Здравствуй, мир! Сегодня у нас серия статьей для людей со средними знаниями о работе процессора в которой мы будем разбираться с процессорными архитектурами (у меня спелл чекер ругается на слово Архитектурами/Архитектур, надеюсь я пишу слово правильно), создавать собственную архитектуру процессора и многое другое.

Принимаются любые замечания!
Немного про архитектуру процессора
Исторически сложилось, что существуют много процессоров и много архитектур. Но многие архитектуры имеют схожести. Специально для этого появились "Группы" архитектур типа RISC, CISC, MISC, OISC (URISC). Кроме того они могут иметь разные архитектуры адресации памяти (фон Неймана, Гарвард). У каждого процессора есть своя архитектура. Например большинство современных архитектур это RISC (ARM, MIPS, OpenRISC, RISC-V, AVR, PIC** и т.д.), но есть архитектуры которые выиграли просто за счет других факторов (Например удобство/цена/популярность/etc) Среди которых x86, x86-64 (Стоит отметить, что x86-64 и x86 в последних процессорах используют микрокод и внутри них стоит RISC ядро), M68K. В чем же их отличие?
RISC
Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так). Данное направления развилось в итоге после того, как оказалось, что большинство компиляторов того времени не использовали все инструкции и разработчики процессоров решили получить больше производительности использую Конвейеры. В целом RISC является золотой серединой между всеми архитектурами.
Яркие примеры данной архитектуры: ARM, MIPS, OpenRISC, RISC-V
TTA
Что такое TTA? ТТА это Архитектура на основе всего одной инструкции перемещения из одного адреса памяти в другую. Данный вариант усложняет работу компилятора зато дает большую производительность. У данной архитектуры есть единственный недостаток: Сильная зависимость от шины данных. Именно это и стало причиной ее меньшей популярности. Надо отметить что TTA является разновидностью OISC.
Яркие примеры: MOVE Project
OISC (URISC)?
One Instruction Set Computer — Архитектура с единственной инструкцией. Например SUBLEQ. Такие архитектуры часто имеют вид: Сделать действие и в зависимости от результата сделать прыжок или продолжить исполнение. Зачастую ее реализация достаточно простая, производительность маленькая, при этом снова ограничение шиной данных.
Яркие примеры: BitBitJump, ByteByteJump, SUBLEQ тысячи их!
CISC
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию. Таким образом можно было теоретически увеличить производительность программ за счет увеличения сложности компилятора. Но по факту у CISC плохо были реализованы некоторые инструкции т.к. они редко использовались, и повышение производительности не было достигнуто. Особенностью этой группы является еще ОГРОМНАЯ Разница между архитектурами. И несмотря на названия были архитектуры с маленьким количеством инструкций.
Яркие примеры: x86, M68K
Адресация памяти
Архитектура фон Неймана

Особенностью таких архитектур была общая шина данных и инструкций. Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард. У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины. (Что ограничивает общую производительность процессора).
Архитектура гарварда

Особенность этой архитектуры является отдельная шина данных и инструкций. Дает большую производительность чем фон Нейман за счет возможности за один такт использовать обе шины (читать из шины инструкций и одновременно записывать в шинну данных), но осложняет архитектуру и имеет некоторые ограничения. В основном используется в микроконтроллерах.
Особенности процессоров
Конвейеры
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт. Это очень грубо, но при этом отображает суть. Конвейеры за счет усложнения архитектуры позволяют поднять производительность. Например конвейер позволяет прочитать инструкцию, исполнить предыдущую и записать в шину данных одновременно.

