Например, поиск теперь впервые использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.

Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
В этом посте я постараюсь немного рассказать о том, как у нас это получилось и почему это не просто ещё один алгоритм машинного обучения, а важный шаг в будущее.
Искусственный интеллект или машинное обучение?
Почти все знают, что современные поисковые системы работают с помощью машинного обучения. Почему об использовании нейронных сетей для его задач надо говорить отдельно? И почему только сейчас, ведь хайп вокруг этой темы не стихает уже несколько лет? Попробую рассказать об истории вопроса.
Поиск в интернете — сложная система, которая появилась очень давно. Сначала это был просто поиск страничек, потом он превратился в решателя задач, и сейчас становится полноценным помощником. Чем больше интернет, и чем больше в нём людей, тем выше их требования, тем сложнее приходится становиться поиску.
Эпоха наивного поиска
Сначала был просто поиск слов — инвертированный индекс. Потом страниц стало слишком много, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf.
Эпоха ссылок
Потом страниц стало слишком много на любую тему, произошёл важный прорыв — начали учитывать ссылки, появился PageRank.
Эпоха машинного обучения
Интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. Произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Где-то на этом этапе человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Один из лучших алгоритмов машинного обучения изобрели в Яндексе — Матрикснет. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Но у «классического» машинного обучения есть предел: оно работает только там, где очень много данных. Небольшой пример. Миллионы пользователей вводят запрос [вконтакте], чтобы найти один и тот же сайт. В данном случае их поведение является настолько сильным сигналом, что поиск не заставляет людей смотреть на выдачу, а подсказывает адрес сразу при вводе запроса.
Но люди сложнее, и хотят от поиска всё больше. Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды в течение всего периода наблюдений. Это значит, что у поиска нет данных о поведении пользователей в достаточном количестве, и Матрикснет лишается ценных факторов. Такие запросы в Яндексе называют «длинным хвостом», поскольку все вместе они составляют существенную долю обращений к нашему поиску.
Эпоха искусственного интеллекта
И тут время рассказать о последнем прорыве: несколько лет назад компьютеры становятся достаточно быстрыми, а данных становится достаточно много, чтобы использовать нейронные сети. Основанные на них технологии ещё называют машинным интеллектом или искусственным интеллектом — потому что нейронные сети построены по образу нейронов в нашем мозге и пытаются эмулировать работу некоторых его частей.
Машинный интеллект гораздо лучше старых методов справляется с задачами, которые могут делать люди: например, распознаванием речи или образов на изображениях. Но как это поможет поиску?
Как правило, низкочастотные и уникальные запросы довольно сложны для поиска – найти хороший ответ по ним заметно труднее. Как это сделать? У нас нет подсказок от пользователей (какой документ лучше, а какой — хуже), поэтому для решения поисковой задачи нужно научиться лучше понимать смысловое соответствие между двумя текстами: запросом и документом.
Легко сказать
Строго говоря, искусственные нейросети – это один из методов машинного обучения. Совсем недавно им была посвящена лекция в рамках Малого ШАДа. Нейронные сети показывают впечатляющие результаты в области анализа естественной информации — звука и образов. Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске?
Простой ответ — потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова. Тем не менее, в поиске смыслов искусственный интеллект действительно стал приходить из той области, где он уже давно король, — поиска по картинкам.
Несколько слов о том, как это работает в поиске по картинкам. Вы берёте изображение и с помощью нейронных сетей преобразуете его в вектор в N-мерном пространстве. Берете запрос (который может быть как в текстовом виде, так и в виде другой картинки) и делаете с ним то же самое. А потом сравниваете эти вектора. Чем ближе они друг к другу, тем больше картинка соответствует запросу.
Ок, если это работает в картинках, почему бы не применить эту же логику в web-поиске?
Дьявол в технологиях
Сформулируем задачу следующим образом. У нас на входе есть запрос пользователя и заголовок страницы. Нужно понять, насколько они соответствует друг другу по смыслу. Для этого необходимо представить текст запроса и текст заголовка в виде таких векторов, скалярное умножение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы хотим обучить нейронную сеть таким образом, чтобы для близких по смыслу текстов она генерировала похожие векторы, а для семантически несвязанных запросов и заголовков вектора должны различаться.
Сложность этой задачи заключается в подборе правильной архитектуры и метода обучения нейронной сети. Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение).
Дальше — о том, что мы пробовали, как добились успеха и как смогли обучить то, что получилось.
DSSM
В 2013 году исследователи из Microsoft Research описали свой подход, который получил название Deep Structured Semantic Model.
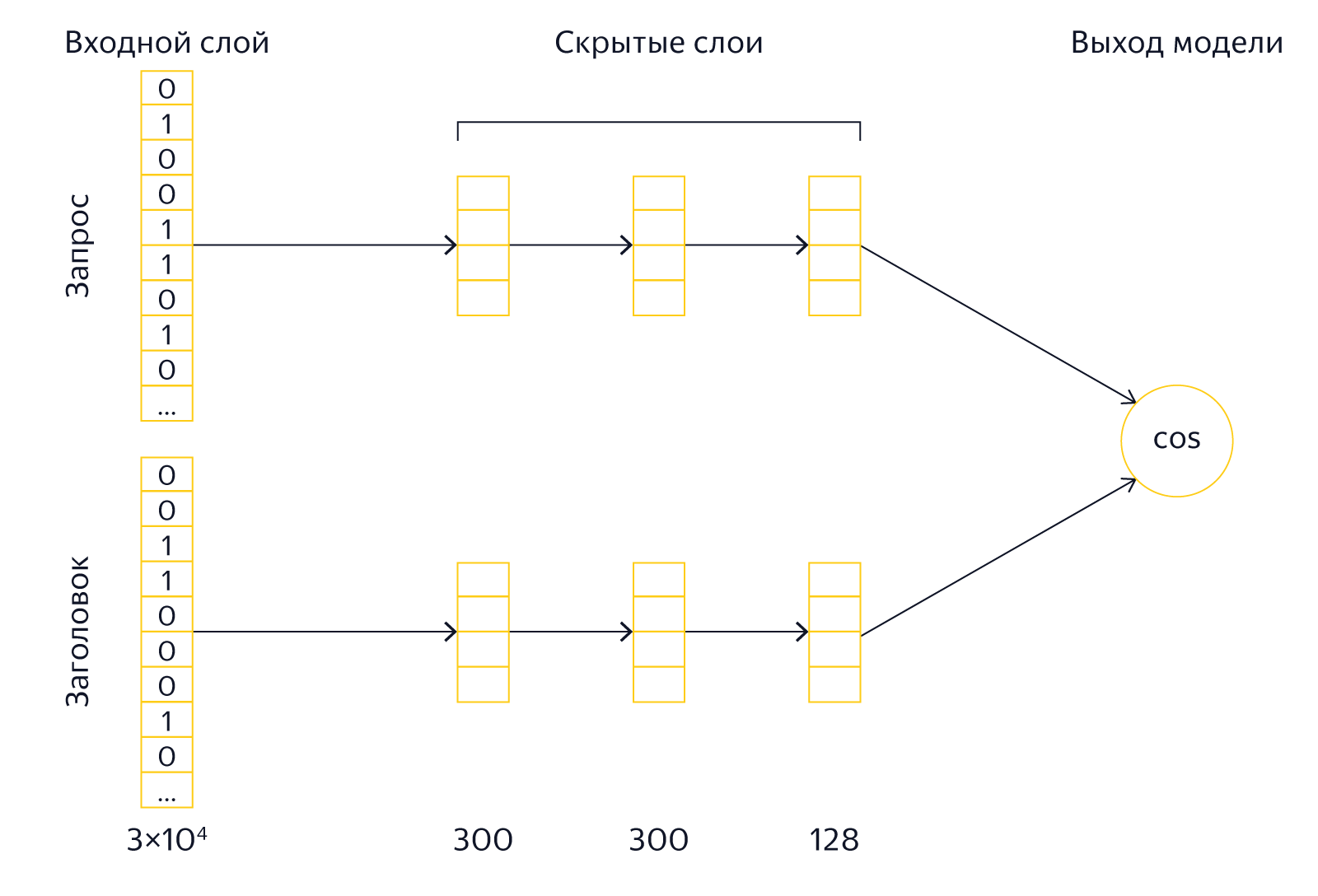
На вход модели подаются тексты запросов и заголовков. Для уменьшения размеров модели, над ними производится операция, которую авторы называют word hashing. К тексту добавляются маркеры начала и конца, после чего он разбивается на буквенные триграммы. Например, для запроса [палех] мы получим триграммы [па, але, лех, ех]. Поскольку количество разных триграмм ограничено, то мы можем представить текст запроса в виде вектора размером в несколько десятков тысяч элементов (размер нашего алфавита в 3 степени). Соответствующие триграммам запроса элементы вектора будут равны 1, остальные — 0. По сути, мы отмечаем таким образом вхождение триграмм из текста в словарь, состоящий из всех известных триграмм. Если сравнить такие вектора, то можно узнать только о наличии одинаковых триграмм в запросе и заголовке, что не представляет особого интереса. Поэтому теперь их надо преобразовать в другие вектора, которые уже будут иметь нужные нам свойства семантической близости.
