
Если вы хотите просто взглянуть на код Python, проследуйте в репозиторий на GitHub.
Для подготовки материалов использован IPython Notebook. Вы можете скачать его по ссылке.
Аудиоанализ с использованием алгоритмов обработки изображений
Графические процессоры были разработаны с единственной целью – для имитации физических свойств света, но сегодня мы используем их для решения множества других, самых разнообразных задач. Можно ли воспользоваться алгоритмами обработки изображений за пределами привычной области? Почему бы не использовать их для обработки сигналов?
Для исследования этого вопроса я решил воспользоваться методом сопоставления шаблонов и изображений для определения аудио. Классические алгоритмы принимают на входе изображение и шаблон, а возвращают степень подобия шаблона любому участку изображения. Моей задачей было определить аудиозапись в базе данных, частью которой является аудиосэмпл, используя масочный метод сравнения (Это то, что делают Shazam или SoundCloud).
Предварительная обработка данных
Аудиоданные представляются в виде одномерного массива дискретных отсчетов, равномерно распределённых во времени. Одноканальные изображения, обычно, хранятся и обрабатываются как двумерные массивы, поэтому мне нужно было как-то представить аудиозапись в двух измерениях. Самый примитивный способ – это просто переформатировать одномерный массив в двумерный.
Однако на практике это нужно делать осторожно. Допустим, что мы начали захватывать аудио с источника на полсекунды позже начала записи в базе данных – полученные двумерные массивы этих двух записей будут сильно отличаться. Два пика, расположенные рядом, могу случайно оказаться на противоположных концах выборки.

Неочевидно, что второе изображение является частью (подвыборкой) первого.
Простой алгоритм сравнения с маской последовательно накладывает маску на изображение и производит сравнение (Здесь этим занимается функция match_template в skimage.feature). Алгоритмы, работающие подобным образом, не смогут распознать меньшее изображение, представленное выше, в большем.

Как вы можете видеть, match_template дает очень низкий шанс сопоставления шаблона с каким-либо участком изображения.
Воспользуемся преобразованием Фурье
Чувствительность к смещению временного диапазона может быть сведена к минимуму, если абстрагироваться от временной шкалы и перейти к уровню сигнала. Это делают с помощью дискретного преобразования Фурье (ДПФ), а делают быстро – с помощью быстрого преобразования Фурье или БПФ (Если вам нужно больше информации по ДПФ и БПФ, можете посмотреть пост Джейка Вандерпласа (Jake VanderPlas)).
Если мы применим преобразование Фурье к каждой колонке нашего переформатированного сигнала, то получим представление о том, как гармоники меняются с течением времени. Оказывается, что это довольно распространённая техника, широко используемая при создании спектрограмм.
По своей сути, преобразование Фурье говорит нам, какие из частот сигнала обладают самыми высокими энергиями. Поскольку гармоники аудиосигнала, обычно, меняются с течением времени, то спектрограмма заключает в себе свойства временной и частотной областей.
Давайте посмотрим на спектрограмму тестового звукового отрезка:
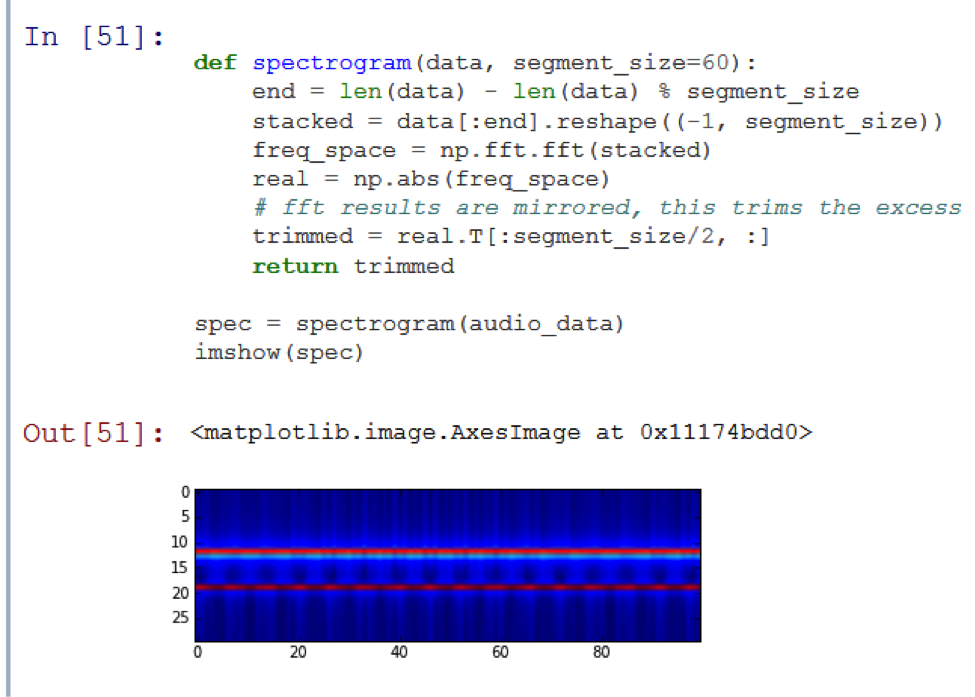
Как вы можете наблюдать, на картинке видны две горизонтальные линии. Это означает, что аудио состоит из совокупности двух неизменяющихся сигналов. Так получилось, потому что тестовая запись – это не что иное, как сумма двух синусоидальных сигналов различной частоты.
Теперь у нас есть что-то похожее на изображение и, в теории, наш подход хорошо работает с подвыборками, смещенными во времени. Давайте же проверим нашу теорию:

