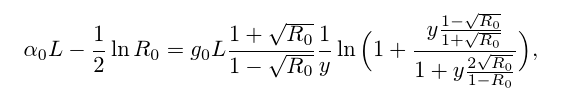
В чём профит? Ответ прост: мне нужно было запрогать нахождение минимума достаточно сложной функции, считать производные этой функции по её параметрам ручкой на бумажке было лень, проверять потом, что я не опечатался при написании кода, и поддерживать этот самый код — лень вдвойне, поэтому было решено написать штуковину, которая это сделает за меня. Ну, чтобы в коде можно было написать что-то такое:
using Formula_t = decltype (k * (_1 - r0) / (_1 + r0) * (g0 / (alpha0 - logr0 / Num<300>) - _1)); // сама формула
const auto residual = Formula_t::Eval (datapoint) - knownValue; // регрессионный остаток
// производные по параметрам:
const auto dg0 = VarDerivative_t<Formula_t, decltype (g0)>::Eval (datapoint);
const auto dalpha0 = VarDerivative_t<Formula_t, decltype (alpha0)>::Eval (datapoint);
const auto dk = VarDerivative_t<Formula_t, decltype (k)>::Eval (datapoint);Вместо крокодилов, которые получатся, если брать частные производные функции на картинке вначале (вернее, некоторого её упрощённого варианта, но он выглядит не так страшно).
Ещё неплохо быть достаточно уверенным, что компилятор это соптимизирует так, как если бы соответствующие производные и функции были написаны руками. А уверенным быть бы хотелось — находить минимум нужно было очень много раз (действительно много, где-то от сотни миллионов до миллиарда, в этом была суть некоего вычислительного эксперимента), поэтому вычисление производных было бы бутылочным горлышком, происходи оно во время выполнения через какую-нибудь рекурсию по древообразной структуре. Если же заставить компилятор вычислять производную, собственно, во время компиляции, то есть шанс, что он по получившемуся коду ещё пройдётся оптимизатором, и мы не потеряем по сравнению с ручным выписыванием всех производных. Шанс реализовался, кстати.
Под катом — небольшое описание, как оно там всё работает.
Начнём с представления функции в программе. Почему-то так получилось, что каждая функция — это тип. Функция — это ещё и дерево выражений, и узел этого дерева представляется типом
Node:template<typename NodeClass, typename... Args>
struct Node;Здесь
NodeClass — тип узла (переменная, число, унарная функция, бинарная функция), Args — параметры этого узла (индекс переменной, значение числа, дочерние узлы).Узлы умеют себя дифференцировать, печатать и вычислять для данных значений свободных переменных и параметров. Так, если определен тип для представления узла с обычным числом:
using NumberType_t = long long;
template<NumberType_t N>
struct Number {};то специализация узла для чисел тривиальна:
template<NumberType_t N>
struct Node<Number<N>>
{
template<char FPrime, int IPrime>
using Derivative_t = Node<Number<0>>;
static std::string Print ()
{
return std::to_string (N);
}
template<typename Vec>
static typename Vec::value_type Eval (const Vec&)
{
return N;
}
constexpr Node () {}
};Производная любого числа по любой переменной — ноль (за это отвечает тип
Derivative_t, оставим пока его шаблонные параметры). Распечатать число — тоже просто (см. Print()). Вычислить узел с числом — вернуть это число (см. Eval(), шаблонный параметр Vec обсудим позже). Переменная представляется похожим образом:
template<char Family, int Index>
struct Variable {};Здесь
Family и Index — «семейство» и индекс переменной. Так, для  они будут равняться
они будут равняться 'w' и 1, а для  —
— 'x' и 2 соответственно.Узел для переменной определяется чуть интереснее, чем для числа:
template<char Family, int Index>
struct Node<Variable<Family, Index>>
{
template<char FPrime, int IPrime>
using Derivative_t = std::conditional_t<FPrime == Family && IPrime == Index,
Node<Number<1>>,
Node<Number<0>>>;
static std::string Print ()
{
return std::string { Family, '_' } + std::to_string (Index);
}
template<typename Vec>
static typename Vec::value_type Eval (const Vec& values)
{
return values (Node {});
}
constexpr Node () {}
};Так, производная переменной по ей же самой равна единице, а по любой другой — нулю. Собственно, параметры
FPrime и IPrime для типа Derivative_t — это семейство и индекс переменной, по которой требуется взять производную.Вычисление значения функции, состоящей из одной переменной сводится к её нахождению в словаре значений
values, который передаётся в функцию Eval(). Словарь сам умеет находить значение нужной переменной по её типу, поэтому ему мы просто передадим тип нашей переменной и вернём соответствующее значение. Как словарь это делает, мы рассмотрим позже.С унарными функциями всё становится ещё интереснее.
