В данном посте мы хотели бы поделиться нашим опытом разработки модуля импорта в Битрикс с сообществом разработчиков.
Наш модуль импорта имеет следующие особенности:
- Работает с MySQL БД Битрикс напрямую (т.е. внутри воссоздана вся объектная модель CMS Битрикс для товаров).
- Соединяться с БД можно следующими способами:
- Прямое соединение;
- SSH;
- HTTP Bridge connection.
- Источником для импорта данных является CLP файл (sqlite БД c объектной моделью данных CatalogLoader).
- Язык программирования C#/.NET 4.0.
Требования
К модулю было предъявлено несколько требований:
Скорость наполнения
Модуль должен отрабатывать максимально быстро. Во-первых, клиент всегда хочет увидеть результат "здесь и сейчас", а ещё лучше "уже вчера". И это правильно. Мы часто делаем наполнение нескольких тестовых товаров непосредственно при обращении клиента, чтобы он мог оценить, как это работает и, если нужно, сразу определиться, какие правки нужны.
Во-вторых, если товаров и их комбинаций очень много, то и загрузка данных может идти весьма долго. Особенно долго идёт загрузка фото, т.к. у каждого товара могут быть десятки фото, несколько комбинаций (торговых предложений) в разном цвете, к каждой соответственно тоже несколько фото, плюс каждое фото должно иметь несколько размеров для корректного отображения на сайте. Однако постоянные изменения на сайте и снижение скорости сайта из-за импорта нежелательны.
Устойчивость к изменениям среды
Модуль должен быть максимально устойчив к изменениям в самом сайте. Битрикс тоже не стоит на месте. Регулярно появляются новые версии, новые расширения. Также сайт может быть в процессе доработки дизайнером и веб-программистом (вплоть до того, что некоторые страницы бывают недоступны в текущий момент). Но мы не можем ждать, нам нужно выполнять нашу работу здесь и сейчас и двигаться в светлое будущее.
С учетом данных требований оптимальным решением была разработка собственного независимого модуля, который позволяет загружать данные напрямую в базу, минимизировав использование дополнительных компонент.
