 Создатели шаблонов в C++ заложили основу целого направления для исследований и разработки: оказалось, что язык шаблонов C++ обладает полнотой по Тьюрингу, то есть метапрограммы (программы, предназначенные для работы на этапе компиляции) C++ в состоянии вычислить всё вычислимое. На практике мощь шаблонов чаще всего применяется при описании обобщенных структур данных и алгоритмов: STL (Standard Template Library) тому живой пример.
Создатели шаблонов в C++ заложили основу целого направления для исследований и разработки: оказалось, что язык шаблонов C++ обладает полнотой по Тьюрингу, то есть метапрограммы (программы, предназначенные для работы на этапе компиляции) C++ в состоянии вычислить всё вычислимое. На практике мощь шаблонов чаще всего применяется при описании обобщенных структур данных и алгоритмов: STL (Standard Template Library) тому живой пример.Однако, с приходом C++11 с его
variadic-шаблонами, библиотекой type_traits, кортежами и constexpr'ами метапрограммирование стало более удобным и наглядным, открыв дорогу к реализации многих идей, которые раньше можно было воплотить только с помощью расширений конкретного компилятора или сложных многоэтажных макросов.В данной статье будет разработана реализация бинарного дерева поиска времени компиляции: структуры данных, являющейся логическим «расширением» кортежа. Мы воплотим бинарное дерево в виде шаблона и попрактикуемся в метапрограммировании: переносе рекурсивных и не только алгоритмов на язык шаблонов C++.
Содержание
- Немного теории
- Разминка: операции с кортежами и превращение числа в класс
- Бинарное дерево поиска
- Применение
- Что потом?
- Литература
Немного теории
Для начала вспомним некоторые определения и понятия о структурах данных и алгоритмах. Можно пропустить этот раздел и сразу перейти к деталям реализации, если читатель знаком с основами теории графов и/или представляет, что такое бинарные деревья и как их можно готовить.
Дерево с корнем — свободное дерево, в котором выделена одна вершина, называемая корнем (root).
Узлы (nodes) — вершины дерева с корнем.
Родительский узел или родитель узла X — последний узел, предшествующий X на пути от корня R к этому узлу X. В таком случае узел X называется дочерним к описанному родительскому узлу Y. Корень дерева не имеет родителя.
Лист — узел, у которого нет дочерних узлов.
Внутренний узел — узел, не являющийся листом.
Степень узла X — количество дочерних узлов этого узла X.
Глубина узла X — длина пути от корня R к этому узлу X.
Высота узла (height) — длина самого длинного простого (без возвратов) нисходящего пути от узла к листу.
Высота дерева — высота корня этого дерева.
Упорядоченное дерево — дерево с корнем, в котором дочерние узлы каждого узла упорядочены (т.е. задано отображение множества дочерних узлов на множество натуральных чисел от 1 до k, где k — общее количество дочерних узлов этого узла). Простыми словами, каждому дочернему узлу присвоено имя: «первый», «второй», ..., "k-тый".
Бинарное дерево (binary tree) — (рекурсивно) либо пустое множество (не содержит узлов), либо состоит из трёх непересекающихся множеств узлов: корневой узел, бинарное дерево, называемое левым поддеревом, и бинарное дерево, называемое правым поддеревом. Таким образом, бинарное дерево — это упорядоченное дерево, у которого каждый узел имеет степень не более 2 и имеет «левый» и/или/либо «правый» дочерние узлы.
Полностью бинарное дерево (full binary tree) — бинарное дерево, у которого каждый узел либо лист, либо имеет степень два. Полностью бинарное дерево можно получить из бинарного добавлением фиктивных дочерних листов каждому узлу степени 1.
Бинарное дерево поиска — связанная структура данных, реализованная посредством бинарного дерева, каждый узел которого может быть представлен объектом, содержащим ключ (key) и сопутствующие данные, ссылки на левое и правое поддеревья и ссылку на родительский узел. Ключи бинарного дерева поиска удовлетворяют свойству бинарного дерева поиска:
если X — узел, и узел Y находится в левом поддереве X, то Y.key ? X.key. Если узел Y находится в правом поддереве X, то X.key ? Y.key.Подразумевается, что мы умеем сравнивать ключи (на множестве значений ключа задано транзитивное отношение порядка, т.е. проще говоря операция «меньше») и говорить о равенстве ключей. В реализации без ограничения общности мы будем оперировать строгими неравенствами порядка, используя только операцию "<" и "==", построенную на её основе из соотношения
Обход дерева — формирование списка узлов, порядок определяется типом обхода.
Разминка: операции с кортежами и превращение числа в класс
Прежде чем окунуться с головой в рекурсивные дебри и насладиться буйством угловых скобок, поупражняемся в написании метафункций. Далее нам понадобятся функции конкатенации кортежей и функция добавления типа в существующий кортеж:
template <class U, class V>
struct tuple_concat;
template <class Tuple, class T>
struct tuple_push;
Стандарт C++11 вводит заголовочный файл
type_traits (как часть библиотеки поддержки типов), содержащий коллекцию полезных метафункций. Все они являются шаблонами структур, и после инстанцирования определяют локально некий тип type или числовую константу value (или ничего, как в случае отключения перегрузки с использованием std::enable_if). Мы будем придерживаться тех же принципов проектирования метафункций.Первая функция принимает в качестве аргументов шаблона два кортежа, вторая — кортеж и тип, который необходимо добавить в кортеж. Подстановка в качестве аргументов неподходящих типов (например, при попытке сделать конкатенацию
int и float) — операция бессмысленная, поэтому базовый шаблон этих структур не определяется (это предотвратит его инстанцирование для произвольных типов), а вся полезная работа делается в частичных специализациях:template <template <class...> class T, class... Alist, class... Blist>
struct tuple_concat<T<Alist...>, T<Blist...>> { using type = T<Alist..., Blist...>; };
template <template <class...> class Tuple, class... Args, class T>
struct tuple_push<Tuple<Args...>,T> { using type = Tuple<Args..., T>; };
Примерный перевод на человеческий язык специализации
tuple_concat:Если в качестве аргументов шаблона выступают два класса, которые в свою очередь являются результатами инстанцирования одного и того же шаблона класса (
T) с переменным числом аргументов, и они были инстанцированы с parameter pack'ами Alist и Blist, то определить локально псевдоним type как инстанцированую версию того же шаблона класса T с конкатенированным списком аргументов, т.е. T<Alist..., Blist...>.Звучит зловеще, но на практике всё проще, чем кажется: при попытке вызвать
tuple_concat с двумя кортежами одного вида (например, с двумя std::tuple), внутри структуры определится тип того же кортежа со «сшитым» списком аргументов входных кортежей. Иные попытки инстанцирования просто не скомпилируются (компилятор не сможет вывести типы для определенной выше частичной специализации, а инстанцирование общего шаблона окажется невозможным ввиду отсутствия его тела). Пример:using t1 = std::tuple<char,int>;
using t2 = std::tuple<float,double>;
using t3 = std::tuple<char,int,float,double>;
using conc = typename tuple_concat<t1,t2>::type;
// using err = typename tuple_concat<int,bool>::type; // ошибка
static_assert(std::is_same<t3,conc>::value, ""); // утверждение истинно, типы одинаковы
В свете вышесказанного рассмотрение специализации
tuple_push не должно составить большого труда. Дополнительно, для удобства определим соответственные псевдонимы шаблонов:template <typename U, typename V>
using tuple_concat_t = typename tuple_concat<U,V>::type;
template <typename Tuple, typename T>
using tuple_push_t = typename tuple_push<Tuple,T>::type;
Эта удобная возможность появилась в языке в C++11 стандарте: она, например, позволяет для доступа к
type вместо заковыристого typename tuple_concat<t1,t2>::type писать просто tuple_concat_t<t1,t2>.tuple содержит определение (не мета-)функции tuple_cat(), конструирующей кортеж посредством конкатенации неопределенного числа std::tuple'ей, переданных в качестве аргументов. Внимательный читатель может заметить, что tuple_concat может быть проще реализована посредством вывода типа результата decltype(tuple_cat(...)), однако, во-первых, полученная выше реализация не ограничена типом кортежа std::tuple, а во-вторых, это было разминочным упражнением для постепенного погружения в более сложную арифметику типов.Последние приготовления: не для дела, а для
/// Модно-молодёжно STL-like путём
template<size_t number>
struct num_t : std::integral_constant<size_t, number> {};
// ИЛИ классически определим внутренность руками
template<size_t number>
struct num_t { enum : size_t { value = number } };
Смысл у обоих определений один: инстанцирование шаблона с различными численными аргументами будет приводить к определению различных типов:
num_t<0>, num_t<13>, num_t<42> и т.д. Не более чем для удобства наделим эту структуру статическим числовым значением value, что позволит нам явно получать назад число из аргумента шаблона (посредством доступа some_num_type::value) без прибегания к выводу типа.Бинарное дерево поиска
Рекурсивное определение бинарного дерева поиска оказывается удобным для непосредственного воплощения в виде шаблона. Упрощенное определение
ДЕРЕВО : NIL | [ДЕРЕВО, ДАННЫЕ, ДЕРЕВО]
можно перефразировать как «дерево — ЭТО пустое множество ИЛИ множество из трёх элементов: дерево (т.н. левое поддерево), данные, дерево (т.н. правое поддерево)».
