Здравствуй, Хабр! Сегодня я хочу завершить цикл статей об организации тестирования (начавшийся с изучения ошибок и опыта), рассказав о том, как же все-таки Badoo выпускает два качественных серверных релиза каждый день. Кроме пятницы, когда мы релизимся только утром. Не надо релизиться в пятницу вечером.
Я пришел в Badoo чуть более четырех лет назад. Все это время наши процессы и инструменты для тестирования непрестанно развивались и совершенствовались. Для чего? Число разработчиков и тестировщиков увеличилось примерно в два раза — значит, для каждого релиза готовится больше задач. Количество активных и зарегистрированных пользователей тоже удвоилось — а значит, и цена любой нашей ошибки стала выше. Для того чтобы доставлять пользователям максимально качественный продукт, нам нужны всё более и более мощные средства контроля качества, и эта гонка не заканчивается никогда. Цель этой статьи не только продемонстрировать работающий пример, но и показать, что какими бы крутыми ни были ваши процессы контроля качества, наверняка можно сделать их еще лучше. Технические реализации некоторых инструментов вы сможете найти по ссылкам на другие статьи, о некоторых из них нам еще предстоит написать.
В Badoo существует несколько разных QA-флоу, отличие которых обосновано разными средствами разработки и целевыми платформами (но мы используем для них общие системы: JIRA, TeamCity, Git и т.д.), и я вам расскажу о процессе тестирования и деплоя наших серверных задач (а заодно и веб-сайта). Его можно условно разделить на 5 больших этапов (хотя тут, конечно, многие мои коллеги считают по-разному), каждый из которых включает в себя и ручную, и автоматизированную составляющую. Постараюсь рассказать вам по очереди о каждом из них, отдельно выделяя то, что изменялось и развивалось в последние годы.
1. Code Review
 Да, не удивляйтесь, это вообще-то тоже этап контроля качества. Он придуман для того, чтобы в боевой код не попадали архитектурные и логические ошибки, а задача никоим образом не нарушала наши стандарты и правила.
Да, не удивляйтесь, это вообще-то тоже этап контроля качества. Он придуман для того, чтобы в боевой код не попадали архитектурные и логические ошибки, а задача никоим образом не нарушала наши стандарты и правила. Код ревью у нас начинается в автоматическом режиме еще до того, как разработчик «запушит» свой код в общий репозиторий. При попытке сделать git push на принимающей стороне запускаются pre-receive хуки, которые делают огромное количество различных вещей:
- проверяют имя ветки: каждая ветка в нашем репозитории должна быть привязана к тикету в JIRA, и ключ тикета должен содержаться в названии ветки, например, HABR-1_make_everything_better;
- проверяют комментарии к коммитам: каждый коммит должен в своем описании содержать тот же самый ключ тикета. Это у нас делается автоматически с помощью клиентских хуков, и комменты всегда выглядят как-то так: [HABR-1]: Initial commit;
- проверяют соответствие код-формату: весь код в репозитории должен соответствовать принятому в Badoo стандарту, поэтому каждая измененная строка PHP-кода проверяется утилитой phpcf;
- проверяют статусы в JIRA: чтобы в задачу можно было делать коммиты, она должна находиться в определенном статусе: например, нельзя вносить в код задачи изменения, если задача уже «замержена» в релизную ветку;
- и многое, многое другое...
Провал любой из этих проверок приводит к запрету на пуш, и разработчику необходимо исправить возникнувшие замечания. Подобных хуков постоянно становится все больше и больше.
А помимо pre-receive хуков у нас есть и растущий пул post-receive хуков, которые выполняют множество операций, автоматизирующих наши процессы: изменяют поля и статусы задач в JIRA, запускают тесты, дают сигналы нашей системе деплоя… В общем, они очень большие молодцы.
 Если код смог прорваться через все этапы автоматической проверки, то он добирается до ручного code review, который проводится на базе сильно модифицированной нами версии GitPHP. Коллега-разработчик проверяет оптимальность и соответствие решения задачи принятой архитектуре, общую корректность бизнес-логики. На этом же этапе проводится проверка покрытия нового или измененного кода юнит-тестами (задачи, не покрытые тестами в должной мере, ревью не проходят). Если же во время решения задачи был затронут код других отделов, то их представители обязательно присоединятся к ревью.
