
Про предмет статьи ходит много домыслов — от «русский Барроуз» до «не имеющий аналогов». Вызвано это в немалой степени отсутствием (доступной) полноценной документации, немногочисленным кругом лиц, имевших с ними дело да и немалым временем, прошедшим с тех пор. «Эльбрус» превратился в один из мифов ушедшей эпохи.
С другой стороны, вычислительный комплекс несомненно существовал и показывал отличные для своего времени результаты. Возможно, благодаря скудости элементной базы, которая принуждала разработчиков к выдумыванию разного рода архитектурных трюков. Многие из этих трюков сейчас выглядят архаично, а некоторые достаточно актуальны.
Так что автор из свойственной ему любознательности попытался разобраться с доступной документацией и составить более — менее цельную картину. Если читателю это интересно — добро пожаловать под кат.
Элементная база
Новое поколение техники возникает не тогда, когда подросло новое поколение инженеров, а на основе качественных изменений в технологии. В том, что касается советских “Эльбрусов”, таким изменением стало появление интегральных схем. Для «Эльбрус-1», это была 133 серия микросхем с логикой ТТЛ (быстродействие 10...15 нс на вентиль). Для «Эльбрус-2» — 100-я серия с логикой ЭСЛ (быстродействие 2 нс на вентиль).
100 серия сделана (серийный выпуск с 1974 г.) на основе MECL 10K от Motorola (с 1971 г.) [6]. 133 серия (с 1969 г.) базировалась на 54 серии от TI (с 1965 г.) [6]. Т.е. какого-то особого отставания в элементной базе на тот момент не было.
Организация памяти
Физическая память
Подсистема памяти строилась на базе микросхемы К565РУ3В (NMOP) [3] ёмкостью 16Кбит и организацией 16384х1.
Аппаратура коррекции и контроля позволяет исправлять одиночные и обнаруживать двойные ошибки при считывании информации. Для этого при записи формируются и добавляются к 72-разрядному информационному слову восемь разрядов кода Хемминга. Таким образом, слово, хранящееся в памяти, содержит 80 разрядов, включая: 8 — управляющая информация (тег), 64 — данные, 8 — контрольные разряды кода Хемминга.
Адресная шина имеет разрядность — 24, т.е. размер физической памяти ограничен 16 мега-словами (по 72 бита), 144 Мб данных вместе с тегами.
Если считать вместе с кодами Хэмминга, получим 180 Мб или 90 Кмикросхем. Всё это удалось для максимальной комплектации разместить в 8 шкафах (секциях ОП).
В максимальную комплектацию входит 10 процессоров, при этом каждый процессор соединен с каждой секцией ОП. Длина линий связи выбрана примерно равной 10 м из условия размещения устройств комплекса. Такую длину свет пролетает в вакууме за ~1/30000000 секунды (33 нс). В Э-2 же сигналы передаются от выходного регистра передающей станции до регистра приемника за 80 нс (при рабочем цикле в 44 нс), что очень неплохо.
Каждый шкаф памяти (секция ОП) состоит из четырёх модулей памяти и коммутатора. Модули функционально независимы и могут одновременно обмениваться информацией с разными процессорами. Всего 32 модуля, в каждом по половине мега-слова. При групповом обращении все четыре модуля запускаются одновременно. Это позволяет получить максимальный темп обмена данными с секцией ОП.
Цикл работы модуля составляет 13 тактов, однако последовательные обращения к разным микросхемам одной группы могут обслуживаться каждые семь тактов.
На нижнем уровне, минимальный размер блока — 16К слов соответствует объему микросхемы памяти 16К бит. Блок состоит из 80 микросхем памяти, по одной микросхеме на разряд. Следовательно, модуль памяти состоит из 32 таких минимальных блоков.
Устройство обмена с оперативной памятью (УООП)
Является частью процессора. Имеет отдельный канал связи с каждой из восьми секций ОП и может обращаться в каждую секцию как с одиночными, так и с групповыми запросами.
При групповом запросе за одно обращение происходит обмен четырьмя словами. Время обращения по записи в память составляет для УООП около восьми тактов, время обращения по считыванию из памяти — около 20 тактов (обращение может быть задержано коммутатором ОП в случае занятости модуля памяти или конфликта по обращению с другим ЦП).
Одновременно в УООП может храниться до трех запросов. УООП имеет внутреннее распараллеливание на два канала, что позволяет выставлять одновременно два запроса на обмен в разные секции ОП. Максимальная частота смены в канале — один запрос за восемь тактов. Таким образом, при групповых обращениях к памяти УООП обеспечивает темп обмена — одно слово за такт [1].
Для оптимизации работы при последовательном обходе адресов используется техника расщепления (interleaving). Часть битов в физическом адресе перемешивается, в результате последовательно идущие слова оказываются в разных единицах вышеописанной иерархии памяти и могут читаться параллельно. Схема перемешивания такова:
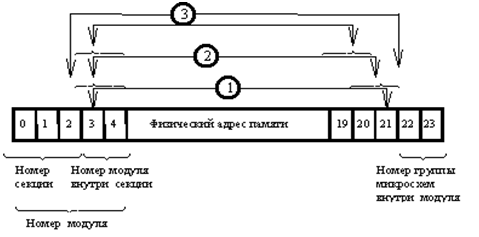
При исключении отдельных модулей из конфигурации, операционная система не назначает их адреса. Наличие выключенного модуля делает невозможным расщепление в данной секции.
Математическая (виртуальная) память
Математическая память описывается 38-разрядным математическим адресом при условии указания размещения величины с точностью до одного разряда (32-разрядным адресом при указании с точностью до машинного слова).
Величины
Основной единицей информации является величина. Величина -логическая единица информации, к которой можно адресоваться с помощью математического адреса. Над величинами же производятся операции при выполнении команд программ.
Величины могут иметь следующие размеры в разрядах (форматы): 1, 4, 8, 16, 32, 64, 128.
Ни одна из величин кроме 128-разрядной не может быть расположена более чем в одном слове.
В одном слове могут находиться величины только одинакового типа и формата за одним исключением: целое и вещественное формата 32 разряда могут быть упакованы в одном слове в любом порядке.
В управляющих разрядах слова хранится информация о типе и формате величин, находящихся в слове.
Страницы
Математическая память разбита на страницы. Страницы могут быть различных размеров (кратных 16) — от 16 до 1024 слов. Адрес начала страницы имеет младшие 10 (из 38) разрядов нулевыми [2 стр.61].
Блок из 16 слов, расположенный в математической памяти так, что в 38-разрядном адресе первого слова младшие 10 разрядов нулевые, называется строкой.
Сегменты
Сегменты — области непрерывной адресации, выделяемые системой. Начало любого сегмента в математической памяти совпадает с началом некоторой страницы.
Для размещения сегмента используется страница минимально возможного размера. Сегменты размером более 1024 слов размещаются в математической памяти на смежных страницах, при этом все страницы, кроме последней, должны иметь максимальный размер.
Начало страницы, а следовательно и сегмента, в физической памяти может размещаться в начале любой физической строки. Страница располагается в смежных ячейках физической памяти.
Поэтому сегмент размером более 1024 слов может присутствовать не полностью в физической памяти (swapping), а его страницы в физической памяти не обязаны идти подряд.
Поддержка виртуальной памяти.
Виртуальная память организована довольно логичным и естественным образом. Сегменты создаются ядром ОС, что неизбежно, учитывая теговую систему и вопросы защиты памяти.