На картинке более понятно, не правда?
IF — получение инструкции,
ID — расшифровка инструкции,
EX — выполнение,
MEM — доступ к памяти,
WB — запись в регистр.
Вроде все просто? А вот и нет! Проблема в том что например прыжок (jmp/branch/etc) заставляют конвейер начать исполнение (получение след. инструкции) заново таким образом вызывая задержку в 2-4 такта перед исполнение следующей инструкции.
Расширение существующих архитектур
Достаточно популярной техникой является добавление в уже существующую архитектуру больше инструкций через расширения. Ярким примером является SSE под x86. Этим же грешит ARM и MIPS и практически все. Почему? Потому что нельзя создать унивирсальную архитектуру.
Другим вариантом является использование других архитектур для уменьшения размера инструкций.
Яркий пример: ARM со своим Thumb, MIPS с MIPS16.
Техники применяемые в GPU
В видеокартах часто встречается много ядер и из-за этой особенности появилась потребность в дополнительных решениях. Если конвейеры можно встретить даже в микроконтроллерах то решения используемых в GPU встречаются редко. Например Masked Execution (Встречается в инструкциях ARM, но не в Thumb-I/II). Еще есть другие особенность: это уклон в сторону Floating Number (Числа с плавающей запятой), Уменьшение производительности в противовес большего количества ядер и т.д.
Masked Execution
Данный режим отличается от классических тем, что инструкции исполняются последовательно без использования прыжков. В инструкции хранится некоторое количество информации о том при каких условия эта инструкция будет исполнена и если условие не соблюдено то инструкция пропускается.
Но Зачем?
Ответ прост! Что бы не нагружать шину инструкций. Например в видеокартах можно загрузить тысяче ядер одной инструкцией. А если бы использовалась система прыжков то пришлось бы для каждого ядра ждать инструкцию из медленной памяти. Кеш частично решает проблему, но все еще не решает проблему полностью.
Прочее
Здесь мы будем описывать несколько техник используемых в центральный процессорах и микроконтроллерах.
Прерывания
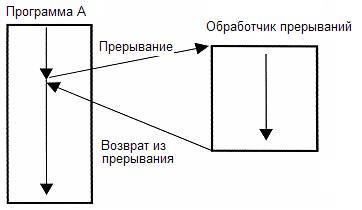
Прерывания это техника при которой исполняемый в данный момент код приостанавливается для выполнения какой-то другой задачи при каких-то условиях. Например при доступе в несуществующий участок памяти вызывается HardFault или MemoryFault прерывания или исключения. Или например если таймер отсчитал до нуля. Это позволяет не бездействовать пока нужно ждать какое-то событие.
Какие недостатки? Вызов прерывания это несколько тактов простоя и несколько при возврат из прерывания. Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
Exception (исключения)
Но кроме прерываний еще существуют исключений которые возникают например при деления на ноль. Зачастую его совмещают с прерываниями и системными вызовами, как например в MIPS. Исключения не всегда присутствуют в процессоре например как в AVR или младших PIC
Системные вызовы
Системные вызовы используется в Операционных системах для того что бы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Контроллеры доступа в память и прочие методы сдерживания программ
Здесь описываются методы запрета доступа приложений к аппаратуре напрямую.
Привилегированный режим
Это режим в котором стартует процессор. В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU. Все программы запускаются в непривилегированном режиме во избежания прямого доступа к аппаратным подсистемам программ для этого не предназначенных. Например вредоносным программам. В Windows ее часто называют Ring-0 а в *nix системным. Не стоит путать РУТ и Привилегированный режим ибо в руте вы все еще не можете иметь прямой доступ к аппаратуре (можно загрузить системный модуль который позволит это сделать, но об этом чуть позже :)
MPU и MMU
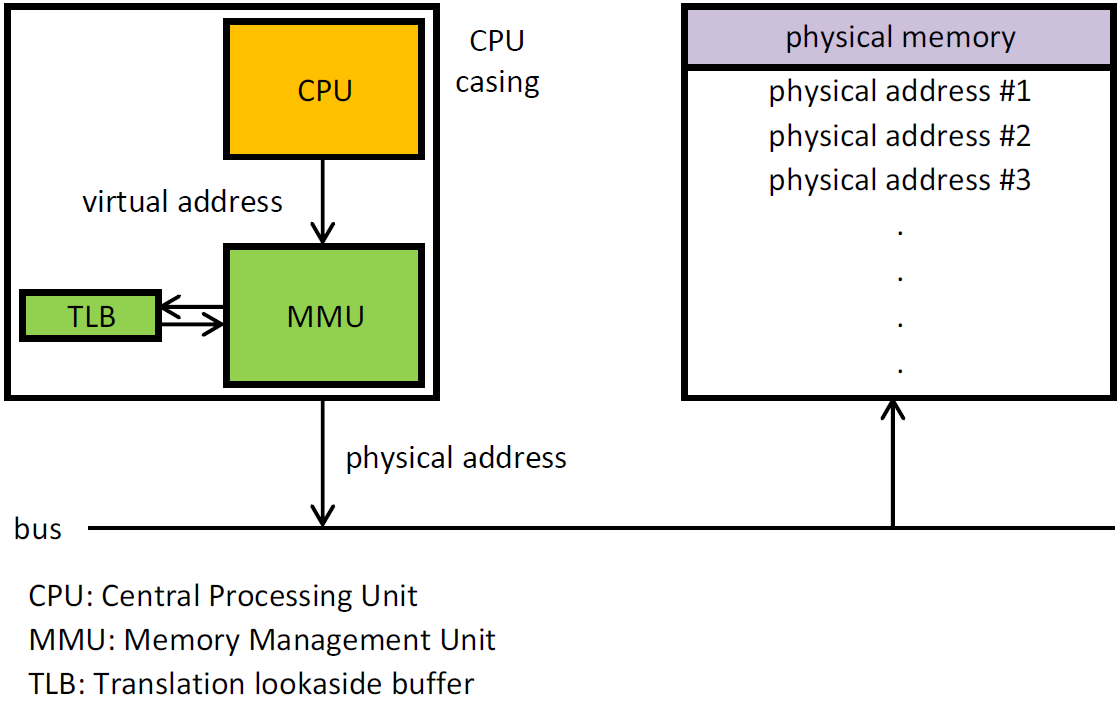
MPU и MMU используется в современных системах чтобы изолировать несколько приложений. НО если MMU позволяет "передвинуть" память то MPU позволяет только блокировать доступ к памяти/запуск кода в памяти.
PIC (PIE)
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техник благодаря которому компилятор генерирует код который будет работать в любом месте в памяти. Это техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
SIMD
Популярная техника SIMD используется для того что бы за один такт выполнять несколько действий над несколькими регистрами. Иногда бывают в качестве дополнений к основной архитектуре например как в MIPS, ARM со своими NEON/VFP/etc, x86 со своим SSE2.
Reposition for Optimization
Это техника используется для того что бы оптимизировать код который генерирует компилятор что бы увеличить производительность процессора с помощью пересортировки инструкций. Это позволяет использовать конвейер на полную.
Status register

Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution. Некоторые разработчики специально исключают регистр статуса ибо она может являться узким местом как поступили в MIPS.
mov vs $0 reg
В MIPS нет отдельной инструкции загрузки константы в память. Но есть инструкция addi и ori которая позволяет в связке с нулевым регистром ($0) эмулировать работу загрузки константы в регистр. А в других архитектурах она присутствует. Я затронул эту тему, потому что она пригодиться нам в статьях с практикой.
Rd, Rs vs Rd, rs, rt
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи. С другой стороны использования двух операндов позволяет сократить код за счет уменьшения размера инструкции. Пример совмещения является MIPS16 в MIPS и Thumb-I в ARM. В плане производительности они практически идентичны (Если исключать размер инструкции как фактор).
Endianness

Порядок байт. Возможно вам знакомы Выражения Big-Endian и Little-Endian. Они описывают порядок байт в инструкциях/в регистрах/в памяти/etc. Здесь думаю все просто :). Есть процессоры которые совмещают режимы. Как например MIPS. Или которые используют одну систему команд но имеют разный порядок байт. Как пример ARM.
Битность процессора
И так что такое битность процессора? Многие считают, что это битность шины данных. Но это не так. Почему? В ранние переоды микроконтроллеров и микропроцессоров шина могла быть например 4-х битной но передавала пакетами по 8 бит. Для программы казалось, что это 8-и битный режим, но эта была иллюзия. Как и сейчас. Например в ARM SoC-ах часто применяют 128-и битную шину данных или инструкций.
Сопроцессоры
Что такое сопроцессоры? Сопроцессоры являются элементами процессора или внешней микросхемой, который позволяют исполнять инструкции который слишком громоздки для основной части процессора. Как яркий пример сопроцессоры в MIPS для деления и умножения. Или например 387 для 80386 который добавлял поддержку чисел с плавающей запятой. А в MIPS сопроцессоров было много и они выполняли свои роли. Например были контроллерами прерываний/исключений/системных вызовов. Часто сопроцессоры имеют собственные инструкции и на системах где этих инструкций нет (Пример ARM) Эмулируют ее через Trap-ы (ловушки?). Несмотря на костыльность, и маленькую производительность они часто являются единственным выбором в микроконтроллерах.
Атомарность операций
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций который выполняют несколько действий за один Псевдо такт.
Вариант другого решения атомарность переферии. Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.
Кеш

Вы навярника слышали о L1, L2, L3 и регистрах. Если коротко процессор анализирует часть кода, что бы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти. Кеш зачастую бывает прозрачным для программы, но бывают и исключения из этого правила. Например в Программных ядрах в ПЛИС используется програмный кеш.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предустмотренна процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не остается не заметными просадки в производительности. Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
Shadow Registers
В современных процессорах часто используеться техника теневых регистров. Которые позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.
Stack

Стек? Я видел Стек в .NET и в Java! Что же. Вы частично правы. Стек существует, но он никогда не был апаратным в большинства процессорах. Например в MIPS его по просту нет. Спросите КАК ТАК ТО?! Ответ прост. Стек это просто доступ к памяти которую не нужно резервировать (очень грубое определение). Стек используется для вызова функций, передачи аргументов, сохранения регистров для того чтобы востановить их после выполнения функции и т.д.
Спросите тогда что такое хип (Heap)? Хип это память размером намного больше чем стек (Стек обычно ~1MB). В хипе храниться все глобальное. Например все указатели полученные с помощю Malloc указывают на часть хипа. А указатели хранятся в стеке или в регистрах. С помощю инструкций загрузки данных относительно регистра можно ускорить работу стека и других доступов к памяти по типу стека посколько не нужно постоянно использовать операции PUSH/POP, INC/DEC или ADDI, SUBI (добавить константу) что бы получить данные глубже по стеку, а можно просто использовать доступ относительно стека с отрицательным смещением.
Регистры

Не буду описывать регистры слишком подробно. Это мы затронем в практической статье.
В x86 регистров достаточно мало. В MIPS используется увеличенное количество регистров а именно 31 ($0 имеет значение всегда равное нулю). В процессоре университета беркли использовались регистровые окна, которые жестки ограничивали вложенность функций, при этом имели бОльшую производительности. А в других (например AVR) ограничили использование регистров (например три 16 битных, которые можно трактовать, как шесть восьми битных. первые 16, которые недоступны при некоторых операциях). Я считаю, что лучший метод был выбран MIPS-ом. Это мое сугубо личное мнение.
Выравнивание
Что такое выравнивание? Оставлю-ка я этот вопрос вам :)
Конец
Это конец первой главы нулевой части. Вся серия будет крутиться вокруг темы создания собственного процессора. Собственной операционной системы. Собственного ассемблера. Собственного компилятора и много чего другого.
Нулевые части будут посвящены теории. Я сомневаюсь что доведу всю серию до победного конца, но попытка не пытка! )
Комментарии (58)
novice2001
02.12.2016 00:23+3Кстати, тут есть и другие фактические ошибки. Например, «CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за такт». Количество действий за такт от набора команд в общем случае не зависит вообще. Оно зависит от количества и быстродействия исполнительных устройств.
В данном случае особенность CISC в увеличенном количестве действий за инструкцию (для некоторого подмножества инструкций).