Если код смог прорваться через все этапы автоматической проверки, то он добирается до ручного code review, который проводится на базе сильно модифицированной нами версии GitPHP. Коллега-разработчик проверяет оптимальность и соответствие решения задачи принятой архитектуре, общую корректность бизнес-логики. На этом же этапе проводится проверка покрытия нового или измененного кода юнит-тестами (задачи, не покрытые тестами в должной мере, ревью не проходят). Если же во время решения задачи был затронут код других отделов, то их представители обязательно присоединятся к ревью. 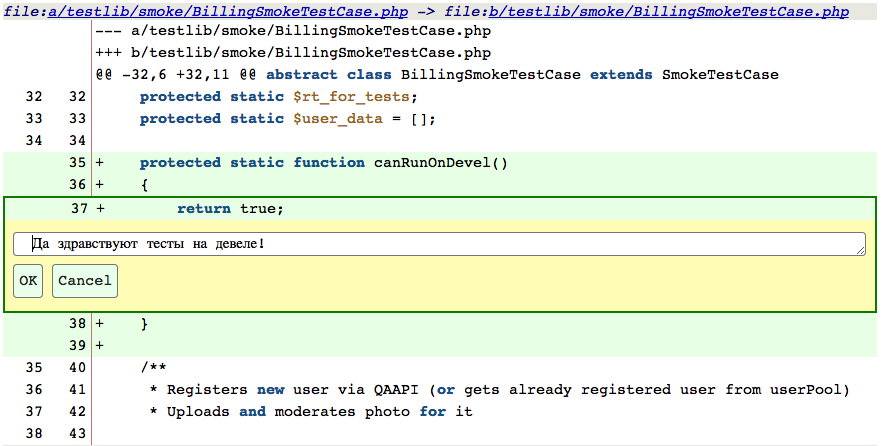
Прямо в GitPHP ревьюер может делать комментарии к коду — и они все отобразятся в качестве комментариев в соответствующей задаче в JIRA, а QA-инженер сможет проверить исправление всех замечаний при тестировании (разработчики даже иногда устраивают холивары в этих комментариях, читать — одно удовольствие).
2. Тестирование на «девеле»
Что такое в нашем понимании «девел-окружение»? Это полноценная платформа, максимально копирующая архитектуру продакшена в меньших масштабах, предназначенная для разработки и тестирования. Девел содержит свои собственные базы данных, собственные копии демонов, сервисов и CLI-скриптов. Он даже разбит на две полностью отдельные площадки для тестирования их взаимодействия: одна находится в московском офисе и эмулирует работу нашего пражского дата-центра, вторая — в лондонском, эмулирует работу дата-центра в Майами.
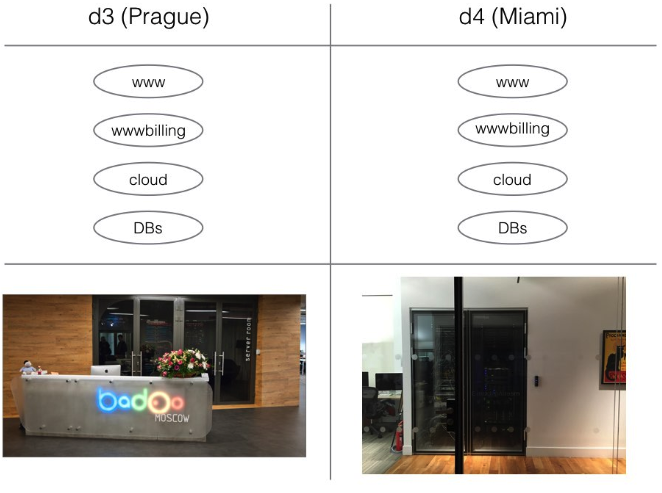
В рамках девела для каждого разработчика и тестировщика выделена собственная «песочница», куда он может выгружать любую необходимую ему версию кода сервера и которая доступна из нашей внутренней сети по соответствующему URL. Разворачивать каждому разработчику свою собственную песочницу на локальной машине, к сожалению, слишком накладно: Badoo состоит из слишком большого количества различных сервисов и зависит от конкретных версий ПО.
2.1. Автоматическое тестирование ветки
Было бы здорово, если бы сразу же после того, как разработчик закончил работу над задачей, в ней запускались хотя бы интеграционные и юнит-тесты, правда? Сейчас я вам расскажу одну небольшую историю отчаянной борьбы.
- 2012 год. 15000 тестов. Запускаются в один поток, либо топорно рубятся на несколько равных потоков. Проходят приблизительно минут за 40 (либо абсолютно бесконечно в случае высокой нагрузки серверов), ни о каком автоматическом запуске речи быть и не может. Грустим.
-
 2013 год. 25000 тестов. Никто и не пытается подсчитать, сколько они идут в один поток. Грустим. Но вот мы разрабатываем нашу собственную многопоточную «пускалку»! Теперь все тесты проходят приблизительно за 5 минут: можно их запускать сразу же по выполнении задачи! Теперь тестировщик, беря задачу в руки, может сразу же оценить ее работоспособность: все результаты прогонов тестов в удобной форме постятся в JIRA.
2013 год. 25000 тестов. Никто и не пытается подсчитать, сколько они идут в один поток. Грустим. Но вот мы разрабатываем нашу собственную многопоточную «пускалку»! Теперь все тесты проходят приблизительно за 5 минут: можно их запускать сразу же по выполнении задачи! Теперь тестировщик, беря задачу в руки, может сразу же оценить ее работоспособность: все результаты прогонов тестов в удобной форме постятся в JIRA.
- 2014 год. 40000 тестов. Все было хорошо, многопоточная пускалка справлялась… Но потом пришел замечательный PHP 5.5, и использовавшийся нами фреймворк runkit стал работать… ну, скажем, очень медленно. Грустим. Приходим к выводу, что нужно дробить тесты на очень маленькие наборы. Но если попробовать запустить даже 100 (вместо ранее использовавшихся 10) процессов на одной машине, то она очень быстро захлебывается. Решение проблемы? Выносим тесты в облако! Как результат — 2-3 минуты на все тесты, и они прямо вжжжжжж!