Помимо этого, как уже упоминалось, бинарное дерево поиска требует задания отношения порядка на множестве значений, хранящихся в узлах дерева (мы должны уметь как-то сравнивать и упорядочивать узлы, т.е. иметь операцию «меньше»). Каноничным подходом является разбиение данных узла на ключ и значение (ключи сравниваем, значения просто храним), но в нашей реализации в целях упрощения структуры без ограничения общности будем считать данные узла единым типом, для задания же отношения порядка воспользуемся специальным типом
Comp (comparator, поговорим о нём далее)./// Пустое множество
struct NIL {};
/// Узел
template<typename T, typename Left, typename Right, typename Comp>
struct node {
using type = T; // node value
using LT = Left; // left subtree
using RT = Right; // right subtree
using comp = Comp; // types comparator
};
/// Лист: узел без потомков (псевдоним шаблона)
template <typename T, typename Comp>
using leaf = node<T,NIL,NIL,Comp>;
Несмотря на то, что отношение порядка всё-таки задано на множестве хранимых в узлах типов, удобно приписать его самому дереву и хранить как часть типа этого дерева: при вызове метафункций поиска, вставки и обхода непустого дерева нет необходимости в дополнительном указании компаратора.
Сама по себе ситуация не критичная и имеет обходное решение в виде разделения объявлений и определений типов:
template<...>
struct one {
struct two;
using three = one<two, ...>;
struct two : one<three, ...> {};
};
Примечание: экспериментальным путём обнаружено, что такие структуры компилируются и инстанцируются современными gcc и clang, тем не менее, я пока не проверял строгое соответствие стандарту объявлений таких необычных шаблонов.Однако на практике работать с такими сущностями и создавать их оказывается очень, ОЧЕНЬ сложно. Обратная ссылка на родительский элемент производит интересный эффект: фактически наше «односвязное дерево» превращается в настоящий граф (вкусно!), который при любой модификации должен инстанцировать себя «единовременно», заново и полностью (грустно). Более глубокий анализ данной ситуации выходит за рамки настоящей статьи и входит в число моих дальнейших планов по исследованию возможностей метапрограммирования в C++.
Это не единственный способ реализации и представления дерева (например, можно хранить узлы в кортеже и проводить их индексацию), однако такое описание более наглядно и удобно для непосредственного применения алгоритмов работы с деревом.
Отношение порядка
Структура
Comp должна содержать метафункции сравнения типов (т.е. шаблоны операций «меньше» и «равно»). Напишем пример такого сравнителя, основанного на sizeof'ах типов (возможно, единственная числовая характеристика, определенная для всех полных типов):struct sizeof_comp {
template <typename U, typename V>
struct lt : std::integral_constant<bool, (sizeof(U) < sizeof(V))> {}; // меньше
template <typename U, typename V>
struct eq : std::integral_constant<bool, (sizeof(U) == sizeof(V))> {}; // равно
};
Здесь всё должно быть прозрачно:
lt — метафункция «меньше» для типов, eq — метафункция «равно». Использован подход, показанный ранее для определения типов чисел: наследование от std::integral_constant наделит инстанцированные lt и eq статическими булевыми значениями value.На практике конкретные деревья конкретных типов должны снабжаться сравнителем, специфичным для данной задачи. Например, напишем сравнитель для описанного ранее класса «числовых типов»:
struct num_comp {
template <typename U, typename V>
struct lt : std::integral_constant<bool, (U::value < V::value)> {};
template <typename U, typename V>
struct eq : std::integral_constant<bool, (U::value == V::value)> {};
};
Такой компаратор, вообще говоря, универсален и умеет сравнивать любые типы, содержащие статическое значение
value./// Шаблон для базового класса всех сгенерированных компараторов
template <typename lt_traits>
struct eq_comp {
template <typename U, typename V>
struct lt : std::integral_constant<bool, lt_traits::template lt<U,V>::value> {};
template <typename U, typename V>
struct eq : std::integral_constant<bool, (!lt<U,V>::value && !lt<V,U>::value)> {};
};
/// Переписаный компаратор sizeof, наследование наделит его метафункцией eq_comp::eq
struct sizeof_comp : public eq_comp<sizeof_comp> {
template <typename U, typename V>
struct lt : std::integral_constant<bool, (sizeof(U) < sizeof(V))> {};
};
/// Переписаный компаратор num_t
struct num_comp : public eq_comp<num_comp> {
template <typename U, typename V>
struct lt : std::integral_constant<bool, (U::value < V::value)> {};
};
Теперь у нас есть всё для того, чтобы явно, «руками», определить первое дерево типов:
using t1 = node<
num_t<5>,
node<
num_t<3>,
leaf<num_t<2>>,
leaf<num_t<4>>
>,
node<
num_t<7>,
NIL,
leaf<num_t<8>>
>
>;
Примечание: Здесь и далее в примерах по-умолчанию подразумевается сравнительnum_comp, явное указание его в списке аргументов шаблонов опускается. Вообще, после разработки операцииinsertнам не придётся строить деревья таким образом (явным определением).
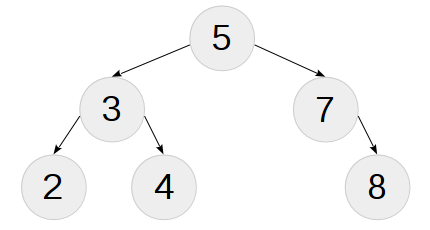
Эта отдельная интересная тема для дискуссии и исследования — отладка метапрограмм. У нас нет ни стека вызовов, ни переменных, ни, чёрт возьми, банального
printf/std::cout. Есть техники, позволяющие печатать внутри сообщений об ошибках компилятора удобочитаемые выведенные типы, и, в принципе, это достаточно полезная возможность проверки сгенерированных структур (например, после модификации дерева).Не будем здесь касаться вопроса многомегабайтных сообщений об ошибках просто в случае некорректной программы: после некоторой практики это перестаёт быть проблемой, так как в подавляющем большинстве случаев лишь первая ошибка инстанцироания ведёт к каскаду дальнейших ошибок: отладка в таком случае ведётся «методом последовательных приближений».
Но, как бы парадоксально это ни звучало, что делать, если программа скомпилировалось успешно? Здесь уже автор более свободен в выборе методов отладки. Тип результата метафункций наподобие определенных в
type_traits можно просто печатать в виде typeid(t).name() (начиная с C++11 можно легально подсматривать в RTTI). Простые структуры данных можно выводить на экран специальными метафункциями с хвостовой рекурсией, для сложных придётся городить «принтеры», сопоставимые по сложности с операциями над самой структурой.Библиотека деревьев содержит такой принтер и примеры его использования, читатель может ознакомиться с ними по ссылке на github в конце статьи. Вот, например, напечатанное дерево из примера выше:
/--{2}
/--{3}--<
\--{4}
--{5}---<
\--{7}-- \--{8}
Высота
Посмотрим на рекурсивную функцию вычисления высоты бинарного дерева:
/// Вход: T - дерево, выход: h - высота
ВЫСОТА(T):
ЕСЛИ T == NIL
ВЫВОД 0
ИНАЧЕ
ВЫВОД 1 + MAX(ВЫСОТА(T.LEFT), ВЫСОТА(T.RIGHT))
Она прекрасна. Просто берём и переносим эту функцию на C++:
/// Объявление общего шаблона
template <typename Tree>
struct height;
/// Частичная специализация: "ЕСЛИ T == NIL"
template <>
struct height<NIL> : std::integral_constant<size_t, 0> {};
/// Определение общего шаблона (рекурсивное)
template <typename Tree>
struct height {
static constexpr size_t value = 1 + max(
height<typename Tree::LT>::value,
height<typename Tree::RT>::value
);
};
Примечание: мы сознательно пошли на небольшое упрощение, из-за которого вычисленная высота дерева будет на 1 больше её математического определения (высота пустого множества не определена). Читатель без труда сможет исправить при необходимости эту особенность, добавив ещё один уровень косвенности и явно вычитая 1 из результата вызова метафункции, однако тогда придётся запретить инстанцирование height для пустого дерева.Код достаточно прост: при попытке вызова height с пустым множеством будет инстанцирована соответствующая специализация, содержащая статическое value = 0, в противном случае продолжится каскад инстанцирований, пока мы не наткнёмся на пустое поддерево (то есть тот же самый NIL), на котором рекурсия и остановится. Это характерная особенность реализации рекурсивных функций посредством шаблонов C++: мы обязаны специализировать дно рекурсии, иначе каскад инстанцирований либо не остановится (компилятор выдаст ошибку о превышении лимита вложенных инстанцирований), либо на одном из шагов произойдёт попытка доступа к несуществующему члену или значению в классе (без специализации описанная выше функция в определенный момент не смогла бы получить Tree::LT, когда Tree было бы равно пустому поддереву NIL).В коде выше используется функция
max. Она должна быть constexpr (или просто метафункцией, тогда её вызов немного изменится), пример простой и известной реализации:template <typename T> constexpr T max(T a, T b) { return a < b ? b : a; }Наконец, использование функции
height:static_assert(height<t1>::value == 3, "");Скажем о «сложности» функции
height: требуется n инстанцирований, где n — число узлов дерева; глубина инстанцирования равна h — т.е. высоте дерева.constexpr-функций и длину variadic-списков аргументов.В документации к своему любимому компилятору читатель сможет найти конкретные значения: например, gcc-5.4 «из коробки» (без дополнительных опций) инстанцирует шаблоны не глубже 900 уровней. В свете вышесказанного это означает, что нельзя забывать об оптимизации метафункций (как бы дико это ни звучало). Например, вызов
height вполне может отказаться компилироваться gcc, если дерево имеет высоту > 900. Можно даже ввести O-нотацию для описания сложности (хотя часто можно точно посчитать число и глубину инстанцирований), и она будет иметь вполне здравый смысл.Например, в стандарте C++14 планируется ввести шаблон для генерации целочисленных последовательностей (
std::integer_sequence): прямая рекурсивная реализация требует N инстанцирований для последовательности 0..N-1, однако существуют элегантные древоподобные решения, глубина рекурсии которых растёт со скоростью логарифма от длины последовательности. В конце концов, мы всегда можем реализовать любую функцию полным перебором, но компилятор этому точно не обрадуется (как и мы, час ждущие завершения компиляции 30-строчной программы или вынужденные читать 9000-страничные сообщения об ошибках).Если превышение допустимой глубины инстанцирований может просто помешать компиляции, то количество инстанцирований (т.е. вызовов метафункций) прямо влияет на время компиляции: для сложных метапрограмм оно может оказать весьма велико. Здесь играет роль множество факторов (необходимость вывода типов, сопоставление частичных специализаций и т.д.), посему не стоит забывать, что компилятор — такая же программа, а механизм шаблонов — своего рода API к внутреннему кодогенератору компилятора, и пользоваться им надо учиться так же, как осваивать отдельный язык программирования — последовательно и аккуратно (и чтобы никаких «Курсов программирования для чайников за 24 часа»!).
