Живая миграция – что это?
Живая миграция контейнеров подразумевает собой процесс перемещения приложения между разными физическими машинами или облаками без прерывания работы приложения и разрыва связи с пользователем. Память, файловая система и сетевое соединение контейнеров, запущенные поверх «голой» аппаратуры, передаются от исходного хост-компьютера к месту назначения, поддерживая рабочее состояние без прерывания работы.
Проблемы, которые решает живая миграция
Существует несколько проблем, которые может решить живая миграция:
- Период простоя во время обслуживания аппаратуры
- Несбалансированная загрузка кластера
- Проблемы с облаком
Альтернативные Решения
Все выше упомянутые проблемы можно решить, и сейчас мы расскажем несколько вариантов решения данных проблем без помощи живой миграции.
- Запланированные периоды простоя. Для выполнения технических работ по обслуживанию кластера, нужно пройти три шага:
1. Заранее уведомить пользователей (владельцев приложений) об окне обслуживания и возможном периоде простоя
2. Отключить аппаратное оборудование
3. Подключить обратно только после того, как все необходимые изменения будут выполнены. В этом случае проблемой является относительно большой период простоя.
- Перенаправление трафика. Чтобы выполнить обслуживание кластера необходимо восстановить копию каждого приложения в другом аппаратном узле, затем перенаправить трафик к этой новой копии и закрыть предыдущую. В этом случае проблемой является сложность данного процесса — необходимо иметь специально разработанные приложения для получения высокой доступности и синхронизации данных. Кроме того, для выполнения этой задачи может потребоваться больше аппаратных ресурсов.
- Микросервисы. Детальное деление сервисов приложений на отдельные контейнеры и их распределение по различным физическим серверам помогает избежать периодов простоя в случае сбоя аппаратного обеспечения. Вышедшие из строя контейнеры будут автоматически восстановлены в активном аппаратном узле. Однако в этом случае проблемой является опять же сложность данного процесса, поскольку приложения в кластере должны быть разработаны таким образом, чтобы можно было управлять высокой доступностью и восстановлением процесса после сбоя.
Как Работает Живая Миграция
Давайте рассмотрим процесс живой миграции с технической стороны на примере следующей схемы:
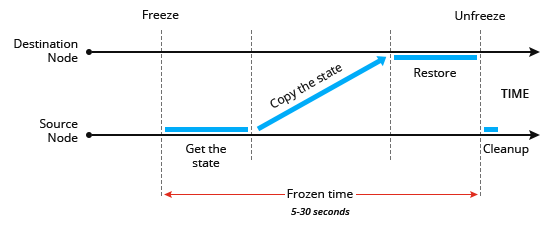
- Исходный Узел (Source Node) — местоположение контейнера перед живой миграцией
- Узел назначения (Destination Node) — местоположение контейнера после живой миграции
Чтобы выполнить миграцию, платформа замораживает контейнер в исходном узле, блокируя память, процессы, файловую систему и сетевые соединения, и сохраняет состояние этого контейнера. После этого он копируется в узел назначения. Платформа восстанавливает состояние и размораживает контейнер в данном узле. Затем, в исходном узле осуществляется процесс быстрой очистки данных мигрирующего контейнера.
Всё довольно таки просто: вы получаете, копируете и восстанавливаете состояние контейнера. Однако, в этом случае нужно принимать во внимание период заморозки, который нужно учитывать при разработке (архитектуры) приложений, так как этот момент может оказаться критическим для некоторых из них.
Существует два способа осуществления живой миграции. Одним из них является предварительное копирование памяти. Если вы хотите перенести контейнер, платформа направит отслеживаемую память на исходный узел, и будет копировать эту память одновременно с узлом назначения до тех пор, пока различие не станет минимальным. После этого платформа замораживает контейнер, получает оставшееся состояние, переносит его на узел назначения, восстанавливает и размораживает его.