Процесс наполнения
Вот мы и добрались до самого вкусного =)
Упрощённая схема данных Битрикс в режиме магазина выглядит следующим образом
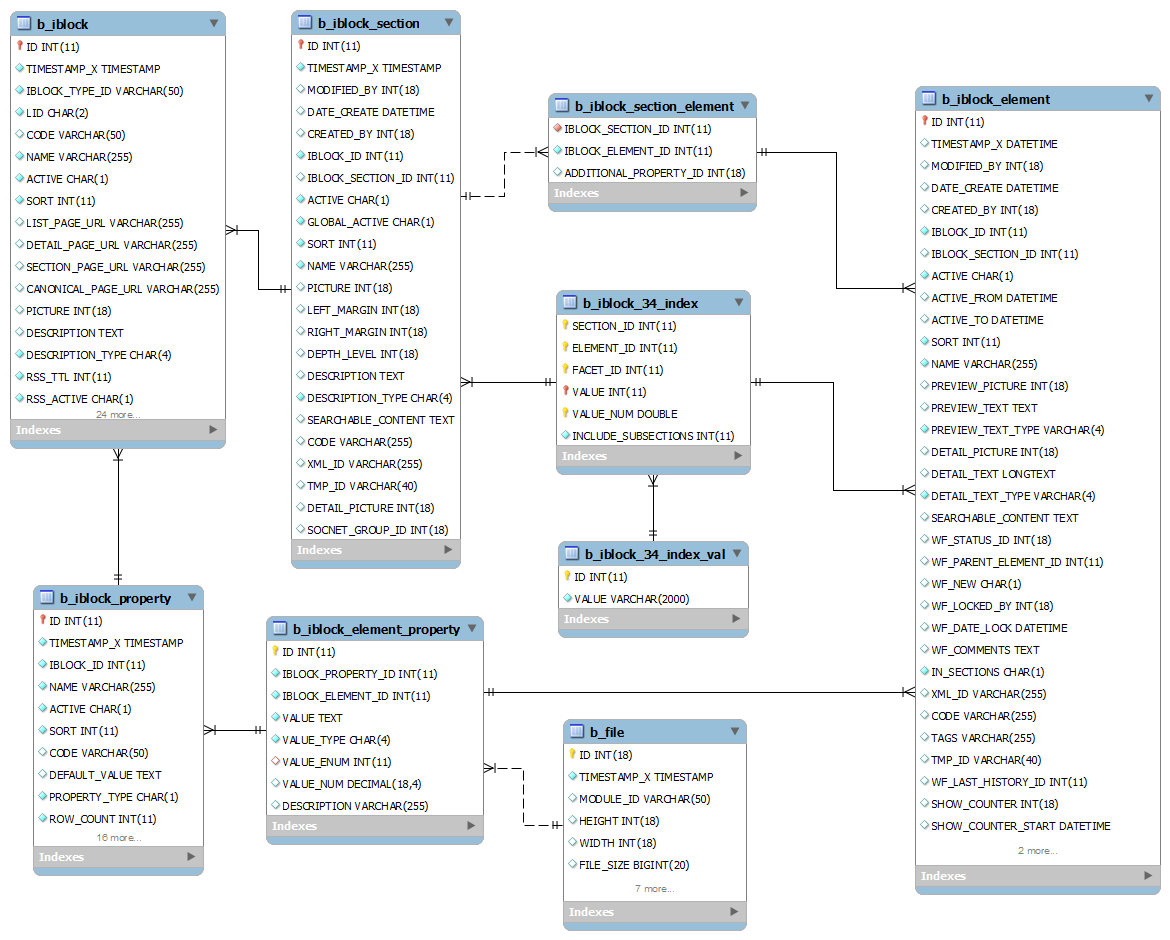
Краткое описание этих таблиц:
- b_iblock — справочник инфоблоков
- b_iblock_section — справочник категорий
- b_iblock_element — справочник товаров и их комбинаций
- b_iblock_section_element — справочник соответствия категорий и товаров. Один товар может быть в нескольких категориях.
- b_iblock_property — справочник характеристик
- b_iblock_element_property — характеристики продукта
- b_file — таблица, хранящая данные о фото и дополнительных файлах (например даташитах) для товаров. В контексте Битрикса все файлы — это просто ещё одна характеристика, только особого типа (VALUE_TYPE = ‘F’). Сами же файлы физически хранятся отдельно от БД, на диске.
- b_iblock_34_index — фасетный индекс для инфоблока №34.
- b_iblock_34_index_val — таблица значений для фасетного индекса инфоблока №34.
Процесс наполнения магазина выполняется в следующем порядке:
- Создание нужных инфоблоков
- Наполнение категорий
- Наполнение товаров
К каждому товару также необходимо заполнить характеристики, комбинации, фото и поисковые индексы.
Создание инфоблоков
Обычно для торгового каталога отводится всего один инфоблок, который должен быть соответственно настроен (наименование, где и как отображается, нужен ли ему дочерний инфоблок для торговых предложений). Таково поведение по умолчанию. Но некоторые клиенты делают более сложную структуру: у них инфоблок по сути является категорией верхнего уровня и приходится совмещать данные из инфоблоков с данными из таблицы категорий, чтобы корректно построить полное дерево магазина.
Наполнение категорий
Вложенные множества (Nested Sets)
Дерево категорий базируется на вложенных множествах. Аналогичные применяются в PrestaShop и ShopScript. Они позволяют делать очень красивое, с алгоритмической точки зрения, ветвление, позволяют делать быстрые удобные выборки из базы данных.
