
— Не понимаю, почему люди так восхищаются этим Карузо? Косноязычен, гугнив, поёт — ничего не разберешь!
— А вы слышали, как поёт Карузо?
— Да, мне тут кое-что из его репертуара Рабинович напел по телефону.
Детектив по материалам IT. Часть первая
Я осознаю, что писать очередную статью на тему Модель-Вид-Контроллер это глупо и вредно для «кармы». Однако с этим «паттерном» у меня слишком личные отношения – проваленный проект, полгода жизни и тяжелой работы «в корзину».
Проект мы переписали, уже без MVC, просто руководствуясь принципами – код перестал быть похож на клубок спагетти и сократился наполовину (об этом позже, в обещанной статье про то, как мы применяли «принципы» в своем проекте). Но хотелось понять, что же мы сделали не так, в чем была ошибка? И в течении долгого времени изучалось все, что содержало аббревиатуру MVC. До тех пор пока не встретились исходные работы от создателя – Трюгве Реенскауга…
И тогда все встало на свои места. Оказалось что фактически на основе принципов мы пере-изобретали «original MVC». А то, что зачастую преподносится как MVC, не имеет к нему никакого отношения… впрочем также как и к хорошей архитектуре. И судя по тому сколько людей пишет о несостоятельности «классического MVC», спорит о нем и изобретает его всевозможные модификации, не одни мы столкнулись с этой проблемой.
Более 30 лет собранные в MVC идеи и решения остаются наиболее значимыми для разработки пользовательских интерфейсов. Но как ни странно, несмотря на существующую путаницу и обилие противоречивых трактовок, разработчики продолжают довольствоваться информацией «из вторых рук», черпая знания о MVC из википедии, небольших статей в интернете и фреймворков для разработки веб-приложений. Самые «продвинутые» читают Мартина Фаулера. И почему-то почти никто не обращается к первоисточникам. Вот этот пробел и хотелось бы заполнить. И заодно развеять некоторые мифы.
Мифы: MVC создавался для языка SmallTalk
Концепция MVC была сформулирована Трюгве Реенскаугом (Trygve Reenskaug) в результате его работы в Xerox PARC в 1978/79 годах. Как правило создание MVC связывают с языком SmallTalk, но это не совсем так. На самом деле Реенскауг работал в группе, занимавшейся разработкой портативного компьютера "для детей всех возрастов" Dynabook под руководством Алана Кэя (Alan Kay).
Чтобы оценить масштаб и революционность того проекта, нужно иметь ввиду что это были годы, когда для работы с ЭВМ требовалось штудировать многостраничные мануалы и иметь ученую степень. Задача, которую пытался решить Алан Кэй, состояла в том, чтобы сблизить компьютер и рядового пользователя, «сломать» разделяющую их стену. Он хотел обеспечить пользователя средствами, которые были бы предельно простыми и удобными, но при этом давали бы возможность управлять компьютером и сложными приложениями.
Именно тогда/там закладывались основы графического интерфейса, формировалось понятие "дружелюбного интерфейса". А также разрабатывался язык SmallTalk, вместе с концепциями объектно-ориентированного программирования, чтобы неподготовленный пользователь “мог понимать и писать программы”. Вот как описывает увиденное в Xerox PARC в 1979 году Стив Джобс – How Steve Jobs got the ideas of GUI from XEROX (from 6.30)
Проект велся около 10 лет, группой очень сильных разработчиков. Найденные в результате решения, подходы, принципы и в области пользовательских интерфейсов, и в области объектно ориентированного программирования и вообще в разработке больших и сложных компьютерных систем были в какой-то степени проссумированы Реенскаугом и составили основу MVC. Так что MVC это действительно прежде всего совокупность направляющих архитектурных идей. В SmallTalk-80 эти идеи всего лишь получили свою первую значимую реализацию. Причем сделано это было уже после ухода Реенскауга из Xerox PARC и без его участия.
К сожалению в течении долго времени о «реальном MVC» не было практически никакой доступной информации. Первая серьезная публикация от создателей появилась лишь 10 лет спустя – "A Cookbook for Using the Model-View-Controller User Interface Paradigm in Smalltalk-80". Даже Фаулер упоминает, что он изучал MVC по работающей версии SmallTalk – "у меня был доступ к работающей версии Smalltalk-80, чтобы я мог изучить MVC. Я не могу сказать, что это исследование было тщательным, но оно позволило мне понять некоторые аспекты решения, которые другие описания объяснить не смогли".
Так что не удивительно появление «мифов» и разнообразных трактовок. Проблема заключается в том, что многие «вторичные» источники описывают MVC не только в искаженном, но еще и в обманчиво-упрощенном виде, как правило в виде некой формальной схемы.
В результате многие действительно считают MVC схемой или паттерном (из-за чего постоянно возникает вопрос – какая же из множества существующих схем «правильная» и почему их так много?). В более продвинутом варианте MVC называют составным паттерном, то есть комбинацией нескольких паттернов, работающих совместно для реализации сложных приложений (тут обычно упоминаются Observer, Strategy и Composite). И лишь немногие понимают, что MVC это прежде всего набор архитектурных идей/принципов/подходов, которые могут быть реализованы различными способами с использованием различных шаблонов...
К последним относится в частности Мартин Фаулер. Вот что он пишет: “MVC часто называют паттерном, но я не вижу особой пользы воспринимать его как паттерн, поскольку он включает в себя множество различных идей. Разные люди читают про MVC в различных источниках и извлекают от туда разные идеи, но называют их одинаково — «MVC». Это приводит к большой путанице и кроме того служит источником недоразумений и непониманию MVC, как будто бы люди узнавали про него через «испорченный телефон»…. Я уже потерял счет сколько раз я видел что-то, описываемое как MVC, которое им не оказывалось.”[ GUI Architectures]
Рискну предположить, что одна из причин «испорченного телефона» заключается в том, что большинство вторичных источников «за кадром» оставляют самое главное – собственно сами архитектурные идеи, заложенные в MVC его создателями, и те задачи, которые они пытались решить. Как раз все то, что позволяет понять суть MVC и избежать огромного количества подводных камней и ошибок. Поэтому в данной статье я хочу рассказать о том, что обычно остается «за кадром» – MVC с точки зрения заложенных в него архитектурных принципов и идей. Хотя схемы тоже будут. Вернее с них и начнем.
Но сначала ссылки. Исходный доклад Реенскауга – "The original MVC reports". Позже Реенскауг все это более четко сформулировал и оформил в своей последующей работе “The Model-View-Controller (MVC ). Its Past and Present”. Возможно кому-то будет интересна страница, где собраны записи Ренскауга, относящиеся к тому периоду, с его комментариями - MVC XEROX PARC 1978-79.
Уже упоминавшаяся первая публикация о MVC в языке SmallTalk-80 от разработчиков только в улучшенном качестве "A Description of the Model-View-Controller User Interface Paradigm in the Smalltalk-80 System" (Glenn Krasner и Stephen Pope). Хорошим дополнением служит также статья “Applications Programming in Smalltalk-80.How to use Model-View-Controller” (автор SteveBurbeck учавствовал в разработке компилятора SmallTalk для IBM на основе Smalltalk-80, а также в разработке MacApp). Ну и если кто-то хочет полного погружения – “Smalltalk-80. The Interactive Programming Environment” от знаменитой Адель Голдберг в дискуссиях с которой Реенскаугом и создавались термины Model, View, Controller.
Схемы MVC
Для того, чтобы стало понятно, о чем идет речь и в чем заключается проблема, давайте вначале все же разберем наиболее типичные «схемы» MVC. Это важно, поскольку часто к схемам не дается никаких пояснений и к тому-же бывает, что определения заимствуются из одного места, а схемы из другого. В результате можно встретить одинаковые описания MVC с совершенно разными диаграммами, что очень запутывает.
Итак, несмотря на то, что MVC трактуется и изображается очень по разному, во всем этом многообразии все же можно выделить общее «ядро». Общим является то, что везде говорится о неких трех частях — Модели, Виде и Контроллере, которые связаны между собой определенным образом, а именно:
Модель ничего не знает ни о Виде, ни о Контроллере, что делает возможным ее разработку и тестирование как независимого компонента. И это является главным моментом MVC.
Вид отображает Модель. И значит, он каким-то образом должен получать из нее нужные для отображения данные. Наиболее распространены следующие два варианта: 1) Активный Вид, который знает о Модели и сам берет из нее нужные данные. 2) Пассивный Вид, которому данные поставляет Контроллер. В этом случае Вид с Моделью никак не связан.
Видов может быть несколько — они могут по разному отображать одни и те же данные, например в виде таблицы или графика, или же отвечать за отображение разных частей данных из Модели.
- Контроллер является пожалуй самым неоднозначным компонентом. Тем не менее общим является то, что Контроллер всегда знает о Модели и может ее изменять (как правило в результате действий пользователя).
А также он может осуществлять управление Видом/Видами (особенно если их несколько) и соответственно знать о Видах, но это не обязательно.
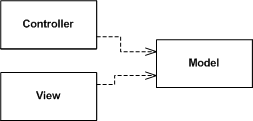
Отсюда мы получаем базовые (максимально упрощенные) схемы двух наиболее часто встречающихся разновидностей MVC. Перечеркнутой линией обозначена необязательная связь Контроллера с Видом.
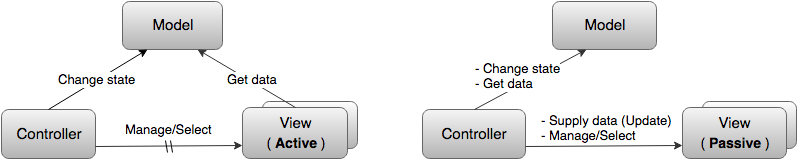
Вот так базовая схема выглядит у Фаулера: "Основные связи между Моделью, Видом и Контроллером. (Я называю их основными, потому что на самом деле Вид и Контроллер могут быть связанными друг с другом непосредственно. Однако, разработчики в основном не используют эту связь.)":
Далее. Модель, как и Вид, тоже может быть Пассивной либо Активной. Пассивная Модель никак не воздействует ни на Вид ни на Контроллер. В этом случае все изменения Модели отслеживаются Контроллером и он же отвечает за перерисовку Вида, когда это необходимо.
Но обычно, под MVC все таки подразумевают вариант с Активной Моделью.
«Активная Модель» оповещает о том, что в ней произошли изменения. И делает она это посредством шаблона Наблюдатель, рассылая уведомления о изменениях всем своим «подписчикам». «Активный Вид» подписывается на эти сообщения сам и таким образом знает когда нужно заново считать из модели нужные ему данные и обновиться. В случае «Пассивного Вида», подписчиком является Контроллер, который затем уже обновляет Вид.
Шаблон Наблюдатель позволяет Модели с одной стороны информировать Вид или Контроллер о том что в ней произошли изменения, а с другой фактически ничего о них «не знать» (кроме того что они реализуют некий заданный интерфейс «подписчика») и тем самым оставаться независимой. Это называется слабым связыванием и считается вторым ключевым моментом MVC.
Именно поэтому, когда говорится, что MVC это составной шаблон, то в первую очередь в качестве одного из его компонентов упоминается паттерн Наблюдатель. На диаграммах слабое связывание принято рисовать пунктирной стрелкой, но многие это правило игнорируют.
Таким образом, более продвинутые «схемы MVC» будут выглядеть так:

Замечание: встречаются авторы, которые в термины Пассивная и Активная модель вкладывают совсем иной смысл. А именно то, что обычно принято называть Тонкой моделью (модель содержащая исключительно данные) и Толстой моделью (полноценная модель содержащая всю бизнес логику приложения).
Ну и последнее. Вообще говоря MVC, в любой своей разновидности, это прежде всего шаблон для разработки приложений с пользовательским интерфейсом и его главное назначение – обеспечить взаимодействие приложения с пользователем. Поэтому в полноценной MVC схеме (явно или неявно) должен присутствовать пользователь. И тут в основном встречаются две трактовки:
Пользователь управляет приложением через Контроллер, а Вид служит исключительно для отображения информации о Модели, и пользователь его лишь видит
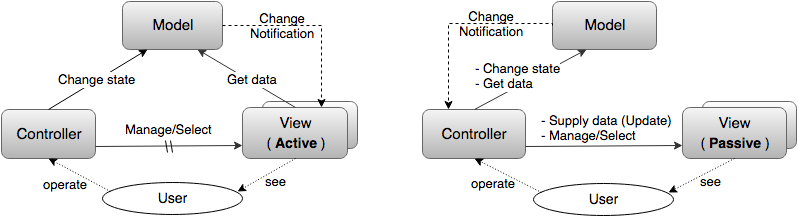
Часто указывают/рисуют лишь то, что пользователь действует на Контроллер, а то что он видит Вид опускается.
Пользователь взаимодействует только с Видом. То есть Вид не только отражает Модель, но также принимает команды пользователя и передает их Контроллеру. В этом случае между Видом и Контроллером образуется еще одна связь: прямая (Вид знает о Контроллере и напрямую передает информацию) или, чаще всего, ослабленная (Вид просто рассылает информацию о действиях пользователя всем заинтересованным подписчикам а Контроллер на эту рассылку подписывается)
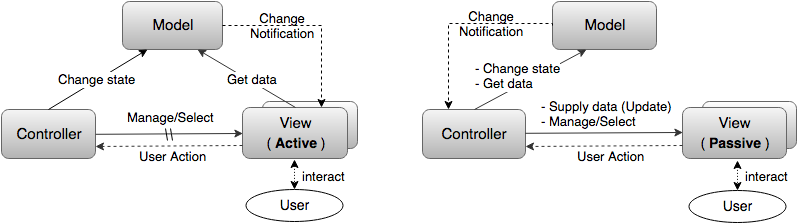
Замечание: нужно иметь ввиду, что вариант с Пассивным Видом, когда Вид никак не связан с Моделью и данные для отображения ему поставляет Контроллер, иногда называют MVC, а иногда выделяют в отдельную разновидность — MVP и тогда Контроллер переименовывают в Презентер.
Для иллюстрации всего вышесказанного несколько диаграмм «из интернета» (надеюсь стало понятнее почему они такие разные):

А теперь самое главное — как применяются, что обозначают и чему соответствует Модель Вид и Контроллер при написании приложений?
Тут можно выделить два кардинально отличающихся подхода, в каждом из которых Модель, Вид и Контроллер трактуются весьма различным образом.
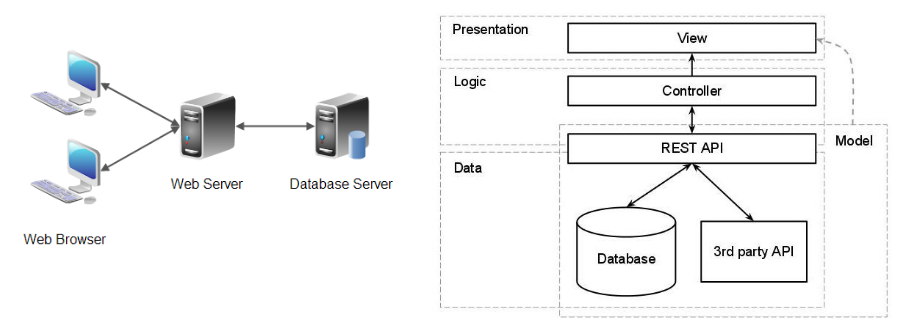
«Трехуровневый MVC» от веб
Первый подход идет из веб-программирования, где MVC получил самое широкое распространение, и поэтому в нем максимально отразились свойственные веб-программированию черты. А именно, привязка к трехуровневой архитектуре «клиент–сервер–база данных» и преобладание скриптовых языков. В результате компоненты MVC формально привязываются к трем слоям архитектуры и получается что:
Модель = База Данных
Модель — это просто данные, которыми оперирует приложение
Контроллер = Сервер
Контроллер — это бизнес-логика приложения. Иногда еще говорят что контроллер это центр обработки всех запросов и принятия решений, а также промежуточный слой обеспечивающий связь модели и представления.
- Вид = Клиент (как правило тонкий)
Вид — это пользовательский интерфейс. Причем интерфейс в этом случае, как правило, понимается в основном исключительно как «дизайн», просто набор графических элементов. Логика же работы этого интерфейса, как и логика работы с данными, выносится в Контроллер
Про неадекватность этого подхода написано уже так много, что это вошло даже в википедию (MVC. Наиболее частые ошибки). Хорошо и подробно возникающие при этом проблемы рассматриваются в статье, ставшей своего рода классикой "M в MVC: почему модели непоняты и недооценены". Поэтому постараюсь просто кратко просуммировать:
Независимость Модели является главным в MVC. Если Модель тонкая, то есть содержит лишь данные, то возможность ее независимой разработки имеет мало смысла. Соответственно при таком подходе теряет смысл и сам MVC
Вся бизнес логика приложения, то есть большая часть кода, сосредотачивается в Контроллере и это при том что как раз Контроллер является самой зависимой частью в MVC – в общем случае он зависит и от Модели и от Вида. Вообще говоря в хорошо спроектированных приложениях стараются делать с точностью до наоборот – наиболее зависимые части должны быть минимальными, а не максимальными
На практике Контроллеру в веб-приложении обычно соответствует один скрипт и вынесение всей бизнес-логики в Контроллер фактически означает еще и то, что большая часть приложения оказывается в одном скрипте. Отсюда и появился термин ТТУК — толстый тупой уродливый контроллер
- Поскольку, как правило, тонкой является не только Модель но также и Вид (тупой Вид или тупой интерфейс — Dumb GUI, Dumb View), то, как следствие, в Контроллер помимо всей бизнес-логики приложения помещается также еще и логика управления пользовательским интерфейсом. То есть, вместо разделения бизнес логики и логики представления при таком подходе получается их смешение.