enum class UnaryFunction
{
Sin,
Cos,
Ln,
Neg
};
template<UnaryFunction UF>
struct UnaryFunctionWrapper;В специализации
UnaryFunctionWrapper мы запихнём логику по взятию производных каждой конкретной унарной функции. Чтобы минимально дублировать код, будем брать производную унарной функции по её аргументу, за дальнейшее дифференцирование аргумента по целевой переменной через chain rule будет отвечать вызывающий код:template<>
struct UnaryFunctionWrapper<UnaryFunction::Sin>
{
template<typename Child>
using Derivative_t = Node<Cos, Child>;
};
template<>
struct UnaryFunctionWrapper<UnaryFunction::Cos>
{
template<typename Child>
using Derivative_t = Node<Neg, Node<Sin, Child>>;
};
template<>
struct UnaryFunctionWrapper<UnaryFunction::Ln>
{
template<typename Child>
using Derivative_t = Node<Div, Node<Number<1>>, Child>;
};
template<>
struct UnaryFunctionWrapper<UnaryFunction::Neg>
{
template<typename>
using Derivative_t = Node<Number<-1>>;
};Тогда сам узел выглядит следующим образом:
template<UnaryFunction UF, typename... ChildArgs>
struct Node<UnaryFunctionWrapper<UF>, Node<ChildArgs...>>
{
using Child_t = Node<ChildArgs...>;
template<char FPrime, int IPrime>
using Derivative_t = Node<Mul,
typename UnaryFunctionWrapper<UF>::template Derivative_t<Child_t>,
typename Node<ChildArgs...>::template Derivative_t<FPrime, IPrime>>;
static std::string Print ()
{
return FunctionName (UF) + "(" + Node<ChildArgs...>::Print () + ")";
}
template<typename Vec>
static typename Vec::value_type Eval (const Vec& values)
{
const auto child = Child_t::Eval (values);
return EvalUnary (UnaryFunctionWrapper<UF> {}, child);
}
};Считаем производную через chain rule — выглядит страшно, идея простая. Вычисляем тоже просто: считаем значение дочернего узла, затем вычисляем значение нашей унарной функции на этом значении при помощи функции
EvalUnary(). Вернее, семейства функций: первым аргументом функции идёт тип, определяющий нашу унарную функцию, чтобы гарантировать выбор нужной перегрузки во время компиляции. Да, можно было бы передавать само значение UF, и умный компилятор почти наверняка сделал бы все нужные constant propagation passes, но здесь проще перестраховаться.Кстати, отдельную унарную операцию отрицания можно было бы и не вводить, заменив её на умножение на минус единицу.
С бинарными узлами всё аналогично, только производные выглядят совсем страшно. Для деления, например:
template<>
struct BinaryFunctionWrapper<BinaryFunction::Div>
{
template<char Family, int Index, typename U, typename V>
using Derivative_t = Node<Div,
Node<Add,
Node<Mul,
typename U::template Derivative_t<Family, Index>,
V
>,
Node<Neg,
Node<Mul,
U,
typename V::template Derivative_t<Family, Index>
>
>
>,
Node<Mul,
V,
V
>
>;
};Тогда искомая метафункция
VarDerivative_t определяется довольно просто, ибо по факту лишь вызывает Derivative_t у переданного ей узла:template<typename Node, typename Var>
struct VarDerivative;
template<typename Expr, char Family, int Index>
struct VarDerivative<Expr, Node<Variable<Family, Index>>>
{
using Result_t = typename Expr::template Derivative_t<Family, Index>;
};
template<typename Node, typename Var>
using VarDerivative_t = typename VarDerivative<Node, std::decay_t<Var>>::Result_t;Если теперь определить вспомогательные переменные и типы, например:
// алиасы для типов унарных и бинарных функций:
using Sin = UnaryFunctionWrapper<UnaryFunction::Sin>;
using Cos = UnaryFunctionWrapper<UnaryFunction::Cos>;
using Neg = UnaryFunctionWrapper<UnaryFunction::Neg>;
using Ln = UnaryFunctionWrapper<UnaryFunction::Ln>;
using Add = BinaryFunctionWrapper<BinaryFunction::Add>;
using Mul = BinaryFunctionWrapper<BinaryFunction::Mul>;
using Div = BinaryFunctionWrapper<BinaryFunction::Div>;
using Pow = BinaryFunctionWrapper<BinaryFunction::Pow>;
// variable template из C++14 для определения переменной в общем виде:
template<char Family, int Index = 0>
constexpr Node<Variable<Family, Index>> Var {};
// определим переменную x0 для удобства, авось, ей часто пользоваться будут:
using X0 = Node<Variable<'x', 0>>;
constexpr X0 x0;
// и так далее для других переменных
// константа для единицы, единица часто встречается в формулах:
constexpr Node<Number<1>> _1;
// перегрузки операторов, им даже не нужно тело, достаточно типа:
template<typename T1, typename T2>
Node<Add, std::decay_t<T1>, std::decay_t<T2>> operator+ (T1, T2);
template<typename T1, typename T2>
Node<Mul, std::decay_t<T1>, std::decay_t<T2>> operator* (T1, T2);
template<typename T1, typename T2>
Node<Div, std::decay_t<T1>, std::decay_t<T2>> operator/ (T1, T2);
template<typename T1, typename T2>
Node<Add, std::decay_t<T1>, Node<Neg, std::decay_t<T2>>> operator- (T1, T2);
// не совсем операторы, но тоже чтобы удобно писать было:
template<typename T>
Node<Sin, std::decay_t<T>> Sin (T);
template<typename T>
Node<Cos, std::decay_t<T>> Cos (T);
template<typename T>
Node<Ln, std::decay_t<T>> Ln (T);то можно будет писать код прямо как в самом начале поста.
Что осталось?
Во-первых, разобраться с тем типом, который передаётся в функцию
Eval(). Во-вторых, упомянуть про возможность преобразований искомого выражения с заменой одного поддерева на другое. Начнём со второго, оно проще.Мотивация (можно пропустить): если немного попрофилировать код, который получится с текущей версией, то в глаза бросится, что довольно много времени уходит на вычисление
 , который, вообще говоря, один и тот же для каждой экспериментальной точки. Не беда! Введём отдельную переменную, которую посчитаем один раз перед расчётом значений нашей формулы на каждой из экспериментальных точек, и заменим все вхождения на эту переменную (собственно, в мотивационном коде в самом начале это уже и сделано). Однако, когда мы будем брать производную по
, который, вообще говоря, один и тот же для каждой экспериментальной точки. Не беда! Введём отдельную переменную, которую посчитаем один раз перед расчётом значений нашей формулы на каждой из экспериментальных точек, и заменим все вхождения на эту переменную (собственно, в мотивационном коде в самом начале это уже и сделано). Однако, когда мы будем брать производную по  , нам придётся вспомнить, что , вообще говоря, не свободный параметр, а функция от . Вспомнить очень просто: заменим на (для этого используется метафункция
, нам придётся вспомнить, что , вообще говоря, не свободный параметр, а функция от . Вспомнить очень просто: заменим на (для этого используется метафункция ApplyDependency_t, хотя правильнее было бы её назвать Rewrite_t или вроде того), продифференцируем, вернём на обратно:using Unwrapped_t = ApplyDependency_t<decltype (logr0), decltype (Ln (r0)), Formula_t>;
using Derivative_t = VarDerivative_t<Unwrapped_t, decltype (r0)>;
using CacheLog_t = ApplyDependency_t<decltype (Ln (r0)), decltype (logr0), Derivative_t>;Реализация многословна, но идейно проста. Рекурсивно спускаемся по дереву формулы, подменяя элемент дерева, если он в точности совпадает с шаблоном, иначе ничего не меняем. Итого три специализации: для спуска по дочернему узлу унарной функции, для спуска по дочерним узлам бинарной функции, и собственно для замены, при этом специализации для спуска по дочерним узлам должны проверять, что шаблон не совпадает с поддеревом, соответствующим рассматриваемой подфункции:
template<typename Var, typename Expr, typename Formula, typename Enable = void>
struct ApplyDependency
{
using Result_t = Formula;
};
template<typename Var, typename Expr, typename Formula>
using ApplyDependency_t = typename ApplyDependency<std::decay_t<Var>, std::decay_t<Expr>, Formula>::Result_t;
template<typename Var, typename Expr, UnaryFunction UF, typename Child>
struct ApplyDependency<Var, Expr, Node<UnaryFunctionWrapper<UF>, Child>,
std::enable_if_t<!std::is_same<Var, Node<UnaryFunctionWrapper<UF>, Child>>::value>>
{
using Result_t = Node<
UnaryFunctionWrapper<UF>,
ApplyDependency_t<Var, Expr, Child>
>;
};
template<typename Var, typename Expr, BinaryFunction BF, typename FirstNode, typename SecondNode>
struct ApplyDependency<Var, Expr, Node<BinaryFunctionWrapper<BF>, FirstNode, SecondNode>,
std::enable_if_t<!std::is_same<Var, Node<BinaryFunctionWrapper<BF>, FirstNode, SecondNode>>::value>>
{
using Result_t = Node<
BinaryFunctionWrapper<BF>,
ApplyDependency_t<Var, Expr, FirstNode>,
ApplyDependency_t<Var, Expr, SecondNode>
>;
};
template<typename Var, typename Expr>
struct ApplyDependency<Var, Expr, Var>
{
using Result_t = Expr;
};Ффух. Осталось разобраться с передачей значений параметров.