- 2015 год. 55000 тестов. Задач решается все больше, тесты множатся, и даже облако перестает с ними справляться. Грустим. Что можно с этим сделать? А давайте попробуем при завершении задачи запускать только те тесты, которые покрывают затронутый ею функционал, а все тесты запускать уже на последующих этапах? Сказано — сделано! Дважды в день мы собираем информацию по покрытию кода тестами, и если мы можем собрать исчерпывающий набор тестов, который покроет весь затронутый в задаче код, то мы запускаем только их (если есть какие-то сомнения, новые файлы или масштабные изменения в базовых классах — все равно запустим все). Теперь получаем 1-2 минуты в среднем на прохождение всех тестов на ветке и 4-5 минут на прогон всех тестов вообще!
- 2016 год. 75000 тестов. Не успели тесты начать тормозить (а мы не успели снова начать грустить), как к нам пришло сразу несколько спасителей. Мы перешли на PHP7 и заменили вызывавший у нас трудности runkit (который все равно не поддерживает PHP7) на нашу собственную разработку SoftMocks. Все тесты сейчас проходят за 3-4 минуты, но кто знает, с какими проблемами мы столкнемся в следующем году?
 Запуском тестов в нужных ветках в нужный момент занимается наша незаменимая помощница AIDA (Automated Interactive Deploy Assistant), разработанная нашими релиз-инженерами. На самом деле, большая часть всех автоматизированных процессов при нашей разработке не обходится без ее нежных (хоть и достаточно костлявых) рук.
Запуском тестов в нужных ветках в нужный момент занимается наша незаменимая помощница AIDA (Automated Interactive Deploy Assistant), разработанная нашими релиз-инженерами. На самом деле, большая часть всех автоматизированных процессов при нашей разработке не обходится без ее нежных (хоть и достаточно костлявых) рук.2.2. Ручное тестирование на «девеле»
Итак, тестировщик наконец-то получает на руки задачку. Все юнит-тесты в ней прошли, можно приступать к тестированию. Что же нужно делать? Правильно, надо воспроизводить все нужные кейсы. И 4 года назад это было очень унылое занятие.
 Badoo — сервис знакомств, а значит, весь функционал сильно зависит от пользователя. Практически для каждого теста (а по-хорошему — и для каждого кейса) нам нужно регистрировать свежего пользователя. Поскольку большая часть функционала закрыта для пользователей без фото, то нужно еще и загрузить (и промодерировать) несколько фотографий. В сумме это уже занимает минут 5 рутинной работы.
Badoo — сервис знакомств, а значит, весь функционал сильно зависит от пользователя. Практически для каждого теста (а по-хорошему — и для каждого кейса) нам нужно регистрировать свежего пользователя. Поскольку большая часть функционала закрыта для пользователей без фото, то нужно еще и загрузить (и промодерировать) несколько фотографий. В сумме это уже занимает минут 5 рутинной работы.Затем нужно подготовить тестовые данные. Мы хотим увидеть промо-окошко, отображаемое пользователю, который за сутки написал сообщение сотне других пользователей? Что ж, разминаем пальчики и начинаем флудить. И плакать.
О, для этого кейса нужен пользователь, зарегистрированный более года назад? У меня такого нет :( Ребят, а у вас есть у кого-нибудь? Нет? :((( Придется идти дергать разработчиков, чтоб они подправили значения в базе данных…
Очень печальная история, не находите? Но к нам пришло спасение— QaApi! Что это такое? Это замечательная система, которая позволяет с помощью http-запросов производить различные действия на серверной стороне (разумеется, все это прикрыто авторизацией и может аффектить только пользователей, которые помечены как тестовые. Не надо пытаться отыскать этот интерфейс у себя дома).
 QA-инженер может сделать простенький запрос на QaApi (вида qaapi.example.com/userRegister), GET-параметрами передать нужные настройки (пол пользователя, город регистрации, возраст и т.д.) и в ответ сразу же получить авторизационные данные! Причем таким образом можно получать пользователей как на девел-окружении, так и на продакшене. В то же время мы не засоряем наш продакшен ботами, тестовые пользователи не отображаются живым, а вместо регулярной регистрации пользователей мы получаем подходящего (и уже полностью очищенного после предыдущих тестов) пользователя из пула, если такой уже есть.
QA-инженер может сделать простенький запрос на QaApi (вида qaapi.example.com/userRegister), GET-параметрами передать нужные настройки (пол пользователя, город регистрации, возраст и т.д.) и в ответ сразу же получить авторизационные данные! Причем таким образом можно получать пользователей как на девел-окружении, так и на продакшене. В то же время мы не засоряем наш продакшен ботами, тестовые пользователи не отображаются живым, а вместо регулярной регистрации пользователей мы получаем подходящего (и уже полностью очищенного после предыдущих тестов) пользователя из пула, если такой уже есть.Такими же простыми запросами можно изменять и заполнять различные данные, недоступные к изменению из интерфейса: уже упомянутую дату регистрации, количество новых контактов или лайков за сутки (ура!) и все что только душе угодно. А если для изменения нужного параметра нет QaApi-метода? Чаще всего для его добавления достаточно базовых знаний PHP и это может сделать любой инженер! Иногда, впрочем, требуются более глубокие правки в коде, и тогда приходится обращаться к ответственным за компонент разработчикам.
Естественно, вся эта красота была придумана не только для ручного тестирования. Наши тесты тоже стали вовсю использовать QaApi: тесты стали быстрее и атомарнее, тестируют только то, что действительно должны тестировать (разумеется, отдельные тесты на упрощаемые таким образом операции тоже есть).
А когда мы решили, что и этого недостаточно, то реализовали QaApi-сценарии, которые позволяют писать на Lua (не спрашивайте) простые скрипты, которые посредством вызова различных методов в один клик подготавливают даже сложные данные для тестирования сложных кейсов.
2.3. Улучшенное окружение и инструментарий
Помимо способов оптимизировать и автоматизировать тестирование на девеле, конечно же, очень важны способы сделать его максимально полным и приближенным к продакшену.
Например, CLI-скрипты. Раньше они запускались с помощью крона. Соответственно, если тестировщик хотел проверить новую версию какого-нибудь скрипта, он должен был сделать следующее:
- закомментировать строчку запуска скрипта в кронтабе;
- убить все действующие инстансы этого скрипта;
- запустить свою версию скрипта и протестировать ее;
- убить все свои инстансы этого скрипта;
- раскомментировать строчку в кронтабе.
 Пропуск любого из этих этапов приводит к проблемам либо для самого тестировщика (может работать не та версия скрипта, которую он ожидает), либо для всех окружающих (скрипт не работает и никто не знает, почему).
Пропуск любого из этих этапов приводит к проблемам либо для самого тестировщика (может работать не та версия скрипта, которую он ожидает), либо для всех окружающих (скрипт не работает и никто не знает, почему).Сейчас же у нас таких проблем не бывает: все скрипты гоняются в общем скриптовом фреймворке, на девел-версии которого есть возможность сказать скрипту: «Запускайся теперь из моей рабочей директории, а не из общей». При этом любые ошибки или истечение тайм-аута возвращают скрипт обратно на общий поток, а система проследит за тем, чтобы все воркеры были только нужной версии.
Другая проблема — множественные A/B тесты. У нас их в каждый момент времени проходят буквально десятки. Раньше нужно было либо создавать десяток пользователей, чтобы захватить все варианты тестов, либо хакать код, чтобы намеренно пихать своих пользователей в интересующие тебя в данный момент варианты. А теперь мы используем общую систему UserSplit, позволяющую для каждого конкретного теста добавлять QA-настройки вида «Вот этот юзер всегда получает вот этот вариант» и всегда быть уверенным, что ты проверяешь именно то, что тебе нужно в данный момент.
3. Тестирование в «шоте»
Что такое «шот» в нашем понимании? Фактически это ветка задачи (плюс текущий мастер) в продакшен-окружении. С технической точки зрения он представляет собой директорию с нужной версией кода на одной из наших машин в стейджинговом кластере и строчку в конфиге NGINX, которая направляет в эту папку http-запросы вида habr-1.shot. Таким образом шот можно указывать в качестве сервера для любых клиентов — как для веба, так и для мобильных. Создавать шоты для конкретной задачи могут все инженеры с помощью ссылки в JIRA.
Предназначен он в первую очередь для проверки работоспособности задачи в реальном окружении (вместо очень похожего, но все-таки «синтетического» девела), но также и для решения дополнительных задач, таких как генерация и проверка переводов (для того чтобы переводчики работали с новыми лексемами до попадания задачи на стейджинг и не задерживали релиз остальных задач). Также существует возможность пометить шот как external — и тогда он будет доступен не только из нашей рабочей сети (или по VPN), но и из интернета. Это позволяет нам предоставить возможность тестировать задачу нашим партнерам, например, при подключении нового платежного метода.
Главное изменение, которое произошло за последние годы —это автоматический запуск тестов в шоте сразу же после его генерации (шот гораздо более стабильное окружение, чем девел, поэтому результаты тестов здесь всегда намного релевантнее и реже дают ложные результаты). AIDA запускает здесь два вида тестов: Selenium-тесты и cUrl-тесты. Результаты их прогонов постятся в задачу и отправляются лично ответственному за задачу тестировщику.
 А что делать, если измененный или добавленный функционал не покрыт Selenium-тестами?! В первую очередь — не паниковать. Тестами у нас покрывается только устоявшийся либо критический функционал (наш проект очень быстро развивается, и покрытие тестами каждой экспериментальной фичи сильно бы замедлило этот процесс), а задачи на написание новых тестов ставятся уже после релиза задачи на продакшен.
А что делать, если измененный или добавленный функционал не покрыт Selenium-тестами?! В первую очередь — не паниковать. Тестами у нас покрывается только устоявшийся либо критический функционал (наш проект очень быстро развивается, и покрытие тестами каждой экспериментальной фичи сильно бы замедлило этот процесс), а задачи на написание новых тестов ставятся уже после релиза задачи на продакшен.А если тест есть и упал? У этого может быть две возможные причины. В первом случае в задаче есть ошибка: программист не молодец и должен задачу чинить, а тесты сделали свою работу. Во втором случае функционал работает исправно, но его логика (или даже просто верстка) изменилась и тест более не соответствует текущему состоянию системы. Нужно чинить тест.
 Раньше этим у нас занималась отдельная группа QA-инженеров, ответственная за автоматизацию. Они умели делать это хорошо и быстро, но все равно каждый релиз ломал какое-то количество тестов (иногда огромное), и ребята тратили гораздо больше времени на поддержание системы, чем на ее развитие. В результате мы решили изменить подход к этому делу: провели ряд семинаров и лекций, чтобы каждый QA-инженер имел хотя бы базовые навыки для написания Selenium-тестов (а заодно и модифицировали наши библиотеки так, чтобы писать тесты стало удобнее и проще). Теперь, если в задаче тестировщика начинает падать тест, он сам же чинит его в ветке задачи. Если же случай очень сложный и требующий серьезных изменений, то все-таки отдает задачу знающим людям.
Раньше этим у нас занималась отдельная группа QA-инженеров, ответственная за автоматизацию. Они умели делать это хорошо и быстро, но все равно каждый релиз ломал какое-то количество тестов (иногда огромное), и ребята тратили гораздо больше времени на поддержание системы, чем на ее развитие. В результате мы решили изменить подход к этому делу: провели ряд семинаров и лекций, чтобы каждый QA-инженер имел хотя бы базовые навыки для написания Selenium-тестов (а заодно и модифицировали наши библиотеки так, чтобы писать тесты стало удобнее и проще). Теперь, если в задаче тестировщика начинает падать тест, он сам же чинит его в ветке задачи. Если же случай очень сложный и требующий серьезных изменений, то все-таки отдает задачу знающим людям.4. Тестирование на стейджинге
Итак, задача прошла свои три
Вот здесь уже проходят ВСЕ наши тесты. При изменении стейджинг-ветки запускаются смоук-тесты и полные наборы наших системных, интеграционных и юнит-тестов. Каждая ошибка в них передается ответственным за релиз людям.
Затем тестировщик проверяет задачу на стейджинге. Главным образом здесь нужно проверять совместимость задачи с остальными, уехавшими на стейджинг (их у нас в каждом билде порядка двадцати).
 О нет, что-то все-таки сломалось! Надо как можно скорее разобраться, какой тикет в этом виноват! Этому поможет наша простая, но мощная система Selenium manager. Она позволяет просмотреть результаты прогонов тестов в шоте каждой задачи, находящейся на стейджинге, и запустить не прогонявшиеся тесты (по умолчанию при создании шота запускается не полный сьют). Таким образом часто можно обнаружить тикет-виновник… Но далеко не всегда. Тогда приходится рыться в логах и искать виновный код самостоятельно: все-таки не все еще можно оптимизировать.
О нет, что-то все-таки сломалось! Надо как можно скорее разобраться, какой тикет в этом виноват! Этому поможет наша простая, но мощная система Selenium manager. Она позволяет просмотреть результаты прогонов тестов в шоте каждой задачи, находящейся на стейджинге, и запустить не прогонявшиеся тесты (по умолчанию при создании шота запускается не полный сьют). Таким образом часто можно обнаружить тикет-виновник… Но далеко не всегда. Тогда приходится рыться в логах и искать виновный код самостоятельно: все-таки не все еще можно оптимизировать.И вот мы нашли этот проблемный тикет. Если все совсем плохо и решение проблемы требует продолжительного времени, мы откатываем тикет со стейджинга, пересобираем билд и продолжаем спокойно работать, пока невезучий разработчик чинит произошедшее. Но если же для исправления ошибки достаточно просто поменять один символ в одной строчке?
 Раньше разработчики фиксили такие проблемы прямыми коммитами в билдовую ветку. Это достаточно быстро и удобно, но это настоящий кошмар с точки зрения QA. Проверить такой «приложенный к ранке лист подорожника» достаточно сложно, а еще сложнее — найти все такие фиксы и обнаружить виновника, если он вызвал новую ошибку в другом месте. Долго жить так было нельзя, и наши релиз-инженеры написали собственный интерфейс патчей.
Раньше разработчики фиксили такие проблемы прямыми коммитами в билдовую ветку. Это достаточно быстро и удобно, но это настоящий кошмар с точки зрения QA. Проверить такой «приложенный к ранке лист подорожника» достаточно сложно, а еще сложнее — найти все такие фиксы и обнаружить виновника, если он вызвал новую ошибку в другом месте. Долго жить так было нельзя, и наши релиз-инженеры написали собственный интерфейс патчей.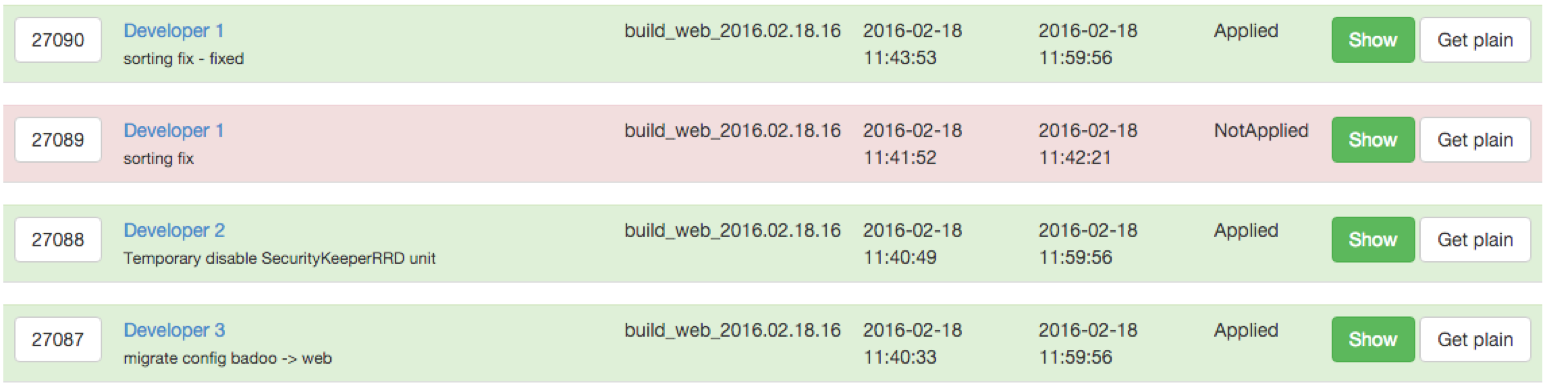
Он позволяет приложить Git-патч к текущему билду с описанием решаемой проблемы, отмеченным именем автора и возможностью предварительного ревью со стороны другого разработчика или тестирования со стороны QA. Каждый патч привязывается к той или иной задаче, и при откате задачи из билда все привязанные к ней патчи также автоматически будут откачены.
Кажется, все всё проверили. Кажется, можно ехать на продакшен. Точно ли? Раньше ответственному за релиз инженеру приходилось самостоятельно выяснять, все ли в порядке: смотреть результаты прогонов тестов, узнавать, действительно ли все упавшие Selenium-тесты починены, все ли задачи проверены, все ли патчи протестированы и применены… Огромное количество работы и очень большая ответственность. Поэтому мы собрали такой простенький интерфейс, позволяющий каждому ответственному за тот или иной компонент (или блок тестов) поставить галочку «у меня все хорошо», и как только вся табличка зеленеет — можно ехать.

Итак, мы справились! Можно праздновать, разливать шампанское и танцевать на столе… На самом деле нет. Скорее всего, впереди еще несколько часов рабочего времени. И вполне вероятно — еще один релиз. Но даже и это не главное: контроль качества задачи не завершается в момент ее отправки пользователям!
5. Верификация на продакшене
 Обязательно нужно проверить, что под давлением продакшен-окружения и сотен тысяч (или миллионов!) пользователей задача ведет себя именно так, как ожидалось. Большие и сложные проекты мы изначально выкладываем только на часть аудитории (например, только в рамках определенной страны) для того, чтобы оценить работоспособность и стрессоустойчивость системы в боевых условиях. Оценкой результатов таких экспериментов с разных сторон занимаются все участники процесса: и разработчики, и тестировщики, и менеджеры. И даже после того, как такой «эксперимент» был признан успешным и новая фича разъехалась на всех пользователей, даже несмотря на работу полноценного отдела мониторинга, всегда полезно и самим внимательно поглядеть на состояние системы после релиза: все-таки живые пользователи могут нагенерировать больше кейсов, чем может придумать мозг самого изощренного тестировщика.
Обязательно нужно проверить, что под давлением продакшен-окружения и сотен тысяч (или миллионов!) пользователей задача ведет себя именно так, как ожидалось. Большие и сложные проекты мы изначально выкладываем только на часть аудитории (например, только в рамках определенной страны) для того, чтобы оценить работоспособность и стрессоустойчивость системы в боевых условиях. Оценкой результатов таких экспериментов с разных сторон занимаются все участники процесса: и разработчики, и тестировщики, и менеджеры. И даже после того, как такой «эксперимент» был признан успешным и новая фича разъехалась на всех пользователей, даже несмотря на работу полноценного отдела мониторинга, всегда полезно и самим внимательно поглядеть на состояние системы после релиза: все-таки живые пользователи могут нагенерировать больше кейсов, чем может придумать мозг самого изощренного тестировщика.К чему это я?
Всегда есть куда стремиться и развиваться. 4 года назад я пришел в Badoo и был в восторге от того, как здесь все было классно устроено. Я активно участвовал в развитии процессов и уже через год выступал на конференциях, рассказывая, что стало ЕЩЕ лучше. Прошло три года — и я не представляю, как мы жили без QaApi, без таких классных авто-тестов и других прекрасных и удобных штук. Посидите как-нибудь в свободное время и пофантазируйте, что бы вы хотели изменить или усовершенствовать в своих собственных процессах? Дайте волю воображению, придумайте самые невероятные фичи и поделитесь ими с товарищами. Очень может быть, что-то из этого страшно нужно всем окружающим, а реализация будет далеко не такая фантастичная, как вам может показаться. И тогда вы все (а в конечном счете и ваши пользователи) станете немного счастливее.
Кудинов Илья, Sr. QA Engineer
Комментарии (30)


dohlik
16.12.2016 11:26+2Слегка оффтоп, но все же спрошу. На недавней конференции в Баду рассказывали про техническое ревью, когда разработчик-исполнитель описывает в тикете, как он понял постановку задачи. То есть по сути переводит с менеджерского на разработческий. И далее это ревью проверяется командой на корректность.
Можете немного подробнее рассказать, как это реализовано, всегда ли оно выполняется и тд.
Relz
16.12.2016 13:50+1Надеюсь, я правильно понял ваш вопрос, если нет — уточните, пожалуйста.
