
Очень часто, созданию базы данных CDR отводится мало места в описаниях настройки. Как правило, все сводится к цитате SQL команд и обещанию, что если кинуть ее в консоль то «все будет ОК».
К примеру, первая же ссылка в гугле рекомендует создать табличку таким образом:
CREATE TABLE `cdr` ( `calldate` datetime NOT NULL default '0000-00-00 00:00:00', `clid` varchar(80) NOT NULL default '', `src` varchar(80) NOT NULL default '', `dst` varchar(80) NOT NULL default '', `dcontext` varchar(80) NOT NULL default '', `channel` varchar(80) NOT NULL default '', `dstchannel` varchar(80) NOT NULL default '', `lastapp` varchar(80) NOT NULL default '', `lastdata` varchar(80) NOT NULL default '', `duration` int(11) NOT NULL default '0', `billsec` int(11) NOT NULL default '0', `disposition` varchar(45) NOT NULL default '', `amaflags` int(11) NOT NULL default '0', `accountcode` varchar(20) NOT NULL default '', `userfield` varchar(255) NOT NULL default '' ); ALTER TABLE `cdr` ADD INDEX ( `calldate` ); ALTER TABLE `cdr` ADD INDEX ( `dst` ); ALTER TABLE `cdr` ADD INDEX ( `accountcode` );
Сразу можно обратить внимание, что как минимум два индекса в базе бесполезны. Это calldate и accountcode. Первый в силу того, что при ежесекундном добавлении записей, размер индекса будет равен количеству записей в самой базе. Да, этот индекс отсортирован, и можно применить некоторые способы к ускорению поиска, но будет ли он эффективен? Второй индекс (accountcode) практически никогда и никем не используется. В качестве подопытной базы — база с 80 млн записей.
Выполним запрос:
SELECT * FROM CDR WHERE src=***** AND calldate>'2016-06-21' AND calldate<'2016-06-22';
/* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 00:09:36 */Почти 10 минут ожидания.
Другими словами, создание отчетов становится проблемой. Конечно, табличку можно ратировать, но зачем такие жертвы, если достаточно провести оптимизацию.
Внимание! Никогда не делай это в продакшене! Только на копии базы! База лочится на время от 1 часа до нескольких и возможны потери данных при аварийном завершении!
Итак, два шага к успеху эффективного хранения CDR:
- Разбить на партиции, чтобы ускорить выборку по периодам
- Эффективное индексирвоание
Шаг 0. Выбор движка хранения
Собственно есть два распространенных варианта — MyISAM и INNODB. Холиварить на эту тему можно бесконечно долго, но сравнение движков на реальной базе дало перевес в пользу MyISAM.
Причин тут несколько:
- При чистой настройке сервера неопытным админом, именно MyISAM более корректно работает при индексации больших объемов. В то время, как INNODB требует тюнинга. В противном случае можно увидеть интересные ошибки о том, что индекс не может быть перестроен
- MyISAM при включении опции FIXED ROW приобретает дополнительные свойства, а именно:
- Устойчивость к сбоям даже при падении сервера
- Возможность читать файл напрямую из внешнего приложения, минуя сервер MySQL, что бывает полезно
- Скорость обращения к рандомным строкам выше, за счет того, что все строки имеют одинаковую длину
Другими словами, для логирования лучше всего (ИМХО) подойдет MyISAM.
Остановимся на нем.
Шаг 1. Партиции.
В виду того, что мы либо дополняем базу, либо читаем из нее, эффективно раз и навсегда поделить базу на файлы, чтобы уменьшить возможное количество обращений, при чтении определенных временных промежутков. Естественно, разбивать базу нужно по какому-то ключу. Но по какому? Определенно, это должно быть время, но эффективно ли бить базу по calldate? Думаю нет, поэтому вводим дополнительное поле, которое нам также пригодиться и в следующем шаге. А именно — дату. Просто дату, без времени.
Вводим дополнительное поле date, и делаем очень простой триггер на табличку, before update cdr:
BEGIN
SET new.date=DATE(new.calldate);
END
Таким образом, в это поле у нас попадет только дата. И сразу разбиваем табличку на партиции по годам:
ALTER TABLE cdr PARTITION BY RANGE (YEAR(date))
(PARTITION old VALUES LESS THAN (2015) ENGINE = MyISAM,
PARTITION p2015 VALUES LESS THAN (2016) ENGINE = MyISAM,
PARTITION p2016 VALUES LESS THAN (2017) ENGINE = MyISAM,
PARTITION p2018 VALUES LESS THAN (2018) ENGINE = MyISAM,
PARTITION p2019 VALUES LESS THAN (2019) ENGINE = MyISAM,
PARTITION p2020 VALUES LESS THAN (2020) ENGINE = MyISAM,
PARTITION p2021 VALUES LESS THAN (2021) ENGINE = MyISAM,
PARTITION p2022 VALUES LESS THAN (2022) ENGINE = MyISAM,
PARTITION p2023 VALUES LESS THAN (2023) ENGINE = MyISAM,
PARTITION pMAXVALUE VALUES LESS THAN MAXVALUE ENGINE = MyISAM) Готово, теперь если мы будем выборку делать с указанием диапазона даты, то MySQL не придется лопатить всю базу за все года. Небольшой плюсик уже есть.
Шаг 2. Индексируем базу.
Собственно, это самый важный шаг. Эксперименты показывают, что в 90% случаев возникает необходимость в индексах на 3 столбцах (по мере необходимости):
- date
- src
- dst
date
MySQL может использовать только один индекс за раз, поэтому некоторые администраторы пытаются создавать составные индексы. Эффектность их не очень высока, потому что как правило приходиться выбирать диапазоны, а в этом случае составные индексы игнорируются MySQL, т.е. происходит FullScan. Исправить поведение скуля мы не можем, но можем сделать так, чтобы количество строк для сканирования было минимальным и дать движку выбор, какой индекс использовать. С одной стороны, нам необходима максимальная подробность индекса, с другой стороны нам нужно затратить как можно меньше операций, чтобы получить диапазон, который мы будем перебирать. Именно поэтому и рекомендую использовать индекс по полю date, а не calldate. Количество элементов в индексе будет равно количеству дней, с момента начала ведения базы, что позволит базе быстро перейти к нужным строчкам.
Есть еще один споcоб помочь базе — сделать так, чтобы она могла вычислить положение строки в файле еще ДО открытия файла. Именно для этого можно использовать FIXED ROW. Положение строки в файле будет вычисляться умножение номера строки на длину строки, а не перебором. Естественно, у того подхода есть жертвы — база будет занимать на диске значительно больше места. Вот к примеру:

Размер базы вырос с 18 Гб до 53,8 Гб. Делать или нет — выбор каждого админа, но если место на сервере позволяет, то это будет еще одним плюсиком.
src,dst
Тут несколько меньше простора для оптимизаций. Точнее, один момент:
Если у вас не используется текстовых номеров, например в софтфонах, то данные поля можно преобразовать в BigInt, что тоже очень хорошо скажется на индексировании и выборке. Но если, Вы как и мы, используете текстовые номера, то данная оптимизация не для вас и придется смириться с более низкой производительностью.
В качестве вишенки на торте — подчищаем те поля, которые нас не интересуют и выставляем размер полей в ожидаемый для нашего случая. У меня получилось вот так:
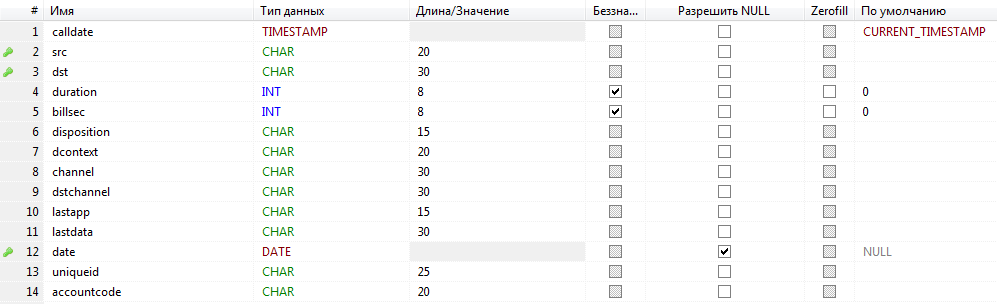
Ну и финальный запрос:
SELECT * FROM CDR WHERE src=***** AND date='2016-06-21';
/* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 0,577 sec. */Прирост на два порядка.
Для примера еще, по диапазону:
SELECT * FROM CDR WHERE src=***** AND date>'2016-09-01' AND date<'2016-09-05';
/* Affected rows: 0 Найденные строки: 1 Предупреждения: 0 Длительность 1 query: 3,900 sec. */Комментарии (18)