Успех! Функция match_template говорит нам, что эти два «изображения» имеют сильную корреляцию. Однако сработает ли алгоритм со звуком, который является чем-то большим, чем просто суммой синусоидальных сигналов?
Реальные данные
Я хочу сделать так, чтобы мой компьютер умел определять, какой эпизод заранее заданного сериала воспроизводится в данный момент. В качестве примера я буду использовать 1 сезон мультипликационного сериала Adventure Time. Я сохранил 11 WAV-файлов (по одному на каждый эпизод) в поддиректории adv_time.
{kind=link}
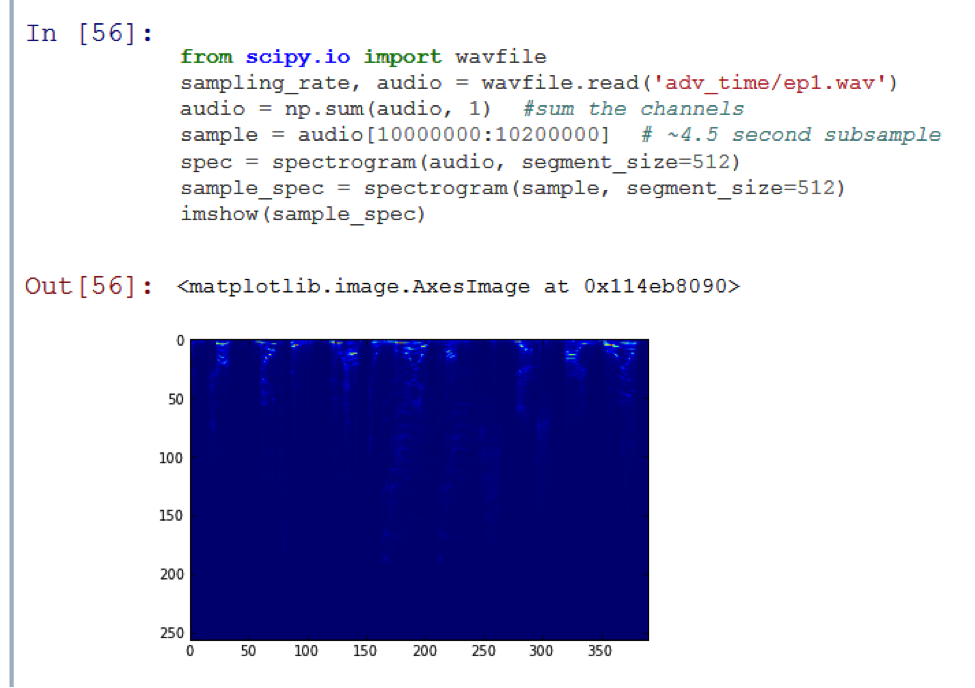
На результирующем графике появился пик! Функция match_template точно определила, что подвыборка является частью оригинальной аудиодорожки. Однако выполнение алгоритма сравнения заняло 20 секунд, что слишком долго. Чтобы его ускорить, нам нужно «потерять» часть данных.
Спросим Найквиста
Человек по имени Гарри Найквист показал нам, что наибольшая частота, которую мы можем достоверно определить, равна половине частоты дискретизации.

Частота дискретизации 44.1 кГц означает, что мы можем определять аудиочастоты до 22 кГц. Этого вполне достаточно, поскольку человеческое ухо воспринимает частоты в пределах только 20 кГц.
Однако на спектрограмме выше видно, что практически все интересующие нас данные находятся в верхней половине, а самое большое их количество – в верхней восьмой. Кажется, что область полезной информации, содержащейся на звуковой дорожке Adventure Time, даже близко не подходит к верхней границе человеческого восприятия. Это означает, что мы можем произвести передискретизацию с шагом 8, и не потерять слишком много важной информации.