Вспомним, что каждый параметр имеет свой собственный тип, поэтому если мы построим семейство функций, перегруженных по типу параметров, каждая из которых возвращает соответствующее значение, то снова (прямо как с вычислением унарных функций чуть ранее) есть шанс, что компилятор это дело свернёт и соптимизирует (а он, кстати, и соптимизирует, умница такой). Ну, что-то вроде:
auto GetValue (Variable<'x', 0>)
{
return value_for_x0;
}
auto GetValue (Variable<'x', 1>)
{
return value_for_x1;
}
...Только мы хотим сделать это красиво, чтобы можно было написать, например:
BuildFunctor (g0, someValue,
alpha0, anotherValue,
k, yetOneMoreValue,
r0, independentVariable,
logr0, logOfTheIndependentVariable);где
g0, alpha0 и компания — объекты, имеющие типы соответствующих переменных, а следом за ними идут соответствующие значения.Как мы можем скрестить ужа и ежа, сделав в общем виде функцию, тип параметра которой задаётся в компил-тайме, а значение — в рантайме? Лямбды спешат на помощь!
template<typename ValueType, typename NodeType>
auto BuildFunctor (NodeType, ValueType val)
{
return [val] (NodeType) { return val; };
}Пусть у нас есть две таких функции, как мы можем получить семейство функций в одном пространстве имён, чтобы нужная выбиралась перегрузкой? Наследование спешит на помощь!
template<typename F, typename S>
struct Map : F, S
{
using F::operator();
using S::operator();
Map (F f, S s)
: F { std::forward<F> (f) }
, S { std::forward<S> (s) }
{
}
};Мы наследуемся от обеих лямбд (ведь лямбда разворачивается в структуру со сгенерированным компилятором именем, а значит, от неё можно наследоваться) и приносим в скоуп их операторы-круглые-скобочки.
Более того, можно наследоваться не только от лямбд, но и от произвольных структур, имеющих какие-либо операторы-круглые-скобочки.
Map от первых двух лямбд, следующую Map — от первой Map и следующей лямбды, и так далее. Оформим это в виде кода:template<typename F>
auto Augment (F&& f)
{
return f;
}
template<typename F, typename S>
auto Augment (F&& f, S&& s)
{
return Map<std::decay_t<F>, std::decay_t<S>> { f, s };
}
template<typename ValueType>
auto BuildFunctor ()
{
struct
{
ValueType operator() () const
{
return {};
}
using value_type = ValueType;
} dummy;
return dummy;
}
template<typename ValueType, typename NodeType, typename... Tail>
auto BuildFunctor (NodeType, ValueType val, Tail&&... tail)
{
return detail::Augment ([val] (NodeType) { return val; },
BuildFunctor<ValueType> (std::forward<Tail> (tail)...));
}Автоматом получаем полноту и единственность: если какие-то аргументы не будут заданы, это будет ошибкой компиляции, равно как и если какие-то аргументы будут заданы дважды.
Собственно, всё.
Разве что, один мой приятель, которому я это показывал в своё время, предложил, на мой взгляд, более элегантное решение на constexpr-функциях, но у меня до него уже 9 месяцев не доходят руки.
