Но виновен не Жираф,
А тот, кто крикнул из ветвей:
«Жираф большой — ему видней!» (с)
Потребовалось оперативно разобраться с технологией Apache Spark заточенную для использования Big Data. В процессе выяснения активно использовал habrahabr, так что попробую вернуть информационный должок, поделившись приобретенным опытом.
А именно: установкой системы с нуля, настройкой и собственно программированием кода решающего задачу обработки данных для создания модели, вычисляющей вероятность банкротства клиента банка по набору таких признаков как сумма кредита, ставка и т.д.
Больших данных вроде как должно быть много, но почему-то не просто найти то злачное место, где их все щупают. Сначала попробовал вариант с ambari, но на моей Window7 валились ошибки настроек сетевого моста. В итоге прокатил вариант с преднастроенной виртуальной машиной от Cloudera (CDH). Просто устанавливаем VirtualBox, запускаем скачанный файл, указываем основные параметры (память, место) и через 5 минут достопочтенный
Несколько слов, почему именно Spark. Насколько я понимаю, ключевые отличия от изначальной MapReduce в том, что данные удерживаются в памяти, вместо сброса на диск, что дает ускорение во много раз. Но, пожалуй, более важны реализации целого ряда статистических функций и удобным интерфейсом для загрузки/обработки данных.
Дальше собственно код для решения следующей задачи. Есть реально большие данные (ибо рука очень устает скролить эти 2000 строк) в формате:

Есть предположение, что дефолт как-то связан с остальными параметрами (кроме первого, к уважаемым Ивановым1…N претензий нет) и нужно построить модель линейной регрессии. Прежде чем начать, стоит оговориться, что это мой первый код на Java, сам я работаю аналитиком и вообще это мой первый запуск Eclipse, настройка Maven и т.д. Так что не стоит ждать изысканных чудес, ниже решение задачи в лоб тем способом, который почему-то заработал. Поехали:
1. Создаем Spark сессию. Важный момент – это все работает только с версии 2.0.0, тогда как в поставке CDH идет v1.6. Так что нужно сделать апгрейд, иначе будет исключение при запуске.
SparkSession ss = SparkSession
.builder()
.appName("Bankrupticy analyser")
.getOrCreate();2. Загружаем данные в специальный тип JavaRDD. По сути это примерно как List в C#, по крайней мере я так это себе объяснил. Библиотека умеет читать много чего, но для начала сойдет обычный csv файл.
JavaRDD<Client> peopleRDD = ss.read()
.textFile(filename)
.javaRDD()
.map(new Function<String, Client>()
{
public Client call(String line) throws Exception
{
String[] parts = line.split(","); // Разделитель
Client client = new Client();
client.setName(parts[0]); // Парсим поля (ФИО в первой колонке)
client.setYearOfBirth(Double.parseDouble(parts[1]));
client.setAmount(Double.parseDouble(parts[2]));
client.setTerm(Double.parseDouble(parts[3]));
client.setRate(Double.parseDouble(parts[4]));
client.setPaid(Double.parseDouble(parts[5]));
client.setStatus(Double.parseDouble(parts[6])); // Тут признак банкротства (1 - банкрот, 0 – пока еще платит)
return client;
}
});Где Client это обычный класс с нашими атрибутами (можно найти в файле проекта, по ссылке в конце поста).
3. Создаем датасет, который необходим для нормализации данных. Без нормализации расчет модели линейной регрессии методом градиентного спуска не прокатит. Сначала пытался прикрутить StandardScalerModel: fit -> transform но возникли проблемы c типами данных, кажется из-за разности версий. В общем, пока обошелся обходным решением, а именно через селект к данным, выполняя нормализацию прямо в нем:
Dataset<Row> clientDF = ss.createDataFrame(peopleRDD, Client.class);
clientDF.createOrReplaceTempView("client");
Dataset<Row> scaledData = ss.sql(
"SELECT name, (minYearOfBirth - yearOfBirth) / (minYearOfBirth - maxYearOfBirth),"
+ "(minAmount - amount) / (minAmount - maxAmount),"
+ "(minTerm - term) / (minTerm - maxTerm),"
+ "(minRate - rate) / (minRate - maxRate),"
+ "(minPaid - paid) / (minPaid - maxPaid),"
+ "(minStatus - status) / (minStatus - maxStatus) "
+ "FROM client CROSS JOIN "
+ "(SELECT min(yearOfBirth) AS minYearOfBirth, max(yearOfBirth) AS maxYearOfBirth,"
+ "min(amount) AS minAmount, max(amount) AS maxAmount,"
+ "min(term) AS minTerm , max(term) AS maxTerm,"
+ "min(rate) AS minRate, max(rate) AS maxRate,"
+ "min(paid) AS minPaid, max(paid) AS maxPaid,"
+ "min(status) AS minStatus, max(status) AS maxStatus "
+ "FROM client)").cache();4. Модель принимает данные в формате JavaRDD в которые запихнем ФИО клиента. Это норм для красивого отображения тестового варианта, в жизни конечно так не стоит делать, хотя вообще подобное может понадобится для других целей.