Ревью задачи/проекта у нас выглядит так:
1. Когда PRD готово оно проходит ревью команды продукта: разработчик PRD проводит презентацию и все участники продукт-команды обсуждают все кейсы, вопросы за и против и так далее.
2. После проведения данного ревью, идет почтовая рассылка, в которой каждый заинтересованный может оставить свой фидбэк.
3. Также есть техническая API-команда, которая тесно содействует с продуктом при написании протокола (то есть также проводит процесс ревью).
4. Kick off внутри команды разработки. Совещание, которое проводится до начала разработки проекта, где как раз обсуждаются все кейсы, продукты рассказывают про проект, а тех отдел делает свое ревью по данному проекту. До проведения kick-off'a все участники проекта знакомятся с PRD.
5. По выполнении задачи она отправляется на код-ревью, где коллеги-разработчики могут проверить детали реализации и подходы к решению той или иной проблемы.
6. После прохождения код-ревью разработчик составляет сообщение для отдела QA, в котором рассказывает, как с технической точки зрения был реализован проект, чтобы мы при изучении задачи могли понять ход его мысли.
И на каждом из этих этапов в PRD могут вноситься различные поправки и дополнения, чтобы проект ушё на продакшн максимально проработанным и развитым.dohlik
16.12.2016 14:00Соответственно, это только для новых продуктов или при заметной переработке существующих, так? Для багфиксов и мелких улучшений это будет выглядеть бюрократией, имхо
Relz
16.12.2016 14:02Да, багфиксы и мелкие исправления логики обычно даже не проходят полноценный этап PRD, а начинают жизнь уже в задаче в JIRA — в таком быстроразвивающемся проекте как наш иначе жить было бы невозможно

Al8xRomanov
16.12.2016 12:37+1Огромное спасибо за статью. Тулзы и подход к автоматизации вдохновляют.
Есть вопросы:
— как работает Selenium manager?
— как Вы обнаруживаете «тикет виновник»?
— сохранили ли у Вас отдельную должность автоматизатора или этими задачами занимаются девелоперы?Relz
16.12.2016 12:45+1Дождёмся автора Selenium Manager'а с больничного и отпишем развёрнутый ответ, может быть даже полноценную статью :)
Совсем вкратце — это веб-приложение, которое позволяет просмотреть результаты тестов в шоте каждой задачи, находящейся сейчас в билде и запустить на каждом шоте тест, который по той или иной причине не запускался. По результатам прогона этого теста на каждом шоте часто можно найти, какой шот виновен в поломке теста:

Насчёт автоматизаторов: разработчики пишут только интеграционные и юнит-тесты. В нашем отделе QA есть три специалиста, занимающиеся поддержкой Selenium и smoke-тестов фулл-тайм, они же занимаются поддержкой инфраструктуры, Selenium-grid фермы и всего такого. Все остальные QA-инженеры занимаются разработкой тестов наравне с непосредственным тестированием задач.Al8xRomanov
16.12.2016 13:29+2Спасибо за ответ. Буду ждать еще отдельной статьи.

nizkopal
16.12.2016 14:05+1Илья все верно написал про Selenium Manager. От себя могу только добавить, что на работе с шотами его функционал не заканчивается.
В целом я писал веб-интерфейс для простого запуска тестов «в один клик», без необходимости ставить локально selenium server, знать ключи для запуска тестов и вообще каким-либо образом «смотреть под капот».
Изначально он умел запускать один тест для указанного окружения, затем научился запускать несколько тестов параллельно. После добавилась система инвестигейтов (почти как в ТимСити) к тестам: если какой-то тест не работает по известной причине (оформленной в виде задачи), он заносится в эту систему и при запуске тестов со специальным ключом, с которым мы гоняем их для шотов и стейджинга, автоматически скипается, чтобы не засорять лог заведомо известными ошибками. И так далее…
В итоге получился довольно удобный и расширяемый инструмент. Обязательно соберусь написать о нем в следующем году. :)roversochi
28.03.2017 09:22Спасибо, заказал себе несколько штук.
nizkopal
16.12.2016 16:22+1На данный момент нет: большая часть функционала Selenium Manager'а завязана на нашем флоу и наших проектах.
Я оформлю статью в виде туториала, в котором постараюсь разделить бизнес-логику с реализацией непосредственно самого запуска тестов и манипуляцией данных — всякого рода инвестигейтов, дашбордов и прочего.
В идеале получится пример, который можно будет скопировать лишь частично, внося изменения по своему вкусу, но, в конечном итоге, описывающий суть инструмента.nizkopal
16.12.2016 16:23+1Ух! Разрекламировал так, что теперь от статьи точно не отмазаться. Пошел рефакторить код… :)

AnROm
16.12.2016 13:51+2Сначала подумала, что вот, очередная реклама, а нет, статья, на мой взгляд, стоит прочтения. Спасибо, что поделились опытом.

Deenamo
16.12.2016 15:14+1Отличная статья, мне лично особенно полезны идеи для pre-receive hooks, вот прямо сейчас отправился реализовывать на своем проекте.
Расскажите пожалуйста подробнее, как вы решаете проблему совместимости задач (когда отдельные задачи, успешно протестированные в своих шотах, «ломают» друг друга в совместном билде)?
