 Свою предыдущую статью я посвятил тому, как и на сколько можно ускорить аналитические (типовые для OLAP/BI систем) запросы в СУБД Oracle за счёт подключения опции In-Memory. В продолжение этой темы я хочу описать несколько альтернативных СУБД для аналитики и сравнить их производительность. И начать я решил с in-memory RDBMS Exasol.
Свою предыдущую статью я посвятил тому, как и на сколько можно ускорить аналитические (типовые для OLAP/BI систем) запросы в СУБД Oracle за счёт подключения опции In-Memory. В продолжение этой темы я хочу описать несколько альтернативных СУБД для аналитики и сравнить их производительность. И начать я решил с in-memory RDBMS Exasol.Для тестов, результаты которых я публикую, выбран TPC-H Benchmark и при желании читатели могут повторить мои тесты.
Краткая информация о СУБД Exasol
Exasol – это реляционная аналитическая in-memory база данных со следующими ключевыми характеристиками:
- In-memory. БД в первую очередь предназначена для хранения и обработки данных в оперативной памяти. При этом данные дублируются на диск и вся база данных не обязательно должна помещаться в память. При выполнении запросов отсутствующие в памяти данные читаются с диска;
- MPP (massive parallel processing). Данные распределяются по узлам кластера для высокопроизводительной параллельной обработки (реализована по архитектуре shared nothing);
- Сolumn-wise data storage. Информация в таблицах хранится по столбцам в сжатом виде, что значительно ускоряет аналитические запросы;
- Поддерживает стандарт ANSI SQL 2008;
- Хорошо интегрируется с большинством BI инструментов;
- In-Database Analytics. Поддержка пользовательских функций на языках LUA, Python, R, Java.
- Java-based интерфейс к Hadoop’s HDFS.
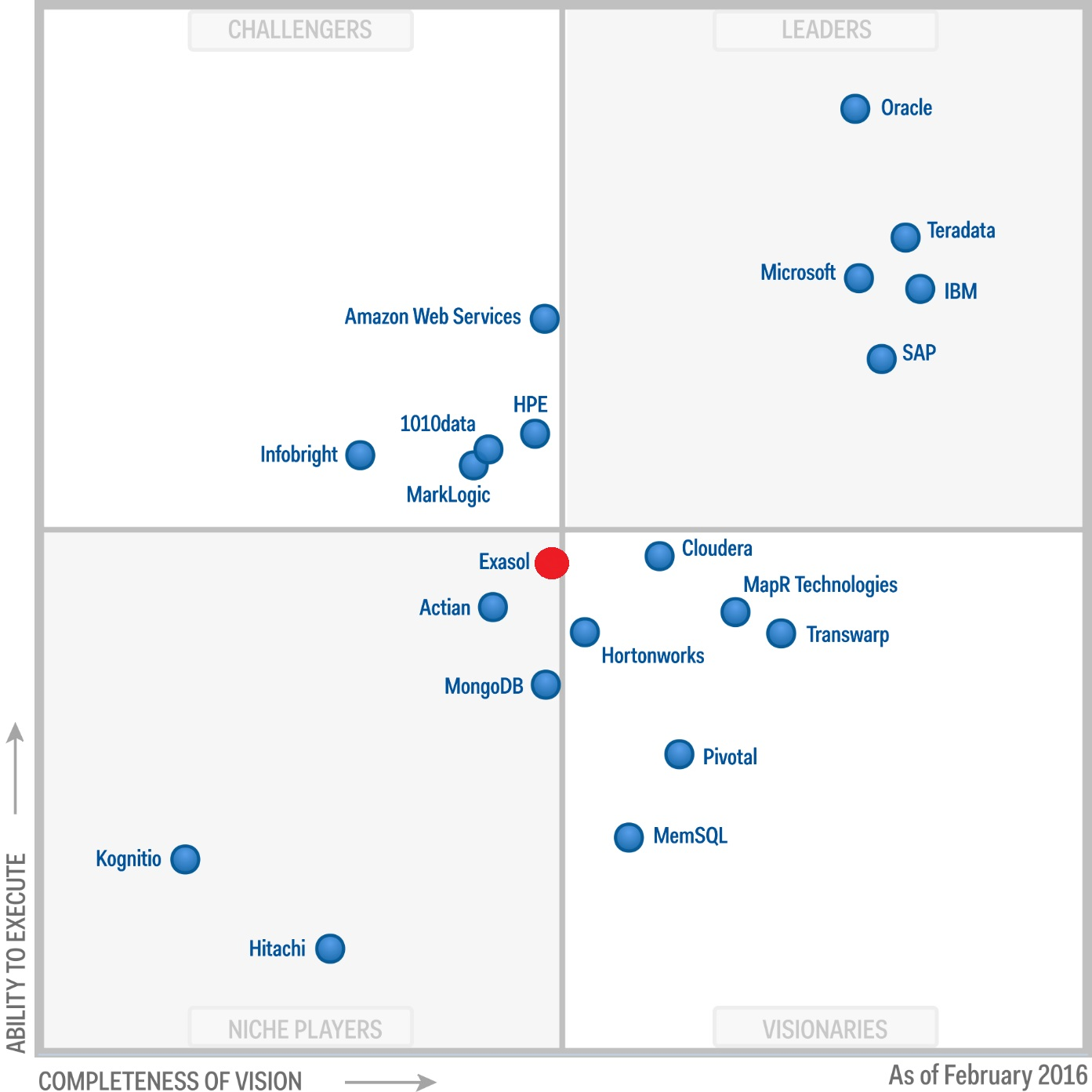
Более подробно про возможности Exasol можно прочитать в отличной статье на Хабре. Добавлю только то, что, несмотря на невысокую популярность в наших краях, это зрелый продукт, который присутствует в Gartner Magic Quadrant for Data Warehouse and Data Management Solutions for Analytics с 2012 года.