JavaRDD<Row> rowData = scaledData.javaRDD(); // Dataset to JavaRDD
JavaRDD<Tuple2<String,LabeledPoint>> parsedData = rowData.map(
new Function<Row, Tuple2<String,LabeledPoint>>()
{
public Tuple2<String,LabeledPoint> call(Row row)
{
int last = row.length();
String cname = row.getString(0); // Первый элемент - ФИО
double label = row.getDouble(last - 1); // Последний – признак дефолта
double[] v = new double[last];
for (int i = 1; i < last - 1; i++) // Посередине независимые переменные
v[i] = row.getDouble(i);
v[last - 1] = 1; // +intercept
return new Tuple2<String, LabeledPoint>
(cname, new LabeledPoint(label, Vectors.dense(v)));
}
});5. Выделим данные LabeledPoint для модели:
JavaRDD<LabeledPoint> parsedDataToTrain = parsedData.map(
new Function<Tuple2<String,LabeledPoint>, LabeledPoint>()
{
public LabeledPoint call(Tuple2<String,LabeledPoint> namedTuple)
{
return namedTuple._2(); // 2 означает второй элемент в составе <String,LabeledPoint>
}
});
parsedData.cache();6. Создаем собственно модель:
int numIterations = 200;
double stepSize = 2;
final LinearRegressionModel model
= LinearRegressionWithSGD.train(JavaRDD.toRDD(parsedDataToTrain), numIterations, stepSize); 7. И собственно основная работа + результат:
final NumberFormat nf = NumberFormat.getInstance(); // Для красоты вывода чисел
nf.setMaximumFractionDigits(2);
JavaRDD<Tuple2<Double, Double>> valuesAndPreds = parsedData.map(
new Function<Tuple2<String,LabeledPoint>, Tuple2<Double, Double>>()
{
public Tuple2<Double, Double> call(Tuple2<String,LabeledPoint> namedTuple)
{
double prediction = model.predict(namedTuple._2().features()); // Расчет зависимой переменной для набора признаков данного клиента
System.out.println(namedTuple._1() + " got the score " + nf.format(prediction)
+ ". The real status is " + nf.format(namedTuple._2().label()));
return new Tuple2<Double, Double>(prediction, namedTuple._2().label());
}
});
8. И посчитаем средний квадрат ошибки (из п. 7):
double MSE = new JavaDoubleRDD(valuesAndPreds.map(
new Function<Tuple2<Double, Double>, Object>()
{
public Object call(Tuple2<Double, Double> pair)
{
return Math.pow(pair._1() - pair._2(), 2.0);
}
}).rdd()).mean();
В данном случае вывод будет выглядеть так:
Иванов1983 got the score 0.57. The real status is 1
Иванов1984 got the score 0.54. The real status is 1
Иванов1985 got the score -0.08. The real status is 0
Иванов1986 got the score 0.33. The real status is 1
Иванов1987 got the score 0.78. The real status is 1
Иванов1988 got the score 0.63. The real status is 1
Иванов1989 got the score 0.63. The real status is 1
Иванов1990 got the score 0.03. The real status is 0
Иванов1991 got the score 0.57. The real status is 1
Иванов1992 got the score 0.26. The real status is 0
Иванов1993 got the score 0.07. The real status is 0
Иванов1994 got the score 0.17. The real status is 0
Иванов1995 got the score 0.83. The real status is 1
Иванов1996 got the score 0.31. The real status is 0
Иванов1997 got the score 0.48. The real status is 0
Иванов1998 got the score 0.16. The real status is 0
Иванов1999 got the score 0.36. The real status is 0
Иванов2000 got the score -0.04. The real status is 0
16/11/21 21:36:40 INFO Executor: Finished task 0.0 in stage 176.0 (TID 176). 3194 bytes result sent to driver
16/11/21 21:36:40 INFO TaskSetManager: Finished task 0.0 in stage 176.0 (TID 176) in 432 ms on localhost (1/1)
16/11/21 21:36:40 INFO TaskSchedulerImpl: Removed TaskSet 176.0, whose tasks have all completed, from pool
16/11/21 21:36:40 INFO DAGScheduler: ResultStage 176 (mean at App.java:242) finished in 0.433 s
16/11/21 21:36:40 INFO DAGScheduler: Job 175 finished: mean at App.java:242, took 0.452851 s
Training Error = 0.11655428630639536
Теперь имеет смысл сравнить его с аналитическим решением в эксель:
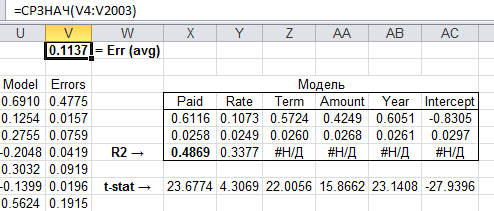
Как видим, результат весьма близкий, модель получилась годная, можно натравливать на тестовую выборку. Код проекта с исходными данными можно скачать тут.