Программа, конечно, разбивается на множество MVC, соответствующих страницам веб-приложения, и это спасает ситуацию но, увы, не меняет сути. Проблема эта известна, вот неплохая статья — "RIA Architecture".
Типичные ошибки: смешение в Контроллере бизнесс-логики и GUI-логики
Хорошая новость заключается в том, что «веб-вариант MVC», всего несколько лет назад бывший самым распространенным, сейчас активно сдает позиции. Плохо то, что он по прежнему распространен, только теперь не в явном, а в замаскированном виде. Поскольку за фразы (цитирую): "Модель это обмен данными с БД и т.п. Контроллер логика обработки этих данных и подготовка к View" сейчас активно «минусуют», то стали писать:
- Модель — это данные и методы работы с ними
- Контроллер — обработка действий пользователя и вводимой им информации
Дело в том, что в объектно-ориентированном приложении нет данных, а есть множество объектов и каждый из них содержит какие-то данные и методы работы с ними. В том числе и объекы доступа к базе данных (если они имеются). Поэтому когда определение Модели начинается со слова «данные», то оно в сущности имеет мало смысла и нередко в завуалированной форме подразумевает все тот же самый доступ к базе данных. В обработку же действий пользователя нередко помещается львиная доля бизнес логики и в результате по прежнему вся, или почти вся, логика приложения часто оказывается в Контроллере.
«Архитектурный MVC»
Второй подход гораздо ближе к первоисточникам. Поэтому разберем его подробнее.
Мартин Фаулер абсолютно прав, когда говорит что MVC это не паттерн, а набор архитектурных принципов и идей, используемых при построении пользовательских информационных систем (как правило сложных).
Архитектурные принципы мы постарались собрать и описать в статье "Создание архитектуры программы или как проектировать табуретку". Если же говорить предельно кратко, то суть состоит в следующем: сложную систему нужно разбивать на модули. Причем декомпозицию желательно делать иерархически, а модули, на которые разбивается система, должны быть, по возможности, независимы или слабо связаны (Low coupling). Чем слабее связанность, тем легче писать/понимать/расширять/чинить программу. Поэтому одной из основных задач при декомпозиции является минимизация и ослабление связей между компонентами.
Давайте посмотрим, как эти принципы применяются в MVC для создания первичной архитектуры (декомпозиции) пользовательских приложений. По сути в основе MVC лежат три довольно простые идеи:
«1» Отделение модели предметной области (бизнес логики) приложения от пользовательского интерфейса
Первая и основная идея MVC заключается в том, что любое пользовательское приложение в первом приближении можно разделить на два модуля — один из которых обеспечивает основной функционал приложения, его бизнес логику, а второй отвечает за взаимодействие с пользователем:
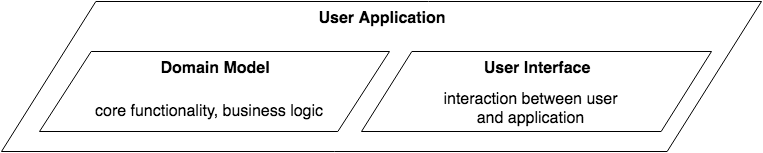
Тем самым мы получаем возможность разрабатывать модель предметной области, содержащую бизнес-логику системы и составляющую функциональное ядро приложения, не думая о том как именно она будет взаимодействовать с пользователем.
Задача же взаимодействия с пользователем выносится в отдельный модуль – пользовательский интерфейс и тоже может решаться относительно независимо.
Именно модель предметной области (Доменная Модель от английского domain model) считается Моделью в «архитектурном MVC» (отсюда и термин). Поэтому так важно чтобы она была независимой и могла независимо разрабатываться и тестироваться.
"Сердцевиной идеей MVC, как и основной идеей для всех последующих каркасов, является то, что я называю «отделенное представление» (Separated Presentation). Смысл отделенного представления в том, чтобы провести четкую границу между доменными объектами, которые отражают наш реальный мир, и объектами представления, которыми являются GUI-элементы на экране. Доменные объекты должны быть полностью независимы и работать без ссылок на представление, они должны обладать возможностью поддерживать (support) множественные представления, возможно даже одновременно. Этот подход, кстати, так же был одним из важных аспектов Unix-культуры, позволяющий даже сегодня работать во множестве приложений как через командную строку, так и через графический интерфейс (одновременно)." — Фаулер
«2» Независимость Модели и синхронизация пользовательских интерфейсов за счет шаблона Наблюдатель
Вторая ключевая идея заключается в том, что для того, чтобы иметь возможность разрабатывать Модель независимо, необходимо ослабить ее зависимость от пользовательского интерфейса. И делается это, как уже упоминалось выше, за счет шаблона Наблюдатель.
Модель рассылает извещения об изменениях. Интерфейс подписывается на эти оповещения и таким образом знает, когда нужно заново считать данные из модели и обновиться. Благодаря этому мы получаем практически независимую Модель, которая ничего не знает о связанных с ней пользовательских интерфейсах, кроме того что они реализуют интерфейс «наблюдателя».
«3» Разделение Пользовательского Интерфейса на Вид и Контроллер.
Третья идея это просто второй шаг иерархической декомпозиции. После первичного разделения приложения на бизнес модель и интерфейс, декомпозиция продолжается на следующем иерархическом уровне и уже пользовательский интерфейс, в свою очередь, делится на Вид и Контроллер.

У меня сложилось впечатление, что суть этого деления мало кто понимает и соответственно может объяснить. Обычно приводят лишь стандартную обтекаемую формулировку, что Контроллер как-то реагирует на действия пользователя, а Вид отображает Модель (поэтому в большинстве реализаций именно Вид подписывается на извещения об изменениях Модели. Хотя, как уже говорилось, подписчиком может быть и Контроллер, либо Вид и Контроллер вместе).
Поскольку деление пользовательского интерфейса на Вид и Контроллер относится ко второму уровню иерархии, оно гораздо менее значимо чем первичное разделения приложения на доменную модель и интерфейс. Очень часто (особенно когда дело касается простых виджетов) оно вообще не делается и используется «упрощенный MVC», в котором имеется только Модель и единый UI-компонент, представляющий собой объединенный ВидКонтроллер. Более подробно об этом речь пойдет чуть позже.
«Архитектурный MVC» на первый взгляд выглядит вполне разумно. Но как только мы попытаемся применить его не к учебному примеру из трех классов а к реальной программе, то столкнемся с целым рядом проблем и вопросов, о которых редко пишут, но которые чрезвычайно важны. И касаются они не только пользовательского интерфейса, но и самой Модели. Так что предлагаю таки попробовать с ними разобраться и, наконец-то, "послушать Карузо", то есть обратиться к первоисточникам.
«Original MVC»: Реенскауг и SmallTalk-80
Мы привыкли к тому, что MVC почти всегда рассматривается на примере создания какого нибудь простейшего графического компонента, вся «бизнес логика» которого помещается в один класс с данными и парой методов для их изменения. Но что делать, когда речь идет о реальных приложениях, ядро которых состоит из многих взаимосвязанных объектов работающих совместно?
В общем случае Модель это один объект или множество объектов? И на самом ли деле Модель в «MVC-схеме» тождественна доменной модели, описывающей предметную область и бизнес-логику приложения?
То, что Модель реализует шаблон Наблюдатель явно указывает на то, что Модель это именно один объект. На это же указывает и то, что Вид и Контроллер должны знать о Модели (для того чтобы брать из нее данные и вносить изменения) и следовательно они должны содержать на нее ссылку. Но тогда, если считать, что под Моделью подразумевается доменная модель, мы вновь приходим к тому что все ядро приложения оказывается в одном объекте. Только теперь вместо толстого уродливого Контроллера, у нас появляется толстая Модель. Толстая Модель конечно лучше, поскольку она независима и в ней, по крайней мере, не смешивается бизнес логика с логикой GUI, но все равно такое решение сложно отнести к хорошей архитектуре.
Остается второй вариант — Модель это множество доменных объектов, совместно реализующих бизнес логику. Это предположение подтверждает и сам Реенскауг: "A model could be a single object (rather uninteresting), or it could be some structure of objects." Но тогда остается открытым вопрос – кто реализует шаблон Наблюдатель, откуда берет данные Вид, куда передает команды пользователя Контроллер?
И вот здесь нередко встречается попытка обмануть самих себя путем примерно следующего рассуждения: "пусть Модель это множество доменных объектов, но… среди этого множества есть в том числе и «объект с данными», вот он-то и будет реализовывать шаблон Наблюдатель, а также служить источником данных для Вида." Эту уловку можно назвать «Модель в Модели». И по сути это еще один «завуалированный» вариант того, что «Модель это данные».
Тут можно сказать лишь одно: архитектура, в которой один модуль (Вид или Контроллер), должен «лезть» внутрь другого модуля (доменной модели) и искать там для себя данные или объекты для изменения очень нехорошо «пахнет». Получается что Вид и Контроллер зависят от деталей реализации доменной модели, и если структура этой самой модели изменится, то придется переделывать весь пользовательский интерфейс.
Для того же, чтобы понять «а как должно быть» предлагаю вновь обратится к «принципам». Когда говорилось о том, что систему надо разбивать на модули, слабо связанные друг с другом, мы не упомянули главное правило, позволяющее добится этой самой слабой связанности. А именно – модули друг для друга должны быть «черными ящиками». Ни при каких условиях один модуль не должен обращаться к объектам другого модуля напрямую и что либо знать о его внутренней структуре. Модули должны взаимодействовать друг с другом лишь на уровне абстрактных интерфейсов (Dependency Inversion Principle). А реализует интерфейс модуля как правило специальный объект — Фасад.
И если поискать какие же паттерны позволяют добится слабой связанности, то на первом месте будет находится именно паттерн Фасад, и только затем Наблюдатель и тд.
Ну а теперь схема из доклада Трюгве Реенскауга:
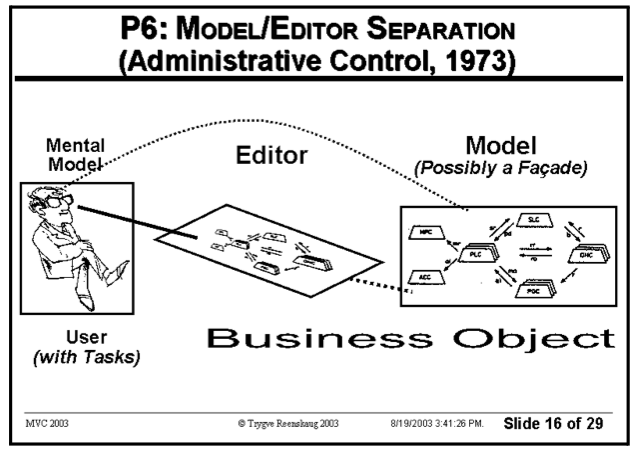
Пояснение: Поскольку во времена создания MVC интерфейсы компьютерных программ были в основном текстовыми, то есть, по сути представляли собой простейший вид редактора, то вместо термина «Пользовательский Интерфейс», который появился позже, Трюгве Реенскауг использует термин «Editor» (редактор).
Таким образом, ключевая идея MVC действительно состоит в том, что пользовательское приложение делится на два модуля – один из которых моделирует предметную область и реализует бизнес логику (доменная модель), а второй отвечает за взаимодействие с пользователем (пользовательский интерфейс). Но при этом Модель в «MVC схеме» вовсе не тождественна доменной модели (которая может быть сколь угодно сложной и состоять из множества объектов), а является всего лишь ее интерфейсом и фасадом.
Так что ни Вид ни Контроллер разумеется не должны знать о том, как устроен модуль предметной области (доменная модель), где и в каком формате там храняться данные, и как именно осуществляется управление. Они взаимодействуют лишь с интерфейсом и реализующим его объектом-фасадом, который предоставляет все нужные данные в нужном формате и удобный набор высокоуровневых команд для управления подсистемой, а также реализует шаблон Наблюдатель, для извещения о значимых изменениях в подсистеме. И если мы захотим поменять базу данных, использовать облако, или вообще собирать нужные нам данные из различных источников в сети… если внесем какие угодно изменения в бизнес логику приложения, но при этом оставим неизменным интерфейс-фасад, то ни Вид, ни Контроллер это никак не затронет. Мы имеем архитектуру устойчивую к изменениям.
И если уж рисовать схему MVC, то выглядеть она должна следующим образом:

Давайте рассмотрим данную схему подробнее. Традиционно в клиент серверных приложениях главным считается сервер. Он предоставляет услуги/сервисы и решает в каком виде это должно быть реализовано. Соответственно интерфейс и фасад, как правило, определяются с точки зрения сервера. А клиенты под этот заданный формат подстраиваются.
На практике же более адекватной оказывается не сервер-ориентированная архитектура, а клиент-ориентированная. В ней фокус с сервера смещается в сторону клиента и интерфейс, вернее интерфейсы (и фасад или фасады), определяются исходя из потребностей клиентов. Вместо Предоставляемого Интерфейса (Provided Interface) используются Требуемые Интерфейсы (RequiredInterface).
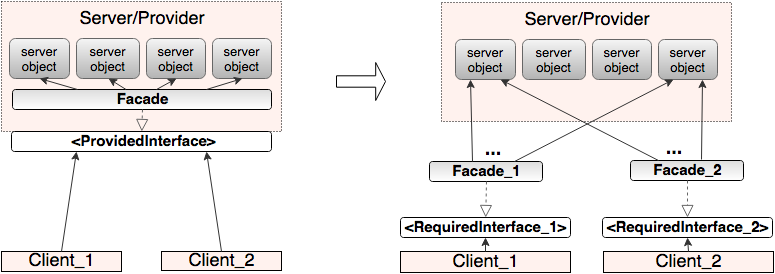
Конкретные реализации могут варьироваться, но это не суть важно

Клиент ориентированный подход гораздо лучше соответствует Принципу разделения интерфейсов (Interface Segregation Principle) поскольку в нем вместо единого для всех толстого ProvidedInterface используется множество тонких RequiredInterface.
Если я не ошибаюсь, именно такой подход используется в архитектуре микросервисов. Там для взаимодействия с множеством сервисов введено понятие шлюза, который является ни чем иным как фасадом — “An API Gateway is a server that is the single entry point into the system. It is similar to the Facade pattern from object-oriented design. The API Gateway encapsulates the internal system architecture and provides an API that is tailored to each client. ” Building Microservices: Using an API Gateway.
Причем шлюз этот "вместо того чтобы обеспечивать общий единый для всех API, предоставляет различные API для каждого клиента (Rather than provide a one-size-fits-all style API, the API gateway can expose a different API for each client. For example, the Netflix API gateway runs client-specific adapter code that provides each client with an API that’s best suited to it’s requirements)" API Gateway.
Как мы увидим дальше клиент-ориентированный подход применялся также и в SmallTalk-80. Но вначале давайте просто пере-рисуем схему MVC с учетом вышесказанного:
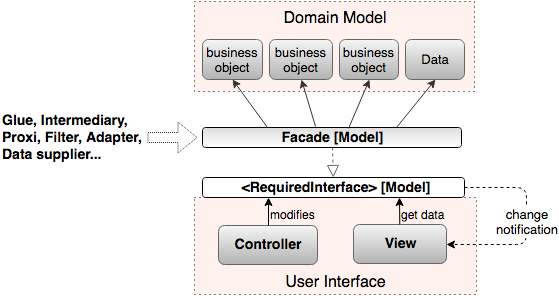
Смотрим на фасад… Вот он тот самый клей (glue), объект посредник, прокси, фильтр, адаптер… связывающий между собой доменную модель и пользовательский интерфейс и поставляющий нужные данные в нужном/удобном формате.
Удивительно то, что кроме Реенскауга об этом почти никто не пишет. Хотя некоторые пере-открывают эту идею самостоятельно (пример можно посмотреть тут или тут раздел "Interface-Based Programming Techniques").
Особенно хорошо тема Моделей-интерфейсов раскрыта в статье одного из JavaGuru — Advanced MVC Patterns. Автор подчеркивает, что Модели это не данные, а исключительно интерфейсы/объекты-посредники/фильтры (Models as Proxies, Models as Filters), обеспечивающие удобный доступ к данным, которые могут находится где угодно – на разных машинах, в разных форматах: “О чем большинство программистов не думает, так это о том, что модели являются всего лишь интерфейсами. Они не должны содержать никаких данных!.. Модели-посредники расширяют охват и позволяют использовать уже существующие данные где бы они не находились”.
Из-за того что фасад, присутствующий в original MVC, был «утерян», то его роль зачастую берет на себя Контроллер. Отсюда и проистекают представления что Контроллер находится «между Моделью и Видом», служит клеем между ними и обеспечивает нужные Виду данные.
На форумах нередко встречается вопрос — "Чем контроллер отличается от фасада?". Не смотря на наивность этот вопрос вполне закономерен и на него сложно дать разумный ответ поскольку во многих MVC фреймворках Контроллер на самом деле фактически является фасадом — «Фронт-Контроллер».
Чем плохо такое решение? Если оно граммотно реализовано, то ничем. Но это в теории. А на практике нередко происходит путаница концепций и понятий и в результате Фронт-Контроллер с одной стороны злоупотребляет своими полномочиями и вместо делегирования команд начинает включать в себя реализацию бизнес логики. А с другой – продолжает одновременно выполнять функции пользовательского интерфейса и в результате в нем происходит уже упоминавшееся смешение «бизнес логики» и «GUI логики» (что собственно и делает его код похожим на огромную свалку).
Думаю, что пришло время перейти к Smalltalk. Smalltalk-80 создавался очень талантливыми людьми. С документацией в нем действительно имелись проблемы (тем более что «шаблонов проектирования» тогда еще не существовало) но вот с реализацией в основном все было хорошо и пользовательские интерфейсы, конечно же, не взаимодействовали с доменной моделью напрямую.
Между интерфейсом и доменной моделью (объектами языка SmallTalk) всегда располагался некий промежуточный класс/объект, который обеспечивал удобный интегральный доступ к доменным объектам их данным и методам. Вот эти-то промежуточные объекты (по сути выполняющие роль фасадов) и были в действительности Моделями в SmallTalk-80.
Например, для работы с кодом в Smalltalk использовались следующие GUI интерфейсы: Inspector, Browser, Workspace,…

Вот что пишет об их устройстве Glenn Krasner:
"Inspector в системе состоит из двух видов. ListView отображает список переменных (слева), а TextView показывает значение выбранной переменной (справа)… Моделью для этих видов служит экземпляр класса «Inspector»… Отдельный класс «Inspector» является посредником или фильтром для того чтобы обеспечивать доступ к любому свойству любого объекта. Использование промежуточных объектов между View и "actual" models является типичным способом изолировать поведение отображения от модели приложения...
Как и в случае Inspector, промежуточные объекты использовались также в качестве моделей для системных браузеров. Экземпляр класса «Browser» является моделью-посредником для каждого системного браузера..."
Замечание: название класса-посредника, описывающего промежуточный объект-фасад, обычно совпадало с названием отображающего его виджета. У Inspector промежуточная модель так и называлась «Inspector», а у Browser соответственно – «Browser».
В случае Workspace, который был одним из простейших интерфейсов "моделью служил экземпляр StringHolder, который просто предоставлял текст, то есть строку с информацией о форматировании".