Все свободные области памяти в ядре объединены в упорядоченный список свободных областей. Упорядочение производится по размеру области. В системе команд имеется специально для этих целей предназначенная команда “ПОИСК ПО СПИСКУ”, которая находит либо область, точно совпадающую по размеру с требуемым, либо минимально превосходящую по размеру требуемый размер. В первом случае найденная область исключается из списка, загружается в математическую память (если это требуется) и в качестве результата процедуры формируется дескриптор этой области. Во втором случае, если размер найденной области превосходит требуемый более чем на 15 слов, из найденной области забирается область требуемого размера, а остаток возвращается в область свободной памяти, где он будет включен в соответствующее место списка свободной памяти. Пользователю выдается дескриптор на область памяти размером, в точности совпадающим с запрашиваемым.
В том случае, если памяти требуемого размера нет, происходит попытка консолидации участков свободной памяти путем перемещения занятых участков меньшего размера, разделяющих соседние свободные области, в имеющиеся свободные области.
Если это не приводит к цели, происходит откачка (свопирование) занятых участков на внешние носители. Это не касается выполняемых сегментов, их можно просто освободить…
Каждая задача имеет свой файл откачки, а каждый сегмент знает свою задачу. Распределение свободной памяти в файле производится по битовой маске[2, стр.143], в которой один разряд соответствует странице. (Для математической памяти размером 2**32, требуется маска в 2**(32-16)=64К на задачу, что не так уж и мало. Кроме того, непонятно как быть со страницами размером меньше максимально возможных 8К.) Таким образом удаётся избежать проблем с поддержанием реестра свободных страниц в сравнении с общим файлом откачки. Ведь каждая задача имеет свою математическую память. Кроме того, высвобождение всей памяти процесса сводится к удалению его файла откачки, работа перекладывается на файловую систему. При относительно небольшом числе задач это отличный подход. К его минусам можно отнести разве что дополнительную нагрузку на файловую систему.
В ядре ОС есть задача, которая в фоновом режиме “подстригает” задачи [2, стр.143], сбрасывая некоторый процент страниц. Данные пассивных задач при этом постепенно оказываются в файлах откачки, активно работающие задачи балансируются.
Разберём теперь преобразование адреса из математического в физический. Все области памяти задачи (сегменты) объединены списком, голова и хвост которого расположены в дескрипторе задачи. Отметим, что в данной архитектуре не предусмотрены обращения по голому указателю в духе “C”, всегда преобразуется пара (указатель, смещение).
В упомянутом списке сегментов задачи с помощью инструкции “ПОИСК ПО СПИСКУ” находится описатель сегмента, а в нём физический адрес нужной страницы. Если в физической памяти данная страница отсутствует, включается механизм подкачки.
Для ускорения преобразования математического адреса в физический в ЦП для наиболее “активных” страниц предусмотрен ассоциативный массив размером в 64 элемента. Ассоциативным признаком является номер математической страницы, ответ — физический адрес начала страницы, ее размер, а также некоторые служебные признаки. Время поиска в этом ассоциативном массиве — 3 такта, темп обработки — одна заявка в такт.
Кроме того, само слово, к которому происходит обращение, вместе со своим математическим адресом помещается в ассоциативную память слов, которая также имеется у каждого ЦП. Такая память является аналогом современной кэш памяти.
Есть упоминание [2, стр.144] о таблице откачанных страниц (ТОС), предназначенной для размещения информации об откачанных или еще не инициализированных страницах. Голова этой таблицы находится в ОЗУ, область переполнения — во внешней памяти (барабане). Её величина пропорциональна количеству существующих страниц, а не всей математической памяти.
ТОС одна на систему, значит для каждой страницы надо запоминать еще и идентификатор задачи.
Для ускорения работы с ТОС в ядре предусмотрен кэш, причем, как утверждается, весьма эффективный. Но это странно, ведь для эффективного кэширования необходимо понимать логику работы прикладной задачи с памятью, а она разработчикам ОС неизвестна.
Итак:
- Страницы откачиваются на внешние носители фоновой задачей ядра, “подстригающей” задачи. Поэтому в ТОС они идут пачками и (вероятно) в упорядоченном виде.
- Свободное место в файлах откачки распределяется с помощью упомянутой битовой маски.
- Подкачиваются же страницы в произвольном порядке, определяемом логикой работы прикладных задач.
- Под ТОС отдали самую быструю (и самую маленькую — до 136 Мб) внешнюю память — барабаны, среднее время доступа 5-5,5 мс, темп обмена 3.6 Мб/с [2, стр.187]. В качестве сравнения, для дисков: среднее время доступа 60 мс, темп обмена — 180 Кб/с.
- Тем более обидно, если в процессе работы ТОС окажется фрагментированной и будет требовать избыточного места. Кроме того, со временем ТОС потеряет упорядоченность и для поиска нужной страницы её придется читать целиком.
- По всей видимости, хоть ТОС называется таблицей, она устроена как Б-дерево (1970г) или, например, аналогично хэш-таблице DBM (1979 г), дёшево и сердито. Скорее первое, учитывая, что дерево-образная структура использована для распределения свободной памяти файловой системой [2, стр.146]. С другой стороны, в [2, стр. 200] можно увидеть сожаления по поводу того, что управление сегментами получилось слишком сложным и повлекло за собой применение отличного от принятого в ЕС ЭВМ интерфейса обмена ОЗУ с внешней памятью. Со всеми вытекающими последствиями.
Типы данных
Как уже говорилось, слово состоит из 64 разрядов данных и 8 управляющих разрядов. Управляющие разряды содержат тег — описание того, что лежит в информационной части слова.
Это может быть:
- Пусто формата 32 и 64 бита — обычно это неинициализированные данные. Пустышки вполне можно считывать, записывать, передавать в процедуры и даже проверять и менять биты. Но при попытке работать как с числами или с массивами — произойдёт прерывание.
- Целое формата 32 и 64 бита — в отличие от распространенного ныне формата, здесь знак выделен в старший бит.
- Вещественное 32 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 24 разрядов
- Вещественное 64 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 56 разрядов
- Вещественное 128 — знак мантиссы/знак порядка/порядок 6 разрядов/мантисса 56 разрядов/старшие разряды порядка — 8 разрядов/старшие разряды мантиссы — 56 разрядов. Вообще, формат чисел отличается от принятого сейчас IEEE 754. Он взят и системы 360.
- Бит
- Цифра — 4 разряда, обычно используется для представления десятичных чисел
- Байт — 8 бит, обычно — символ строки
- Набор — 64 разряда, совокупность однотипных элементов, которые не являются величинами и индивидуальный доступ к ним недопустим (SIMD?)
- Дескриптор — 64 разряда, описатель области памяти, создается только ядром, содержит математический адрес, размер в элементах, размер элемента в разрядах, тип защиты памяти. Максимальный размер области, описываемой дескриптором, равен 2**20 слов.
- Индексное (косвенное) слово — 64 разряда — это счётчик цикла в Э-1.
В нём записано текущее значение счётчика, шаг цикла, и предельное значение(все по 20 разрядов+знак).
В арифметических операциях или операциях обращения к элементам массива автоматически преобразуется в целое, при операциях цикла происходит автоматическая проверка выхода за предельное значение и переход
по адресу или автоматическое изменение счётчика. - Косвенное слово имеет структуру дескриптора и отличается тем, что при считывании такого значения автоматически происходит считывание значения, на которое указывает адрес(может повторяться несколько раз).
