
Какими программами постоянно пользуются люди? Если подумать над этим вопросом, то окажется, что список этот не такой уж большой. К постоянно используемым программам можно отнести: саму операционную систему, файловый менеджер, текстовый редактор, браузер, мессенджер. Это именно тот базовый набор, которым пользуется на компьютере практически каждый человек. Требования к таким программам должны быть высокими: безотказная работа, быстрое выполнение всех функций, понятный и удобный интерфейс.
Можно сказать, что вышеперечисленный набор программ — это самые нужные программы, которыми пользуется человек в цифровую эпоху. Этот список покрывает все базовые потребности человека-пользователя. Или не все? Есть ли еще одна базовая потребность, которая не учтена в вышеприведенном списке самых необходимых программ? Является ли эта потребность самой важной из тех, что должен автоматизировать компьютер? Для меня такая потребность есть, но в списке самых используемых программ ей места не нашлось. Что же это за потребность?
Историческая ретроспектива
Ранее компьютер считался устройством для проведения вычислений. Даже бытовые старые компьютеры ориентировались на очень продвинутого пользователя, который использовал компьютер для вычислений путем написания собственных небольших программ. Для полноценной работы с компьютером, пользователь должен был знать язык программирования. Дальнейший взлет более продвинутых компьютерных платформ произошел во многом благодаря появлению первых вариантов электронных таблиц, которые тоже были нацелены на вычисления, но снижали требования к пользователю, не заставляя его быть программистом. В любом случае, это был период, когда назначение компьютера напрямую соответствовало его названию. Сам вычислительный модуль — процессор — ставился во главу угла, ведь именно появление микропроцессора сделало возможным появление самого компьютера.
Однако, последующее развитие не зациклилось на улучшении характеристик процессоров. Развивались все компоненты компьютера, и, в частности, память. Память оперативная, и память постоянная. В тот момент, когда стало ясно, что компьютер способен хранить и быстро доставать невиданные объемы данных, появилась возможность реализовать на компьютере другую давнишнюю мечту человека: накопление и быстрое извлечение данных. Сделать как бы безграничную память, некоторое место, в которое можно положить информацию, а потом быстро ее найти и извлечь. Так стали развиваться базы данных и языки запросов.
Постепенно появилась самая большая в мире база данных — Интернет, со всеми его миллиардами сайтов: википедиями, библиотеками, форумами и соцсетями. Инструменты поиска кардинально поменялись, а обычный пользователь даже не может иметь личный поисковик в Интернете — это практически невозможно, да и не нужно.
Много ролей примерил на себя компьютер за все годы развития ИТ. Компьютер — это очень универсальная вещь, а цифровая вселенная способна вместить в себя все проявления человеческой фантазии. И хорошо, что к настоящему времени сформировался тот необходимый минимум программ, который демонстрирует эволюционный путь, который прошло человечество в своих потребностях в цифровую эпоху. Потребности эти, честно говоря, сильно сдвинуты в область потребления и передачи контента. Не сказать что это плохо, но…
За всем этим буйством технологий немного в сторону отошла одна очень важная мечта многих людей с древности и до наших дней, которая хорошо реализуется в форме персонального компьютера. Эта мечта — заполучить персонального интеллектуального помощника с бесконечной памятью, который бы помогал человеку если не мыслить, то вспоминать и находить те знания (а не данные!), которые человек уже успел осмыслить, или хотя бы бегло видел краем глаза, или знал, что нечто нужное есть в некоторой библиотеке. Одно это помогло бы вывести развитие человека на новый качественный уровень. Возможно, древние греки могли сказать, что надо развивать собственный мозг (когда развивалась письменность, многие греки демонстрировали чудеса цитирования по памяти, пренебрегая записями). Однако прошло много времени, мир изменился, и сейчас наша цивилизация уперлась в ограничение: в наше время человеческий мозг не справляется с тем объемом информации, который требуется знать и помнить. Информации стало слишком много. И это случилось не сегодня, а в момент победного шествия научно-технической революции.
История знает как минимум один концептуальный проект, в котором впервые была предпринята попытка решить вышеозначенную проблему на новом технологическом уровне. Американский инженер-разработчик аналоговых компьютеров Вэнивар Буш предложил отойти от тетрадей с записями, картотек, библиотек, и толпы личных секретарей к устройству, которое бы все это смогло заменить. Он предложил в 40-х годах прошлого века концепцию устройства MEMEX. Вот как оно описывается:
… электромеханическое устройство, позволяющее создать автономную базу знаний, снабжённую ассоциативными ссылками и примечаниями, которые могут быть в любое время переданы в другие такие же базы знаний. Это устройство должно было максимально точно имитировать ассоциативные процессы человеческого мышления, при отсутствии недостатков, таких как «забывание» информации.
Описание этого устройства в конечном счете косвенно повлияло на появление гипертекстовой разметки HTML, но нас сейчас интересует именно класс программ, которые в каком-то виде реализовали бы идею этого концепта. Следует обратить внимание на слова «автономная база знаний» — они для нас являются ключевыми. Есть ли программы, попадающие под такое определение? Конечно есть! Это менеджеры персональной информации (PIM), mind-map решения, некоторые органайзеры и их различные гибриды.
Поиск идеального помощника
Особенность выбора идеального персонального помощника состоит в том, что такая программа выбирается на десятилетия. А это требование налагает большие ограничения на возможных кандидатов.
В силу моих убеждений, при поиске подходящей программы я ориентировался в первую очередь на кроссплатформенность и открытость кода. Первое требование — кроссплатформенность — связана с тем, что на домашних компьютерах я использую Linux, а на работе мне предписано использовать Windows, и на какой платформе мне придется работать завтра — я точно не знаю. Но знаю точно, что на каждой платформе мне нужен один и тот же помощник. Открытость кода связана со многими факторами, но самый главный — это безопасность во времени и в пространстве кода. Безопасность во времени — это твердая уверенность, что завтра автор проприетарной программы не закроет свой проект или не поднимет цену лицензии. Безопасность в пространстве кода — это уверенность, что программа не сольет хранимые личные данные в места, где этим данным делать нечего.
Конечно, существенным фактором является и открытость формата хранимых данных. Ничто не должно мешать «бегству с формата», если по каким-то причинам изначальный выбор помощника был неудачным. Очень было бы неприятно расстаться с накопленной базой знаний просто потому, что она хранится в закрытом проприетарном формате.
Примечание: почему я использую термин «база знаний» а не «база данных»? Потому что хотелось бы накапливать именно знания, а не данные. Вопрос в том, каков механизм превращения данных в знания. В общем случае можно сказать, что данные превращаются в знания после их осмысления человеком. Именно после этого мыслительного процесса человек, глядя на знакомые записи (данные) может использовать их в качестве знаний.
Как выяснилось, программ, удовлетворяющих вышеозначенным критериям, не так уж много. И я даже поначалу сильно снизил планку требований, сказав себе, что в крайнем случае есть Wine, да и чего пугаться закрытых форматов — другие же пользуются. И я перебрал большое количество проектов, чтобы понять, что же мне таки лучше всего подойдет.
Из проприетарных продуктов я пересмотрел линейные и древовидные PIM-менеджеры, попробовал mind-map решения, пощупал возможность вести записи в органайзерах. Ничего из испробованного мне не подошло: всегда был какой-нибудь неприятный изъян, который останавливал меня в дальнейшем использовании продукта. Хороший редактор текста, но линейность записей вместо древовидности. Наличие древовидности, но ужасный редактор. Попытки сделать ограниченный набор типов записей, не описывающий все многообразие возможных ситуаций. Невозможность получать данные от офисных программ или из окна браузера. Падения в течении пяти минут при элементарных действиях. Непродуманный интерфейс, сильное загромождение рабочей области, налезание элементов друг на друга в русифицированных версиях. Возможно, что сейчас дела обстоят лучше, но восемь лет назад я ужаснулся тому, что предлагают людям купить за деньги. По сути, из всего зоопарка более-менее доделанными оказался Microsoft OneNote и какой-то китайский комбаин с кучей функций и кнопочек, которые, на удивление, все работали (возможно это был TreeDBNotes). Но видя, каким деструктивным маркетингом занимается Микрософт, связываться с OneNote я не стал. А китайский комбаин на тот момент я не мог приобрести потому, что оплата шла то ли валютной банковской картой, то ли через PayPal, а у меня ни того ни другого не было. Пиратить же я принципиально не собирался.
В стане свободного программного обеспечения я потрогал CherryTree, Zim, KOrganizer, KeepNote, даже пробовал использовать Eclipse в отдельной директории, создав дерево поддиректорий и открывая в нем текстовые и HTML файлы. Проблемы оказались те же самые: крупные и мелкие недоработки, мешающие полноценно пользоваться программой, либо большие неудобства вместо работы как в случае с Eclipse (не предназначен он для таких вещей, да и сильно тормозит, ибо Java). Даже более-менее приличная CherryTree, например, не могла свернуться в систрей при клике по крестику в заголовке окна: она просто завершала работу. Под Linux я как-то проблему решил, а в Windows она оказалась нерешаема. В свое время я отказался от WinAmp, когда он вдруг разучился сворачиваться и продолжать работать при клике на крестик. Ведь личный помощник — это такая вещь, которая всегда должна быть под рукой, и не должно быть опасений, что он закроется при естественных элементарных действиях.
Кстати, о древовидности. Человеческий мозг привык все классифицировать. В этом его сила. Например, такая сложная вещь как классификация живых существ от Аристотеля и Теофраста до Роберта Гука и Карла Линнея и до наших дней имеет древовидную структуру. И хоть по современным представлениям, происхождение видов является, больше не деревом а графом, а электронные энциклопедии при структуризации информации вообще исключают древовидность, что вместе косвенно говорит о том, что дерево непригодно для описания всех возможных группировок данных, я все же считаю, что дерево — это тот удобный компромисс между простотой линейностью (как в первых версиях Evernote) и сложностью графа (как в Википедии). Как минимум, при построении дерева всегда можно выделить один условно главный признак, по которому можно производить группировку информации. Зато наличие дерева дает ту опору, благодаря которой можно искать информацию «по логике вещей», если таковая логика прослеживается.
Дерево имеет много других полезных свойств: вырастание вверх без существенного утолщения, иерархичность, наглядность. Из дерева легко можно сделать граф: достаточно просто добавить связи между ветками.
Создание идеального помощника
В общем, я очутился в классической ситуации: хочешь получить что-то хорошее — сделай это сам. В тот момент я присматривался к плюсовому фреймверку Qt, который вышел в своей 4-й версии. И я решил, что нет ничего лучше, чем сделать свой собственный менеджер, который бы удовлетворял меня в меру моих собственных способностей. Даже если проект «не пойдет», я, как минимум, смогу на практике изучить перспективный кроссплатформенный фреймверк.
Я прочитал пару книжек, засел за программирование, и сделал первую минимальную версию программы. Я назвал её MyTetra. Выглядела она вот так:
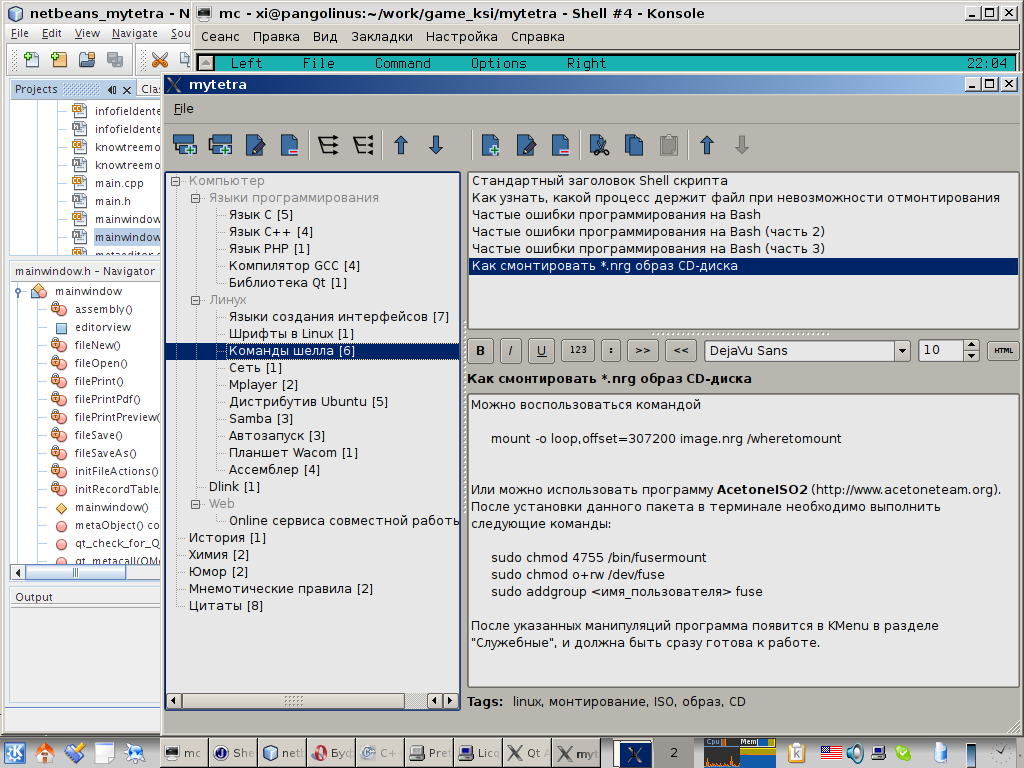
Изначально я точил те мелочи, которых мне не хватало в других менеджерах: нормальное сворачивание в трей, разделение дерева на сущности «ветка» и «запись», подсчет количества записей в ветках, копипаст записей через буфер обмена. В первой версии даже не было поиска, но я начал наполнять базу своими записями, чтобы прочувствовать, можно ли удержать информацию в дереве, не уткнусь ли я в то, что мне потребуются различные «срезы» дерева (в необходимости автоматически реконфигурируемого дерева меня страстно убеждал один товарищ), возникнет ли необходимость группировки по разным признакам. И быстро понял, что дерево свою функцию «базиса» хорошо выполняет, особенно, если ты сам вырастил это дерево.
Формат хранения данных я изначально делал в «естественном» виде, и никаких собственных бинарных форматов использовать не собирался. Так же отказался от хранения данных в БД. Все форматы открытые: дерево хранится в XML-файле, форматированный текст — в HTML, картинки в PNG, настройки в INI. Изначально структура проектировалась так, чтобы данные были аккуратно разложены по файлам, и поддавались дифференциальной синхронизации через системы контроля версий. Имена хранимых файлов и директорий сделаны платформонезависимыми: все-таки кроссплатформенная программа должна работать на любой современной платформе без переделок и побочных эффектов. Всё это элементарные вещи, но оказывается, разработчики похожих программ не всегда их понимают: например автор OutWiker позволяет давать каталогам русскоязычные названия — то есть, использует в качестве имени каталога на диске имя ветки, причем со знаками препинания, что меня в свое время сильно потрясло: программа на Питоне заявлялась как кроссплатформенная, но при синхронизации данных с разных платформ такое решение обязательно бы вызвало проблемы.
Для сущностей «ветка» и «запись» я определил основные действия, которые с ними можно выполнять: создание, редактирование, копирование, вставка, перемещение, удаление. И когда этот минимум полностью заработал и появился поиск, я немного причесал код и выпустил первую публичную версию.
Что я записывал в свою программу? Первым делом я стал записывать такие сведения, которые все время забывал, и найти которые в простом виде очень трудно. Есть такие вещи, за которыми постоянно лезешь в свои записульки. Например, в Linux man-страницы традиционно пишутся в форме «минимально необходимого и достаточного», поэтому, быстро понять опции командной строки какой-нибудь программы очень сложно. К примеру, опции упаковки tar.gz архива: четыре плохо произносимые буквы, которые вечно забываешь.
Так же стал подробно записывать действия, которые произвожу при настройке какого-нибудь линухового софта. Часто в Linux сложно не только настроить программу, а сложно ее установить, не говоря уже о запустить. И чтобы программа завелась, надо сделать не пять и не пятнадцать неочевидных действий, а гораздо больше. К концу, если что-то получилось, человек уже не помнит точно, что он делал в начале. А если записывал — то такой проблемы нет.
Еще я себе записывал действительно хорошие материалы из Интернет или «выжимки», которые делал на их основе. Бывает так, что долго не можешь разобраться в каком-либо вопросе. И вдруг натыкаешься на текст, в котором все подробно, легко и просто объясняется. Жалко такой текст потерять: он может исчезнуть из интернета, о нем можно просто, заработавшись, забыть. Но если скинуть его в свою базу знаний, то можно испытать чувство успокоения, что эти важные сведения никуда не денутся, и останутся с вами. Честно говоря, я не понимаю людей, которые делают закладки в браузере: неприятно делать закладки и знать, что в какой-то момент информация может исчезнуть. Несколько раз меня моя предусмотрительность выручала: интересный материал исчезал из интернета, зато оставался в моей базе.
И конечно, я записывал всю возможную информацию по своим бытовым электронным устройствам, пароли входа в админки и прочие интернет-сервиса, телефоны и адреса всяких организаций и знакомых, прочую мелочевку, которая очень важна, но сложно запомнить.
Постепенно база росла, а программа видоизменялась. В настоящий момент она выглядит вот так (кстати, это скриншот из Linux, а не Windows):
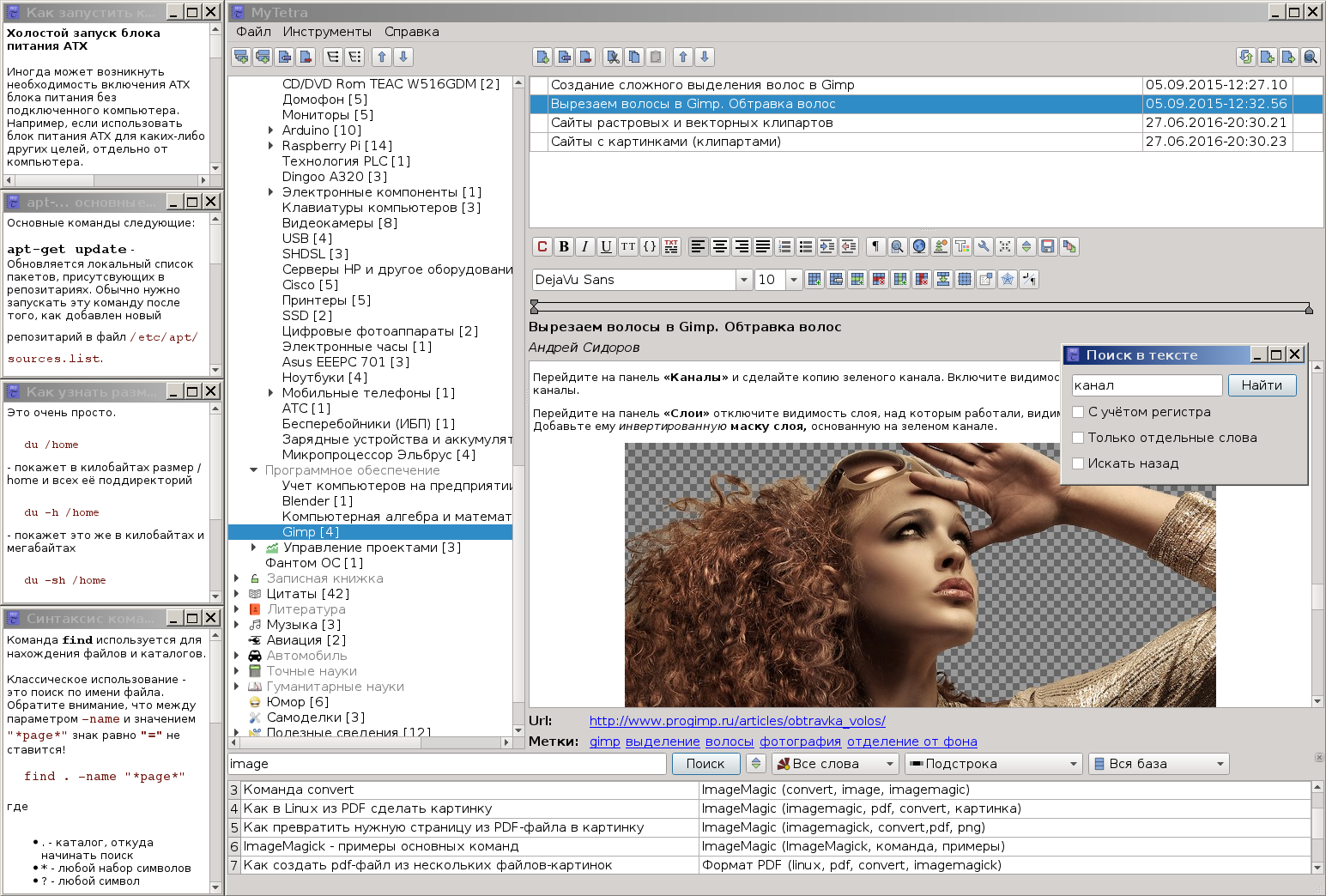
Да, учитывая, что сейчас легко доступны хостинги распределенных систем контроля версий, такие как GitHub и BitBucket, а так же облачные хранилища типа DropBox или Яндекс.Диск, грех бы было ими не воспользоваться для бесплатного хранения в них своих баз знаний. Заодно решался вопрос бекапа и синхронизации. Возникала только одна проблема: хранение приватных данных. В открытом виде их нельзя загружать на хостинг. Поэтому была разработана небольшая криптографическая библиотека, и на ее основе сделано шифрование выбранных веток. То есть, появилась возможность безопасного хранения приватных данных у всех на виду. Почему была сделана библиотека, а не использована существующая? Потому что менеджер позиционируется как Qt-only. Он должен легко собираться командами qmake & make на любой платформе, где есть только Qt, и никаких дополнительных библиотек не требовать. Такой принцип позволяет легко получать сборки для всех популярных платформ: Linux, Windows, MacOs, FreeBSD, Android, и даже под такую экзотику как MeeGo. Впрочем, в формате шифрования предусмотрено версионирование, и, возможно, я когда-нибудь прикручу OpenSSL, когда разберусь как ее включать в проект для всех вышеперечисленных платформ.
Помимо шифрования, в программе была реализована настраиваемая синхронизация, навигация по истории, встроенный довнлоадер, прикрепляемые файлы, сортируемый список записей и много еще чего нужного. Спустя пять лет открытой разработки, получился PIM-менеджер с теми характеристиками, которые были нужны: открытый, кроссплатформенный, легкий и быстрый, способный работать месяцами не выключаясь, с набором функционала, который необходим для удобной работы по ведению записей.
Я, как человек, ежедневно пользующийся MyTetra, к настоящему времени держу в ней порядка 5000 записей. Средний прирост — около 1000 записей в год. Для сравнения: автор сервиса Evernote Степан Пачиков в одном из своих интервью обмолвился о 20000 записей. Однако у него другой концепт: он собирает в свою систему все подряд, используя ее как «внешнюю» человеческую память. Я же собираю нужную мне информацию, оформляю ее, тегирую, т. е. работаю с информацией руками. И за последние три года накопилась вот такая статистика:
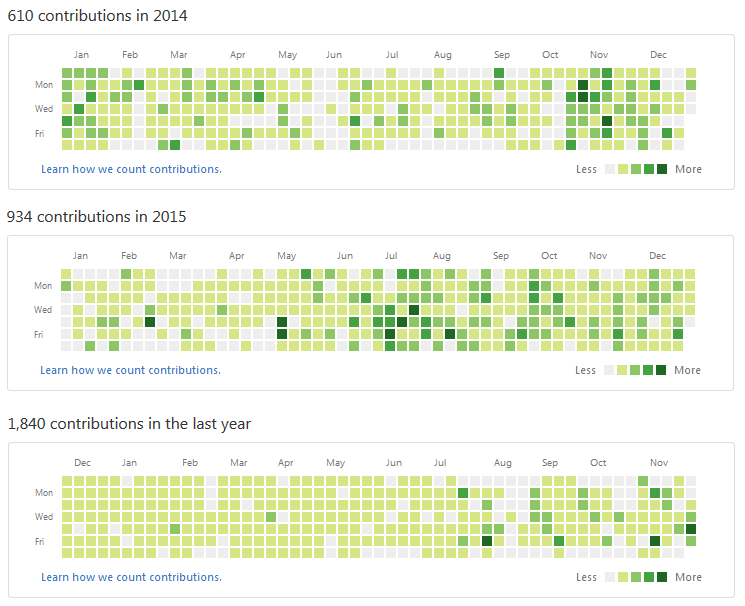
Не каждый может похвастаться таким Contributions Map на GitHub-е. А я даже не замечаю, как эта статистика набралась, так как MyTetra — это мой ежедневный рабочий инструмент.
MyTetra и Интернет
Менеджер персональных записей — это, конечно, хорошо. Каждый может сделать свой маленький огородик и втихомолку пилить свою базу знаний. Сколько в такой базе личных данных, а сколько таких, которые, возможно, были бы нужны другим людям? По своему опыту скажу, что записей, которыми можно делиться, примерно 2/3 от общего числа. Это с учетом того, что в приватных записях у меня идет постоянная ежедневная работа, т. е. их процент у меня очень большой.
Как то раз я игрался с визуализацией моей базы через пакет GraphViz. И для понимания масштаба моих открытых данных, сделал пару картинок. Здесь на сводной картинке облако повернуто на 90 градусов, иначе оно выглядело бы слишком широким. Здесь отображено около 3000 открытых записей. Полная база была бы на ~2000 записей больше.