TPC-H Benchmark
Для теста производительности я использовал tpc-h benchmark, который используется для сравнения производительности аналитических систем и хранилищ данных. Этот бенчмарк используют многие производители как СУБД, так и серверного оборудования. На странице tpс-h доступно много результатов, для публикации которых необходимо выполнить все требования спецификации на 136 страницах. Я публиковать официально свой тест не собирался, поэтому всем правилам строго не следовал. В рейтинге TPC-H — Top Ten Performance Results Exasol является лидером по производительности (на объёмах от 100 Гб до 100 Тб), что и стало изначально причиной моего интереса к этой СУБД.
TPC-H позволяет сгенерировать данные для 8-ми таблиц с использованием заданного параметра scale factor, который определяет примерный объём данных в гигабайтах. Я ограничился 2 Гб, так как на этом объёме тестировал Oracle In-Memory.

Бенчмарк включает 22 SQL запроса различной сложности. Отмечу, что сгенерированные утилитой qgen запросы, нужно корректировать под особенности конкретной СУБД, но в случае Exasol изменения были минимальны: замена set rowcount на LIMIT clause и замена keyword value. Для теста было сгенерировано 2 вида нагрузки:
- 8 виртуальных пользователей параллельно 3 раза по кругу выполняют все 22 запроса
- 2 виртуальных пользователя параллельно 12 раз по кругу выполняют все 22 запроса
В итоге, в обоих случаях оценивалось время выполнения 528-ми SQL запросов. Кого заинтересуют DDL cкрипты для таблиц и SQL запросы, напишите в комментариях.
Для целей сравнения БД или оборудования для аналитики (в т.ч. для Big Data) ещё рекомендую обратить внимание на другой более свежий benchmark — TPC-DS. В нём больше таблиц и значительно больше запросов – 99.
Тестовая площадка
Ноутбук со следующими характеристиками:
Intel Core i5-4210 CPU 1.70GHz – 4 virt. processors; DDR3 16 Gb; SSD Disk.
ОС:
MS Windows 8.1 x64
VMware Workstation 12 Player
Virtual OS: CentOS 6.8 (Memory: 8 Gb; Processors: 4)
СУБД:
EXASOL V6 Free Small Business Edition rc1 (single node)
Загрузка данных в БД Exasol
Данные я загружал из текстовых файлов с помощью утилиты EXAplus. Скрипт загрузки:
IMPORT INTO TPСH.LINEITEM
FROM LOCAL CSV FILE 'D:\lineitem.dsv'
ENCODING = 'UTF-8'
ROW SEPARATOR = 'CRLF'
COLUMN SEPARATOR = '|'
SKIP = 1
REJECT LIMIT 0;Время загрузки всех файлов составило 3 мин. 37 сек. Отмечу ещё, что очень приятное впечатление оставила документация с множеством примеров. Так, в ней описан ряд альтернативных способов загрузки данных: напрямую из различных СУБД, c использованием ETL инструментов и другие.