В конце своей статьи Krasner приводит список использовавшихся в SmallTalk Моделей (наследников базового класса Model): StringHolder, Browser, Inspector, FileModel, Icon… А также отмечает что "the models were almost always some sort of filter class".
Позже в VisualWorks Smalltalk идея промежуточных Holder-ов была развита и реализована в полной мере. Там для доступа к каждой переменной, принадлежащей доменным объектам, используется свой интерфейс и фасад – ValueModel и ValueHolder. И, как не трудно догадаться, именно ValueModel реализует шаблон Наблюдатель, извещая GUI о происходящих «в домене» изменениях.
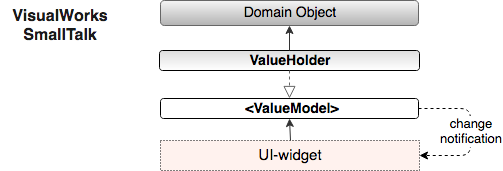
Типичные ошибки: обращение к доменным объектам напрямую
Поскольку на практике в любом сколько нибудь серьезном приложении сложно обойтись без фасадов, то не удивительно что во многих фреймворках и "модификациях MVC" аналоги фасада или объекта-посредника между GUI и доменной моделью пере-изобретаются под самыми разными именами. Помимо Front-Controller здесь можно упомянуть также ApplicationModel, ViewModel (подробнее см. дискуссию Model-ModelView-Controller) и Proxy-model.
Из-за того, что разработчики не всегда хорошо понимают что стоит за всеми этими «моделями», а сами модели привыкли воспринимать как данные а не интерфейс, то это становится источником еще одной весьма распространенной и ресурсоемкой ошибки. Вместо того чтобы нужным образом всего лишь интерпретировать и адаптировать имеющиеся доменные данные с помощью моделей-посредников их начинают копировать в эти модели-посредники.
Например, ValueHolder это, как правило, всего лишь обертка вокруг уже существующей доменной переменной, он не должен содержать данные, он содержит ссылку на данные. Вот что пишут: "ValueModel does not need to actually store the value because it is already being stored by another model" (Understanding and Using ValueModels).
А вот цитата из статьи Advanced MVC Patterns: "Одна из самых распространенных ошибок, которую совершают люди когда используют Swing компоненты, заключается в копировании данных в модели этих Swing компонент. Правильный же способ состоит в том чтобы использовать уже существующие данные, адаптируя их при помощи фильтра… Запомните: никогда не копируйте данные которые можно просто интерпретировать!".
Рассмотрим следующий простой пример. Если последовать интернет советам и для "добавления элементов в список" использовать код подобный этому (взято со StackOverflow и Adding and Removing an Item in a JList), то будет происходить как раз то самое копирование данных в модель списка:
Object[] items; // Доменный объект
DefaultListModel model = new DefaultListModel();
JList list = new JList(model);
for (int i = 0; i < items.length; i++){
// КОПИРОВАНИЕ доменных данных в модель списка!
model.addElement(items[i]);
}Правильнее, конечно же, использовать данные массива просто обернув их в интерфейс ListModel (тем более что для этих целей создана уже почти готовая AbstractListModel):
// создаем фасад-адаптер к доменным данным,
// который просто интерпретирует их нужным образом
ListModel model = new AbstractListModel() {
public int getSize() {return items.length;}
public Object getElementAt(int index) {return items[index];}
};
// передаем созданный фасад списку в качестве модели
JList list = new JList(model);И если надо объединить данные, отфильтровать или преобразовать каким-нибудь образом, то совершенно не нужны промежуточные массивы. Все делается непосредственно в модели-фасаде
Object[] items1; Object[] items2; // Доменные объекты
// модель-фасад которая объединяет массивы
ListModel model = new AbstractListModel() {
public int getSize() { return items1.length + items2.length;}
public Object getElementAt(int index) {
return index<items1.length ? items1[index] : items2[index-items1.length];
}
};
JList list = new JList(model);В случае небольших статических массивов преимущества не очевидны. Но в общем случае такой подход позволяет не только избегать копирования, но прежде всего защищает от проблем связанных с рассинхронизацией данных (если не полениться прописать методы извещающие слушателей об изменениях).
Ну а если хочется краткости, то тогда уж лучше так:
JList list = new JList(items);В этом случае Джава сама сделает обертку-адаптер вместо копирования.
Типичные ошибки: копирование доменных данных в модели GUI-компонент
Ну и наконец мы может развеять главный миф, являющийся источником наибольшего количества проблем и ошибок.
Мифы: Модель в «MVC схеме» тождественна доменной модели и данным
Путаница возникает из-за того что одно и то же слово «Модель» используется в разных контекстах. Когда речь идет о декомпозиции и отделении бизнес-логики от пользовательского интерфейса, то под Моделью действительно понимается именно доменная модель, содержащая данные и логику работы с ними и обеспечивающая основной функционал приложения.
Но в контексте шаблонов и схем Модель это прежде всего интерфейс и реализующий его объект-посредник (фасад, адаптер, прокси) обеспечивающие удобный и безопасный доступ к доменным данным, которые могут находится где угодно. Реенскауг так и писал: "model object with a facade that reflects the user’s mental model".
Когда MVC преподносится исключительно как «схема», то наличие «промежуточных моделей» кажется сложным и запутанным. Появляются вопросы ("Чем эти модели отличаются друг от друга?", “Как их правильно использовать?”), неоднозначные трактовки и множество возможностей сделать ошибку.
Но если понимать заложенные в MVC архитектурные идеи, то все становится предельно ясным: пользовательский интерфейс не имеет права обращаться к объектам доменной модели напрямую. А значит между доменной моделью и пользовательским интерфейсом должнен находиться фасад/посредник/адаптер..., и взаимодействовать пользовательский интерфейс (Вид и Контроллер) может только с ним. Возможностей сделать ошибку – ноль.
И по большому счету становится все равно каким термином этот объект-посредник называется и какая именно Model-View-Whatever разновидность MVC используется… Начинаешь видеть: какая задача решается, с помощью каких шаблонов и то, насколько хорошо или плохо это делается
В принципе на этом статью можно и закончить. Как уже упоминалось деление пользовательского интерфейса на Вид и Контроллер является наименее значимым, даже вспомогательным моментом. Но с другой стороны пользовательский интерфейс присутствует в каждом пользовательском приложении и иметь представление о подходах и идеях наработанных в этой области часто бывает полезно. К тому же именно вокруг Контроллера ведутся основные споры. Поэтому, если есть те, кому интересно и «не надоело», то пишите и я выложу вторую часть полностью посвященную именно этой теме.
Комментарии (383)



novar
07.02.2017 10:58+1Спасибо, помогли прояснить некоторые моменты. Например, стало понятно, что контроллер вообще не нужен если используются продвинутые умные элементы управления в представлении, которые сами по себе могут реагировать на уведомления и посылать стандартные команды в модель (например как в WPF/UWP с использованием MVVM).

MadridianFox
07.02.2017 11:01+2В ходе размышлений о MVC, я пришёл к выводу, что, то MVC что в вебе, можно выделить в отдельную ветвь как минимум по способу работы с событиями. Если в графических приложениях у нас происходит множество событий, и на них должны реагировать множество представлений, то в серверном MVC есть одно событие — http запрос. Второго события, на которое могут реагировать представления просто нет. т.к. как такового объекта представления, который живёт в течение нескольких событий не существует.

Alex_ME
07.02.2017 11:11А как же всевозможные SPA и просто страницы с большим количеством динамического контента, где различные запросы отправляются на сервер по AJAX и потом меняют отдельные элементы страницы (представления)?

s-kozlov
07.02.2017 11:13Сервер-то тут при чем? В случае HTTP он просто отвечает на запросы.
Alex_ME
07.02.2017 11:18Я невнимательно прочитал комментарий.
Если в графических приложениях у нас происходит множество событий, и на них должны реагировать множество представлений, то в серверном MVC есть одно событие — http запрос.
s-kozlov
07.02.2017 11:12+3в серверном MVC есть одно событие — http запрос
А потом мы делаем вебсокеты…aquamakc
07.02.2017 11:22А потом мы делаем вебсокеты…
а пользователь открывает это в IE 6 )))s-kozlov
07.02.2017 12:55В мире, где существует IE 6, вполне себе существуют и вебсокеты.
aquamakc
07.02.2017 13:09Веб-сокеты это не HTML5 разве? С миром вэба редко пересекаюсь, мог что-то упустить.
s-kozlov
07.02.2017 15:23Веб-сокет — это протокол передачи данных поверх TCP. Он не имеет никакого отношения к HTML5.
mayorovp
07.02.2017 15:30Веб-сокет — это еще и API, которое должен поддерживать браузер. IE поддерживает веб-сокеты только с 11й версии.
aquamakc
07.02.2017 15:33Ну значит меня обманул тов. Мэтью Мак-Дональд в книге «HTML5 недостающее руководство» от 2014 года, в которой он написал, что Веб-сокеты появились в HTML5, но
… она (технология веб-сокетов, прим. моё) ещё надохится в процессе развития и не имеет хорошего уровня браузерной поддержки. Изначально технология была добавлена в браузеры Firefox 4 и Opera 11, но была удалена через несколько месяцев в связи с проблемой потенциальных нарушений безопасности.
©s-kozlov
07.02.2017 16:47Что там курит товарищ Мак-Дональд? WebSocket — это протокол передачи данных поверх TCP, как и HTTP. HTML (5) — это язык разметки, т.е. всего лишь специальным образом структурированный текст, который может передаваться с помощью любого протокола. Браузер — лишь один из возможных участников обмена данными по этому протоколу. А http://learn.javascript.ru/websockets — всего лишь один из возможных API для использования WebSocket и мне совершенно непонятно, какое отношение он имеет к HTML.
Это ж какую кашу в голове надо иметь, чтобы написать в книжке, что Веб-сокеты появились в HTML5. Он бы еще сказал, что они появились в JSON.mayorovp
07.02.2017 16:48Ну и как вы будете подключаться к веб-сокету из шестого IE?
s-kozlov
07.02.2017 17:36В огороде бузина, а в Киеве дядька. Может, я вообще не поддерживаю IE 6: здоровье дороже, чем полпроцента юзеров. А может, я использую какую-нибудь либу, которая эмулирует веб-сокет для IE 6. Впрочем, какое отношение это имеет к тому, что WebSocket — протокол передачи данных, а HTML — язык разметки?
mayorovp
07.02.2017 17:50Раз вы пытаетесь цепляться к словам — вот вам:
Стандарт HTML5:
4.11 Scripting
6 Web application APIs
Конкретно про веб-сокеты — HTML Living Standard:
9.3 Web socketss-kozlov
08.02.2017 11:22-1По первым двум ссылкам не нашел слово «socket».
Третья — это вообще что? Какое отношение имеет к W3C?
VolCh
07.02.2017 17:53+1WebSocket не только протокол передачи данных, но и название JavaScript API, входящего в семейство HTML5 API. Да, HTML тоже не только язык разметки. Даже стандарт HTML 4 специфицировал отображение сущностей языка HTML на DOM API.
VolCh
07.02.2017 17:50всего лишь один из возможных API для использования WebSocket и мне совершенно непонятно, какое отношение он имеет к HTML.
https://developer.mozilla.org/en/docs/Web/Guide/HTML/HTML5
MadridianFox
07.02.2017 11:26+1Да, но пропаганда «пишем сайт на php используя MVC» не затрагивает тему вебсокетов.
VolCh
07.02.2017 12:26Но в целом никак ей не противоречит. У нас «сайт» (приложение) на PHP c MVC и веб-сокетами. Просто ещё один тип событий веб-сокеты. На самом деле четвёртый: первый — http-запрос, второй — cli-команда, третий — amqp событие (пуллинг по хрону), а потом и веб-сокеты прикрутили, причём в двух вариантах — через прослойку на node.js и нативно. В ближайших планах честный пушинг amqp. Приложению как таковому (инфраструктуре и бизнес-логике) абсолютно всё равно откуда пришло событие «пользователь такой-то прислал данные о новом(ых) платеже(ах)», оно абстрагируется от канала поступления на самой ранней стадии обработки и дальше идёт по единому маршруту.

Fesor
07.02.2017 22:20давайте подумаем что это меняет.
- простая модель — запрос/ответ.
Ну то есть мы посылаем на сервер какой-то ивент и получаем ответ. Собственно все. Просто другой транспорт но модель выполнения абсолютно такая же как и в случае с http.
- Подписка на изменения данных.
Вот тут уже интереснее. Мы получаем какое-то событие о том что мы хотим подписаться на изменения, ну например баланса. Сервер при операциях с балансом будет кидать ивент о том что "воу у нас стэйт поменялся" а какой-то объект будет отслеживать эти события и формировать представление для клиента. Тут уже похоже на MVC c вью которое постоянно обновляет представление стэйта модели.
Но опять же, это вопрос не транспорта а того что нам нужно сделать.
Fesor
07.02.2017 22:16Поэтой причине на бэкэнде хорошо себя показывает такой вариант как Model-View-Adapter. То есть есть некий адаптер между HTTP и приложением, который занимается обработкой "событи" и конвертирует их в какое-то действие в приложении. Так же результат работы приложения конвертируется в HTTP ответ. Ну и т.д.

claygod
07.02.2017 22:46+1Не расскажете поподробней о Model-View-Adapter?
Fesor
07.02.2017 22:54https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93adapter
То есть идея такая. У вас есть View и есть Model. И они друг о друге ничего не знают. То есть одно и то же View может работать с разными моделями просто за счет смены адаптеров. Ну и наоборот. Одна и та же модель может иметь несколько видов представлений в зависимости от адаптера между ними.
Так же интересная особенность это то, что адаптеров может быть много и они формируют между собой своего рода цепь (мидлвары например хороший пример таких адаптеров).
postgree
08.02.2017 20:38Практический смысл это может иметь в случае, если объекты (скорее модели чем адаптеры) реализуют один интерфейс. И тогда у нас вью уже кое что знает о модели или адаптере. И тогда возникает вопрос — какая разница, где гвозди прибивать?
Fesor
08.02.2017 21:29Практический смысл это может иметь в случае, если объекты (скорее модели чем адаптеры) реализуют один интерфейс.
Можете пояснить? Ибо у них могут быть разные интерфейсы. Просто между каждой парой view — model будет свой адаптер или цепочка адаптеров.

http3
07.02.2017 11:06Перечеркнутой линией обозначена необязательная связь Контроллера с Видом.
Это как?
Может V и M?mayorovp
07.02.2017 11:18Вы картинку-то смотрели? Вариант "без связи между V и M" — он на отдельной схеме расположен. Слева же связь между V и M есть, а между контроллером и видом — опциональна.
http3
07.02.2017 13:08Так я и смотрел. Поэтому и спросил. :)
В вебе контроллер практически всегда вызывает рендеринг вида явно (я не говорю, что это правильно). :)
А вот вид практически никогда не лезет в модель сам.VolCh
07.02.2017 13:39Вид очень часто лезет в модель. Передает контроллер виду объект $user, а вид лезет в него запросами типа $user->getName()
cobiot
08.02.2017 07:14Простите, не очень понятен вопрос. Там прямо под картинкой цитата Фаулера «на самом деле Вид и Контроллер могут быть связанными друг с другом непосредственно. Однако, разработчики в основном не используют эту связь»
А если интерисует «физический смысл», то это когда во время работы приложения одни виды сменяют другие (открываются, закрываются) и считается что всем этим ансамблем управляет контроллер
cobiot
08.02.2017 07:16Простите, не очень понятен вопрос. Там прямо под картинкой цитата Фаулера «на самом деле Вид и Контроллер могут быть связанными друг с другом непосредственно. Однако, разработчики в основном не используют эту связь»
А если интерисует «физический смысл», то это когда во время работы приложения одни виды сменяют другие (открываются, закрываются) и считается что всем этим ансамблем управляет контроллер
http3
07.02.2017 12:06-8Но обычно, под MVC все таки подразумевают вариант с Активной Моделью.
Хм, а в вебе обычно пассивные модели. :) Страничка отдалась и все. Ничего в ней больше не меняется. :)
Независимость Модели является главным в MVC.
Независимость приветствуется везде… :)
Вся бизнес логика приложения, то есть большая часть кода, сосредотачивается в Контроллере и это при том что как раз Контроллер является самой зависимой частью в MVC – в общем случае он зависит и от Модели и от Вида.
Почему же?
Есть API — используйте его.
Хотите, поместите некоторую логику в модель — и так само используйте API.
Зависимости от M нету, так как M — пустая.
Как вообще может быть зависимость от V?
Отсюда и появился термин ТТУК — толстый тупой уродливый контроллер
Другой вариант — толстая тупая уродливая модель. :)
в Контроллер помимо всей бизнес-логики приложения помещается также еще и логика управления пользовательским интерфейсом
Что это вообще такое? :)
Дело в том, что в объектно-ориентированном приложении нет данных, а есть множество объектов и каждый из них содержит какие-то данные и методы работы с ними.
Прекращайте дрочить на ООП.
MVC возможно не только на ООП головного мозга.
Данных нету. Вокруг сферические объекты. Буквы — это тоже объекты.
Второй подход гораздо ближе к первоисточникам.
Та плевать, что было в первоисточниках.
Иногда появляются уникумы, которые говорят, что ООП — на самом деле это не то, что называют ООП сейчас, а обмен сообщениями.
Мартин Фаулер абсолютно прав, когда говорит что MVC это не паттерн
Та это вам все адекватные люди говорят. Но вы же кастрюли на голову оденете и как носороги упираетесь.
«1» Отделение модели предметной области (бизнес логики) приложения от пользовательского интерфейса
В называемом вами классическом это тоже есть.
«2» Независимость Модели и синхронизация пользовательских интерфейсов за счет шаблона Наблюдатель
К вебу имеет слабое отношение…
Очень часто (особенно когда дело касается простых виджетов) оно вообще не делается и используется «упрощенный MVC»
И выходит черти что. Каша из php и html.
То, что Модель реализует шаблон Наблюдатель явно указывает на то, что Модель это именно один объект.
В один класс пихать методы для работы с БД и бизнес-логику? Перемога.
И логика вывихнутая.
Использование наблюдателя никак не говорит, что один объект.
если внесем какие угодно изменения в бизнес логику приложения, но при этом оставим неизменным интерфейс-фасад, то ни Вид, ни Контроллер это никак не затронет.
Хм.
Предположим, что у нас нет фасада.
Глупо же было из-за изменения движка базы менять шаблоны? :)
Причем шлюз этот «вместо того чтобы обеспечивать общий единый для всех API, предоставляет различные API для каждого клиента
Это же так классно поддерживать несколько API :)
Автор подчеркивает, что Модели это не данные, а исключительно интерфейсы/объекты-посредники/фильтры
Вообще-то да.
обеспечивающие удобный доступ к данным, которые могут находится где угодно – на разных машинах, в разных форматах
Программисты на фреймворках понимают это так, что модели остаются ходилками в БД, поверх которых навешали мусора. :)
Типичные ошибки: копирование доменных данных в модели GUI-компонент
Хм.
Но если мы имеем дело с объектами, то они передаются по ссылке.
А как же как быть, когда нам нужны данные из 2 моделей?
А нагружать этой логикой V не хочется. Проще эти данные объединить в С.
Но в контексте шаблонов и схем Модель это прежде всего интерфейс и реализующий его объект-посредник (фасад, адаптер, прокси) обеспечивающие удобный и безопасный доступ к доменным данным, которые могут находится где угодно.
+100500
Но пропагандисты фреймворков ведут людей по быстрому пути :)
Поэтому, если есть те, кому интересно и «не надоело», то пишите и я выложу вторую часть полностью посвященную именно этой теме.
Конечно же, выкладывайте.
В общем первая часть статьи (первая часть того, что выложено, а не вся статья) — ничего нового. Такие самые заблуждение, как и везде, в частности и на хабре.
А вторая часть — грамотная.
MVC — это всего лишь разделение кода на уровни.
Разделять нужно с умом. А не делать так, как пишут идиоты в интернете.
Есть необходимость — вынесли что-то в отдельный класс, нету — не вынесли.
Дополню:
Если логика примитивная и нужна только одному контроллеру, то ее все же можно оставить и в контроллере.
Но не в виде ни под каким предлогом.VolCh
07.02.2017 12:55+1Программисты на фреймворках понимают это так, что модели остаются ходилками в БД, поверх которых навешали мусора. :)
Бред. Мои модели ничего о БД вообще не знают. Ходилка в БД работает поверх них.
Но пропагандисты фреймворков ведут людей по быстрому пути :)
К фреймворкам это не имеет никакого отношения. Можно с фреймворком преобразовывать доменный объект в какой-то DTO или прятать его прокси/адаптером/фасадом, а можно без него не преобразовывать и вообще из шаблона в базу писать.
Но не в виде ни под каким предлогом.
А если логика нужна виду? Банальное: список каких-то значений пустой — выдать параграф «нет данніх», не пустой — відать список.http3
07.02.2017 13:18+1Бред. Мои модели ничего о БД вообще не знают.
Вы молодец. :)
Если бы все были такими, то и статьи не было бы. :)
К фреймворкам это не имеет никакого отношения.
Самое непосредственное.
Почти вся разработка сейчас или на фреймворках, или на CMS.
А если логика нужна виду? Банальное: список каких-то значений пустой — выдать параграф «нет данніх», не пустой — відать список.
Та пишите.
Получите то, от чего начали:
Мешанина php и html. :)
Но спасибо хоть ответили, а не как некоторые :)VolCh
07.02.2017 13:46Самое непосредственное.
Почти вся разработка сейчас или на фреймворках, или на CMS.
Да без разницы на чём она. не зависит от использования фреймворка отдавать во вью или контроллер объект модели или прятать его за прокси/адаптерами/фасадами или, как вариант, давать дто.
Та пишите.
Получите то, от чего начали:
Мешанина php и html. :)
Есть шаблонизаторы вообще. Так или иначе логика того что и как показывать (например одни сообщения красным, другие зеленым) должна быть в виде, а не в контроллере или модели.http3
07.02.2017 16:25+1Да без разницы на чём она
Да, без разницы на чем.
Только пропагандисты фреймворков предлагают быстрый путь вместо правильного. :)
Есть шаблонизаторы вообще.
Ну тогда в шаблонизаторе будете в базу лазить. :)
Это уже будет не совсем шаблонизатор. :)
Хотя я не против вызова из шаблона других виджетов / контроллеров / шаблонов.
Только это только вызов, без логики обработки данных.
Так или иначе логика того что и как показывать (например одни сообщения красным, другие зеленым) должна быть в виде, а не в контроллере или модели.
Это ж другое.
Такая логика уместна в шаблоне. :)VolCh
07.02.2017 17:55Ну так суть MVC в чём — каждой логике своё место, а не что в виде, например, не должно быть никакой логики.

franzose
08.02.2017 13:50Вы зря обобщаете «пропагандистов фреймворков». И вообще: кто они, єти пропагандисты?

jetexe
07.02.2017 15:53Если логика примитивная и нужна только одному контроллеру, то ее все же можно оставить и в контроллере.
Но не в виде ни под каким предлогом.Тут ещё вот какой момент есть, сейчас логика нужна только в одном месте. А завтра она, как всегда внезапно понадобится ещё в пяти местах.
VolCh
07.02.2017 12:11+3Спасибо, виден системный подход. Жду продолжения.
Типичные ошибки: обращение к доменным объектам напрямую
Часто использую в виде передачи в вид через контроллер доменных объектов (сущностей и объектов-значений), но не считаю это ошибкой в общем случае, а просто оптимизацией своего труда — в большинстве случаев создание отдельных фасадов будет заключаться в написании кучи геттеров типа FacadeObject::getSomeValue() {return $this->domainObject->getSomeValue();}. Да, оно изолирует доменный объект от вида и контроллера, не допускает даже в теории (без хаков типа рефлексии) изменение доменных объектов, но в большинстве случаев, имхо, эта изоляция не стоит потраченного времени и усложнения кода, если соблюдать дисциплину — не дергать в виде и контроллере методов объектов, изменяющих их состояние и только в контроллере дергать сервисы, изменяющие состояние домена. В каких-то языках, возможно, помог бы её соблюдать модификатор доступа типа friendly, но в PHP его нет, а в JS вообще модификаторов нет толком.
Ну и фронт-контроллер отвечает у меня за инициализацию приложения (в PHP) и роутинг пользовательских событий в отдельные контроллеры, которые инициализируют доменную модель для реакции на событие UI, дергают сервисы, передают, если нужно часть данных доменной модели в вид для отображения (в PHP, в JS вид слушает события модели) и сохраняют изменения доменной модели. То есть контроллеры обеспечивают не только UI, но и инфраструктуру для доменной модели, в частности обеспечивают персистентность её данных.
Сама же доменная модель зависит только от объявленных в ней же абстракций, которые контроллеры заполняют конкретными инфраструктурными реализациями. Иногда, конечно, абстракции текут (прежде всего из-за трудоемкости полной абстракции от инфраструктуры хранения данных), но в целом считаю, что у меня удачный компромисс между стремлением всё сделать по науке и практическими требованиям заказчика прежде всего к скорости разработки. Главное, соблюдать дисциплину и внимательно следить когда действительно пора вводить дополнительный слой абстракций и делить существующую на несколько для изоляции и уменьшения связанности.http3
07.02.2017 15:00внимательно следить когда действительно пора вводить дополнительный слой абстракций
+1
Тут преждевременная оптимизация не нужна. :)

QuickJoey
07.02.2017 12:16+1Если не по теме, игнорируйте.
Есть приложение, не веб, десктопное, которое общается с базой данных. Вся бизнес-логика вынесена в хранимые процедуры (или функции в терминах Postgre). Насколько я понимаю, это толстая модель данные+бизнес-логика. В приложении нет ни одного прямого select, insert, update, delete. Соответственно на каждое действие есть соответствующая процедура, с правами для каких-то групп пользователей. Вроде бы всё логично.
Но попытка узнать, как части этого приложения перенести в веб интерфейс (интранет), натыкается на какое-то фундаментальное непонимание меня веб-программистами. Начиная с того, что авторизацию в таком веб-приложении нельзя делать на основе авторизации в базе данных (пустили в БД, пользователь вошёл, не пустили, не вошёл). Заканчивая тем, что у меня «неправильно» организованы данные, функциями никто не пользуется и права так раздавать нельзя. А разделением прав будет заниматься некая прокладка фреймворка, а все пользователи приложения, в БД будут логиниться под одним пользователей (условным web_user). Так как знаний у меня не достаточно, оценить полный спектр технологий/фреймворков и самое главное структуру такого веб интерфейса я не могу.
Читая статью, мне показалось, что моя идея имеет права на существование. Я не прав?VolCh
07.02.2017 12:45А как в десктопном приложении аутентифицируются пользователи? Каждому заведена учётка в СУБД и её данные вводят? В вебе так же предлагается? Делать так можно, просто у многих разработчиков на фреймворках/cms нет знаний как это делать, прочитали когда-то в туториале как настроить соединение с базой с пользователем и паролем из конфига и всё.
QuickJoey
07.02.2017 12:53Да, учётные данные в БД. Пользователи, которые распределены по ролям, так как на каждый чих (действие) есть процедура, то правами управлять просто. В вебе (конечно с учётом того, что это внутренняя сеть, и соединений будет до 1000) хотелось бы так же, чтобы не плодить сущности, и не заниматься раздачей прав с нуля.
VolCh
07.02.2017 13:01Компромисс — пользователи авторизуются в фреймворке его средствами, там же им назначаются роли, а для каждой роли фреймворк ходит под отдельным пользователем БД, условные web_manager, web_accounter, web_admin, web_director, которым в базе назначено по одной роли. Фреймворк выбирает нужную пользователю роль и от её имени стучится в базу. Во многих фреймворках это делается с минимум разработки, в основном только конфиги написать под каждую роль. Минус — стандартными средствами СУБД не сделать бизнес-логирование, надо дописывать в функции параметр «пользователь» и использовать его (если пустой, то пользователя БД).
oxidmod
07.02.2017 13:06Зачем 1к конектов к бд, когда есть persistent connections?
Что делать когда юзеров станет не 1к, а 10к, 100к. Столько одновременных коннектов уже субд не вытянет.
Авторизачия через бд весьма узкий кейс, который фреймворками не предусмотрен. Кроме того, не дает каких-либо плюсов по сравнению с классической авторизацией через приложение.VolCh
07.02.2017 13:08Плюс — управление пользователями и логирование их действий стандартными средствами СУБД. На уровне СУБД исключается ситуация, что какие-то даные увидит, изменит или удалит тот, кто не должен с градацией вплоть до отдельных столбцов.
oxidmod
07.02.2017 13:16На уровне приложения это вполне достижимо, приэтом не нужно постоянно держать в голове, кто там что может увидеть или не может. Вся логика приложения сосредоточена в приложении, а не размазана между кодом и субд. Изменения в логике легко версионируются.
QuickJoey
07.02.2017 14:19+1Так я как раз и не думаю, о том, кто и что может увидеть или не может, я один раз добавляю пользователя в роль. Всё. Дальше всё по умолчанию нельзя (нет прав на исполнение процедуры). Дальше, самое страшное что может произойти, это пользователь не сможет что-то сделать, или увидеть.
Вся логика в приложении это круто. Поменять условия выборки — поменяй код. Поменялись проверки — поменяй код. При этом надо заставить всех пользователей перезапустить приложение. Громоздкие SQL запросы в коде. Зачем? Если сейчас я чуть меняю хранимую процедуру (параметры передаются те же) и у всех всё работает по-новому. Не говоря уже о фантазиях сделать приложение под другую платформу (веб, macOS).mayorovp
07.02.2017 14:24Веб-приложения не надо перезапускать. И код обычно меняется проще, чем схема БД.
Вот декстоп — там да, с доставкой новых версий целая эпопея. Да и небезопасен неограниченный доступ к базе с рабочих мест. Поэтому десктопные приложения делают клиент-серверными.
QuickJoey
07.02.2017 14:36Перезапускать не надо, только если в клиентской (браузерной) части нет логики, так?
А про неограниченный доступ к БД с рабочих мест — а какая альтернатива в вебе? Если мы говорим про приложение, которое работает только с БД, и только после авторизации. Зачем какой-то дополнительный компонент авторизации, если уже всё есть – можно/нельзя войти проверяет сервер БД.mayorovp
07.02.2017 14:46Клиентскую часть перезапускать не надо, если не менялся API.
Зачем какой-то дополнительный компонент авторизации, если уже всё есть – можно/нельзя войти проверяет сервер БД.
Потому что так проще (процедурные расширения SQL — не самые простые языки программирования). Возможно, для вас это не так. Но не стоит обобщать свой опыт на весь мир.
Потому что веб-сервер может держать больше соединений чем сервер БД.
Сервер БД не умеет идентифицировать пользователя через WS-Federation или OAuth/OpenID.
Если доступ пользователя к столбцам в БД настраивается довольно просто — то доступом к строкам управлять вам придется вручную, и никакие фреймворки тут не помогут.
- Вам придется городить знатные велосипеды, чтобы передать из БД уведомление об изменении данных.
А про неограниченный доступ к БД с рабочих мест — а какая альтернатива в вебе?
Доступ к БД только от веб-сервера, конечно же. Пароль никому не сообщать, порт закрыть файерволом или биндить на loopback.
QuickJoey
07.02.2017 15:171. «Проще», это вот опять, сложный вопрос. Я до сих пор не понимаю какой комплект технологий (на сервере и клиенте) мне нужен, чтобы просто вытащить в веб-интерфейс справочник из двух полей. Так чтобы легко добавлять/изменять/удалять данные прямо в гриде.
2. Мне не актуально, правда.
3. Аргумент, но наверное не для внутреннего использования.
Я бы с удовольствием обменялся опытом, проектировал бы БД, заедуобучение веб-подходам в очень узкой области)mayorovp
07.02.2017 15:40«Проще», это вот опять, сложный вопрос. Я до сих пор не понимаю какой комплект технологий (на сервере и клиенте) мне нужен, чтобы просто вытащить в веб-интерфейс справочник из двух полей. Так чтобы легко добавлять/изменять/удалять данные прямо в гриде.
На клиенте: HTML + CSS + jquery или какая-нибудь библиотека для двусторонней привязки данных (KnockoutJs или AngularLight).
На сервере: PHP или другой язык, пригодный для веб-программирования (C#, Java, Ruby, Python).
Самым сложным тут будет — избежать отправки на сервер справочника целиком (что чревато конфликтами при одновременном редактировании). Если справочник редактируется монопольно — то задача вообще простейшая, иначе надо будет отслеживать какие строки пользователь менял, а какие — нет.
Я бы с удовольствием обменялся опытом, проектировал бы БД, за еду обучение веб-подходам в очень узкой области)
Да я и "за так" вам про веб-подходы расскажу. Но лучше все-таки это делать на http://ru.stackoverflow.com/, а не в комментариях к случайному посту на хабре.
Аргумент, но наверное не для внутреннего использования.
Для внутреннего использования неплохо заходит авторизация через Active Directory (которая на самом деле Kerberos, не путать с авторизацией через LDAP!). И она, насколько я знаю, из всех СУБД работает только с MS SQL Server.
VolCh
07.02.2017 14:36Хранить пароли не обязательно в открытом виде и вообще хранить не обязательно. Можно хранить зашифрованными (не путать с захешированными), можно передавать с каждым запросом и даже тоже зашифрованным.
michael_vostrikov
07.02.2017 15:17+1Ну так и с логикой в коде так же. Один раз назначили пользователю роль и все. С этой стороны разница только в том, что они хранятся в таблицах типа user и role, а не в системных.
С коннектом напрямую в БД проблема в том, что подключенный пользователь имеет доступ ко всем средствам SQL, поэтому надо по умолчанию ограничивать права на всё.
С доступом через веб-приложение немного попроще — если приложение не предоставляет возможность для отображения таблицы транзакций, то никто их и не прочитает, без всякой проверки прав. А если предоставляет, то можно например id пользователя добавлять в каждый запрос, чтобы он только свои видел.
Если сейчас я чуть меняю хранимую процедуру (параметры передаются те же) и у всех всё работает по-новому. Не говоря уже о фантазиях сделать приложение под другую платформу (веб, macOS).
Вот с доступом через промежуточное веб-приложение все то же самое. Поменяли код — все запросы обрабатываются по-новому. В десктопной разработке это кажется называется сервер приложений и тонкий клиент.
Другое приложение тоже подключить не проблема, для этого делается API, и все клиенты используют его.
QuickJoey
07.02.2017 14:23+21к соединений, это потолок в данном случае, в реальности речь про сотни. 10к и 100к не будет. В чём узость авторизации через БД, я не понял. Плюсы выше про раздачу прав один раз. Равно как, и например, удаление пользователя. В одном месте удалил и не думаешь, откуда и как он ещё мог зайти.
M_AJ
07.02.2017 18:43Я, честно говоря, давно не интересовался вэб-программированием, но «кейс фреймворками не предусмотрен» звучит странно. Почти как «стандартная библиотека моего любимого языка программирования не предусматривает умножения матриц». Неужели в мире вэба свет окончательно сошелся на фреймворках, и на чистом php уже никто не хочет даже просто «пообщаться с БД»?
oxidmod
07.02.2017 19:04Логично, что фрймворки пишуться так, чтобы покрыть самые частые способы использования. И решить самые частые проблемы. И да, я не знаю ни одного фреймворка, который бы авторизовал юзеров посредством бд. Но это не значит что этого нельзя сделать или это сложно сделать. Просто это нужно крейне редко.
И я, как и большинство пользователей пхп-шных фреймворков не вижу никакой пользы от такой фичиVolCh
08.02.2017 09:14И да, я не знаю ни одного фреймворка, который бы авторизовал юзеров посредством бд.
Symfony c Doctrine позволяют это делать, причём на уровне конфигов.Fesor
08.02.2017 10:17+1Эм… это как? Ну то есть, там аутентификация на стороне php происходит, с хэшированием пароля через password_hash и т.д. Да и Doctrine тут не причем, просто есть дефолтный entity user provider.
VolCh
08.02.2017 10:51Это без использования механизма аутентификации Симфони. При создании Doctrine подключения к базе данных, брать параметры не из parameters.yml, а из request. Тупо не аутенфицировался — ошибка подключения, запросил процедуру/вью без необходимых (на уровне БД) прав — ошибка исполнения запроса.
VolCh
08.02.2017 09:12+2Неужели в мире вэба свет окончательно сошелся на фреймворках, и на чистом php уже никто не хочет даже просто «пообщаться с БД»?
В целом да. Более того, это считается дурным тоном для большинства задач. Уж как минимум, соединение должен настроить фреймворк по конфигам. Справедливости ради, нормальные фреймворки позволяют и соединение устанавливать с динамическими параметрами, но большинство разработчиков на них, наверное, даже не знают как это делать, из голого ПХП знают как, а в воркфлоу фреймворка как заинжектить динамику не знают, привыкли к «магии».
http3
08.02.2017 10:47-2Неужели в мире вэба свет окончательно сошелся на фреймворках
Не везде, но фреймворки доминируют.
Разработчики то ли обленились, то ли отупели, то ли тупыми и были, то ли не хотят брать на себя ответственность. :) Бла-бла-бла.
Много свежей крови, которая кроме фреймворков ничего не умеет.
Поколение программистов, не умеющих программировать на языке, на котором написан фреймворк :)
а в воркфлоу фреймворка как заинжектить динамику не знают, привыкли к «магии»
Но фреймворки тоже толком не умеют. :)
Ну такое.
Давайте, вахтеры, минусуйте. :)VolCh
08.02.2017 10:53Разработчики то ли обленились, то ли отупели, то ли тупыми и были, то ли не хотят брать на себя ответственность. :)
Обленились, да. Хороший разработчик — ленивый разработчик. Он не будет писать сотни раз один и тот же код в разных проектах. И даже один раз писать и потом копипастить или подключать не будет, если знает, что есть готовое решение. Это только люди с синдром NIH пишут всё сами, начиная чуть ли не с BIOS.http3
08.02.2017 11:28+1Хороший разработчик — ленивый разработчик
Согласен.
если знает, что есть готовое решение
Вот только пользоваться фреймворками люди не умеют.
Вы же сами это говорили. :)
Да и MVC унылый на фреймворках, как показала статья и комменты. :)
Это только люди с синдром NIH пишут всё сами, начиная чуть ли не с BIOS.
Есть понятие unix-way.
Фреймворк — это швейцарский нож, которым никто не умеет пользоваться :)
Это разве нормально, что программист на фреймворке языка не знает языка и не умеет программировать? :)
Хотя да, разные программисты нужны. :)michael_vostrikov
08.02.2017 12:09+1«Не хочет писать SQL-запросы вручную» не означает «не умеет программировать».
http3
08.02.2017 13:51«Не хочет писать SQL-запросы вручную» не означает «не умеет программировать».
Карл, а где я такое говорил?.. :)michael_vostrikov
08.02.2017 16:24Вы так хотите, чтобы вас носом ткнули? Примерно вот здесь:
Дело в том, что в объектно-ориентированном приложении нет данных, а есть множество объектов и каждый из них содержит какие-то данные и методы работы с ними.
Прекращайте дрочить на ООП.
Если вы предлагаете не использовать объекты, по которым запросы к базе данных строятся автоматически, значит предлагаете использовать запросы вручную и массивы.
Fesor
08.02.2017 13:48+5Вот только пользоваться фреймворками люди не умеют.
Я вам больше скажу. Если вы дадите разработчику голый PHP выйдет скорее всего хуже. Ну то есть тут проблема не в том что люди не умеют пользоваться фреймворками, а в целом не умеют или не хотят думать что они делают. Культ карго, эффект Даннинга-Крюгера и т.п.
Да и MVC унылый на фреймворках, как показала статья и комменты. :)
MVC это buzz-word. В целом например фэйсбук со своим flux подошел очень грамотно. Они просто переименовали вещи и отгородились от общей концепции. Что бы меньше конфликтов вызывало в понимании.
Фреймворк — это швейцарский нож, которым никто не умеет пользоваться :)
Посмотрите на современные фреймворки. Как правило они состоят из набора готовых самодостаточных компонентов. Обычно есть стандартная сборка этих компонентов которая и именуется фреймворком. Но никто не мешает вам брать и использовать другие компоненты.
Есть правда чуть другой вид фреймворков. Они ориентированы на то чтобы дать разработчику не конструктор, из которого он может собрать что ему надо и заменять детали, а скорее платформу. Тот же RoR, Yii и подобные монолитные фреймворки идут именно по этому пути. У этого подхода есть как свои минусы так и плюсы.
Есть понятие unix-way.
Он обязывает иметь самодостаточные модули которые можно комбинировать. Каждый модуль со своей узкой зоной ответственности. Делай что-то одно и делай это хорошо. Но желательно использовать готовые модули а не писать велосипеды. Очень часто когда люди кричат "фреймворки не нужны" потом проскакивает фраза в духе "вот у меня свое ядро есть". И это обычно означает что есть не пачка модулей независимых а каша в которой просто очень хорошо ориентируется ее автор. Так что… тут такое, вопрос восприятия.
Это разве нормально, что программист на фреймворке языка не знает языка и не умеет программировать? :)
Нет, не нормально. Бизнес логика приложения по хорошему не должна быть завязана на язык. Так же есть такая проблема среди разработчиков что если они выбирают один конкретный инструмент, то пытаются потом задачи подгонять под него же. Например ORM. Это хороший инструмент когда нам надо сделать что-то с каким-то небольшим набором данных. Провести бизнес транзакцию. Но многие начинают впадать в крайности и пытаться тем же ORM решать вопросы репортов, сложных выборок и т.д. Это не означает что "ORM не нужны", это означает что люди любят зацикливаться и не особо хотят думать.
http3
08.02.2017 14:41Если вы дадите разработчику голый PHP выйдет скорее всего хуже. Ну то есть тут проблема не в том что люди не умеют пользоваться фреймворками, а в целом не умеют или не хотят думать что они делают.
Выходит парадокс :)
Для того, чтобы нормально пользоваться фреймворком, нужно быть хорошим программистом.
Но хороший программист может обойтись и без фреймворка.
А плохие программисты не могут нормально пользоваться фреймворком.
Но без фреймворка будет еще хуже. :)
ЦА фреймворков — плохие программисты? :)
Культ карго, эффект Даннинга-Крюгера и т.п.
А, ну это да. Странно только, что он так сильно распространен среди программистов или «программистов» :)
Они просто переименовали вещи и отгородились от общей концепции.
Ерунда какая-то :)
Как правило они состоят из набора готовых самодостаточных компонентов. Обычно есть стандартная сборка этих компонентов которая и именуется фреймворком.
1. Только не все умеют эту сборку готовить :)
2. А что должно быть во фреймворке, если выбросить все компоненты?
И это обычно означает что есть не пачка модулей независимых а каша в которой просто очень хорошо ориентируется ее автор.
Хм, но общение может быть организовано посредством какой-то шины :)
Очень часто когда люди кричат «фреймворки не нужны»
Правильней «фреймворки не всем нужны» :)
Но многие начинают впадать в крайности
Об этом и речь, что не нужно впадаться в крайности. :)
Что еще скажу: если человек понимает, что он делает, и знает где что лежит, то плевать, что кто-то считает, что он делает неправильно. :)
Хотя в крайности тут тоже впадать не нужно.
Я вот раньше писал плохо отформатированный код :) Но мне он был понятен :) А сейчас самому противно смотреть на такой код. :)VolCh
08.02.2017 15:12+2Выходит парадокс :)
Для того, чтобы нормально пользоваться фреймворком, нужно быть хорошим программистом.
Но хороший программист может обойтись и без фреймворка.
А плохие программисты не могут нормально пользоваться фреймворком.
Но без фреймворка будет еще хуже. :)
Нет парадокса.
Хороший программист может обойтись без фреймворка, но хорошо подходящий под задачу фреймворк (обычно значительно) ускорит её решение (а плохо подходящий он не выберет).
А плохому программисту фреймворк поможет (или, скорее, заставит) создавать не такой уж плохой код, с которым, в частности, хорошему будет проще разобраться или
ЦА.
В общем ЦА фреймворков — программисты вообще.
Fesor
08.02.2017 19:10+1Для того, чтобы нормально пользоваться фреймворком, нужно быть хорошим программистом.
Но хороший программист может обойтись и без фреймворка.
А плохие программисты не могут нормально пользоваться фреймворком.
Но без фреймворка будет еще хуже. :)Никакого парадокса. Есть такая штука — сюхари.
- не опытный программист если ему дать просто язык программирования напишет вам небезопасное и кривое решение. Причем оно будет плохим во всем.
- Чтобы уменьшить риск ему можно одеть смирительную рубашку в виде фреймворка, который декларирует "правильные" подходы. Далеко не факт что программист будет эти подходы правильно понимать. И да есть проблема что поскольку подходы принимаются на веру программисты становятся религиозны.
- Со временем и при нормальной команде разработчик начинает понимать подходы и использовать инструменты с умом.
- Сильный разработчик прошел все эти этапы, прекрасно ориентируется почему фреймворки такие какие они есть, понимает подходы и т.д. А зная разные подходы и трезво оценивая плюсы и минусы каждого, уже не важно на каком фреймворке (даже если вы решитесь делать все без них у вас выйдет свой фреймворк) будут делаться дела.
Странно только, что он так сильно распространен среди программистов или «программистов» :)
Это общечеловеческий феномен.
- Только не все умеют эту сборку готовить :)
- А что должно быть во фреймворке, если выбросить все компоненты?
- Да, смотрите про "три стадии обучения".
- Клей, мосты между компонентами, адаптеры, загрузка конфигураций и базовая структура. Это не много кода обычно.
Хм, но общение может быть организовано посредством какой-то шины :)
если у вас кучу компонентов связывает одна шина, вы получаете систему с высокой связанностью. Ну то есть все та же каша но с иллюзией порядка.
Правильней «фреймворки не всем нужны» :)
Фреймворки нужны всем. Это каркас. Хотите вы или нет но он у вас появится. Другое дело что есть те 0.1% разработчиков чьи задачи требуют создание своего уникального каркаса.
Что еще скажу: если человек понимает, что он делает, и знает где что лежит, то плевать, что кто-то считает, что он делает неправильно. :)
И тут мы приходим к эффекту Даннинга-Крюгера. Как понять что человек на самом деле понимает что делает а не игнорирует советы других? Проблема то в том что программисты частенько самоучки. И частенько они тусуются в кругу таких же вот самоучек. И невежество начинает укрепляться и распространяться. И в итоге люди исповедующие нормальные подходы остаются в меньшинстве. А поскольку они в меньшинстве то все надеятся на мудрость толпы и т.д.
Я вот раньше писал плохо отформатированный код :) Но мне он был понятен :) А сейчас самому противно смотреть на такой код. :)
Я раньше геттеры у классов делал и думал что это нормально. Как же я был не прав.
http3
09.02.2017 11:27-2Никакого парадокса. Есть такая штука — сюхари.
Беда в том, что программист может застрять на первом уровне и иметь культ карго. :)
Ибо никакого обучения и осмысления нету. Обычное кодирование, как макака. :)
На предложение подумать своей головой, в ответ агрессия. :)
Процитирую:
До того, как вы начнете на практике применять паттерны ООП, и не поймете их минусы и плюсы, я советую не читать книг по паттернам, и не использовать фреймворки, иначе случится паттерн головного мозга, и паттерны будут применяться не по назначению, а просто потому, что вы их знаете, вы будете лепить их к месту и не к месту.
Вам не кажется, что те, кто начинал на голом языке, имеют больший профессионализм?
если у вас кучу компонентов связывает одна шина, вы получаете систему с высокой связанностью.
А на фреймворках компоненты как взаимодействуют друг с другом? :)
Service Container — это та самая единая шина. :)
У меня единая шина событий.
А компоненты одного пространства имен свободно вызывают зависимости, но их не много.
Фреймворки нужны всем.
Тогда так:
«Мейстримовые фреймворки не всем нужны» :)
Клей, мосты между компонентами, адаптеры, загрузка конфигураций и базовая структура. Это не много кода обычно.
Так я и говорю, что это не много. :)
Это можно и самому реализовать, как нужно. :)
И в итоге люди исповедующие нормальные подходы остаются в меньшинстве. А поскольку они в меньшинстве то все надеятся на мудрость толпы и т.д.
Но большинство пишет на фреймворках… :)Fesor
09.02.2017 16:21+3Беда в том, что программист может застрять на первом уровне и иметь культ карго. :)
Это происходит вне зависимости от инструментов. Это лишь говорит о том что разработчик не особо хочет вникать что он делает и зачем. И да, таких много. Но это не проблема инструментов и таким людям обычно ничего не помогает. Обычно они занимаются всякими вордпрессами и подобным.
На предложение подумать своей головой, в ответ агрессия. :)
У человеческого мозга есть такой интересный механизм защиты. Если мы встречаемся с чем-то новым, чем-то что противоречит нашим убеждениям, обычно это воспринимается в штыки. Если у человека развито критическое мышление, но при достаточном количестве аргументов человек начинает менять и адаптировать свою точку зрения. Но чаще всего если это что-то что является основной системы координат (что-то вроде "фреймворки это плохо" или "мой бог круче твоего") мы получим холивар и высокий уровень агрессии.
Если смотреть на это с точки зрения эволюции, скорее всего работает это для того, чтобы встретившись с чем-то новым мы не забывали старый опыт. Например вы знаете что огонь горячий. И когда будете видеть что-то похожее на огонь и вам кто-то скажем что "он холодный" вы врядли поверите и вряд ли без колебаний засунете туда руку. Более того,
Процитирую:
Кого?
Паттерны лишь словарь. Вы говорите кому-то "используй адаптер" и разработчик понимает что ему надо завернуть объект с одним интерфейсом в другой объект, с другим интерфейсом чтобы сделать совместимость (слово адаптер не просто так выбрано). То есть возможно в документации к фреймворку будут использоваться подобные слова, но в целом я не припомню ни одного где подобные вещи диктовались бы. Обычно вы будете натыкаться на предложение "заюзать паттерн" далеко не в начале документации.
Ну и опять же. Перед тем как учить паттерны стоит разобраться с такими понятиями как связанность, управление зависимостями, инкапсуляция, декомпозиция задачи и т.д. Структурное программирование можно вместо ООП поизучать. Но это поднимает уже вопрос процесса обучения — его нет. Я часто видел когда на вопрос "с чего начать" кидают книжку по паттернам, хотя человек еще не умеет алгоритмы строить.
Вам не кажется, что те, кто начинал на голом языке, имеют больший профессионализм?
тут вопрос в том что есть "начинал". Вот к примеру я начинал писать на PHP не потому что мне надо было заказ на фрилансе закрыть, а потому что нужен был простой консольный скриптик который бы сконвертил 3000 документов из одного формата в другой и я не хотел это делать руками. Пришлось разобраться с основами программирования, регулярками и подобным.
А многие под "начинать" подразумевают "ну я на выходных почитал про php и сейчас взял пару заказов на фрилансе и времени разбираться нат надо просто проблему решить".
Перед тем как брать фреймворк в руки разработчик уже должен:
- знать как информация представлена в памяти хотя бы на базовом уровне
- знать что есть алгоритмы и как их писать. Банально понимать как написать свой пузырек или алгоритм бинарного поиска.
- знать хотя бы основную часть синтаксиса языка.
- представлять как происходит процесс разработки ПО.
Если вы посмотрите на какой-нибудь Ruby-on-rails и какие-нибудь толковые курсы в духе "RoR за 3 месяца", то там еще до знакомства с самим фреймворком вас сначала научат на ruby писать, потом научат тесты писать и только потом фреймворк.
То есть знать язык надо, но писать свой фреймворк — плохая идея.
А на фреймворках компоненты как взаимодействуют друг с другом? :)
Service Container — это та самая единая шина. :)давайте разберемся с терминологией что бы лучше друг-друга понимать. "шина" это что-то что выступает как транспорт между компонентами. То есть для того что бы компоненты общались между собой они должны знать о шине. Контейнер зависимостей же это такая штука, которая хранит в себе все зависимости и умеет их выдавать по просьбе. Но компоненты ничего о контейнере не знают. Они общаются напрямую а контейнер лишь "сводит их вместе". Короче говоря это не шина.
У меня единая шина событий.
а вот это уже шина. И это та самая глобальная зависимость в ваших проектах. Если мы возьмем любой компонент вашей системы ему нужна будет эта самая шина.
В целом по поводу событий для снижения связанности… Это очень хороший способ снизить связанность между компонентами. Но помимо связанности есть еще такое понятие как "зацепление" (coheasion) и если связанность должна быть низкой, то зацепление должно быть высоким. Что это значит? Это значит что код который относится к одной области ответственности (все что связано с юзерами например) должно лежать рядом и общаться напрямую без всяких там шин.
«Мейстримовые фреймворки не всем нужны» :)
Они нужны 99.9% проектов. Да, это не всем, но подовляющему большинству. А вот "не мэйнстрим" фреймворки не нужны никому. По очень простой причине. Если вы берете фреймворк написанный васей пупкиным у которого 10 звезд на гитхабе, то все расходы на поддержку этого фреймворка ложатся на вас. Фреймворки комьюнити которых насчитывает десятки тысяч разработчиков использовать как-то проще. Тупая экономика.
Это можно и самому реализовать, как нужно. :)
на готовых компонентах — да. Но только опять же зачем? в чем смысл? берем symfony/framework-standard-edition и он покрывает 90% всех проектов. А вот если мы хотим делать продукт свой например, и нам очень хочется что бы структура проекта отражало то как мы планируем работать с проектом, и мы хотим точно представлять что мы используем — то тут да. компонентики, контейнер зависимостей какой, и все будет хорошо. Вот только для этого на проекте должен быть синьер разработчик который будет следить за всем этим. Джунам — только стандартные сборки.
Но большинство пишет на фреймворках… :)
мне больше нравится интерпретация "большинство используют фреймворки". Если для вас "фреймворк" это структура проекта — ну ок. Для меня "фреймворк" это все что составляет инфраструктуру проекта. То есть если у меня нет фреймворка, он у меня будет.
http3
09.02.2017 18:02Кого?
Чувака одного с форума :)
тут вопрос в том что есть «начинал»
Я тоже начинал по маленькому.
Захотел прикрутить динамику к своему статичному сайту. :)
Контейнер зависимостей же это такая штука, которая хранит в себе все зависимости и умеет их выдавать по просьбе. Но компоненты ничего о контейнере не знают.
Но они же знают, что они ищут. :)
Допустим кеш.
Или кеш на мемкеше наследует базовый кеш.
еще такое понятие как «зацепление» (coheasion) и если связанность должна быть низкой, то зацепление должно быть высоким.
Зацепление высокое :)
Они нужны 99.9% проектов.
Я обязан упомянуть статью
то все расходы на поддержку этого фреймворка ложатся на вас
Какие ж там расходы.
Там же не так и много кода по сравнению с самим приложением.Fesor
10.02.2017 00:57+1Но они же знают, что они ищут. :)
они явно объявляют свои зависимости. Например в такой штуке кака конструктор. И им без разницы есть там какой-то конструктор или клиентский код сам все разрулит.
Зацепление высокое :)
Опять же, когда зацепление высокое но связанность недостаточно низкая то это приводит к вещам вроде god object. Важен баланс. И я не склонен верить высказываниям что у вас все хорошо (только если в скажете что у вас 90+ покрытие юнит тестами кода, и это не 100 тест кейсов, и это настоящие юнит тесты не выходящие за пределы одного процесса).
Я обязан упомянуть статью
Я обязан дать ссылку на докладик: Greg Young — Stop over engineering. Там очень хорошо и про написание своих фреймворков, и про ложный нон конформизм, или за попытки обобщить специализированный функционал....
Там же не так и много кода по сравнению с самим приложением.
любой код который вы используете надо поддерживать. Ваш он, или это внешняя зависимость… Просто если вы используете что-то популярное шанс того что баги за вас будут вылавливать другие тысячи людей повыше. И расходы на поддержку будут равномерно распределяться на большое количество людей.
http3
10.02.2017 14:53Хм. :)
Я тоже не приветствую оверинжиниринг. :)Fesor
10.02.2017 15:08собирать свой фреймворк даже из готовых компонентов в 99% случаев оверинженеринг. Например у меня специализация — апишки писать. Я взял стандартный симфони, накрутил туда пару своих решений, пару чужих, тупо своя сборка, и просто использую из проекта в проект. Большая часть "клея" — стандартная. Это значит что можно дать этот проект на суппорт и дальнешнее развитие любому разработчику который знаком с symfony. А особенности и отличия прописать в README.
Делать же сборку под один проект можно только если вы прекрасно понимаете что делаете. А это уже не новички.
VolCh
08.02.2017 13:59Да и MVC унылый на фреймворках, как показала статья и комменты. :)
Нормальный MVC. Используют его многие ненормально. Например, руководствуются туториалами как пользоваться фреймворками
Есть понятие unix-way.
Фреймворк — это швейцарский нож, которым никто не умеет пользоваться :)
Хороший фреймворк состоит из изолированных, слабосвязанных, заменяемых на сторонние реализации или просто исключаемых модулейhttp3
08.02.2017 15:17Нормальный MVC. Используют его многие ненормально. Например, руководствуются туториалами как пользоваться фреймворками
Плевать.
Когда будут использовать нормально, тогда и поговорим. :)
Прекращайте троллинг.
mayorovp
08.02.2017 11:10+1Открою для вас секрет: фреймворки для того и изобретают, чтобы написание программ было доступнее. Программисты не обленились, нас просто стало больше.
mayorovp
07.02.2017 13:19-2Если бы вы писали БД для веба с нуля — то авторизация средствами БД была бы ужасной архитектурной ошибкой, так же как и бизнес-логика в хранимках. Просто из-за скорости разработки.
Но если БД уже есть и готовая, то веб-фронтэнд к ней сделать намного проще. Фактически, веб-разработчику не нужно вообще думать об авторизации, только об аутентификации. Да и вся серверная часть будет очень простой — вызвать хранимку, передать ей параметры, получить результаты, отобразить их. Фреймворки тут тоже не нужны, разве что что-нибудь для шаблонизации. И для защиты от CSRF, но ее и самому сделать можно.
Возможно, веб-программисты просто не понимали зачем вам вообще они. По-хорошему, тут верстальщика достаточно, а PHP в требуемом объеме вы и сами изучить можете.
Самой большой проблемой будет хранение паролей. Скорее всего, вам придется сохранять пароль пользователя в сессии в открытом виде. Это связано с тем, что базе данных пароль требуется при каждом соединении, а веб-сайт запрашивает его у пользователя один раз. Длительное хранение паролей в открытом виде считается является небезопасным — но само по себе, без других дыр, к проблемам привести не должно. А дыр в подобной крайне простой серверной части быть не должно.
Если использовать языки программирования, отличные от PHP, то там можно хранить в сессии не пароль к БД, а непосредственно открытое соединение. Да и на PHP так можно делать, если написать свой http-сервер или fastcgi-обработчик. Но это будет уже намного сложнее.
Основное ограничение подобного подхода — принципиальная невозможность нормально передать из БД наружу событие об изменении данных. Это значит, что никаких веб-сокетов в подобном веб-сайте не появится никогда, да и AJAX при таком подходе будет не лучшим решением. С другой стороны, в интранете большего и не надо.

VMichael
07.02.2017 14:26+1«Если бы вы писали БД для веба с нуля — то авторизация средствами БД была бы ужасной архитектурной ошибкой, так же как и бизнес-логика в хранимках. Просто из-за скорости разработки.»
Не стоит делать таких обобщений.
Задачи бывают разные, как и подходы к решению задач.
И вы себе противоречите:
Но если БД уже есть и готовая, то веб-фронтэнд к ней сделать намного проще.
Т.е. вы хотите сказать, что весь вопрос только в готовности БД?
Или
Просто из-за скорости разработки.
А что, на другие параметры работы приложений, кроме скорости разработки можно забить?
mayorovp
07.02.2017 14:29-1Т.е. вы хотите сказать, что весь вопрос только в готовности БД?
Да, весь вопрос в готовности БД. Веб-приложение с логикой внутри можно сделать быстрее чем БД с той же самой логикой внутри.
VMichael
07.02.2017 14:37Веб-приложение с логикой внутри можно сделать быстрее чем БД с той же самой логикой внутри.
Ничего себе у вас обобщения.
Вы когда нибудь работали с банковскими приложениями?
Когда бывает на обдумывание, как рассчитать какое нибудь говно со сложными процентами, которое придумали маркетологи, уходит времени на порядки больше, чем оформление расчета в процедуре?
И данные вы будете вытаскивать себе в приложение, что бы там их покрутить?
А БД при этом подождет с блокировками?
Может быть стоит принять, что для разных задач существуют разные оптимальные подходы?mayorovp
07.02.2017 14:50-2Вот именно "говно со сложными процентами" и делается намного проще на нормальных языках программирования, нежели на SQL.
VMichael
07.02.2017 15:00-1Т.е. SQL это «не нормальный» язык программирования?
Я же говорю, вопрос религии всплыл.mayorovp
07.02.2017 15:12+1SQL — это прежде всего язык написания запросов, а не программирования. Это уже накладывает некоторые ограничения.
А поведение оптимизаторов в некоторых СУБД и вовсе заставляет заниматься какой-то ерундой, когда план желаемый выполнения очевиден любому школьнику — но оптимизатор запросов никак не желает его строить.
QuickJoey
07.02.2017 15:05Это же так приятно, написать красивый запрос, который быстро работает и не нагружает сервер. В том числе и вычисление сложных процентов. Сначала вы с кайфом проектируете структуру, которая устойчива к перерасчётам, ковыряниям ручками в данных, изменениям сальдо задним числом, и всему такому, а потом вычисление по всем вкладам/ссудам, и так чтобы одним запросом.
QuickJoey
07.02.2017 14:59+1Вот извините, не соглашусь. Может быть если приложение простое это и верно. У меня только хранимых процедур 2к, если представить, что это переехало в код приложения, да ещё и с обёртками, становится страшно. А зачем это делать, если ровно тоже самое можно сделать не вылезая из сервера, не понятно.
Мне нравится проектировать БД, стараюсь делать, чтобы результатом можно было пользоваться откуда угодно.
Попробую привести пример. Есть прайс-лист, видеть его может почти кто угодно. Например в нём пять колонок. И изменения в одних колонках вызывает каскадные изменения в других, плюс запись лога изменений, плюс что-нибудь ещё.
Изменять отдельную колонку может менять только определённая группа пользователей. Я бы написал 5 хранимых процедур, раздал права на каждую соответствующей группе и всё. Приложение понятия не имеет о том, что и кому можно, оно зовёт одну процедуру в зависимости от того, какую колонку меняют. И можно или нельзя менять проверяет сервер БД. Это же просто и быстро пишется что со стороны приложения, что со стороны сервера БД. Неужели перенеся эту логику в приложение станет проще? (Я осознаю, что почти всё, что я написал можно вообще сделать в триггере).VMichael
07.02.2017 15:07Триггера не очень люблю, отслеживать их сложно.
Описанный вами пример можно сделать проще.
Одна процедура входная.
В зависимости от параметров вызывает другие процедуры, а приложение дергает всегда одну процедуру с разными значениями параметров. :))
mayorovp
07.02.2017 15:29У меня только хранимых процедур 2к, если представить, что это переехало в код приложения, да ещё и с обёртками, становится страшно
А мне вот становится страшно, что 2к функций из потенциального кода уже переехало в базу :) Предлагаю отказаться от понятия "страшно" и прочих эмоций и обсудить в чем именно вы видите проблему.
Лично я вижу проблему 2к хранимок в том, что там наверняка есть куча повторяемого кода, который нельзя куда-то вынести потому что язык не позволяет. Та же обработка ошибок...
Еще проблема может быть с доработками: добавление колонки в часто используемую таблицу приведет к тому, что надо вручную исправлять все хранимки, поскольку инструменты рефакторинга отсутствуют.
По поводу вашего примера с прайсом. В вашем варианте разницы действительно нет (кроме проблемы изменений при доработках).
Но представьте себе, что назначать права доступа нужно не на колонки, а на строки. Например, есть несколько отделов — и менять в каждом из них цены может только тот, что за этот отдел отвечает. Получается, возможность доступа к строке зависит от значения внешнего ключа (номера отдела).
В веб-приложении при хорошем фреймворке практически ничего не изменится. А в БД?
QuickJoey
07.02.2017 15:42Лично я вижу проблему 2к хранимок в том, что там наверняка есть куча повторяемого кода, который нельзя куда-то вынести потому что язык не позволяет. Та же обработка ошибок...
Нет, повторяемого кода нет. Есть, только если нужны выборки с разным доступом, с разным набором полей, что достаточно редкий случай.
Еще проблема может быть с доработками: добавление колонки в часто используемую таблицу приведет к тому, что надо вручную исправлять все хранимки, поскольку инструменты рефакторинга отсутствуют.
Вручную надо исправить ровно одну процедуру – выборку, где это поле нужно добавить. И написать ещё одну, для изменения этого поля (если нужно).
Но представьте себе, что назначать права доступа нужно не на колонки, а на строки.
Да, это действительно проблема, но она обходится, например вспомогательными таблицами с признаками доступа по пользователю/группе, дальше можно просто присоединить к таблице с доступом данные.mayorovp
07.02.2017 16:00Вручную надо исправить ровно одну процедуру – выборку, где это поле нужно добавить. И написать ещё одну, для изменения этого поля (если нужно).
А если поле не добавляется, а выносится в отдельную таблицу? Тогда надо исправлять каждую выборку, где это поле присутствует.
Если у этого поля еще и "популярное" имя — то поиск такого поля по всем хранимкам станет тем еще приключением.
А если схема БД еще и не в виде файла хранится...
OlegYch_real
09.02.2017 22:47+1вас не понимают потому что так никто не делает
так не делают потому что:
1. pl\pgSQL — _очень_ плохой язык, который мало кто знает
2. очень редко вся бизнес логика должна выполняться в транзакции, поэтому для масштабируемости её целесообразно выполнять на отдельном сервере
3. авторизация и прочие дополнительные функции в БД слабо кастомизируются
4. выше упомянутые проблемы с отслеживанием версий и параллельной разработкой
5. БД коннект на пользователя это обычно очень расточительно
6. не уверен насколько гибкие настройки пермишенов в pgsql, но по идее любой кулхацкер сможет заддосить вашу БД просто написав пару строк в консоли браузера
даже если все эти проблемы не актуальны для тупого круда в интранете, вы надеюсь понимаете что никому не интересно применять абсолютно не применимое в 99% случаев решение
из жизни пример — у нас на проекте в начале было очень много хранимых процедур, в итоге почти все выкосили потому что писать их никто не умел а те что были написаны — жутко тормозили
PS это не про вас случайно http://thedailywtf.com/articles/table-driven-software?
PPS просто интересно, а чем вы предлагаете дергать postgres из жаваскрипта?
oxidmod
07.02.2017 12:35+1логика в субд — это боль и страдания, имхо
QuickJoey
07.02.2017 12:43Почему?
При много большом количестве пользователей неизбежны коллизии. На сервере я всегда могу точно сказать в каком состоянии данные, а транзакции помогают эту целостность поддерживать. Или вы про что-то другое?VolCh
07.02.2017 12:47-1Лично я не нашёл удобного инструмента для её версионирования с разными ветками.
VMichael
07.02.2017 12:57+2Код процедур хранится в файлах.
Файлы в контроле версий.VolCh
07.02.2017 13:04В одной ветке процедуры 1, 2, 3, в другой 1,2, 4. При переключении ветки с первой на вторую процедура 3 должна удалиться, а 4 создаться, причём вторая ветка ничего о первой не знает, ветвление произошло когда были только 1 и 2. Как это легко сделать?
VMichael
07.02.2017 13:10+1А как это легко сделать, если у вас логика лежит не в процедуре, а некоем другом файле с логикой?
Или поясните, о чем вы?michael_vostrikov
09.02.2017 20:16+2Логика в файлах, файлы в системе контроля версий. Переключили ветку, поменялись файлы. Всё.
VolCh
12.02.2017 10:48В случае логике на обычных ЯП мне нужно только сбилдить проект после переключения (а в случае интерпретируемых вообще ничего не нужно делать) В случае логики в СУБД, мне нужно после переключения удалить процедуру 3 и создать процедуру 4. Крайне желательно не путём удаления процедур 1, 2 и 3 и создания 1, 2 и 4.
И это самый простой пример. Могут быть разные версии одной процедуры, например. Если не изменилась, то трогать ничего не надо в базе, если изменилась надо изменить и в базе.
QuickJoey
07.02.2017 12:59+1Может быть я неправильно подхожу к разработке, но с такой проблемой не сталкивался. Версия приложения соответствует такой в БД. Изменение версии приложения и обновлённых процедур происходит синхронно.
Меня больше беспокоит прямой доступ к данным, когда все кому не лень при наличии инструмента и некоторых знаний может выбрать что угодно. И такие случаи были, пытались запросы писать из excel.VolCh
07.02.2017 13:06-1Как добиться такого соответствия, если переключаешься между версиями по десятку раз на дню?
VMichael
07.02.2017 13:15+2У вас редкая ситуация.
Но вы можете хранить версии, например бекапа БД, раз у вас такая потребность.
В бекапе таблицы и процедуры вместе.
Или база с таблицами отдельно, код процедур отдельно.
При необходимости можно заскриптовать создание версии БД и файл скрипта хранить там же в ветке.
Туда же в ветку положить и файлы вашего приложения.
Варианты есть.oxidmod
07.02.2017 13:26-1Но самое интересное, что что эти варианты решают проблему, которая не существуюет, если не хранить бизнес-логику в бд. Просто и писать приложение нужно без подстановки данных из запроса напрямую в запрос, тогда никто ничего не выковыряет.
VMichael
07.02.2017 13:34+1О чем вы?
О каких подстановках?
Я говорю о бизнес-приложениях.
Бизнес-приложения, это работа с данными.
Процедуры сохраняют данные (с проверками, например), изменяют данные (по различным правилам), удаляют данные (по правилам), извлекают данные (по правилам).
Веб или десктоп приложения отображают данные.
Различные сервисы принимают-отправляют данные вызывая процедуры.
О какой проблеме вы говорите?
Я выше писал о решении проблемы версионности.
Если вы храните бизнес логику гдето, это где то, тоже файл.
И наплодили веток.
И думаете как между ними переключатся и не потерять изменения, при чем тут хранение бизнес логики в хранимых процедурах?
Это другие проблемы.oxidmod
07.02.2017 15:17-1В чем смысл хранить правила в бд? Ведь ЯП позволит это сделать более выразительно и проще.
mayorovp
07.02.2017 13:29-1Нет, это довольно частая ситуация. Есть подходы разработки, которые плодят довольно много веток.
Тот же git flow.
И с логикой в БД эти подходы не дружат.
VMichael
07.02.2017 13:45+1Я, признаюсь, так и не понял, в чем они не дружат, с логикой в БД?
mayorovp
07.02.2017 13:46+1Ну не умеет GIT переключать разные версии БД. И отслеживать обновления схемы БД не умеет! И нет инструментов, которые бы во всех случаях эти самые обновления умели отследить и объединить, в отличии от файлов.
VMichael
07.02.2017 13:54+1А GIT это и не нужно.
Вопрос вероятно в компетенции или привычке.
Вся схема (структура) БД легко скриптуется и записывается в файл, или как вариант, сохраняется файл бекапа (но там данные место занимают, что вам нужно, не нужно).
Т.е. когда вы коммитите свои изменения вы добавляете в ветку файл со скриптом.
Взяли ветку, развернули скрипт с БД из ветки.
Работайте.
Или вы хотите сказать, что если логика хранится где то, не в процедурах (кстати, процедуры можно воспринимать как файлы с логикой), то никогда не происходит изменения структуры БД?
И вы можете использовать свое приложение с любой версией БД начиная с царя гороха?
Я такого идеального мира не встречал, признаюсь.oxidmod
07.02.2017 14:01ну миграции в современных фреймворках как раз таки этот вопрос решают. Но они могут оперировать структурой и данными, а вот создавать юзеров/раздавать им права это както вне компетенции приложения
VMichael
07.02.2017 14:19Миграции делаются автоматически?
Или программист делает их ручками?
Если второе, так это аналог скрипта для обновления БД, который вы можете положить себе в ветку.
И что то мне говорит, что тривиальные случаи изменения БД, проблем не вызывают при любой технологии.
А сложные, все равно приходится работать руками.
Мы пользовались сторонним инструментом для сравнения БД и составления скриптов, для приведения к единому состоянию.mayorovp
07.02.2017 14:27+1Разумеется, миграции — это те же скрипты, которые можно положить в ветку (и они там лежат!).
Проблемы возникают в случае нелинейной истории, при объединении веток или при переключении между ними.
oxidmod
07.02.2017 14:42ручками пишет в консоли чтото типа bin/console dcotrine:migrations:diff
а дальше оно уже само анализирует состояние кода и состояние бд. На основании разницы формирует миграцию.
зы. Всем поклонникам хранимок. Code First не глупые люди придумалиVMichael
07.02.2017 14:48-1Посмотрел.
Повсеместно принято, что в «серьезных» CRUD приложениях база данных становится во главу угла. Ее проектируют самой первой, она обрастает хранимыми процедурами (stored procedures), с ней приходиться возиться больше всего. Но это не единственный путь! Для Entity Framework есть Code First подход, где главным становится код, а не база. Преимущества:
Никакого генерированного кода
База — это снова просто хранилище. Над ней не надо дрожать, дропается легко и без проблем.
Простейшая установка среды разработки. Выкачал код и запустил — никакой возни с бэкапами.
Господи, это же для тривиальные случаев.
Для таких случаев отличный инструмент.
А когда идет обновление сложнее, с взаимосвязанными элементами, с правильной последовательностью обновления, с обновлением справочников и данных, тогда ценность этой штуки резко уменьшается.
Это примерно как использовать мастера создания чего то.
Отличные инструменты и реально ускоряют.
В тривиальных случаях.
А дальше ручками.
И чем сложнее у вас логика, тем менее ценными становятся мастера.mayorovp
07.02.2017 14:52+1Господи, это же для тривиальные случаев.
Для таких случаев отличный инструмент.
А когда идет обновление сложнее, с взаимосвязанными элементами, с правильной последовательностью обновления, с обновлением справочников и данных, тогда ценность этой штуки резко уменьшается.Именно! В том-то и проблема, что нормальных инструментов для нелинейного версионирования схемы БД — не существует.
Существовали бы — писать хранимки было бы намного проще.
А пока — используется подход "схему БД меняем только после согласования со всеми коллегами"
VMichael
07.02.2017 14:55Я же говорю, вопрос в привычке или компетенции.
Хранимки не равны схеме БД.
Хранимки вы можете хранить в другой БД.
Можете убить хранимки, схема БД от этого не изменится.
А вы все время их смешиваете.
И что такоенелинейного версионирования схемы БД
вообще не понятно.
У вас в один момент времени на сервере живет много версий БД?
Ладно, не убедили в общем.
Вижу тут вопрос религии.mayorovp
07.02.2017 15:08https://habrahabr.ru/post/321050/#comment_10056898
Зря вы в разных ветках отвечаете, раз сами жалуетесь, что вам это трудно.
VolCh
08.02.2017 09:07+1Хранимки не равны схеме БД.
Да, не равны. Они часть часть схемы.
И что такое
нелинейного версионирования схемы БД
вообще не понятно.
Когда база меняется не пошагово в одном потоке и одном направлении, максимум иногда откатывается, а шаг иди два, а идёт развитие параллельно в нескольких направлениях, возможно разными разработчиками, и эти направления потом сливаются.
У вас в один момент времени на сервере живет много версий БД?
Одновременно одна, но за день может менятся несколько раз и это не только «вперёд» и «назад», но и «влево-вправо».
Простой пример:
в продакшене база с таблицей contract c полем типа enum status. В рамках одной задачи нужно расширить количество значений, разбив существующее на два, в рамках другой перенести поле в отдельную таблицу для хранения истории изменений. Задачи разработчики делают в разных ветках гита/мерка/свн/… О задачах друг друга до поры до времени вообще не знают. Их лид должен сначала проверить изменения одного, потом другого, а потом слить их. Разработчики написали скрипты миграции (накатывания и отката) для своих задач. Сейчас у него копия продакшен базы (версия A). Сначала он должен быстро проверить задачу разбиения значения на два (версия B), потом создания отдельной таблицы (версия C). Для этого система версионирования должна позволять ему быстро (читай автоматически) переключаться с версии A на B (разбить значение), с B на A (объединить значения), с A на C (создать таблицу, скоипровать значения, удалить поле) с C на A (создать поле, скопировать последнее значение, удалить поле). Эта задача, в принципе решена существующими инструментами в виде скриптов миграции созданными разработчиками или даже автоматически (на пустой базе, без сохранения данных кроме самых тривиальных случаев типа переименования столбца/таблицы). Но вот задача переключения с B на C и обратно решена уже хуже. Система версионирования должна понять, что общий предок у них версия A, откатить изменения версии B, накатить изменения версии C и наоборот. Задача объединения версий B и С практически не решена, максимум по таймстампам пытается определить какой скрипт миграции ставит первым. И это лишь по схеме собственно данных, когда есть формальное описание схемы, как правило не на SQL. С хранимыми процедурами, функциями, триггерами всё ещё хуже. Собственно из рассмотренных мною решений никто и не пытается автоматически что-то делать.
VMichael
08.02.2017 09:38-1Хранимые процедуры НЕ часть схемы БД.
Хранимые процедуры это скомпилированный код с сохраненным планом запроса.
Хранимые процедуры могут хранится в другой базе и даже на другом сервере.
Тоже и функции.
Схема БД от этого не меняется.
К триггерам я отношусь не очень хорошо, часто триггерами прикрывают косяк проектированя БД, когда приходится обновлять где то данные. Хотя как инструмент они есть и вероятно кому то очень нужен. Я обходился без триггеров, хотя механизмо работы с ними владею, конечно. Но это мое частное мнение, отстаивать не готов. Так отступление.
Так вот, когда вы примете, что процедуры и функции, это просто код, сохраненный где то, с ними и работать остается как с кодом.
А ситуация описанная вами не разруливается легко и при хранении логики не в функциях. Приходится ручками работать.
Подумайте об организационных решениях.
Как вариант, может стоит подумать, что бы несколько разрабов не дербанили один модуль одновременно, раз такие издержки возникают.
Или продумывайте схему данных более тщательно, возьмите базовика в команду, тогда меньше придется схему данных гонять туда сюда.michael_vostrikov
08.02.2017 09:46+2Или просто пишите код не в базе. Разница в том, сколько именно приходится работать ручками.
mayorovp
07.02.2017 14:26Схема БД, записанная в 1 файл, хорошо смотрится только пока БД разворачивается с нуля.
Но вот у вас в БД уже полно данных, и вам надо выкатить новую версию. Что будете делать?
VMichael
07.02.2017 14:31+1Выкатить новую версию чего?
Веб морды, дескопного прилоения или новую версию БД?
Или и того и другого?
И мы говорим про обновлении продакшена или про работу разработчика, который вынужден прыгать по веткам?
P\S: (У вас преимущество, я могу писать раз в 5 минут, это снижает мотивацию писать, особенно в разные ветки).mayorovp
07.02.2017 14:34Мне странно ваше непонимание.
Я говорил, конечно же, про продакшен или приближенные к нему окружения. Локальную базу разработчика пересоздать — ни разу не проблема.
Развертывать нужно новую версию приложения, куда входит новая схема БД.
VMichael
07.02.2017 14:42Если вы посмотрите дискуссию выше, вопрос был у человека, которому по роду разработки постоянно (десять раз на дню) приходится переключатся на разные ветки. Думаю это не продакшен все таки.
А вопрос разворачивания новых версий, он вообще отдельный.
Если смотреть в БД, то по любому, для создания новой схемы, там накатывается скрипт.
И как вы запустите этот скрипт, уже другой вопрос.
У нас было специальное приложение, которое накатывало скрипты и файлы обновления и следило за ошибками.
И создавая скрипты, мы обязаны были думать о последовательности обновлений и о возможности отката, если что то пошло не так.
Не вижу тут принципиальной невозможности использовать процедуры.mayorovp
07.02.2017 15:06+1У нас было специальное приложение, которое накатывало скрипты и файлы обновления и следило за ошибками.
… и это приложение было написано для линейной истории версий. То есть для одной ветки. У меня в каждом проекте такое же есть, кстати.
А вот при разработке в разных ветках проблемы и начинаются.
- Александр добавил в таблицу колонку X
- Борис добавил в таблицу колонку X
- Виктор добавил в таблицу колонку Y
- Изменения Александра (1) были развернуты на сервере
- Виктор смерджил себе изменения Бориса (2)
- Александр смерджил себе изменения Виктора (5) и обнаружил конфликт
- Александр переименовал свою колонку X, два ей имя Z.
- Борис переименовал свою колонку X, два ей имя T.
Теперь все эти изменения надо развернуть на сервере. Не потеряв данные, которые уже накопились в колонке X.
Вы представляете себе, с какой стороны вообще подступать к этой задаче?
А ведь есть и более сложные случаи, когда колонка была удалена, потом удаление отменили — и надо получившуюся ветку слить с основной так, чтобы не потерять данные на продуктиве. Но при этом скрыть факт удаления колонки из истории нельзя — потому что на тестовом сервере ее уже удалили и надо восстанавливать, пусть и без данных.

realbtr
07.02.2017 15:14Это Вам прямая дорожка к философии MDM. Не к частным решениям, а к детально прописанного подходу к манипулированию данными.К регламентам и процедурам. И git тут не помощник. Разные сферы.
Разумеется, обычные СУБД не предоставляют соответствующих инструментов. Но для промышленных СУБД такой инструментарий за хорошие деньги стоит приобретать.mayorovp
07.02.2017 15:48А-а-а! Нахер! Нахер MDM! Это чертово глюкалово, которое нихера не работает, только тормозит!
Извините, не сдержался.
VMichael
07.02.2017 15:38Экая вакханалия у вас с базой творится.
Тут нужно прописывать порядок работы, быть может.
И ваш инструмент автоматически такую ситуацию разруливает?
Как такой вариант:
К таблице обращение только через процедуру.
Изменилась таблица, изменилась процедура.
Все кто берет процедуру из ветки, видят, что таблица изменилась.
Далее разруливается, как обычно с кодом.mayorovp
07.02.2017 15:52+2И как работа через процедуру позволит не запутаться в нелинейных миграциях?
И ваш инструмент автоматически такую ситуацию разруливает?
Такие — никак. Я намеренно привел ситуацию, которую не умеет разруливать ни один известный мне инструмент.
Но заметьте: когда такое творится с базой — это "вакханалия". А когда такое творится с кодом — это нормальный рабочий процесс, разруливаемый гитом без всяких проблем.
Причина различий — в том, что в коде нет накопленных данных, которые нельзя терять. Каждый билд кода — все равно что создание базы с нуля. Именно поэтому код мне нравится больше базы.
VMichael
07.02.2017 16:37-1Т.е. отстаивая свою нелюбовь к БД вы приводите пример, который не разруливается и вне БД.
Такой аргумент нет смысла учитывать.
То, что вам код нравится больше, чем БД, не отменяет того, что с БД нужно работать, просто вы, скорее всего, «не умеете их готовить».
Это довольно распространенная ситуация.mayorovp
07.02.2017 16:46Глаза разуйте уже.
Но заметьте: когда такое творится с базой — это "вакханалия". А когда такое творится с кодом — это нормальный рабочий процесс, разруливаемый гитом без всяких проблем.
VMichael
07.02.2017 17:58Нет, вакханалией я назвал ситуацию, когда Вася, Петя, Коля и т.д. меняют структуру БД в одном и том же месте, не связанно друг с другом, кому как бог на душу положил.
Т.е. речи об некоей архитектуре общей не идет.
И приходится потом разруливать всякие косяки.mayorovp
07.02.2017 17:59Они меняют ее не в одном месте, а в разных. Колонки-то независимы друг от друга.
VolCh
07.02.2017 17:34В приложении у меня хранится описание схемы данных (таблиц, индексов, ключей), при переключении ветки происходит сравнение текущей схемы базы с описанной в приложении и накатываются изменения приводящие её к описанной. Не всегда всё хорошо отрабатывает, но процентов 90, а то и больше потребностей разработки и тестирования покрывает с сохранением данных в базе при переключении без всяких бэкапов. С хранимками и прочими триггерами я не нашел удобного способа переключаться между ветками. Единственный рабочий вариант — дропать базу и создавать её с нуля.
mayorovp
07.02.2017 17:40С хранимками и триггерами как раз нормальный рабочий вариант — дропать все хранимки и создавать их с нуля.
VMichael
07.02.2017 18:04-1Т.е. процентов 90 у вас работает, остальное нет?
Это же не вариант.
Вариант единственный, должно работать все.
Дропнуть базу и накатить скрипт, тривиальная операция.
А в вашем варианте наборы данных, хотя бы тестовых вы тоже храните в приложении?VolCh
08.02.2017 09:17Процентов 10 требует ручного вмешательства. Собственно как и при работе с кодом посредством популярных VCS.
QuickJoey
07.02.2017 14:29Вот честно, не сталкивался, есть боевая база и приложение к ней. И есть несколько версий для разработчиков, где каждая версия БД соответствует версии приложения которое меняет разработчик, он не переключается никуда.
VMichael
07.02.2017 12:43+1Хм.
Вовсе нет.
Логика в хранимых процедура это весьма удобно и часто используется.
А отображать можно хоть вебом, хоть десктопом.s-kozlov
07.02.2017 13:01-2Логика в хранимых процедура это весьма удобно и часто используется.
«Потом его в дурку забрали, конечно» (с)
Извините, не удержался.reforms
07.02.2017 14:33У Вас жгучий сарказм, не понимаю почему минусуют.
Логика в хранимых процедура это весьма удобно и часто используется.
А здесь все зависит от типа приложения и характера сопровождения: у нас, например, 4 типа СУБД поддерживаются, а решение сопровождается самим клиентом. Поэтому все в хранимках делать — это та еще задачка.
Но если рассматривать конкретных случае — решение вполне себе приемлимое.VMichael
07.02.2017 15:21Но если рассматривать конкретных случае — решение вполне себе приемлимое.
Все верно.
Это и пытаюсь донести.
С чего началось обсуждение:
логика в субд — это боль и страдания, имхо
oxidmod
07.02.2017 15:34+1Если вас отпустит, то я добавлю: боль и страдание в большинстве случаев, но допустимо в узких кейсах
VMichael
08.02.2017 09:46Что такое «большинство случаев»?
Большинство случаев в вашей личной практике?
Большинство случаев создания сайтов визиток?
Или даже скажем, что кроме веба жизни нет?oxidmod
08.02.2017 10:32+1Даже не в вебе почемуто есть «сервер приложений» и «сервер баз данных».
Если оглядется, то можно увидеть что все больше и больше десктопного софта сползает в веб.
И, вы наверно не поверите, но подавляющее большинство «веб-приложений» эту визитки, лендинги или простые cms-based решения, в которіх вообще нету смысла авторизировать юзеров посредством логина в бдVMichael
08.02.2017 11:11Хорошо.
Пример.
Двигается груз.
На складах скануют, десктопные приложения.
Пишут в БД посредством дерганья процедур.
При этом сразу создаются накладные и происходят проверки.
С веба клиенты отслеживают движение груза, веб интерфес обращается к БД, дергает процедуры, в процедурах правила описаны, что показывать клиенту, что не показывать.
Отдел расчетов, десктопное приложение, обращается в БД, дергает процедуры,
которые выбирают данные из БД (накладные, созданные на складах), на основе и по правилам обработки данных выставляются счета.
Счета клиент, через веб приложение просматривает и оплачивает.
Другие клиенты, на своих складах, через приложение, создают накладные на груз и через веб (а кто то по е-майл) заливают их в БД, через те же процедуры (в которых описаны проверки и правила).
Т.е. все источники и потребители дергают одни и те же процедуры для обработки данных.
Далее репликация разносит данные в десятки филиалов на локальные сервера баз данных, где работает все аналогчно (остановка на часы недопустима, каналы связи этого не позволяют гарантировать, поэтому репликация бегает).
Все это крутится с логикой в хранимых процедурах.
Проект не маленький, работает без сбоев и развивается.
Данные и логика обработки данных живут в одном месте и хорошо живут.
Ну просто как пример.
Теперь эту кухню, разместите у себя в коде и прикиньте возникающие при этом сложности.
Просто как вариант.oxidmod
08.02.2017 11:38+2Все тоже самое, только через АПИ. При этом бд доступна только с локалхоста (сесурити), а не со всего мира.
При этом у вас есть красивая, легкая админка, где можно мышкой создавать новых юзеров, новые группы юзеров, управлять правами и доступами.
При этом вы не ограничены количеством конектов к бд, потому что коннект только между приложением и бд.
При этом клиентские приложения не имеюют прямого доступа к бд и физически не могут ничего сделать с бд, только то что дает АПИ.
Теперь эту кухню, разместите у себя в коде и прикиньте возникающие при этом сложности.
Почему вы не учитываете сложность написание всей этой кухни в процедурах, без возможности переиспользования кода. Без возможности использовать готовые, оттестированные решения?VMichael
08.02.2017 12:44«Красивая, легкая админка».
Все через API.
А по поводу сложности написания всех этой кухни.
Апи ваше данными манипулирует на каком языке? Не SQL?
Но кроме сложности манипулированя данными вы добавляете обертку сверху в виде API, что еще усложняет.
В общем, если вы столкнетесь с приложениями такого уровня, вы откроете для себя много нового.
oxidmod
08.02.2017 12:58Уж поверьте, но писать приложение на высокоуровневом ЯП гораздо проще чем на языке предназначенном только для манипулирования данными.
Для всех выскоуровневых ЯП имеюются удобные абстракции для работы с СУБД. А так же возможность писать рав запросы для кейсов, когда средсв ОРМ недостаточно.
Тут как раз все наоборот.
Что вы будете делать, когда часть данных придется вынести из базы в редис/монгу/етц?
Что вы будете делать, когда бизнесс захочет искать по по гигабайтах текста? sql очень мощный и выразительный язык. Но у него своя нишаVMichael
08.02.2017 13:06удобные абстракции для работы с СУБД
Простите, друг.
Но, вероятно, Вы не работали в ситуации, когда не понятно, как вытянуть производительность БД используя все тонкости конкретной СУБД, в рамках выделенных ресурсов для этого.
Только на днях консультировал любителей абстракций и ОРМ, на предмет, почему не могут выполнить простенький, вроде, отчет, который работал отлично, когда данных было мало, и вдруг перестал работать, когда приложение отработало пару месяцев.
Ладно, удачи вам, пусть ваш путь будет легким.mayorovp
08.02.2017 13:19Вы слышали что-нибудь про преждевременные оптимизации?
То, что вам пришлось консультировать коллег — это совершенно нормальный рабочий процесс. Поймите: у них уже два месяца как есть приложение, которое работает! У них не было проблем ни с занесением данных в БД, ни с отображением их для пользователя.
И через два месяца все что случилось — сломался один отчет! Который они, после ваших консультаций, починили. А все остальное у них продолжает работать.
Если бы у них еще и было больше опыта — они бы знали про проблему с отчетом заранее — и за те два месяца, пока их приложение работало, успели бы десять раз его исправить.
VMichael
08.02.2017 13:35Не совсем так.
Через два месяца пришло осознание, что БД это не просто какая то лабуда, а отдельный раздел знаний, требующий навыков и времени на освоение.
Что когда демонстрировали заказчику на тестовых данных, все было отлично.
А когда контроллеры оборудования стали лить реальные данные, все встало колом, отчет это первая ласточка.
А теперь идет речь о перепроектировании приложения, о выбросе того, что сделано, потому, что БД это фундамент, образно говоря, и чешут репу, где взять на это деньги.
А проблем с занесение данных и с отображением, обычно не бывает.
Это тривиальные операции.
Как раз отчеты обычно и ставят раком плохо спроектированную БД.
Попробую еще раз, для вас специально.
Я ЗНАЮ, что существуют операции с данными, которые вы не сможете сделать с адекватной производительностью и обработкой, без использования процедур в БД. Возможно вам это не встречалось, но поверьте, я более 20 лет работаю с базами данных в разных организациях.
Т.е. ваше приложение будет вынуждено в такой ситуации дергать процедуру.
И вы начнете размазывать вашу логику. Часть на сервере приложений. Часть в процедурах.
Улавливаете мысль?
Следующих шаг, зачем делать обработку данных в разных местах?
Логичнее сосредоточить ее в одном месте.
И вот логика перелезла в процедуры.
А веб, десктоп, прочие сервисы, это просто интерфейсы для отображения и обмена данными.
Я не утверждаю, что нельзя делать по другому.
Да можно конечно.
Я утверждаю, что бизнес логика в процедурах это не боль, как вы утверждаете, а вполне себе рабочее решение (каким цветом рисовать строку, это не бизнес логика, простите, это тривиальная рюшечка интерфейса, хотя признак цвета строки может отработать процедура также).mayorovp
08.02.2017 13:40Следующих шаг, зачем делать обработку данных в разных местах?
Чтобы упростить код. Потому что когда логика в разных местах, код получается проще.
VMichael
08.02.2017 13:52Чтобы упростить код. Потому что когда логика в разных местах, код получается проще.
Вы это серьезно пишете?mayorovp
08.02.2017 14:17+1Да. На нормальных языках программирования доступны всевозможные инструменты борьбы со сложностью, придуманные поколениями программистов.
Все паттерны, библиотеки, фреймворки и технологии — это не просто страшные или модные слова, это средства, которые делают код проще. Они были созданы для этой цели.