Вложенное множество — это древовидная структура, в которой помимо самого элемента хранится его область вложения, выраженная через два числовых поля, обычно называемых в литературе LEFT и RIGHT. В Битрикс они названы LEFT_MARGIN и RIGHT_MARGIN. Они позволяют одним запросом получить все дочерние элементы, независимо от количества подкатегорий, в уже отсортированном порядке либо всех родителей. Нам не нужно рекурсивно обходить каждую категорию, чтобы получить её связи, что значительно уменьшает время и ресурсы сервера затраченные на эти операции.
Вот пример простейшей выборки из двух категорий на живом проекте. Хорошо видно порядок сортировки и уровень вложенности, можно наглядно оценить как связаны поля LEFT_MARGIN и RIGHT_MARGIN со стандартными DEPTH_LEVEL (глубина), SORT (порядок сортировки) и IBLOCK_SECTION_ID (ссылка на категорию-родителя).
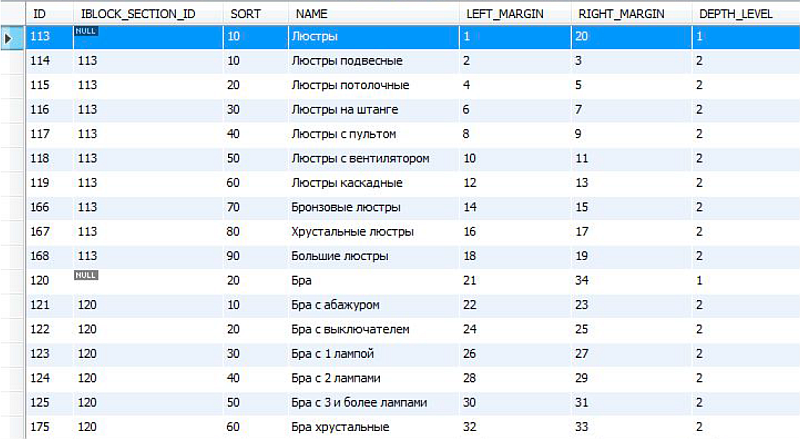
В выборке две категории верхнего уровня и их подкатегории. В виде дерева эта структура выглядит примерно следующим образом:

“Люстры” и “Бра” — категории первого уровня и представляют собой две соседние ветви. Левая цифра в блоке категории — это LEFT_MARGIN, а правая — RIGHT_MARGIN. У родительской категории LEFT_MARGIN является минимальным ключом для текущей ветви, RIGHT_MARGIN — максимальным. Всё что выпадает из диапазона между LEFT_MARGIN и RIGHT_MARGIN — не относится к нужной нам ветви. Вы можете видеть, что у двух соседних (и отображаемых подряд) категорий одного уровня нумерация индексов идёт подряд: левый ключ следующего элемента всегда на единицу больше правого ключа текущего элемента. Если категории должны идти подряд, но вы видите, что значения ключей не подряд — это первый признак проблем с построением ключей.
Всё это выглядит красиво и работает нормально ровно до тех пор, пока индексы идеально заполнены. Как только с индексом что-то случилось — в лучшем случае ваши категории начнут "плясать", в худшем — ломается вёрстка или категории пропадают. С ними нужно работать очень аккуратно, ведь если категория пропадает, пользователь не увидит продуктов в ней и работа пойдёт насмарку.
А испортить эту структуру очень легко. Вам больше не достаточно просто вставить или просто удалить запись в БД. Если вы вставили, удалили или перетащили запись (изменив порядок сортировки) — вам придётся перестроить дерево категорий, чтобы индексы остались консистентными. Очень часто новички увидев понятные поля DEPTH_LEVEL, SORT и IBLOCK_SECTION_ID считают, что их заполнения достаточно, а про Nested Sets вообще не в курсе, соответственно индексы не перестраиваются и дерево категорий медленно, но верно превращается в фарш. Когда там всего несколько не сильно меняющихся категорий — это доставляет минимальные проблемы, часто народу проще удалить всё и пересоздать, чем разобраться. Но когда магазин после доработок загружается рабочими данными с тысячами категорий — проблема становится поперёк горла.