- Интервал — 64 разряда, применяется для получения дескриптора под-области из области, описываемой индексируемым дескриптором.
- Метка операции перехода. Можно использовать только в команде GOTO. — 64 разряда, содержит
- математический адрес контекста охватывающей процедуры внутри которой эта метка описана. — 32 разряда
- номер байта от начала области — 16 разрядов
- дескриптор программного сегмента — 12 разрядов
- лексикографический уровень процедуры — 5 разрядов (0 — системные вызовы, 1&2 — пользовательские процедуры. 3 — первый выполняемый… [2, стр.43]).
- Метка процедуры. Имеет ту же структуру, отличается тегом, можно использовать только в операциях входа в процедуру.
- Техническая метка. Имеет ту же структуру, отличается тегом. При считывании происходит автоматический вход в процедуру без параметров, возвращающую одно значение.
- Семафор — средство синхронизации в системе.
- Заготовка массива. В системе Эльбрус не принято явно вызывать процедуру типа getmem или maloc.
Вместо этого в память кладётся так называемая заготовка массива- слово со специальным тегом, в котором указан размер массива и размер элемента массива. Если массив ни разу не понадобится, то заготовка так и останется заготовкой. Иначе при считывании такой заготовки произойдет прерывание, процедура обработки которого выделит память и запишет на место этой заготовки дескриптор выделенного массива.
Особенности системы команд
- Данные снабжены тегами, это позволяет аппаратно защищать их а также упростить систему команд, например, заменив целое семейство типизированных команд сложения на одну единственную — с учетом тегов.
- Принята безадресная система команд, в результате чего отсутствует лишняя информация о распределении регистров. Эффективное динамическое распределение регистров реализует аппаратура. Безадресный формат команд базируется на аппаратной реализации стека.
- Адресация данных в командах происходит по паре — сегмент/индекс с учетом контекста выполнения, а не по математическому адресу. Например, порядковый номер в области стека, отведенной для конкретной процедуры.
- Для вызова функций помимо математического адреса используется довольно подробный дескриптор, в котором помимо всего прочего указан размер локального стека под данные и параметры. Реализовано отложенное выделение данных, при входе в функцию создается только дескриптор сегмента, собственно выделение происходит при первом обращении. Сообщается [2 стр.42], что, это новаторская техника. В самом деле, номер дескриптора функции идет аргументом вызова так же как и математический адрес кода. В x86, например, всю вспомогательную работу делает компилятор, размещая пролог и эпилог функции.
Безадресный код.
Мы говорим “безадресная система команд”, подразумеваем — “стековый процессор”. Рассмотрим простой пример, вычисление выражения x+y*z+u.
При построении дерева разбора компилятором оно выглядит так:
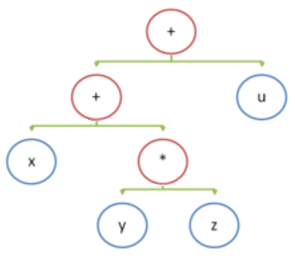
Ассемблерный код (x86) для этого выражения:
mov eax,dword ptr [y]
imul eax,dword ptr [z]
mov ecx,dword ptr [x]
add ecx,eax
mov eax,ecx
add eax,dword ptr [u]
Для гипотетической стековой машины псевдокод таков:
push x
push y
push z
multiply
add
push u
add
Для работы со стеком необходимы операции следующих типов:
- запись элемента на вершину стека (push)
- удаление элемента с вершины стека (pop)
- бинарные операции, удаляющие два элемента с вершины стека и записывающие результат операции (+-*/)
- унарные операции, замещают результат на вершине стека (смена знака)
Что нам предлагает архитектура Эльбруса?
- Операции загрузки в стек. Информация может загружаться в стек либо непосредственно из командного потока, либо из области данных. В первом случае загружаемая величина находится в самой команде, во втором случае величина загружается по адресу, находящемуся либо в команде, либо в верхушке стека (загрузка по адресу).
Отметим, что поскольку стек реализован как циклический буфер из регистров, загрузка нового элемента может вызвать автоматическую выгрузку части стека в память.
Особый интерес представляет загрузка по адресу, при которой:
- по адресной паре находится математический адрес величины
- при этом проверяется возможность доступа к величине
- величина загружается в верхушку стека
- далее выполняется цикл
- по тегу проверяется класс значений загруженной величины
- если величина принадлежит классу значений, операция завершена
- если это косвенное слово, происходит считывание по косвенному слову
- метка процедуры, является вполне себе значением, цикл останавливается
- если это техническая метка процедуры, вызывается процедура, которая должна оставить свой результат на вершине стека
- Запись в память из стека. Для этого нужны две величины с верхушки стека: величина и адрес записи. В качестве адреса записи может выступать либо адресная пара, либо косвенное слово. Запись производится «одношагово», то есть непосредственно по адресу записи.
- Арифметические операции, операции отношения и логические операции. Арифметические операции производятся над одной или двумя величинами, содержащимися в верхушке стека. Как правило, операнды являются целыми или вещественными, причем, если операнды различного типа (целое и вещественное), то перед операцией производится автоматическое преобразование целого в вещественное. Если операнды имеют различные форматы, то перед операцией производится автоматическое «выравнивание длин» по наибольшей длине.
Исходные числа убираются из стека (с соответствующим смещением указателя), а затем результат помещается в верхушку стека.
Одноместные арифметические операции берут операнд из верхушки стека и заменяют его на результат.
Центральный процессор
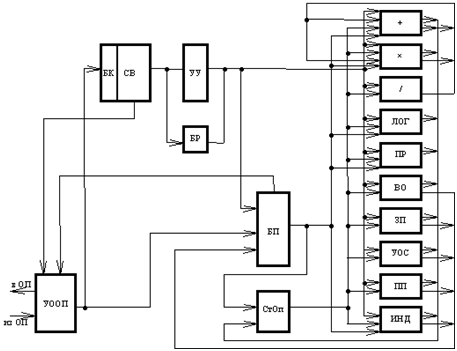
Структурная схема ЦП [1]:
- устройство обмена с оперативной памятью (УООП)
- буферная память команд (БК) объемом 512 слов для согласования темпа дешифрации команд и вызова программы из оперативной памяти
- устройство управления (УУ)
- 10 специализированных исполнительных устройств (ИУ) для выполнения команд
- базовые регистры (БР) для преобразования относительных адресов в абсолютные
- стек операндов (СтОп) объемом 256 слов для хранения промежуточных результатов операций
- буферная память (БП) 1024 слова, предназначена для хранения глобальных данных плюс буферная память массивов на 256 слов с предварительной подкачкой
- СВ – схема выборки (декодирования)
Декодирование
Программный код вычитывается в буфер команд (БК). БК работает как ассоциативный массив, имеет объем в 512 слов, которые поделены на 32 равных сегмента. Подкачка информации в БК из оперативной памяти производится блоками по четыре слова. Темп подкачки определяется необходимым запасом командных слов в буфере команд и автоматически регулируется при изменении темпа декодирования команд.
Схема выборки извлекает очередную команду из БК, дешифрует и передает в УУ для преобразования во внутренний регистровый формат.
Система внутренней адресации
Все передачи адресной и числовой информации сопровождаются в ЦП внутренним адресом источника или потребителя информации. Внутренние адреса присвоены буферу команд, стеку операндов (СтОп), БП и некоторым входным регистрам ИУ.