Ссылки на полноразмерные картинки (Внимание! Картинки очень большие, браузер может сегфолтнуться. Лучше выкачать и посмотреть просмотрщиком.):
Дерево PNG 1.751 x 32.767 pix (7.2 Мб)
Облако PNG 31.279 x 5.289 pix (19.2 Мб)
Жалко, что большие массивы знаний просто лежат на дисках пользователей, и у них нет даже возможности поделиться ими, даже если бы они и захотели, потому что нет соответствующей инфраструктуры.
Какой резон пользователям делиться своими базами знаний? Это каждый решает сам для себя. Кто-то хочет «вернуть долги» информационному сообществу, кто-то просто считает, что на пути восхождения каждый человек должен делиться своими знаниями. Кто-то испытывает потребность улучшить свою карму. Кто-то хочет это делать просто из альтруистических соображений, а кто-то из практических: удобно заглянуть в свои открытые записи из любого места, где есть Интернет.
В общем, помимо самой программы накопления записей я решил сделать сервис, позволяющий выводить свои записи в пространство Интернет. Первоначально я сделал JavaScript-приложение, которому можно скормить URL индексного файла базы MyTetra, доступного по HTTP(S). И это приложение открывает базу MyTetra в WEB-интерфейсе, напоминающем Qt-интерфес MyTetra. Я назвал это приложение MyTetra Web Client. Выглядит это дело вот так:
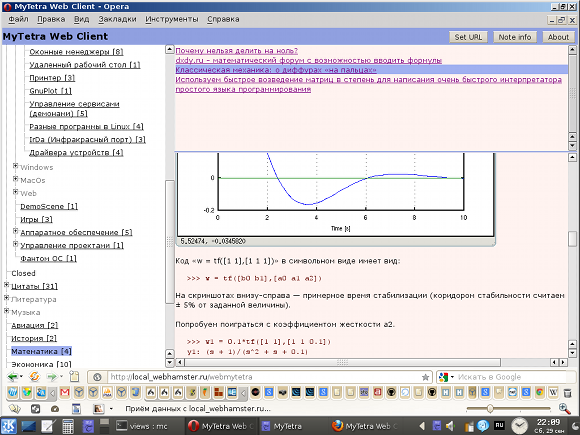
Этот клиент был написан в 2012 году, и с тех пор я его не развивал. Это очень простая оболочка, в которой не сделано даже поиска по названию записей и тегам. Просто демонстрация того, что базу MyTetra можно увидеть в браузере прямо в Интернете, если хранить данные в открытых репозитариях GitHub или BitBucket. Клиент работает и сейчас, а увидеть демонстрацию его работы можно так:
- Скопируйте в буфер обмена следующий URL: raw.github.com/xintrea/mytetra_syncro/master/mytetra.xml
- Перейдите по ссылке Web Client, и вставьте этот URL в появившемся диалоге.
Если есть другая база MyTetra, хранимая где-то в открытом HTTP(S) доступе — GitHub, BitBucket, расшаренный каталог DropBox, то можно увидеть и ее, достаточно указать URL файла mytetra.xml. Никакой регистрации не требуется — все просто работает. Если в базе есть приватные зашифрованные ветки, то они просто не отображаются: нет никакого смысла показывать людям то, что невозможно прочитать.
Однако у этого веб-клиента имеется один недостаток: по сути, это просто JavaScript-страница, и отображаемые на ней данные не индексируются поисковиками. Какой толк от баз знаний, если о них никто не знает?
Поэтому я сделал второй проект, который называется MyTetra Share. Девиз проекта: «Делитесь знаниями!». Этот сервис динамически преобразует базу знаний MyTetra в набор HTML-страниц, которые можно просматривать через Интернет. На официальной страничке проекта перечислено 8 баз пользователей, которые можно сразу просмотреть. Принцип такой же как у MyTetra Web Client: если база хранится в открытых репозитариях, можно сформировать специальный URL, по которому откроется содержимое базы знаний в HTML-виде. Если поисковик проиндексирует такой URL, значит он пойдет дальше и проиндексирует все содержимое открытой базы данных. Как я уже сказал, таких баз сейчас 8 (пример одной базы), и они проиндексированы поисковиками. Выглядит MyTetra Share следующим образом. Само дерево:
И запись:

Этот проект оказался более востребованным, и я с помощью него даже смог монетизировать содержание своего хоумпейджа и сервиса MyTetra Share: на некоторых страницах можно заметить текстовую рекламу. Этих средств хватает на оплату хостинга, доменного имени и оплаты мобильного телефона. Можно было бы зарабатывать больше, но я сразу поставил жесткий фильтр на всякие аудио-наркотики, игровые автоматы, вибраторы, микрозаймы, на колдунов и экстрасенсов. К сожалению, даже в текстовой рекламе основные прибыли идут с мракобесия и разврата. Я же занимаюсь выравниванием цифровой вселенной в более правильное русло, поэтому такие вещи на моем сайте не допустимы.
Благодаря размещению хорошо протегированной информации, проект MyTetra Share сформировал для сайта индекс цитирования в 100 ТИЦ, и обеспечил около 3000 посетителей в сутки. Для Pet-проекта это не полохие показатели, учитывая что никакой раскруткой я не занимался.
О несбывшихся надеждах
Какие же надежды я возлагал на этот гигантский и многолетний проект? Самое главное, чего я хотел от проекта — это формирование хоть небольшой, но постоянной команды разработчиков, чтобы можно было развиваться не как программист-одиночка, а в плотном общении с себе подобными. Вторая надежда была на то, что я смогу разобраться с языком C++, и наконец-то почувствую легкость в программировании на нем. К сожалению, ни того ни другого не произошло.
Периодически появлялись люди, которые делали небольшие правки и багфиксы в проекте. И я им очень благодарен. Иногда они делали что-то для проекта сами, без просьбы, иногда я сам обращался к сообществу ЛОРа и Тостера, и находились люди которые помогали решить конкретную проблему. Но это всё единичные случаи, весь проект приходится тянуть самому.
Что касается языка C++, то он оказался гораздо сложнее и неоднозначнее, чем я мог предположить десять лет назад, когда начинал его плотно использовать. К сожалению, моя работа не связана с программированием: там, где я живу, такой вещью не заработаешь. В моем окружении нет знакомых, кто хотя бы знал разницу между «сями» и «плюсами», только пара PHP кодеров. И так получается, что если нет личного общения ртом и ушами с доской и фломастером под рукой, то нет и развития. Не с кем обсудить сложные вещи так, чтобы не осталось недопонимания и они хорошо уложились в голове. Возможно, мне помогли бы книги, которые мне очень рекомендовали:
- Николас А. Солтер, Скотт Дж. Клепер, «C++ для профессионалов»
- Брюс Эккель, «Философия С++» (1-й том)
- Брюс Эккель, «Философия С++. Практическое программирование» (2-й том)
но я нигде не могу найти их в бумажном виде. С экрана же глубокого чтения у меня не получается. Максимум что могу читать — художественную литературу с книгочиталки. Но техническую не воспринимаю. Возможно потому, что книгочиталки — это один «лист», а мне нужно быстро прыгать вперед-назад в поисках разных мест, но книгочиталки такого не позволяют, слишком они медленные и неудобные.
Я пытался улучшить понимание C++ просмотром лекций из курсов удаленного обучения. Самое вменяемое, что я нашел — это курсы Евгения Линского на lektorium.tv. Но все равно, лекции по интернету к учебе отнести нельзя: у видео не спросишь те вещи, которые тебе были непонятны по ходу лекции. Так что толку от такого «обучения» немного.
В общем, для меня язык C++ так и остался загадкой. Я использую очень малую часть языка — процедуры и ООП, с болью пишу шаблоны, если без них не обойтись. Каждый раз плачу от синтаксиса указателей и адресов. С осторожностью использую наследование, хотя понимаю, что сила языка именно в нем. С ужасом смотрю на множественное наследование и на кастинг типов объектов. Qt немного сглаживает все эти проблемы, но он их больше маскирует, чем решает. Апофеозом моего понимания языка стала новость на ЛОРе, которую быстро выпилили, вот небольша часть:
Какие изменения предлагает инициативная группа стандарта C++!!, чтобы сделать язык C++ красивым, мощным и востребованным средством современной разработки? Из наиболее заметных улучшений:
- Включение в стандарт концепторов, реализующих аспектно-ориентированную парадигму наследуемого кода;
- Многовекторная диспетчеризация динамического полиморфизма для трансляции полиморфного интерфейса в рантайм;
- Нативная поддержка каппа-функторов, и отображение их на множества булеан с ковариантной структурой, решающая проблему единичности метаданных;
- Рекуррентные конструкторы, реализующие перезагрузку объектов-функций для дружественных родовых классов;
- Расширенная арифметика указателей для поддержки адресации фрагментов унаследованных виртуальных структур данных в спецификаторе сборки;
- Трансформация мутабельных объектов через операторы доступа к полям класса посредством лаяй-генераторов.
Чтобы стало понятно — эту новость я писал на 1 апреля, и в ней написана просто мешанина терминов. Примерно такое у меня восприятие языка. Самое смешное, что почти никого вышенаписанная белиберда не смутила — народ активно обсуждал действия комитета ISO и угарал над названием C++!!..
Как вы можете помочь проекту
О том, что появятся люди, помимо меня постоянно занимающиеся кодом проекта, я даже не мечтаю. За все время развития проекта было несколько человек, которые продержались чуть дольше чем люди, делающие единичные правки. Но их энтузиазм быстро сходит на нет, когда приходит осознание, что перед тем как кодить, надо согласовывать изменения. Возможно, когда-нибудь чудо произойдет, и у меня появятся постоянные напарники.
Поэтому, реальная помощь проекту MyTetra может заключаться только в одном: нужно начать им пользоваться. Если вы настроите синхронизацию, и начнете пользоваться MyTetra Share, то у вас получится удивительная вещь: вы накапливаете свою базу знаний, и автоматически делитесь знаниями со всем Интернетом, просто пользуясь этим самоорганизовывающим инструментом. Можно пользоваться MyTetra Share втихую для себя, а чтобы ссылка на базу появилась на странице проекта, можно сообщить об этом желании автору MyTetra. О том как настроить синхронизацию через Интернет, написана отдельная статья.
Важно понимать: если вы пользуетесь бесплатными тарифами CVS-хостингов типа GitHub или BitBucket, то при начале пользования вы принимаете правила хостинга о том, что ваши данные являются открытыми для всех под различными OpenSource лицензиями. Соответственно, ваши данные могут появиться на страницах MyTetra Share просто по факту их размещения на таких открытых хостингах, без вашего участия. Это суровая правда мира OpenSource, и это есть хорошо!
На официальном форуме можно высказывать свои пожелания по необходимым улучшениям программы. Хоть у меня и есть свое видение функций программы, аргументированные доработки находят свое отображение в коде.
Для того, чтобы проект развивался дальше, мне как создателю, надо видеть, что проект востребован. Никаких объективных средств для определения количества инсталляций программы не предусмотрено: люди не любят, когда программа начинает сливать какую-то информацию, даже если она предварительно спросила разрешения на это. Поэтому единственным мерилом востребованности может быть переписка на форуме, количество email сообщений и наличие активности в MyTetra Share.
Если количество баз в MyTetra Share увеличится вдвое относительно текущего, я начну работу по созданию отдельного сайта для проекта MyTetra. На новом сайте планируется сделать разделы новостей, исходников, Wiki, скриншотов, разместить форум, перенести туда сервисы MyTetra Share и MyTetra Web Client. Возможно, наличие сайта и англоязычных версий страниц выведет проект на новый уровень.
Кстати, об английском языке. Ко мне постоянно обращаются англоязычные пользователи, и я понимаю, что некоторый интерес в англоязычном мире MyTetra имеет. Две официальных страницы — страница MyTetra и MyTetra Web Client имеют англоязычные версии на кривом английском (я много перевожу с, но не могу на). По-хорошему, их надо причесать и привести в соответствие с русскоязычными версиями. Так же требуют перевода страницы по MyTetra Share, по синхронизации данных через Интернет, по формату хранения данных (ссылки приведены в конце этого поста). Кроме того, было бы неплохо заполучить если не звуковую дорожку, то хотя бы англоязычные субтитры к обзорным видео (тоже в конце поста). Я всего этого сделать не могу, но возможно кто-то с хорошим знанием языка возьмется за такую работу.
О форках MyTetra
Автору очень приятно, что несколько месяцев назад китайский разработчик Beimprovised (реальное имя Hugh Young) сделал форк MyTetra, называемый MyTetra WebEngine. В течении нескольких месяцев он неистово коммитит в GitHub громадные куски кода, что заставляет искренне удивляться его работоспособности. Наличие этого форка говорит о том, что код программы MyTetra был достаточно понятен и прост для того, чтобы другой разработчик, даже являющийся носителем другого языка, смог подхватить проект и начать делать на его основе новый продукт.
У Hugh Young свое видение проекта, и его форк очень далеко ушел от оригинальной MyTetra. Но недавно он высказал сожаление о том, что пути проектов разошлись, и нововведений, появившихся в последней версии MyTetra у него нет, а воспользоваться новым кодом проблематично, потому что он сильно изменил внутреннюю структуру проекта.
В любом случае, наличие форка меня, как автора, очень радует. Это значит, что мои усилия по написанию проекта были не напрасными.
Заключение
О программе MyTetra я написал несколько материалов, позволяющих разобраться с возможностями, заложенными в нее:
- MyTetra — программа накопления осмысленной информации
- MyTetra Share
- MyTetra Web Client
- MyTetra v.1.28 — подробный обзор
- MyTetra v.1.30 — подробный обзор
- MyTetra v.1.42 — подробный обзор
- Как в MyTetra настроить синхронизацию через интернет
- MyTetra: формат хранения данных
- Исходники MyTetra на GitHub
Есть хорошая идеологическая статья человека под псевдонимом Игорь Блогератор (к сожалению, я с ним не знаком), во второй части которой рассматривается MyTetra:
Так же, ввиду того, что на днях я выпустил свежую версию 1.42, я сделал видеообзор программы в 3 частях, видеообзор выложен на YouTube:
- Видеообзор MyTetra v.1.42. Часть 1. Обзор основных возможностей MyTetra
- Видеообзор MyTetra v.1.42. Часть 2. Настройки программы MyTetra
- Видеообзор MyTetra v.1.42. Часть 3. Нововведения в MyTetra v.1.42
В этих видео подробно рассказываются все аспекты работы с программой (поэтому видео длинные по 20-40 мин.), и рассматриваются основные приемы работы. MyTetra — это не только менеджер заметок, это инструмент, какорый помогает организовать собственный рабочий процесс. Например, в MyTetra можно вести список дел и создавать для себя небольшие отчеты. Об этой методике рассказывается в первой части.
По новой версии MyTetra 1.42 (юбилейный выпуск на 5-ти летие открытия исходников) опубликована новость, в которой описаны изменения и нововведения, есть информация по установке и обновлению программы.
Надеюсь, сообществу Хабрахабра понравится программа, и идеи, в нее заложенные.
Комментарии (284)

generall
05.12.2016 15:44Метакадемию не смотрели? Похожая идея, на мой взгляд.

webhamster
05.12.2016 16:40А что в ней есть? Навскидку попробовал поискать «Linux», а мне в ответ:
We did not find any relevant results (is your spelling correct?).
Consider checking our full list of concepts to see if you can find what you're looking for.
Try using a: Google search for «linux» on Metacademy.
alexkunin
05.12.2016 17:56Там же написано: «Search for concept you want to learn, e.g. b-trees». Линукс — не концепция, вот и не нашелся.
Но вообще да, это скорее база методов и алгоритмов научного толка, а не практические навыки.
Кстати, если в поиске ввести русские буквы, то падает с ошибкой 500.

webhamster
05.12.2016 16:24Но там же только текст, картинок нет. Прикрепляемые файлы — под вопросом. И конечно интерфейс явно не для меня: я не воспринимаю ни Emasc ни Vi/Vim. Вообще не понимаю, как в XXI веке могут существовать такие интерфейсы. Я понимаю, когда подобные интерфейсы делали на Радио-86-РК, но зачем сейчас так мучиться — мне лично не ясно.
S_A
05.12.2016 16:47Не наезжайте на vim. Очень классная штука, гораздо быстрее «мышечного» интерфейса. Просто в разы. Не суть.
При всем признании вашей работы — объемной — советую все же обратить внимание на «хипстерские» нынче технологии — node.js, meteor, electrify. С ними рендеренг хтмл из коробочки, кодобаза смешная будет по объему, а функционал и интефейс приятно привычные, хоть bootstrap, хоть материальный. И в вебе, и на десктопе (после двух команд — пакет arboleya:electrify — пробовал сам, знаю-верю).
Честное слово, правда рассмотрите. Удивитесь как ваше дело превратится в перспективный стартап почище евернота, который ниочемщина в сравнению с накопленной вами базой (знаний и пользователей). Вот так…webhamster
05.12.2016 17:06+1> Не наезжайте на vim. Очень классная штука, гораздо быстрее «мышечного» интерфейса. Просто в разы. Не суть.
Я не наезжаю, просто для меня он очень сложен и неудобен. Я плохо запоминаю несвязанные вещи (именно из-за плохой памяти и сделал MyTetra кстати), а команды Vim я отношу как раз к таким вещам.
Более того, я за то, чтобы интерфейс всегда и везде был единообразен. Если в GUI-шных DE принято для удаления строки выделить ее и нажать DEL, то так должно быть и в редакторе. Если принято копировать в буфер обмена по Ctrl+C, то так должно быть везде, даже в консоли Linux. И я себе именно так и настраиваю, и статью по этому поводу давненько написал:
Как «освободить» клавиши Ctrl+C, Ctrl+V, Ctrl+X в терминале
Я понятия не имею, можно ли настроить Vi и Emasc на такое стандартное поведение. Но мне больше по душе появившийся недавно Micro, в нем основные действия стандартные, хотя тоже закидонов хватает.S_A
05.12.2016 17:21Как и всё в linux (а вы в курсе;)), команды vim также являются сокращениями. dw — delete word например. я тоже все *nix команды не помню по аббревиатурам, вспоминаю каждый раз mv — это move, и так далее.
Мой коммент про «смотрите метеор» :) Что вам этот vim :) понятно дело, будь он доступен хотя 72% пользователей, на нём бы уже все сидели (ну и видать это далеко не так).S_A
05.12.2016 17:25Кстати и мобильные приложения из meteor получить — пара команд. Как говаривал Даня Шаповалов — «мне на три года проплатили эту фразу». :)
webhamster
05.12.2016 21:29Я бы больше хотел обсудить не технологии, хотя они тоже важны, а вот какую вещь.
Рано или поздно придется решить проблему: правка данных через веб-интерфейс. Я все не могу придумать, как это организовать, учитывая что данные хранятся просто как файлы, и синхронизируются через cvs или cloud.
Если я даже создам онлайн — сервис, то пользователь должен будет как-то получать изменения, вносимые в веб-интерфейсе, на свои локальные инстансы. Вот как это можно организовать? Так, чтобы пользователю было прощще. И чтоб для пользователя было безопасно.S_A
05.12.2016 22:05Гляньте filebrowser.io — облачный навигатор по файлам. Если надо править файлы на локальном компе — то естественно, сервер сервиса никак не сможет это сделать — без десктопного клиента или связки по api/ftp/whatever с клиентом.
Вот те самые технологии, которые важны, meteor упомянутый, десктопного клиента электрифицирует по умолчанию с собственной монгодб, то есть интернет как бы и не нужен. А по-хорошему, это задача синхронизации двух баз данных, локальной и удаленной, и да — без клиента с логикой, пусть даже опосредованной только облачными хранилищами — никак.S_A
05.12.2016 22:09Ну и конечно самый простой вариант — реэкспорт файликов. Но не слишком удобно, поэтому даже не писал.

svboobnov
05.12.2016 22:31rsync / git push или аналоги не предлагать?
webhamster
05.12.2016 22:37Проблема в безопасности: при взломе онлайн-сервиса злоумышленник может понапихать изменений в синхронизированные локальные базы пользователей. И будет это делать через rsync и git.
Хотелось бы какую-то другую схему, не поверженную таким проблемам.

avalak
06.12.2016 15:10-1> кодобаза смешная будет по объему
Это да. Смех сквозь слёзы и цирк с конями.

