
Тестирование, несомненно, является одним из китов, на которых стоит разработка приложений. Как и любой характерный кит, тестирование может зафонтанировать багами и долго не останавливаться. Но главный вопрос заключается в достаточности тестового покрытия – все ли баги по написанным тест-кейсам удастся отловить? Возможно, некоторые появятся только под пользовательской нагрузкой. Для выявления оных, как правило, детонирует обращение пользователя и далее задействуется следующая цепная реакция: специалист Help Desk, вторая линия поддержки и, если повезет, сообщение о нештатной работе попадет в руки разработчика. Да, инцидент может также прийти от системы APM-мониторинга (если она у вас есть, конечно). Но все эти вещи не позволят однозначно определить, какие значения принимали переменные до возникновения исключения. В посте мы как раз поговорим о решении, призванном в помогать в подобных ситуациях.
Устраивайтесь поудобнее. Поговорим об OverOps – решении для обнаружения ошибок в работе приложений на Java, Scala, Clojure и Groovy. Покажу несколько скриншотов и расскажу об основных фичах продукта. Во вступительной части не случайно шла речь о тестировании. Ошибки. возникающие в продуктивной среде совсем не обязательно появятся в среде разработки и тестирования. А нагрузка реальной пользовательской активностью может выдать доселе невиданные исключения.
Суть работы OverOps в следующем:
1) при старте JVM рядом с ней запускается агент OverOps;
2) агент умеет мониторить возникновение в коде исключений (как обрабатываемых, так и не обрабатываемых);
3) агент в момент возникновения исключения снимает heapdump и накладывает его на декомпилированный байткод.
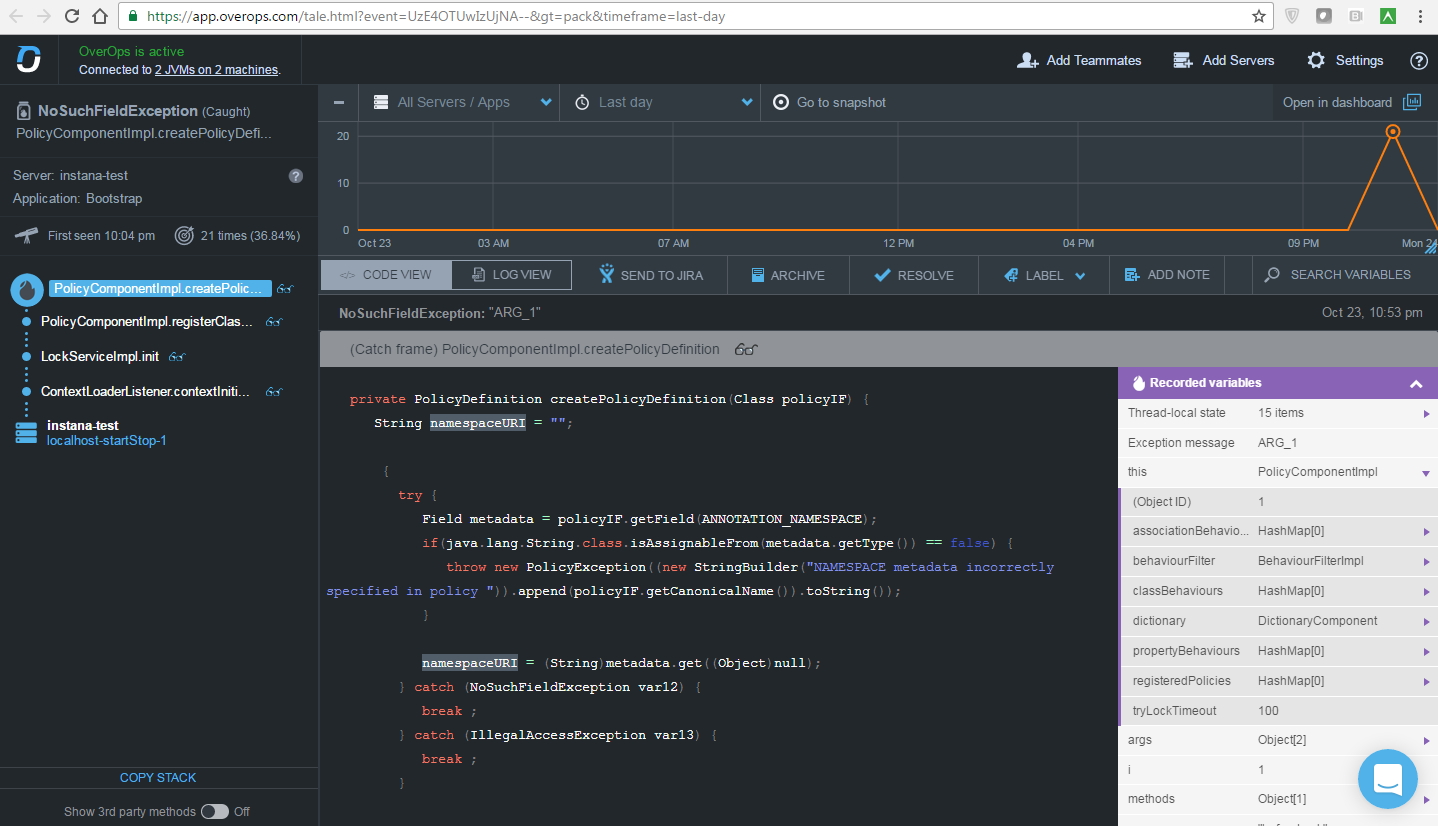
В итоге можно увидеть, какие значения принимали переменные до момента возникновения исключения. При работе агента вендор заявляет его максимальный overhead в 3%. На нашем лабораторном стенде при небольшой нагрузке приблизиться к этому показателю очень сильно не удалось, поэтому пока верим на слово.