miksoft
29.12.2016 19:05MySQL может использовать только один индекс за раз
В сформулированном виде — это неверно.
Как минимум, см. http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
приходит
Не игнориуются, если поля в индексе в правильном порядке для конкретного запроса.ься выбирать диапазоны, а в этом случае составные индексы игнорируются MySQL, т.е. происходит FullScan
http://dev.mysql.com/doc/refman/5.7/en/range-optimization.html
xomiakba
29.12.2016 20:07Как минимум, см. http://dev.mysql.com/doc/refman/5.7/en/index-merge-optimization.html
Это я тоже читал. На практике, скуль ни разу не применил объединение индексов, предпочитая полное сканирование строк, даже если их было несколько миллионов.
Завтра постараюсь более подробно предоставить EXPLAIN запросов, которыми тестировал базу.
Не игнориуются, если поля в индексе в правильном порядке для конкретного запроса.
Утром повторю эксперимент с индексами на базе, выложу EXPLAIN.
Если окажется что был не прав, дополню статью составными индексами. Но статья родилась после нескольких дней изучения вопроса и практического применения.miksoft
29.12.2016 20:37Завтра постараюсь более подробно предоставить EXPLAIN запросов, которыми тестировал базу.
И укажите, пожалуйста, кардинальность полей и диапазоны значений.
Это облегчит понимание причин неиспользования формально подходящих индексов.
Например, если залиты данные всего за трое суток, то при отборе данных за сутки от индекса, скорее всего, толку будет мало.xomiakba
30.12.2016 09:05-1В базе 80 млн записей, диапазон — последние 4 года с одного из серверов (реальные данные).
Добавил индексы:
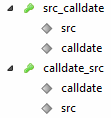
Запрос:

Ключ calldate,src отработал. НО:
SELECT * FROM CDR WHERE src=*****AND calldate>'2016-06-21' AND calldate<'2016-06-22'; /* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 6,068 sec. */
6 секунд против 0,577 сек из статьи. Использование такого индекса пока под вопросом.
mayorovp
30.12.2016 13:16Я, конечно, знал что в MySQL с оптимизацией запросов все плохо — но не настолько же!
Этот запрос должен хорошо ложиться на индекс (src, calldate). А вот индекс (calldate, src) особо помогать и не должен.
miksoft
30.12.2016 14:01А вот индекс (calldate, src) особо помогать и не должен.
Да, там по key_len видно, что использовано только первое поле из индекса.
И литерал во фрагменте src=***** должен быть того же типа, что само поле src, т.к. иногда MySQL ошибается с направлением неявного преобразования типов.
xomiakba
30.12.2016 15:11Ну я же ничего не придумал, сухая практика.
Иногда теория и практика вещи разные, увы.
xomiakba
30.12.2016 09:14Вот кстати план запроса из статьи по индексу date:

Он быстрее отрабатывает из-за того что приходиться лопатить меньше ключей в индексе, и возвращает меньшее число строк для сканирования.
Возможно имеет смысл скомбинировать два варианта и сделать индекс date+src. Попробую, но индексация займет несколько часов.xomiakba
30.12.2016 11:09Проиндексировалось.

Но MySQL предпочел его не использовать:

Если форсировать использование индекса, то видим такую картину:

У меня большая часть запросов при написании статьи, составные индексы не использовала. Кроме того, диапазон для сканирования строк, которые получаются при составных ключах всегда больше, если брать именно CDR таблицы.
Индексы:

Такие дела.
miksoft
30.12.2016 13:56Но MySQL предпочел его не использовать:
После создания индексов очень желательно делать ANALYZE TABLE.
Если индекс все равно не подхватывается, а должен, то надо попробовать указать его явно в запросе.

Insspb
30.12.2016 04:12+2Что за мода давать картинки не по теме? Ну пишите вы про Астериск, так сделайте нормальную картинку. 3 минуты втыкал что к чему.

shutkarmannbii
30.12.2016 09:07Картинка прям крутая, первое впечатление от заголовка и картинки — статья про использование CD-R

UserAd
30.12.2016 17:41+1А зачем делать триггер? Если у вас уже есть поле, то просто можно сделать где надо
exten… => SET(CDR(date)=${STRFTIME(${EPOCH},,%d%m%Y)}))
lexore
30.12.2016 18:23Мне кажется, если бы у вас calldate был в формате unixtime, работало бы шустро без дополнительного поля date.
Ещё вариант, вместо одного datetime сделать два поля: date и time.

foxmuldercp
30.12.2016 19:05Duration и billsec я бы не занулял. толку от знания про звонок, если по факту у него длительность 3 секунды до автоответчика на той стороне. или же наоборот, полтора часа разговора на нерабочие темы, например.
miksoft
План запроса смотрели?
Имхо, хватило бы индекса (src,calldate). Поля в индексе должны быть именно в таком порядке, чтобы диапазон по calldate работал.
xomiakba
Некорректно выразился, имелось в виду количество ключей в индексе, по которым скуль отбирает диапазоны для сканирования.
Эти индексы работают только для точной выборки, при выборке по диапазону значений они будут проигнорированы. Из CDR в 90% случаев как раз выбирают по диапазону дат и исходящих номеров (групп пользователей) или номеров назначения. Стоит ли поддерживать составной индекс для незначительного ускорения 10% запросов, с учетом того что индекс по дате и так дает прирост производительности? Пробовал на этой базе делать составные индексы, на реальной нагрузке профит оказался меньше, чем казалось в теоретической части. В продакшене можно легко от составных индексов отказаться без существенной потери производительности. Зато время пересчета индексов будет меньше.