Rayslava
06.12.2016 09:26Ну, собственно, по поводу того самого emacs: приблизительно для тех же целей, что и ваше приложение там предусмотрен org-mode.
Картинки есть, файлы прикладываются, никаких проблем с синхронизацией чем угодно, вплоть до гита, поскольку хранится плейнтекстом, древовидная структура со сворачиванием, теги, поиск, запуск кода на любом языке прямо in-place, табличный процессор, экспорт в html/tex/odt. Ну и, соответственно, открытый, кроссплатформенный, GPL, всё, как положено.
Правда не уверен насчёт объёмов, по три тысячи записей с картинками и аттачментами в одном файле хранить не пробовал, но поиск по директории org с помощью какого-нибудь ag работает очень быстро.

Cheater
06.12.2016 14:06+1 ко всем, кто советует Emacs org-mode. У вашей программы хорошая функциональность, но до org-mode ей далеко.
> Но там же только текст, картинок нет. Прикрепляемые файлы — под вопросом.
Картинки есть. См. http://orgmode.org/manual/External-links.html. Вместо прикрепления блобов применяются гиперссылки.
> зачем сейчас так мучиться — мне лично не ясно
Это в разы быстрее GUI в большинстве случаев.svboobnov
06.12.2016 20:17Вот за org-mode спасибо. Это весомый повод перейти с вима на емакс.

EvilShadow
06.12.2016 22:54Вовсе необязательно переходить. К примеру, у меня на текущий момент сложилась такая конфигурация:
— Код в Атоме с vim-mode-plus
— Управление задачами в emacs с org-mode. На тему настройки есть такие монументальные труды, как http://doc.norang.ca/org-mode.html
— Конфиги по ssh и локально и мелкие файлы локально — neovim
Берите лучшее из всех миров. Если переезжать с вима на емакс ещё и для активной правки текста или кода, то можно посмотреть на evil-mode.svboobnov
06.12.2016 23:30Ну, задачи и планы у меня в Thunderbird / Lightning, так уж привык давно. А вто структурированные записки — полезная штука. Они должны быть под рукой, на расстоянии одного-двух шорткатов. Тут либо VimOutline, либо ещё что-то подобное нужно.
Saffron
07.12.2016 10:21> Вот за org-mode спасибо. Это весомый повод перейти с вима на емакс.
Есть ещё evil-mode, чтобы чувствовать себя на емакс как дома.


EXL
05.12.2016 16:51-1Рад, что вы донесли свою программу и до хаброжителей.
Думаю, начну ей пользоваться, а то веду свои заметки совсем примитивно: текстовые файлики и синхронизация с помощью git.
Whiteha
05.12.2016 17:24За выбор Qt и за полезную программу спасибо, не раз задумывался о том что было бы не плохо иметь подобный менеджер знаний вместо обычных тетрадных записей.
Кстати действительно, его xml файл можно положить под гит и получится вообще удобно)
svboobnov
05.12.2016 17:49Ух ты! Настоящая база знаний на десктопе!
Вы меня прямо порадовали, я вот подумывал об изучении C++, как раз для того, чтобы иметь возможность дорабатывать Mozilla Thunderbird, и попробовать сделать быструю базу знаний.
Но потом пришёл к выводам:
- что надо делать веб-приложение (например, на основе vibe.d), которое можно открыть локально (через http://localhost/wiki);
- Язык С++ сложноват, проще освоить D(dlang.org)
- Надо реализовать (или взять готовую библиотеку) именно графовую БД,
- В качестве источника вдохновения надо взять Fossil там есть wiki и контроль версий.
ЭЭЭ… А если есть готовая вики с контролем версий, то зачем мне писать свой велосипед с треугольными колёсами? Взял Fossil и ни о чём не думаю.
Правда, Вашим требованиям оно не соответствует: требует браузера, и в трее не висит.
svboobnov
05.12.2016 18:07+1Кстати, насчёт готовой графовой СУБД: поглядите на ScyllaDB (русский анонс я видел здесь)
Или, ещё лучше: библиотека СУБД Sophia, хранит данные в формате ключ->значение, работает быстро.
worker
05.12.2016 19:23+1Есть ли MyTetra база по MyTetra использованию?:)
webhamster
05.12.2016 21:15Это упущение по причине нехватки времени. Для демонстрации надо бы написать документацию по MyTetra внутри самой MyTetra, все инструменты для этого есть, а времени нет.

worker
05.12.2016 19:30О монетезации
Может автору стоит рассмотреть возможность добавлять рекламу в записи
Т.е. есть записи пельмени, блины, соленое сало,
и рядом добавлять от гугла/яндекса рекламу, где их купитьFree_ze
12.12.2016 09:53Расстрелять!
Зря что ли шифрование присобачивали, чтобы содержимое индексировалось?

synedra
05.12.2016 19:30+9Сразу скажу, что не хочу критиковать конкретно ваш проект, но для чего-то более крупного древовидная организация знаний скорее недостаток, чем достоинство.
И быстро понял, что дерево свою функцию «базиса» хорошо выполняет, особенно, если ты сам вырастил это дерево.
Вторая часть этого предложения и есть ИМХО главная проблема. Получившаяся база сугубо индивидуальна. Вот у вас на скрине, например, есть категория «Ноутбуки», а есть категория Asus EEEPC 701, которая не является её подкатегорией. Рискну предположить, что первая категория заполнялась при выборе ноутбука перед покупкой, а вторая — уже про особенности конкретного компьютера, который вы в итоге купили, или ещё по каким причинам так лежит. Ваши данные, вам и решать, как их раскладывать. Но в идеальном-то мире, ежели это не ваша собственная свалка заметок, а что-то масштабов википедии, должно бы быть компьютеры/модели/ноутбуки/асусы/ASUS EEEPC701 или ещё как-нибудь вроде того. Есть немаленький риск погрязнуть в бесконечных спорах остроконечников о том, должны ли нетбуки выделяться в отдельную категорию, и должна ли эта категория быть подкатегорией ноутбуков.
Вы в качестве примера приводите биологическую таксономию, и там наблюдается именно эта картина. Даже с современными требованиями молекулярно подтверждённой монофилии таксонов есть группы, положение которых на древе жизни описывается десятком способов, более или менее принятых в разных кругах, и переносы групп из одних надгрупп в другие происходят постоянно. И это при наличии пусть не безупречных, но всё же методов определить вложенность групп и ранг конкретной группы (и кучи людей, готовых потратить всю жизнь на уточнение третьестепенных деталей классификации). А знания не делятся каким-нибудь очевидным образом на набальзамированные, принадлежащие Императору, нарисованные тонкой кистью и способные лучше меня цитировать Борхеса по памяти.webhamster
05.12.2016 21:13+5Вы все правильно написали. Но следует учитывать еще одну вещь — психологию. Человеку очень важно иметь образ «места», куда он складывает свои записи. Место в иерархии дерева — вот это оно и есть. Иначе возникает неприятное чувство, что данные хранятся где-то в какой-то куче или болтаются где-то в невесомости. А еще хуже осознавать то, что если неточно составиль запрос, то можешь данные вообще не найти.
Достаточно посмотреть, насколько сложнее стало пользователям windows 8 — 10. Раньше у них было древовидне меню, а теперь им надо искат по имени или в каких-то нереально длинных списках. Люди не могут даже запустить нужную программу.
Но в любом случае, как я сказал, дерево — это опора. Я все свои записи хорошо тегирую и активно пользуюсь поиском. Теги — это горизонтальные связи, поэтому в MyTetra имеется на самом деле граф, а не дерево. Дерево слева выполняет вспомогательную функцию: психологическая опора и возможность потыкаться по веткам при поиске «по логике вещей». Ну и еще спользуется при организации списков дел.
В общем, повторюсь, что дерево — это компромисс а не панацея. В MyTetra оно больше подходит для старта, дальше стиль работы меняется, и используется поиск. Наличие связей по тегам и возможность прописывать в текстах ссылки на другие записи превращает дерево в граф.
AlexTest
06.12.2016 01:56А что если предоставить пользователю возможность «вырастить» персональное «опорное дерево» на основе своих предпочтений?

JKot
06.12.2016 07:04+1Совершенно противоположный опыт с пуском. В XP мне требовались часы на группировку всех программ по дереву, продумывании структуры и т.д, а в результате доступ всё равно был в разы дольше чем набрать 2 первые буквы приложения. Теперь использовать ос без поиска по программам просто не могу, настолько я привык уже к этому. Естественно ничего теперь не сортирую.
И почему не теги? По моему они отлично вписываются в вашу концепцию «места» куда складываются записи.webhamster
06.12.2016 07:07Теги есть. В принципе, вам ничто не мешает все складывать в одну ветку, и писать теги. Не знаю, насколько это удобно, но можно и так. А можно одну ветку рассматривать как один блокнот, и держать несколько тематических блокнотов.
Единственное, чего пока нет, это подсказок по тегам, но необходимости такой у меня еще не возникало.

r3verser
06.12.2016 16:30+1согласен, какие варианты вы предлагаете вместо дерева?
synedra
07.12.2016 05:48+2Ничего лучше википедийных категорий не знаю. Категории могут, но не обязаны, быть вложенными и категории из отдалённых областей знаний не связаны никакими иерархическими взаимоотношениями. Каждая статья может принадлежать любому количеству категорий от нуля до плюс бесконечности.
Ну и пользователю надо дать организовывать кастомные категории по вкусу, если это десктоп-приложение и данные хранятся локально.
svboobnov
07.12.2016 11:19synedra говорит про граф, насколько я понимаю.

Stalker_RED
08.12.2016 12:34Да называйте это хоть тегами. Главное, что можно одному документу присвоить метки из нескольких разных «веток» дерева.
ytc39898
05.12.2016 19:51Я делаю такую же программу для себя, но полностью в виде веб-приложения. У меня соответственно вопрос — почему standalone? Как пользоваться заметками на планшете или телефоне? А на другом компьютере? Как защитить заметки от воровства, если спионерят компьютер/ноутбук? Веб-подход был бы гораздо удобнее.
Второй вопрос — почему github и нарушение своей собственной приватности? Всё же личные заметки не для посторонних.
Насчёт необходимости такой идеи как таковой — её невозможно переоценить. До подобного вида заметок (у меня они относятся к древовидным тегам вместо категорий, хотя это по смыслу одно и то же) чувствовал себя слепым щенком. К этой идее тоже шёл несколько лет. Приводить свои заметки в порядок и систематизировать их — это невероятно удобно и практично.
redmanmale
05.12.2016 20:07Веб-подход был бы гораздо удобнее.
И требовал бы интернета.
Как пользоваться заметками на планшете или телефоне?
Для этого есть версии для планшетов и телефонов, судя по описанию.
А на другом компьютере?
Для этого есть синхронизация.
нарушение своей собственной приватности
Насколько я понял, вы сами выбираете, чем делиться, а чем нет. И личные заметки зашифрованы.
avalak
06.12.2016 15:20> И требовал бы интернета.
Как бы 2016 год на дворе, светлое будущее наступило и интернет в основном и быстрый и доступный. К тому же self-hosted сервисы можно и у себя на машине держать.webhamster
06.12.2016 16:28Я так понимаю, вы никогда не были в ситуациях, когда приезжаешь в командировку, на проходной у тебя изымают телефон, ноутбук проносишь по спецпропуску, в сети предприятия интернета нет, и тебе вместо привезенного тобой образа суют другой диск с дистрибутивом Linux, который ты раньше в глаза не видел. И развертывание нужно сделать за полдня, потому что вечером поезд.
Вот тогда ты понимаешь, что наличие всех своих записулек локально на ноуте — это просто спасение, и ты радуешься, что пару лет назад работал с чем-то подобным, и не поленился сделать записи. В такие минуты ты сам себя готов в жопу расцеловать за предусмотрительность.avalak
06.12.2016 17:51Нет, не случалось. Как бы то ни было при использовании self-hosted решения это не проблема (ноутбук же не отобрали и от localhost не отлучили).
На своей машине (стационарный пк/ноут не принципиально) запущен сервис с web ui. Даже проблем с обслуживанием nginx, php-fpm нет. Достаточно uwsgi + db (опционально) и браузера. Получается весьма компактное самодостаточное решение (чтоб совсем красиво было надо ещё в docker затолкать, но там свои заморочки).
Если озадачиться можно без особых проблем:
* расшарить сервис в локалку (использовать с планшета/смартфона или дать домашним доступ)
* настроить доступ по клиентскому сертификату
* настроить tor hidden service и иметь доступ к системе отовсюду
У меня так rss, wiki и прочие локальные сервисы живут. Довольно удобно.
thunderspb
06.12.2016 19:05А есть гденить хороший мануал про настройку клиентского сертификата в связке nginx + (letsencrypt|startssl)? Гуглится только про selfsigned.
avalak
06.12.2016 20:26Тут ничего порекомендовать не могу. Сам с selfsigned настраивал.
Попробуйте про intermediate ca поискать.

kost
08.12.2016 22:52Купите нормальный сертификат и настройте локальный домен. Сертификат стоит $9 в год.
webhamster
07.12.2016 09:35— self-hosted решения
— localhost
— запущен сервис с web ui
— обслуживание nginx, php-fpm
— достаточно uwsgi + db (опционально)
— в docker затолкать
Как все это барахло пользователь будет у себя устанавливать? Я вообще расстраиваюсь, что до сих пор не сделал сборку под Win с инсталлятором, чтоб иконка сама на рабочем столе появилась. А ты тут такой ужосо рассказываешь.svboobnov
07.12.2016 11:32Self-hosted решение — 1 скрипт на питоне (перле, люа, джаваскрипте, пэхэпэ), которому нужна только среда исполнения, т.е. интерпретатор языка программирования с подключенной или встроенной библиотекой веб-сервера.
Можно, вместо скриптов, написать и статически скомпилировать исполняемый файл (на C++ том же), но трудоёмкость мелкой настройки выше.
* Локальное применение
Вы запускаете систему примерно так:knowlege-base --port=8080 --bind=127.0.0.1 --datadir=/var/db/knowlegebase
а затем открываете Ваш браузер, и вводите «http://127.0.0.1:8080/» и видите заглавную страничку Вашей вики/базы знаний;
* Применение в сети предприятия:
knowlege-base --port=8080 --bind=192.168.1.5 --datadir=/var/db/knowlegebase
И ваши пользователи лезут в «http://192.168.1.5:8080» и точно так же пользуются этой базой знаний.
Вот в этом и есть преимущество баз знаний с веб-интерфейсом: вы можете начать локально, а когда понадобится — запустить для окружающих.
semenyakinVS
07.12.2016 14:39Вы запускаете систему примерно так:
knowlege-base --port=8080 --bind=127.0.0.1 --datadir=/var/db/knowlegebase
По-моему, комментарий был как раз по поводу действий запуска и/или настройки, которые выглядят страшно для конечного пользователя. Для людей, далёких от мира продвинутого пользования компьютеров и программирования (а таких среди весомое количество) даже адресная строка браузера — это «программирование». Серьёзно, сталкивался с подобными ситуациями. А приведённая в цитате строчка из команд (!), которую нужно ввести в консоль (!!) отпугнёт просто 100%. Чтобы было хорошо — всё должно ставиться в самом сложном случае через «дальше-дальше-готово», а запускаться «через иконочку» и без каких-либо других шаманств.avalak
07.12.2016 16:04Для пользователя это и сводится к установке пакета в linux или приложения в windows. Сюрприз-сюрприз.
Эту «страшную» команду он, весьма вероятно, даже не увидит, потому что при установке скрипты всё сделают за него.
Целая ветка удивительных открытий: сайты можно хостить на локальной машине (wow), при установке приложение интегрируется в систему само (wow). Дурдом.
avalak
07.12.2016 14:51Всё смешалось в доме Облонских… Вы для драматизма в этот список забыли добавить чистку Авгиевых конюшен. А ведь это важно, без этого чудо не случится.
Приложений с web ui хватает: deluge, transmission, ngrok, syncthing, btsync, portainer (docker ui), jenkins и прочие. Пока никто не помер.
PsyHaSTe
12.12.2016 16:53Честно говоря, очень расстраивают JS-ошибки в том же Atom'е, причем что делать с ними — непонятно, `undefined is not a function` и всё, приехали.

OnkelTem
12.12.2016 17:14Что поделаешь, JS слишком быстро развивается, не успеешь сваять продукт, все либы уже устарели. Еще несколько лет такой гонки точно будет, если не десятилетий.
svboobnov
06.12.2016 20:06Вам уже несколько раз напомнили: на Вашем ноутбуке крутится маленький, локальный веб-сервер, который и управляет этой базой знаний. А браузер становится GUI'ём для этого сервера.

AndreyDmitriev
06.12.2016 16:37Есть и другая реальность. У меня домашний интернет — 2 (два) мегабита на вход и 256 кбит на выход. Это недалеко от Гамбурга, кстати. За время отправки в «облако» 20-30 мегабайт можно легко успеть поужинать.
По работе же я занимаюсь промышленной автоматизацией (машинное зрение, неразрушающий контроль) и на работе сижу са семью файрволлами с авторизацией и капчами, а в командировках-пусконаладках интернета нет на рабочем месте по определению, и даже точку доступа не поднять, ибо чтобы появилась мобильная связь, надо порой выйти из цеха на улицу.azsx
06.12.2016 17:06Правда в обоих случаях любопытно, а точно тогда картинки нужны? Может тогда в файлах в консоли, поиск grep, имя файла — титл, каталог — дерево и теги отделять ключевым словом. В чём недостаток?
AndreyDmitriev
06.12.2016 17:26+1Да нет никаких недостатков — надо пользоваться тем, что удобно, а «удобство» — в данном случае понятие сильно субъективное. Вот будете смеяться — один из основных моих помощников — Natara Bonsai, этой программой я пользуюсь лет пятнадцать уже, она отработала каждую копейку, которую я потратил на покупку и обновления. И да, у меня до сих пор Palm Tungsten T3. Есть и портативная версия на флешке U3. Что касается «с картинками» — тут я пользуюсь ToDoList.
Эти инструменты чуть разные, но хорошо дополняют друг друга. В Natara — в основном оперативное планирование, GTD, и списки всякие типа возьми в командировку то-то и то-то. В ToDoList — работа над проектами — я сейчас работаю как QA, и мне приходится много чего тестить на отдельно стоящих компах без интернета. Эти продукты объединяет древовидная структура.
Кстати, вот ещё пример очень похожего на myterra решения «для себя» — pdb. Cценарий использования у автора: Кросс-платформенная разовидность TreePad.webhamster
07.12.2016 12:06Natara Bonsai — почему ссылка на WebArchive? Даже сайта от нее не осталось? Наверно стоит сделать перенос данных на другой менеджер? Или данные в закрытом формате?
По PDB попытался искать хотя бы скриншоты в Яше и Гоголе. Вообще ничего не находится. Как-то боязно связываться с таким проектом. Плюс на официальной странице программы несуществующая ссылка на исходники.AndreyDmitriev
07.12.2016 12:37Компания Natara тихо скончалась, но продуктом я пользуюсь о сих пор. Перенести данные — без проблем, там тоже всё в XML (скажем в ToDoList оно перебрасывается без проблем), но мне без пока надобности.
pdb — тот продукт, когда автор сделал раз для себя. Он не обновляется, тут тот случай, когда делается форк, и дальше начинается допиливание.
avalak
06.12.2016 17:57Соболезную. Как бы то ни было при использовании self-hosted решения это не проблема. До localhost скорость хорошая.
На своей машине (стационарный пк/ноут не принципиально) запущен сервис с web ui. Даже проблем с обслуживанием nginx, php-fpm нет. Достаточно uwsgi + db (опционально) и браузера. Получается весьма компактное самодостаточное решение (чтоб совсем красиво было надо ещё в docker затолкать, но там свои заморочки).
Если озадачиться можно без особых проблем:
* расшарить сервис в локалку (использовать с планшета/смартфона или дать домашним доступ)
* настроить доступ по клиентскому сертификату
* настроить tor hidden service и иметь доступ к системе отовсюду
У меня так rss, wiki и прочие локальные сервисы живут. Довольно удобно.redmanmale
07.12.2016 00:53-1Когда вместо десктопного приложения пытаешься сделать веб-приложение там, где не нужно, получается pgAdmin4.
jkollss
05.12.2016 20:46Я пользуюсь dokuwiki, и если бы в неё добавить древовидные тэги (удобно иногда, чтобы одна и та же заметка была в разных категориях одновременно), переписать бэкенд на ноде или golang (rust, dlang, etc), (что дало бы возможность работать оффлайн без возни с установкой php или же, в варианте ноды, использовать electron для десктопа), добавить стандартный markdown — было бы практически идеально.
Веб-подход в данном случае действительно гораздо удобнее, даже для десктопа.