После входного слоя, как и полагается в глубоких архитектурах, расположено несколько скрытых слоёв как для запроса, так и для заголовка. Последний слой размером в 128 элементов и служит вектором, который используется для сравнения. Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами). Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных — маленьким. Иначе говоря, сравнивая векторы последнего слоя, мы можем вычислить ошибку предсказания и модифицировать модель таким образом, чтобы ошибка уменьшилась.
Мы в Яндексе также активно исследуем модели на основе искусственных нейронных сетей, поэтому заинтересовались моделью DSSM. Дальше мы расскажем о своих экспериментах в этой области.
Теория и практика
Характерное свойство алгоритмов, описываемых в научной литературе, состоит в том, что они не всегда работают «из коробки». Дело в том, что «академический» исследователь и исследователь из индустрии находятся в существенно разных условиях. В качестве отправной точки (baseline), с которой автор научной публикации сравнивает своё решение, должен выступать какой-то общеизвестный алгоритм — так обеспечивается воспроизводимость результатов. Исследователи берут результаты ранее опубликованного подхода, и показывают, как их можно превзойти. Например, авторы оригинального DSSM сравнивают свою модель по метрике NDCG с алгоритмами BM25 и LSA. В случае же с прикладным исследователем, который занимается качеством поиска в реальной поисковой машине, отправной точкой служит не один конкретный алгоритм, а всё ранжирование в целом. Цель разработчика Яндекса состоит не в том, чтобы обогнать BM25, а в том, чтобы добиться улучшения на фоне всего множества ранее внедренных факторов и моделей. Таким образом, baseline для исследователя в Яндексе чрезвычайно высок, и многие алгоритмы, обладающие научной новизной и показывающие хорошие результаты при «академическом» подходе, оказываются бесполезны на практике, поскольку не позволяют реально улучшить качество поиска.
В случае с DSSM мы столкнулись с этой же проблемой. Как это часто бывает, в «боевых» условиях точная реализация модели из статьи показала довольно скромные результаты. Потребовался ряд существенных «доработок напильником», прежде чем мы смогли получить результаты, интересные с практической точки зрения. Здесь мы расскажем об основных модификациях оригинальной модели, которые позволили нам сделать её более мощной.
Большой входной слой
В оригинальной модели DSSM входной слой представляет собой множество буквенных триграмм. Его размер равен 30 000. У подхода на основе триграмм есть несколько преимуществ. Во-первых, их относительно мало, поэтому работа с ними не требует больших ресурсов. Во-вторых, их применение упрощает выявление опечаток и ошибок в словах. Однако, наши эксперименты показали, что представление текстов в виде «мешка» триграмм заметно снижает выразительную силу сети. Поэтому мы радикально увеличили размер входного слоя, включив в него, помимо буквенных триграмм, ещё около 2 миллионов слов и словосочетаний. Таким образом, мы представляем тексты запроса и заголовка в виде совместного «мешка» слов, словесных биграмм и буквенных триграмм.
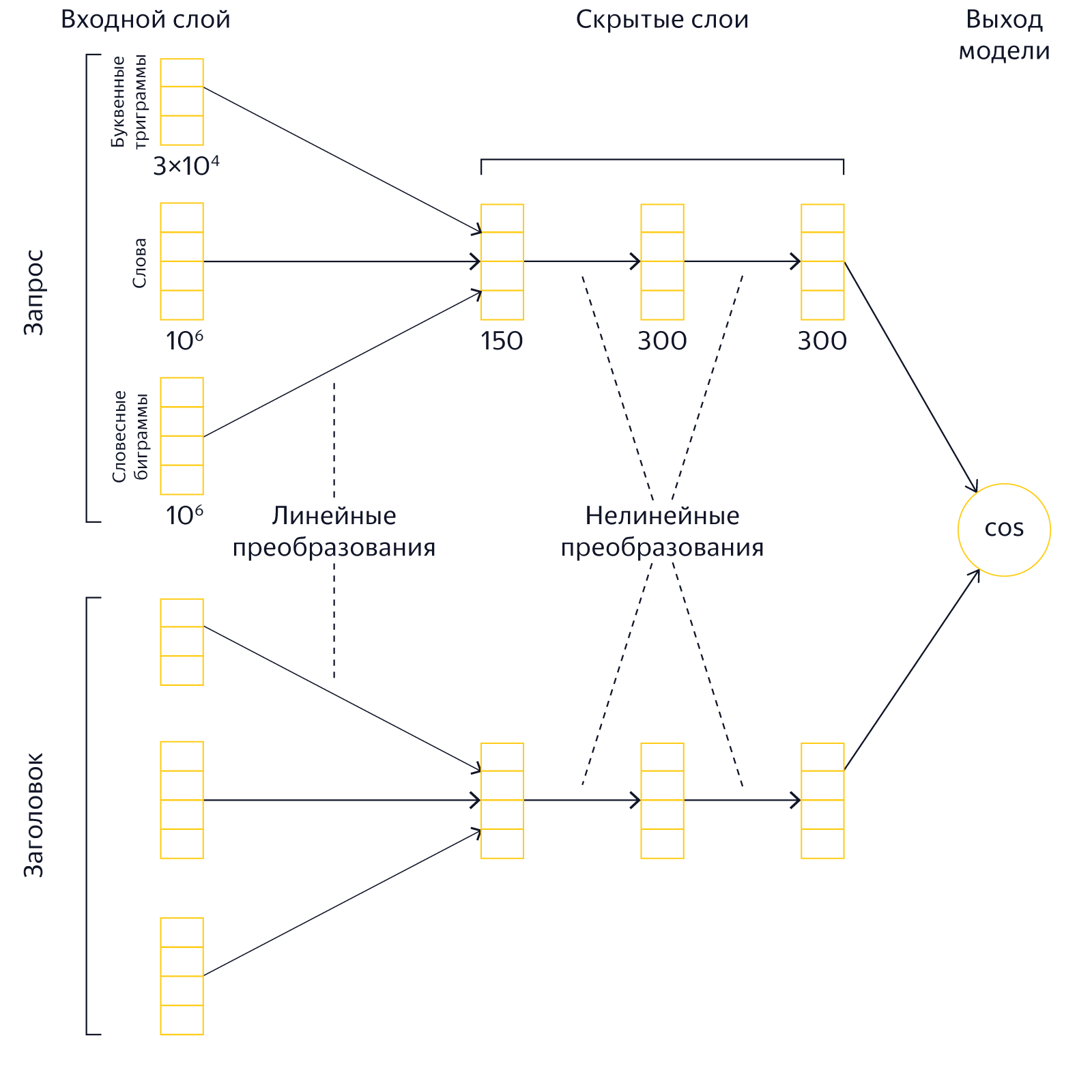
Использование большого входного слоя приводит к увеличению размеров модели, длительности обучения и требует существенно больших вычислительных ресурсов.
Тяжело в обучении: как нейронная сеть боролась сама с собой и научилась на своих ошибках
Обучение исходного DSSM состоит в демонстрации сети большого количества положительных и отрицательных примеров. Эти примеры берутся из поисковой выдачи (судя по всему, для этого использовался поисковик Bing). Положительными примерами служат заголовки кликнутых документов выдачи, отрицательными — заголовки документов, по которым не было клика. У этого подхода есть определённые недостатки. Дело в том, что отсутствие клика далеко не всегда свидетельствует о том, что документ нерелевантен. Справедливо и обратное утверждение — наличие клика не гарантирует релевантности документа. По сути, обучаясь описанным в исходной статье образом, мы стремимся предсказывать аттрактивность заголовков при условии того, что они будут присутствовать в выдаче. Это, конечно, тоже неплохо, но имеет достаточно косвенное отношение к нашей главной цели — научиться понимать семантическую близость.
Во время своих экспериментов мы обнаружили, что результат можно заметно улучшить, если использовать другую стратегию выбора отрицательных примеров. Для достижения нашей цели хорошими отрицательными примерами являются такие документы, которые гарантированно нерелевантны запросу, но при этом помогают нейронной сети лучше понимать смыслы слов. Откуда их взять?
Первая попытка
Сначала в качестве отрицательного примера просто возьмём заголовок случайного документа. Например, для запроса [палехская роспись] случайным заголовком может быть «Правила дорожного движения 2016 РФ». Разумеется, полностью исключить то, что случайно выбранный из миллиардов документ будет релевантен запросу, нельзя, но вероятность этого настолько мала, что ей можно пренебречь. Таким образом мы можем очень легко получать большое количество отрицательных примеров. Казалось бы, теперь мы можем научить нашу сеть именно тому, чему хочется — отличать хорошие документы, которые интересуют пользователей, от документов, не имеющих к запросу никакого отношения. К сожалению, обученная на таких примерах модель оказалась довольно слабой. Нейронная сеть – штука умная, и всегда найдет способ упростить себе работу. В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть — хорошая пара, нет — плохая. Но это мы и сами умеем делать. Для нас важно, чтобы сеть научилась различать неочевидные закономерности.
Ещё одна попытка
Следующий эксперимент состоял в том, чтобы добавлять в заголовки отрицательных примеров слова из запроса. Например, для запроса [палехская роспись] случайный заголовок выглядел как [Правила дорожного движения 2016 РФ роспись]. Нейронной сети пришлось чуть сложнее, но, тем не менее, она довольно быстро научилась хорошо отличать естественные пары от составленных вручную. Стало понятно, что такими методами мы успеха не добьемся.