СтОп состоит из 32 регистров и 32-разрядного регистра — битовой маски. Каждый бит в этой маске отвечает за конкретный регистр, 1 — означает занят, 0 — свободен.
При выдаче команды в ИУ формируются внутренние адреса операндов и результата операции. Для операций со стеком, операнды и результат — номера регистров из СтОп.
Для декодирования команды суммирования, например, считается, что номера операндов уже получены ранее, можно назначать любой свободный регистр из СтОп. После того как команда исполнилась, операнды освобождаются.
Исполнение
Не все команды могут быть исполнены непосредственно после их декодирования, поэтому необходим буфер декодированных, но не исполненных команд. ЦП обладает таким буфером на 32 команды во внутреннем представлении.
Из декодера команды выдаются в последовательности, заданной программой. При этом они последовательно нумеруются и этот номер сопутствует команде всю её жизнь. Этот номер — индекс в упомянутом буфере декодированных команд, когда он доходит до 32, то опять начинает с нуля. Зная текущее значение, можно выстроить все команды в очереди по порядку их декодирования.
Время выполнения команд в ИУ определяется их типом и колеблется от 2 до 20 тактов для операций над операндами однократной точности (32) и до 30 тактов над операндами удвоенной точности (64). ??? Умножение(Ф64) — 4 такта. Деление (Ф64) — 24 такта.
Выполнение операций над вещественными числами формата Ф128 требует трехкратного сложения — сложения младших разрядов, сложения старших разрядов с учетом переноса из младших разрядов, повторного сложения младших разрядов с учетом переноса из старших разрядов. Для этого требуются станции хранения промежуточных результатов.
Исполняться команды начинают по готовности аргументов и доступности нужного исполнительного устройства. Т.к. порядок исполнения не обязательно совпадает с исходным, мы имеем внеочередное исполнение (OoO). А поскольку исполнительных блоков несколько и работают они параллельно, налицо суперскалярность. Правда, сумматор, делитель и умножитель в единственном экземпляре, но могут работать параллельно.
Учитывая, что всего имеется 10 исполнительных устройств, возникает вопрос, а сколько же инструкций за такт может быть исполнено. В [2 стр. 185] упоминается, что в технологическом режиме с последовательным выполнением команд производительность падает в 2-3 раза. В [4] говорится о 2 командах за такт. Связано это, по-видимому, с реализацией СтОп, которая допускает только две записи за такт.
Пример
Для демонстрации возможности вполне суперскалярного поведения, разберем выражение “(a * b) + (c / d)”. При этом, переменные “a” & “c” расположены в области локальных переменных процедуры и присутствуют в кэше, а “b” & “d” глобальные и в кэше отсутствуют. Для простоты, все они типа F64.
Ассемблерный код выглядит примерно так:
ВЗ а
ДВЗ b
∗
ВЗ c
ДВЗ d
⁄
+
Где ВЗ означает “вызвать значение”, ДВЗ — “длинная ВЗ”, а мнемоники арифметических операций неизвестны.
После декодирования код во внутреннем представлении примерно таков (мнемоники придуманы):
загр a -> R1 ; с захватом R1 в СтОп
загр b -> R2 ; с захватом R2 в СтОп
∗ R1 R2 ->R3 ; с захватом R2 в СтОп, R1 & R2 освобождаются по выполнении
загр с -> R4 ; с захватом R4 в СтОп
загр d -> R5 ; с захватом R5 в СтОп
⁄ R4 R5 ->R6 ; с захватом R6 в СтОп, R4 & R5 освобождаются по выполнении
+ R3 R6 ->R1 ; с захватом освобожденного было R1 в СтОп,
; R3 & R6 освобождаются по выполнении
; результат в R1
Из-за зависимостей между командами исполнение происходит в следующем порядке (2 инструкции за такт, загрузка из кэша — 1 такт, загрузка из памяти 13 тактов, “*”-4 такта, “/” — 24 такта, “+” — 3 такта):
| такт | Старт | Исполнилось |
| 1 | загр a -> R1; загр b -> R2 | |
| 2 | загр с -> R4; загр d -> R5 | загр a -> R1 |
| 3 | загр с -> R4 | |
| 13 | загр b -> R2 | |
| 14 | ? R1 R2 ->R3 | загр с -> R4 |
| 15 | ? R4 R5 ->R6 | |
| 17 | ? R1 R2 ->R3 | |
| 38 | ? R4 R5 ->R6 | |
| 38 | + R3 R6 ->R1 | |
| 40 | + R3 R6 ->R1 |
Умножение и деление выполняются вполне параллельно. Увы, но арифметические исполнительные устройства не имеют конвейеров, которые планировались только в векторном процессоре [2, стр.150].
Остановка и продолжение исполнения
Иногда может потребоваться приостановить работу программы с возможностью при необходимости продолжить работу, например, при истечении кванта времени. Для этого требуется восстановление исходного порядка инструкций. При этом:
- запоминается номер команды, вызвавшей прерывание
- завершаются команды, дешифрованные ранее неё, и отменяется выполнение команд, дешифрованных позднее
- восстанавливается состояние регистров на момент, соответствующий декодированию команды, вызвавшей прерывание
- входим в прерывание
Восстановление состояния регистров потребует специального механизма, например, циклического буфера для лога изменений значений регистров размером 2 * “максимальная длина инструкции в тактах”. В этот лог при завершении инструкции записываются — старое значение регистра из СтОп, новое значение, номер регистра и номер команды. Тогда при необходимости можно открутить назад изменения для отменяемых команд.
Отмена выполнения команд используется также при обработке команд условного перехода. Таким образом осуществляется спекулятивное исполнение кода.
Про предсказатель направления ветвления есть упоминание [1], но механизм неясен.
Итак, что мы имеем?
- суперскалярность на уровне 2 инструкции за такт
- для реализации суперскалярности использована техника scoreboarding, никакого переименования регистров, как указано в [5], нет и близко, эта техника здесь просто неприменима
- использование стека операндов близко к технике регистровых окон, появившейся независимо, но на несколько лет позднее (Э-1: разр. 1973-1979, BerkeleyRISC: 1980-1984)
- внеочередное исполнение команд
- предсказание переходов со спекулятивным исполнением
- сочетание безадресной архитектуры и суперскалярности в Эльбрусе-1 по-видимому имеет приоритет
Многопроцессорная работа
Проблема межпроцессорного взаимодействия связана с наличием у каждого процессора своего СОЗУ (кэш) и, следовательно соответствием данных в ОЗУ и СОЗУ. СОЗУ позволяет значительно снизить частоту обращений в относительно медленную память, но при этом возможна ситуация, когда данные в памяти свежее оных в СОЗУ.
В МВК “Эльбрус” задача может порождать несколько процессов (threads), разделяющих общую математическую память. Участок программы, использующий (считывающий или модифицирующий) общие для нескольких процессов данные, называется критической секцией.
Проблем две — синхронизация и поддержка когерентности кэша.
Семафоры:
- Семафор — это тип данных в системе команд, который имеет свой тег [2 стр.121]. Непривилегированный пользователь не может никак изменить содержимое семафора. Он может лишь подавать семафор по имени в качестве параметра в процедуры синхронизации (семафоры не могут копироваться и каждый семафор существует лишь в одном экземпляре, однако на каждый семафор может быть установлено несколько ссылок)
- Семафор может быть в состоянии “открыто” или “закрыто”.