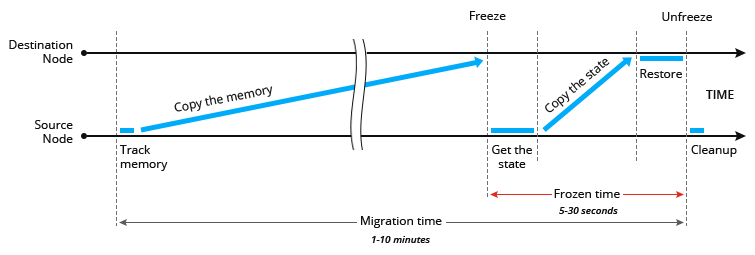
Другой способ — пост-копирования памяти, или другими словами — ленивая миграция. Система вначале замораживает контейнер в исходном узле, получает состояние наиболее быстро меняющихся страниц памяти, переносит состояние на узел назначения, восстанавливает его и размораживает контейнер. Остальная часть состояния в фоновом режиме копируется из исходного узла на узел назначения.

Обычно, в зависимости от приложения, время замораживания для каждого контейнера занимает от 5 до 30 секунд. Это действительно короткий срок по сравнению с возможными часами простоя во время обслуживания кластера.
Примеры Использования Живой Миграции
- Обслуживание аппаратных средств без периода простоя
- Перераспределение загрузки
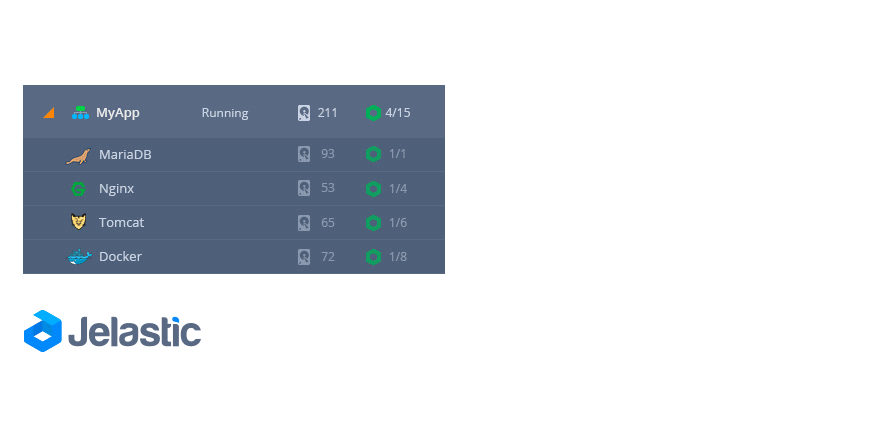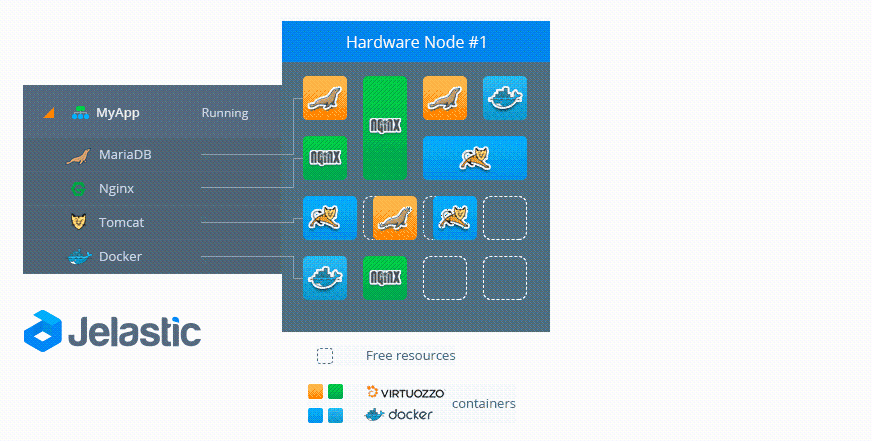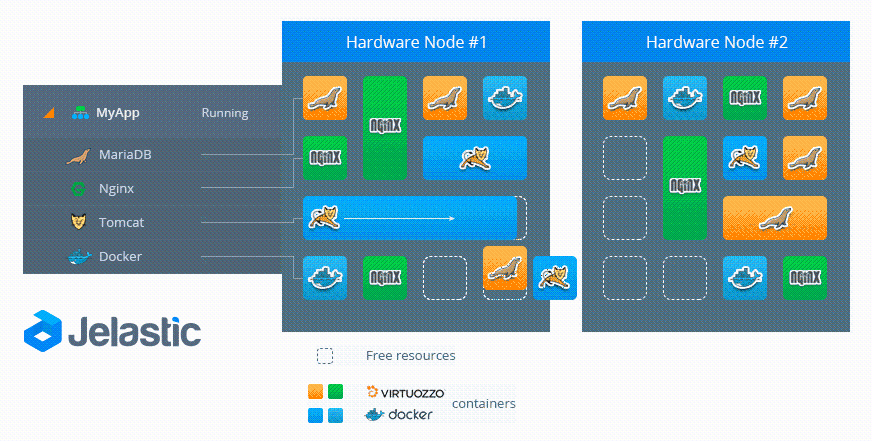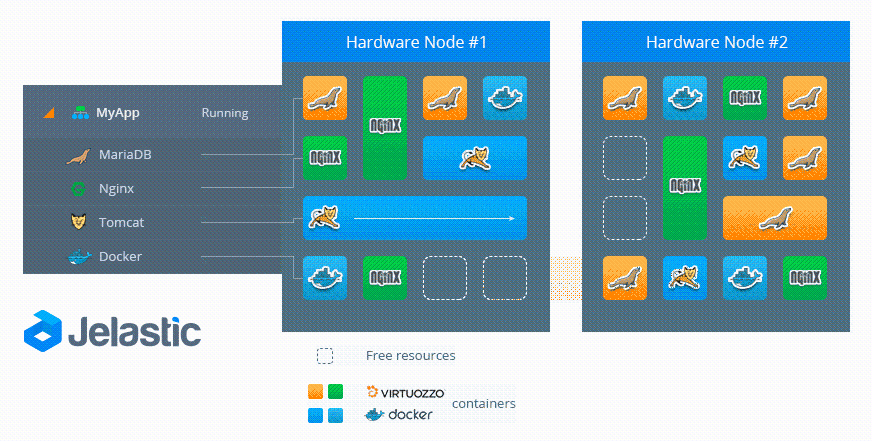
- Высокая доступность между зонах доступности в центрах обработки данных (ЦОД)
- Переход к другому облачному провайдеру
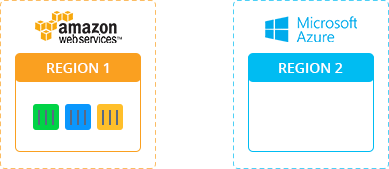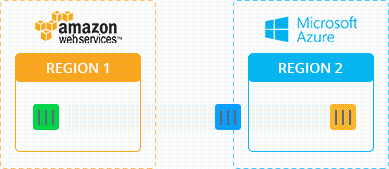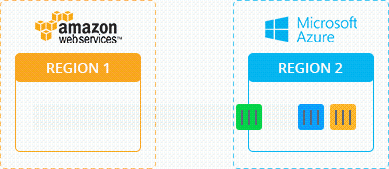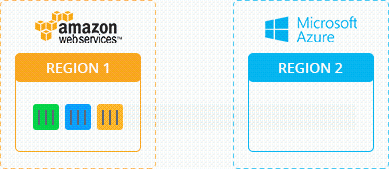
Подводные Камни и Возможные Недостатки
При всех преимуществах живой миграции, также существуют несколько недостатков, которые нужно принимать во внимание перед началом миграции:
- Во время живой миграции вы можете заметить некоторое снижение производительности пока контейнер находится в состоянии заморозки. Для некоторых приложений это критический недостаток, так как они не приемлют любое снижение производительности (к примеру, монолитные высоконагруженные онлайн приложения). Однако, кратковременная заморозка не является серьёзным недостатком для большинства приложений в интернете, особенно если говорить о веб-приложениях.
- Другая сложность связана с большим объемом быстро-меняющихся данных, которые не так легко перенести от одного облачного провайдера к другому. Период ожидания и большой объем данных могут препятствовать успешному выполнению живой миграции.
- Публичные IP-адреса в мульти-облаке. Невозможно перенести контейнеры с публичным IP-адресом от одного облачного провайдера к другому, поскольку IP-адрес привязан к конкретному провайдеру.
- Если приложение внутри контейнера использует проприетарный API или проприетарные облачные сервисы конкретного облачного провайдера, выполнить живую миграцию с одного облака на другое может быть очень сложно или даже невозможно.
Живая Миграция на Современном IT-Рынке
Какие компании предлагают живую миграцию контейнеров на сегодняшний день?