Уж не знаю кому как, но мне особое удовольствие доставляют монстры, которые периодически мелькают то там, то сям в интерфейсе. Оказывается, у OverOps есть целый монстрический набор, отдельные представители которого материализуются при возникновении соответствующих ошибок. Забавно, да?

В самом интерфейсе это выглядит примерно так:
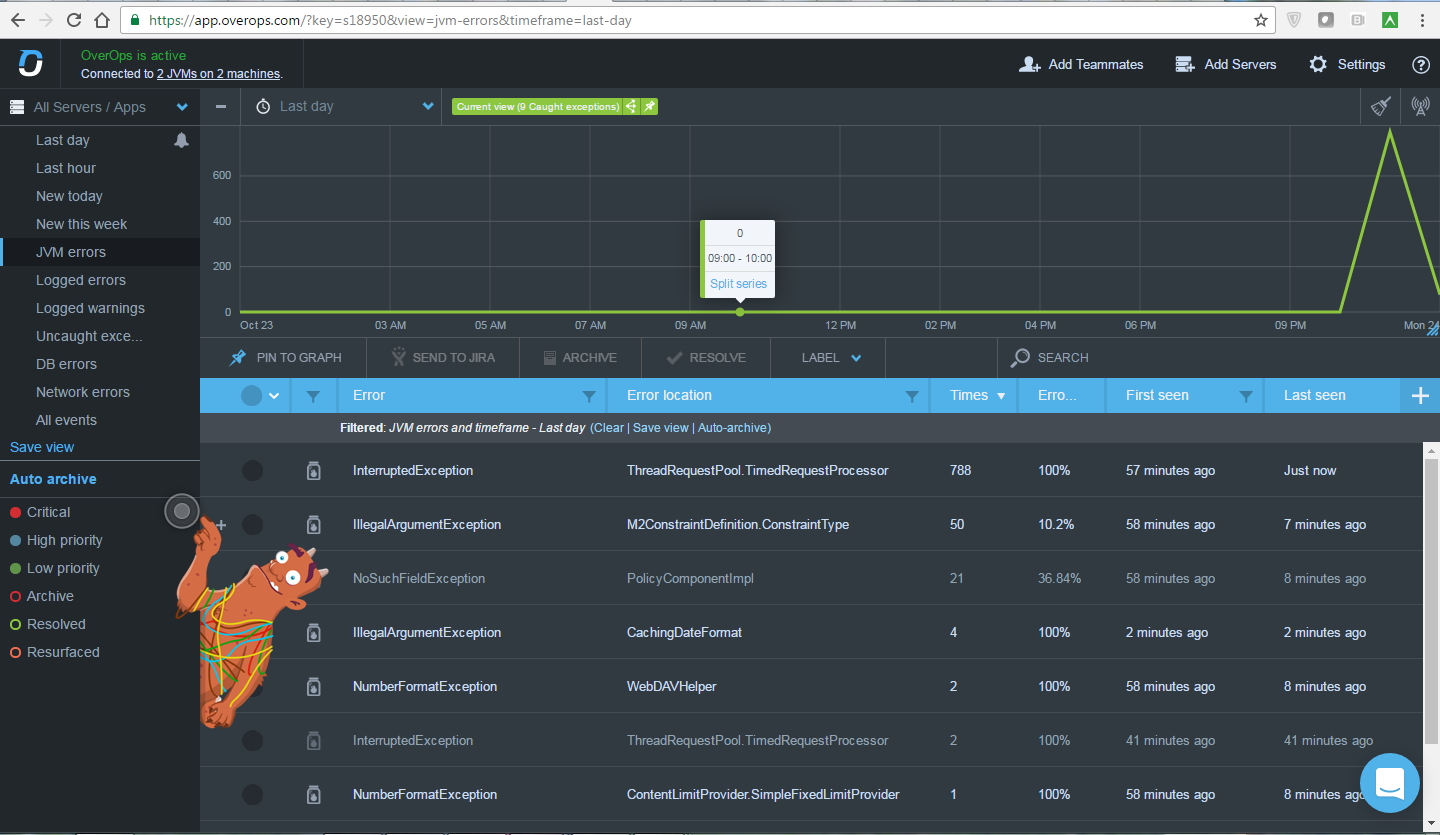
Система собирает снапшоты на периодической основе (т.е. мы увидим не все ошибки, но увидим их количество). Можно создавать правила, например, «10 ошибок такого-то типа»: «сообщи туда-то» («заведи баг в Jira», «черкани в Slack»,«запости в Твиттер» и т.д.). Полный список интеграций можно посмотреть по ссылке.