- Функция “ЖДАТЬ” (с аргументом — ссылкой на семафор) блокирует (ставит его в очередь семафора) текущий thread, если тот закрыт или ничего не делает, если открыт. После разблокирования, thread продолжит исполнение со следующей после вызова этой функции инструкции.
- Функция “ОТКРЫТЬ” (...) переводит семафор в открытое состояние, все ждущие его открытия процессы (threads) переносятся в очередь готовых к исполнению
- Функция “ПРОПУСТИТЬ” (...) переводит все процессы (threads), заблокированные на данном семафоре в разряд готовых к исполнению, семафор остается закрытым
- Функция “ЗАКРЫТЬ” (...) переводит семафор в закрытое состояние, если он был открыт. Если семафор был закрыт, то текущий thread блокируется и ставится в очередь семафора. Отличие от функции “ЖДАТЬ” в том, что когда данный thread разблокируется, вновь будет сделана попытка закрыть семафор.
- Функция “ОТКЗАКРЫТЬ” привилегированная[2,124], первым операндом должен быть спинлок, а вторым — обычный семафор, атомарно открывает первый семафор и закрывает второй. производитель-потребитель. Например, процессы обмениваются порциями данных, при потребитель должен получать сигнал, что готова новая порция данных, а производитель — что потребитель обработал предыдущую. Решение этой задачи на двух семафорах состоит в том, что один семафор используется для оповещения производителя, а другой — потребителя.
- Для привилегированных пользователей доступны операции со спинлоками — “ЖУЖ”(да, от слова жужжать [2 стр.124]) и “ОТКРСЕМ”, аналогичные “ЗАКРЫТЬ” и “ОТКРЫТЬ”. Эти операции заметно быстрее, но пригодны только для кратковременных работ, при этом недопустимы прерывания (работа с виртуальной памятью и устройствами). С семафором нельзя одновременно работать и как с семафором и как со спинлоком.
- На пользователей возлагается ответственность за правильностью использования этой техники. Например, если какой-то процесс открывает семафор, который им не закрывался, то процесс, который закрывал семафор, теряет монополию на работу с данными, охраняемыми этим семафором. Кроме того, эта техника не гарантирует отсутствия тупиков.
- При закрытии семафора запоминается время этого события, оно нам еще пригодится.
Когерентность памяти
Считается, что работа с общими данными может производиться только в критической секции, то есть между операциями «ЗАКРЫТЬ» и «ОТКРЫТЬ» или операциями «ЖУЖ» и «ОТКСЕМ».
Все данные, записываемые в СОЗУ процессора между этими операциями, помечаются как «общие» и, кроме того, запоминается время их занесения в СОЗУ. Под СОЗУ понимается память глобальных данных объемом 1024 слова [2 стр. 186].
Каждая процедура имеет свое собственное локальное адресное пространство, глобальные данные принадлежат другим процедурам, насколько это позволяет область видимости процедуры. Т.е. для компилятора и для процессора обращения к локальным и глобальным данным неравноценны.
При открытии семафора в него записывается время открытия. При каждом закрытии семафора анализируется записанное в него время и время записи общих данных в СОЗУ. Те общие данные, которые попали в СОЗУ раньше открытия этого семафора, теперь не достоверны, так как могли быть изменены другим ЦП. Те данные, которые попали в СОЗУ после открытия семафора, достоверны, так как они не имеют отношения к данному семафору.
Разберемся на примере. Предположим, речи идет о потоко-безопасном счетчике.
- поток-1 захватывает (закрывает в терминах Эльбрус) семафор-1 на ЦП-1 в момент Т-1
- поток-1 читает переменную счетчик-1, которой не было в глобальном кэше
- поток-2 пытается захватить семафор-1 и блокируется
- теперь счетчик-1 появился в глобальном кэше ЦП-1 со временем Т-2
- поток-1 наращивает и записывает счетчик-1 в глобальный кэш ЦП-1 со временем Т-3
- поток-1 освобождает (открывает в терминах Эльбрус) семафор-1 со временем Т-4. В этот момент выявляется изменение счетчик-1 в пределах времени захвата семафора-1 и это значение записывается в память, теперь оно доступно всем
- поток-2 проснулся в момент Т-5 на ЦП-2 с захваченным (закрытым) семафором-1
- поток-2 пытается прочитать значение счетчик-1, которое уже есть в глобальном кэше ЦП-2 с меткой времени Т-0. Т.к. Т-0 меньше Т-5, значение считается инвалидным и читается из памяти.
- поток-2 освобождает (открывает в терминах Эльбрус) семафор-1 со временем Т-6. Поскольку ничего не менялось, ничего не происходит
Таким образом, на основании сравнения времени открытия семафора и времени занесения общих данных в СОЗУ, ЦП однозначно решает проблему достоверности данных. При этом не нужно сбрасывать весь глобальный кэш, что нанесло бы удар по производительности.
Чтобы обеспечить всё это, для меж-процессорного взаимодействия введены инструкции:
- “ПРЕРВАТЬЦП” с аргументом — маской заинтересованных процессоров. В результате все указанные процессоры получают прерывание.
- “ЖДАТЬЦП” — выполнение команды заключается в ожидании исполнения команды “ОТВЕТЦП” от всех процессоров, указанных в команде (параметре команды)
- “ОТВЕТЦП” — подтверждение получения и исполнения прерывания
По всей видимости, так распространяется информация о изменении состояния семафоров.
Также предположительно, таким образом должны распространяться данные, которые заносятся в СОЗУ аппаратно без закрытия каких-либо семафоров. Сюда относятся дескрипторы программных сегментов и таблицы соответствия математических и физических адресов.
Таким же образом можно (было бы) решить проблему доставки изменений в СОЗУ при закрытии семафора до СОЗУ других процессоров.
Вызов функций
Параметры вызова функции и локальные переменные лежат в стеке. Контекст вызова также лежит в стеке. В сущности, контекст состоит из двух указателей — на старый контекст (т.е. контексты связаны списком для осуществления выхода из функций) и на инструкцию, с которой произошел вызов. Плюс дополнительная информация, всё это удалось упаковать в два слова.
Но вызов функций в Эльбрусе своеобразен. Он многофазный.
- Сначала мы должны создать контекст будущего вызова и поместить его на вершину стека (маркировка стека)
- Вычисляем параметры вызова, которые оказываются на вершине стека в нужном порядке. Таким образом параметры находятся после контекста и к ним можно обращаться через дескриптор области локальных данных используя общий механизм аппаратной защиты.
- Выделяется память (размер которой определяет компилятор) под локальные данные. И всё, можно начинать исполнение функции.
При выходе, если необходимо, функция на месте своего бывшего контекста оставляет возвращаемое значение.
Зачем такие сложности? Почему не вызвать функцию более традиционно, одной инструкцией?
В этом случае параметры функции окажутся перед контекстом и дескриптор области локальных данных, который начинается с этого контекста не сможет их покрыть. Если же сдвинуть начальную область дескриптора назад, на начало области параметров, сломается список стека вызовов, либо придется прописывать в стек псевдо-параметр -длину области параметров. Что фактически та же самая маркировка стека.
Что касается упомянутого дескриптора для доступа к локальным данным, то он не один, их аж 32. И какой из них используется, определяется лексикографическим уровнем функции.
Лексикографический уровень процедур.