frog
02.12.2016 00:28+1Про TTA наверное стоит сказать, что выполняемая операция определяется выбранным источником/приёмником данных. А то непонятно, в чём суть.
p.s. в целом как-то сумбурно и в одну кучу, IMHOArmleo
02.12.2016 06:46Про тта было сказанно мало. Согласен.
Этг именно попытка свалить в кучу. В дальнейших статьях все более подробно.
saw_tooth
02.12.2016 00:52+1Уж простите, но я с критикой
И так что такое битность процессора? Многие считают, что это битность шины данных. Но это не так.Почему?
Далее можно было не писать.Почему? Потому что следующие предложения ничего не поясняют, и я как читатель чувствую себя дибилом в кругу умных.
Например для установки ножки в STM32 в высокое и низкое состояние используется разные регистры, что позволяет иметь атомарность на уровне переферии.
Тоже самое… если начинаете говорить в лицах, то как то логичнее заканчивайте мысль:
"… используются разные регистры BSRR/BSR для атомарного, и ODR для не атомарного..."novice2001
02.12.2016 00:55+3К сожалению, это не статья уровня Хабра, а компиляция из различных источников, при этом автор сам слабо понимает о чем идет речь…
Armleo
02.12.2016 06:49Автор понимает все. Это попытка донести минимум информации о процессоре. Как я уже сказал, в дальнейшем все будет НАМНОГО подробнее.
novice2001
02.12.2016 08:27+3Нет, к сожалению именно не понимает, иначе здесь не было бы как указанных мной ошибок, так и других.
Касающихся, например, работы кэша.
«Если коротко процессор анализирует часть кода, что бы предугадать прыжки и доступ в память и зараннее просит кеш получить эти данные из памяти».
Процесссор не анализирует код, он использует информацию об уже произошедших обращениях к памяти. Это совершенно разные вещи. Тем более, что предвыборка, как таковая, для работы кэша вовсе не обязательна.
И это нельзя списать на то что «потом будет подробнее». Потому что «подробнее» и «по-другому» не одно и то же.crazyblu
02.12.2016 09:49+1Насчет кеша Вы неправы. У Вас понимание работы кеша осталось на уровне именно понимания программиста. В реализациях все немножечко по другому. Кеш имеет отдельный от ядра механизм — машину состояний грубо говоря, — но на изменение состояний этой машины воздействуют не только операции доступа к памяти.
Насчет предвыборки — в тех-же Intel с четыремя ядрами, которые Вы, как программист, видете, параллельно работает пятое ядро на предсказаниях и предвыборке, которое дает рекомендацию кешу на предпрочтение. И предсказание работает НЕ только на статистике предыдущих выборок.
Если не верите — почитайте какой-нибудь учебник по проектированию процессоров. Даже классический Харрис сойдет — его перевод кстати сейчас ДМК планируют в печатной форме выпустить…novice2001
02.12.2016 11:14+2Я не говорю о таких деталях реализации.
Суть в том, что автор не написал о том, почему кэш вообще полезен. Высокой ПСП и низкой латентности самих по себе недостаточно, нужна еще и локальность данных.
Автор пишет о предвыборке, хотя предвыборка вообще не является обязательной для кэша. И т.п.
Armleo
02.12.2016 06:51-2Я специально исключил термины и названия, что бы не путать новичков. И мне надо это исправить :). Да с "почему" бред вышел. Там предложения было сокращено и несколько абзацов исчезли. Почему должен был относиться к другому предложению.
Zenitchik
02.12.2016 10:23+1Наоборот. На правах нуба в процессорах говорю: термины нужно использовать, и пояснять их при первом появлении. Чтобы я (читатель, нуб в процессорах) сразу их запомнил и потом знал.
Armleo
02.12.2016 10:47-2Обязательно учту во второй части. Просто я редко пишу для "нубов". Только набираюсь опыта :)
Disasm
02.12.2016 01:00+2Как-то сумбурно и недостаточно широко. Если это всё, что вы знаете, то в лучшем случае вы придумаете какой-нибудь MIPS. Я бы добавил ещё как минимум про микрокод, delay slot-ы и стековые архитектуры.
И да, мне кажется, или PIC/PIE вообще никакого отношения к процессорным архитектурам не имеют?Armleo
02.12.2016 06:37-1В данном случае будут иметь. В дальнейшем при разработке процессора именно это повлияет на несколько инструкций
MacIn
02.12.2016 01:29+4Разрабатывал для диплома процессор необычной архитектуры, с микрокодом и перенастройкой. В шутку назвал его CSISC — Custom structure and Instruction Set Computer. Потому что его структура и набор инструкций недетерминированы изначально. Написать что ли статью? Правда, разработка велась не «в железо», сугубо на уровне блоков, для опробования самой идеи. Но есть транслятор микрокода, эмулятор самого процессора, демонстрационный микрокод под определенный набор инструкций и ассемблер для трансляции в этот машинный язык.

impetus
02.12.2016 17:09Да, напишите.
Когда я в своё время на дипломе предложил память и арифметику тактировать по-разному, с отсуствием ожидания готовности (синхрон, всё считано) — меня заклевали так, что пришлось почти всё переделывать… даже слова были типа «техническое хулиганство» и прочий «авантюризм» (когда получаешь недопуск к защите это, скажу я вам, оч-чень неприятно)… (просто там почти на порядок быстродействие поднять удалось на той же элементной базе по сравнению с тогдашней типовой учебной схемой, если бы вышло чуть хуже — никто б не возбудился)…
Так и создаётся впечатление, что все идеи «оттуда».