Насколько я понял, Selenium manager позволяет покопаться в тестах каждого отдельного тикета + мастер, но не комбинации тикетов.
И как выглядит откатывание тикета на практике? Откат мастера до прошлого релиза + повторный мердж всех тикетов кроме подозреваемого «виновника», или есть более умные решения?Relz
16.12.2016 16:15Как бы хорош не был Selenium Manager, он позволяет в автоматическом режиме обнаружить только часть проблем. Если же проблема возникает только в комбинации задач — да, сидим и проверяем различные комбинации руками, либо всё же по текстам ошибок и симптомам пытаемся сразу обнаружить виновников — всё таки редко из 20 задач более двух затрагивают один и тот же компонент. Не представляю, как это можно было бы эффективно и дёшево автоматизировать.
По поводу отката вам лучше ответит кто-нибудь из наших релиз-инженеров, постараюсь прикастовать кого-нибудь из них в эту ветку (:
nizkopal
16.12.2016 16:28+1Вот тут мы в свое время выкладывали статью о том, как работает наш gitflow в целом и система отката в частности: https://habrahabr.ru/company/badoo/blog/169417/
Там много интересного, советую ознакомиться на досуге.
Ответ на ваш вопрос:
«Если с задачей в релизе что-то не так, то мы откатываем ветку с ней при помощи git rebase. Эта функция используется не случайно: нам не подходит revert, так как после отката релизная ветка сольётся в master, а ветки с задачами постоянно из него обновляются. В итоге, когда разработчик проблемной задачи обновит свою ветку, его код пропадёт, и придётся делать revert на коммит revert.»
ShaggyRatte
16.12.2016 16:29+2Касательно отката задач
На самом деле, была целая статья про автоматизацию: https://habrahabr.ru/company/badoo/blog/169417/
Если лень читать, вот ответ именно на ваш вопрос: мы используем git-rebase и с помощью него убираем коммиты, которые относятся к задаче, включая различные правки (патчи). Есть альтернативный вариант с git-revert, но он кажется нам менее удобным :)
Я не очень понял про «откат мастера» в вопросе. На всякий случай уточню, что мы собираем билд в виде отдельной ветки, которая попадет в мастер только после всех проверок, в т.ч. на production окружении.Deenamo
16.12.2016 16:54Теперь понятно, спасибо.
По поводу отката, я неясно выразился – конечно же, откат ветки билда до текущего мастера (предполагая, что предыдущие билды уже были смерджены в мастер).

w4r_dr1v3r
16.12.2016 22:59+1Весьма! Автору большой спасибр за техинсайд, обязательно пишите ещё, очень полезно и познавательно новичкам вроде меня.

greabock
18.12.2016 02:01+1— Я вам говорю: «Не думайте о слонах». О чём вы сейчас думаете?
— О слонах.Почему Lua?
Relz
19.12.2016 16:41+1Сами удивились. Изначально сценарии «на коленке» написал для себя один из наших разработчиков, а потом выложил это дело в общий доступ (вообще многие наши qa-инструменты имеют подобный жизненный цикл).
А сам он выбрал lua потому что он прост как две копейки, наши сценарии на нём выглядят почти человекопонятными фразами, да ещё и в php он встраивается простым расширением.
Так что ответ на ваш вопрос — «Так получилось»

ilvar
20.12.2016 16:08Я правильно понял, что степень покрытия кода тестами проверяется вручную при code review? Может ли быть такое, что изменение в одном куске кода (попавшее в ревью) вынесло из покрытия другой кусок (не попавший в ревью — он же не изменился), и никто об этом не узнает?
Relz
20.12.2016 16:13В полностью автоматическом режиме — да, об уменьшении покрытия какого-то конкретного места мы не узнаем. Но мы дважды в день собираем полный каверидж по всему проекту — и по уменьшившемуся покрытию компонента можно будет узнать, что что-то не так. А на плохо покрытые тестами места у нас регулярно заводятся тикеты.
ilvar
20.12.2016 16:17Это хуже, чем автоматическая проверка 100% покрытия при прогоне автотестов (у нас так), но все же неплохо — особенно
на плохо покрытые тестами места у нас регулярно заводятся тикеты.
Спасибо!Relz
20.12.2016 16:30+1Мы однажды писали статью о том, как мы фантастически увеличили скорость сборки кавериджа: https://habrahabr.ru/company/badoo/blog/192538/
С тех пор всё стало ещё лучше, но все равно полная сборка кавериджа занимает чуть более часа и порядочно нагружает машину. Делать это на каждый тикет (ещё раз повторю — до 40 тикетов релизится в день) несколько затруднительно :)
Krizai
23.12.2016 23:53Спасибо за статью. Было бы интересно узнать как происходит тот же процесс на проектах mobile клиентов.
wir_wolf
Ребята, спасибо за статью. Вы круты и делаете реально крутые вещи и что самое главное делитесь опытом с другими. С нетерпением жду новой какой-то интересной статьи.
Relz
Вам спасибо! Когда я выступаю с докладом или пишу статью и это кажется полезным хотя бы одному человеку (а тем более если это побуждает его к каким-либо созидательным действиям), то я знаю, что работа была сделана не напрасно. Думаю, мои коллеги придерживаются того же мнения.