Этот механизм в чем-то похож на уровень привилегий х86. Имеются 32 базовых регистра дескрипторов, описывающих локальные данные процедур (+параметры) в стеке.
Каждый (как обычный дескриптор области) содержит:
- 32...38 разрядов — математический адрес начала описываемой области (“МАНАЧ”)
- 13...18 разрядов — максимальный индекс или размер (“ИНДМАКС”)
- 3 разряда — шаг дескриптора 2**n бит (n = 0,1,2,...,7) (“ШАГДЕСК”)
- 4 разряда — информация о режиме доступа (“ЗАЩИТА”)
Разные базовые регистры описывают разные контексты стека. Так, регистр №0 содержит дескриптор, описывающий стек из описателей процедур и данных операционных систем, регистры №1 и №2 описывают стеки описателей процедур и внешних имен выполняемой задачи, регистр №3 содержит дескриптор, описывающий стек блока верхнего уровня и так далее.
Таким образом, если некоторая инструкция инструкции содержит закодированное «имя» величины (физически расположенной в стеке), то оно определено только в данном контексте. Доступ к элементу стека осуществляется через лексикографический уровень функции, и порядковый номер слова в области стека, выделенной для данных этой функции (адресная пара).
ФОРТРАН, КОБОЛ, ЛИСП, APL — языки, не имеющие блочной структуры
В процедурах таких языков доступны лишь локальные переменные и параметры вызова. Распределение памяти для каждой вызываемой процедуры производится динамически. При входе в процедуру ей отводится в стеке необходимая область свободной памяти для формальных параметров и локальных переменных, указатель стека (УС) передвигается на новую границу.
Отводимая процедуре область памяти описывается дескриптором, помещенным в один из базовых регистров (пусть N). Обращение к величине в этой области осуществляется с помощью адресной пары (N, И).
Область свободной памяти в стеке ниже новой границы используется для хранения промежуточных результатов.
При выходе из процедуры, отведенная ей область памяти возвращается обратно в область свободной памяти путем восстановления прежнего УС. Таким образом, каждой процедуре отводится ровно столько памяти, сколько потребует динамика ее выполнения, и только тогда, когда это необходимо.
Если из рассматриваемой процедуры Р производится обращение к другой процедуре Q, то для процедуры Q отводится область свободной памяти точно таким же образом, как и для процедуры Р. При этом переменные, описанные в процедуре Р, и ее промежуточные результаты остаются в стеке и могут быть вновь использованы, когда произойдет возврат из процедуры Q.
При выходе из процедуры Q необходимо восстановить содержимое базового регистра с номером N и передать управление на оператор, следующий за оператором вызова процедуры Q. Для этого при входе в любую процедуру в начале области свободной памяти отводится 2 слова для связующей информации, состоящей из специальных управляющих слов:
- МКС — маркер стека аналогичен дескриптору, содержит размер области данных процедуры, а его собственный адрес — адрес начала этой области. Сверху вниз:
- 32 разряда — математический адрес предыдущего МКС (“АДРЕС”)
- 1 разряд — признак блокировки записи адресной информации (“БЛ”)
- 1 разряд — признак привилегированной процедуры (“РЕЖ”)
- 19 разрядов — размер области памяти в стеке, отведенной для процедуры (“РАЗМЕР”)
- 2 разряда — тип возврата: без значения; 1 слово; 2 слова (“ЗН”)
- 5 разрядов — резерв
- 4 разряда — номер лексикографического уровня процедуры (“LL”)
- УСВ — управляющее слово возврата — метка, по которой будет передано управление после возврата из данной процедуры плюс дополнительная информация.
- 18 разрядов — “? АДРЕСА” разница между адресом данного УСВ и адресом МКС запустившей процедуры
- 3 разряда — “триггеры”, информация о состоянии запустившей процедуры
- … признаки завершенности входа, прерывания …
- 16 разрядов — “Nk”, номер байта возврата относительной программной базы
- 11 разрядов — “БАЗА”, информация о базе программного сегмента, фактически, адрес функции, пара (Nk & БАЗА) содержит адрес возврата
- 4 разряда — номер лексикографического уровня процедуры
- …
При вызове процедуры Q принята следующая последовательность операций:
- Загружается в стек метка процедуры Q, то есть информация о том, в каком месте математической памяти находится вход в процедуру Q.
- Выполняется команда “МС” — маркировать стек. При этом:
- отводится свободная ячейка в верхушке стека, и в нее помещается заготовка УСВ для вызываемой процедуры Q
- в поле “? АДРЕСА” заготовки УСВ записывается разность между адресом этого УСВ и содержимым УМС (вспомогательный регистр, называемый указателем маркера стека), формируется так называемая динамическая цепочка. В УМС записывается адрес метки. Нужен этот регистр только в особый период, при передаче параметров.
- далее следуют команды, которые последовательно загружают в стек информацию о фактических параметрах.
- Выполняется команда “ВХОД”.
Выход из процедуры осуществляется командой “ВОЗВРАТ”, при этом:
- по лексикографическому уровню процедуры (К) находятся МКС и УСВ текущей процедуры, фактически, базовый регистр со смещением 0 смотрит на МКС
- соответствующее поле в УСВ процедуры (“ЗН”) указывает, оставлять ли значение в стеке
- по информации, хранящейся в поле “? АДРЕСА” процедуры (динамическая цепочка) поля “МАНАЧ” дескриптора К, находится МКС процедуры, вызвавшей данную (Р) и формируется новый дескриптор в её базовом регистре.
- управление передается в процедуру Р по информации, хранящейся в её УСВ. При этом по содержимому поля “БАЗА” в регистр базы записывается дескриптор программного сегмента процедуры Р, а в счетчик команд записывается содержимое поля Nk — номер программного слова, с которого должно быть возобновлено выполнение процедуры Р.
АЛГОЛ60, ПЛ/1, СИМУЛА, АЛГОЛ68 — языки с блочной структурой
Разработчиками принята точка зрения, согласно которой блок является частным случаем процедуры без параметров, у которой описание и вызов находятся в одном и том же месте программы.
Следовательно, каждый вход в блок сопровождается внесением на вершину стека двух слов — МКС & УСВ и имитацией вызова процедуры. Поскольку параметров нет, всё делается сразу. Для блока выделяется в стеке область под локальные переменные и создается дескриптор под эту область плюс предыдущие 2 слова с контекстом.
Однако, блок отличается от полноценной функции тем, что в нём доступны переменные из вышестоящих блоков той же функции. Как же это обеспечить?
Данная проблема была решена организацией стека дескрипторов. Как мы помним, у нас в наличии 32 дескриптора, первые 3 из которых зарезервированы. Остальные используются как стек. Т.е. при входе в блок мы наращиваем текущий лексикографический уровень (для этого есть регистр уровня), при выходе из блока, уменьшаем его. Итого, максимально возможный уровень вложенности блоков — от 30 для простых смертных до 32 для операционной системы.
Тут возникают проблемы — пусть мы из блока с уровнем вложенности N функции Q вызываем функцию P со своим деревом блоков. Если ничего не предпринять, то дескрипторы блоков (в базовых регистрах) будут перезаписаны и возврат из P произойдет в неработоспособное состояние.
