
Об успехах Google Deepmind сейчас знают и говорят. Алгоритмы DQN (Deep Q-Network) побеждают Человека с неплохим отрывом всё в большее количество игр. Достижения последних лет впечатляют: буквально за десятки минут обучения алгоритмы учатся и выигрывать человека в понг и другие игры Atari. Недавно вышли в третье измерение — побеждают человека в DOOM в реальном времени, а также учатся управлять машинами и вертолетами.
DQN использовался для обучения AlphaGo проигрыванием тысяч партий в одиночку. Когда это ещё не было модным, в 2015 году, предчувствуя развитие данного тренда, руководство Phobos в лице Алексея Спасского, заказало отделу Research & Development провести исследование. Необходимо было рассмотреть существующие технологий машинного обучения на предмет возможности использования их для автоматизации победы в играх управленческих. Таким образом, в данной статье пойдёт речь о проектирование самообучающегося алгоритма в игре виртуального управленца против живого коллектива за повышение производительности.
Прикладная задача анализа данных машинного обучения классически имеет следующие этапы решения:
- формулировка проблемы;
- сбор данных;
- подготовка данных;
- формулировка гипотез;
- построение модели;
- валидация модели;
- представление результатов.
В данной статье будет рассказано о ключевых решениях в проектировании интеллектуального агента.
Более подробные описания этапов от постановки задачи до представления результатов опишем в следующих статьях, если читателю будет интересно. Таким образом, вероятно, мы сможем решить задачу рассказа о многомерном и неоднозначном результате исследования не теряя в понятности.
Выбор алгоритма
Итак, для выполнения задачи поиска максимума эффективности управления коллективом было решено использовать глубокое обучение с подкреплением, а именно Q-learning. Интеллектуальный агент формирует функцию полезности Q каждого действия из доступных ему на основе вознаграждения или наказания от перехода в новое состояние среды, что дает ему возможность уже не случайно выбирать стратегию поведения, но учитывать опыт предыдущего взаимодействия с игровой средой.
Основная причина выбора именно DQN в том, что для обучения агента этим методом не требуется модель ни для обучения, ни для выбора действия. Это критичное требование к методу обучения по той простой причине, что формализованной модели коллектива людей с применимой на практике предсказательной силой пока не существует. Тем не менее, анализ успехов искусственного интеллекта в логических играх показывает, что преимущества подхода, основанного на экспертных знаниях, становятся более явными по мере усложнения среды. Это обнаруживается в шашках и шахматах, где оценка действий на основе модели имела больший успех, чем Q-learning.
Одна из причин того, что обучение с подкреплением ещё не оставляет без работы офисных клерков в том, что метод плохо масштабируется. Проводящий исследование среды Q-обучающийся агент — активный ученик, который должен неоднократно применить каждое действия в каждой ситуации для того чтобы составить свою Q-функцию оценки выгодности всех возможных действий во всех возможных ситуациях.