Обход центрированный (in-order traversal)
Задача обхода — определенным образом сформировать список узлов (или данных из узлов, вопрос терминологии и имеет значение на практике). Центрированный (симметричный) обход — обход, при котором корень дерева занимает место между результатами соответствующих обходов левого и правого поддеревьев. Вместе со свойством бинарного дерево поиска (которое о неравенствах, см. теорию) это говорит о том, что центрированный обход бинарного дерева поиска сформирует нам отсортированный список узлов — круто! Вот как будет выглядеть обход определенного ранее дерева:
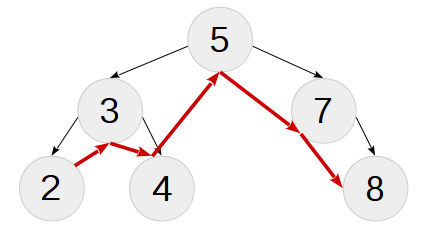
Рекурсивный алгоритм обхода довольно прост:
/// Вход: T - дерево, выход: w - список данных из узлов in-order обхода
INORDER(T):
ЕСЛИ T == NIL
ВЫВОД {}
ИНАЧЕ
ВЫВОД INORDER(T.LEFT) + {T.KEY} + INORDER(T.RIGHT)
Операция "+" в данном случае обозначает конкатенацию списков. Да-да, это именно то, ради чего мы реализовывали конкатенацию кортежей, так как кортежи — это наши списки типов на этапе компиляции. И снова — просто берём и пишем код:
/// Объявление общего шаблона
template <typename Tree>
struct walk;
/// Частичная специализация: "ЕСЛИ T == NIL"
template <>
struct walk<NIL> { using type = std::tuple<>; };
/// Определение общего шаблона (рекурсивное)
template <typename Tree>
struct walk {
private:
// обход левого поддерева
using accL = typename walk<typename Tree::LT>::type;
// добавляем корень
using accX = tuple_push_t<accL, typename Tree::type>;
// конкатенируем с обходом правого поддерева
using accR = tuple_concat_t<accX, typename walk<typename Tree::RT>::type>;
public:
// результат
using type = accR;
};
В данном случае не более чем ради наглядности мы воспользовались локальными
private псевдонимами: все псевдонимы можно подставить друг в друга и получить фарш, обфусцированный похлеще случайно сгенерированной строки, и даже отступы нас не спасут. Но мы же стараемся для людей, не так ли?Сложность функции
walk: O(n) инстанцирований, где n — число узлов дерева (O-нотация использована для упрощения: аккуратный подсчёт даст примерно 3n вызовов метафункций с учётом конкатенаций). Приятно, что функции tuple_concat и tuple_push выполняют свою работу за 1 инстанцирование, так как они не рекурсивны (благодаря возможности вывода типов parameter pack'ов). Глубина инстанцирований, как и в случае height, равна h — высоте дерева.Ещё одно замечание по написанию метафункций: читатель, возможно, обратил внимание на то, что для последних двух функций нет необходимости разделять объявление и определение общего шаблона. Это так, однако я придерживаюсь стандартизированного подхода: «от максимально частного к максимально общему». Многие шаблоны целиком работают на частичных специализациях, и в таком случае очень удобно оказывается описывать эти специализации с возрастающим уровнем общности: мысленно программист проходит тот же путь, какой проходит компилятор в попытках инстанцирования и вывода типов.
Поиск
Поиск по ключу является основной операцией в классических бинарных деревьях поиска (название говорит само за себя). Мы решили не разделять ключ и данные, поэтому для сравнения узлов будем применять введённый сравнитель
Comp. Рекурсивный алгоритм поиска:/// Вход: T - дерево, k - тип-ключ, /// выход: N - узел, содержащий тип k` == k в терминах сравнителя
SEARCH(T,k):
ЕСЛИ T == NIL ИЛИ k == T.KEY
ВЫВОД T
ИНАЧЕ
ЕСЛИ k < T.KEY
ВЫВОД SEARCH(T.LEFT, k)
ИНАЧЕ
ВЫВОД SEARCH(T.RIGHT, k)
Реализация внешне похожа на разработанные ранее:
/// Объявление общего шаблона
template <typename Tree, typename T>
struct search;
/// Специализация для пустого дерева
template <typename T>
struct search<NIL,T> { using type = NIL; };
/// Определение общего шаблона
template <typename Tree, typename T>
struct search {
using Comp = typename Tree::comp;
using type = typename std::conditional<
Comp::template eq<T, typename Tree::type>::value, // k == T.KEY ?
Tree, // поиск завершен, иначе:
typename std::conditional<
Comp::template lt<T, typename Tree::type>::value, // k < T.KEY ?
typename search<typename Tree::LT, T>::type, // тогда ищем в левом
typename search<typename Tree::RT, T>::type // иначе -- в правом
>::type
>::type;
};
Выглядит несколько сложнее, это неспроста: во-первых, сам алгоритм содержит больше ветвлений (больше сравнений и условий), во-вторых, здесь мы уже должны применять определенное ранее отношение порядка, и на его основе продолжать поиск рекурсивно либо в левом, либо в правом поддереве. Обратим внимание на детали:
- Для сравнения типов используется сравнитель из корня дерева:
Tree::comp, что логично: отношение порядка определяет как способ построения дерева, так и последующие операции (в том числе, поиск), вот почему было удобно поместить псевдоним сравнителя прямо внутрь шаблона дерева (node<>). - Для доступа к шаблону, зависящему от аргумента шаблона (
Tree::comp::eq<...>иTree::comp::lt<...>), необходимо использовать ключевое словоtemplate. - Мы пошли по пути наименьшего сопротивления и использовали
std::conditional— стандартную метафункцию, определяющую результирующий псевдоним в зависимости от булевой переменной (такой аналог тернарного оператора ?: для типов). Почему это может быть не очень хорошо — см. далее, однако из положительных моментов — большая наглядность.
Сложность такой реализации
search — опять-таки O(n) инстанцирований, глубина — h (высота дерева). «Стоп!» — воскликнет удивленный читатель, — «а как же логарифмическая сложность поиска и всё такое?»Тут-то и летят камни в сторону
std::conditional и выявляется его принципиальное отличие от оператора ?:: тернарный оператор не вычисляет то выражение, которое не будет его результатом (например, мы можем с чистой совестью разыменовывать нулевой указатель в одном из двух выражений, которое отбросится при проверке этого указателя в первом аргументе оператора). std::conditional же инстанцирует все три аргумента (как обычная метафункция), именно поэтому одного только std::conditional недостаточно для остановки рекурсии, и мы всё ещё должны специализировать дно рекурсии.Прямой результат — лишние инстанцирования, захватывающие всё дерево целиком от корня до листьев. Особым колдунством с добавлением ещё одного уровня косвенности можно-таки «отключить» на каждом шаге рекурсии инстанцирования по пути поддерева, в котором точно нет искомого узла (написав ещё пачку специализаций для этого уровня косвенности), и добиться заветной сложности O(h), однако, на мой взгляд, это задача для более глубокого исследования и в данном случае будет являться преждевременной оптимизацией.