Gem
03.12.2016 10:29+1Всё новое — хорошо забытое страрое :-)
https://en.wikipedia.org/wiki/Transmeta_Crusoe
VaalKIA
03.12.2016 13:19То же можно сказать и про Эльбрус, тоже VLIW, фактически последним словом и можно ограничиться.
MacIn
03.12.2016 17:31the Crusoe runs a software abstraction layer, or a virtual machine, known as the Code Morphing Software (CMS). The CMS translates machine code instructions received from programs into native instructions for the microprocessor. In this way, the Crusoe can emulate other instruction set architectures (ISAs).
То же самое можно сказать про любую машину с микрокодом. А еще я могу вспомнить машину МИР 60х гг.


grossws
02.12.2016 03:07+2Системные вызовы используется в Операционных системах для того что бы программы могли общаться с операционной системой например просить ОС прочитать файл. Очень похоже на прерывания. Аналогично исключениям не всегда присутствуют в процессоре
Это сущность уровня ОС. Иногда в наборе инструкций есть специальный(е) опкод(ы) для большего удобства (типа svc в arm), которые порождают event и, соответственно, прерывание как реакцию на него. Но говорить, что системные вызовы есть на уровне процессора как-то странно.
В таком режиме программа или ОС имеют полный доступ к памяти в обход MMU/MPU.
Привилегированный режим не означает отключение MMU и MPU, они могут управляться в этом режиме (не всегда, иногда может производиться блокировка MPU после его конфигурации и следующий раз можно конфигурировать только после reset'а; не знаю есть ли такие режимы для MMU у кого-нибудь).
Что такое PIE? (PIC не использую для избежания путаницы с МК PIC). PIE это техник благодаря которому компилятор генерирует код который будет работать в любом месте в памяти. Это техника в совмещении с MPU позволяет компилировать высокие языки программирования которые будут работать и с MPU.
Высокие языки программирования — это хорошо, смешно. PIC, конечно, генерирует position independent code, который содержит ещё таблицы для загрузчика, чтобы можно было заставить этот код работать после расположения по определенному адресу. И эта функциональность предоставляется ОС. Что означает последняя фраза — мне неведомо, написано очень криво.
Пример совмещения является MIPS16 в MIPS и Thumb-I/II в ARM.
Вы thumb и thumb2 не путайте. Thumb2 поддерживает операции с 3 регистрами вида
ADD Rd, Rn, <operand2>иADD Rd, Rn, #<imm12>;<operand2>может содержать регистр с опциональным сдвигом на константу или другой регистр (типаADD Rd, Rn, Rm, LSL #3).Armleo
02.12.2016 06:55-1И вправду там thumb 2 откуда то взялся! Сейчас исправлю.
Armleo
02.12.2016 07:24-1И ошибка в PIE получилась смешная.
Кажеться вы пропустили часть чуть выше. Я чуть выше описал, что оно не всегда присутсвует.Armleo
02.12.2016 08:02-1U, the 'User/Supervisor' bit, controls access to the page based on privilege level. If the bit is set, then the page may be accessed by all; if the bit is not set, however, only the supervisor can access it. For a page directory entry, the user bit controls access to all the pages referenced by the page directory entry. Therefore if you wish to make a page a user page, you must set the user bit in the relevant page directory entry as well as the page table entry.
Из http://wiki.osdev.org/Paging.
Я имел ввиду, что можно обойти MPU и использовать память предназначенную только для супервизора.