Успех
Многие очевидные решения становятся очевидны только после их обнаружения. Так получилось и на этот раз: спустя некоторое время обнаружилось, что лучший способ генерации отрицательных примеров — это заставить сеть «воевать» против самой себя, учиться на собственных ошибках. Среди сотен случайных заголовков мы выбирали такой, который текущая нейросеть считала наилучшим. Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки мы стали использовать в качестве отрицательных примеров. Другими словами, можно показать сети лучшие из случайных заголовков, обучить её, найти новые лучшие случайные заголовки, снова показать сети и так далее. Раз за разом повторяя данную процедуру, мы видели, как заметно улучшается качество модели, и всё чаще лучшие из случайных пар становились похожи на настоящие положительные примеры. Проблема была решена.
Подобная схема обучения в научной литературе обычно называется hard negative mining. Также нельзя не отметить, что схожие по идее решения получили широкое распространение в научном сообществе для генерации реалистично выглядящих изображений, подобный класс моделей получил название Generative Adversarial Networks.
Разные цели
В качестве положительных примеров исследователи из Microsoft Research использовались клики по документам. Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу. В конце концов, наша задача состоит не в том, чтобы поднять в поисковой выдаче самые посещаемые сайты, а в том, чтобы найти действительно полезную информацию. Поэтому мы пробовали в качестве цели обучения использовать другие характеристики поведения пользователя. Например, одна из моделей предсказывала, останется ли пользователь на сайте или уйдет. Другая – насколько долго он задержится на сайте. Как оказалось, можно заметно улучшить результаты, если оптимизировать такую целевую метрику, которая свидетельствует о том, что пользователь нашёл то, что ему было нужно.
Профит
Ок, что это нам дает на практике? Давайте сравним поведение нашей нейронной модели и простого текстового фактора, основанного на соответствии слов запроса и текста — BM25. Он пришёл к нам из тех времён, когда ранжирование было простым, и сейчас его удобно использовать за базовый уровень.
В качестве примера возьмем запрос [келлская книга] и посмотрим, какое значение принимают факторы на разных заголовках. Для контроля добавим в список заголовков явно нерелевантный результат.
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0.91 | 0.92 |
| ученые исследуют келлскую книгу вокруг света | 0.88 | 0.85 |
| book of kells wikipedia | 0 | 0.81 |
| ирландские иллюстрированные евангелия vii viii вв | 0 | 0.58 |
| икеа гипермаркеты товаров для дома и офиса ikea |
0 | 0.09 |
Все факторы в Яндексе нормируются в интервал [0;1]. Вполне ожидаемо, что BM25 имеет высокие значения для заголовков, которые содержат слова запроса. И вполне предсказуемо, что этот фактор получает нулевое значение на заголовках, не имеющих общих слов с запросом. Теперь обратите внимание на то, как ведет себя нейронная модель. Она одинаково хорошо распознаёт связь запроса как с русскоязычным заголовком релевантной страницы из Википедии, так и с заголовком статьи на английском языке! Кроме того, кажется, что модель «увидела» связь запроса с заголовком, в котором не упоминается келлская книга, но есть близкое по смыслу словосочетание («ирландские евангелия»). Значение же модели для нерелевантного заголовка существенно ниже.
Теперь давайте посмотрим, как будут себя вести наши факторы, если мы переформулируем запрос, не меняя его смысла: [евангелие из келлса].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| келлская книга википедия | 0 | 0.85 |
| ученые исследуют келлскую книгу вокруг света | 0 | 0.78 |
| book of kells wikipedia | 0 | 0.71 |
| ирландские иллюстрированные евангелия vii viii вв | 0.33 |
0.84 |
| икеа гипермаркеты товаров для дома и офиса ikea | 0 | 0.10 |
Для BM25 переформулировка запроса превратилась в настоящую катастрофу — фактор стал нулевым на релевантных заголовках. А наша модель демонстрирует отличную устойчивость к переформулировке: релевантные заголовки по-прежнему имеют высокое значение фактора, а нерелевантный заголовок — низкое. Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Ещё пример. Запрос [рассказ в котором раздавили бабочку].
| Заголовок страницы | BM25 | Нейронная модель |
|---|---|---|
| фильм в котором раздавили бабочку | 0.79 | 0.82 |
| и грянул гром википедия | 0 | 0.43 |
| брэдбери рэй википедия | 0 | 0.27 |
| машина времени роман википедия | 0 | 0.24 |
| домашнее малиновое варенье рецепт заготовки на зиму | 0 | 0.06 |
Как видим, нейронная модель оказалась способна высоко оценить заголовок с правильным ответом, несмотря на полное отсутствие общих слов с запросом. Более того, хорошо видно, что заголовки, не отвечающие на запрос, но всё же связанные с ним по смыслу, получают достаточно высокое значение фактора. Как будто наша модель «прочитала» рассказ Брэдбери и «знает», что это именно о нём идёт речь в запросе!
А что дальше?
Мы находимся в самом начале большого и очень интересного пути. Судя по всему, нейронные сети имеют отличный потенциал для улучшения ранжирования. Уже понятны основные направления, которые нуждаются в активном развитии.
Например, очевидно, что заголовок содержит неполную информацию о документе, и хорошо бы научиться строить модель по полному тексту (как оказалось, это не совсем тривиальная задача). Далее, можно представить себе модели, имеющие существенно более сложную архитектуру, нежели DSSM — есть основания предполагать, что таким образом мы сможем лучше обрабатывать некоторые конструкции естественных языков. Свою долгосрочную цель мы видим в создании моделей, способных «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека. На пути к этой цели будет много сложностей — тем интереснее будет его пройти. Мы обещаем рассказывать о своей работе в этой области. Cледите за следующими публикациями.
Комментарии (112)