Примеры применения (использованы шаблоны псевдонимов, больше примеров см. в репозитории):
using found3 = search_t<NIL, num_t<0>, num_comp>; // в пустом дереве
using found4 = search_t<t1, num_t<5>, num_comp>; // значение в корне
using found5 = search_t<t1, num_t<8>, num_comp>; // значение в листе
static_assert(std::is_same<found3, NIL>::value, ""); // не найдено
static_assert(std::is_same<found4, t1>::value, ""); // само дерево
static_assert(std::is_same<found5, leaf<num_t<8>>>::value, ""); // лист
Это может показаться странным: мы ищем в дереве узел с типом… который фактически уже указан в качестве аргумента — зачем? На самом деле, ничего необычного в этом нет — мы ищем тип, равный аргументу в терминах сравнителя. Деревья STL (
std::map) тоже хранят в узлах пары (std::pair), и первый элемент пары считается ключом, который, собственно, и участвует в сравнениях. Достаточно хранить в нашем дереве ту же std::pair и заставить сравнитель Comp сравнивать пары по первому типу в паре — и получим классический ассоциативный (мета-)контейнер! Мы ещё вернёмся к этой идее в конце статьи.Вставка
Настало время научиться строить деревья с помощью метафункций (не для того же всё затевалось, чтобы рисовать деревья руками так, как мы это сделали ранее?). Наш рекурсивный алгоритм вставки будет создавать новое дерево:
/// Вход: T - дерево, k - тип-ключ для вставки, /// выход: T' - новое дерево со вставленным элементом
INSERT(T,k):
ЕСЛИ T == NIL
ВЫВОД {NIL, k, NIL}
ИНАЧЕ
ЕСЛИ k < T.KEY
ВЫВОД {INSERT(T.LEFT,k), T.KEY, T.RIGHT}
ИНАЧЕ
ВЫВОД {T.LEFT, T.KEY, INSERT(T.RIGHT,k)}
Поясним его работу: если дерево, в которое происходит вставка, пусто, то вставляемый элемент создаст новое дерево {NIL,k,NIL}, т.е. просто лист с этим элементом (дно рекурсии). Если же дерево не пусто, то мы должны рекурсивно проваливаться до пустого дерева (т.е. до момента, пока левое или правое поддеревья не окажутся пустыми), и в итоге сформировать в этом поддереве тот же лист {NIL,k,NIL} вместо NIL, по пути «подвешивая» себя в виде нового левого или правого поддерева. В мире типов изменять существующие типы мы не можем, но можем создавать новые — это и происходит на каждом шаге рекурсии. Реализация:
template <typename Tree, typename T, typename Comp = typename Tree::comp>
struct insert;
/// Дно рекурсии
template <typename T, typename Comp>
struct insert<NIL,T,Comp> { using type = leaf<T,Comp>; };
/// Основной шаблон
template <typename Tree, typename T, typename Comp>
struct insert {
using type = typename std::conditional<
Comp::template lt<T, typename Tree::type>::value, // k < T.KEY?
node<typename Tree::type, // новое дерево {INSERT(T.LEFT,k), T.KEY, T.RIGHT}
typename insert<typename Tree::LT, T, Comp>::type,
typename Tree::RT,
Comp>,
node<typename Tree::type, // новое дерево {T.LEFT, T.KEY, INSERT(T.RIGHT,k)}
typename Tree::LT,
typename insert<typename Tree::RT, T, Comp>::type,
Comp>
>::type;
};
Для добавления элемента в пустое дерево надо явно указать компаратор
Comp; если же дерево не пусто, компаратор берётся по-умолчанию из корня этого дерева*.Сложность такой вставки: O(n) инстанцирований (n — количество уже существующих узлов), глубина рекурсии равна h (h — высота дерева). Пример явного использования:
using t2 = leaf<num_t<5>, num_comp>;
using t3 = insert_t<t2, num_t<3>>;
using t4 = insert_t<t3, num_t<7>>;
static_assert(height<t4>::value == 2, ""); // первые 2 уровня
using t5 = insert_t<insert_t<insert_t<t4, num_t<2>>, num_t<4>>, num_t<8>>;
static_assert(std::is_same<t5, t1>::value, ""); // равно первоначальному дереву
В библиотеке есть реализация метафункции
insert_tuple, позволяющая разом положить в дерево кортеж типов (под капотом это просто рекурсия insert по кортежу), пример:using t6 = insert_tuple_t<NIL, std::tuple<
num_t<5>,
num_t<7>,
num_t<3>,
num_t<4>,
num_t<2>,
num_t<8>
>, num_comp>;
static_assert(std::is_same<t1, t6>::value, "");
Обход в ширину (breadth-first traversal)
Обход в ширину бинарного дерева (или поиск в ширину из теории графов) формирует список узлов в порядке «по уровням» — сначала выводит корень, затем узлы с глубиной 1, затем с глубиной 2 и т.д. Алгоритм такого обхода использует очередь узлов для дальнейшего вывода (а не стек), поэтому он плохо поддаётся «конвертации» в рекурсивный. Под спойлером далее интересующийся читатель найдёт обходное решение. Здесь отметим лишь тот полезный факт, что «разобранное» обходом в ширину дерево может быть собрано обратно в точно такое же последовательной вставкой элементов из кортежа результата обхода. На рисунке предствлен обход в ширину нашего тестового дерева:
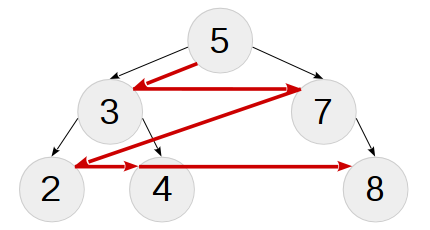
/// Вход: T - дерево, l - уровень для вывода, /// выход: t - список узлов этого уровня
COLLECT_LEVEL(T,l):
ЕСЛИ T == NIL
ВЫВОД {}
ИНАЧЕ
ЕСЛИ l == 0
ВЫВОД {T.KEY}
ИНАЧЕ
ВЫВОД COLLECT_LEVEL(T.LEFT,l-1) + COLLECT_LEVEL(T.RIGHT,l-1)
Полную реализацию на шаблонах читатель может найти в репозитории. В отличие от всех рассмотренных ранее операций, обход в ширину будет иметь сложность O(nh) инстанцирований из-за наличия цикла по высоте (который, хоть и превратится в хвостовую рекурсию, будет содержать пересчёт
collect_level для всего дерева на каждом шаге).Удаление?
Удаление узла — задача нетривиальная. Классический подход рассматривает 3 случая (по количеству дочерних узлов), и в алгоритме используются понятия последующего и родительского узла. Без обратной ссылки на родительский узел (см. спойлер «Об отцах и детях»), эффективно реализовать алгоритм проблематично: каждая операция подъёма вверх по дереву должна будет иметь сложность O(n). Наивная реализация такого удаления приведёт к «комбинаторному взрыву» по количеству инстанцирований (сложность что-то около O(nn)). Разработка метафункции удаления узла входит в дальнейшие планы по усовершенствованию библиотеки. См. UPD2 в конце статьи.
Применение
Переведём дух и наконец уделим внимание вопросу, зачем может понадобиться бинарное дерево поиска времени компиляции? Есть три ответа:
Неконструктивный:
*Картинка с троллейбусом*. Опустим.
Очевидный:

Конструктивный:
Приведём примеры возможных применений подобной структуры:
- Сортировка типов: симметричный обход дерева формирует кортеж со списком типов, отсортированным в терминах заданного компаратора. Определение пары вспомогательных шаблонов псевдонимов позволяет одной командой «отсортировать» заданный кортеж. Как самоцель для разработки дерева — не самое полезное применение (сложность — O(n2) инстанцирований), но как лёгкий естественный бонус — вполне имеет право на существование.
- Плоская runtime структура данных: после проделанной работы не составит особого труда наделить каждый узел дерева не только статическими полями, но и данными-членами. После инстанцирования дерево превратится в подобие кортежа
std::tuple— плоскую структуру данных. Разумеется, в runtime изменять его структуру уже будет нельзя, но доступ по типу и обходы всё ещё будут полезными операциями, так как будут разворачиваться на этапе компиляции без единой строчки машинного кода (какstd::getв применении кstd::tuple).
- Ассоциативный контейнер в compile-time: в первом приближении такое дерево можно использовать как аналог
std::map(или множестваstd::set) — если вспомнить, что даже строки (точнее, строковые литералы) особой магией можно превратить в типы (и даже выполнять типичные строковые операции — конкатенацию, поиск подстрок и т.д.), такое дерево может играть ту же роль в compile-time, какую его старшие братья играют в runtime реализациях самых разных алгоритмов. Примеры: деревья суффиксов, дерево алгоритма Хаффмана, синтаксические деревья. А ещё: чувствуете этот дивный аромат рефлексии?
- Генерация иерархий: как упоминалось в примечании «Лирическое отступление», Александреску использовал шаблоны для генерации сложных иерархий наследования. Дерево само по себе уже является иерархической структурой, поэтому, думаю, оно может найти применение в аналогичных задачах.
static_assert до того, как Собственно, это к слову об основной мотивации адептов метапрограммирования: перенести как можно большую часть работы в compile-time — правила мира времени компиляции гораздо строже, однако цена ошибки намного ниже (чаще всего программа всего лишь не скомпилируется, а не выстрелит в ногу после запуска), а хорошо отлаженные библиотеки шаблонов являются незаменимым подспорьем в разработке промышленного ПО (на низком уровне практически любой «велосипед», порожденный хотелками заказчика, может быть описан стандартным шаблоном с небольшим количеством предметно-ориентированных настроек).
В довершение хочу сказать несколько слов о задаче, сподвигнувшей к разработке дерева и написанию статьи. Существует несколько алгоритмов прямой конвертации регулярного выражения в ДКА (детерминированный конечный автомат), его распознающий, часть которых оперирует т.н. синтаксическим деревом, которое по своей природе «не более чем» бинарное. Таким образом, бинарное дерево поиска времени компиляции — составная часть (и просто интересная структура для реализации) compile-time парсера регулярных выражений (после компиляции и встраивания способного развернуться в плоский код своего ДКА), который, в свою очередь, станет частью другого проекта.