Alex_GDI
02.12.2016 07:38+1Так и не понял что там с «разрядностью процессора», всегда считал что это размер регистра общего назначения. Поправьте. И конечно продолжайте интересно!
VaalKIA
02.12.2016 08:04+2Почему? Потому что нельзя создать унивирсальную архитектуру.
Как раз на возможности создать универсальную архитектуру базируется всё ИТ, если Тьюринг вам о чём-то говорит. Возможно имелась ввиду оптимальность?VaalKIA
02.12.2016 08:25+2Хотел написать ещё кучу комментариев, например про то, что упомниается гарвардская архитектура и кеш, но никаких параллелей не проводится, хотя в современных архитектурах кеш имеет несколько уровней именно потому что один из уровней это кеш данных и кеш инструкций — отдельно. Пишется про endian, но ничего не говорится про то как это влияет на вычисления, упоминается атомарность, но нет никаого контекста с многоядерностью и общим доступом к одним и тем же данным и соотвествующие инструкции (там их 4 всего можо привести), есть про битность, но нет про аккумуляторы и адресацию, в принципе, про SIMD с одним тактом вообще убило. Я бы характеризовал как: статья обо всём и — ни о чём. Скорее это черновик «о чём бы я сам хотел узнать и разобраться»
Armleo
02.12.2016 09:16-2Да говорит :) Подразумевалась архитектура, которая будет решать все задачи. Нельзя создать процессор, который будет маленьким и поддерживать много операций. Нельзя создать процессор, который будет дешевым и будет функциональным. Итд.
Кеш и Гарвард связанны, но когда мы будем создавать свой процесор кеша не будет. Поэтому здесь много моментов пропущенно.
Про многоядерность будет во второй части.
Акумуляторы в современных процессорах не используеться.
Скорее "Чтобы я хотел, чтобы читающий знал до перехода к практике".
Спасибо за замечания!
aso
02.12.2016 08:26+3Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций
Штоэээа?
Аразве не архитектура с «упрощённым набором инструкций» (буквально)?
CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за такт.
Штоэээа?
Прям таки «за такт», а не за машинный цикл?
И вообще, разве это не подразумевает «сложные инструкции», с «богатой семантикой»?
Архитектура фон Неймана
[...]
Особенностью таких архитектур была общая шина данных и инструкций
Штоэаа?
Фон Нейман — это архитектура с общей памятью программ и данных.
К «общей шине» она не имеет непосредственного отношения.
Большинство современных архитектур это программный фон Нейман, однако никто не запрещает делать аппаратный Гарвард.
Обожемой…
Архитектура гарварда
Harvard
Особенность этой архитектуры является отдельная шина данных и инструкций.
Гарвардская архитектура имеет раздельную память программ и данных.
Легче реализуется.
Микропрограммные устройства практически автоматом реализуются в гарвардсткой архитектуре.
Может эмулировать архитектуру фон Неймана — изображая из себя «микроядро» и реализуя его функциональность при соотв. аппаратной поддержке.
Что такое конвейеры? Если сказать очень глупым языком это несколько параллельных действий за один такт.
Удивительно, но это так.
Хотя стоит отметить, что при конвейеризации параллельно исполняются отдельные этапы исполнения команды — т.е. когда цикла исполнения команды (машинный цикл) состоит из нескольких тактов — в каждом из них одновременно выполняются разные этапы разных (последовательно расположенных) команд.
Что такое регистр статуса? Это регистр который хранит состояние процессора. Например находится ли процессор в привилегированном режиме, чем закончилась операция последнего сравнения.
Используется в связке с Masked Execution.
Ойфто? 0_0
Идут множество споров насчет того сколько должно быть операндов в арифметических инструкциях. Например в MIPS используется вариант с 3-мя регистрами. 2 операнда, 1 регистр записи.
Это, вообще говоря, следует отнести к архитектурным особенностям.
Возможна трёхадресная, двухадресная, одноадресная и безадресная системы команд.
Трёхадресная: A < — B * C, результат операции "*" между B и C помещается в регистр A, все регистры произвольно адресуемые.
Двухадресная: B < — B * C.
Одноадресная: A < — A* C, здесь A — фиксированный регистр-аккумулятор. Обычно мнемоника либо включает его, либо подразумевается — MOVA, к примеру. Возмодны одноадресные команду «просто» — инверсия операнда, к примеру.
Безадресная — операции на стеке с помещением результата в него же.
Фон Неймановская архитектура обычно реализует двухадресную или одноадресную (с аккумулятором) систему команд, Гарвардская — может иметь трёхадресную.
И так что такое битность процессора? Многие считают, что это битность шины данных. Но это не так. Почему? В ранние переоды микроконтроллеров и микропроцессоров шина могла быть например 4-х битной но передавала пакетами по 8 бит.
Внезапно!
Первый Пентиум имел 64-битную шину данных, но 32-битное АЛУ.
В общем, с этим всё непросто — хотя чаще битность считают по АЛУ.
Атомартность операций обеспечивает потоко-независимое исполнение за счет инструкций который выполняют несколько действий за один Псевдо такт.
Атомарность — это непрерываемость исполнения.
Например, инструкция практически всегда является атомарной, бо не может быть прервана «на половине» прерыванием.
И вы кончено слышали о такой вещи, как Cache Miss или промах по кешу. Это операция которая не была предустмотренна процессорам или процессор не успел закешировать эту часть памяти. Что достаточно часто является проблемой замедления доступа к памяти. Промах проходит незаметно для программы, но не остается не заметными просадки в производительности. Так же переключения контекстов например при прерываниях тоже заставляет страдать кеш ибо небольшой код сбивает конвейер и кеш для собственных нужд.
Shadow Registers
В современных процессорах часто используеться техника теневых регистров. Которые позволяют переключаться между прерываниями и пользовательским кодом практически без задержек связанных с сохранением регистров.
Стек? Я видел Стек в .NET и в Java! Что же. Вы частично правы. Стек существует, но он никогда не был апаратным в большинства процессорах.
М-ммм.
Что имеется в виду?
Отдельная память для стека — иле отсутствие специализированных инструкций (push/pop/call/ret) — работающих в связке со специализированным регистром-указателем стека SP?
Например в MIPS его по просту нет. Спросите КАК ТАК ТО?! Ответ прост.
«It's a BAD».
Например в действительно древних УС-ках стека тоже не было — и это не есть гуд.
Конец
Низачод.
Будь я Вашим преподом в СШ — именно такую оценку я бы Вам выставил.
Не раскрыты темы микропрограмм, АЛУ, DSP — а в остальном чрезвычайно много э-ээ, неверного.
Низачод.Armleo
02.12.2016 08:56-2- RISC прочитайте мой коментарий чуть выше
- CISC слегка подредактировал.
- Вы правы. Какой-то бред в итоге получился. Хотел укоротить, вынес вперед ногами весь смысл.
- Согласен здесь все не просто. Надо было мне больша букАв про битность. А то получилось просто небольшое опровержение мифа.
- Не много не понял.
- Shadow registers и кеш. Не вижу вашего текста.
- Отсутсвие инструкций. Здесь стоит не согласится. Я считаю, что инструкции PUSH и POP не нужны. Посмотрите на код генерируемый GCC он использует указатель стека для локальных переменных используя инструкции ld и st относительно указателя стека в MIPS. Я считаю MIPS эталоном RISC ядер. Хотя это сугубо личное мнение.
- Прочитайте текст далее. Конец ПЕРВОЙ главы нулевой части. Это не конец. Это начало (хоть и не удачное). И судить ПОКА о всей серии рано.
grossws
02.12.2016 13:13Гарвардская архитектура имеет раздельную память программ и данных.
Легче реализуется.
Микропрограммные устройства практически автоматом реализуются в гарвардсткой архитектуре.
Может эмулировать архитектуру фон Неймана — изображая из себя «микроядро» и реализуя его функциональность при соотв. аппаратной поддержке.Сейчас вообще в микроконтроллерах часто применяется modified harvard, о которой автор вообще не упомянул. И modified harvard, например, позволяет читать данные из instruction memory и наоборот. Плюс часто реально используется общая память, которая разделяется на уровне i- и d-cache или соответствующих шин.
maxlilt
02.12.2016 09:29Правильно я понимаю, что проект Мультиклет относится к transport triggered architecture(TTA)?