Ещё хуже, если проект достался новому разработчику уже битым — очень много времени тратится на выяснение причин проблем.
Вот вам полезных SQL запросов для проверки вашей БД, они помогут вам проверить корректность Nested Sets и не тратить время на гадание на кофейной гуще в поисках проблем.
?-- Если все правильно то результата работы запроса не будет, иначе, получаем список идентификаторов неправильных строк;
SELECT * FROM `b_iblock_section` WHERE LEFT_MARGIN >= RIGHT_MARGIN;
-- Получаем количество записей (узлов), минимальный левый ключ и максимальный правый ключ, проверяем что младший = 1; максимальный = количество * 2
SELECT COUNT(ID), MIN(LEFT_MARGIN), MAX(RIGHT_MARGIN) FROM `b_iblock_section`;
-- Если все правильно то результата работы запроса не будет, иначе, получаем список идентификаторов неправильных строк;
SELECT * FROM (SELECT ID, MOD((RIGHT_MARGIN - LEFT_MARGIN), 2) AS ostatok FROM `b_iblock_section`) t WHERE ostatok = 0;
-- Если все правильно то результата работы запроса не будет, иначе, получаем список идентификаторов неправильных строк;
SELECT * FROM (SELECT ID, MOD(LEFT_MARGIN - DEPTH_LEVEL + 2, 2) AS ostatok FROM `b_iblock_section`) t WHERE ostatok = 1;
-- Выводит список категорий, с указанием уровня вложенности, родителя. Список отсортирован по левому ключу, при повторении ключа легко это увидеть
SELECT ID, CONCAT(REPEAT('--', DEPTH_LEVEL - 1), `NAME`) as `NAME`, LEFT_MARGIN, RIGHT_MARGIN, DEPTH_LEVEL, IBLOCK_SECTION_ID as PARENT FROM `b_iblock_section`
ORDER BY IF(ISNULL(IBLOCK_SECTION_ID), ID, IBLOCK_SECTION_ID), LEFT_MARGIN;
-- Выводит список продублировавшихся ключей
SELECT ID, CONCAT(REPEAT('--', DEPTH_LEVEL - 1), `NAME`) as `NAME`, LEFT_MARGIN, RIGHT_MARGIN, DEPTH_LEVEL, IBLOCK_SECTION_ID as PARENT FROM `b_iblock_section`
WHERE LEFT_MARGIN IN (SELECT LEFT_MARGIN FROM `b_iblock_section` GROUP BY LEFT_MARGIN HAVING count(*)>1)
ORDER BY LEFT_MARGIN;
-- Выводит список ошибочных секций, чьи ключи не находятся в рамках родителя или чья глубина не совпадает с реальной, или левый ключ больше либо равен правому
SELECT CHILD.ID, CHILD.DEPTH_LEVEL, CHILD.`NAME`, CHILD.LEFT_MARGIN, CHILD.RIGHT_MARGIN, PARENT.LEFT_MARGIN as PARENT_LEFT_MARGIN, PARENT.RIGHT_MARGIN as PARENT_RIGHT_MARGIN
FROM `b_iblock_section` AS CHILD
JOIN `b_iblock_section` AS PARENT ON PARENT.ID = CHILD.IBLOCK_SECTION_ID
WHERE (CHILD.LEFT_MARGIN <= PARENT.LEFT_MARGIN) OR (CHILD.RIGHT_MARGIN >= PARENT.RIGHT_MARGIN) OR ((CHILD.DEPTH_LEVEL - 1) <> PARENT.DEPTH_LEVEL) OR (CHILD.LEFT_MARGIN >= CHILD.RIGHT_MARGIN);Наполнение товаров
Полноценное отображение товаров “из коробки” не работает
Такая вот “фича”. Независимо от того, что и как вы импортировали и видите в админке, вы не увидите свойств во фронтэнде пока дополнительно, руками, не разрешите их отображение через режим правки.