ValdikSS
05.12.2016 23:46+19У меня соответственно вопрос — почему standalone?
Если честно, я просто не представляю, как люди пользуются любыми веб-приложениями. Либо я вырос на десктопных, не тормозящих приложениях, и такой требовательный, либо что-то не так с моим софтом, либо люди не знают, каким вообще приложение должно быть.
Вот, скажем, открываете вы документ в Google Docs. Открываете страницу, начинаете набирать, и понимаете, что полностью страница еще не загрузилась, и джаваскрипт не успел перевести фокус на поле ввода. Первые три набранные буквы пропали.
Это просто первая мелочь, пришедшая мне в голову, но она для меня столько значит, что сразу ставит крест на Google Docs.
Или, например, нажимаете во многих веб-приложениях правую кнопку мыши на каком-нибудь объекте, ожидая, что вы получите меню объекта, и видите там «назад», «вперед», «сохранить страницу», и так далее. Понимаю, что нажатие правой кнопки мыши можно перехватывать, как это делает тот же Google Docs, но когда ты такое видишь в, казалось бы, десктопном приложении (написанном на node.js, который тащит с собой chrome.exe и ffmpeg.dll, и простейшее приложение занимает больше 50 мегабайт в архиве), то это просто неприемлемо.
«Десктопные» приложения Slack, Mattermost, текстовый редактор Atom, который раньше не умел открывать файлы с размером более 2 МБ, а сейчас открывает мегабайтный файл несколько секунд — просто какой-то мусор, непонятно, кто в здравом уме будет пользоваться такими программами, пока есть альтернативы в виде нормальных десктопных приложений.MonkAlex
06.12.2016 00:07+15Ух ты, я думал я один такой упоротый и не понимаю этого веба на десктопах вместо обычных приложений.
Все пользуются и хвалят, а у меня ощущение тормозов даже на современных ПК с SSD и 100мбит каналом.OnkelTem
07.12.2016 14:49У меня десктопный Emacs тормозил когда я им пользовался (?2004-2006), десктопный Eclipse тормозил вообще ужасно, Azureus/Vuze торрент-клиент черепаха та еще.
А вот вебовские Telegram, Toggl, feng, rizzoma и другой софт работает на пятерочку.
Даже хабр не заставляет меня чего-то ждать, все открывает хорошо, комменты постятся сразу, жаловаться не на что.
В общем, скорость софта и "вебововсть" с "десктоповостью" связаны косвенно. А уж если что-то крутится локально и комп шустрый, так разницы вообще нет.
svboobnov
07.12.2016 19:06Наверное, у Вас просто компьютер стал раз в 10 мощнее (обновляли ведь?).
OnkelTem
07.12.2016 19:16Может и стал, но Eclipse на нем тормозит и сейчас, так что это не критерий. А вот появление и стремительное развитие того же V8 перенесло JS на серверы, а также сделало возможным создавать "гладкую" анимацию там, где до этого использовался Flash, что говорит о значительной оптимизации. Поэтому проблем с использованием "веб-технологий" в десктопных приложениях я лично не вижу.
Вообще не понимаю зачем автору потребовался C++ для данной задачи (по сути — простейшая картотека). Взял бы JS и было бы нормальное масштабируемое решение для всех платформ.
aGGre55or
14.12.2016 03:43Есть куча платформ на которых JS нет в помине. И вообще web-технологий. Понятно что лично Вам эти платформы не очень-то нужны, но люди которые их используют — есть и любой web-стек всегда проиграет сишнику в распространённости. Хотя бы уже просто потому что сам этот web-стек написан на сишнике или асме. А для того чтобы радоваться его юзабельности, надо его сначала ещё запустить.
BarrelRoll
06.12.2016 17:31-1Последние пол года активно пользуюсь клиентом Slack под windows, проблем не обнаружил. Интересно стало что Вас в нем раздражает?
EvilShadow
06.12.2016 23:05А какой альтернативой Атому пользуетесь Вы?
ValdikSS
07.12.2016 10:51Я пользуюсь Kate, это тоже текстовый редактор.
EvilShadow
07.12.2016 11:08Спасибо
webhamster
07.12.2016 22:59Если нужен редактор без боковой навигации по файлам, то лучше использовать kwrite. Это тот же самый kate, только не MDI. И кстати, помоему kate уже не развивают.
По kwrite я писал цикл из трех статей:
Как я искал текстовый редактор под Linux.
Внизу справа ссылка на следующую часть.

Ramires
07.12.2016 14:30+1Неплохая альтернатива — sublime text.
EvilShadow
07.12.2016 22:37Саблайм действительно неплох, но, по моему личному мнению, скорее мёртв, чем жив.

ckr
11.12.2016 05:33Атомом стоит пользоваться просто хотя бы из-за этого плагина
https://atom.io/packages/activate-power-mode
Для всего остального gedit и vim

pmcode
05.12.2016 19:54+3Я пробовал Zim и Outwiker. Оба не прижились по одной причине, думаю, общей для всех заметочников такого рода. Например, Outwiker. Создаем простую текстовую заметку, а он создает директорию (со служебным файлом, в котором лежит наш текст); добавляем к этой заметке дочернюю, и он создает поддиректорию. WTF1: зачем мне две директории, когда я хотел два текстовых файла? Дальше больше, добавляем вложение, и появлется директория attach. WTF2: но я вообще не просил складывать мои файлы куда бы то ни было — они уже лежат там где надо. В этом фундаментальная проблема всех десктопных заметочников, они ломают твою сложившуюся иерархию, и строят свою. Как и ваш, к сожалению. А проблема это потому, что эта иерархия — не стандарт, и если, в условном завтра, данный заметочник загнется по любой причине, то несчастному пользователю останутся руины того, что он собирал, может быть, годами. И дооолгая процедура миграции.
Каталог data/ аля MyTerra — такая же ни с чем не совместимая файлопомойка, как и у Outwiker, Dokuwiki и прочая. Вы пишете, что отказались от БД, но ваш каталог data/ в общем-то и есть БД, для пользователя он неюзабелен.
Вторая проблема, это то, что каждый wiki-движок считает своим долгом написать собственную wiki разметку. У вас сохраняется в HTML, что в общем одно и тоже. Совершенно не берутся в расчет люди, которым лень тыкать по кнопкам WYSIWYG редактора :) и такие прекрасные штуки как markdown и asciidoc. Чем хорош markdown — написал один раз использукшь везде. Закинуть в Gist, выдрать кусок для README, спопипастить со SO, нет проблем. Можно даже на Хабр запостить. :)
Я на самом деле давно и много над всем этим думал, тоже порывался писать свое решение, но в целом пришел к выводу, что обычная строгая каталогизация покрывет 90% функционала. Да, может где-то не так быстро, и не так удобно, но приемлемо и бесхлопотно. А идеальный PIM — это приложение которое бы умело быстро строить индекс по различным форматам файлов (text, docx, odt, pdf, mht и т.д.). Натравливаешь его на каталог, и оставляешь висеть в трее, чтобы всегда иметь быстрый доступ. Все что от него нужно э- то быстро найти файл(ы) и перейти в каталог или запустить их. Вот такого ПО удовлетворительного качества пока нет, к сожалению.webhamster
05.12.2016 20:24У вас совсем другая задача: вам нужно индексируемое хранилище файлов.
Есть такая вещь, правда windows only, но вроде с открытым исходным кодом, называется Docfetcher, использует Java. Там просто вы имеете каталоги с нужной вам структурой и файлами традиционных форматов. Докфетчер натравливается на каталог и индексирует его. Потом можно искать файлы по имени, содержанию, другим критериям.
У него даже есть служба фоновой индексации, но что-то у меня она толком не работала.
webhamster
05.12.2016 21:59Кстати, тут ниже советуют такую штуку:
https://www.tagspaces.org
Возможно она вам больше подойдеsvboobnov
05.12.2016 22:43+1Поглядел, увидел аналог старинного текстового файла descript.ion, который понимался файловыми менеджерами VolkovCommander и FAR. Впрочем, раз раньше эта идея работала, то и сейчас для кого-то будет полезной.

quverty
06.12.2016 13:35Да, тоже интересно, правда я сам как-то привык к минимальному дизайну в стиле Total Commander и т.д.
ckr
11.12.2016 05:41А идеальный PIM — это приложение которое бы умело быстро строить индекс по различным форматам файлов (text, docx, odt, pdf, mht и т.д.). Натравливаешь его на каталог, и оставляешь висеть в трее, чтобы всегда иметь быстрый доступ. Все что от него нужно э- то быстро найти файл(ы) и перейти в каталог или запустить их. Вот такого ПО удовлетворительного качества пока нет, к сожалению.
Из коробки может быть решения и нет, но по отдельности все давно решено. Можно прикрутить, например, yad-морду к sphinx.azsx
11.12.2016 06:00Натравливаешь его на каталог, и оставляешь висеть в трее, чтобы всегда иметь быстрый доступ.
Винда Copernic Desktop Search Corporate. linux — recol. Я под винду использовал — очень удобно!
ps
В итоге переборов вариантов софта из топика решил вернуться на ms expresion web 4. Да минусы есть, но плюсов вагон. В прошлый раз я от него отказался, так как не логична работа с изображениями.

kartvladek
05.12.2016 19:54В качестве источника для вдохновения могу порекомендовать вам Convera RetrievalWare. Понимаю, что повторить подобное не удастся, но как ресурс для анализа возможностей советую. Самому довелось пользоваться (правда под присмотром) — впечатления удивительные.
Jogger
05.12.2016 19:56+1Кросплатформенность это хорошо, но мне кажется для такого проекта было бы куда полезнее иметь мобильную версию. Потому что если это помощник — то он всегда должен быть рядом, а пк — это всё же не слишком мобильная платформа, даже в формате ноутбука.
webhamster
05.12.2016 20:31MyTetra собирается под Андроид. Только проблема с синхронизацией: я еще на разобрался как в Android запустить git, причем так, чтобы он работал не в своем каталоге, а в каталоге MyTetra.
А если синхронизировать через Dropbox, то выясняется, что Dropbox не хранит файлы на мобильном устройстве: только кеширует последние используемые, и подкачивает из интернета открываемые ручками пользователем.
И та же проблема безопасности: в Андроид программа не может работать в каталоге другой программы. Нужно рутовать, или как-то очень хитро настраивать, в чем я не разобрался.redmanmale
05.12.2016 20:36+1Вместо dropbox для синхронизации можно попробовать Syncthing.
webhamster
05.12.2016 21:51На официальной странице не указаны как поддерживаемые платформы Android и iOs. Там только десктоп. А вопрос то был про мобильные платформы.
ckr
11.12.2016 05:51В копилку средств для синхронизации https://owncloud.org/. Правда, в моем случае (бесплатно) требует свой сервер, за то без ограничений, разве что кроме физических (в сравнении с dropbox, если не ошибаюсь, бесплатно 1гб, а цены на сам dropbox выше, чем на дешевенький голландский vds).
Jogger
05.12.2016 20:42А обязательно хранить данные в каталоге программы? Нельзя во внешнем пользовательском каталоге?
webhamster
05.12.2016 20:55Можно. Лишь бы MyTetra имела права туда писать, а не только читать. В Андроиде именно с этим проблема. И в разных версиях с правами все немного по-разному. Не знаю, зачем такой расколбас авторы подсистемы безопасности андроида устроили.
svboobnov
05.12.2016 22:48Есть jgit он запустится там, где ему укажут. Работает в 3 раза медленнее, чем родной гит, но работает. Вот документация к нему.
vikarti
06.12.2016 07:09для Android есть Dropsync, который позволяет сделать нормальную синхронизацию
webhamster
06.12.2016 10:43На 4pda написано, что не прошная версия синхронизирует только файлы в одном выбранном каталоге.
Вопрос. А подкаталоги в этом каталоге синхронизируются?

potan
05.12.2016 20:00Вы упомянули язык запросов. Можно несколько примеров более-менее нетривиальных запросов на этом языке?
webhamster
05.12.2016 20:39Я упоминал язык запрсов только в исторической ретроспективе.
В MyTetra очень простой поиск с настройками все слова/одно слово, полное слово/подстрока, вся база/выбранная ветка. Плюс можно пользоваться кавычками.
В первой части видеообзора на 29-й минуте рассказывается про поиск:
https://m.youtube.com/watch?v=Bmp_dk2LA6I#t=29m47s
no_one
05.12.2016 20:51Программа просто супер! Автору респектище за такой труд!
Я новичок в программировании, изучаю Java, Python. Давно искал подобную программку, перепробовал разные, но эта о которой я думал. Огромное количество информации из книг я пытался систематизировать сначала в обычном ворде, потом в эверноте и т.д. В голове летала идея такой программы, но реализовать её не хватало знаний. Если бы изучал С++ то по любому участвовал бы бы в проекте. Хотя теперь может и возьмусь за него.
kenrube
05.12.2016 20:57Браво! Мне сразу вспомнился незавершенный, увы, Xanadu Project и HyperCard, позволявший создавать связанные базы знаний на Macintosh годах в 80-90-х. Про последний можно глянуть на Internet Archive. Все они тоже черпали вдохновение из идей Буша
semenyakinVS
05.12.2016 21:05Самая идея отличная… Но уж слишком всё сложно и запутанно в смысле настройки и использования. Например, на мой взгляд, не будут обычные пользователи тратить время на подобное конфигурирование синхронизации. Обычные пользователи любят, когда всё красиво, понятно и работает в один клик. Пока продукт не начнёт соответствовать указанными критериям, он, увы, останется нишевым.
Попробуйте дать MyTetra каким-нибудь знакомыми, которые совсем-совсем не программисты. Пусть они с минимальными подсказками попробуют использовать его. Если им всё будет просто и ясно — значит продукт удался. Если нет — стоит послушать их комментарии и подумать над правками в UI.
P.S.: Если будет время — расскажите, как работает ваш механизм поиска и выборок? Как я понял, можно выполнять какие-то запросы, которые будут перестраивать дерево… Как это реализовано в рамках UI?
На правах рекламыВторой месяц разрабатываю библиотеку+приложение для работы с информацией, насыщенной метаданными. К новому году планирую доделать MVP. Главный приоритет — юзабилити, красота и интуитивность UI. Максимум использования drag&drop для редактирования и просмотра метаинформации.
При этом MVP — это не универсальный продукт, а софт для конкретной предметной области, инструмент для сценаристов и режиссёров, который сможет помочь в организации медиаархивов. С другой же стороны, архитектура проекта строится с прицелом на модульность и расширяемость функционала плагинами. В качестве backend написана универсальная библиотека для хранения информации, насыщенной метаданными.
Автору статьи я уже написал в личку предложение обменяться опытом. Если кому-нибудь ещё интересны детали проекта — обращайтесь. Очень нужны люди со знанием Qt, а также спецы в UI/UX, готовые проектировать новаторские интерфейсы.
P.S.: Предваряю вопросы по поводу саморекламы… В своё время спрашивал администрацию хабры и мне ответили, что ограниченная самореклама без ссылок на сайт проекта допустима. Я же тут даже название не указываю… Если-таки что не так будет — всецело принимаю любое решение НЛО.webhamster
05.12.2016 21:54Сложно и запутанно — это синхронизация, потому что для ее использования нужны сторонние сервисы. Нативной синхронизации нет, ибо это обширная тема, которую я один осилить не могу.
А UI интерфейс в MyTetra очень простой, расчитан на обычных начинающих пользователей.

Harrix
05.12.2016 21:09Такой вопрос. А можно ли в программе показать в одном окне все заметки какого-то раздела?
webhamster
05.12.2016 21:55Это как?

qw1
05.12.2016 22:33Встать на узел дерева, нажать какую-то кнопку и получить в правом окне полный список статей из всего поддерева выбранного узла.
webhamster
05.12.2016 22:41Для чего это может быть нужно?
qw1
05.12.2016 22:48Удобно, если дерево сильно ветвистое, но в каждой ветке по 1-2 записи, с такой кнопкой легче их все пролистать.
Harrix
06.12.2016 19:15Например, у меня в каком-то разделе много каких-то заметок (например, цитаты, куски кода, советы и так далее). Да, чаще всего нужно посмотреть лишь одну заметку, которая выбирается из списка. Но хотелось бы иметь возможность в одном окне увидеть не просто список заметок, а все заметки сразу.
webhamster
07.12.2016 09:40+1> в каком-то разделе много каких-то заметок например, цитаты, куски кода, советы
Вопрос номер один: зачем вам тогда вообще разделы, если у вас одна куча всего?Harrix
07.12.2016 18:08Потому что чаще всего нужно просматривать список по названию заметок. Но иногда нужно просмотреть всё сразу. Например, на сайтах можно посмотреть просто список статей и отдельно каждую статью, а можно посмотреть с подробным описанием.
Причем такой функционал реализован много где касательно сайтов, RSS рассылок и др. Например, в feedly.com можно настроить показ RSS рассылки в виде Title only, а можно в виде Full Articles. А вот в различных менеджерах заметок такого нет. Частично в Evernote реализовано в старом интерфейсе, но не полностью.
lvv1227
05.12.2016 21:40tagspaces — отличная штука для заметок. Используются просто папки и файлы. Нет БД. Поддержка markdown. Есть десктоп версии для всех ОС, есть веб-версия. Проект ативно развивается. Поставил ее на свой VDS, синхронизацию делаю через git. На серваке скрипт синхронизации дергается cronoм, на домашнем компе мануально. Получается еще и история хранится.
На работе блокируется все что только можно (вкл evernote), эта работает без проблем.webhamster
05.12.2016 22:04Использование просто папок и файлов таит в себе такую опасность: ограничение ФС на длину полного пути к файлу, а так же ограничения ФС на длину имени файла или директорий.
Особенно неприятно будет смотреть на свою базу будучи перенесенной с linux на windows, или будучи записанной на флешку с ФАТ или на CD: длиные имена порежутся.

robert_ayrapetyan
05.12.2016 22:02+2Подозреваю, что ваше огромное облако знаний — на 99% состоит из копипасты с интернета (у вас там даже ссылки на сайты). Смысл в таком облаке, кроме как «а вдруг война, отключат интернет и я забуду какой ноутбук выбирал в две тысяча лохматом году и рецепт плова от Егора»?
Вот я когда-то хранил пароли в текстовом файле, когда браузеры не умели это делать нормально, возможно несколько команд и заметок, которые не актуальны уже лет 10, потом понял что все это не нужно, готовые решения по деплою заскриптованы и являются частью проекта, пароли хранятся в браузере, туториалы и книги по ЯП — да господи, любой сайт и форму пестрит подборками, всей жизни не хватит перечитать, а по конкретному вопросу — гугл в помощь. А специфические вещи, которые делаютсч часто и их нет в гугле (как подмонтировать айфон в фрибсд например UPD: уже есть) и так помнишь.
Не обижайтесь, но вы этакий «цифровой Плюшкин» 21-го века.
Почему-то вспомнилось два случая:
1. Знакомый качал и хранил терабайты каких-то док. фильмов конспирологического содержания, забив жесткими дисками всю комнату. На вопрос «зачем если все есть на торрентах» отвечал что-то невнятное, типа так надежнее.
2. Сосед по гаражу, который тащил туда всякий хлам из близлежайших окрестней. Какие-то ножки от кроватей, любой найденный гвоздь на улице и т.п. Гараж был забит сверху донизу всем этим, при этом машина ржавела на улице…webhamster
05.12.2016 22:23+399% — это вы загнули. Процентов 50 наверно есть, остальное лично переработано в удобный мне вид, сделана выжимка.
Но должен вам сказать, что скорость поиска и нахождение именно того, чего записывал — гораздо выше, в разы выше чем в интернете через поисковики. Поисковик мне никогда не даст такую релевантность, как в моей собственной базе. Вы просто такими вещами не пользовались и не знаете всех удобств и достоинств.
И кроме того, я бы не был столь категоричен в рассказах о том, что интернет есть везде и всегда и никуда не денется. Вот вам ссылочка для расширения кругозора:
Корпорация «Росатом» полностью отказалась от сети Интернет
Это происходит сейчас, в наше время. В таких условиях наличие маленькой личной плюшкинской копии интернета — просто спасение для специалиста.robert_ayrapetyan
06.12.2016 01:37Можете дать 5 публичных и самых полезных, с вашей точки зрения, записи из своей базы? То что на скринах гуглится за 5 секунд.
webhamster
06.12.2016 09:49+2Гоголь то тут причем? Мы наоборот говорим о личном поиске в заранее собранных данных. Держание копии открытых данных в интернете — это дополнительная фишка, типа «ребята, мне не жалко поделиться» ну и плюс резервная копия.
По полезным записям, вот например: http://webhamster.ru/mytetrashare/index/mtb0/1337019863kodwj7p9ip
То, что про Debian и Scientific — это мои записи. Плюс еще есть по CentOs и Fedora в приватных записях, и чтобы вынести в открытые мне надо почистить от настоящих IP-шников и прочих локальных подробностей. Надо этим заняться, но на это нужно время. Но мне то и так хорошо: эта информация у меня и так есть. Набрал «1С Linux» и видишь сразу то, что записывал. Это не гугол, когда пользователь ищет что там расскажут другие, тут иной принцип.robert_ayrapetyan
06.12.2016 22:26Я и пытаюсь понять ценность такого принципа. Смотрите, эти туториалы по установке — ими можно и нужно делиться в интернете (как вы и сделали, и их нашел гугл и вы сразу в выдаче по 1С на дебиан на первой странице). И так делают миллионы людей, и в этом сила интернета. Теперь вы говорите, что есть еще по CentOS и Fedora в черновиках и вы хотели бы ими поделиться, но руки не доходят… Уверяю вас, что за два года ваш туториал стал неактуальным, если вы им не поделились вовремя, то пользы от его хранения никакой, и даже более того — один вред, руководствуясь старыми принципами установки вы пропускаете что-то важное, что появилось за два года (грубо говоря — в Федоре появился новый менеджер пакетов, или базу постгресовскую уже по другому модно сетапить и вообще там уже 9.6 версия и т.п.). Опять же, если это рабочие проекты, то все эти скрипты должны быть частью репозитория проекта, если это хобби… странное у вас хобби, устанавливать 1С на разные линукс-сервера. Не пытаюсь вас ни в чем убедить, просто не могу понять полезность хранения устаревших и неактуальных записей.
frog
07.12.2016 01:24Сам давно пользуюсь подобными offline заметками и ощущаю, в некоторых аспектах, огромное преимущество перед Интернетом (который вполне быстр). Преимущество в том, что заметки заточены лично под меня. Скажем, если по какой-то теме я что-то твёрдо знаю и помню, я не буду записывать это в заметку по данной теме. Запишу только то, что не помню. В следующий раз, когда я в эту заметку полезу, то, если увижу там банальную (по моему нынешнему мнению) информацию, я её оттуда сотру и, может, добавлю что-то новое, чего ещё не помню наизусть.
Таким образом годами поддерживается некая база знаний, которая удобна в работе именно для меня и актуальна именно в плане удобства для меня.
Но, конечно, делиться этой информацией с другими — довольно бессмысленно.
azsx
07.12.2016 05:36Я и пытаюсь понять ценность такого принципа.
1. Автор весьма неудачно подобрал примеры, они реально гуглятся за 5 минут.
2. Для кого то примонтировать nrg в линукс — это малопонятная фигня, которую надо вспоминать. Мне для этого записулька не нужна. Зато вот предложат мне вывести атомный реактор на рабочий режим — ух я порезвюсь перед большим балабумом.
—Не пытаюсь вас ни в чем убедить, просто не могу понять полезность хранения устаревших и неактуальных записей.
Вот я недавно искал как можно включать и выключать энергосберегающий режим монитора в винде по реакции на внешний сигнал с lpt порта. Поиск этой информации занял много времени, задавал вопрос на форуме. Конечно я всё сохранил в свою записку о компах.
Другой вопрос сложный импорт, невозможно работать с большим объёмом информации. Коленные велосипеды, я уж на мопеде тогда.
— Насчёт поиска в интернете. Две проблемы: 1. поиск так или иначе ориентирован на контекстную рекламу, то есть надо выдать такой текст, чтобы вы ткнули на рекламу; 2. авторские права и просто скан удаляют с индекса. Как вывод для специалистов поисковые системы — это ужас какой-то. Дожились, яндекс за деньги будет предлагать полные результаты поиска с точным вхождением. https://extract.yandexdatafactory.com/ru/ Кругом приличные люди, поэтому особо релевантность информационного поиска никто не комментирует. Но он ужасен.semenyakinVS
07.12.2016 14:43авторские права и просто скан удаляют с индекса
Если не ошибаюсь, в гугле с недавних пор появилась возможность поиска по лицензии. Сейчас проверил — в поиске по картинкам точно есть, в «инструментах поиска» -> «права на использование».
webhamster
07.12.2016 10:11> И так делают миллионы людей, и в этом сила интернета.
И у меня это делается на автомате. Но некоторые записульки я сразу пишу обезличенно, и сразу размещаю их в открытой ветке. Некоторые задачи я начинаю описывать обезличено, но если сложность начинает зашкаливать и обрастать локальными подробностями, переношу в приватную ветку.
> Теперь вы говорите, что есть еще по CentOS и Fedora в черновиках и вы хотели бы ими поделиться, но руки не доходят… Уверяю вас, что за два года ваш туториал стал неактуальным, если вы им не поделились вовремя, то пользы от его хранения никакой, и даже более того — один вред, руководствуясь старыми принципами установки вы пропускаете что-то важное
Именно поэтому я всегда указываю версии того, с чем имею дело. И в углу справа вверху есть дата публикации (меня вообще вымораживает, когда в половине блогов указывается день и месяц, но не виден год). И мне постоянно приходится иметь дело с устаревшими дистрибутивами, так что не думайте, что эта информация никому не нужна.
Гораздо хуже, когда в текстах не указываются версии, вот например старые тексты в Фидо по Linux и UNIX часто грешили этим — инфа 10-ти летней давности выдавалась как свежая. И народ вообще не ориентировался во времени, и невозможно было понять, устаревшая это информация или нет.
qw1
05.12.2016 23:03+1Смысл в таком облаке, кроме как «а вдруг война»
Чтобы было за что зацепиться. Например, был случай, когда 2 года назад видел статью о тонкостях настройки SOAP для 1c, но в нужный момент никак не мог вспомнить, по каким словам её гуглить.
А если бы написал выжимку в текстовый файлик, который сохранился бы в надёжном месте, и гуглить бы не пришлось — скопипастил настройки из файла и всё готово.
Не обижайтесь, но вы этакий «цифровой Плюшкин» 21-го века
Вообще да, база эта навевает такую ностальгию по временам 2000-х, когда ходили копии сайтов rsdn и delphi kingdom в формате chm, с таким же деревом слева и заметочками/статьями справа )))
Интернет был не всегда под рукой — только ночью, или в интернет-кафе. Поэтому такие сборники были хороши.robert_ayrapetyan
06.12.2016 01:31А если бы написал выжимку в текстовый файлик, который сохранился бы в надёжном месте, и гуглить бы не пришлось — скопипастил настройки из файла и всё готово.
Как раз про это написал, что все что используется для настроек\деплоя должно скриптоваться и становиться частью проекта (по сути это код\данные проекта), а не храниться в записках непонятных.
Не, ну может какой-то сферический эникейщик студент, который бегает по соседям настраивает винду, может ему и пригодится… не знаю… лицензионный ключ винды… Но тру эникейщики помнят такое наизусть )
Cheater
06.12.2016 14:29+2> Смысл в таком облаке, кроме как «а вдруг война, отключат интернет и я забуду какой ноутбук выбирал в две тысяча лохматом году и рецепт плова от Егора»?
Именно в этом смысл. Любители хранить всё в Интернете обычно начинают выглядеть довольно беспомощно, если этого доступа их лишить.
> Вот я когда-то хранил пароли в текстовом файле, когда браузеры не умели это делать нормально
Браузер — не единственное место, где надо вводить пароль.
> готовые решения по деплою заскриптованы и являются частью проекта, пароли хранятся в браузере
Это всё довольно частные случаи.
> А специфические вещи, которые делаютсч часто и их нет в гугле (как подмонтировать айфон в фрибсд например UPD: уже есть) и так помнишь.
Кто как. Сегодня помнишь, потом проходит 2 месяца и знания улетучиваются за ненадобностью, а потом та же задача возникает снова. Каждый раз в гугл лезть? А если руководство ищется только сложным поиском и находится на 10 странице выдачи? А если страницы с руководством уже нет? А если интернета нет?robert_ayrapetyan
06.12.2016 22:43Каждый раз в гугл лезть?
Да, они тратят миллиарды долларов, чтобы этот процесс был безболезненным и естественным.
А если руководство ищется только сложным поиском и находится на 10 странице выдачи
Ой, очень сомнительный и изумительно редчайший кейс, у вас такое случается чаще, чем раз в году?
А если страницы с руководством уже нет?
Значит оно неактуально и авторы посчитали что по нему вредно\небезопасно что-либо делать. Да, данные устаревают, и их нужно вычищать.
А если интернета нет?
Еще лет 10 назад было актуально, сейчас уже нет.Cheater
06.12.2016 23:37+1> Да, они тратят миллиарды долларов, чтобы этот процесс был безболезненным и естественным.
Они могут потратить хоть триллионы, сомневаюсь что это поможет им реализовать фичу «вернуться назад во времени на N месяцев/лет и выдать мне содержимое страницы c решением, которую я тогда нагуглил, причём сделать это за 1 минуту и не заставляя меня повторно гуглить».
> Ой, очень сомнительный и изумительно редчайший кейс, у вас такое случается чаще, чем раз в году?
Да. Пример: разнообразные математические задачи с mathoverflow (математические проблемы часто трудно гуглить из-за абстрактности ключевых слов), бесплатные прокси, некоторые специфические задачи по настройке Linux (например настройка UEFI с подписанными загрузчиками).
> Значит оно неактуально и авторы посчитали что по нему вредно\небезопасно что-либо делать.
Это не всегда так.
> Еще лет 10 назад было актуально, сейчас уже нет.
Я вас умоляю… Отъедьте километров на 50 из города, скажем на дачу, и попытайтесь с местным мобильным интернетом провести активное гугление какой-нибудь более-менее нетривиальной проблемы (например, как раздать интернет с ПК с USB-модемом). Или то же самое, будучи туристом в городе в другой стране.r3verser
07.12.2016 00:30Кстати да, то что гуглилось на первой странице год назад, уже может быть на 25, а предыдущие 24 страницы забиты сеошным хламом…

StayAtHome
07.12.2016 10:13Сегодня помнишь, потом проходит 2 месяца и знания улетучиваются за ненадобностью, а потом та же задача возникает снова. Каждый раз в гугл лезть? А если руководство ищется только сложным поиском и находится на 10 странице выдачи?
Evernote решает эту проблему установкой браузерного расширения, которое отображает в результатах поиска Гугла — результаты поиска по своей базе заметок. Автору — как идея для развития.
stepik777
05.12.2016 22:19+7https://github.com/xintrea/mytetra_dev/blob/experimental/src/libraries/crypt/RC5Simple.cpp
Отвлекли: когда будешь ложиться спать, закрой у ребенка окно
Отвлекли: папа, бабушка нам дала адрес бабушки Люды
Отвлекли: таймер, готовить макароны
Отвлекли: сканируй письмо
Отвлекли: надо покушать, кончай питаться йогуртами
Отвлекли: сходи в магазин Магнит, у нас есть нечего
Отвлекли: попугаи наверно голодные, кто бы их кормил, надо покормить
...:)
webhamster
05.12.2016 22:29Блин, вроде бы я это выпиливал. А да, выпилил в репозитарии самой библиотеки, не выпилил в копии в MyTetra.
Это я просто помечал места, где меня отвлекали, чтобы внимательнее их просмотреть позже, чтоб ошибок не понаделать.r3verser
06.12.2016 17:34Отвлекли: потренируй мне складку
оО :)))AndreyDmitriev
06.12.2016 17:53Папа, мама, я — спортивная семья!
Вообще мне это хорошо знакомо — у меня только-только родились близнецы, а я как-то взял на дом доделку — реализовать преобразование Фурье-Меллина. Жаль, я не был так дотошен с комментариями.
svboobnov
05.12.2016 22:58Я места, на которых меня отвлекли, помечаю заметными восклицаниями: // Абырвалг!!! //ЫЫЫ-- //АРРГХ
Этих восклицаний немного, их ярко выраженная бессмысленность привлекает внимание, и служит меткой. Даже если IDE закроется, я найду их средствами редактора и восстановлю картинку, которую живописал в коде. И ничего личного в код не попадёт.
Nikobraz
05.12.2016 23:42Мне самая первая версия больше понравилась. Наверное в целях обучения плюсам начну пилить свой велосипед на эту тему.

ZakharS
05.12.2016 23:52+3Спасибо за статью — очень основательно. Сам такой идеей болею давно — мне тоже важно не зависеть от проприетарных форматов и различных облаков. До сих пор храню все в файловой системе, папки созданы для крупных рубрик, а внутри — или подпапки или файлики с говорящими именами. Чтобы не погрязнуть в куче хлама, постоянно чищу лишнее. Пользуюсь накопленным довольно часто. Но эта система имеет массу недостатков — нет тегов (древовидность файловой системы, как здесь верно заметили, не всегда подходит), закладки все равно хранятся отдельно в браузере, текстовый файл имеет тенденцию разрастаться и структура теряется, помимо моих заметок в папках лежат книги.
Но в вашей системе тоже кое-чего не хватает. В том же evernote очень удобно сграбить веб-страничку, выделив нужную область или все целиком. В вашем случае придется копировать и вставлять вручную. Еще не очень понял, ищет ли ваша программа внутри документов (тех, которые в виде аттача прилагаются к записям). Полагаю, что нет.
Пока писал, подумал, что проприетарный формат не так уж и страшен. Думаю, что большинство программ, включая Evernote, умеют экспортировать свою базу во что-то открытое, что можно потом распарсить.
P.S. В обучающем видео совершенно прекрасные примеры записей в дереве :-) Про космодром Восточный и головные обтекатели. Это та самая ваша основная работа, не связанная с программированием? :-)webhamster
06.12.2016 07:13Вы правильно поняли, движка поиска внутри прикрепленных документов нет. Если найду подходящее решение, прикручу.
Основная работа — атомная отрасль, не космос.
svboobnov
06.12.2016 20:30В файловых системах ext2, ext3/4, f2fs(линуксы), HPFS(маки) и в новой NTFS(начиная от Win7) есть возможность делать ссылки (link) то есть, файловая система, при должном упорстве, может быть точно такой же базой знаний.
Пусть есть библиотека (книги в разных форматах, потому не поддаются индексации в myhomelib)
По_Авторам Авдеев Баратынский Жуковский Яковлев //а рядом есть каталог ссылок По_Темам Гидравлика -- Жуковский Поэзия -- Баратынский Авиация -- Яковлев
И таким образом, в древовидной файловой системе имеем граф. У меня вот упорства не хватает взять и разложить всё по полочкам, а файловая система ext4 такое вполне позволяет, да.OnkelTem
06.12.2016 20:44IMHO, если делать напрямую, через файловый менеджер, то потом убьешься а) рефакторить такое дерево и б) обеспечивать ссылочную целостность (даже с учетом повсеместного использования ссылок). Так что как средство хранения — да, как front-end — нет :)
semenyakinVS
06.12.2016 23:44Так а hardlink чем для этих задач не подходят? Вроде, они и раньше были
svboobnov
07.12.2016 00:03Подходят, конечно. Только у меня за 12 лет собралось 300ГиБ книг, картинок и статей разного вида. Какие-то давно пора выбросить, какие-то до сих пор интересны и полезны. И всё лежит на внешних хардах + давно когда-то записано на DVD.
webhamster
07.12.2016 10:22В файловых системах ext2, ext3/4, f2fs есть возможность прикрутить ACL с EA – Extended Attributes. И тогда даже можно файлам писать теги.
На ЛОРе был один такой товарищ, который утверждал, что ему линков и EA хватает за глаза, и ничего вообще не нужно делать, все уже есть. Не помню его имени к сожалению. Думаю, что рано или поздно он столкнулся с непереносимостью своих данных на другие платформы.
Dmitriusan
06.12.2016 07:14Несколько лет назад поднял для себя движок mediawiki (opensource, на нем крутится Википедия). Неплохой вариант. Его можно кастомизировать плагинами (есть большая коллекция на сайте), есть поддержка тегов, древовидной структуры, стандартизированная разметка, поддержка многими программами, мобильная версия, поддержка разных языков, версионирование и т.д. Точно безопасен, потянет миллионы записей, очень хорошо оттестирован и поддерживается.
Из недостатков — ограниченный поиск из коробки (но есть плагин с Lucene), немного замороченная заливка рисунков, нет поддержки диаграмм (кроме встраивания через plain html сторонних сервисов). Хотя может это и обходится, давно не проверял новые плагины.

akledirs
06.12.2016 07:14+2Ух, как это всё близко к моим поискам нечто схожего. Тоже перебрал много различного софта, даже TiddlyWiki попробовал. Какое-то время пользовался OneNote пока не начал задаваться вопросами приватности. В конечном итоге я просто пересел на… Microsoft Word. Да, вот так вот просто.
Ту самую древовидную структуру обеспечивает использование стилей для заголовков, автоматически формируемое содержание и панель навигации сбоку.
Формат docx — уже открытый, открыть не проблема почти на любом более менее современном устройстве.
Поддержка шифрования файла.
Все заметки в одном файле — благодаря чему легко решается вопрос бэкапа и переноса на другое устройство.
azsx
06.12.2016 07:39Постоянно использую такие деревья. Всю жизнь более чем целиком хватало portable версии dreamweaver, но однажды купил платную программу на паскале и прикипел к ней. Стоит 15 тысяч, так что не уверен, что надо давать рекламу.
В есть всё, что мне надо, но имеются проблемы, учтите как пожелания.
1. Программа ужасно работает с данными более 100 тысяч записей. И разработчик сказал — это неисправимо. В dreamweaver было хуже.
2. В программе нет прав доступа, то есть нельзя нанять кого то, чтобы он в основной базе за тебя чо то набил. Разработчик верно пишет как надо выкручиваться, но заморочно.
В вашей программе полно недостатков, но мне недостатки, вам всё хорошо.
— Мне крайне интересен другой вопрос, может он не по этой теме, но спрошу. У меня есть несколько миллионов вопросов и ответов (с майл) и 600 форумов. Мне крайне интересно создать отвечающего бота, то есть вы ему вопрос или несколько сообщений, он вам релевантный ответ.
Сейчас такие базы хранятся в текстовых файлах (знаю всего 1 такую программу). А как или в чём их хранить более правильно? То есть какие книги надо почитать, чтобы делать такие программы по науке?webhamster
06.12.2016 08:50Видимо мы говорим о разных классах программ. Здесь обсуждается менеджер персональных данных. 100.000 записей для персональной БД как-то очень много (хотя, в пределе, MyTetra выдержит и больше, просто по моим подсчетам изменение XML-дерева на 100.000 записей будет занимать около 2 сек. на современном средненьком компе), тем более что вы пишите про разделение прав доступа — это явно не персональная база.
Базы, о которых вы говорите, разумно хранить в NOSQL-ных БД. Большего вам не скажу, потому что проектов с такими объемами у меня не было. Вам нужно поговорить с нормальным проектировщиком, у которого за плечами есть подобные проекты с такими объемами данных. В любом случае это будет клиент-серверное приложение, не монолит на файлах как у вас скорее всего сейчас на дельфи.azsx
06.12.2016 09:18+1Большего вам не скажу, потому что проектов с такими объемами у меня не было.
Вдруг кто другой ответит?
100.000 записей для персональной БД как-то очень много
Просто как и многие в топике я делаю парсинг с интернета и мастерю поиск под себя.
разумно хранить в NOSQL-ных БД.
Абсолютно точно нет.
В любом случае это будет клиент-серверное приложение, не монолит на файлах как у вас скорее всего сейчас на дельфи.
Монолит очень удобен, вот если бы он изначально сделал под внешнюю БД и разделение прав на уровне БД — было бы очень здорово. Но как есть.
Denkenmacht
06.12.2016 09:49-5Такая программа — это ретроградство, правильно выше написали, что это похоже на то, как нездоровые люди забивают гараж ненужными вешами. Зачем изобретать велосипед, если можно все отправлять себе на почту (заметки, файлы, статьи)? Зачем нужна древовидная структура, если есть поиск? Надо всего лишь правильно называть темы писем (в вашем случае заметки и файлы, хотя поиск по тексту файлов легко этот вопрос решает). Архивы почты можно сохранять локально, ничего никуда не пропадет, к ним можно подключаться почтовым клиентом. У вас решается проблема шифрования, кроссплатформенности, вэб/не вэб. Извините, но это ужас какой-то — городить отдельное приложение ради того, чтобы записывать, какой ноутбук выбрал и купил 10 лет назад.
webhamster
06.12.2016 09:59Не понимаю, зачем использовать для вполне определенного вида деятельности программы (почтовые), которые для этой деятельности не предназначены. Они же тупо неудобные. Например, в стандарте почты нет такого понятия как текстовые метки, и в почтовых клиентах они если и есть, то сбоку припёку. Я написал, что пробовал делать так как вы говорите в Eclipse — проблемы те же. Нет никакого смысла использовать программу, не предназначенную для того, что вы хотите на нее возложить.
ZakharS
06.12.2016 10:25+1Дерево против тегов — это вопрос индивидуальный, выше уже в комментариях обсудили. Кому-то удобно запомнить путь в дереве, кому-то проще воспользоваться поиском. Лучше иметь оба способа категоризации.

lightman
06.12.2016 11:24+2Дерево против тегов
А зачем выбирать? Дерево тегов – спасение для всех! По умолчанию пользуемся как обычным деревом (каждая запись имеет один тег), но при необходимости прикрепляем запись к множеству листьев, добавляя к ней дополнительные теги.

alan008
06.12.2016 10:05+1Рекомендую посмотреть на The Brain (Personal Brain)
webhamster
06.12.2016 12:44Я смотрел его перед тем как писать MyTetra. Это интересная штука из мира mind-map, но мне она оказалась неудобной. Там интерес в том, что создаются связи между сущностями, и можно выделять сущности в фокус своего внимания, и видеть связанные сущности. Насколько помню, там был режим «размышления», когда тыкаешь на центральную сущность, и программа начинает рандомно переходить к другим связанным сущностям. Ты все это наблюдаешь, и типа можешь увидеть какие-то позабытые или дальние взаимосвязи, что поможет принять какое-то решение относительно рассматриваемой сущности.
Кстати, элемент этого механизма я перенес в MyTetra. В MyTetra кликабельные метки, а метки — это связи между записями (а записи можно рассматривать как сущности). Тыкая по меткам, можно в поиске получать списки связанных записей. И так можно блуждать по записям, причем «уйти» можно очень далеко, так что удивительно, как в базе может быть все взаимосвязано.
zedxxx
06.12.2016 10:29Возможно, мне помогли бы книги, которые мне очень рекомендовали:
Николас А. Солтер, Скотт Дж. Клепер, «C++ для профессионалов»
Брюс Эккель, «Философия С++» (1-й том)
Брюс Эккель, «Философия С++. Практическое программирование» (2-й том)
но я нигде не могу найти их в бумажном виде. С экрана же глубокого чтения у меня не получается. Максимум что могу читать — художественную литературу с книгочиталки. Но техническую не воспринимаю.
Абсолютно согласен про читалки, на них адски сложно читать техническую литературу. Но выход есть — самостоятельно распечатать интересующую книгу не такая уж и проблема. Лично я печатаю их через FinePrint в виде буклетов, получается достаточно удобно. Обычно делю книгу на несколько частей, с расчётом, чтобы буклет выходил не более 35-40 листов A4 (~150 страниц книги). Буклеты между собой не сшиваю, а просто пользуюсь ими как небольшими томиками. Поскольку литература техническая, то обычно томика хватает на неделю/другую вдумчивого изучения. Помимо того, что такой томик можно всегда легко взять с собой, в нём можно смело делать пометки на полях или выделять особенные моменты маркером (такой вандализм я бы не смог себе позволить с покупной книгой). Цена вопроса — лазерный принтер и немного сноровки.

optiklab
06.12.2016 12:33Спасибо за статью, интересно. Тоже занимался поиском подобного решения пару лет назад. Пробовал ведение своих заметок в Word/Excel, потом OpenOffice, потом txt, потом Markdown… В итоге эти поиски привели меня к Microsoft OneNote, которым пользуюсь до сих пор и души в нём не чаю.
Бесплатные клиенты под Windows и MacOS, все мобильники, а также веб ( то бишь Linux, тоже не вопрос). Хранию и форматированный тект, и картинки, и ссылки, и просто дофига всего с раскладкой по разделам и древовидной структурой.
Формат, конечно, не открытый, но бэкапить свои заметки никто не запрещает, багов особо найдено не было (а потому текущей версией можно пользоваться, не ожидая подвоха от микрософтовцев).

VladSavitsky
06.12.2016 14:27Я тоже пытался делать свою личную базу знаний. На базе движка WikiMedia и других, но отказался в пользу stackoverflow. Не смотрели в эту сторону?
webhamster
06.12.2016 15:45+1А что на него смотреть? Я там зарегистрирован, написал туда несколько вопросов без ответа, хоть на Ru, хоть на Eng. Такое впечатление, что с теми вещами, с которыми мне приходится разбираться, никто в мире больше не работает. Поэтому мне и нужна программа, в которую я потихоньку собираю все крохи информации, и потом сам решаю проблему.

metalim
06.12.2016 15:12Идея — 5. У самого такая была. Реализация — 2. На уровне хобби-проекта Самоделкина. Где-то скотчем, где-то степлером…
metalim
06.12.2016 15:16Ощущение, что пользуешься Web 1.0 страницей с фреймсетом. Кеширования нет, опережающего чтения/синхронизации нет.
webhamster
06.12.2016 15:48+1Конечно, вы могли сделать лучше, но не сделали. Где вы нашли в Qt-only проекте скотч и степлер — непонятно.
metalim
07.12.2016 01:56+1К любой программе я подхожу с точки зрения нового пользователя, не видевшего проект и не понимающего зачем он нужен. Поясню на MyTetra Web Client.
1. Первое что бросается в глаза в веб клиенте: выскакивающее окно времён HTML 2.0 для ввода адреса. Какого адреса, для чего он нужен — читайте доки. Ссылку на веб-клиент с конкретной базой можно сделать? А ссылку на конкретную страницу в базе?
2. Введёный адрес сохраняется в куках. Другую базу откроешь — кука перепишется. Списка открытых баз нет, две базы открыть разом нельзя — при рефреше останется одна.
3. Каждая запись — отдельный запрос на сервер. При повторном открытии — снова запрос.
4. Редактирование в веб клиенте отсутствует в принципе. Просто читалка.
Допустим веб клиент на самом деле не предназначен для широкого использования. Тогда зачем он? И в каком клиенте можно редактировать базу онлайн? У всех конкурентов есть онлайн редактор.
А у вас в инструкции по использованию первым делом расписаны шаманские манипуляции с репозиториями.
Ну не тянет оно на «самую нужную программу на свете». Понятно, что это ваше детище, вы его долго и с любовью разрабатывали, но до нормального публичного использования её ещё пилить и пилить. Сейчас это утилита для узкого круга лиц, изучающих всякие диковинки. Доки и статьи не помогут расширить аудиторию. Такое могло прокатить 20 лет назад, когда подобного софта было мало. Сейчас нужен интуитивно понятный интерфейс.webhamster
07.12.2016 10:26Вы точно ничего не перепутали? Цитата из текста:
Этот клиент был написан в 2012 году, и с тех пор я его не развивал. Это очень простая оболочка, в которой не сделано даже поиска по названию записей и тегам. Просто демонстрация того, что базу MyTetra можно увидеть в браузере прямо в Интернете.
Странно было бы ожидать всего того, что вы написали.
OnkelTem
06.12.2016 15:16+1Очень и очень интересно!
Заранее прошу простить объемность комментария.
Во-первых, был удивлен как же много людей интересуется темой организации знаний, судя по кол-ву комментариев и разнообразию предложенных решений.
Во-вторых, проникся уважением к автору программы за такие титанические усилия и способность доводить дело до конца.
Позвольте теперь озвучить несколько мыслей по существу проблемы.
Многие годы я искал инструмент, который позволит не сколько накапливать знания, сколько помогать самому процессу познания. На данный момент я располагаю следующими выводами:
- Процесс, способствующий познанию ч-л можно изобразить деревом.
- Записанный таким образом процесс и является предметом накопления. Поэтому решаются две задачи сразу.
- Дерево по одному и тому же предмету индивидуально.
- Узлом дерева является любая информация — текстовая, графическая, и вообще аудиовизуальная. И вообще, узел дерева может иметь атрибуты любых типов, включая ссылки на другие деревья.
- Вариантов ветвления от каждого узла может быть несколько.
- Заполнение дерева в каждый конкретный момент выполняется самым естественным образом, которым располагает человек в этот момент.
- Рефакторинг дерева должен проводиться также просто, как и заполняться. Поэтому в идеале дерево — это иерархический список с возможностью редактирования.
Завершенное дерево познания какого-либо предмета является личным сценарием, который можно легко повторить/проиграть в будущем с целью восстановления знаний о предмете. Но он может быть и переработан (отрефакторен) с целью создания конспекта и например публикации. В общем, все должно быть предельно гибким.
Дальше встал вопрос поиска инструмента, позволяющего работать с такими деревьями. К моему сожалению идеального инструмента я так и не нашел, но есть близкий к идеалу. А пробовал я различные решения, включая записные книжки типа TomBoy, монстров типа Evernote и всевозможные mind-maps. Например, типичное ограничение всех mind-map — единственный вариант ветвления, а зачастую — невозможность работать с простым иерархическим списком, а нужно мышкой тыкать.
Насколько я могу судить из описания предлагаемого инструмента, он вряд ли будет идеальным для таких деревьев. Например, внутри узла дерева, внутри заметки, дерево как-бы "кончается", а ведь оно может и должно продолжиться, при появлении новых данных. Также не совсем понятно насколько просто выполняется рефакторинг дерева.
Но я спешу порадовать тех, кто мыслит примерно так же как я и ищет то же самое. Самое лучшее, что существует на данный момент это https://rizzoma.com/ — клон ушедшего Google Wave. Именно здесь вы пишете простой текст, который может быть и списком, а при возникновении ветвления в мыслях — просто создаете ветку по
Ctrl-Enter. Проблем масса, но ничего лучше я пока не встречал.webhamster
06.12.2016 15:55Ваши мысли понятны, но идеального ответа на ваши вопросы походу нет ни у кого.
> Например, внутри узла дерева, внутри заметки, дерево как-бы «кончается», а ведь оно может и должно продолжиться, при появлении новых данных.
Внутри заметки можно создавать ссылки на другие заметки. Поэтому ничего не кончается.
> Также не совсем понятно насколько просто выполняется рефакторинг дерева.
В дереве сделаны классические возможности по управлению ветками и подветками: создание, копирование, вставка, удаление, перемещение. Таким образом, дерево можно менять как угодно.OnkelTem
06.12.2016 15:59+1Я мечтаю такое создать. Пока есть только десятки килобайт мыслей (записанных в Риззоме, а до этого — в TomBoy) за года наверное 3 и страх перед задачей. В идеале, я бы хотел получить инструмент, с помощью которого можно и знания накопить и сайт создать (внезапно). Ведь результатом — вычищенным и причесанным деревом — можно делиться, а это может быть какое-то исследование, а значит вот она и идея сайта. Как-то так.

caballero
06.12.2016 18:43Спасибо автору — как раз думал чем себя полезным занять — но я стопроцентный технарь с нулевой креативностью — сам ничего придумать не могу. Но раз такие ништяки востребованы есть смысл попробовать изобразить нечто подобное. Редко натыкаешься на полезную идею которая многим нужна но как ни странно не реализована для широкой публики (либо платное либо кривое либо еще чего).
Разумеется веб решение — кроссплатформенность, кроссбраузерность, возможность развертывания как saas сервиса так и персонального решения в виде сборки с каким нибудь wamp, легкость шаринга ссылок.
Само собой — оперсорс проект.
Даже если дальше обдумывания дело не пойдет — все равно какое никакое развлечение на праздники.
И еще такая мысль — в инете ща контента наверно уже петамегабайты или какая там дальше разрядность. Поисковики, предназначенные для отбора данных, справляются не ахти, особенно если перед поисковиком стоит дилемма — выдать юзеру нужное или то за что заплатили чтобы выдал. Посему не исключена тенденция к распространению ресурсов с ручной модерацией данных. Подобные проекты могли бы быть вариантом решения организации баз знаний. ИМХО конешно.
Saffron
06.12.2016 18:53Каждый раз, когда я зависал над листком бумаги, чтобы подумать, или записывал заметки в текстовый файл, я думал о том, что неплохо было бы наконец-то радикально решить эту проблему софтварным способом, а то как в железном веке живу, а не песочном.
Всё сводится к тому, что мне нужно три вещи, которые никогда не идут вместе: удобное редактирование, семантика, презентация. Вот если что-то хочется по-быстрому записать, то конкурентов org-mode нет. Но никакого представления данных кроме деревянного нет. Семантики тоже нет, разве что встроить таблички. Если хочется годного представления, обзоримого глазу — берёшь любой mindmap и раскладываешь вручную схемки. При этом удобство редактирования очень мало, а семантики снова нет. Единственный вариант получить семантику — это какая-нибудь графовая технология. Дохлый стандарт TopicMap. Примитинвый, но рабочий RDF. Вот в самом деле, хорошо работает, проверял на примере protege. Ресолверы работают как надо. Можно задать произвольную формулу и она материализует объекты — это как формулы экзель, только не привязанные к таблице, а поверх произвольного графе. Зато совершенно невозможно редактировать, и смотреть на записи можно только по-одной. А хотелось бы произвольно разложить информацию по рабочему столу и сохранить эту визуализацию, поскольку презентация значит для осмысления много.
Конечно, персональный менеджер должен быть ещё и социальным. Во-первых, должен допускать возможность шарить информацию, что для опенсорса и открытых стандартов происходит само собой. Во-вторых, надо извлекать информацию из сети. Ну что-то вроде интеграции со scrapbook. А можно не только паразитировать на браузере, но и добавлять возможности — например делать запросы к гуглу. В браузере ты должен прощёлкивать стринички вручную, чтобы с удивлением узнать, что половина выдачи тупо не содержит слов, указанных в запросе. Было бы просто замечательно, если бы извлечение информации было тоже автоматизировано.
Потому что удобство, интеграция и автоматизация очень важна. Без них проще будет полагаться на собственную память, чем привлекать к работе PIM. Это всё равно что бекапы без автоматизации. Так что я продолжаю искать.OnkelTem
06.12.2016 19:42Совершенно верно! Именно визуализации не хватает чаще всего. Попытка сделать данные одновременно употребимыми для их ввода и для визуализации к успеху не приводит — например, это то, что делается в mind-map. Иначе говоря, то, что удобно заполнять обычно не сильно удобно созерцать, и обратно. Кроме того, обычно нужно несколько проекций для одних и тех же данных, так как цели визуализации могут быть разные.
Также поддерживаю акцент на социальности. Данные должны быть доступны другим для своего использования.
Поэтому задача кмк состоит в создании веб-инструмента, который позволил бы просто и удобно вводить структурированные данные и который бы предоставлял API для доступа к данным, а также имел ряд встроенных визуализаторов.
r3verser
06.12.2016 19:57Структурированные по каким параметрам\алгоритмам?
OnkelTem
06.12.2016 20:12Ничего конкретного ввиду не имел, это классическая задача структурирования, где параметры: точка зрения, масштаб и цель моделирования. В нашем случае организации знаний — всё то же дерево, иерархические списки. Структура выбирается автором согласно его видению естественной иерархии этих данных, но скорее всего — для удобства ввода. Если данные структурированы удачно, их можно визуализировать сразу, если неудачно, возможно потребуется ряд преобразований (производные отношения, аля Views in RDBMS), чтобы изменить структуру, сделать выборку.
semenyakinVS
07.12.2016 00:03+1Ох, как же замечательно видеть такую активность в обсуждении темы баз знаний. И ещё приятнее видеть людей, которые идут по моему пути размышлений!.. Именно такую штуку делаю в данный момент. Именно с прицелом на максимально удобную визуализацию и, в перспективе, с прицелом на социальность. К новому году, если всё пойдёт как запланировано, доделаю MVP и будет что показать.
P.S.: Кстати, обсуждаемое здесь утверждение «альтернативы дереву как формы представления нет» считаю весьма спорным. Раскрывать интригу до конца не буду (да и NDA не позволяет), но смутно намекну: графы можно собирать не только из заметок и записей.
P.P.S.: Если кому-нибудь интересно подключиться к разработке — пишите. Приношу извинения, если кажусь назойливым — просто не знаю когда ещё на хабре подвернётся возможность попробовать найти людей на проект.

zamboga
06.12.2016 20:42Слушайте, но вы же просто написали клон OneNote. Только с ограниченным функционалом.
Восемь лет назад он уже был хорош, а сейчас и придраться-то особо не к чему.
Древовидная структура с неограниченной вложенностью, поиск, теги, аттач любого файла, интеграция видео, запись звука, мощные сторонние надстройки, расширяющие и без того обширный базовый функционал (Onetastic и OneNoteGem), шаринг (и недавно, наконец, сделали шаринг отдельной страницы), полная кросс-платформенность, веб-приложение, полная бесплатность. Даже и не знаю, что еще надо для Щастья=)
У меня 2000+ заметок.
Многое, что я постоянно использую для создания и управления своей базой знаний в вашем продукте нет.OnkelTem
06.12.2016 20:52+1Цитата из автора:
В силу моих убеждений, при поиске подходящей программы я ориентировался в первую очередь на кроссплатформенность и открытость кода.
Очевидно, решение для Windows не подходит по обоим критериям. От себя добавлю, что лично мне такое даже и запустить негде...
Leo_Gan
06.12.2016 22:01Мне очень понравилась идея хранения своей «памяти» в виде разделяемой «базы данных». Я здесь вижу пересечение с идеей Wikipedia. Вы не думали о том, чтобы написать экспорт в формат Wikipedia? Или же попробовать использовать формат данных Википедии для данных MyTetra? Как вам такая идея?
И спасибо большое за замечательную статью, за массу идей! В MyTetra есть все для успешного стартапного проекта.svboobnov
06.12.2016 23:24Нет тут новизны, необходимой для создания стартапа (стартап нужен для быстрого освоения нового рынка, новой ниши, а тут всё окучено). Программ — менеджеров информации, на самом деле, очень много, действительно много.
Тут надо придумать, как её монетизировать, и понемногу получать доход.
safinaskar
06.12.2016 22:30К сожалению, моя работа не связана с программированием: там, где я живу, такой вещью не заработаешь. В моем окружении нет знакомых, кто хотя бы знал разницу между «сями» и «плюсами», только пара PHP кодеров.
Попробую дать пару советов, как пообщаться с людьми, знающими C++.
- Устройтесь в фирму, можно удалённо
- Присоединитесь к свободному проекту или создайте свой
- Сидите на гитхабе, выкладывайте там свои проекты и участвуйте в чужих
- Понятное дело, для вышеназванных пунктов будет крайне полезно общаться и читать по-английски
Ещё можно мне написать...
safinaskar
06.12.2016 22:43Я пытался улучшить понимание C++ просмотром лекций из курсов удаленного обучения
Да что ж такое. Читайте книги (можно на читалке, можно в бумаге, можно в электронном виде), далее обязательно набирайте весь код в примерах в компьютер (да, да, просто по дороге в метро так не получится), компилируйте его, исправляйте пока не заработает. Если есть упражнения — решайте их. Экспериментируйте, пишите код. Сидите на http://cppreference.com (да, надо параллельно инглиш подкачивать).
Читайте Страуструпа, причём не пролистывая непонятные места, а именно прорешивая их. Сам Струструп советует для новичков свою книжку "Programming: Principles and Practice using C++", а для хороших программистов — "The C++ Programming Language".
Ну и вообще, C++ — очень сложный язык, и лучше начинать не с него. Начните с питона или javascript.
Ещё посмотрите сейчас эти две ссылки:
http://norvig.com/21-days.html (там есть ссылка на русский вариант)
http://pikabu.ru/story/vyiuchit_yazyik_programmirovaniya_c_za_21_den_34413r3verser
06.12.2016 22:50вы смотрели исходники программы автора?:)) тынц он далеко не новичок, думаю он имел ввиду более глубокое понимание языка.
safinaskar
07.12.2016 01:28Пошёл по вашей ссылке, посмотрел на первый попавшийся фрагмент кода ( https://github.com/xintrea/mytetra_dev/blob/experimental/src/main.cpp ):
char* fromQStringToChar( const QString& str ) { /* (коммент) */ return str.toLocal8Bit().data(); }
Мне лень проверять, но у меня сильное подозрение, что здесь возвращается указатель на локальный объект (ping webhamster ). toLocal8Bit возвращает QByteArray, который уничтожается после выхода из функции. Автор пока не словил сегфолт, потому что ему везло (или словил?). Ну и добавил сюда, что автор сам говорил, что плохо разобрался с наследованием. И я не говорю, что новичок, я просто накидал ссылокwebhamster
07.12.2016 11:13Да тут явная проблема, надо исправлять.
Поэтому я и не люблю ни Си ни плюсы. Хотелось бы мыслить более абстрактными категориями: получил строку в подпрограмму, сделал преобразование, вернул. И не париться с тем что там с памятью происходит.
Я даже скажу больше: чтобы делать таких размеров проект в одиночку, сваливаться в низкоуровневые подробности вообще нельзя — просто не вытянешь проект, завязнув в мелочах. Поэтому я и выбрал Qt — он хотя бы сглаживает подобные вещи своим QString и прочими готовыми объектами. Казалось бы, такая малось — человеческие строки в плюсах. Но если бы их не было, я бы вообще не взялся за этот проект.
Но тут на стыке с традиционными строками всегда для меня будут проблемы. Я когда программирую, выкидываю из головы все эти указатели, стеки, кучи: мне нужно мыслить в терминах решаемой задачи. Но Си и плюсы эту естественную потребность сильно ограничивают.
И я считаю, что подобные ошибки — это явная проблема языка, никак не решенная до сих пор. Что это за язык такой, который позволяет сразу после возврата значения его потерять? Понятно, что возвращается не значение, а указатель на него. Значение бъется, а указатель правильный. Но елки палки, это же строки! Это же самая простая и естественная вещь в программировании. Как можно было сделать язык с такими строками?
Предваряя холивар: я писал на Ассемблере (см. размер интрушек), и хорошо себе представляю и стек и кучу, и как на низком уровне работает компьютер. Но эти знания мне не помогают избавиться от ошибок в сях и плюсах. И сам язык (во всяком случае gcc) таких ошибок не ловит.safinaskar
07.12.2016 15:14«И я считаю, что подобные ошибки — это явная проблема языка, никак не решенная до сих пор» — в этом суть C и C++. Ручное управление памятью. Это делает их быстрее других языков. Не нравится — используйте другие языки (сказал уже: заюзайте python или javascript).
В C++ можно немного облегчить себе жизнь, если не использовать char *, а всегда использовать только std::string (если используется Qt, то ещё и QString). Но низкоуровневые вещи всё равно будут вылезать
semenyakinVS
07.12.2016 15:28Небольшой оффтоп…
Контроль низкоуровневых процессов — не только слабость, но и сила. Нужно её правильно использовать.
Стиль написания кода в плюсах подразумевает создание послойного приложения. Берётся (или пишется) ядро, которое контролирует низкоуровневые нюансы — и уже над этим ядром создаётся прикладной код, в котором можно использовать либо безопасные (но более медленные) классы ядра, либо писать хорошо оптимизированный, но более опасный код на уровне самого ядра (такой код будет использоваться ограничено, инкапсулироваться в местах, нужных для подобных сверхоптимизаций и со временем, вероятно, будет переносится в ядро).
Беда плюсов заключается в отсутствии общих стандартов дизайна программ и отсутствии внятного инструмента для простого выбора и настройки нужной степени абстрагирования от «уровня железа». Нет модулей. Как следствие, нет внятного менеджера пакетов и нет возможности быстро выбрать и встроить в проект нужную в смысле навороченности прослойку-ядро. Наличие пакетного менеджера позволило бы собирать приложение по принципу бутерброда, выбирая между безопасностью кода и его эффективностью.
Закончу тезисом: пакетный менеджер не роскошь — а жизненно необходимая вещь. Пакетный менеджер и стандарты дизайна кода — вот, что может навести порядок во экосистеме языка и спасти его от потери позиций. DIXI
Ещё раз приношу извинения за оффтоп.
semenyakinVS
07.12.2016 15:32Ой, и ещё забыл, прошу прощения…
И сам язык (во всяком случае gcc) таких ошибок не ловит.
Есть статические анализаторы, правила работы которых — да — должны декларироваться как-нибудь в рамках стандарта и должны встраиваться в компиляторы. Тот же rust, по моим наблюдениям (сам на нём не писал), это вычищенные от legacy-хлама плюсы со встроенным статическим анализатором, который не даёт совершать глупости. Rust любят за это, а плюсы, увы, слоупочат, опять же теряя позиции.
bhagavate
09.12.2016 11:50ммм джава?)
вы явно выбрали не то средство для задачи, тем более когда нужно активно работать со стрингами.webhamster
09.12.2016 12:02> тем более когда нужно активно работать со стрингами.
Стринги QString прекрасны.
Вопрос в стыках с традиционными сишными строками. В сях и плюсах вообще идет подмена понятий. Чарные строки — это не строки вовсе а просто массивы. Но их постоянно называли строками, и даже в именах функций, которые по сути работают с набором байт, зачем-то писали «str». Сейчас имеем то, что имеем. В сях появились std::string, но прототипы низкоуровневых функций по прежнему требуют чарные строки.bhagavate
09.12.2016 21:06все требования что вы описали есть в джаве. при этом там из коробки вменяемая работа со стрингами (в отличие от того же питона2). а на сях сейчас наверное стоит писать только перфоманс критичные вещи, явно не ваш случай.
webhamster
07.12.2016 11:29Нужно личное общение. Книги, видео, чаты, форумы, телефон и скайп личного общения не заменят. Говорю это как человек, пять лет проработавший удаленно. Удаленка — это деградация. Это явление, которе называется «программист-одиночка». На фоне программистов, которые работают в коллективе, он будет всегда проигрывать.
OnkelTem
07.12.2016 12:13Как странно слышать такое устаревшее мнение в наши дни, тем более от человека, который живет и работает в мире OpenSource, созданного практически полностью людьми на удаленке. Качества софта определяется кол-вом усилий/бабла вваленных в проект, а вовсе не в том, сидит программист дома или в офсе. Последнее скорее является либо выбором самих программистов (когда невозможно создать условия дома), либо прихотью начальства, живущего в предыдущей эпохе. За исчерпывающими аргументами прошу сюда: https://37signals.com/remote
webhamster
07.12.2016 14:17> практически полностью людьми на удаленке
Вы слишком радужно смотрите на удаленку. Серьезные вещи делали люди, которые до этой удаленки десятилениями работали в коллективе и имели профильное образование и обрасли профессиональными связями.
А вчерашний студент с непрофильным образованием, будучи сразу помещенный на удаленку, ничего в серьезном OpenSource не сделает при всем своем энтузиазме и тихо будет деградировать. Еще хуже, если он будет жить не в дефолситях, а в провинциальном городе: ни на каких конференциях он не побывает, рядом с ним в местной тусовке никого не будет, человек будет просто сидеть и работать. До некоторых пор. В лучшем случае он уйдет в какой-ниюудь инди-гейм-девелопинг под iOs, в худшем — плюнет на это дело и станет работать по профессии. Да, и не забывайте, что у очень многих людей при всем желании нет возможности учиться там, где они должны были бы учиться. Не у всех родителей есть возможность обеспечить учебу студента не только в нормальном вузе, но даже просто в другом городе.
У меня небыло ни профильного образования, ни десятилетий работы в коллективе. К моему возрасту я по призванию смог проработать разработчиком только один год на постоянке по невероятным стечениям обстоятельств. Потом пять лет там же удаленно. Все остальное время — работа для выживания на должностях, никак не связанных с программингом. Но я знаю, как я вырос за год очной работы разработчиком, и как сдеградировал за время удаленки.OnkelTem
07.12.2016 14:31+1Серьезные вещи делали люди, которые до этой удаленки десятилениями работали в коллективе
Ага, например Линус Торвальдс. Или 37 signals — команда, которая на удаленке сделала Ruby on Rails, Basecamp и целую серию других продуктов. У них есть офис, да, для кофе и переговоров.
Вы берете свой не сильно удачный по вашей же оценке опыт и распространяете на всех. У меня есть друг, который тоже говорит, что не может работать дома, по его словам он
начинает сразу пить водкуне может сосредоточиться. Что ж, возможно для него это и так. Но вот я понимаю, что лучше чем дома условия не создам нигде, разве что в своем офисе (тоже пробовал, кстати, чтобы не мешали домашние, теперь же просто щеколда на двери). У меня 3 монитора, скоро будет стол с подъёмником, чтобы стоя работать, я могу в жару сидеть за компом в одних шортах, летом могу пойти искупаться.
Пример же про глубинку для меня непонятен, если мы говорим про IT, ведь есть интернет.
В личном присутствии на конференциях если не собираетесь делать доклад тоже не вижу смысла, что мешает в записи их посмотреть?
webhamster
07.12.2016 22:32Вы в интернет много работы можете найти, помимо фриланс-бирж с разовыми заказами?
По поводу конференций подумайте, зачем их вообще устраивают, и зачем туда люди ходят. Ведь можно просто видео записать, а кому надо — посмотрит.OnkelTem
07.12.2016 23:14+1Вы в интернет много работы можете найти, помимо фриланс-бирж с разовыми заказами?
Разовые заказы для новичка — самое оно, так как при этом осваивается целый ряд различных видов деятельности, которые он бы не освоил, сидя в тепличных условиях офиса. Это и маркетинг себя любимого, и переговоры, и умение быстро въехать в задачу и задать правильные вопросы, оценить сложность проекта, организовать свое время, выполнить заказ, и при этом взаимодействовать с заказчиком. Добавьте сюда умение вести пусть и примитивную бухгалтерию, уплату налогов, взносов и получите гражданина.
В ходе этой деятельности отлично усваиваются такие вещи как ответственность, потому что на кону стоит оплата труда, и компромисс — между требованиями и твоими затратами времени.
Иначе говоря, ты должен выдать такой результат, который устроит заказчика, но при этом не потратить времени больше запланированного/оплачиваемого.
Что же касается изучения технологий, то новичку иногда приходится землю носом рыть, чтобы чему-то научиться, причем в реальных боевых условиях. И что самое главное: самому, а не отрывая соседа по офису по каждому поводу.
В результате получается тертый универсал ±, который и А с Б связать сможет, которого уже не испугаешь техзаданием и который смотрит на вещи совсем другими глазами нежели наивный студент. В общем, все эти навыки только на пользу пойдут будущему специалисту.
А с профессиональным ростом специалиста расширяется и круг его возможностей. Он обрастает связями и портфелем выполненных работ. Всё это — его актив, настоящий, а не офисный. Я не имею ничего против работающих в офисах, просто вот эта придурь "хочу чтобы все работали в офисе" сильно ограничивает рост самой отрасли:
1) начальник ограничен специалистами живущими поблизости
2) специалист ограничен конторами расположенными поблизости
Сплошные минусы и ни одного плюса.
По поводу конференций подумайте, зачем их вообще устраивают, и зачем туда люди ходят.
Был на нескольких. Завел несколько знакомств, ни одно не пригодилось. Насколько я успел заметить, люди туда ходят развлечься с пользой. В основном это происходит ВМЕСТО работы, так что других мотивов и искать часто не нужно. А вот выпить пива с корифеями после конфы — это реально полезная тема, но, в основном — для души. Я вот для этого на рок-концерты хожу, например.
azsx
08.12.2016 02:38+1Разовые заказы для новичка — самое оно
Хочется заметить, язык программирования должен быть популярен у новичков. То есть найти аутсорс заказы на php, pyton, java se очень легко. На java ee — в разы сложнее. На pure C при этом вы не паяете, а только кодите — очень не уверен, что найдёте аутсорс. Я могу ошибаться, поправьте, пожалуйста.
Во вторых, хронометраж времени. Для большей части кодеров он ужасен. Многие за целый день не пишут ни одной строчки кода, не потому что они учат, что-то новое или ошиблись и стёрли результат труда. Они слишком отвлеклись на форумы и хабр. Большая часть кодит не более 2 часов в день. Тем, кто кодит 5 часов и выше я бы сразу зп на три умножал. Обратите, внимание, мои циферки не работают для php и delphi кодеров, также может ещё для кого.
Просто есть люди которым необходим начальник для работы.OnkelTem
08.12.2016 02:56Да, вы правы, не все возможно и не все доступно, как для новичков, так и для удаленной работы — атомный реактор дома не поставишь, например.
Тем, кто кодит 5 часов и выше я бы сразу зп на три умножал.
Есть проблема с самоорганизацией, подтверждаю. У меня сейчас выходит норма в месяц (150-180 часов), но… нет выходных уже лет наверное 10. Просто когда в будни возникает идея где-то интересно поковыряться, то редко себе отказываю, так как знаю — зато еще 2 выходных есть :) Так что в этом смысле работа в офисе по часам, конечно, элемент организации "свыше". Но и минус есть: ты недоступен для домашних дел. Нет идеала, но мне кажется все же удаленная работа, если она в принципе возможна для данной профессии, более предпочтительна.
OnkelTem
07.12.2016 14:37+1Еще один комментарий короткий. Что вызывает у меня недоумение — это желание личного общения, в то время как единственным объективным критерием в программировании является обезличенный код (и за это я лично и люблю программирование). А если программист написал такой код, который не осиливаешь, то и скорее всего общаться с ним не имеет смысла, так как либо его стиль не для тебя, либо твой уровень недостаточный, то есть снова возвращаемся к коду и курим курим курим.
qw1
07.12.2016 20:11Курим, курим, курим — это один из вариантов.
Но, видимо, автор хочет, чтобы был наставник. В компаниях (как я это видел) примерно так новички и обучаются — всё им разжуют и на все вопросы ответят, делай только на первых порах всё, что скажут и спрашивай, что непонятно.webhamster
07.12.2016 22:28Не наставник, а напарники, с которыми можно много чего обсудить. Хотя для молодых спецов наставник не помешает, это хорошо для любой профессии.
safinaskar
06.12.2016 22:46у видео не спросишь те вещи, которые тебе были непонятны по ходу лекции
Можно спросить у компилятора. Далее можно попытаться выяснить на http://cppreference.com. Ещё можно спросить на канале c++ IRC-сети Freenode. Ещё на stackoverflow или тостере (либо искать уже заданные вопросы там же). Ну и в поисковиках

Leo5700
07.12.2016 01:02+1«Верной дорогой шагаете, товарищ!» (с)
Сейчас мы с коллегами используем в виде базы знаний такой набор костылей:
* ZimWiki
* EverythingSearch
* Файл-теги (пустые файлы #теги, которые добавляются в папки для упрощения поиска)
* Launchy (в режиме телефонного справочника, каждый контакт — отдельный .txt)
Ваша работа очень кстати — вопрос PIM как нельзя более актуален сегодня, когда мы от «устного эпоса» наконец переходим к «письменности».
Self_Perfection
07.12.2016 01:26Файл-теги (пустые файлы #теги, которые добавляются в папки для упрощения поиска)
Чем встроенная поддержка @тегов в zim не подходит?
semenyakinVS
07.12.2016 04:22Теги есть и в самих операционных системах (например).
Leo5700
07.12.2016 22:56+1Чесно говоря, всегда опасался их попробовать в деле. Видимо, мешает подспудное ощущение подставы от майкрософт.
AndreyDmitriev
07.12.2016 10:57+1То, что вы сделали — это фактически WinHelp «на стероидах». На самом деле, похожие решения есть, вот, к примеру Mars Notebook или TreePad, но как вы совершенно верно заметили, в каждом из них есть что-то что не нравится по тем или иным причинам и приводит к решению «пилить под себя». Из того, чем я пользуюсь — Natara Bonsai (лет пятнадцать уже как ) и AbstractSpoon ToDoList. Вот ещё, кстати, пример, чем-то похожий на ваш — pdb. Cценарий использования у автора: Кросс-платформенная разновидность TreePad.
Навскидку — что можно было бы изменить:
Из косметического — добавить иконку в исполняемый файл. Если программа уже запущена, то при попытке повторного запуска не показывать сообщение с одинокой кнопкой (кстати, не локализованное), а просто разворачивать программу из трея. Иконки на тулбаре мелковаты (ну для меня во всяком случае — мой монитор 2560x1600). По юзабилити — всё, что, делается из контекстных меню можно сделать доступным и из основного меню (скажем, добавить туда пункт «редактировние» и динамически менять его в зависимости от контекста. Также добавить горячие клавиши, типа Ctrl+C/Ctrl+V, Ctrl+N для новой ветки, Ctrl+Shif+N для подветки, и т.д. Если я хочу удалить что-то — ветку или статью — я инстинктивно нажимаю Del, но ничего не происходит. Ветки было бы здорово просто таскать мышкой, а не через «преместить вверх/вниз»). Редактирование статьи можно разместить справа от дерева, а не снизу — нынче мониторы широкие (это первое, что я сразу же поменял — там одна строчка всего). Поскольку предпочтения у всех разные — добавить опцию. Переименование ветки/записи можно делать сразу в таблице или дереве, не показывая диалог. Редактор — чуть допилить — сделать возможность менять цвет текста — пока что это можно сделать лишь ручным редактированием html. Список прикреплённых файлов можно показывать совместно с окном редактирования, чтоб не переключаться туда-сюда.
В принципе можно не разбивать представление на «ветки» и «записи», а обойтись одним деревом, где каждый узел уже и будет записью. Вот сейчас, если я хочу добавить к записи дочерние элементы, я не могу этого сделать.
К записям можно было бы добавить тип — скажем, ToDo, Task или Simple. Пока что у вас все записи — «Simple» Если изменить тип на Task, то там можно добавить прогресс-бар, степень исполнения может пользователь задать, ну или автоматически вычислять его, если там есть подзадачи с типом ToDo (ну там чекбокс в таблице выкатывать). Это превратит проект в более полноценный PIM. Ну там соответственно надо будет добавить время завершения, приоритет, и т.д.
Это просто мысли, я понимаю, что исходники открыты (спасибо) — я давно хотел посмотреть Qt, теперь будет с чем поковыряться долгими зимними вечерами. Выше есть некоторое количество комментов в стиле «зачем это надо» — не обращайте на них внимание и продолжайте работать над проектом, вы всё делаете правильно.webhamster
07.12.2016 11:46Посмотрите видеообзор MyTetra, хотя бы первую часть. Многие запросы сами собой отпадут :).
DoktorS
07.12.2016 11:34+1Очень хорошо, то, что вы разработали… Но, признаться, при знакомстве с вашим творением я не нашел, чем оно принципиально отличается от Zim. У Zim уже есть использование картинок, линков, древовидная организация заметок, теги для ускоренного поиска, поиск. А еще плагины, расширяющие его в любую требуемую сторону. Есть версии под Линукс и Виндоуз… И то, что мне представляется особым плюсом — хранение записанного в виде простых .txt файлов, что позволяет добраться до записи и без самого Zim. Хранение на сервере и доступ из разных мест… ну сейчас и правда много облачных хранилищ…
Не хочу сказать, что не нужно изобретать велосипеды. Нужно. Это дает новые инженерные решения. Но если есть что-то, что может быть существенным отличием, то, на мой взгляд, стоило бы развивать это самое отличие…
MaOR
07.12.2016 11:34Для тех же целей использую Makagiga. Хорошая программа с похожей на MyTetra концепцией, но не идеальна. Никогда не пробовали сравнить с ней?
lolikandr
07.12.2016 11:34Уважаемый webhamster, как Вы решаете проблему битых ссылок? Если я начну ссылаться на ветку вашего дерева, а Вы её перенесёте — то моя ссылка работать не будет.
webhamster
07.12.2016 11:44У веток и у записей всегда формируется уникальный ID. При переносе ветки и записи ID сохраняется.
Я не понял, какую ссылку вы имеете в виду.
URL на запись в интернете типа http://webhamster.ru/mytetrashare/index/mtb0/1380477009ru8td8so8d?
Или ссылку на запись внутри MyTetra типа mytetra://note/14031612667yhiim7knf?
Shrk
07.12.2016 11:35Уже спрашивали, но так как ответа нету, повторюсь. У Evernote и Google Drive есть недостатки, кроме фатального?
webhamster
07.12.2016 11:37Есть. Гоголь драйв — это вообще не PIM-менеджер.
У Evernote другая концепция, плюс он проприетарен и платен.zamboga
08.12.2016 22:30Тогда и я повторюсь. Чем OneNote не угодил? Проприетарностью и закрытым кодом?
Все остальное есть: дерево, теги, поиск, сторонние или самописные расширения, все бесплатно, кроссплатформенность, полный онлайн/оффлайн доступ к базе или стэндалон оффлайновая база. На любую базу можно пароль повесить. Что там вам еще было нужно?AndreyDmitriev
09.12.2016 09:04+1OneNote бесплатен только «онлайновый». Десктопный OneNote очень даже не бесплатен.
Кроме того у него есть фатальный недостаток — его невозможно носить с собой на флешке.
Вот мой сценарий использования:
Я работаю на пусконаладке промышленной АСУТП. Соединения с интернетом у меня нет. На управляющий компьютер я ничего ставить не могу. Хочется иметь доки под рукой (их несметное количество) и записную книжку прямо на компе, где я работаю. Вот тут предложенное решение очень даже.
Ну и кроме того есть еще такой синдром "неприятия чужой разработки". Вы странным образом допытываетесь у автора, почему ему не угодило то или иное существующее решение. Он просто сделал так, как удобно ему, плюс сделал проект открытым, чтобы каждый мог или поучаствовать в проекте, либо форкнуть и допилить под себя, только и всего.zamboga
10.12.2016 10:29Уже года полтора Onenote полностью бесплатен, в том числе и десктопный клиент. Зайдите на onenote.com и убедитесь в этом сами.
OneNote portable гуглится. Сами «записаные книжки» и так можно хранить где угодно, в том числе и на флешке.
Форкнуть под себя — пожалуйста, пишите надстройку или используйте готовую (onetastic, onenote gem).
Я указал автору, что он потратил годы разработки, а вышло только хуже с точки зрения интерфейса и функционала.
Единственный аргумент, «неприятие чужой разработки» уважаю, но тратить 8(!) лет на свой софт, и ни разу не посмотреть, «а что там у конкурентов» — - за гранью моего понимания. Тем более, что этот продукт не монетизируется.OnkelTem
10.12.2016 13:25Форкнуть под себя — пожалуйста, пишите надстройку или используйте готовую (onetastic, onenote gem).
То есть, исходный код Oneonte опубликован? И где можно посмотреть на это? Я вот зашел на их сайт, а там только для винды download, а мне под Убунту надо.
AndreyDmitriev
11.12.2016 21:13Ещё раз — полностью «отвязанный от онлайна» OneNote не бесплатен. OneNote 2016 по-прежнему продаётся за деньги в составе офиса 2016. Попробуйте хотя бы скачать инсталляшку бесплатного OneNote и установить на компьютер без подключения к интернет — и ничего не получится.
Portable версии официально не существует. «Неофициальные» сборки есть для старых версий, и работают так себе.
Дома я, кстати, пользуюсь OneNote 2010 — на работе раздавали профессиональный офиc за 12 Евро. Бесплатная версия однако вот не «прижилась» совершенно (тут ещё очень медленный интернет сыграл свою роль — у меня 2 мегабита на вход и всего 256 кбит/c на отдачу).
На самом деле автор смотрел на другие продукты:
Из проприетарных продуктов я пересмотрел линейные и древовидные PIM-менеджеры… более-менее доделанными оказался Microsoft OneNote… Но видя, каким деструктивным маркетингом занимается Микрософт, связываться с OneNote я не стал.
Вот у меня есть аналогия с бумажными органайзерами. Лет двадцать назад коллеги подарили мне органайзер-ежедневник. А я как раз прочитал книгу Даниила Гранина «Эта странная жизнь» (кстати, рекомендую), и, познакомившись с «тайм-менеджментом» Любищева, начал всё записывать в эту красивую книжечку в кожаной обложке. Довольно быстро я понял, что рамки «прокрустова ложа» календаря мне не подходят — некоторые дни занимали две строчки, а другие — две страницы, кроме того, мне нужна была бумага в клетку. Я завёл тогда простую тетрадку на 96 листов, но формат был не очень удобен, я даже пробовал её скальпелем подрезать, кроме того, под конец она просто разваливалась. Потом я нашёл "Moleskine". Стоят эти записные книжки невменяемых денег, но почти хороши — ими довольно приятно пользоваться. И вот не хватало мне сущей мелочи — нумерации страниц (это первое что я делаю с новым блокнотом — нумерую все страницы — у меня есть система оглавления). Вроде мелочь, но вызывает дискомфорт. Я даже был готов напечатать и переплести свою версию (это, фактически, именно то, что делает автор). А потом я нашёл то, что так долго искал — Leuchtturm1917, и для меня наступило счастье — там прекрасно всё (ну, кроме цены, пожалуй) и я снова в своей «зоне комфорта». Я тоже потратил годы на постройку и поддержание стройной (для меня) системы, при этом она подойдёт далеко не каждому.
То, что у автора вышло «хуже» — это ведь с вашей точки зрения. А с точки зрения автора там всё нормально — он своими руками сделал себе идеальную записную книжку. Там ровно столько функционала, сколько нужно автору.zamboga
14.12.2016 05:44Скачайте инсталяшку, поставьте, создайте офлайновую книжку, отключите инет. Работает?
Сейчас полно дистрибутивов, качающих на ходу.
Skit25
07.12.2016 11:35Долго искал нечто подобное, ну таки нашел… плюс завел блог.
Но в общем и целом простая и понятная программа, сделана красиво.
Осталось сделать возможность писать на нее плагины. Как практический учебник сохраню в заметки.
DjOnline
07.12.2016 20:19+1Для хранения заметок использую… черновики писем в Gmail, затем через поиск на любом устройстве это можно найти.
OnkelTem
07.12.2016 20:48Думаю вот сейчас все разработчики PIM вздрогнули.
webhamster
07.12.2016 22:36Разработчики pim усмехнулись в усы, и продолжили пилить свои поделия. Либо у вас слишком низкие запросы к удобству работы, либо вы привыкли суп вилкой есть.
DjOnline
07.12.2016 23:12Мне кажется разработчики pim варятся где-то в собственном соку в своих личных хотелках, создавая несомненно полезные продукты, но не для всех.
Какой категорично другой опыт даст мне любой pim, включая evernote?
Да, в gmail нет сейчас одного — ссылок из одной заметки в другую. Но как-то живу без этого.webhamster
08.12.2016 00:20Ну например, вы сделали ветку с какимито данными и хотите передать ее другому. Попробуйте это сделать в gmail. Еще помоему в гмыле нет древовидности, каталоги одного уровня. Да и не каталоги это в общем, а теги. А нормальных тегов нет.
Ну и еще вам про наличие интернета уже говорили, повторять не буду.DjOnline
08.12.2016 01:00Да, передать нельзя, только переслать, если это один черновик.
Наличие интернета неважно, если на то что точно будет нужно заранее поставить звёздочку, и оно будет синхронизированно с устройством даже с вложением внутри.
azsx
08.12.2016 02:10Ну и еще вам про наличие интернета уже говорили, повторять не буду.
Можно использовать оффлайн версии, например, в thunderbird я как то в итоге хранил почти 500 тысяч писем. Поиск был очень быстрый.
Передать кому то, вполне реально экспортируя определённые письма.
Говорить, что нет древовидной структуры совсем — неверно, можно разбить по каталогам внутри программы. Неудобно.
Зато решается множество проблем, которые не решены в вашем софте. Не идеально, но близко.Denkenmacht
08.12.2016 04:40Мне кажется люди, пользующиеся таким софтом и люди, используюшие почту для таких задач (к которым и себя отношу), принципиально разные в одном отношении. Первым просто надо закрыть вопрос с хранением любой инфы, в тч “на бегу“, и иметь к ней доступ из любого места, любой ОС, и не тратить много времени на это, потому что есть чем другим заняться. А вторым интересно создать самим себе вторую работу — научиться пользоваться этим софтом, привыкнуть к нему, а потом постоянно туда складывать все подряд, периодически просматривая все старые записи (похоже на ведение дневника, тренировку самодисциплины).
AndreyDmitriev
08.12.2016 09:03Люди вообще все разные. Подсознательно каждый стремится к своей «зоне комфорта», и у каждого она своя. Кто-то пишет в бумажных блокнотах (как я), кто-то хранит всё в самописных программах, кто-то — в почте, кто-то в Evernote или WizNote. Я тоже в какой-то мере пользуюсь почтой, как хранилищем — правда не gmail, а TheBat! — там у меня выстроена система папок и фильтров, за двадцать лет накопилось более 100K писем.
OnkelTem
08.12.2016 11:17+1Люди вообще все разные.
Проиллюстрирую тезис из недавнего. Наткнулся на видео с примерами визуализации времени разными людьми и, честно говоря, смотрел с отвисшей челюстью. Воодушевленый, создал в одном интернет-сообществе топик с просьбой написать как контингент себе представляет Время. Таки что вы думаете? В комментариях царил "камеди-клаб", все старались друг друга перешутить, и ни один не ответил серьезно. Видимо, для них сам вопрос был бессмысленный.
azsx
08.12.2016 11:47Парадокс рекламы, люди абсолютно разные в мыслях, но в реальном мире достаточно однотипны и предсказуемы в поступках.
Соответственно думайте, что хотите, но мы не находим новые фичи программ, мы толпами пользуемся одинаковыми программами для одинаковых целей.OnkelTem
08.12.2016 12:14Так-то оно так, но вот что насчет принятия визуализации и вообще моделей?
Со школы помню и люто ненавижу блок-схемы, считаю одной из самых неудачных попыток визуализации алгоритма. Спустя десятилетия наткнулся на отечественные блоксхемы на стероидах — ДРАКОН, сильно заинтересовался, но практического применения не нашел. Сейчас в виде хобби продолжаю интересоваться визуализацией (в основном — данных), и вот ищу святой грааль для визуализации событий на временной шкале.semenyakinVS
10.12.2016 02:33и вот ищу святой грааль для визуализации событий на временной шкале
Нашлось чего-нибудь? Чем не походит обычный таймлайн?OnkelTem
10.12.2016 12:56+1Нашлось чего-нибудь? Чем не походит обычный таймлайн?
Таймлайн безусловно является классикой и без него никуда. Но не всегда является достаточным. Например, такая схема прекрасна для визуализации отдельного промежутка времени, где важна последовательность событий, безотносительно других событий, не попавших в промежуток, но такая схема не дает общей картины, не предоставляет какой-то абсолютной системы координат к которой можно привязаться. Не уверен, что грамотно излагаю мысль.
Я вот пробовал круг. Движение по часовой стрелке совпадает с ходом времени, почти как циферблат часов. Такая картинка, как мне кажется, имеет больше шансов стать некоей базовой координатной системой, к которой можно цеплять свои знания, достаточно выбрать дату начала, ведь дата конца — это текущая дата.
Большим плюсом этой круговой схемы является наличие радиального направления для кодирования дополнительной информации, причем доступно множество слоев:

По идее, если эту схему положить на плоскость, то для кодирования станет доступно еще одно измерение (ортогональное плоскости диаграммы).
Другой вариант, который так и напрашивается — сделать шар. Но боюсь тут же возникнет конфликт восприятия с нашим родным земным шариком, так что в этом направлении не думал.
semenyakinVS
11.12.2016 13:47Не очень понял что значит «такая схема <...> не предоставляет какой-то абсолютной системы координат к которой можно привязаться». Объясните подробнее, интересно.
Идея попробовать свернуть таймлайн в бублик необычна… Но, как мне кажется, такое решение оставляет много пустоты (собственно, центр бублика), а если сделать не бублик, а спираль (чтобы события шли плотно из центра) — считывать информацию станет не очень удобно.
Вообще, как мне кажется, популярность горизонтальных и вертикальных таймлайнов связана с тем, что они дают чёткий критерий сортировки событий. Справа точно то, что позже. Слева — то, что раньше. Естественно и удобно, на мой взгляд.
Возможно, я что-то не так понял. Если будет возможность — расскажите подробнее. Интересно.OnkelTem
11.12.2016 14:35+1Не очень понял что значит «такая схема <...> не предоставляет какой-то абсолютной системы координат к которой можно привязаться»
Любое событие имеет место и время. Для координат мест у нас есть географическая карта, так что проблемы с привязкой информации к месту нет. Другое дело — время. У таймлана нет начала и конца, любой его кусок относителен и являет собой отрезок на бесконечном, в общем-то, луче. Любая попытка поменять масштаб схемы приводит к наружению начальных соотношений. Например, мы вывели последние 2000 лет, тогда падение Римской Империи приходится на отметку примерно отстоящую на 1/4 от левой части схемы. Если мы теперь попытаемся детализировать схему и "приблизим" ее, то соотношения "сбиваются".
А вот угол — конечен. Их всего 360, и любой отрезок времени легко отображается в углы. Например, если за круг принять нашу эру, то Римская Империя развалилась примерно "на востоке", "в три часа", "в пятнадцать минут". И как ты не масштабируй, оно там и останется. Поэтому на схему в основе которой круг или нечто подобное можно нанизывать новые знания.
Есть еще один огромный плюс. На площадях вообще значительно нагляднее видны соотношения, чем на линиях:

А на круге — нагляднее, чем на прямоугольнике:

Если на круг добавить еще условные отметки времени — минуты, часы — то соотношения станут еще более органичными (вспомним хотя бы ориентирование с его направлениями "на 2 часа", "на 10 часов").
Но есть и минусы. Например, на такой схеме мне кажется будет неудобно сопоставлять разные события. Для отображения двух и более "сюжетов" на отдельном промежутке времени больше подойдет таймлайн, а еще лучше — таблица сравнения характеристик, как на сайтах с комплектующими, где в колонках — девайсы (т.е. сюжеты), а по-вертикали — характеристики (т.е. ось времени).
Идея попробовать свернуть таймлайн в бублик необычна… Но, как мне кажется, такое решение оставляет много пустоты (собственно, центр бублика),
Да, отображать несколько видов информации не очень удобно, но можно. Например, вот мой набросок-конспект антропогенеза: http://imgh.us/Evo1_export.svgz Там можно видеть как сектора используются для вывода доп информации — об эпохах.
webhamster
08.12.2016 20:07А ты можешь мне прислать, как дья тебя выглядит время? Можешь изобразить само время, и твое восприятие всей истории, года, недели, суток.
Если пришлешь, я тебе тоже пришлю две картинки от меня и моего товарища. Мы как-то раз рисовали такое. И ничего подобно что там намазякали буржуи у нас небыло.OnkelTem
08.12.2016 20:21Могу, как раз сегодня набросал, чтобы вспомнить. Очень коряво, но примерно отражает действительность. В личку кину
Leo5700
07.12.2016 22:49Я тоже иногда так делаю. Письма от себя себе падают в папку «bookmarks». Всё ж удобнее, чем закладки браузера.
bhagavate
09.12.2016 21:07+1еще лет 10 назад задумывался о проблемах организации инфы, но кривые велосипеды писать не хотелось, потому забил.
потом лет 5 назад пришлось разбираться в новых для меня областях (экономика, политика, история, философия), и проблема «информационных перегрузок» встала в полный рост. но там я уже немного лучше понимал запущенность проблемы, и снова забил. вернее нашел нечто более менее удобоваримое (diigo), и успокоился.
окончательно ситуация сдвинулась когда прочитал замечательную статью об Информационно-Аналитической Системе (ИАС) Palantir (Говорящие камни на службе цру, на здньюс от берда киви) — и чтото в голове перещелкнуло. сразу стало понятно что всякие пимы, миндмапы, блокноты и прочие поделки это просто не тот уровень, нужна именно комплексная аналитическая система по типу палантира, только открытая) и как раз это уже вполне реально(хотя и более трудозатратно, но само решение более адекватно вызову).
кстати есть более менее доступные варианты ИАС, например «сайтспутник». не помню есть ли там организация базы знаний(должна быть), но по функционалу уже чтото близкое. кому интересно можно еще на сайте hrazvedka.ru пошерстить инструментарии, там тоже много интересного, хотя именно ИАС вообще довольно мало, и практически все коммерческие.
>но я нигде не могу найти их в бумажном виде. С экрана же глубокого чтения у меня не получается. Максимум что могу читать — художественную литературу с книгочиталки. Но техническую не воспринимаю. Возможно потому, что книгочиталки — это один «лист», а мне нужно быстро прыгать вперед-назад в поисках разных мест, но книгочиталки такого не позволяют, слишком они медленные и неудобные.
а вы не задумывались что вот это «быстро прыгать вперед назад в поисках разных мест» — это 100% кейс который должен решать ваш «Мемекс»? то есть в идеале книжки тоже нужно читать из вашей системы, да и чтоб она сначала делала какуюнить предобработку инфы, а потом вы еще сами по тексту могли какието вещи отмечать и так далее?
лично я скорее пытаюсь решать более общую проблему — не только организацию своих знаний, но и поиск релевантной информации и преобразование ее в знания. как минимум прежде чем читать книжку, сначала нужно найти правильную книжку, а не читать все подряд. ну и это не только книжек касается — те кто пытался почитать отзывы перед покупкой нового девайса(чтобы потом не быть разочарованными), или проверять факты (исторические или банально новости, что особенно актуально), или просто разобраться в новой для себя области — все сталкиваются с проблемой информационных перегрузок, и им нужны соответствующие инструменты. вообще это уже область OSINT — опен соурс интеллидженс (разведка по открытым источникам). и она имеет самое прямое отношение к работе с информацией в любой сфере.
но пока что действительно складывается впечатление что в информационном веке у нас все еще нет подходящих инструментов для жизни и работы в нем. все какието палки копалки из 90х. при этом сами люди такие же как и до книгопечатания, а информация все пребывает и пребывает) многих уже просто смыло потоком, и они уже даже не пытаются барахтаться)OnkelTem
10.12.2016 12:20+2Как-то несколько сумбурно, но мысль ясна, хотя мне кажется вы что-то не договариваете :)
bhagavate
10.12.2016 16:07просто пытаюсь сказать что проблема гораздо шире и глубже чем просто создание заметок, и нужно подняться на уровень повыше.
вот кстати автор в самом начале написал про мемекс — и венневер буш как раз и пытался более общую проблему решить (информационных перегрузок), а не просто заметок. просто в его время интернета не было, потому он особо поиск информации вовне не описывал, насколько я помню, только организацию своих записей. хотя уже там как раз была работа с книгами — записи делали из книг, из них составлялся целый путь последовательного погружения в проблему, и он уже описывал что этими путями можно было обмениваться. и кстати это все дало серьезный толчок развитию пк, например под демонстрацию концепции мемекса (https://ru.wikipedia.org/wiki/%D0%AD%D0%BD%D0%B3%D0%B5%D0%BB%D1%8C%D0%B1%D0%B0%D1%80%D1%82,_%D0%94%D1%83%D0%B3%D0%BB%D0%B0%D1%81#The_Mother_of_All_Demos) даже мышку в свое время придумали, а так же там по моему первый раз показывали работу по сети). так что лично меня удивляет что про эту концепцию забыли, и даже саму проблему мало кто видит, при том что она с каждым днем все актуальнее. хотя недавно дарпа еще какойто проект начала, он прям так и называется «мемекс», но там уже чтото с поиском связанное.bhagavate
10.12.2016 16:16както ссылка криво встала https://ru.wikipedia.org/wiki/Энгельбарт,_Дуглас#The_Mother_of_All_Demos
OnkelTem
10.12.2016 16:32Да, это действительно следующий уровень, а PIM'ы, которые тут обсуждаются, находятся на более низком уровне. Одно другое не отменяет, а например дополняет.
Не ходил пока по ссылкам, но насколько я понял из описания, как вариант применения того, о чем вы пишите, при чтении книги можно руководствоваться некой стратегией "разметки" текста, с тем чтобы потом получить грамотный конспект. Это, очень заманчиво звучит, и хотел бы я увидеть примеры, потому что сам пока ничего толкового не "изобрел", в лучшем случае получается подборка фраз из книги, которую конечно легче читать чем книгу, но все равно не очень удобно.
С вашим направлением мысли кстати пересекается параллельно идущее выше обсуждение о визуализации данных.
bhagavate
10.12.2016 16:51разметки могут быть на разном уровне. например куски текста (типа как раньше пометки карандашом на полях или маркером делали), но тут во первых их сразу можно найти(а не нужно листать книги), во вторых можно сохранять привязку к тексту (так называемая дата интегрити — ссылка на источник данных, что сейчас в эпоху фейков очень важно), в третьих можно еще выделять в тексте обьекты и например если вы выделили цитату какогонить исторического деятеля, то при заходе на него(ну как в википедии страничка о человеке) вы сразу будете видеть что он сказал, или что о нем сказали, где это сказали, в каком году и так далее (ну тут будет проблема как это все аккуратно вывести, не перегружая). ну и там уже можно дополнительно накручивать анализ тональности например, выделять аспекты обьектов итд, но это уже задачка со звездочкой.
примеров много, от простых аннотатор тулзов (подсветка кусков текста цветом) типа того же дииго, до навороченных, с обьектами (отдельно можно например митре аннотатор тулз посмотреть), или уже конкретно иас, но даже там это не везде есть.
svboobnov
10.12.2016 18:24Может, надо просто вставлять «пометки на полях», которые индексируются?
Дело в том, что искусственного интеллекта, который угадает Ваши пожелания, и выделит какой-то фрагмент, пока нету. А вот в электронной книге можно вставить примечание, проиндексировать его вместе со всеми пометками к книгам одной тематики.
К примеру, все пометки к книгам по истории сложить в одну индексированную кучку, все пометки к математическим книгам сложить в другую, и так далее.
beatangel
11.12.2016 09:14Однако, тенденция наблюдается, господа! В том, что потребность в накоплении и классификации знаний увеличивается. И не удивительно, что столько PIM менеджеров есть (кстати, не знал, что они так называются).
Лично сам, пользуюсь отправкой письма к себе и с последующим переносом в папку.
Какие впечатления от прочитанного?
1) Программирование. Силы и времени вложено достаточно много в этот труд. Это хорошо, когда делается что-то конкретное, не отвлекаясь на мелочи и абстракции (мне напомнило веянием этой статьи
«Хабр: Это не твоя проблема»). С другой стороны: чтобы создать что-то действительное конкурирующее, нужно развернуться и решить следующие задачи. Например, задачи не связанные с программированием. Это базы знаний, экспертные системы. Я к тому, что программирование это всего лишь инструмент. Сильный инструмент, который и дает результаты. Но, нужна основа — математическая модель, то есть выделить её, создать. Хотя все уже создано до нас. Значит — задача уметь использовать существующие знания вкупе с инструментами. Автор в принципе это и сделал. А как насчет создать что-то новое и нестандартное? Не дерево, а что-то другое. Не поиск, а вопрос-ответ. Или это вообще не проблема наша, не проблема автора? Делай, что нужно тебе! Ничего лишнего! Это не твоя проблема!
2) По поводу PIMов вообще, в том числе и отправки заметок на почту. Ну, знаете, даже если у нас есть облака, смартфоны под рукой, синхронизация и т.п. Просто человек не может все помнить, или он завален другими делами, чтобы даже напомнить себе о том, что у него в ПИМе есть какая-то заметка. Ясно, что заметки и знания делятся на нужные и ненужные.
3)Опыт. В целом главное, что автор получал опыт разносторонний. Вот это прекрасно!
Вообще мне понравилась статья позитивом, историей создания продукта и вдохновением. Такие авторы и претворяют в жизнь стимул… Для этого двигаемся дальше!







{kind=link}
{kind=link}
RPG18
В исходниках Qt есть каталог 3rdparty, в которой помещены сторонние приложение, а для интеграции в сборку были сделаны соответствующие *.pri файлы. Поэтому вместо велосипеда можно было взять Crypto++.
webhamster
Как-то этот проект прошел мимо меня. Я перед тем как велосипедить спрашивал на ЛОРе о возможных решениях. Мне дружно напихали OpenSSL, но никто внятно не смог объяснить, как сделать проект под все платформы (как минимум Win, Lin, BSD, Mac).
Я пока из доки не понял, Crypto++ — это чистая плюсовая библиотека, которую можно просто положить рядом с проектом и заинклюдить? Или для ее компиляции ее надо «подготавливать» под каждую платформу исходники через make, закомпилить, и только потом использовать?
RPG18
В некоторых местах используются ассемблерные вставки. Отключить что-то можно через дефайны CRYPTOPP_DISABLE_ASM, CRYPTOPP_DISABLE_SSSE3, CRYPTOPP_DISABLE_AESNI.
Нужно исходники прописать в .pro/.pri файле в переменные SOURCES и HEADERS. Тогда библиотека будет собираться во время компиляции основного приложения.