AnROm
02.12.2016 10:51+3Видимо статья писалась на скорую руку, Вы даже решили не париться по поводу грамматики. Сначала хотелось написать лично, но в публикации их более десятка
GarryC
02.12.2016 13:32+2Стек существует, но он никогда не был апаратным в большинства процессорах. Например в MIPS его по просту нет. Стек это просто доступ к памяти которую не нужно резервировать (очень грубое определение). Стек используется для вызова функций, передачи аргументов, сохранения регистров для того чтобы востановить их после выполнения функции и т.д.
Ну если Вы знаете, как обрабатывать прерывания без аппаратного стека возвратов, то с нетерпением жду следующую статью.
И Вы таки правы, Ваше определение стека очень грубое и, по моему мнению, настолько грубое, что даже и неверное.
shooter9688
02.12.2016 14:30Стек? Я видел Стек в .NET и в Java! Что же. Вы частично правы. Стек существует, но он никогда не был апаратным в большинства процессорах. Например в MIPS его по просту нет. Спросите КАК ТАК ТО?! Ответ прост. Стек это просто доступ к памяти которую не нужно резервировать (очень грубое определение). Стек используется для вызова функций, передачи аргументов, сохранения регистров для того чтобы востановить их после выполнения функции и т.д.
Если она аппаратно не реализуется тогда его нужно реализовать явно для обработки(возврата к инструкциям до вызова и возврата состояния регистров) функций и прерываний?


unixwz
02.12.2016 21:42Хорошая статья, жду продолжения. Как раз тоже решил попробовать реализовать свой процессор на базе ПЛИС.
Armleo
03.12.2016 10:36-1Здесь мы будем затрагивать ПЛИС. Но пока рано :)
Небольшая статья, которая мне помогла https://embeddedmicro.com/tutorials/lucid/basic-cpu