Что потом?
std-совместимый контейнер (с итераторами — сам tutorial по разработке контейнеров должен быть интересен). Более того, на горизонте проект парсера регекспов и некоторые другие наработки нашей команды.Конструктивная критика категорически приветствуется!
Литература
- Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Алгоритмы: построение и анализ = Introduction to Algorithms. — 2-е. — М.: Вильямс, 2005. — 1296 с.
- Александреску А. Современное проектирование на С++: Обобщенное программирование и прикладные шаблоны проектирования = Modern C++ Design: Generic Programming and Design Patterns Applied. — С. П.: Вильямс, 2008. — 336 с. — (С++ in Depth).
- Саттер Г., Андрей Александреску. Стандарты программирования на С++. Серия «C++ In-Depth» = C++ Coding Standards: 101 Rules, Guidelines and Best Practices (C++ In-Depth). — М.: «Вильямс», 2014. — 224 с.
- Готтшлинг П. Современный C++ для программистов, инженеров и ученых. Серия «C++ In-Depth» = Discovering Modern C++: A Concise Introduction for Scientists and Engineers (C++ In-Depth). — М.: «Вильямс», 2016. — 512 с.
> Репозиторий
UPD:
std::conditional. Исправленная версия search без дополнительных специализаций и сложностью O(h) инстанцирований:Обновление в репозитории (+template <typename Node, typename T, typename Comp> struct search { using type = typename std::conditional< Comp::template eq<T, typename Node::type>::value, Node, typename search<typename std::conditional< Comp::template lt<T, typename Node::type>::value, typename Node::LT, typename Node::RT >::type, T, Comp>::type >::type; };
insert) в процессе.UPD2:
insert и search он содержит также реализацию remove со сложностью и глубиной O(h) инстанцирований (подход похож на исправленный insert). Интересным моментом реализации является использование SFINAE+decltype для диспетчеризации и отключения веток условий на этапе компиляции (сама эта техника заслуживает отдельной небольшой статьи в виду дикой неочевидности и мощности, см. пример). Вот полная реализация remove:Комментарии в исходном коде, возможно, появятся позже. Алгоритм рекурсивного удаления, использованный в реализации, можно подсмотреть, например, здесь.template <typename Tree, typename T> struct remove { private: enum : bool { is_less = Tree::comp::template lt<T, typename Tree::type>::value }; enum : bool { is_equal = Tree::comp::template eq<T, typename Tree::type>::value }; enum : size_t { children = children_amount<Tree>::value }; using key = typename min_node_t< typename std::conditional< is_equal && children == 2, typename Tree::RT, leaf<typename Tree::type, typename Tree::comp> >::type >::type; using recursive_call = typename remove< typename std::conditional< is_less, typename Tree::LT, typename std::conditional< !is_equal || children == 2, typename Tree::RT, NIL >::type >::type, typename std::conditional< is_equal, key, T >::type >::type; static typename Tree::RT root_dispatcher(...); template <typename Bush> static typename std::enable_if< sizeof(typename Bush::LT::type), typename Bush::LT >::type root_dispatcher(Bush&&); public: using type = typename std::conditional< is_equal && (children < 2), decltype(root_dispatcher(std::declval<Tree>())), node< key, typename std::conditional< is_less, recursive_call, typename Tree::LT >::type, typename std::conditional< !is_less, recursive_call, typename Tree::RT >::type, typename Tree::comp > >::type; };
Комментарии (63)
kmu1990
28.01.2017 20:27+1Существует несколько алгоритмов прямой конвертации регулярного выражения в ДКА (детерминированный конечный автомат), его распознающий, часть которых оперирует т.н. синтаксическим деревом, которое по своей природе «не более чем» бинарное. Таким образом, бинарное дерево поиска времени компиляции — составная часть
Если под «синтаксическим деревом» вы имеете ввиду АСД представляющее выражение регулярное выражение, то это очень странное утверждение. Потому как АСД не является деревом поиска (даже если оно оказалось бинарным). Так что не очень понятно, каким образом у вас получается, что бинарное дерево поиска — это составная часть?
И другой вопрос, вы пробовали замерять время компиляции на разных примерах использования все этого «чуда»? Если да, то, пожалуйста, поделитесь результатами.
Readme
29.01.2017 01:24Речь не об АСД, в эпилоге имеется в виду конкретный алгоритм типа «first/last/follow pos» (пример описания, самое простое, что сразу нашёл).
Нет, готовых измерений производительности нет, но вопрос интересный, доп. флагами компилятора можно включить вывод времени фаз компиляции. Сделаю замеры и обновлю комментарий/эпилог статьи.kmu1990
29.01.2017 01:32То что описано по ссылке ничто иное как АСД, и оно не является деревом поиска.
Readme
29.01.2017 13:14Каюсь, согласен, это частный случай АСД, однако данное конкретное дерево имеет узлы степени не более 2 и может быть построено рекусивным спуском особым сравнителем и типами-ключами. Вообще, описанное дерево имеет косвенное отношение к указанной задаче, и было, можно сказать, тренировкой и проверкой выразительных возможностей.

bitver
28.01.2017 23:45-13Давно не пишу на плюсах и надеюсь больше не буду, поэтому абсолютно всё равно про что статья и какой смысл она несёт, но большое спасибо за интересный С++, а не С с классами.

izvolov
29.01.2017 00:59+4Не понравилось изложение материала. Сумбурно, неточно, неполно.
Сложность такой реализации search — опять-таки O(n) инстанцирований, глубина — h (высота дерева). «Стоп!» — воскликнет удивленный читатель, — «а как же логарифмическая сложность поиска и всё такое?»
Во-первых, для логарифмической сложности требуется сбалансированность дерева. Здесь про это нет ни слова.
Во-вторых, остановка ненужных конкретизаций шаблонов чрезвычайно важна.
камни в сторону std::conditional
Летят совершенно напрасно.
std::conditional недостаточно для остановки рекурсии
Это не так.
std::conditionalздесь не при чём.
Просто нужно конкретизировать шаблон не внутри, а снаружи.
Неверно:
std::conditional < condition, expression1::type, expression2::type > ::type;
Верно:
std::conditional < condition, expression1, expression2 > ::type::type;
это задача для более глубокого исследования и в данном случае будет являться преждевременной оптимизацией
Это не вопрос для исследования, и это не оптимизация. Это необходимое условие.
Без остановки прохода по ненужным веткам и без сбалансированности такое "дерево поиска" — внимание — хуже простого линейного поиска.
Заголовок спойлерав стандарте C++14 планируется ввести
Так 17-й же уже на подходе.
Readme
29.01.2017 12:37Спасибо за замечания. Это была, так сказать, проба пера*, и некоторый сумбур, безусловно, присутствует.
По пунктам:Во-первых, для логарифмической сложности требуется сбалансированность дерева
Статья не претендует на звание исчерпывающего руководства по алгоритмам и структурам данных (она и так получилась весьма объёмной даже со спойлерами), поэтому я намеренно опускал некоторые моменты: сведующий читатель поймёт, о чём речь, остальные же получат повод загуглить, если эти моменты действительно им интересны. И да, корень «логарифм» встречается только в одном месте в тексте, а сырое бинарное дерево не имеет балансировки (и необходимость в ней, вообще говоря, зависит от решаемой задачи*).
Просто нужно конкретизировать шаблон не внутри, а снаружи
Вот это очень интересное замечание, спасибо, я обращу на конкретизацию особое внимание. Вы хотите сказать, что такой подход автоматически отключит инстанцированиеsearchилиinsertна неверном пути? Пока я в этом сомневаюсь.
Без остановки прохода по ненужным веткам и без сбалансированности такое «дерево поиска» хуже простого линейного поиска.
О сбалансированности было сказано ранее, об отключениях — согласитесь, без сбалансированности оно не имеет особого смысла :) Надо сказать, слово «поиска» в определении немного сбивает с толку: кому-то может показаться, что описанная структура — это готовый мета-std::map, однако это именно бинарное дерево (не более) с минимально необходимым интерфейсом.
Так 17-й же уже на подходе.
Справедливо. У меня до сих пор присутствует некоторая инертность относительно новых и грядущих стандартов — политика партии требует стабильности компиляции.izvolov
29.01.2017 21:06+1Пока я в этом сомневаюсь.
Ну так попробуйте и убедитесь.
согласитесь, без сбалансированности оно не имеет особого смысла
Не соглашусь. Проходить всегда по всему дереву всё равно хуже, чем делать это иногда.
Это сбалансированность не имеет смысла до тех пор, пока мы всегда ходим по всем веткам.Readme
29.01.2017 21:14+1Ну так попробуйте и убедитесь.
Жаль, комментарий нельзя редактировать, я уже добавил UPD в конце статьи. Всё-таки кейс немного другой, но идею понял, реализация поправлена, спасибо.
Не соглашусь
Окай :( В общем, поправлено.

semenyakinVS
29.01.2017 02:13Наблюдая такие статьи, каждый раз думаю: как же плюсам не хватает адекватного, встроенного в стандарт языка редактирования AST на этапе компиляции…
Gryphon88
30.01.2017 13:58Можете привести пример. когда редактирования AST на этапе компиляции может быть полезно или необходимо? Правда не понимаю.