Гораздо лучше. Субдискретизация ускорила выполнение функции в 15 раз, при этом по-прежнему выдавая четкий сигнал на фоне окружающего уровня шума, который составляет 71%. Однако я хочу еще сильнее ускорить обработку, повторно урезав количество данных. Если мы еще раз проведем субдискретизацию по времени, то начнем терять важную высокочастотную информацию. Но можно провести квантование.
Мы снова получили ускорение в 4 раза, по-прежнему сохранив хорошее соотношение сигнал/шум! Я вполне доволен скоростью выполнения алгоритма. Теперь я могу проводить сравнение пятисекундного сэмпла с двухчасовой аудиодорожкой менее чем за секунду. Но остался один, последний тест. Пока что мы использовали подвыборки, вырезанные из записей из базы данных. Мне нужно понять, работает ли алгоритм с сэмплами, записанными с помощью микрофона.

Результат эксперимента представлен после кода ниже. Сначала я подготовил аудиодорожки каждого эпизода и сохранил их в директории store. Затем я использовал pyaudio на своем ноутбуке, чтобы записать звук эпизода Adventure Time с телевизора.


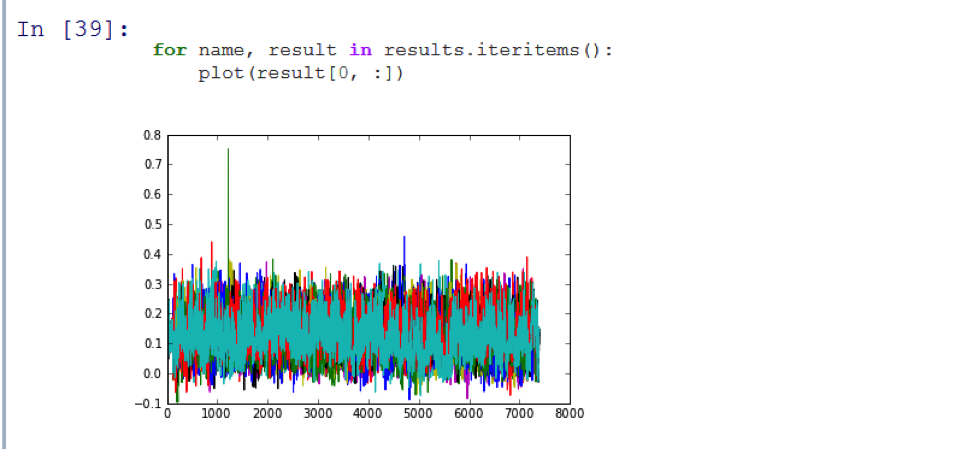
Работает! Как вы можете видеть, на результирующем графике виден пик, который означает, что программа верно распознала первый эпизод сезона. Написанный мною код смог идентифицировать первый из 11 эпизодов сериала Adventure Time с достаточной точностью и менее чем за 3 секунды.
Заключение
Мне удалось использовать алгоритмы обработки изображений за пределами их обычной области применения. У меня получилось создать работоспособное приложение, распознающее аудиозаписи. Возможно, оно реализовано не лучшим образом (я уверен, что Shazaam использует более эффективный алгоритм), но его создание оставило мне пару приятных впечатлений. Я пробовал другие методы, использующие сравнение с маской, например, модуляцию Корнера и SURF (смотрите на github), но классический подход оказался самым понятным и простым в исполнении. Дальнейшая работа может быть направлена на исследование других методов.
Я не писал чистый код, эффективно использующий память компьютера, и думаю, что из него можно выжать гораздо большую производительность. Кроме вопросов, касающихся работы с памятью, эти алгоритмы имеют еще множество проблем, которые нужно разрешить – я не тратил много времени на оптимизацию. Дальнейшая работа может раскрыть всю красоту субдискретизации по времени и частоте. Я бы также хотел поэкспериментировать с длиной семпла и его субдискретизацией.
Я бы хотел проверить надежность этого алгоритма в работе с разными источниками аудио. Проводимая мной субдискретизация не была привязана к определенному типу используемого мной аудио, но могла все испортить при подключении другого источника звука.
Весь код доступен на github.
reddot
Спасибо за перевод интересной статьи, но в абзаце про реальные данные картинка с результатами обрезана из-за чего суть повествования теряется. Пришлось дочитывать в оригинале.