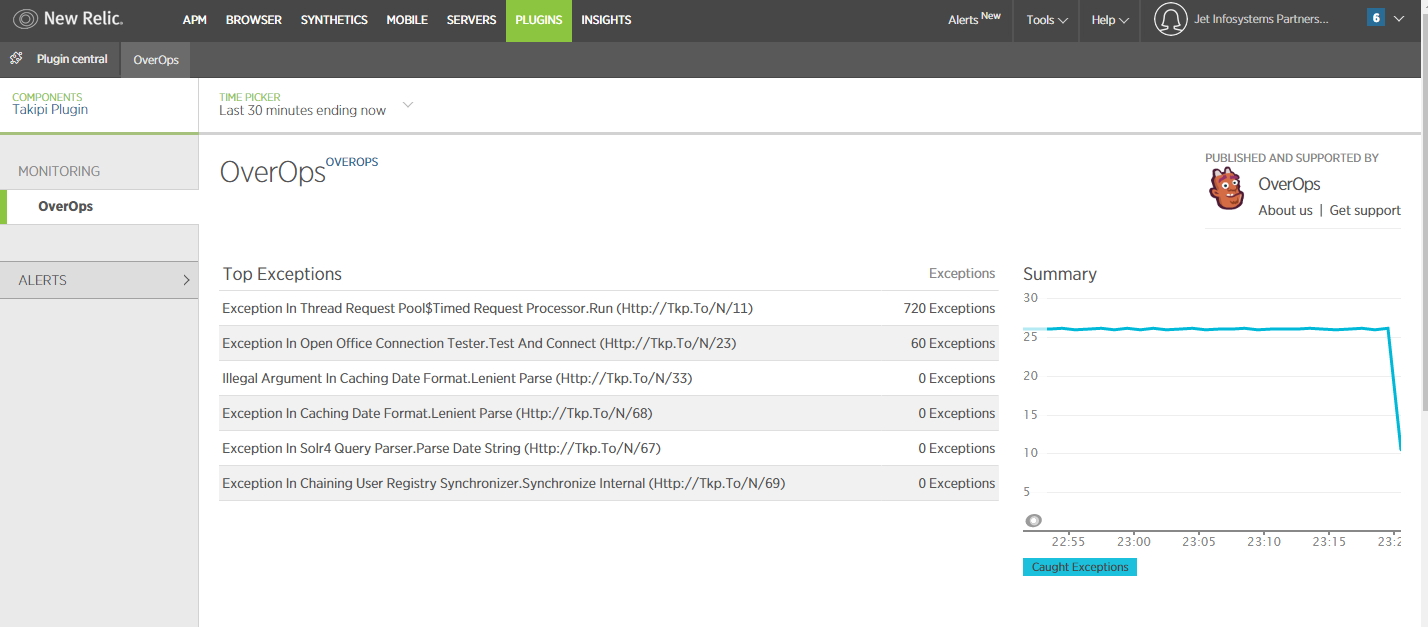
Вот пример моей тестовой интеграции с NewRelic. Детали отображаются на вкладке Plugins и сопровождаются прямой ссылкой в OverOps, что, прямо скажу, весьма удобно:
OverOps умеет фильтровать сторонние библиотеки на предмет исключения их из мониторинга. В самом интерфейсе это выглядит как-то так:
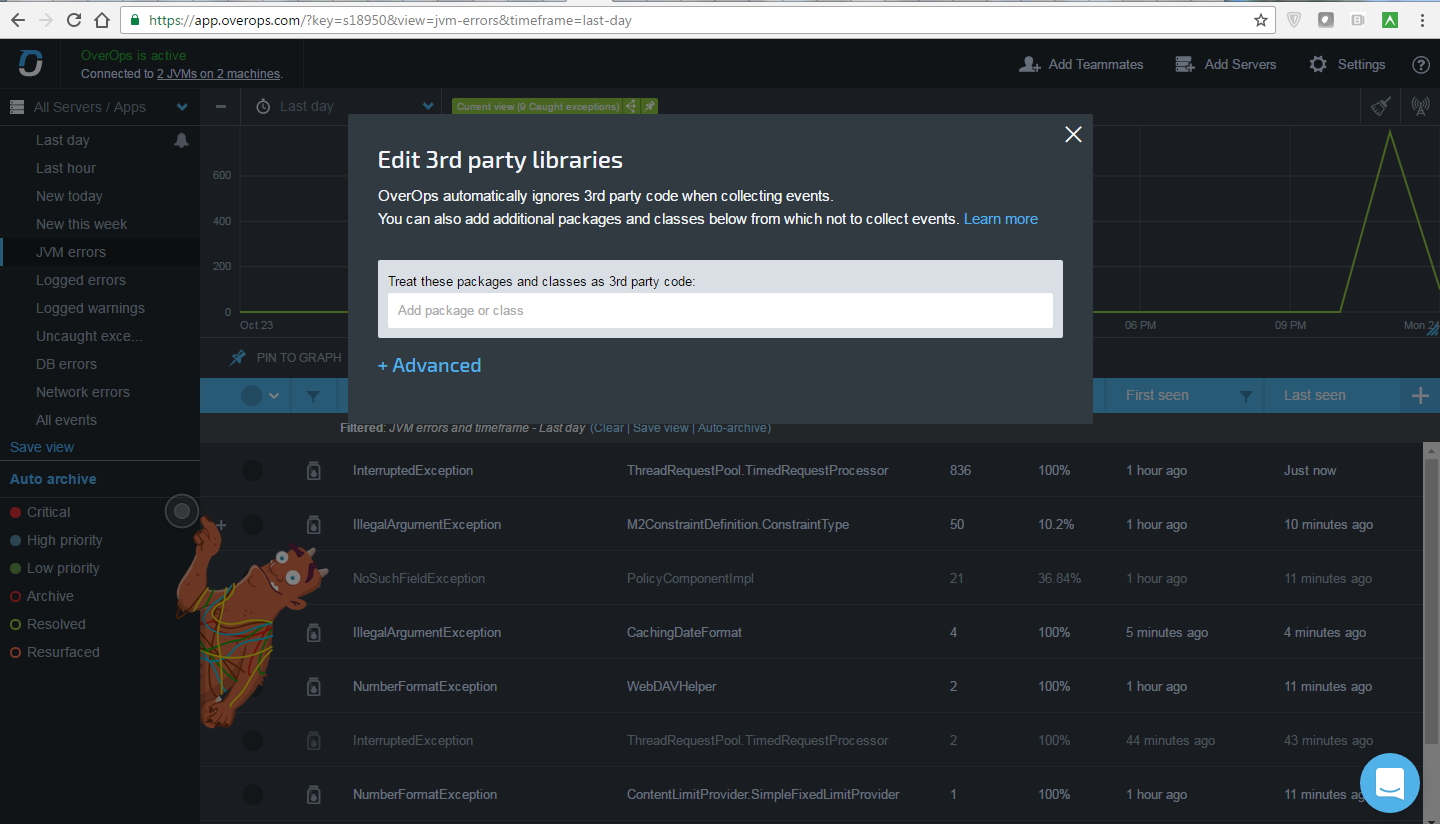
Еще из функциональных возможностей: присоединение исходного кода извне, фильтрация ошибок, если в них содержатся персональные данные (настраивается через регулярные выражения). Из небольших минусов: не умеют показывать тип объекта, если он был унаследован от базового типа, а сигнатура метода принимает базовый тип.
По типу инсталляции решения предоставляются все возможные сценарии: SaaS, Hybrid, On-Premise.