Естественное место, куда можно сохранить содержимое базовых регистров — контексты блоков в стеке. На самом деле даже сохранять ничего не нужно, содержимое базовых регистров можно заново воссоздать при возврате:
- находится адрес МКС предыдущей функции. Для этого достаточно шагать назад по списку МКС число раз, соответствующее предыдущему значению лексикографического (регистра) уровня
- предыдущее значение лексикографического уровня можно взять в поле “LL” ближайшего МКС
- поле “БАЗА” всех просматриваемых УСВ должно быть одинаковым и указывать на адрес нужной функции, это еще один критерий остановки прохода по списку МКС
- в процессе прохода по списку на основании текущего МКС перезаписываем дескриптор с номером поля LL
Поддержка блочных языков выглядит довольно громоздкой. Кроме того, механизм базовых регистров имеет двойственную природу — с одной стороны, это механизм разграничения операционной системы, библиотек и конечных программ. А с другой стороны — стек дескрипторов блоков. Почему так получилось?
Из за аппаратной защиты памяти. Каждому блоку соответствует свой дескриптор, стек блоков соответствует стеку дескрипторов.
Почему нельзя было обойтись единым дескриптором для всей функции? По всей видимости потому, что тогда при входе в функцию пришлось бы выделять локальную память для самого худшего случая.
Например:
procedure p;
begin
integer i;
...
begin
integer array s [1:1000];
...
end
...
end
даже если внутренний блок посещается крайне редко, нам тем не менее пришлось бы каждый раз при вызове P выделять под локальные переменные память для 1001 целого, а не 1 фактически необходимого. В условиях, когда память является весьма дорогим ресурсом, это весомый аргумент.
Но почему не сделать для функции дескриптор от МКС функции до конца стека? Потому что фактически это будет отказ от аппаратной защиты памяти (на 50% :). Кроме того, возможно, сегмент стека умел (или планировалось, что будет уметь) расширяться при переполнении, тогда у него просто нет конца.
Справедливости ради, на современных “Эльбрусах” реализован (в целях безопасности, по-видимому) второй аппаратный стек для хранения информации возврата [9]. С помощью такого механизма вышеописанная защита реализуется куда как более элегантно. Правда, современные “Эльбрусы” имеют мало общего с предметом данной статьи.
Итого
Вот мы и добрались до конца. При этом рассмотрели основные архитектурные особенности “Эльбрусов”. Автор намеренно не касался некоторых аспектов, например, работы с периферией, устройства файловой системы … т.к. за истекший период всё настолько сильно изменилось, что (с точки зрения автора) представляет интерес с почти археологической точки зрения — “интересно, ну и как же они выкручивались в то время то?”.
А вот, некоторые именно архитектурные идеи, заложенные в комплекс, не потеряли актуальности и по сей день. Например, теговая система продолжает жить в “эльбрусах” современных. Жаль, что идея суперскалярного стекового процессора не прижилась, хотя концептуально она (на взгляд автора, по крайней мере) стройнее и проще, чем идея регистровой суперскалярной архитектуры или архитектур с явным параллелизмом.
В любом случае, на момент своего появления “Эльбрус” несомненно был на самом острие прогресса, причем его создатели прокладывали свой собственный путь в будущее, опираясь, конечно, на мировой опыт, выдвигали и реализовывали оригинальные идеи.
Дальнейшее развитие комплекса его создатели видели [2, стр 201] в том числе и в использовании конвейеризированного векторного сопроцессора (который существовал и на реальных задачах показывал производительность в 80 Mflops [2, стр 166]), что вполне укладывается в наши сегодняшние представления.
Источники
[1] Масич Г.Ф. лекции
[2] Сборник статей В.С Бурцева (руководитель проекта, главный по аппаратной части)
[3] WIKI статья про Эльбрусы
[4] www.osp.ru/os/2009/02/7314081
[5] www.ixbt.com/cpu/e2k-spec.html
[6] здесь интерес представляют комментарии Погорилого
[7] www.pvsm.ru/programmirovanie/106969
[8] www.caesarion.ru/warrax/w/warrax.net/88/elbrus.html
[9] www.mcst.ru/files/511cea/886487/1a8f40/000000/book_elbrus.pdf
UPD: огромное спасибо хабровчанину wasya за исправление ошибок, уточнения и комментарии, которые, конечно же, были учтены
Комментарии (37)

nckma
25.10.2016 09:17У меня от одного этого
180 Мб или 90 Кмикросхем. Всё это удалось для максимальной комплектации разместить в 8 шкафах (секциях ОП).
мурашки по спине. 90К микросхем РУ3! Неужели это могло работать?
ru_vlad
25.10.2016 11:21+1Нормально работало, керамический корпус и 5 приемка.
На смену пришли РУ6 объем тот же но требования по питанию меньше.
PaulAtreides
25.10.2016 11:47При этом читал когда-то статью о том, что замена Эльбрус-2 на Эльбрус-90 в системе СПРН дала возможность достигнуть характеристик станций, которые были заложены в изначальном техзадании, но никогда не достигались из-за проблем с вычислительным комплексом.
DrPass
25.10.2016 23:13> 90К микросхем РУ3! Неужели это могло работать?
Да, до тех пор, пока не пропадало напряжение смещения подложки +12В.
rfq
25.10.2016 10:34Я сам слушал лекцию Бабаяна, где он говорил про переименование регистров, то ли в Э-1, то ли в Э-2. А вы про который рассказываете?

zzeng
25.10.2016 10:51Э-1 и Э-2 близки по архитектуре, элементная база разная.
Возможно слово переименование у него имело какой-то другой смысл,
чем общепринятый сейчас.
В некотором смысле регистры действительно переименовывались внутри, хотя прямого доступа к ним (к верхушке стека) именно как к регистрам не было.

rvt
25.10.2016 10:38Я учился в 1980-е годы в Одесском университете. И ходили слухи (передаю слухи, как слышал; как говорится, «почем купил, потом и продаю»), что, вроде бы какой-то «Эльбрус» из штаба Одесского военного округа передают ОГУ.
Потом кто-то нам говорил, что «эта штука» может работать «со 100 тыс. виртуальных машин». Цитирую дословно, я эту фразу хорошо запомнил. Она тогда звучала как-то диковато. Вроде бы имелось в виду, что, теоретически, поддерживается такое количество рабочих мест. Каждое со своей ОС, своим оператором и т. д. То есть, получалось, что «Эльбрус-2» — это ОЧЕНЬ многопользовательская система.
Помню, в компьютерном классе на столах стояли «зеленые» мониторы и клавиатуры. Провода от них уходили в пол. Системных блоков, естественно, не было.
При включении на экране выплывала большая звезда из псевдографики (кажется, из звездочек) и надпись «МЕРА КАМАК».
Потом предлагали выбрать операционную систему из пары десятков каких-то ОС. Не помню уже, что там было. Я далек был тогда от всей этой машинерии :) Кажется, из знакомого, были какие-то DOS.
Что-то мы там выбирали и, потом, работали с FORTRAN'ом.
Извиняюсь, если что-то напутал — давно это было, да и не вникал я тогда во всё это.
Мог это быть «Эльбрус»?zzeng
25.10.2016 10:46ДОС Примус (ЕС-1021, если не ошибаюсь), с которой удалось соприкоснуться, легко тянула 32 терминала на 64 килобайтах озу
Но 100К на Эльбрусе — это вряд ли.
Виртуальные машины были на поздних ЕС-ках.
PaulAtreides
25.10.2016 11:25+2МЕРА-КАМАК — это польские ЭВМ из линейки СМ.