Nashev
02.11.2016 11:32-31Строго говоря, искусственные нейросети – это один из методов машинного обучения.
ЛОЛШТО???


LanMaster
02.11.2016 11:50+11если мы переформулируем запрос, не меняя его смысла
Я так делаю, когда меня не устраивают результаты поиска. Получается, что теперь после переформулировки запроса я буду получать прежние, не устраивающие меня результаты?alsafr
02.11.2016 11:55+5Описанная нейронная модель является всего лишь одним из многих факторов, влияющих на ранжирование в Яндексе. Поэтому после переформулировки запроса результаты будут по-прежнему изменяться. Мы просто стараемся сделать так, чтобы всё находилось с первого раза.
rst256
02.11.2016 17:39+1Вот к примеру ситуация когда пользователь не может найти нужную ему информацию в результатах выданных ему поисковой по некоторому запросу, при это его поведение будет достаточно характерным он будет перебирать предложенные ему ссылки пока не найдет то что искал или не прекратит попытки.
При это ссылки которые были открыты им в рамках данного запроса за исключением последней, как будут расцениваться?
4ebriking
02.11.2016 17:52Самое забавное, что вы описали вообще-то самую распространённую ситуацию — человек ищет пока не найдёт, соотв ВСЁ до последней по-хорошему надо игнорировать.

muxa_ru
02.11.2016 19:20Человек может открыть пяток ссылок сразу, сравнить и найти то что ему нужно по третей ссылке.
rst256
02.11.2016 20:05+1Ну именно по этому я ее и описал, а по хорошему можно еще учитывать те результаты которые пользователь не стал даже открывать. Тут ведь на самом деле имеет место два этапа: сначала мы читаем сопутствующую ссылке информацию: заголовок и фрагмент текста сопровождающий его, назовем это аннотацией, основываясь на содержащейся там информации мы либо пройдем по ссылке либо пропустим ее,
Если мы прошли по ссылке и снова вернулись к поиску, то аннотация была верной, а содержание нет. Содержимое документа есть негативный пример
Если мы не проходим по ссылке, нас не устроила ее аннотация.
Но вот чего я никак не могу понять так это почему нельзя напрямую поинтересоваться мнением пользователя? Сделали бы вверху панельку, с кнопочками "да нашел что искал", "нет не нашел", и еще две "найти далее" и "найти предыдущее"…
Я бы наверное уже только за возможность сразу перейти к заинтересовавшему меня в аннотации фрагменту документа с гугла перешел бы на Яндекса.simpam
03.11.2016 10:50+1
Или как вариант для залогиненных пользователей напротив каждой выданной ссылки выводить лайк/дислайк.
wadeg
02.11.2016 23:19Но ведь в яндексе всегда было так. Поэтому и пользоваться им нельзя было от сотворения, если ваши запросы сложнее, чем «вконтакте».
4ebriking
02.11.2016 11:50+31Дорогой Яндекс.
Верни, пожалуйста возможность принудительного поиска по словам (кавычки не спасают) с принудительным же в запросе (какой нибудь опцией) отключением всякой морфологии и «смысла».
И желательно — без бесконечной капчи (ищешь текст по слову, находит допустим киношку с тем же названием — добавляешь в запрос "-кино" "-фильм" "-посмотреть" — вываливается капча. Робот Яндекса посчитал меня роботом и хочет в том удостовериться.
Примеров у меня много, но вот под рукой сходу нету, т.п. отвечает в стиле «мы ищем по статистике, если все ищут кино, значит правильно искать кино»
bolk
02.11.2016 17:01+3Поддерживаю на 100%. У меня много запросов по которым «Яндекс» выдаёт чепуху, приходится тратить время и лазить по ссылкам только для того, чтобы убедиться, что заданных слов на страниц нет. «Гугл», если выкидывает слова, прямо об этом сообщает — по снипетами выкинутые слова будут зачёркнуты.

Femistoklov
03.11.2016 09:02-1«Миллионы пользователей не могут ошибаться»?
На самом деле, я тоже не понимаю, как нейросеть Яндекса может превзойти мою собственную в действительно сложных случаях. Лишь мешает планировать запрос. А все эти сказки, где монарх ходил без одежды оставьте для твиттера или ЕГЭ по литературе.abcdn
03.11.2016 21:16+1По запросу «сказки, где монарх ходил без одежды» в топ 10 сейчас эта самая статья на Хабре. Рекурсия, однако!:)

ServPonomarev
02.11.2016 12:00+3Так всё-же, выход нейронной сети — это один из факторов, скармливаемых Матрикснету, или вы как-то смешиваете выдачу матрикснета и нейронной сети в выдаче?
Судя по описанию, технология находится на уровне proof of concept, поскольку вязать текст запроса только на заголовок страницы — это шаг назад лет на 20-30. Неужели в прод пустили?alsafr
02.11.2016 12:04+1Совершенно верно, выход нейронной сети используется как один из множества факторов.
ServPonomarev
02.11.2016 12:22Хорошо. Советую посмотреть в сторону кластеров токенов, получаемых одним из методов дистрибутивной семантики (Word2Vec, Glove). У меня прекрасно разделяет даже близкие «по смыслу» тексты на всего-лишь 2048 кластерах. Тогда любой текст представляется в виде вектора фиксированного размера, и на нём уже учиться как душе угодно. Что-бы не бить по площадям миллионами биграмм.

alex4321
02.11.2016 15:57Речь ведь о опубликованном методе с кластеризацией векторных представлений слов?
Не отказался бы от набора векторов, если не затруднит.
bolk
02.11.2016 16:58Word2Vec упоминается в статье как пример неудачного опыта.
ServPonomarev
03.11.2016 09:02Просто надо двигаться дальше. Word2Vec — хорош для токенов, но плох для текстов. А вот если кластеризовать токены Word2Vec, а потом для каждого токены вычислить дистанцию до центра кластеров — получится новый вектор. И такие вектора уже весьма хороши для текстов.
elingur
03.11.2016 12:07вычислить дистанцию до центра кластеров
w2v не выдает веса по кластерам. Значит, центры кластеров можно получить, как я понимаю, только один путем: по порядковому номеру слова в кластере. Не очень понятно, что это дает — центры будут у всех где-то в центре словаря. Идея же в другом: понизить ранг низко информационных кластеров (типа частотных слов) и поднять у семантически наполненных.
Хотя ваша идея сравнивать «семантическую» сигнатуру документов очень правильная.

DiSha
02.11.2016 12:01Любопытно, а можно ли обучить другой ИИ анализировать выдачу Яндекса, чтобы формировать страницы которые будут высоко ранжироваться ИИ «Палех»?
ServPonomarev
02.11.2016 12:18Не можно, нужно. Получается классический автоэнкодер, только одна его часть — это ранжёр Яндекса, а другая — ранжёр SMM'щиков. Но на практике не работает, из-за слишком больших затрат на подготовку обучающих примеров (1 пример — 1 запрос).
DiSha
02.11.2016 12:33Рынок СЕО тоже большой, это вопрос времени. Хотя, с другой стороны, в примерах в основном низкочастотные запросы и с длинными хвостами, а не «ХХХХХ купить недорого» каждого второго интернет-магазина.

Eldhenn
02.11.2016 12:29+2Очень показательна последняя таблица. В ответ на вопрос мы получаем… ссылку на похожий вопрос в другом месте. Хорошо, если это stackoverflow. А если это Вопросы@Mail.ru? Или того хуже — «помогите найти рассказ в котором раздавили бабочку» с «кликнул по ссылке, ввёл код с телефона, всё в порядке!».
rikert
02.11.2016 12:29-9Не уверен, что Яндекс это та компания которая может похвалиться качеством поиска, в 90% случаев он не дотягивает даже до хорошего.
tundrawolf_kiba
02.11.2016 12:58+1При словах "поиск по смыслу" на ум приходит Compreno от ABBYY, есть какие-то планы по добавлению его в свои алгоритмы?

Aingis
02.11.2016 13:03+2Те же ABBYY говорили что он жутко затратный и медленный. Вряд ли он подходит для реалтайм поиска среди огромного массива интернет-документов.
ServPonomarev
02.11.2016 14:06+1Это смотря как использовать.
Например:
Выделяем наиболее типичные запросы, выделяем факты, соответствующие этим запросам. В итоге получаем большое число синтаксических конструкций, описывающих целевые факты. Загоняем эти конструкции в конечный автомат и имеем быструю штуку, выделяющую значительную часть интересных нам фактов корректно.
Мощная и медленная Compreno используется только при подготовке обучающей выборки, не в проде.
elingur
03.11.2016 15:44+1Скорость Compreno ~ одно предложение в секунду, ежедневный только русскоязычный поток порядка тысячи предложений в секунду. Поэтому Compreno живет на небольших статических коллекциях документов.
dvr-pro
02.11.2016 13:10+4Уже много десятилетий исследователи бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. И теперь это становится реальностью.
Ещё столько же будут биться. Контекст продаётся и все довольны.
muxa_ru
02.11.2016 13:43-4Большое вам спасибо за вам труд, но пожалуйста, можно я сам буду решать какой именно смысл я вкладываю в поисковый запрос?


lonlylocly
02.11.2016 14:36Спасибо за статью!
Скажите пожалуйста, есть ли у вас уже научные публикации по этой теме?
Могли бы вы предоставить ссылки на них?
Интересно почитать подробнее.

ddPechkin
02.11.2016 14:39Спасибо за статью!
Кстати, было бы весьма интересно узнать каким именно поисковиком в работе пользуются хабровчане. Я, по старой привычке, использую Google — ибо когда-то поселил в голове мысль, что для поиска технических вопросов он подходит лучше (лет пять назад даже проверял — мысль подтвердилась).Rusheff
02.11.2016 18:54Не использую гугль просто из чувства противоречия. Сравнивал по русскоязычным запросам — примерно одна фигня. На английском гугль ищет однозначно лучше. Но я лично редко делаю такие запросы. Но вопрос с кавычками в яндексе очень донимает (в смысле дословного поиска). Плз, верните взад.
ddPechkin
02.11.2016 19:26+1Вот весьма вероятно, что моя приязнь к Гуглу относится к привычке формулировать запрос на техническую тематику на английском языке (стойкое осознание, что в англоязычном сегменте интернета я скорее найду ответ). К примеру даже физически быстрее вбить запрос «firefox selinux policy template», чем «шаблон политики selinux для firefox» (переключение раскладки, опять же). А запрос типа «IPv4 security options» я на русском даже сформулировать на бегу не могу.
Отсюда и интерес к тому, какой поисковик среди хабровчан популярнее.Rusheff
02.11.2016 21:49-1Думаю, что большинство из молодежи перетекло к гуглю из мобилок, а большинство прогеров из необходимости поиска на английском. Русскоязычных инженеров все меньше. Яндекс популярен среди инженеров закрытых/полузакрытых контор. Там часто гугль просто забанен.
jfhs
02.11.2016 14:40+1А как это работает в поиске? Вы вычисляете скалярное произведение выхода сети для запроса со всеми документами? Если так, то насколько быстро это работает, ведь документов очень много.
alsafr
02.11.2016 15:02Закономерный вопрос. Наше ранжирование состоит из нескольких последовательных стадий, различных по количеству обрабатываемых документов и сложности применяемых на них алгоритмов. Сначала работает очень быстрое ранжирование, которое находит, например, сотни тысяч документов. Затем мы используем более умное и медленное ранжирование и оставляем десятки тысяч документов и так далее. Таким образом, самые тяжелые алгоритмы применяются не ко всем документам вэба, а к некоторому большому, но всё же ограниченному топу наиболее перспективных документов.
jfhs
02.11.2016 15:14+1Спасибо за ответ. Но в таком случае, эта первичная фильтрация должна быть или очень мягкой, или знать что «и грянет гром википедиа» подходит под запрос «рассказ в котором раздавили бабочку» (а тут даже совпадающих слов нет), иначе до вашего алгоритма документ не дойдет. Если не секрет, то сколько документов в среднем доходит до описаного в статье алгоритма?
ServPonomarev
02.11.2016 15:34Поиск по словам в тексте документа — на самом деле меньшая часть поиска. Сильно играют тексты, содержащие ссылки на данный документ, метрики поведения пользователей (клики и переходы).
Так что, документ, не содержащий вообще ни одного слова из запроса вс равно найдётся, если на него ссылаются с заданными словами.
alsafr
02.11.2016 15:34Ключ к высокому качеству поиска находится на поздних стадиях ранжирования. Возможно, это не совсем очевидно, но наш опыт говорит о том, что сделать фильтрацию, которая будет находить хороший топ-10000 документов, заметно проще, чем правильно отранжировать документы в этом топе. Сейчас модель применяется к нескольким сотням лучших документов. Вероятно, в обозримом будущем это число существенно увеличится.
iPumbaza
02.11.2016 15:40Почему интеллектуальные системы называют искусственным интеллектом?