Сейчас уже, конечно, поздновато говорить о том, что в высокий сезон OverOps был бы очень кстати – ведь именно в периоды повышенной нагрузки есть большие шансы отловить разные ошибки, которые в другое время себя никак не проявляли. Но к следующим праздникам и релевантной им пиковой посещаемости все же стоит задуматься о тщательном мониторинге вашей ритейл-системы. Пожалуйста, обращайтесь с вопросами в комментариях. А если задача требует чуть более вдумчивого подхода, наш консалтинг он, как свет в окошке в пургу и вьюгу, – всегда появляется в нужный момент.
Автор статьи: Антон Касимов, архитектор систем управления
Устраивайтесь поудобнее. Поговорим об OverOps – решении для обнаружения ошибок в работе приложений на Java, Scala, Clojure и Groovy. Покажу несколько скриншотов и расскажу об основных фичах продукта. Во вступительной части не случайно шла речь о тестировании. Ошибки. возникающие в продуктивной среде совсем не обязательно появятся в среде разработки и тестирования. А нагрузка реальной пользовательской активностью может выдать доселе невиданные исключения.
Суть работы OverOps в следующем:
1) при старте JVM рядом с ней запускается агент OverOps;
2) агент умеет мониторить возникновение в коде исключений (как обрабатываемых, так и не обрабатываемых);
3) агент в момент возникновения исключения снимает heapdump и накладывает его на декомпилированный байткод.
В итоге можно увидеть, какие значения принимали переменные до момента возникновения исключения. При работе агента вендор заявляет его максимальный overhead в 3%. На нашем лабораторном стенде при небольшой нагрузке приблизиться к этому показателю очень сильно не удалось, поэтому пока верим на слово.
Уж не знаю кому как, но мне особое удовольствие доставляют монстры, которые периодически мелькают то там, то сям в интерфейсе. Оказывается, у OverOps есть целый монстрический набор, отдельные представители которого материализуются при возникновении соответствующих ошибок. Забавно, да?
В самом интерфейсе это выглядит примерно так:
Система собирает снапшоты на периодической основе (т.е. мы увидим не все ошибки, но увидим их количество). Можно создавать правила, например, «10 ошибок такого-то типа»: «сообщи туда-то» («заведи баг в Jira», «черкани в Slack»,
Вот пример моей тестовой интеграции с NewRelic. Детали отображаются на вкладке Plugins и сопровождаются прямой ссылкой в OverOps, что, прямо скажу, весьма удобно:
OverOps умеет фильтровать сторонние библиотеки на предмет исключения их из мониторинга. В самом интерфейсе это выглядит как-то так:
Еще из функциональных возможностей: присоединение исходного кода извне, фильтрация ошибок, если в них содержатся персональные данные (настраивается через регулярные выражения). Из небольших минусов: не умеют показывать тип объекта, если он был унаследован от базового типа, а сигнатура метода принимает базовый тип.
По типу инсталляции решения предоставляются все возможные сценарии: SaaS, Hybrid, On-Premise.
Сейчас уже, конечно, поздновато говорить о том, что в высокий сезон OverOps был бы очень кстати – ведь именно в периоды повышенной нагрузки есть большие шансы отловить разные ошибки, которые в другое время себя никак не проявляли. Но к следующим праздникам и релевантной им пиковой посещаемости все же стоит задуматься о тщательном мониторинге вашей ритейл-системы. Пожалуйста, обращайтесь с вопросами в комментариях. А если задача требует чуть более вдумчивого подхода, наш консалтинг он, как свет в окошке в пургу и вьюгу, – всегда появляется в нужный момент.
Автор статьи: Антон Касимов, архитектор систем управления
Поделиться с друзьями
Комментарии (4)

igor_suhorukov
12.11.2016 00:05Смотрел я этот продукт в свое время — дорогое решение. А повторить самому такое с JVMTI можно только используя агент на C/C++, очень сложно потом еще агрегаты считать и хранить да еще и сотни дашбордов для kibana рисовать…

ITSystemsManagement
12.11.2016 00:20Ну никто же не мешает договориться о дисконте :) Да, и у них оплата только по подписке, постоянных лицензий нет. Самостоятельная разработка? Да не стоит оно того, конечно
turbanoff
HeapDump снимается при каждом исключении?
ITSystemsManagement
Не при каждом исключении. Т.е. при первом появлении такого исключения, конечно, снимают. А при следующих появлениях только считают. Как вендор пишет:
For each exception or error, we take snapshot of the code and state only for some of the occurrences of this event. We basically sample it, according to a certain algorithm — we will always capture it when it first happens, but it happens 1M time in the first hour, we will slow down and take a certain number of samples.