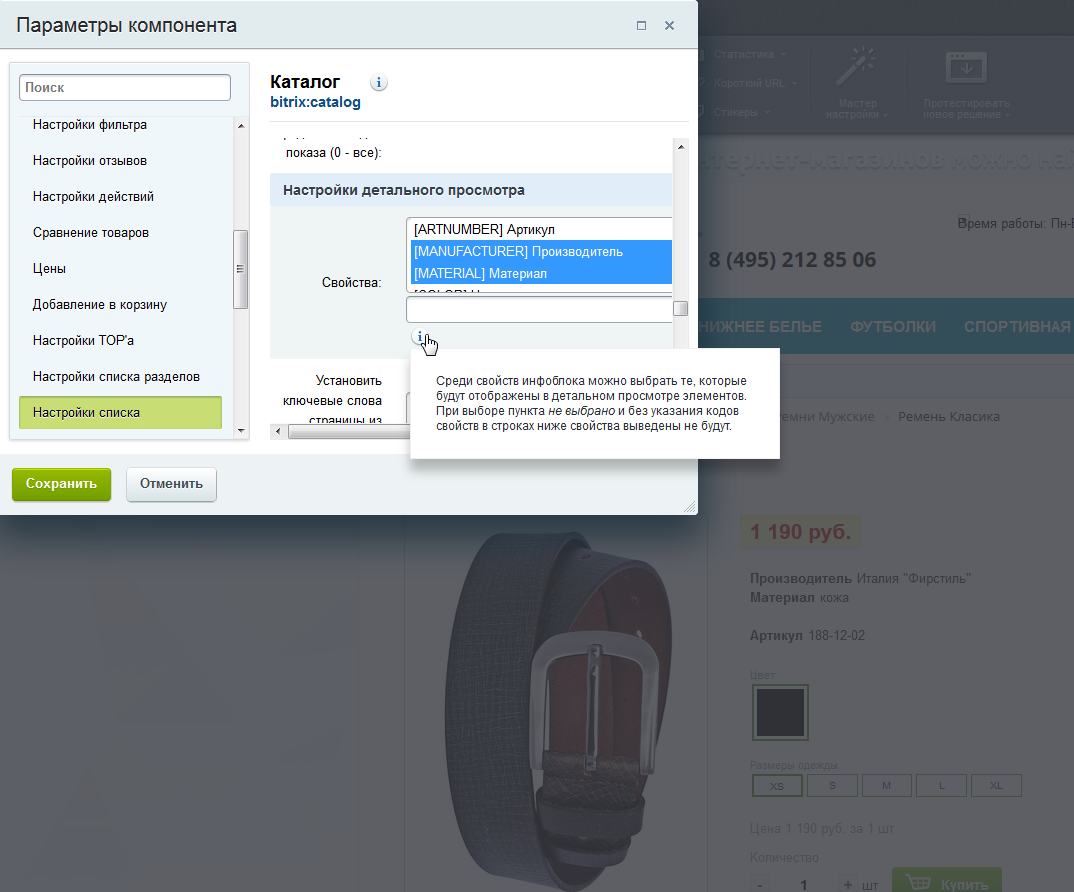
При первом знакомстве с этой CMS такое поведение несколько сбивает с толку, и я не помню ни одной другой CMS с аналогичным поведением по умолчанию. Хотя дизайнер настройки инфоблоков у них мощный, но по умолчанию про него никто не знает, и нужно либо тратить уйму времени на чтение документации, либо тратить уйму денег на специалиста по Битрикс который будет тратить время за вас, либо искать CMS попроще (что опять же отнимает время).