netch80
03.12.2016 14:27+5Сначала общее впечатление от статьи: непонятно, зачем она в таком виде. Кто с этой тематикой не знаком в принципе — ничего в описанном не поймёт. Кто знаком — будет активно возражать. Большинство упомянутых утверждений следовало бы вводить постепенно, по ходу. Кстати, в этом случае и контекст помогал бы их правильно и уместно сформулировать именно для своей цели.
> недостатком является большое зависимости производительности процессора от шины
В статье очень много таких странных грамматических несогласований, и орфографических ошибок («она пригодиться нам в статьях с практикой.»). А тут вообще непонятно, что имелось в виду:
> Так же несколько инструкций в начале кода будет занято инструкциями для Таблицы прерываний.
«Инструкции для таблицы прерываний» это вектора прерываний, что ли? Тогда они обычно не инструкции, если не применён стиль i8080. Если же данный стиль — то лучше было описать в статье с реализацией прерываний.
Рекомендую тщательно вычитать и исправить.
По отдельным пунктам:
> CISC — Complex Instruction Set Computer — ее особенность в увеличенных количествах действий за инструкцию.
Основные признаки CISC:
1. Ориентация на написание ассемблерного кода человеком, или компилятором, транслирующим типичные операции ЯВУ дословно, без их переработки. Во времена слабых компиляторов (считаем, до середины 80-х) это неизбежно.
2. Как следствие (1) — стремление к ортогональности операций и адресации операндов, и предоставление средств для идиоматических действий типа «доступ по адресу, снимаемому с вершины стека».
3. Экономия памяти под инструкции. Этот признак не имеет причиной концепцию CISC, но современен ему (основные разработки шли в условиях дорогой, но быстрой памяти, сравнимо со скоростью процессора). Отсюда — обязательность разной длины инструкций.
Яркие примеры — PDP-11, VAX, M68K. Упоминать здесь x86 не совсем адекватно. У x86, например, у основного блока команд допускается не более одного операнда в памяти (исключения вроде MOVS крайне редки). В этом смысле, x86 — полу-RISC. Ещё жёстче это, например, в линии S/360...z/Arch в блоке RX-команд — в памяти только второй источник, но не первый источник, он же приёмник.
Просто о количествах действий тут говорить нельзя. Например, можно увеличить указатель стека, сняв один из операндов со стека, но не делают инструкции, в которых увеличивается указатель стека, когда стек вообще не участвует. Линия с явным заданием нескольких одновременных действий это EPIC (многими считается как вариант VLIW), но это другая линия.
> Reduced Instruction Set Computer — Архитектура с уменьшенным временем выполнения инструкций (из расшифровка RISC можно подумать, что это уменьшенное количество инструкций, но это не так)
Не так, но и не по-вашему. RISC это уменьшенная сложность одной инструкции. А по второй расшифровке — Rational Instruction Set Computer — оптимизация построения на типичные применения с отбрасыванием лишнего, и на современные компиляторы с их логикой работы.
Время выполнения одной инструкции может быть в типичном случае даже выше, за счёт подъёма всех до 4-5 тактов, но это компенсируется простотой построения параллельного исполнения.
> Архитектура фон Неймана
Есть и другой метод называния — принстонская архитектура (а фон Неймана — общее у принстонской и гарвардской).
> У данной архитектуры большим недостатком является большое зависимости производительности процессора от шины.
Это существенно только для реализаций, исполняющих всю команду за один такт. Такие используются, да, в очень «мелких» реализациях, но как только мы выходим за пределы встраивания процессора в двухкопеечную монету, общая шина к памяти перестаёт быть узким местом. На нынешнем x86 она не является таковым. На мелких RISC конфликты доступа за память только немного притормаживают конвейер.
> В x86 регистров достаточно мало.
Было мало. В современных имеем, даже считая 32-битку,
1) 8 основных (eax, ebx, ecx, edx, esp, ebp, esi, edi)
2) 8 FP или MM
3) 8 XMM/YMM/ZMM
4) 8 предикатных (K0-K7) (AVX512)
и значительную часть целочисленных операций можно использовать на них всех, и тем более эти регистры можно применять для временного сохранения значений без доступа к памяти.
В 64 битах добавляется ещё 8 основных и 8 XMM/YMM/ZMM. Это уже больше, чем 32.
Пока остановился. Ещё раз сводное — в таком виде статья просто бесполезна. Лучше всё описанное вводить постепенно, и на реальных примерах. Потом, после всего цикла, уже можно сделать что-то похожее на эту статью в качестве резюме, но тогда и формулировки каждого пункта будут совсем другими.
novice2001
Простите, а кто-нибудь еще разделяет вашу точку зрения о том, что, вопреки своему названию, RISC — это «Архитектура с уменьшенным временем выполнения инструкций»?
Armleo
Да.
https://ru.m.wikipedia.org/wiki/RISC
novice2001
Здесь проблема в том, что для успешного натягивания совы на глобус сравниваются некоторые современные RISC-архитектуры с некоторыми устаревшими CISC. Либо современные полноценные RISC-процессоры с CISC-микроконтроллерами. Если сравнить процессоры одного класса, то набор команд CISC будет гораздо более сложным (complex), чем у любого сравнимого RISC. Как мининмум за счет разнообразных вариантов работы с регистрами и памятью.
При этом время выполнения одинаковых команд на процессорах RISC и CISC принципиально не отличается. Т.е. если взять подмножество команд CISC, соответствующих командам RISC, то получится, что это практически одно и то же. Только в CISC есть другое, непересекающееся с RISC подмножество команд. Именно этим они и отличаются — набором команд, а не временем их исполнения.
DrPass
Вообще, это условность. Главное различие между RISC и CISC-процессорами состоит в том, что первые работают только с регистровыми операндами, а пересылка данных между регистрами и памятью осуществляется отдельными инструкциями, а вторые включают в свой набор инструкций комплексные команды с возможностью брать/сохранять операнды в память.
novice2001
В итоге у RISC все равно получается сокращенный набор команд, а у CISC — сложный.
frog
Названия остались исторически, когда действительно в RISC'ах было немного инструкций. С тех пор уже всё изменилось. Сейчас сравнивать их по количеству инструкций как-то странно — не в этом суть.
Просто разная идеология.
DrPass
Я бы так не утверждал. Если взять современный CISC x86-64, вы там найдете примерно пять сотен команд, это включая все MMX, SSE и прочие расширения. Если возьмете современный RISC ARMv8, там будет вполне сравнимый набор инструкций, сотни четыре. Включая всяких монстриков, обрабатывающих SIMD-данные за кучу тактов, или считающих CRC32-код. Так что по набору и составу команд они уже не особо отличаются.
MacIn
Интересно. В таком случае, он, возможно, должен быть отнесен к CISC? Просто по факту.
DrPass
Несмотря на всё это, классическое свойство RISC-процессоров «команды пересылки данных из памяти/в память отделены от команд обработки данных» в ARM честно соблюдается.
MacIn
Да, но если мы возьмем старичка 8080, который относится к CISC, то он имеет, если я правильно понимаю, такое же разделение.
DrPass
Неа, там, несмотря на простоту процессора, всё по-честному. Вы можете сделать, например
ADD A, M, и процессор вам сам затянет операнд из указанной в регистрах H и L ячейки памяти. Там нельзя указать адрес непосредственным операндом команды, но по косвенной адресации все инструкции процессора умеют тянуть данные прямо из памяти.MacIn
А, ясно. Спасибо.
LAutour
тут надо еще учесть методы адресации — в одних архитектурах они часть команды, в других они распределены по отдельным командам. И-за этого в первом случае их получается заметно меньше, хотя число вариаций команд с учетом адресаций получается схожим.
x86128
Необходимо иметь ввиду, что если рассматривать процессоры в контексте решаемой задачи из «реального мира», а не с точки зрения «сложить два числа», то RISC потребует большего числа инструкций для решения такой задачи в общем случае, а значит будет больше доступов к внешней памяти, следовательного и времени исполнения программы. Также возрастает и объем кода.
DrPass
А там есть и обратная сторона медали. Более компактные команды RISC, в которых нет суффиксов режимов доступа к данным, занимают меньший объем в памяти. Поэтому по размеру кода есть некий паритет.