Если, как в старых винтажных играх, число действий исчисляется количеством кнопок на джойстике, а состояний — положением мячика, то у агента уйдут десятки минут и часов на обучение для победы над человеком, то в шахматах и GTA5 комбинаторный взрыв уже делает число комбинаций игровых состояний и возможных действий космическим для прохождения учеником.
Гипотеза и модель
Чтобы эффективно использовать Q-learning для управления коллективом, мы должны максимально уменьшить размерность состояний среды и действий.
Наши решения:
- Первое инженерное решение заключалось в том, чтобы представить управленческую деятельность в виде совокупности мини-игр. Каждая из них имеет дискретные количества состояний и действий таких, что порядок комбинаций сопоставим с успешно решенными игровыми задачами. Таким образом, не нужно строить алгоритм, который будет искать оптимальную управляющую стратегию в многомерном пространстве, но множество агентов превосходят игрока-человека в тактических играх. Пример такой игры — управление задачей в YouTrack. Состояния среды (грубо) — время в работе и статус, а действия — открытие, переоткрытие таска, назначение ответственного. Подробнее ниже.
Пример онлайн-обучения простой игре:
https://cs.stanford.edu/people/karpathy/convnetjs/demo/rldemo.html
- Каждый сотрудник офиса — интеллектуальный агент усложняющий среду разнообразием своего поведения. Персонализация позволяет избегать мультиагентных сред, поэтому с одним сотрудником играет один обучающийся агент. В мини-игре с постановкой задач агент получает награду когда сотрудник работает эффективнее (быстрее решает задачи). Если для Q-обучающегося агента сотрудник (допустим, разработчик) окажется неуправляем, то алгоритм не сойдется.
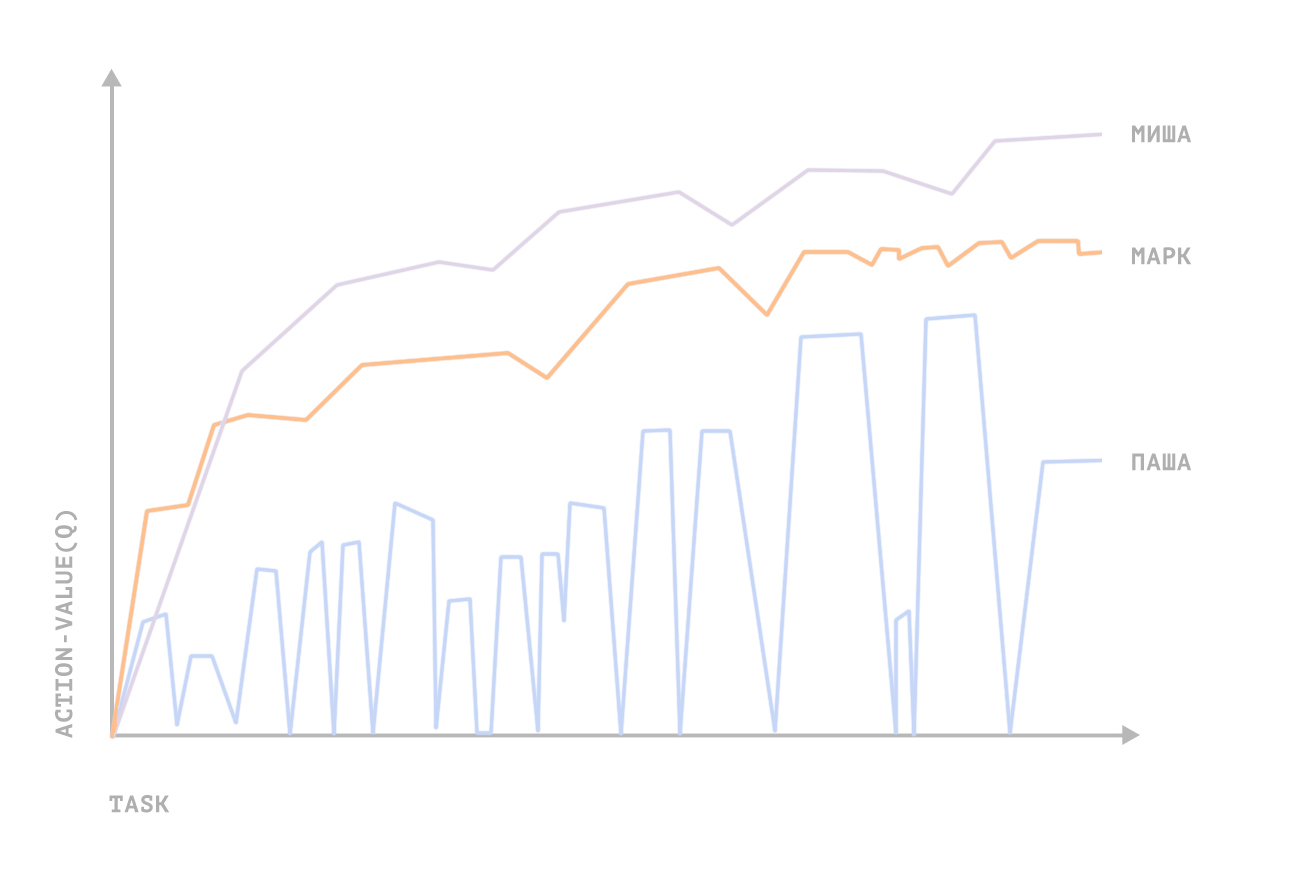
- Самое важное упрощение. В мини-игре по постановке сотрудникам задачи — непрерывное многомерное игровых состояний, хотя бы только из-за параметра времени потраченного на задачу. А самое плохое — не очевидно определяются награды за действия агента. Игровая среда, как конечное множество состояний для каждой мини-игры и расчёт поощрения в том или ном состоянии, на 90% формализованная нашими управленцами бизнес-логика. Это наиболее трудоемкий и важный момент, поскольку именно в формуле экспертной оценки состояний и содержаться экспертные знания, которые являются неявной моделью среды и действий, а также определяют размер вознаграждения в обучении агента. От предсказательной силы данной неявной модели и зависела успешность обучения агента.
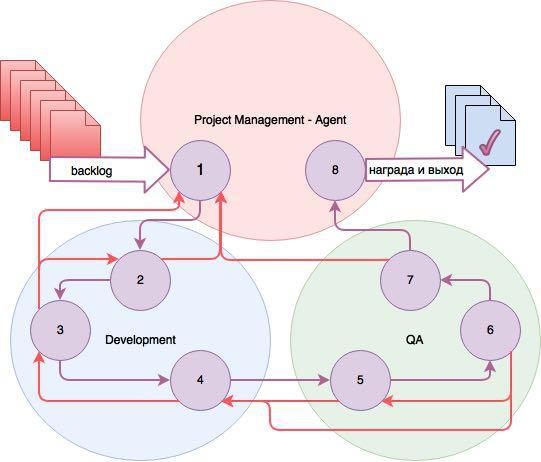
На схеме представлены состояния трёх игровых сред для трёх агентов, управляющих ходом работы над таском.
Состояния:
- Задача зарегистрирована (backlog);
- Задача открыта;
- В работе;
- Разработка завершена, задача открыта для тестирования (QA);
- Открыта для тестирования;
- Тестируется;
- Готова, протестирована;
- Закрыта.
Список действий для каждого из трёх агентов свой. Project Manager — Agent назначает исполнителя и тестировщика, время и приоритет задачи. Агенты, работающие с Dev и QA, персональны для каждого исполнителя и тестировщика. Если происходит переход таска дальше, агенты получают награды, если таск возвращается назад — наказания.
Наибольшую награду все агенты получают при закрытии таска. Также для Q-обучения DF и LF (фактор дисконтирования и обучения соответственно) подбирались таким образом, чтобы агенты были ориентированы именно на закрытие таска. Расчёт подкрепления в общем случае происходит по формуле оптимального управления учитывающей, помимо прочего, разницу в оценке времени и реальными затратами, количество возвратов задачи итд. Плюсом данного решения является его возможность масштабируемости на больший коллектив.
Заключение
Железо на котором выполнялись расчеты — GeForce GTX 1080.
Для приведённой выше мини-игры с постановкой и ведением задачи в Youtrack, управляющие функции сошлись на значения выше средних (продуктивность сотрудника возросла относительно работы с менеджером-человеком) для 3 человек из 5. Общая производительность (в часах) выросла почти вдвое. Довольных экспериментом сотрудников из тестовой группы не было; недовольных 4; один воздержался от оценок.
Тем не менее, мы для себя сделали выводы, что для применения метода «на бою» необходимо вносить в модель экспертные знания по психологии. Общая продолжительность разработки и тестирования — более года.
Комментарии (10)