Ну и линк на библиотечку: I Am Mad. К продакшену не готово, пуллреквесты принимаются, и всё такое.
Ну и ещё можно поудивляться, насколько умны современные компиляторы, которые могут продраться сквозь вот эти все слои шаблонов поверх шаблонов поверх лямбд поверх шаблонов и сгенерировать достаточно оптимальный код.
Комментарии (27)

Hertz
20.09.2016 16:27+1Предлагаю нечто подобное для организации перегруженной вызываемой сущности из набора.
https://gist.github.com/DieHertz/635c56dc82c3084fa0ea
По-моему, и в Boost такое было.
0xd34df00d
20.09.2016 17:04+1Да, там похожий подход, так тоже можно сделать, за исключением пары несущественных деталей — вроде того, что по вашей ссылке нужно указывать типы сущностей напрямую в списке аргументов лямбды, тогда как в предлагаемом решении они выводятся из типов объектов. Если вы пишете код в терминах объектов, отвечающих свободным переменным и параметрам, то второе немножко удобнее, на мой взгляд.
Hertz
20.09.2016 17:23Если мне не изменяет память, там была make-функция, позволяющая ничего кроме самих вызываемых сущностей не указывать.
Неверно понял, ок.
bfDeveloper
20.09.2016 16:47Писал когда-то подобное для лаб по численным методам. Но у меня было просто обобщённое представление функции и возможности собирать суперфункции (каррирование по сути) и подставлять аргументы (частичное применение). Производные — это очень круто, можно развивать дальше.
A-Stahl
20.09.2016 16:55-14После прочтения мне захотелось убить котёнка. А лучше двух…
Вот так взять этот маленький пушистый пищащий комочек и сдавить в кулаке чтобы кровь и кишки полезли сквозь пальцы…
Всё это от бессилия. Бессилия понять как код, так и от бессилия понять за что вы так ненавидите людей чтобы такое писать.
P.S. Не слушайте меня. Я возненавидел шаблоны с первого взгляда. Шаблоны, на мой взгляд, с созданием нечитаемого и неотлаживаемого кода справляются даже лучше, чем макросы. Впрочем… Работает? Ну и ладно. Главное чтобы никому кроме вас не пришлось искать там баг или вносить новые возможности.0xd34df00d
20.09.2016 17:07+6Да, я это и для себя писал. Ну, как в самом начале написано, ручками производные в коде выписывать скучно и лениво, а вот поупарываться — это уже весело.
bfDeveloper
20.09.2016 19:21Не хотелось бы чтобы это выглядело как понты, но не вижу ничего ужасно сложного в данном коде. При необходимости любой С++ программист интересующийся шаблонами (укушенный Александреску) разберётся.
Тем, кто на этом не пишет, непонятно, но шаблоны это другой язык и его просто надо знать. Если знаете, то ничего сложного, если нет, то китайская грамота.
Alcor
20.09.2016 19:32-3Полностью поддерживаю. Но только убить котенка хочется из-за того, что в дальнейшем придется поддерживать этот код и модифицировать его, и никто не спросит, нравится ли этот подход или нет, придется ждать лишнее время при компиляции, притом, что замеров производительности-то нет.
А потом код сломается, возможно. В компиляторе или линкере, работающем не до конца по стандарту. И будет это глубоко-глубоко в проекте на миллионы строк. И автора кода уже не будет в команде — ему станет скучно или шумно, или решит, что пришло время менять работу, или что в фирме xxx платят больше…0xd34df00d
20.09.2016 19:41+8притом, что замеров производительности-то нет.
Замеры производительности и анализ дизасма есть, и про это даже есть пара ремарок, но цель статьи — не в них, поэтому я не стал раздувать её ещё и этим.
Если же вы говорите о замерах скорости компиляции, ко всему прочему, то их банально сложно делать, потому что у компиляторов иногда бывает не совсем линейная сложность, собственно, компиляции в зависимости от инстанциированных шаблонов. Добавили эту мою библиотеку в свой проект из двух строк — время компиляции выросло с пол-секунды до трёх. Добавили эту мою библиотеку в проект, где есть уже и так куча всего — время компиляции выросло с пяти секунд до восьми. Или до шести. Или до десяти.
В конце концов, всегда можно спрятать особо тяжёлый для компилятора код в отдельный translation unit. Я так со всякими парсерами на boost.spirit делаю, например, которые компилируются адски долго, но зато меняются довольно редко.