Readme
30.01.2017 17:48+1Я думаю, автор (@semenyakinVS) скорее хотел обратить внимание на более общий вопрос рефлексии в C++ (см. его цикл статей, рассказывающий о разработке библиотеки поддержки рефлексии).
А так да, действительно, каждый день просто сажусь и описываю AST в compile-time. Вот скоро портboost::spiritна язык шаблонов закончу, вот тесты наstatic_assertдописываю, жаль, компилируются по две недели…semenyakinVS
30.01.2017 21:44+2Да. Вы правы. Однако я имел в виду не только рефлексию. Рефлексия — это лишь доступ к AST. Я же подразумевал нечто большее. Полноценное изменение AST во время прохода по коду парсера/компилятора.
Возможность редактирования AST, де факто, уже есть в С++. Очевидно, шаблоны позволяют подменять узлы синтаксического дерева. В описании шаблонного типа мы помечаем узлы для подмены с помощью аргументов, после чего выполняем подстановку типов или констант в указанные места. Однако когда речь заходит о том, чтобы выполнять подобную подмену на основании каких-нибудь свойств существующего дерева (то есть работа на стыке рефлексии и шаблонов) — начинаются костыли с type traits, рекурсивными списками типов и, в сложных случаях, с макросами.
От этого плохо всем. Плохо компилятору — он мучается с рекурсивными шаблонами и затягивает время сборки кода. Плохо парсеру — мы теряем возможность использования фишек IDE (автоподстановка, индексы типов). Плохо программисту — он вынужден ковыряться в жутких функциональных конструкциях без получения внятных сообщений об ошибках. Плохо экосистеме в целом — функционально-ориентированные шаблоны вызывают оторопь у неофитов С++.
Редактирование AST позволило бы навести порядок, вынеся кодогенерацию из кода основной программы в отдельную категорию «поведения времени компиляции» программы.
Я не думал пока о конкретных языковых конструкциях, с помощью которых можно было бы редактировать AST. Однако в процессе написания комментария набросал некоторые имеющиеся сумасшедшие мысли:
Предупреждаю - много текста... Я не шучу - действительно много1. Реализация шаблонов.
Любители ФП могут меня запинать — но я не устану повторять: людям неудобно мыслить рекурсивными категориями. Мы с детства читаем текст последовательно, не сохраняя в голове точки возврата (например, текст в скобках (даже если он выстроен логично (в рамках выбранной области) и без рекурсивных отсылок (хотя сложно представить себе рекурсию в тексте)) воспринимается тяжело).
Если бы логика генерации шаблонных классов описывались аналогично макросным проверкам — имхо, шаблоны воспринимались бы проще. Например:
Странный псевдокодtemplate< typename T_Type > class Array { private: @if (T_Type is bool) [[ char *_bitarray; ]] @else [[T_Type *_array; ]] public: @if (T_Type.isScalar) [[ T_Type ]] @else [[T_Type &]] operator [](size_t inIndex) { @if(T_Type is bool) [[ return _bitarray[inIndex/8*sizeof(char)] & (1 << (inIndex%8*sizeof(char))); ]] @else [[ return _array[inIndex]; ]] } }
Примечание: Проверки кодогенерации, описанные здесь, выполняются на этапе парсинга/компиляции кода; по-умолчанию после выполнения кодогенерации никакие необходимые для кодогенерации данные не сохраняются.Gryphon88
30.01.2017 22:37Спасибо за развернутый ответ. Ещё такой еретический вопрос: если мы пытаемся реализовать на языке конценцепцию, которая, судя по синтаксису и удобочитаемости, чужда этому языку, то почему не добавить кодогенератор на скриптовом языке как pre-build? А про сборку типов из классов и методов… это похожа на гибрид виртуальной таблицы и описания железа с помощью баз данных
semenyakinVS
31.01.2017 01:32+1почему не добавить кодогенератор на скриптовом языке как pre-build
Подозреваю, что это был сарказм — однако подобная реализация тоже возможна.
По поводу чуждости языку — я согласен с тем, что текущий вариант кодогенерации выглядит уродливо. Однако если показать некоторые многоэтажные шаблонные конструкции программисту Java или C# — они также воспримут это как извращение. Я проверял. На мой взгляд, их реакция обоснована — причём не только непривычкой создания кода на языке С++.
это похожа на гибрид виртуальной таблицы
Отчасти. В динамических языках в классы можно включать как поля (ivars), так и методы (например, первая ссылка для java). В С++ это может происходить на этапе компиляции. И, следует заметить, данную фичу я описал как возможную — далеко не факт что она будет реально нужна.
описани[е] железа с помощью баз данных
Как я понял, к кодогенерации статья относится в том смысле, что в случае с кодогенерацией мы описываем некий каркас для класса, который потом расширяем определённым образом. Если так — это несколько отдалённая ассоциация, но да. В чём-то похоже.
ОффтопСтатья, которую вы привели, несколько родственна одной моей давней идее. Она заключалась в создании пакетного менеджер для С++, в рамках экосистемы которого выделялся бы слой системных пакетов. Фактически, прокси над драйверами устройств компьютера (RAM, CPU, HDD, и т.д.), объектно-ориентированное API которых с разной степенью точности описывал бы поведение соответствующих устройств. Прикладные пакеты жили над этим API (например, подключая RAM как зависимость и аллоцируя память исключительно через методы класса-абстракции RAM), а пакетный менеджер выступал в качестве такой себе тонкой виртуальной машины, выбирающей пакеты под ориентировочную конфигурацию целевого компьютера (как выяснилось позже, эта архитектура чем-то напоминала архитектуру игры doom).
Эх… Вспомнил весь этот мой код — аж ностальгия взяла. Спасибо за ссылку.Gryphon88
31.01.2017 13:23Насколько я понял, цель описанной кодогенерации — автоматическое создание сущностей типов по описанию свойств (полей) и умений (методов) и последующее использование этого boilerplate code в обычном ООП, т.е. пишем код в уверенности, что всё необходимое уже задекларировано/описано, а в определенных случаях создано и инициализировано. Вы эту мысль пытались донести, или я опять нафантазировал?
Подозреваю, что это был сарказм — однако подобная реализация тоже возможна.
Нет, я серьёзно. Пытался понять, как писать одновременно переносимый и быстрый код для разных микроконтроллеров. варианты: жуткие макросы и внешний кодогенератор на скриптоязыке. Что так, что так получается уродливо и тяжко в поддержке
объектно-ориентированное API которых с разной степенью точности описывал бы поведение соответствующих устройств.
Да, удобно, я такое решение тоже видел: описание устройств в micro-manager
semenyakinVS
01.02.2017 18:40Вы эту мысль пытались донести, или я опять нафантазировал?
Не совсем. Цель описанной кодогенерации — иметь возможность использовать нефункциональные подходы при описании сложных, зависящих от контекста шаблонных типов.
Что так, что так получается уродливо и тяжко в поддержке
Да. Я сразу признал что сейчас это выглядит нелепо. Однако моя мысль заключалась в том, что кодогенераторы могут быть ближе к выражению семантики, которая сейчас описывается с помощью шаблонов… Собственно, если почитать существующие в данный момент статьи о рефлексии — достаточно часто люди приходят к идее использования third party кодогенераторов на базе всяких clang-ов.
Да, удобно, я такое решение тоже видел
Спасибо за ссылку. Интересно почитать… На мой взгляд, подход с описанием железа через дешёвые абстракции очень естественен для такого системного языка как С++.
semenyakinVS
02.02.2017 02:24Спасибо за кулуарный диалог. Как обещал, пишу комментарий к статье.
Пожалуй, одно из основных преимуществ нефункциональной кодогенерации, которое я забыл упомянуть — такую кодогенерацию легче отлаживать. Можно ставить компайл-брейкпоинты на логику кодогенерации и пошагово отслеживать процесс модификации AST. Конечно, важно разумно определить точки входа в блоки кодогенерации и порядок их исполнения — но, в целом, это будет всяко лучше чем ломать глаза о десятистраничные скобочные сообщения об ошибке.
P.S.: На одной плюсовой тусовке, помню, кто-то хвастался тем, что дампил шаблонные ошибки компиляции в файл и парсил файл дополнительной тулзой. Подчеркну — хвастался. На мой взгляд, это говорит о достаточно нездоровой атмосфере в сообществе языка.

Antervis
31.01.2017 06:36+2я вас обрадую: концепты, constexpr if и decltype вкупе друг с другом как раз таки позволяют сделать всё вами предложенное. Кроме автоматической генерации имен классов. К черту её, имо.
semenyakinVS
31.01.2017 14:22+1О, интересно. Думал, эти штуки будут двигать язык в сторону всё того же шаблонного ФП… Значит будем ждать и надеяться на то, что всё будет хорошо.
Спрошу ещё — вы не встречали, случайно, каких-нибудь хороших статей/обзоров с примерами описанного использования этих новых фич языка? Любопытно было бы почитать. Если прям сходу нет — то ладно. Сам нагуглю.
Кроме автоматической генерации имен классов. К черту её, им[х]о
Пожалуй, соглашусь. Variatic template отменяют необходимость в данной фиче для, например, функторов под разное количество аргументов (как это было в старом fastdelegate, созданном без поддержки С++11), а предложенный мною кейс — это вообще пережиток С, где для имитации перегрузки функций нужно было выполнять их декорирование вручную.Readme
31.01.2017 14:32+2Энтузиасты пилят совершенно нереальные вещи. Например, паттерн матчинг на C++, даже синтаксис приемлемый, и без макросов (!).
Ещё посмотрите наconstexpr if— фича C++17. Вообще, по мощности C++17 должен получиться тортом. Ждём и желаем удачи (и душевных сил) разработчикам компиляторов!
Readme
02.02.2017 11:45+2Пожалуй, скажу ещё пару слов о
constexpr if. В описании есть несколько важных моментов, и самыми вкусными являются эти:The return statements in a discarded statement do not participate in function return type deduction.
...if condition is not value-dependent after instantiation, the discarded statement is not instantiated when the enclosing template is instantiated.
т.е.constexprфункции отныне действительно смогут «конструировать» типы и останавливать рекурсию по типам (с некоторыми оговорками). Рис возвращается в плов.Antervis
02.02.2017 12:07там еще вкуснота в правилах подавления ветки: подавленный код проверяется на семантическую корректность не полностью. Например, SFINAE печать значения:
void func (auto arg) { if constexpr(requires { cout << arg; }) cout << arg << endl; else cout << "(obj of type " << typeid(arg).name() << ")" << endl; }Readme
02.02.2017 12:26Уоу, это действительно круто, вроде как кейс попадает под «statement is a type-dependent expression» + функция-то шаблонная, но сходу вообще не очевидно.
Вангую, что подобные фичи опять будут открываться методом проб и ошибок a la «ребят, тут фарш инстанцировался, получился Coq».

Orient
29.01.2017 10:21Вы ограничены C++11? Если да, то почему? В C++14 многое можно сделать без шаблонов в
constexpr.Readme
29.01.2017 12:57+1Не совсем корректно:
constexpr-функции всё-таки не способны создавать новые типы (в зависимости от значений аргументов), а если применять вывод возвращаемого типа из типов аргументов черезautoa la C++14, то задача скатывается к старым добрым шаблонам.
Все алгоритмы в статье возвращают именно типы, о наделении же узлов данными-членами сказано несколько слов в Применении.Orient
29.01.2017 16:02+1Всякие сложности (например, операции с числами) можно выполнить в контексте функции, а возвращаемое значение — использовать в качестве аргумента шаблона (пример).
Readme
29.01.2017 16:41+2Понял замечание, согласен, такой подход был бы хорош в случае, если бы узлы хранились в плоском кортеже, а структура дерева описывалась бы последовательностями индексов. В случае же, когда навигация осуществляется непосредственно по вложенным псевдонимам (т.е. так, как дерево описано в статье), «считать» как бы ничего и не остаётся, нужно просто явно применять рекурсивные алгоритмы навигации. В статье есть упоминание о неединственности представления дерева.
Ryppka
29.01.2017 12:34+1Спасибо! Хотя я и считаю, что на практике желание шаблонно пометапрограмировать нужно строго контролировать, но грамотные погружения в эту тему всегда вызывают интерес и уважение! Это одна из возможностей, которая редко требуется, но в этих случаях без нее никуда и она творит чудеса!

Mingun
29.01.2017 14:02Не согласен с предыдущим комментатором. Такого качественного материала, который будет понятен даже минимально сведущему в шаблонах C++ и метапрограммированию человеку, давненько уже не было на просторах Хабра. Особенно порадовала внимательность к «мелочам», как то: адекватное форматирование кода и последовательность изложения.
Если настоящая статья вызовет интерес и найдёт своего читателя, я с удовольствием продолжу тему метапрограммирования (и, возможно, не только) в следующих публикациях.
O(nn) шаблонов этому человеку!

QuantZero
29.01.2017 15:02-1Большое спасибо за статью!
Очень грамотно и интересно написано, буду ждать продолжения
alexeykuzmin0
29.01.2017 19:10+1Блин, чувак, ты офигенен! Надо будет на досуге форкнуть и попытаться реализовать балансировку.
Readme
30.01.2017 13:01+1Форки и импрувы только приветствуются!Рад, что задача вызвала интерес: варка в собственном соку в перспективе не приносит ничего хорошего, всегда важен взгляд со стороны заинтересованного сообщества.
Если даже разработанная реализация никогда явно никому не пригодится (кроме инсайдеров нашей команды), но идеи и подходы заинтересуют энтузиастов и помогут в изучении темы или реализации собственных инструментов и идей, то задача статьи будет выполнена.alexeykuzmin0
30.01.2017 13:39Ну, AVL и RB — это здорово, конечно, но я попробую реализовать Treap, думаю, будет сильно проще. Да и, насколько я помню по опыту олимпиад, оно не сильно проигрывает по скорости std::set/std::map, а там, где это важно, лучше уже смотреть в сторону 2-3- или 2-3-4-деревьев.
kmu1990
30.01.2017 15:28Только в отличие от AVL и RB, для Treap нужен генератор случайных чисел (причем если он плохой, то и от балансировки ничего хорошего ждать не приходиться), а для AVL и RB нет.
alexeykuzmin0
30.01.2017 16:05Действительно, нужен. Но, думаю, для вычислений во время компиляции что-нибудь вроде std::hash от значения вполне подойдет.
kmu1990
30.01.2017 16:28В общем случае у вас там хранятся проивзольные типы, как вы предлагаете в общем случае брать hash от типа? Единственный разумный вариант, который я вижу, это вынести эту функциональность в еще один шаблонный параметр, но это просто переложит ответственность на пользователя, которому все еще придется озадачиваться тем, как брать хеш от типа.
Более перспективный вариант, ИМХО, просто взять чисто функциональное красно-черное дерево, так как чисто функциональные реализации деревьев поиска имеют больше шансов на удачное переложение на шаблоны C++ и не требуют кроме сравнения никаких дополнительных параметров.alexeykuzmin0
30.01.2017 16:33Да, для общей реализации это не подойдет, но я не супермен и мне нужно с чего-то начинать.
kmu1990
30.01.2017 16:40Ок, вы начали с Treap, как вы собираетесь продолжать? Выкинуть Treap и взять нормальный алгоритм? Если так, то зачем брать Treap с самого начала, если в мире функционального программирования с такой задачей уже сталкивались и решили ее, а шаблоны C++ — это просто функциональный язык, и можно воспользоваться их решением? Или начало у вас сразу и конец?
alexeykuzmin0
30.01.2017 16:48Да, выкинуть и взять нормальный алгоритм (а еще провести исследование на тему того, какой алгоритм лучше взять — возможно, это будет 2-3-дерево). Я сомневаюсь в своем умении реализовать нормальный алгоритм сразу, без этой подготовки.
kmu1990
30.01.2017 16:57И как реализация Treap поможет вам подготовится к реализации другого алгоритма?
alexeykuzmin0
30.01.2017 17:23Точно так же, как решение любой более простой задачи в какой-либо области помогает набраться опыта для решения более сложной.
PS: я сомневаюсь в конструктивности нашей дискуссииkmu1990
30.01.2017 17:42То что вы говорите — это абстрактная демагогия (которая, конечно, не может быть конструктивной), а я задал вам вполне конкретный вопрос, как реализация одного вполне конкретного дерева поиска поможет вам в реализации другого, о котором вы еще ничего даже не знаете? Ответа на вопрос я не получил.
alexeykuzmin0
31.01.2017 11:27+1ОК, надеюсь, вам действительно не понятны мои слова, и вы не тролль.
Точно так же, как решение любой более простой задачи в какой-либо области помогает набраться опыта для решения более сложной.
Это общий принцип обучения: «сначала изучи что-то более простое, а потом уже более сложное в той же области», и именно из этого общего принципа я и вывожу необходимость для себя сначала потренироваться на куда более простом в реализации для compile-time Treap (да что там писать-то, merge и split, вот и все), и уже потом реализовывать более сложный алгоритм.
Вы могли заметить, что этот же принцип используется повсеместно в технологиях обучения, как в рамках computer science (например, знание стека не нужно для реализации кучи, но его все равно дают раньше), так и вне его.
Да, если бы я уже имел большой опыт реализации compile-time алгоритмов, не было бы ни малейшего смысла в предварительной реализации Treap, но у меня такого опыта почти нет.
Ну это, конечно, если копать глубже, чем очевидный ответ «все равно в стол пишу, вот и выбрал алгоритм, который мне больше нравится»kmu1990
31.01.2017 11:45Они мне не не понятны, я вам явно выше написал, что ваши слова просто демагогия, а принцип в том виде в каком вы его описываете просто не существует.
То что в курсах по алгоритмам раньше дают стек чем кучу, не значит, что стек чем-то полезен для изучения кучи. В противном случае получится, что алфавит, который дают еще раньше, полезен для изучения стека.
А вот то, что в курсах рассказывают про дерево поиска раньше чем про сбалансированные деревья поиска, вот это уже логичный пример. Очевидно, чтобы сделать сбалансированное дерево поиска нужно знать, что такое дерево поиска впринципе — более простая вещь, необходимая для понимая, дается раньше. Аналогично про массивы и свзные списки рассказывают раньше чем про стек и очередь, потому что первые являются средствами реализации последних. Обратите внимание, в моих примерах польза конкретна, в ваших нет.
Касательно более простого в compile-time Treap-а, то вы не имея опыта реализации алгоритмов в compille-time утверждаете это на каком основании? На основании того, что не в compile-time Treap реализовать легче? Так связный список реализовать будет еще легче.alexeykuzmin0
31.01.2017 11:47-1Если вы сомневаетесь в истинности принципа, на котором во многом построена мировая система образования, можете самостоятельно поискать на эту тему научные статьи на доступных вам ресурсах. Или провести исследование.
Readme
30.01.2017 17:24+1Оуоу, давайте жить дружно! Практика как самоцель тоже имеет право на существование, и ничего плохого в попытке «с нуля» по аналогии соорудить мета-контейнер нет (набить руку, так сказать).
По теме беседы:- Описанное в статье дерево может быть сбалансировано очень простым приёмом (однако сложность O(n2) при конструировании с пустого): добавляем элементы «как попало» => делаем симметричный обход (сортируем) => сортированный кортеж разбираем делением пополам (в новое дерево кладём серединный элемент, далее середины середин и т.д.)
- Генератор псевдослучайных чисел можно соорудить и на этапе компиляции (только надо пробрасывать seed для всех последующих «вызовов»). Есть ещё крайне интересная идея: использовать этот подход для генерации псевдослучайной последовательности (ОПАСНОСТЕ: по ссылке разрыв шаблонов во всех смыслах).
kmu1990
30.01.2017 18:16+1Нет никакой агресии, так что призывы к дружбе излишни.
Касательно вашего первого варианта балансировки — то он вряд ли может считаться за балансировку дерева. Зачем строить дерево, потом отсортированный список, потом опять дерево, если можно изначально построить список и посортировать его и сделать из него дерево (строить список легко, сортировать тоже, плюс не нужна операция вставки в дерево).
Если под генератором вы имеете ввиду что-то подобного вида:
static const int M = ...; static const int C = ...; template <int N, int seed> struct Random { static const int value = Random<N - 1, seed>::value * M + C; }; template <int seed> struct Random<0, seed> { static const int value = seed * M + C; };
Или вроде:
template <int V> struct Random { static const int M = ...; static const int C = ...; static const int value = V * M + C; typedef struct Random<value> next; };
То вам нужно хранить новую версию генератора после того как он «сгенерирует» значение.
Касательно статьи, которую вы привели, то не очень понятно как из этого сделать генератор. По сути, функция из статьи возвращает только последовательность вида false, true, true, true, ...., и так далее. Как заставить значение поменяться обратно с true на false не понятно (и мы еще не рассматриваем вопрос о том, когда нужно поменять значение назад). Т. е. не понятно как из этого получить хотя бы что-то напоминающее случайную последовательность бит.Readme
30.01.2017 18:29-1У вас есть готовая функция сортировки кортежей в рукаве? Замечание о балансировке было сказано только как пример: мол, на основе уже существующего API можно это же дерево и сбалансировать.
Касательно статьи, которую я привел: ознакомьтесь с ней, пожалуйста, прежде, чем делать выводы (+ещё лучше сразу с источником перевода, это цикл из 3-х статей). Техника, описанная в них, позволяет реализовать глобальный счётчик времени компиляции как минимум. Применение его (несть числа способам) — дело техники.kmu1990
30.01.2017 19:03Касательно сортировки списка типов (не кортежей), то вообще-то есть. Конкретно я для этого делал сортировку выбором. Не пробовал лично, но кажется, что сортировка слиянием тоже может неплохо лечь на шаблоны.
Касательно статьи, не надо тыкать в меня пальцами и говорить, что я с ней не ознакомился. Вообще я ее прочитал от начала и до конца и не один раз. Конкретно в той статье, на которую вы дали ссылку, описывается «переменная», которую можно изменить только один раз (вы можете сами попробовать код и убедиться в этом). Заглянув в следующую статью цикла, вы можете заметить, что автор сам пишет ровно то же самое, так что вы поторопились с выводами.
Но да не будем на этом останавливаться, посмотрим что происходит далее. Автор для того, чтобы сделать счетчик с N значениями использует N-1 такую «переменную». Т. е. фактически счетчик построенный с помощью такой идеи не отличается по «сложности» (мы же в данном случае измеряем сложность количеством инстанцирований) от генераторов, которые я привел вам выше, а коли так, то не понятно, зачем вообще это делать используя constexpr функции, если генераторы выше просто проще?Readme
30.01.2017 19:19Хорошо, сортировка у вас есть, но не из коробки: вы сами её реализовывали, а основная мысль была об использовании готового инструментария.
По сложности не отличается, но отличается в удобстве применения. Написатьtemplate<..., counter::next()> func{...};проще (и логичнее), чем помнить пробрасываемый генератор. Следуя вашей логике вообще можно заранее руками написать всю последовательность «случайных» чисел.
Добавлю в TODO мини-задачу реализации compile-time генератора псевдослучайных чисел. Challenge accepted. Закончу — оставлю здесь ссылку.kmu1990
30.01.2017 19:40Вы спросили про готовую функцию — я вам ответил, что у меня есть готовая функция. Какой вопрос такой и ответ. Если вас интересует функция реализованная в каокй-нибудь популярной библиотеке, то в boost mpl есть сортировка. В стандартной библиотеке такого нет, на сколько я знаю.
Касательно сложности и логичности, я, лично, не вижу большой разницы между числом в качестве шаблонного параметра и типом, который хранит число, как не вижу большой разницы между counter::next() и Random::next. Что-то вам все равно придется хранить и передавать.
Не знаю какой моей логике вы следуете, но я нигде не утвеждал, что можно заранее написать всю последовательность. Более того я привел пример того как ее можно сгенерировать, а не описывать руками заранее.
Не понял где вы в моем сообщении увидели какой-то challenge, но удачно вам поразвлекаться.Readme
30.01.2017 19:58не вижу большой разницы между counter::next() и Random::next. Что-то вам все равно придется хранить и передавать
Более того я привел пример того как ее можно сгенерировать
Как раз не придётся. То, что вы описали, просто не будет работать: вам либо придётся руками считать вызовыRandom<...>, либо подсовывать предыдущие псевдонимы в параметр шаблона. Упомянутые статьи как раз и описывают реализацию счётчика, способного инкрементироваться без посторонней помощи.
удачно вам поразвлекаться
Спасибо! Задача действительно интересная.kmu1990
30.01.2017 20:16Число вам все равно придется хранить в каждом узле, в противном случае как вы собираетесь использовать что-то к чему у вас нет доступа при балансировке?
Естественно, кроме числа/типа в каждом узле, нужно будет еще сохранить Random::next, но в единственном экземпляре на все дерево. Нельзя это назвать такой уж существенной сложностью, особенно если учесть реализацию альтернативы (здесь я имею ввиду проблемы с некоторыми компиляторами, переносимость на разные версии C++, плюс некоторое легкое допиливание, чтобы можно было создавать несколько независимых счетчиков/генераторов + удобство использоввания допиленной версии под вопросом).Readme
30.01.2017 20:24А, то есть вы предлагаете хранить генератор вместе с Treap'ом? Хорошо, я же имел в виду внешний «настоящий» генератор, никак не связанный с контейнером. В таком случае ваше решение, безусловно, несоизмеримо проще, это правда.
Antervis
29.01.2017 21:40«ученые были так озадачены поиском ответа на вопрос „а это возможно?“, что забыли ответить на вопрос „а это нужно?“»
Readme
30.01.2017 11:24+5Нужно
Koss1024
03.02.2017 19:33Не так страшен Александреску, как тот кто его начитался :)
Readme
03.02.2017 19:48+4Часто встречал подобное мнение и не считаю его справедливым и конструктивным: всё-таки А.А. сыграл значительную роль в развитии языка (см. спойлер «Лирическое отступление»). В конце концов, никто не заставляет программистов городить воздушные замки из шаблонов: они, как и любой инструмент, имеют свою область применения, а большинство задач может быть решено разными способами (и с разным соотношением время/универсальность/расширяемость/производительность).
ИМХО, гораздо более «страшным» мне видится виртуально-интерфейсный фарш, бездонные иерархии и километровые определения приезжих в C++ из C#/Java, обычно и пышущих ненавистью к углоскобочному миру.
maaGames
Допустим, сформировали «дерево типов», вида int->«int», double->«double» и т.д. Тогда можно будет по типу получать его строковое название на этапе компиляции. ОК, метапрограммирование как бы работает. (другого примера с практическим применением пока что не могу придумать). Однако это будет гораздо сложнее для написания, чем просто структуры вида ToString::name, создание которых будет обёрнуто в макрос и не потребует никаких деревьев и чего-то ещё и будет поддерживаться любым старым компилятором…
В общем, хочу какой-то реалистичный пример использования того, чего вы тут натворили.)
UPD: Перечитал предпоследний абзац. Это что-то типа boost::spirit получилось что ли?
Readme
И сразу вопрос — а зачем? Ответ в вопросе: если в задаче требуется создание дерева и операции с ним на этапе компиляции, то вот и пример) Описан инструментарий, о более реальном(ых) же примерах его применения сказано несколько слов в соответствующем разделе. Вы правы, для описаной вами задачи макроса действительно будет достаточно. Одной из целей статьи, однако, было показать, как можно обходиться без макросов в довольно нетривиальных ситуациях.
Про Spirit — да, в каком-то смысле, вы правы: упрощенно, финальная задача — получить (но на этапе компиляции) некоторый предметно-ориентированный автомат.