rhangelxs
18.01.2017 00:39Можно немного подробнее про датасет… Например, сколько было всего задач в анализе?

Code_phobos
18.01.2017 11:56-11. Была установлена система трекинга YouTrack. Дисциплина по отчётам о проделанных задачах ужесточена — отчитываться нужно было о каждом таске, каждой мелочи. Также, ответственные за исполнение задач теперь должны были выставлять оценки исполнителям. Считалась каждая минута просроченных задач или задач на опережение. В общей совокупности было собрано порядка 15000 задач;
2. Получали данные о создании спринтов на неделю;
3. Время работы сотрудников измеряли по активности рабочих сессиях на машинах.
Более подробная информация о входных и выходных данных, о взаимодействии с пользователями в материале для гиктаймс. Сейчас он под лучами НЛО проходит проверку. Ссылку прикрепим в комментариях или в самом тексте)Code_phobos
22.01.2017 13:04Мы опубликовали материал в Geektimes, где более подробно рассказали о других аспектах в этой теме — https://geektimes.ru/post/284910/

ServPonomarev
18.01.2017 08:00+1Насколько я понял, агент учится давать задачи тем исполнителям, которые их переводят в следующий статус максимально быстро. В идеале, агент определит специализацию каждого из управляемых сотрудников и будет давать им именно такие задачи. Повышая тем самым bus-фактор, разумеется.
В ситуации без менеджера вообще, исполнители и так бы брали себе наиболее комфортные задачи — то есть, произошло ровно такое-же распределение задач, как и с управлением.
И хотелось бы побольше почитать по результатам. С цифрами, если можно.Code_phobos
18.01.2017 12:01-1Наиболее комфортные, по мнению исполнителя, задачи не всегда те, которые он выполнит наиболее эффективно, а также необходимо распределять некомфортные задачи, часто в большом количестве. Цель использования агент-менеджера в максимизации именно конечного результата по всей совокупности задач, повышение эффективности коллектива в целом.
Такие, параметры задач, как дедлайн и приоритет влияют на эффективность выполнения задачи. Были обнаружены наиболее продуктивные сочетания пар тестировщика и разработчика.
На выходе агента:
1. Управляющие сигналы в систему постановки тасков: назначение и переназначение задач из уже созданных исполнителю; назначение/переназначение ответственного; установка дедлайнов, изменение приоритета задачи.
Одним из важных управляющих действий был коэффициент корректировки зарплаты, на который в конце месяца (в теории) умножается базовый оклад.
2. Сообщения особой важности при помощи api telegram транслировались в общий чат. «Важность» задач является одним из ключевых параметров связанным с эффективностью. Срочность и важность задач оценивались отдельной сетью, обученной с учителем. Затем она подставлялись в матрицу Эйхенхауэра.


mpakep
Вот он, тот момент когда план «Порабощения машинами человечества» начал воплощаться в жизнь.