Фасетные индексы
Фасетный индекс предполагает создание индекса для каждой характеристики товаров, по которому можно делать очень быстрый поиск. В базу данных на каждый инфоблок добавляется две таблицы вида b_iblock_{IBLOCK_ID}_index и b_iblock_{IBLOCK_ID}_index_val в которых каждому продукту описываются характеристики, по которым его можно искать. В схеме выше эти две таблицы шли с индексом 34, т.к. для описания торговых предложений в взятой базе данных использовался 34-ый инфоблок. Таких блоков может быть много и соответственно на каждый инфоблок будет создана пара таблиц с фасетными индексами. Запись добавляется для каждой категории в ветви. Т.е. чтобы продукт искался по заданным полям во всех нужных категориях, нужно дублировать записи для каждой категории в которой вы хотите находить этот продукт. Как правило, это категория нижнего уровня — с продуктом, и все категории выше по этой ветви (все родители), чтобы например в категории верхнего уровня можно было найти продукты из подкатегорий.
Появление фасетных индексов было для нас неприятной неожиданностью. После одного из зимних обновлений товары во фронтэнде пропали. Никаких ошибок. Всё видно в панели администрирования. Но во фронтэнде новых товаров не было. Сквозь образовавшуюся тишину было слышно, как седеют программисты. Оказалось, что отныне и навсегда продукты, для которых не заполнены фасетные индексы, не отображаются. Даже если эти самые фасетные индексы никто не хотел, никто не включал намеренно и более того никто ничего не выбирал во фронтэнде. Т.е. фильтр почему-то работает даже если поля для фильтрации пользователем не заполнены. Поведение странное. Последствия таких внедрений — у людей умирали магазины. Люди несли убытки. Независимо от способа наполнения.
Отдельно стоит упомянуть про вычисление идентификатора характеристики. Вы верите в магию? Вот это и есть магия. Во-первых, согласно документации это поле должно не соответствовать идентификатору из общего списка характеристик (что было бы логично для фильтра по характеристикам), а являться идентификатором из общего списка характеристик умноженным на два. Внятного ответа на вопрос “В чём смысл этой магии” мы так и не нашли. Кажется, умножение на 42 работало бы гораздо лучше, в нём есть хоть какой-то смысл. Во-вторых, неоднократно замечалось, что наполнение сайта через админку могло не соблюдать эту, казалось бы, тривиальную магию.
Реализация магии описана здесь, там же есть ссылка на документацию, по которой должно было быть описано что на что и зачем умножается, но увы, на момент написания статьи там опять магия чисел с четвёркой.
Почитать подробнее про фасетные индексы и как с ними бороться можно на форуме разработчиков Bitrix в теме Умный фильтр весь такой фасетный и няшный.
Прочие нюансы
Чрезмерное кэширование вредно
Битрикс по умолчанию имеет собственный включенный кэш. Изменения на сайте могут не отображаться до тех пор, пока этот кэш не будет принудительно сброшен. С этим всё понятно, для сброса можно использовать API самой CMS. Но иногда народ включает дополнительные кэширующие средства, также их может включить хостинг-провайдер, а в завершении усугубить ситуацию может и кэш хрома например.
Системные требования растут вместе с магазином
Мы максимально оптимизировали наш модуль, но это не всегда спасает клиентов от необходимости увеличивать мощности сервера. При большом росте количества и характеристик товаров Битрикс требует и роста серверных мощностей, в особенности ОЗУ для нормальной работы. В конфигурации с самым дешёвым хостингом на котором CMS запустилась и работала с десятком демонстрационных товаров всё успешно сложится, если залить 10000 товаров. Стоит понимать, что это всё-таки мощная многофункциональная CMS для бизнеса, соответственно и хостинг ей нужен серьёзнее, чем для сайта-визитки.