- Virtuozzo – эта компания, на самом деле, создала технологию живой миграции контейнеров; они были пионерами в этой области и на сегодняшний момент предлагают движок живой миграции, позволяющий проводить атомарную миграцию контейнера с одного физического хоста на другой.
- runC от Open Containers Initiative является еще одним многообещающим контейнерным решением с поддержкой живой миграции на базе CRIU.
- Jelastic предлагает платформу с оркестрацией контейнеров, которая предоставляет живую миграцию как атомарных контейнеров, так и приложений со сложной топологией развертывания между аппаратными хостами, зонами доступности, центрами обработки данных и облачными провайдерами.
Демо: Миграция Minecraft в Режиме Реального Времени
Для того, чтобы увидеть процесс миграции приложения Minecraft из AWS на Azure в режиме реального времени без простоев, просмотрите следующее видео:
Живая миграция контейнеров все еще является относительно новой технологией на рынке. Тем не менее, преимущества этой технологии для современного бизнеса очевидны — никаких простоев во время обслуживания, не нужно тратить много усилий на подготовку и проверку рабочей среды в другом облаке. Именно поэтому живая миграция является отличным решением для лучшей доступности и гибкости. Поделитесь своим опытом миграции контейнеров между облаками или датацентрами в режиме реального времени.
Комментарии (35)

Saffron
25.10.2016 13:44+4Всё-таки, у вас заголовок совершенно не совпадает с содержимым. Прочитайте сами: «живая миграция контейнеров: взгляд _изнутри_». Мне даже интересно стало. А вы дали взгляд _снаружи_. Что достаточно очевидно. А вот взгляд изнутри контейнера наверняка содержит множество интересных технических ньюансов.

ihormanchik
25.10.2016 13:56Действительно, изнутри работает все очень интересно, когда-то в руки мне попала диссертация Павла Емильянова как-раз по этому проекту, CRIU, еще немало усилий вложил Кирилл Колышкин, сейчас оба работают в компании Virtuozzo. Если у Вас есть какие-то конкретные вопросы относительно нюансов — буду рад на них дать ответ, в рамках своего понимания конечно же.
Saffron
25.10.2016 14:45Конкретных вопросов нет, я не в теме. Но хотел бы послушать чьи-нибудь рассказы, чтобы понять, насколько это страшно — живая миграция изнутри, надо ли её бояться, чего может отвалится и прочее. Потому что пока по косвенным источникам я для себя пометил живую миграцию как сомнительную технику с возможными осложнениями и предпочитаю думать, что надёжно можно перенести только отключённую машину, а запущенную — как повезёт.
ihormanchik
25.10.2016 16:07+2есть особенности, которые надо соблюдать при живой миграции:
— общий домен коллизий в сети, где жил src контейнер и где будет жить dst контейнер (решается оверлейной сетью если разные провайдеры железа)
— чем реже данные будут изменяться в памяти — тем меньше freezetime, который в любом случае неизбежен во время синка последней дельты изменяющихся данных, тем лучше, ну и приложение должно быть готово к этому маленькому окну (хорошая новость в том, что пакеты сетевые при TCP-соединении не потеряются, и эстеблишить новый конект клиенту не нужно, работает фича ядра linux — tcp-rapair режим)
— важна целостность данные при переезде процесса (именно данных, на которые дескрипторы были отрыты т.е. файл на сорс ноде до заморозки должен быть такой же точно и на dst-ноде после разморозки процесса)

jelastic
25.10.2016 18:30+1вот, кстати, можно посмотреть сессию Павла Емильянова по этой тематике https://www.youtube.com/watch?v=bnvbq0ePqfs
ivlis
25.10.2016 17:23+1Да, чувствуешь себя обманутым. Ожидаешь какой-то хитрый модуль ядра и код утилит, который это делает, а получаешь красивые и бесполезные картинки и триал на 15 дней…

izzholtik
25.10.2016 14:02Стоит отметить, что в представленном видео игрок в майнкрафте намеренно выполнял только те действия, которые не требуют синхронизации с сервером. Об активности сервера свидетельствует только подъём лута в самом начале и несколько движений моба в самом конце, всё остальное время сервер мог быть заморожен. Таймауты соединения в майнкрафте большие.
ihormanchik
25.10.2016 14:09на этом ролике играю я, дело в том, что намеренно я ничего не выполнял т.к. совершенно НЕ умею играть в майнкрафт, что касается таймаутов, то они не такие уж и большие, мы проводили много тестов по результатам которых увидели, что если сервер у клиента забрать больше чем на 3 секунды (вне зависимости от того, что происходит в игре), то игра вываливается с сообщением «Connection Lost», можете сами попробовать
izzholtik
25.10.2016 15:51Насчёт трёх секунд — это как-то странно, ну да ладно, спишем на разные версии майна.