Idot
25.10.2016 15:01Это то, на чём я сам начинал! На УПК была МЕРА за которой я проводил весь день раз в неделю.
(а в школе была Atari, кажется них было то ли два, то ли один урок в неделю)
PS я ещё потом получил некий документ с надписью «оператор ЭВМ» :)

sshikov
25.10.2016 11:57+2Не по поводу Эльбруса, а скорее по поводу многопользовательской работы — у нас на ЕС-1061 с 8 мегабайтами RAM всего-то реально работало под 100 рабочих мест.
Это виртуальные ОС, VM/CMS (но можно было и выбрать, да).
Во многом благодаря тому, что а) ввод-вывод обеспечивали каналы, у которых были свои процессоры, б) терминалы не генерировали прерывание на каждое нажатие кнопки клавиатуры, а умели делать такие вещи, как вставка и удаление символов в пределах экрана.
Но надо честно сказать, что один пользователь с каким-нибудь Reduce (или любой расчетной задачей вообще) мог спокойно загрузить всего один или два процессора на все 100%. Так что многопользовательская работа все-таки была реально ограниченная ресурсами. Поэтому в 100К не верю, хотя смотря что делать, конечно.
BiosUefi
25.10.2016 12:12-8Те кто моего сына научили, что в космос первым полетл Армстронг, причем сразу на луну.
PaulAtreides
25.10.2016 13:11+7Те кто моего сына научили
Кто же те злодеи, которые мешали вам учить своего сына?

dartraiden
25.10.2016 13:27+4Я лично встречал человека, уверенного, что Ленин сверг с престола «то ли Петра I, то ли III».
А разгадка проста — школу не надо было прогуливать, а историю надо было учить.
nikitadanilov
25.10.2016 18:39+1> Этот механизм в чем-то похож на уровень привилегий х86.
Этот массив дескрипторов называется Dijkstra display: http://cs-exhibitions.uni-klu.ac.at/index.php?id=4&uid=9.zzeng
26.10.2016 06:10Спасибо за ссылку. А когда Дийкстра предложил этот механизм? Навскидку я не нашел.
Но в Эльбрусе механизм Dijkstra display содержит зарезервированные индексы — 0 для ОС, 1 для программ, 2 для библиотек. Именно это я имел ввиду когда говорил о привилегиях.

alz72
25.10.2016 19:14Суперскалярность весьма похожа на Интел.
А вот с многопоточностью я так до конца и не понял — что понимается под «контекстом» — это аналог TCB из винды?
kxl
26.10.2016 13:56Не мудрено… Поищите «pentium эльбрус Пентковский», например www.koshcheev.ru/2012/08/27/intel-pentium-pentkovski/
zzeng
26.10.2016 14:04Это что-то из области «американцы на луне не были» наоборот.
МКП и Э-3 реально существовали, также как и векторный сопроцессор к Э-2.
Эль-90 — разве что на бумаге.
Идеи и опыт, полученные при разработке Эльбрусов несомненно пригодились Интелу.
Но у Интела и своего опыта хватает а идеи… они ведь были описаны, достаточно иметь желание читать.
black_semargl
26.10.2016 04:16Его достоинства — одновременно и недостатки.
1) очень узок круг специалистов, способных понять куда всё это можно эффективно применить. Вот для того же Итаниума нормальный оптимизирующий компилятор так и не осилили написать. В общем, «каждая фича, это отдельная песня. Это почти шедевр. Даже чересчур шедевр, просто искусство ради искусства.» (ц)
2) через десять-двадцать лет после разработки программы стали требовать совсем иного набора данных и команд, а тут оно аппаратно прошито и не изменить.
3) стековые команды очень хреново совместимы с кешем и аппаратным предсказанием исполнения.zzeng
26.10.2016 05:50+1Итаниум появился на 20 лет позже и он совсем в другой парадигме живёт — явного параллелизма.
Сами по себе стековые процессоры появились задолго до Эльбруса и отлично себя показали.
Не знаю что там начали требовать программы через 20 лет, но фортран он и до сих пор фортран, например.
Компилятор С для него не написали, впрочем, в начале 80-х совсем неочевидно было, что тот выстрелит.
«МКП, как и Эльбрус-3, был убит „перестройкой“ — прекращением финансирования обронной тематики. Потому и резали „по живому“, закрывая темы, что финансирование упало многократно, пытались сохранить хоть что-то, при этом волей-неволей приходилось прикрывать почти все разработки.» (C)
Стековые команды отлично совместимы с кэшем.
Внутренний паралеллизм они тоже не исключают.khim
26.10.2016 17:24+1Внутренний паралеллизм они тоже не исключают.
Не исключают, но делают реализацию заметно тяжелее. Заметьте что Itanium тоже, в некотором смысле стековый (регистровое окно, фоновая откачка регистров в память, вот это вот всё), что делает и аппаратную реализацию тяжёлой, а эмуляцию — почти невозможной.
Всё хорошо в меру: архитектуры Элюбруса и Итаниума содержат вещи, которые сделали их использование сильно неудобным, но при этом распространённые архитектуры весьма небезопасны.
Их, грубо говоря, можно использовать в «плоском» режиме, когда всё быстро, но одна ошибка — и вся система скомпроментирована. Объёмы кода, которому ядро «доверяет» меряется в мегабайтах, а то и в десятках мегабайт — конечно это добром не кончается!
А можно — в безопасном. С микроядром и постоянным переключением контекстов. Но это медленно, а потому выбирают ускорее на 10 процентов вместо безопасности. Эльбрус был доказательством того, что безопасность не обязана приводить к катастрофическому замедлению как у Intelаzzeng
27.10.2016 05:11Это всё стоит рассматривать на фоне технологического ландшафта.
Если Эльбрусы были порождены появлением интегральных схем, то к моменту их постановки в серию уже возникли СБИС (VLSI) которые позволили разместить процессор на небольом к-ве микросхем.
Что дешевле, меньше расстояния, можно поднять частоту, меньше ест, надёжнее…
Соответственно было и встречное движение — чтобы разместить процессор на меньшем к-ве микросхем приходится упрощать логику, 32-разрядные системам проще чем 64-разрядным, неожиданный шанс получили 16-разрядные. В очередной раз эволюция прорвалась там, где мало кто ждал.
А в это время на просторах бывшей 1/6 разработчики были больше озабочены вопросом «как прокормить семью».
sshikov
29.10.2016 13:54+1А вот будет ли кому-нибудь интересна скажем история про VM/SP и советские машины серии ЕС? Не с точки зрения железа, тут разве что характеристики можно будет вспомнить, а с точки зрения ОС, средств разработки и пр.
PaulAtreides
30.10.2016 15:05Не ошибусь, если скажу, что интересна будет многим.
Любые инженерные решения в условиях ограниченных ресурсов всегда интересны.
sshikov
А термин «файл откачки» это вы где взяли? Мне как-то более привычно видеть термин «подкачки», хотя по смыслу конечно можно употреблять оба. Ну и сегодня вроде второй вариант более широко распространен.
zzeng
Это оригинальный термин, использованный в документации :)
Да, звучит забавно, не решился подменить.
bertmsk
Ну по логике вещей это именно что «файл откачки». Поскольку первичная операция — это сбросить неиспользуемые страницы. Подгрузка обратно в ОЗУ уже вторична.
sshikov
Я тут совершенно не против, просто заметил, что «подкачки» все-таки как-то больше прижился. Причем еще с тех самых пор.