Далее в таблице представлена информация о том, как данные организованы в Exasol и Oracle In-Memory:
| Exasol | Oracle IM | |||||||
|---|---|---|---|---|---|---|---|---|
| Таблица | Кол-во строк | Объём сырых данных (Mb) | Объём таблиц в памяти (Мб) | Коэф. сжатия | Кол-во индексов | Объём индексов в памяти (Мб) | Объём таблиц в памяти (Мб) | Коэф. сжатия |
| LINEITEM | 11 996 782 | 1 562.89 | 432.5 | 3.61 | 4 | 109.32 | 474.63 | 3.29 |
| ORDERS | 3 000 000 | 307.25 | 97.98 | 3.14 | 2 | 20.15 | 264.38 | 1.16 |
| PARTSUPP | 1 600 000 | 118.06 | 40.46 | 2.92 | 2 | 5.24 | 72.75 | 1.62 |
| CUSTOMER | 300 000 | 39.57 | 20.99 | 1.89 | 2 | 1.42 | 32.5 | 1.22 |
| PART | 400 000 | 51.72 | 10.06 | 5.14 | 1 | 1.48 | 20.5 | 2.52 |
| SUPPLIER | 20 000 | 2.55 | 2.37 | 1.08 | 4.5 | 0.57 | ||
| NATION | 25 | 0 | 0.01 | 0.00 | 1.13 | 0.00 | ||
| REGION | 5 | 0 | 0.01 | 0.00 | 1.13 | 0.00 | ||
| TOTAL | 17 316 812 | 2 082.04 | 604.38 | 3.44 | 11 | 137.61 | 871.52 | 2.39 |
Эту информацию в Exasol можно посмотреть в системных таблицах SYS.EXA_ALL_OBJECT_SIZES и SYS.EXA_ALL_INDICES.
Результаты выполнения теста
| Oracle IM | Exasol | |
|---|---|---|
| 8 сессий (1-й запуск), сек. | 386 | 165 |
| 8 сессий (2-й запуск), сек. | ~386 | 30 |
| 2 сессии (1-й запуск), сек. | 787 | 87 |
| 2 сессий (2-й запуск), сек. | ~787 | 29 |
Таким образом, видим, что данный тест на Exasol выполняется быстрее относительно Oracle IM при 1-м запуске и значительно быстрее со 2-го запуска. Ускорение повторных выполнений SQL запросов в Exasol обеспечивается за счёт автоматического создания индексов. 11 индексов заняли в оперативной памяти примерно 23% относительно размера самих таблиц, что, на мой взгляд, стоит такого ускорения. Отмечу, что Exasol не даёт возможности управлять индексами. Приведу перевод фразы из документации на тему оптимизации:
EXASolution сознательно прячет сложные механизмы настройки производительности для клиентов, такие, как например: создание различных типов индексов, вычисление статистики по таблицам и т.д. Запросы в EXASolution анализируются с помощью оптимизатора и необходимые для оптимизации действия выполняются в полностью автоматическом режиме.
Ещё по результатам выполнения видно, что в моём случае Oracle лучше параллелил запросы (8 сессий в сравнении с 2-мя). С причинами этого я пока детально не разбирался.
Exasol в облаке
Для желающих самостоятельно оценить производительность Exasol без необходимости устанавливать виртуальную ОС и загружать данные есть демо Exasol in the cloud. После регистрации мне предоставили доступ на 2 недели к кластеру из 5 серверов. Там доступна TPCH схема со Scale Factor = 50 (50 Gb, ~433 млн. записей). 2-й запуск моего теста с 2-мя сессиями на этих данных занял примерно 2 минуты.
В заключение
Для себя я сделал вывод, что СУБД Exasol – отличный вариант для построения хранилища данных и аналитической системы на нём. В отличии от универсальной Oracle DB, Exasol создана для аналитики. Можно привести аналогию с автомобилями: для поездок на рыбалку хорошо иметь внедорожник, а для передвижения по городу компактный легковой авто.
Как и в предыдущей статье призываю всех делать какие-либо серьёзные выводы только после тестов на ваших конкретных кейсах.
На этом пока всё, на очереди тест для HPE Vertica.
P.S.: Буду очень благодарен, если ребята из Тинькофф Банк (@Kapustor) поделятся информацией о своём итоговом выборе, а Badoo (@wildraid) новостями проекта.
Комментарии (16)

Omankit
26.12.2016 08:06+3Вот интересно как так можно анализировать производительность. В статье два расходящихся факта:
1) субд работает лучше всего от 100гб
2) сравнение в статье идёт на системе с 2гб
mkrupenin
26.12.2016 09:30Нету тут противоречия, по указанной ссылке просто нет результатов для других объёмов. Указал диапазон, чтобы была понятней область применения СУБД. К слову, 100 Тб — максимальный scale factor для tpc-h согласно спецификации.
alexxz
26.12.2016 12:03В Badoo с Exasol всё отлично. Продолжаем наращивать кластер и обвязку над ним. Особых эксплуатационных проблем в нём не встречали пока. В трудных местах ETL добавили функций на питоне. Очень ждём Exasol 6 и его интеграции с HCatalog. А в настоящий момент рассматриваем как-бы нам 40Тб данных Exasol бекапить пооптимальнее.