А что происходит с пакетами, пришедшими непосредственно в момент переноса приложения?ihormanchik
25.10.2016 16:12+2в ядре Linux есть tcp-rapair режим, он позволяет разморозить процесс с уже установленными сетевыми соединениями в таком виде, в котором они были до заморозки, перед моментом фриза контейнер перестает отвечать «TCP-квитанциями» о получении пакетов новых, потом dst-контейнер делает ARP-реанаунс, после чего получает повторно отправленные клиентом пакеты и уже отвечает нормально на них, таким образом при TCP-соединении пакеты не теряются если не умирают по таймауту (в случае если freezetime окно оказалось слишком большим, к примеру в RAM были частоизменяющиеся данные)

Prototik
26.10.2016 06:27Таймаут по-умолчанию в майне 30 секунд — в это время сервер может вообще выпасть из сего мира и вернуться обратно. Поверьте мне, я занимался разработкой модифицированных ядер майнкрафта одно время.
ihormanchik
26.10.2016 12:56верю, я тоже когда-то пересобирал и сервер и клиент для тестов через mc-dev, Вы сейчас говорите о ReadTimeout, который и правда стоит в 30 секунд, но вылетает оно не по нему, еще есть SocketTimeout и IdleTimeout, т.е. Вы можете выставить ReadTimeout по обе стороны хоть в пару минут, это не спасет, клиент будет плевать ConnectionLost по истечении нескольких секунд от которых сервер ему не ответит (возможно еще и зависит от действий клиента, о которых писал izzholtik)
jelastic
25.10.2016 14:17можете также просмотреть ролики с использованием других приложений во время миграции
https://www.youtube.com/watch?v=Yij5gmpTJzg
https://www.youtube.com/watch?v=Ebzf9RvsLCQizzholtik
25.10.2016 15:29С VLC, на самом деле, тоже не всё так однозначно, он наверняка кэширует какую-то часть видео, а вот с докером уже интереснее.
Можно как-то бесплатно «потрогать» ваше решение?jelastic
25.10.2016 16:08можете зарегистрироваться на одном из наших хостинг партнеров, например, Mirhosting https://jelastic.cloud/details/mirhosting
у них две недели триала и доступны докеры
ihormanchik
25.10.2016 16:18с VLC действительно проще т.к. есть буфер и он кеширует стрим на клиенте, потому для этого юзкейса это решение можно назвать «безопасным» и уместным
timofei-durakov
26.10.2016 17:21Могли бы вы записать совсем простой синтетический сценарий(клиент — серверное приложение), где клиент стабильно бы делал 'ping' к серверу скажем раз в секунду. Интересно было бы увидеть статистику со стороны клиента во время живой миграции такого сервера(для pre- и post- copy).
ihormanchik
27.10.2016 13:05технически возможно, но все, что будет видно — это время сколько клиент «не видел» сервер, т.к. пакеты при echo-запросе с TTL в 1с и окном больше 1с будут пропадать в никуда, ну а время окна само будет зависеть от того, что изменяется за определенный промежуток времени в RAM, если скажем минимальный ванильный контейнер с данными в RAM 6mb (на примере Jelastic), которые практически не меняются, то и фризтайм будет порядка той секунды, за которую мы на этом примере ничего не увидим, в том числе и разницы между pre/post copy режимами, более того, нельзя сказать, что один из режимов лучше другого (pre/post), все зависит от конкретного приложения и его данных, иногда быстрее срабывает при одном режиме, иногда при другом…
timofei-durakov
28.10.2016 12:25Я думаю время этого окна одна из метрик важных для живой миграции: в зависимости от того что выполняется в контейнере(условно cattle/pets/pandas) оператор и принимает решение о допустимости миграции, не знаю насколько это валидно для контейнеров, но для виртуальных машин(qemu), post-copy в случае фэйла выключает домен.
ihormanchik
28.10.2016 13:37все верно, при этом есть приложения, которые относительно безопасно мигрировать в 99% случаев, такие как:
— большинство веб-приложений (за исключением случаев когда браузер что-то очень оперативно в реалтайме обрабатывает и запоздание на секунду-вторую есть критичным)
— streaming servers (какие как Red5)
— слейвы баз данных с асинхронной репликацией (т.к. догнать свое состояние они могут уже после переезда, пару секунд не решают ничего)
— MQS (сервера очереди сообщений)
и т.д.
живая миграция не есть панацеей абсолютно от всех проблем, но если применять эту технологию там, где это возможно, то это может очень здорово упростить жизнь
timofei-durakov
25.10.2016 16:15Интересно было бы прочитать про особенности работы живой миграции в двух режимах приведенных в статье:
Что в данном случае происходит с контейнером во время frozen time, — равносильно ли это "паузе" для контейнера?
Что если для pre-copy режима довести копирование страниц памяти до порогового значения так и не получится? Какие методы оптимизации будут использоваться?
Что произойдет с контейнером в случае ошибки во время post-copy миграции? Как реализован rollback на исходный узел?
Как происходит подготовка к миграции? настройка сети, например? Будут ли отличия в post- и pre- copy?jelastic
25.10.2016 16:17спасибо за вопросы, немного выше Игорь рассписал некоторые детали https://habrahabr.ru/company/jelastic/blog/313512/#comment_9877176
дайте знать, если еще что-то интересует
Dm3Ch
25.10.2016 19:13Почитав статью и посмотрев видео с миграцией minecraft сервера между облачными провайдерами, я не смог понять одну вещь. Клиент игры подрубается к серверу на определённом IP, когда контейнер был перенесён в другое облако, как переносится соединение?
Возможно, мой вопрос сформулирован не верно, но очень хотелось бы узнать ответ.ihormanchik
25.10.2016 19:20+1После миграции контейнера, где живет процесс серверного приложения, IP-адреc остается такой же точно как бы до миграции (даже если этот адрес внутренний), в случае если миграция происходила в другое облако, то между облаками тянется оверлейная сеть (грубо говоря внутри физической внешней сети делается другая, уже логическая сеть, инкапсулированная в физическую), таким образом между облаками контейнеры существуют в одном домене коллизий и чувствуют себя как бы в одной сети. Что касается «точки входа» в этом случае (ноды, где будет прибит уже белый IP), то это может быть обычный шлюз, который включен в эту же самую «логическую» оверлейную сеть.
KroArtem
25.10.2016 19:36Мне кажется, или иллюстрации pre-copy и post-copy нарисованы неправильно? В первом случае операция freeze должна быть после копирования основной части памяти, а во втором случае unfreeze должен происходить до ленивого копирования, и тогда описание будет соответствовать иллюстрациям.
ihormanchik
26.10.2016 00:37Вы все верно подметили, благодарю за подсказку, завтра же подправим. Спасибо! )
timofei-durakov
26.10.2016 17:29+1Исправьте, пожалуйста, временную шкалу на иллюстрациях: общая оценка времени 1-10 секунд, Frozen Time 10-30

NoOne
29.10.2016 17:05А почему Frozen Time такое большое? У той же VMware до секунды в лучшем случае (при низкой загрузке, небольшой ВМ), до 5 секунд в худшем случае (большая загрузка хостов, большая ВМ)
ihormanchik
02.11.2016 12:39ну здесь все очень относительно
1) vMotion у VMware иногда может фризиться и на полторы минуты, особенно если у виртуалки много дисков и много снапшотов или очень медленная сеть, все зависит от ситуации
2) vMotion катает виртуальный машины, CRIU катает standalone процессы, это разные подходы для решения одной задачи, каждый имеет свои плюсы и минусы: к примеру, вероятность успешной миграции VM гораздо ниже чем вероятность успешного переезда одного лишь процесса, переезд виртуальной машины в общем занимает больше времени
rawsik
Расскажите пожалуйста, на чём построен у вас PaaS, какая именно система оркестрации контейнеров?
ihormanchik
Оркестратор так и называется — Jelastic. Есть бесплатный триал на 14 дней почти у всех хостинг-сервис провайдеров, через которые продается сервис. Детали есть на сайте компании.