В компиляторе или линкере, работающем не до конца по стандарту.
Если бояться компиляторов или линкеров, работающих не до конца по стандарту, то лучше вообще код не писать.
И будет это глубоко-глубоко в проекте на миллионы строк.
Если у вас нет в продакшен-коде юнит-, интеграционных и прочих тестов, то стоимость внесения изменений и так будет зашкаливающей.
Если же вы боитесь того, что какой-то крайний случай в компиляторе/линкере будет проявляться исключительно в самом проекте, а в юнит-тесте нужный порог сложности не будет преодолён, скажем, то, опять же, см. выше.
И автора кода уже не будет в команде — ему станет скучно или шумно, или решит, что пришло время менять работу, или что в фирме xxx платят больше…
Чую непонятные негативные коннотации в этом высказывании.
А если по существу — я бы предпочёл работать в команде, где такой код понятен не только мне.
shtr
20.09.2016 18:25+1Проводили ли сравнение с такими библиотеками как FADBAD, Sacado, CppAD?

Dark_Daiver
20.09.2016 21:21Это же вроде как autodiff либы, корректно ли будет сравнивать их с аналитическим выводом?


andy_p
21.09.2016 00:22А производную x в степени x вычислит?
0xd34df00d
21.09.2016 08:22+1А чего б и не вычислить!
% ./basic_diff (x_0 ^ x_0) * (ln(x_0) + (x_0 * (1 / x_0)))
Не упростило второе слагаемое, но да и упрощение там сильно базовое, компилятор с -ffast-math всё упростит.
KvanTTT
21.09.2016 16:58Вот кстати да, а что насчет упрощения выражений? Ведь это сделать посложнее, чем просто вычислить производную (исключая простые случаи типа a+0=a, a*1=a и т.д.). Я тоже занимался аналитическими производными, только под .NET. В итоге без перебора не обошлось: Упрощение выражения.
0xd34df00d
21.09.2016 17:10+1Паттерн-матчить деревья выражений в плюсах на шаблонах очень больно. У меня в соседнем проекте на хаскеле есть упрощение выражений, адекватный паттерн-матчинг плюс вещи вроде Uniplate очень сильно помогают.
А вообще, по-хорошему, надо обмазываться каким-нибудь Ehrig'ом [1] и делать с матаппаратом, который там.
[1] K Ehrig H. E., G Taentzer U. P. Fundamentals of algebraic graph transformation. With 41 Figures (Monographs in Theoretical Computer Science. An EATCS Series). – 2006.
degs
21.09.2016 04:03+1Просто аххренеть, извините за оффтоп. У меня плюсов не хватает.
Ценность данного кода в том что он независимо от больших библиотек позволяет создавать модули в нужных местах. Код открытый, локальный и достаточно простой — значит их можно оптимизировать и затачивать под конкретные задачи.
Не знаю кто как, а я немедленно форкую.

Wedmer
21.09.2016 04:11Вспомнилось выражение «Лень — двигатель прогресса».
И ведь не поспоришь.lookid
21.09.2016 04:23Ага и тут картинка «Добро пожаловать на родину лени». А ведь кто-то тебе и +1 поставит.
Wedmer
21.09.2016 05:05+1Я честно признаюсь, что я ленив до ужаса. Для автоматизации многих процессов я написал кучу скриптов и утилит. Чисто ради того, чтобы избавиться от долгой и рутинной ручной работы. Чисто потому, что мне было лень это все делать ручками. Это прогресс. Кого то лень стимулирует создать инструменты упрощающие жизнь. А кто то от лени просто гниет на диване. Люди разные бывают.
KvanTTT
21.09.2016 16:53+1Я бы не сказал, что это лень. Бывает, что такую утилиту дольше писать, чем вручную все сделать. Возможно люди автоматизируют процессы из-за чувства прекрасного.
Wedmer
21.09.2016 17:00+1Если думать о будущем, то однозначно затраты окупаются. Как я сказал ранее, все люди разные, и лень у каждого по разному проявляется. Лучше день потерять и за пять минут долететь.
pkalinin
22.09.2016 13:19+2Насколько я понимаю, это концептуально автоматическое дифференцирование, про которое я писал в свое время. Кажется, там тоже почти все из этого можно сделать, хотя, конечно, реализация на шаблонах впечатляет.
sublihim
Снимаю шляпу :)