А по новым плюшкам, надеюсь wildraid тут отпишет 8)mkrupenin
26.12.2016 13:36Спасибо alexxz, очень интересен ваш опыт.
Можете ещё поделиться, какой подход используете для модели DWH (3NF, DataVault, Kimball, Anchor,...)?
Меня в Exasol очень заинтересовало то, что они рекомендуют использовать полностью нормализованную модель (например, Data Vault), не опасаясь проблем с производительностью запросов при соединении множества таблиц. Планирую это проверить.alexxz
26.12.2016 15:16Ну, ни одной модели в чистом виде у нас нет. Есть 2 основных фактора, которые берутся в учёт при добавлении данных — исходный формат данных и требования от reporting tool (Microstrategy). Если тормозит, проводим подготовку в ETL под конкретный репортинг.
Двумя самыми важными факторами оптимизации, обычно, выступают DISTRIBUTE BY и точное совпадение типов данных в полях JOIN, есть и много других, но эти два — ключевые. Хотя, в вашем тестовом примере для Single node дистрибуция не даст ничего.
Автогенеренными суррогатными ключами не увлекаемся. По строкам джойнит пекрасно. Джойны маленьких справочников (до сотен тысяч), как правило производительность аффектят не сильно.
Практикуем большие CTE, которые Exasol переваривает хорошо. Ещё у Exasol есть слой кеширования результатов view, но у нас он выключен.

wildraid
26.12.2016 15:56Если коротко, то почти нет проблем с JOIN'ами.
У нас много случаев, когда внешний софт создаёт гигантские запросы, в которых соединяет по 30+ таблиц. Больших и маленьких, с группировкой и без, с sub-select'ами и CTE. До тех пор, пока промежуточный результат остаётся в рамках разумного, всё хорошо работает.
За редким исключением, нет необходимости как-то трансформировать данные специально для наилучшей производительности. Проекций, pre join'ов, вручную создаваемых индексов нет. Есть DISTRIBUTE BY, который здорово помогает снизить нагрузку на сеть, но он не обязателен.
wildraid
26.12.2016 16:10Чуть-чуть комментариев по самой статье.
1) После загрузки данных и построения индексов есть смысл запустить RECOMPRESS. Коэффициент сжатия заметно улучшится. В обычной жизни Exasol сам периодически запускает его в background по мере роста объёма данных. Также последний блок в таблице хранится без сжатия для оптимизации быстрых маленьких INSERT'ов.
Проще говоря, чем больше таблица и чем чаще её используют, тем лучше будет сжатие. В некоторых случаях коэффициент может спокойно дойти до 10 и выше.
2) У Exasol на самом деле одна сессия выполняет запрос. Вторая сессия — это ExaPlus подключился, чтобы считывать мета-данные без конфликтов. Имена схем, таблиц, функций, вот это всё. Если во время выполнения теста посмотреть, чем она занята, то будет статус IDLE.wildraid
26.12.2016 16:19Извиняюсь, поздно заметил, что речь о сессиях теста, а не про EXA_ALL_SESSIONS. Комментарий уже не могу изменить.
Если сессии теста запускались синхронно, то первый результат 165 может объясняться тем, что каждая из восьми сессий строила собственные индексы в своей транзакции. Потом семь индексов из восьми выбросили, а один оставшийся был использован во втором запуске.

robert_ayrapetyan
А сколько стоит?
jam31
Если поймаете их промо для стартапов, то облачная база до 500 гигабайт обойдётся всего в 500€ в месяц.
mkrupenin
Ещё можно ориентироваться на спец. предложение для Tableau:
до 100 Gb of raw data — 12 000 Евро
до 500 Gb — 26 000
до 2 Тб — 45 000
Не думаю, что итоговая договорная стоимость для других кейсов, будет значительно дороже.
SLASH_CyberPunk
Та же HP Vertica в разы лучше по производительности, так еще и по слухам, в разы дешевле получается, не говоря про халявные 1 Тб данных…
wildraid
Не стоит сравнивать по этому предложению. По сути, это Exasol + Cloud + Tableau + Support.
Чистые лицензии Exasol'а куда более гибкие и могут не иметь ограничений по размеру загружаемых данных.
Всё не так однозначно. Лучше сравнивать конкретные предложения от обоих вендоров.
wildraid
Free Small Business Edition — бесплатно, в том числе для коммерческого использования.
200GB памяти на одной ноде будут держать примерно 1Tb сырых данных без сжатия.
Также, видимо, ничто не мешает поднять несколько таких instance'ов и, при необходимости, делать между ними запросы через SELECT… FROM EXA (...).