В целом хочется отметить, что ажиотаж вокруг больших данных представляется достаточно чрезмерным (бооольшим таким). Более ценным мне кажется скорее не объем, а то, как именно обрабатывать эти данные. Т.е. какая-нибудь комбинация TF-IDF — нейросеть — ALS может дать изумительный результат при возможности творчески поработать и на ограниченном объеме. Проблема наверное в том, что менеджеры могут выбивать бюджеты под магические слова Big Data, а потратить ресурс на просто исследовательские цели требует слишком долгосрочный горизонт планирования для обычной компании.
Для понимания данной мысли уточню, зоопарк экосистемы Hadoop (Hive, Pig, Impala и т.д.) шикарен. Я сам занимаюсь разработкой распределенной системы вычислений на нейросетях (одновременное выполнение многопоточных приложений на нескольких серверах с синхронизацией и агрегацией результатов) для макроэкономического моделирования и примерно понимаю сколько граблей лежит на этом пути. Да, есть задачи, где альтернатив этим технологиям нет — например примитивная, но потоковая онлайн обработка диких объемов данных (условно говоря какой-нибудь анализ трафика сотовых абонентов Москвы). Тут Apache Storm или Spark Streaming могут сотворить чудо.
Но если у нас есть массив данных по миллиону клиентов за год, то выборка каждого 10-го (или даже 100-го) случайным образом для построения модели какого-нибудь скоринга даст практически тот же результат что и полный массив. Иными словами, вместо королевы бала Data mining стала падчерицей, хотя скорее всего это временно. Ажиотаж спадет, но экспериментальные подходы обкатывающиеся сейчас на Hadoop-кластерах распространятся и те кто первыми осознает перспективы исследования «маленьких» данных окажется в дамках.
Комментарии (9)

SamKrew
25.11.2016 10:20+1Классно, обучающая статья с «У меня тут не получилось, сделал велосипед» и «Так делать нельзя, но я сделяль!».
Не надо так.
pustota_2009
25.11.2016 10:43Знать как делать селекты — полезно. Как скрещивать наборы — полезно. Человек с мозгами разберется как с этим работать. Если человек без мозгов, то читать это не будет. Лично мне бы такой пример сэкономил ровно три дня.

facha
25.11.2016 10:48Проблема наверное в том, что менеджеры могут выбивать бюджеты под магические слова Big Data
Вы просто глядите со своей колокольни (data science). Если посмотреть на hadoop как решение для data warehouse, бюджеты не покажутся такими уж фантастическими (по сравнению с ценниками Teradata, Netezza,...).pustota_2009
25.11.2016 14:11Тут я имел в виду не столько цену hadoop решений самих по себе, сколько возможности обосновать исследовательские расходы. Если условный менеджер приходит и говорит:
«давайте построим хранилище Big Data и найдем там что-то полезное за X рублей»
ему могут их дать. А если он скажет:
«давайте построим хранилище и найдем там что-то полезное за X/5 рублей»
Ему с большей вероятностью откажут, хотя стоить будет дешевле и результат будет похожий. Но нет волшебных слов, так что увы)

Dark_Daiver
25.11.2016 18:23Немного оффтопа
Я правильно понимаю, что у вас на выходе регрессии должны быть значения от 0 до 1? Если так, то может имело смысл использовать логистическую регрессию вместо линейной?
>Без нормализации расчет модели линейной регрессии методом градиентного спуска не прокатит.
Ну на самом деле как повезет. Если разумно выбирать шаг, то может и прокатит. Все таки выпуклая функция ошибки.
Но с нормализацией лучше, конечно.pustota_2009
26.11.2016 14:36В целом согласен, однако в данном конкретном случае была задача свериться с экселем (убедиться что все корректно рассчитано), а там логистической функции вроде нет. И конкретно на этих данных чтобы не расходилось шаг должен быть с десятком нулей после запятой и результат очень плохой, поэтому альтернативы нет)
Avvero
На правах «только начинающего постигать азы».
Расскажите пожалуйста, параметры int numIterations = 200; double stepSize = 2; как выбраны? На сколько я понимаю, их нужно подбирать на основе анализа истории «спуска».
pustota_2009
В данном случае эти параметры оказались именно такими практически случайным образом, это ведь не настоящие данные, а для разработки (были сгенерированны функцией rand() в экселе).
Вообще их выбирают исходя из того, что слишком большой шаг ведет к расходимости, а слишком маленький долго работает. Насколько я понимаю, данная реализация уменьшает шаг с каждой итерацией на stepSize/sqrt(t). Но пока с этим не разбирался детально.