yorko
02.11.2016 16:04Интересно, почему нейронные сети отождествляют с искусственным интеллектом.
Уверен, товарищи из Яндекса не из тех, кто подвергся хайпу, взялся сразу за DL и ничего не слышал о логических и символьных методах, представлении знаний и экспертных системах — о всем том, в чем нейросети только пытаются догонять.
el777
03.11.2016 11:59Интересно, почему нейронные сети отождествляют с искусственным интеллектом.
Думаю, из-за того, что в основе лежит упрощенный принцип работы нейронов, на который работает и наш «естественный» интеллект.



npocmu
02.11.2016 16:08-7Пишите красиво… Захотелось даже попробовать поискать Яндексом (обычно ищу Гуглом).
И что же выдал ваш искусственный интеллект на заведомо бредовый запрос?
купить коллайдер витебск
Ссылку на aliexpess где предлагают купить адронный коллайдер для дома, недорого!
Т.е топом выдана типовая подманка от SEOшников. У которых на запрос любого товара в любом городе заготовлено тысячи бесполезных ссылок.
Грош цена такому поиску!
CEPBAHTEC
02.11.2016 17:37Конечно, то ли дело поиск от Корпорации добра
iPumbaza
02.11.2016 17:54+1Все вы на буржуазные системы смотрите. Вот, поинтересуйтесь-ка! Выдача со Спутника.
rst256
03.11.2016 02:53Это почти идеал, ищет точно то что ему говорят, работает исключение из поиска "-"
жаль вот только кавычки не работают.
Несколько не хочу принизить возможности других поисковых систем, серебряной пули ведь как известно не существует…azsx
03.11.2016 05:35iPumbaza кстати спасибо, очень верно напомнили, что есть Спутник. Ему бы базы побольше и en результаты подмешивать. ps а я не выдержал свой парсер написал, ищу по локальной базе.
Также придерживаюсь мнения, что внедрение нового компьютерного алгоритма никак не повлияет на релевантность выдачи по информационным запросам. Причины в другом, не в поведенческих факторах, которые хотят анализировать «нейросетью».
Тем не менее спасибо за статью, очень интересно.4ebriking
03.11.2016 13:40а я не выдержал свой парсер написал, ищу по локальной базе.
По локальной базе интернета? Вау!springimport
03.11.2016 19:14Представил комнату из жестких дисков и пару десятков серверов с ожиданием ответа от 10 минут.
azsx
04.11.2016 18:47И ошиблись. Я парсил только главные, не более 15 миллионов, масштабы у меня не те и ответы ждал чаще часами. Но и запросы у меня не как для ПС.
На самом деле, ага, финансово не тяну проект. Совсем.4ebriking
07.11.2016 20:01Но попытка! Достойная уважения.
Снимаю шляпу, я думал это огворока или для красного словца, даже неловко перед самим собой, что нехорошо про Вас подумал.
npocmu
03.11.2016 09:17Идеал должен в данном конкретном случае выдать: «По вашему запросу ничего не найдено». Увы и ах — где найти тот идеал…
Danco
02.11.2016 18:53В моем залогиненном гугле ссылок на Али нет, он вообще исключил из запроса слово «коллайдер»
iPumbaza
03.11.2016 11:47-1Вот Гоша, кстати, уже проиндексировал эти комментарии и данная статья выходит в первую десятку выдачи на запрос «купить коллайдер витебск». На Яше — 3 страницы все тех же SEO ссылок, дальше не искал.


bethrezen
02.11.2016 16:10+3Всё круто, результаты интересные. Но как эта модель обрабатывает омонимию?
ServPonomarev
03.11.2016 09:06+1Поскольку она построена на биграммах, то таковые шансы у неё есть.
bethrezen
03.11.2016 09:48Шансы на что? На ошибку?
Либо я что-то упустил в статье, либо получается, что связь с другими словами запроса через триграммы будет крайне маленькой и малоинформативной в плане омонимии. На мой взгляд это принесёт дополнительный шум. Поправьте, если я не прав.
Также не ясно, как обрабатываются спам-документы?
Ну и если я правильно понял, что алгоритм работает только по заголовкам документа:
- Если мы анализируем только TITLE — что делать с сайтами, где идёт глупая генерация этих заголовков и они на половину состоят из например названия сайта?
- Насколько в принципе эффективно работать именно с заголовками, учитывая, что количество уникальных и заполненных заголовков в принципе существенно мало по сравнению с общим количеством документов в интернете?
VioletGiraffe
02.11.2016 16:35+2Парадокс: «Один из лучших алгоритмов машинного обучения изобрели в Яндексе», а Гугл ищет лучше.



ternaus
03.11.2016 06:14Вопрос который толком и не связан с постом, но предполагает, что тут все эксперты по нейронным сетям:
Кто мне подскажет какая архитектура сети хорошо поведет себя под эту задачу: Allstate Claims Severity ?
Анонимизированные данные, сколько-то численных, сколько-то категорийных. Задача предсказать на какую сумму предъявят страховой компании. Метрика: mean absolute error
Что-то я валандаюсь, но ничего толком не поулчается. При cross validation предсказания очень нестабильные.
Что делать? Как быть? Какая литература поможет мне разобраться какую сеть выбрать под эти данные и эту метрику?

nivorbud
03.11.2016 07:26Я интереса ради тоже переформулировал переформулированный запрос:
>>> рассказ в котором раздавили бабочку
на
>>> рассказ в котором раздавили насекомое
Яндекс не справился совсем, А Гугл справился хорошо.
С запросом:
>>> рассказ в котором раздавили живое существо с крылышками
Гугл также частично справился.
А вообще мне не очень нравится эта затея с поиском «по смыслу» (именно в кавычках). Я чаще пользуюсь Гуглом и как он перешел на свой новый аналогичный алгоритм, я стал испытывать проблемы: на мои точные запросы технического характера (например, с ошибкой из логфайла), где каждое слово и даже словоформа имеет значение, я стал получать в выдаче совсем не то, что мне надо.
Также мне не очень нравится то, что такие алгоритмы дают много ложноположительных результатов, что видно и по примерам в статье: совершенно нерелевантные документы про варенье и Икею имеют относительно большой вес и могут легко оказаться в выдаче, а найти порог отсечения весьма не просто. А такие документы (совершенно не в тему) режут глаз, когда их видишь в выдаче.
Также не понятно, как поведет себя нейронная сеть, если на её вход подать материал с совершенно новым смыслом, которого система не знает и которому не обучена.
Ну, и насколько мне известно, нейронные сети отличаются тем недостатком, что являются черным ящиком, т.е. тяжело понять, почему нейронная сеть приняла именно то или иное решение.Nashev
03.11.2016 22:43Пора делать ещё один Гугл, видимо… (
Без этих умностей
Theo_from_Sed
04.11.2016 23:59+1Возможно duckduckgo.com вам подойдёт.

spitty
07.11.2016 16:47Кхм…
Поиск по русскоязычноу запросу ddg.gg выполняет через API Яндекса.
https://duck.co/help/results/sources
In fact, DuckDuckGo gets its results from over four hundred sources. These include hundreds of vertical sources delivering niche Instant Answers, DuckDuckBot (our crawler) and crowd-sourced sites (like Wikipedia, stored in our answer indexes). We also of course have more traditional links in the search results, which we source from Bing, Yahoo, and Yandex.
s1ngleton
03.11.2016 07:26Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение)
Не могли бы вы подробнее рассказать об этом? Можете ли вы привести примеры, где word2vec имеет гораздо лучшие альтернативы? Что это за задачи?
iPumbaza
03.11.2016 12:05Меня в школе учили, что смысл передается предложениями, а в поисковом запросе юзеры по-дефолту из предложения опускают знаки препинания, заглавные буквы, части слов и целые слова. В таких условиях понять смысл еще тяжелее.
alsafr
10.11.2016 13:43На этот счет есть интересная лекция моего коллеги: Андрей Плахов. Язык поисковых запросов как естественный язык.
Если коротко, то язык поисковых запросов (или человеко-машинный пиджин), конечно, отличается от литературного языка, но, судя по всему, его выразительных средств достаточно для решения поисковых задач пользователя.

saterenko
03.11.2016 12:35Объясните пожалуйста, почему для запроса «евангелие из келлса» ВМ25 для заголовков «келлская книга википедия» и «ученые исследуют келлскую книгу вокруг света» выдал 0? У него не получилось просклонять «келлс»?
Я правильно понимаю, что модель строилась не только по заголовкам, но и по тексту. Если только по заголовкам, то как нейронная сеть смогла дать для запроса «келлская книга» высокий рейтинг для заголовка «ирландские иллюстрированные евангелия vii viii вв», т.е. установить связь между «келлская книга» и «ирландское евангелие»?s1ngleton
03.11.2016 13:08Не обязательно анализировать текст для того чтобы идентифицировать связь между этими двумя фразами. Для этого достаточно располагать соответствующими представлениями слов. Созданием подобного рода представлений как раз и занимается глубокое обучение (deep learning). Собственно, это является одной из главных особенностей глубоких нейронных сетей — это продукт их работы (посмотрите на word2vec и text2vec). В случае с «Палех», полагаю, происходит нечто подобное.
saterenko
03.11.2016 13:50Я имею приблизительное представление о том, как работают нейронные сети и, на сколько я понимаю, в обучающей выборке должны были как-то сопоставляться «келлская книга» с «ирландское евангелие», т.е. они либо должны были быть в одном заголовке, либо в обучающей выборке должно было быть указано, что эти понятия связаны. Вопрос в том, откуда это сопоставление взялось.
Если сопоставление взялось из текста, тогда мне кажется некорректным сравнение с ВМ25, который искал только по заголовкам.
nivorbud
03.11.2016 16:59+1т.е. установить связь между «келлская книга» и «ирландское евангелие»?
Возможно, эта смысловая связь возникла из заголовков обучающей выборки, в которых эти фразы встречались вместе. Ведь в тайтлах часто пишут сразу несколько синонимичных вариантов одного и того же понятия, вот оттуда и могла эта связь возникнуть. Например, множество заголовков должно выглядеть примерно так:
>>> «Что такое келлская книга (ирландское евангелие)»
alsafr
10.11.2016 14:09В случае с «келлс» и «келлский» речь идет не о словоизменении, а о словообразовании, то есть с определенной точки зрения это — разные слова. В статье для наглядности использовался вариант BM25, который именно так и считает. Но о том, что слова «келлс» и «келлский» как-то связаны, большой поиск Яндекса, конечно, знает и без DSSM.
binque
03.11.2016 21:17Очень интересная мне тема, спасибо за статью. Остался один вопрос, если он глупый, не пинайте сильно. Статью про DSSM просмотрел, ответа там тоже не увидел. Как я понял, если в запросе встретилась определенная триграмма (или слово, словосочетание), то на соответствующий ей вход сети подается единица. Для тех триграмм, которых в запросе нет, на входы подаются нули. А если триграмма встречается в запросе несколько раз, это как-то учитывается? Или это неважно, главное, что она есть?
alsafr
03.11.2016 21:19В оригинальном DSSM частотность триграмм не учитывается, используются только 0 и 1.
lokiSEO
03.11.2016 21:17Какое максимальное кол-во символом из заголовка сайта, возьмутся для анализа, весь заголовок?
nivorbud
03.11.2016 23:20В общем, если я правильно понял, то данная нейронная сеть является ни чем иным как самообучающимся словарем синонимов. С тем отличием, что синонимами являются не слова, а мешки слов и не с жесткими связями между синонимичными мешками, а вероятностными. И думаю, что его можно использовать так, чтобы для поданной на вход фразы получать на выходе список наиболее синонимичных фраз. Таким образом данный алгоритм можно было бы использовать просто как дополнение к уже работающим алгоритмам ранжирования (т.е. не трогая их) — просто расширяя фразу запроса синонимичными фразами. Вроде как-то так новый алгоритм Гугла (брэйн ранк) и работает (могу ошибаться, детально не изучал).
abcdn
03.11.2016 23:28Мне нравится идея, в особенности тем, что если её удастся развить и удачно применять, то это позволит существенно снизить значимость перенасыщенных ключевыми словами текстов. А это до сих пор является общим принципом работы большинства оптимизаторов. В результате мы можем получить не только более качественный поиск, но и — что важнее — более качественный Интернет, где люди перестанут, наконец, писать бессодержательные тексты с одной лишь целью — добиться вхождения ключевых слов в продвигаемую страницу.
Мне кажется, это шаг в нужном направлении.
Dokondr
04.11.2016 09:02В статье читаем: “Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами). Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных — маленьким.”
Не совсем понятно, как обучается модель. Если я не ошибаюсь, здесь речь идет о сравнении векторов методом Cosine similarity (https://en.wikipedia.org/wiki/Cosine_similarity). Чем меньше угол между двумя векторами и соответственно косинус этого угла ближе к 1, тем более похожими считаются вектора. А косинус угла тем ближе к 1, чем больше значений компонент совпадают в этих векторах.
В обучающей выборке очень даже могут быть такие два примера:
1)
PNeg1 — негативный пример, заголовок по смыслу не соответствует запросу.
Q1 — вектор первого запроса.
H1 — вектор заголовка с которым сравнивается первый запрос.
C1 = 0.9 — косинус угла между Q1 и H1, т.е
вектора сильно похожи.
2)
PPos2 — позитивный пример, заголовок и запрос хорошо похожи по смыслу.
Q2 — вектор второго запроса.
H2 — вектор заголовка с которым сравнивается второй запрос.
C2 = 0.1 — косинус угла между Q2 и H2, т.е
вектора очень мало похожи.
Поскольку вектора запроса и заголовка строятся из триграмм и комбинаций слов без учета их семантики, вполне возможна ситуация, при которой многие компоненты двух векторов совпадут, в то время как по смыслу никакого совпадения между запросом и заголовком нет. И наоборот. Например:
Q: “В какой статье пишут о том как наши атлеты вырываются вперед?”
H: “Наши вырываются вперед!” — заголовок статьи о получении букеровской премии нашего автора.
В момент написания этого текста, Яндекс, в ответ на данный запрос, выдает:
“Эксперт: эффект разорвавшейся бомбы, или о том, как Трамп вырвался вперед”
А Google:
“Болеем в Рио за спортсменов от Краснодарского края”
Правда, интересно получается?
Поскольку любые два вектора характеризуются одним и только одним косинусом угла между ними, то изменить этот косинус (меру похожести), можно только меняя сами вектора.
Если я не ошибаюсь, то в алгоритме Палех это выглядит примерно так:
1) Bq — мешок триграмм и слов построенных из запроса.
Строим всевозможные вектора Vq заданной длинны N комбинируя элементы из мешка Bq.
2) Bh — мешок триграмм и слов построенных из заголовка.
Строим всевозможные вектора Vh заданной длинны N комбинируя элементы из мешка Bh.
Затем строим всевозможные пары векторов (vq, vh), беря по одному вектору из каждого набора Vq, Vh.
Обучая нейронную сеть, для положительных примеров выбираем пару с максимальным косинусом угла между векторами входящими в пару, а для отрицательных примеров — с минимальным.
Так получается? Поправьте, пожалуйста, если где ошибся.nivorbud
04.11.2016 13:53C1 = 0.9 — косинус угла между Q1 и H1, т.е
вектора сильно похожи.
Теоретически слова (лучше сказать «токены»), входящие в оставшиеся 0.1, должны при обучении на большой и разнообразной выборке в итоге резко понижать вес таких связей. Но на практике скорей всего получится именно то, о чем вы пишете далее:
Q: “В какой статье пишут о том как наши атлеты вырываются вперед?”
H: “Наши вырываются вперед!” — заголовок статьи о получении букеровской премии нашего автора.
В момент написания этого текста, Яндекс, в ответ на данный запрос, выдает:
“Эксперт: эффект разорвавшейся бомбы, или о том, как Трамп вырвался вперед”
А Google:
“Болеем в Рио за спортсменов от Краснодарского края”
Правда, интересно получается?
Я экспериментировал с подобными вещами (поиск по смыслам), правда в тепличных условиях — на узкотематическом корпусе текстов относительно скромных размеров. Результаты получались в целом интересные, но неоднозначные. Интересно конечно видеть, как на запрос выдаются в целом релевантные документы, не содержащие ни одного слова из запроса, но с другой стороны неоднократно ловил себя на той мысли, что с практической точки зрения в большинстве случаев мне были бы более полезны результаты классического поиска — по словам.
Тем более, что сейчас все научились составлять запросы кратко и по существу, т.е. пользователь самой формулировкой запроса может управлять поиском, а в случае поиска по смыслам эта возможность утрачивается.
И я также столкнулся с проблемой, о которой вы указали в своем примере, — в выдачу попадают совсем левые документы, пусть и не на первых местах, но всё же это коробит и подвергает сомнениям адекватность всей выдачи.
И в примерах автора статьи можно заметить, что совершенно левые ответы (про Икею и варенье) имеют значительный вес — они хоть и не попадут в ТОП5, но могут оказаться в ТОП20, что не хорошо.
В общем я такой алгоритм как основной для ранжирования не брал бы — слишком всё сыро. А вот для разнообразия выдачи, как дополнение к основному классическому алгоритму, можно было бы и взять.
QuantCat
04.11.2016 22:17+1Хмм, многие жалуются, что теперь с новым «поиском по смыслу» запросами стало управлять труднее. Одновременно подобное выглядит полезным — например, искать рассказ по основам сюжета. Да, как уже заметили выше, меньший вес станут иметь многочисленные оптимизации поиска в духе «купить недорого без смс».
Мне кажется, в идеале должна быть галочка — искать напрямую или с коррекцией запросов нейросетью.

Cybersoph
08.11.2016 23:55-2Конечно же, никакого поиска по смыслу Яндекс не делает, поскольку в Яндексе не умеют извлекать смысл из естественно-язычного текста (ЕЯТ).
Нейросеть, умеющая находить закономерности в потоке или в матрице, по определению не способна на смыловую обработку ЕЯТ.
В принципе, все эти Компрено и Палехи — есть суть семантические сети Ёлкина С.В., разработанные ещё 20 лет назад.
Автор путает термин «семантический» с понятием «смысловой».

qmax
10.11.2016 01:50А в чём именно неудачность word2vec?
Или это просто «по факту» — попробовали и не взлетело?alsafr
10.11.2016 13:18Сам по себе word2vec — штука довольно интересная. Просто он плохо проявил себя в нашей конкретной задаче по улучшению поиска. Мое объяснение состоит в том, что обучение «классического» word2vec происходит без привлечения информации о поведении пользователей. В отличие от word2vec, целевая функция при обучении DSSM непосредственно связана с задачей ранжирования.
qmax
11.11.2016 02:49+1Я предполагаю, что его можно использовать чисто как feature extraction на самом входном слое.
Там, где у вас биграммы/слова/триграммы.
Наверно, можно даже сами буквотриграммы раскрасить по ембеддингу исходных слов (но с неоднозначностью).
Michael134096
Для сравнения, если вбить в google «рассказ в котором раздавили бабочку», то первым результатом тоже будет ссылка на статью в википедии «И грянул гром». Аналогично и с келлской книгой.
Ogi
Попробовал поэкспериментировать.
Гугл: первая же ссылка — «Большой толстый лжец» в Википедии.
Яндекс: мусор.
Гугл: первая же ссылка — «Майор Пэйн» в Википедии.
Яндекс: мусор.
Гугл: мусор.
Яндекс: вторая ссылка — «Схватка» на Кинопоиске.
Гугл: в основном мусор, но третья ссылка — упоминание «Маятника Фуко», не поверите, на Пикабу.
Яндекс: мусор.
el777
[offtop]Да, гугл уже использует нейросети для ранжирования. Поэтому очень интересно почитать практический опыт Яндекса по внедрению данной технологии. Какие возникают проблемы, какие открываются возможности. [/offtop]
Sergey_Kovalenko
Очень интересует способ реализации схемы смыслового поиска, даже в предположении, что яндекс располагает идеальным алгоритмом анализа смысла. С обратным индексом поиска по словам все было просто: по каждому слову собираете адреса документов, в которых оно упоминалось, затем пытаетесь найти документы, в которых больше всего значимых слов из запроса.
Внимание! Как составить идекс смыслов? Я хочу указать на одну принципиальную трудность: конечная конструктивная вещь может иметь бесконечно много нетривиальных свойств, например, сколько интересных свойств двойки вам известно? Представим нелепую упрощенную ситуацию: каждый документы в мире — запись некоторого натурального числа, мой запрос — некоторое хорошее в том смысле свойство натуральных чисел, что по любому конкретному числу можно понять, удовлетворяет оно этому свойству или нет. Каким образом будет обрабатываться мой запрос?
Я хочу сказать, что один и тот же текст при смысловом анализе может отвечать на множество вопросов, предвидеть же заранее все из них может оказаться бесконечно сложной задачей, чуть более сложной, чем анализировать каждый документ на соответствие каждому запросу.
Часто говорят, а давайте сделаем ракету и полетим на Луну, в этом случае стоит спросить: «Предположим, вы сделали ракету и долетели до Луны, что дальше?»