К чему мы пришли
Битрикс дал нам много интересного опыта, как в рамках работы с CMS, так и в рамках взаимодействия с клиентами. Несомненно, это хорошая CMS с огромными возможностями. Но он слишком тяжёлый, слишком перегруженный для новичков. Да что там для новичков, даже программисты могут потратить уйму времени и нервов, чтобы запустить полноценно сайт "из коробки", если работают конкретно с этой CMS впервые. Слишком много нюансов. Если Вы только-только начинаете своё дело и у вас в штате нет опытного Битрикс-программиста, возможно стоит выбрать какую-то более понятную CMS или хотя бы попробовать демонстрационную версию прямо в их сервисе Виртуальная лаборатория до покупки.
Если же вы уже купили Битрикс, первое, что вам нужно сделать — заполнить его контентом и сделать полную резервную копию. Уже позже можно заказать дизайнеру вёрстку, выполнить настройку отображения товаров и прочие правки. Плюс такого подхода в том, что человек дорабатывающий магазин сразу будет иметь возможность визуально оценить последствия правок на живом товаре, с описанием, всеми нужными атрибутами, комбинациями и фото. Неоднократно были случаи, когда сначала сайт отдавали на растерзание дизайнерам, а уже потом нам, и клиент в последний момент перед запуском магазина сталкивался с проблемами в вёрстке.
Также мы сделали небольшой бенчмарк скорости импорта в Битрикс через наш модуль. В тестовом наборе участвовало 1495 товаров с 23298 фото, а так же с комбинациями.
Локальное соединение с БД (прямое соединение с MySQL)
| Тип теста | Время загрузки |
|---|---|
| Импорт в пустую БД | 21,48 секунд |
| Обновление цен и остатков | 15,91 секунд |
Импорт на сайт через http bridge
Тестовый импорт с рабочей машины делался на тестовый магазин bitrixlabs.ru. Фото для импорта располагались на сервере поставщика, были доступны по http протоколу. В этом тесте видно, как загрузка фото и скорость сети влияет на скорость наполнения.
| Тип теста | Время загрузки |
|---|---|
| Импорт в пустую БД (без фото) | 6 минут 8,11 секунд |
| Импорт в пустую БД (с 23298 фото) | 38 минут 11,49 секунд |
| Обновление цен и остатков | 4 минуты 11,87 секунды |
Модуль сейчас используется в следующих программах и сервисах:
- PriceMatrix для обработки прайсов;
- Парсеры сайтов CatalogLoader.
Комментарии (6)

olegprof
22.11.2016 21:59+1Отдельно стоит упомянуть про вычисление идентификатора характеристики.
…
Являться идентификатором из общего списка характеристик умноженным на два
Всё просто. В одном столбце хранятся идентификаторы и свойств и цен. Идентификаторы свойств — чётные, цен — нечётные.


Spunreal
23.11.2016 10:15+1Такая вот “фича”. Независимо от того, что и как вы импортировали и видите в админке, вы не увидите свойств во фронтэнде пока дополнительно, руками, не разрешите их отображение через режим правки.
Всё зависит от реализации. Есть DISPLAY_PROPERTIES, а есть просто PROPERTIES. Через DISPLAY_PROPERTIES обычно работает только стандартный магазин Битрикса, а так же некоторые решения маркетплейса. А с PROPERTIES уже больше возможностей для автоматизации (вывод свойств по префиксу или по любой другой закономерности).
shurupkirov
Правильно ли я понял, что первый импорт идет в вашем случае идет 39 минут, а последующие, где идет минимум добавлений товара, а только изменения цен и свойств — 5 минут?
CatalogLoader
Да, всё верно.
В тесте на 38 минут основную задержку вносит необходимость загружать фото продуктов с сайта поставщика, что само по себе занимает время, а так же создание с них копий во всех необходимых для CMS размерах.
Что касается обновления, то это тоже не одна тривиальная вставка, ведь для обновления нужно сначала вычитать из магазина все товары по категориям, включая их комбинации, затем только начинается процесс обновления. Сам процесс выполняется не долго, ключевую задержку сыграла скорость сети. Тест проводился с локальной машины разработчика, вот результаты замера скорости на его канале связи: