можно как-то динамически формировать имя артефакта?
У меня после сборки получается файл package-${version}-${release}.el7.centos.${arch}.rpm при чем переменные вычисляются в процессе сборки.
DAiMor
07.09.2016 22:33Можно самому упаковать папку и задать имя на основе переменных, есть ряд переменных которые gitlab сам формирует
если переменные вычисляются, то они могут попасть в переменные окружения и использоваться для формирования имени
нужно учитывать что блок scripts, это команды операционной системы и выбранного шелла, да ведь раннер может быть и на винде и команды могут быть powershell

utoplenick
07.09.2016 16:51Было бы неплохо рассказать и о раннерах, раз уж зашла речь про gitlab-ci, потому как в данном примере совсем непонятно зачем вообще нужен докер чтобы грепнуть файл? Понятно что пример простой, а статья — переводю

hippoage
08.09.2016 11:51+1Функционала меньше, чем в Jenkins (это нормально, нужно учитывать):
— нет постоянных ссылок на скачивание последних артефактов (latest, а не номер билда; удобно для скриптов бутстрапа, например)
— вроде бы в последних версиях ручной запуск появился, но нет параметризированного запуска (может и не нужно, можно тот же список серверов забить в файл отдельными ручными работами, но нужно учитывать при проектировании)
— нет работ не привязанных к ветке/репозитарию (из-за этого придется для некоторых вещей сохранить Jenkins)
— нотификации (типа интеграции со слаком) идут вне файла настройки ci
Текущие минусы:
— долго промучился, но команды сборки докера в докере не заработали (ни docker in docker, который не предназначен для систем CI и постоянно в документации Gitlab CI упоминается; ни пробрасывание сокета докера), использую отдельный shell runner для этого.
— кеширует только после успешного завершения работы (например, пока настраиваешь работу каждый раз качает плагины maven)
— медленно (пофайлово?) сохраняет кеш
— нет способа через UI сбросить кеш и посмотреть какие кеши есть. все-таки кеши время от времени приходится сбрасывать
— по ощущениям собирает медленней Jenkins, относительно долго (секунд 15) запускается любая докер-работа с одной командой echo
— нет готового рецепта для Java/Maven, что-то настроил, но еще не все
В целом, удобно, что интегрировано, но еще сыро.

fshp
08.09.2016 16:46Можно ли указать в качестве зависимости другой проект, что бы он тоже подтянулся для сборки?
И можно ли шарить артефакты между проектами?

ALexhha
08.09.2016 17:22Такой вопрос, стокнулся с казалось бы тривиальной задачей в Jenkins — необходимо запускать job при попадании нового тега (с определенным именем, например
build_[0-9]{6,10}). Казалось бы все должно быть очень просто, а на деле оказалось что нет. Например у нас есть следующая история
550313e -> 22ce31f -> e31e663 -> e4c4bf6 (head) tag2 tag3 tag4 tag1
Так вот в Jenkins cборка будет запущена только для head, для остальных 3х тегов она будет игнорироваться. Можно ли в gitlab ci обеспечить сборку в любом "направлении", чтобы при командах
$ git tag build_000001 e4c4bf6 $ git tag build_000002 550313e $ git tag build_000003 22ce31f $ git tag build_000004 e31e663
я получил в итоге 4 билда?
ivanych
12.09.2016 15:18Ничего из описанного не работает:( Вообще не запускается, появляется значок «pending» и всё.
Я так понимаю, нужен некий раннер. Какой минимум нужно сделать, чтобы запустить хотя бы самый простейший тест?
ivanych
А для чего указывать артефакт в задаче compile? Файл compiled.txt понятно, он нам будет нужен в следующих задачах. А зачем его описывать как артефакт?
nem
artifacts используется и для передачи файлов между stages, и для попадания в downloadable artifacts. Возможно это поменятся, но пока так.
ivanych
А что значит «для передачи файлов между stages»?
В следующих стадиях/задачах используется имя файла compiled.txt. Я так понимаю, это тот самый файл compiled.txt, который создался в задаче compile. Вот просто создался он в задаче compile и лежит себе, а в следующих задачах мы к нему обращаемся.
Без указания артефакта мы не сможем обратиться в нему в следующей задаче? Он будет удален по окончанию задачи compile? А указание артефакта это типа «поставить галочку, что этот файл удалять не надо»?
abogoyavlensky
Разные задачи могут выполняться на разных раннерах, поэтому нужно передавать артефакты.
ivanych
А вот в обсуждаемой статье — используется один раннер? В одном раннере сработает обращение к файлу без указания артефакта?
DAiMor
В статье не указано ничего о том что только один раннер, каждая задача выполняется независимо, есть раннер которые его выполняет. раннеры бывают разные, можно использовать те что бесплатно предоставлены gitlab там их сейчас два, физически они в DigitalOcean
раннеры можно и свои запустить, linux, macos или windows, раннер этот может и не использовать докер вообще, а только локально выполнять команды
поэтому и нужна возможность перетягивать файлы между задачами, но при этом весь репозиторий клонируется на всех задачах