Bronx
14.02.2017 11:43Вы гоняете отчёты прямо на том же сервере, в которые заливаете оперативные данные? Или всё же держите для этого реплику (или даже сервер отчётов, со специально денормализованной схемой), да на отдельной машине, выделенной специально для генерации тяжёлых запросов?
Fesor
08.02.2017 13:51+1В PHP комьюнити есть такой ORM как Doctrine. И авторы оного когда выступают на конференциях с докладами вроде "Doctrine best practice" очень много говорят про то что ORM созданы для OLTP и для таких вещей как репорты придуман замечательный инструмент — SQL. Так что проблема не в инструментах а в головах.
Что до "абстракций". Абстракции разные бывают. DAO тоже абстракция и она не мешает вам использовать вашу СУБД на полную катушку. Но вот с точки зрения приложения вся работа с СУБД изолирована и детали работы с оной так же. В этом собственно и заключается суть абстракции.
VMichael
08.02.2017 14:17Я работал с DAO.
Для любой задачи более, менее сложной обработки данных, кроме тривиальных селектов до апдейтов, делаются процедуры обработки данных и потом, удобно из интерфейса через DAO дергать процедуры :)
michael_vostrikov
08.02.2017 13:33+2Но кроме сложности манипулированя данными вы добавляете обертку сверху в виде API, что еще усложняет.
Нет. Обертка над SELECT/INSERT/UPDATE/DELETE в виде API с бизнес-логикой добавляется вместо обертки над теми же SELECT/INSERT/UPDATE/DELETE в виде SQL-процедур.
Сталкивался с приложениями обоих видов. Поддерживал одно время программу на Delphi+Firebird с логином через БД, последнее время занимаюсь веб-программированием. Поэтому могу сказать по опыту — серверные приложения гораздо проще в поддержке. В свою очередь могу вам посоветовать познакомиться с такими приложениями. Откроете для себя много нового)VMichael
08.02.2017 13:41Хорошо.
Вам нужно выбрать из сотни миллионов записей о транзакциях, несколько десятков тысяч, сохранить их во временной таблице, наложить на нее индекс, другой.
Затем из других связанных таблиц выбрать еще пару тыс. записей.
Сохранить их во временной таблице.
Потом пробежаться курсором по результирующему множеству, полученному с помощью оконных функций и в соответствии с правилами обработать, произведя проверки на доступность операций для документов с данным статусом и для отсутствующих документов, сгенерировать их (для генерации есть свои процедуры.
При этом на время операции генерирования, будут блокироваться части таблиц, в которые пишут другие процессы, т.е. нужна максимальная производительность операций.
Вы будете данные операции делать в некоей обертке с бизнес логикой?mayorovp
08.02.2017 13:43Это вы свое решение рассказали. А теперь расскажите условие задачи.
VMichael
08.02.2017 13:46Задача?
Обработка документов в банке.
Начисление процентов, пени, комиссий за услуги, ежедневное.oxidmod
08.02.2017 13:59+11. Никто не спорит, что для аналитических задач орм не годится. Но есть инструменты и поинтересней чем процедуры в субд. Теже кубы/вертика и еще пачках других решений, которые будут более гибкими и удобными.
2. Я вот прямо сплю и вижу как придется менять процедуру начисляющую проценты по кредиту/депозиту каждый раз когда банк предлагает новый продукт для клиента, ага. Кроме того, эта задача работает явно в контексте клиента и легко паралелится на пачку воркеров со всеми удобствами высокоуровневого ЯПVMichael
08.02.2017 14:12-11. Никто не спорит, что для аналитических задач орм не годится. Но есть инструменты и поинтересней чем процедуры в субд. Теже кубы/вертика и еще пачках других решений, которые будут более гибкими и удобными.
Вы пробовали сопровождать кубы и пачки других решений? Очень интересная задача и весьма дорогая в обслуживании.
2. Я вот прямо сплю и вижу как придется менять процедуру начисляющую проценты по кредиту/депозиту каждый раз когда банк предлагает новый продукт для клиента, ага. Кроме того, эта задача работает явно в контексте клиента и легко паралелится на пачку воркеров со всеми удобствами высокоуровневого ЯП
Ну, то есть опыта такой работы у вас нет, но вы точно знаете как это делать лучше.
Хорошо, пусть ваша дорога будет удобной для вас.oxidmod
08.02.2017 14:18Вы пробовали сопровождать кубы и пачки других решений? Очень интересная задача и весьма дорогая в обслуживании.
Ну так вы определитесь, что вам нужно? Перфоманс и гибкость или абы как, но чтобы хоть чтото? Мне ли вам рассказывать о возможностях кубов по сравнению с процедурами?
VolCh
08.02.2017 14:35Кроме того, эта задача работает явно в контексте клиента
Далеко не факт. Очень многое зависит от административных регламентов и политик.oxidmod
08.02.2017 14:44+1Если вам не трудно, то расскажите как начисление процента по кредиту Васи Пупкина или ООО «Рога и Копыта» может зависить от чегото не связанного с самим кредитом и его получателем + какихто общих «справочников» со ставками и тому подобное? Мне просто интересно, что такого может быть в административных регламентах и политиках, что не позволит распаралелить эти рассчеты?
VolCh
08.02.2017 16:09Часто результат начисления процентов по всем договорам должен быть оформлен в виде единого документа по всем операциям и клиенты в нём даже не упоминаются, от них результат расчёта никак не зависит.
И я только про контекст, а не про параллельную обработку.
michael_vostrikov
08.02.2017 16:05Действительно, вы бы подробнее задачу описали, с примером каким-нибудь.
Если задача именно в таком виде, то я бы так и сделал, с временными таблицами и процедурами. Пусть 3% логики будут в базе, но хотя бы остальными 97% будет проще управлять.
Но вообще есть вопросы. Зачем на время операции генерирования блокировать таблицы? Почему нельзя пару тысяч записей вытянуть в оперативную память? Курсор и оконные функции это типичные вычисления в цикле с накоплением результата. Почему нельзя использовать код видаwhile ($row = $query->fetchRow()) { do something }? Джойн двух временных таблиц, подозреваю, можно заменить на группировку вида$orders[$client_id][] = $order.
Вот тут хороший пример был. Куча SQL с временными таблицами заменяется на 3 вложенных цикла.VolCh
08.02.2017 16:13Зачем на время операции генерирования блокировать таблицы?
Чтобы во время начисления не прошла операция выдачи или погашения. Нужно, как минимум, блокировать вставку новых платежей по конкретному счёту по которому в данный момент производится начисление. Знаете способ как блокировать вставку записей в таблицу с конкретным значением поля?michael_vostrikov
08.02.2017 16:41А, ну так какая разница, из SQL мы ее заблокируем, или из приложения.
Способ есть, через блокировки. Блокируем строку счета на запись, и во всех операциях на изменение счета сначала читаем строку с этим счетом.
Bronx
14.02.2017 12:03+1Зачем блокировать клиентские операции? Начисление процентов делается на определённую дату/время, значит нужно лишь ограничить выборку транзакций этой временнОй меткой, после расчёта добавить транзакцию начисления процентов с информацией о времени расчёта. Если во время расчёта прошли какие-то операции — да и пусть их, они будут учтены при следующем расчёте. Так как в запросе указан диапазон, можно включать оптимизации (key-range lock например), чтобы не блокировать всю таблицу.
VolCh
14.02.2017 12:54Если во время расчёта прошли какие-то операции — да и пусть их, они будут учтены при следующем расчёте.
Грозит проблемами не только с конкретным клиентом, но и с регулятором. Банально, у клиента 100 000 тела кредита и 10 000 процентов, нужно начислить ещё 100 процентов в полночь. Начинаем считать. Тут же приходит платеж от клиента на 20 000. Если мы его пишем без блокировок, не дожидаясь окончания расчёта, то, с одной стороны, мы распределим платеж как 10 000 на тело и 10 000 на проценты и рассчитаем проценты на 100 000, хотя должны бы по идее либо 10 100 на проценты и 9 900 на тело, либо 10000 на тело и 10000 на проценты, но тогда расчёт процентов должен быть не на 100000, а на 90000, грубо не 100, а 90. Клиент заметит лишних начисленных 10 рублей или не погашенных 100 рублей процентов и побежит с жалобой в ЦБ РФ.mayorovp
14.02.2017 13:07А проценты на тело и проценты на проценты как-то по-разному считаются?.. Надо просто записать платеж на 20 000 целиком, куда он там достался — можно определить позже, при следующем расчете процентов.
VolCh
15.02.2017 09:50Проценты на проценты могут не считаться как раз. Нам надо не только записать платеж к себе, но и дать клиенту (а также сообщить регулятору, про онлайн кассы слышали?) чек или квитанцию, где четко расписано «тела уплачено 10000, процентов 10000» или «тела уплачено 9900, процентов 10100»
Bronx
14.02.2017 13:57+1Если мы его пишем без блокировок, не дожидаясь окончания расчёта, то, с одной стороны, мы распределим платеж как 10 000 на тело и 10 000 на проценты
Мы его пишем без блокировок, но отнюдь никуда не распределяем. Мы просто создаём запись в таблице транзакций, проставляя время (00:01) и сумму (20к). Так как отметка времени позже полуночи, то в расчёт процентов предыдущего дня этот платёж не попадает. Полночь — это момент отсечки, ровно так же, как если бы мы заблокировали БД.
Как раскидать сумму платежа по телу и по процентам — это должно рассчитываться совершенно отдельно, где-то на этапе составления отчётов и расчёта процентов при закрытии следующего дня.VolCh
15.02.2017 09:54проставляя время (00:01)
Грязный хак. Особенно быстро выплывет, если платеж принимается не самостоятельно, а через внешних посредников типа платежных систем — у клиента в чеке 00:00:00, а у вас 00.00.01 в выписке по счёту.
это должно рассчитываться совершенно отдельно
Это может рассчитываться отдельно, если у регуляторов нет требований выдавать клиенту в момент оплаты чек, квитанцию, корешок к ПКО с чётким разбиением уплаченной суммы на тело, проценты, пеню и т. п.Bronx
15.02.2017 10:13+1Почему хак? Время истинное, не искусственное, это я просто выбрал для примера время близкое к полуночи. Даже если время транзакции будет ровно полночь, наносекунда в наносекунду, работать это будет точно так же, потому что условие выборки будет timestamp < noon.
Если регуляторы требуют выдать квитанцию с немедленной раскладкой, то надо принять платёж без блокирования таблиц, но временно приостановить выдачу квитанции. Клиенту так и так пришлось бы сидеть и ждать окончания расчёта, ну так пусть это будет сделано lock-free.VolCh
15.02.2017 10:54-1Как узнать, что следует приостановить выдачу квитанции? И до каких пор приостанавливать?
Bronx
15.02.2017 11:14Разные варианты могут быть. Например, приостановить все виды отчётов пока день не закрыт полностью. Или пока не закончатся все задачи, способные ретроактивно повлиять на баланс. Или по-быстрому инициировать пересчёт процентов конкретно для этого счёта, что займёт совсем мало времени, после чего выдать актуальную квитанцию.
VolCh
15.02.2017 12:38Квитанция не отчёт, она выдаётся не после закрытия дня. Она результат проведения платежа, её в реалтайме ждут клиент, её ждёт платежная система, не разрывая соединения.
Bronx
15.02.2017 14:17+1Если в квитанции есть информация, не содержащаяся в самом платеже — всякие итоги, раскладки, статистики и т.п., то это уже мини-отчёт. Кто его ждёт — не суть важно. Но это уже игра с терминологией.
Точно так же все будут ждать результатов платежа, если заблокировать таблицу. При этом конца расчёта будет ждать не один клиент, а несколько. Если делать без блокировки, то ждать будет только тот, у кого проценты за день ещё не подсчитаны. Если пересчёт делать индивидуально, маленькими кусками, а не одной большой задачей по всей базе, то время ожидания будет миллисекунды.
mayorovp
15.02.2017 10:23Это не хак, это упрощение. Надо просто милисекунды хранить. Их и показывать-то необязательно.
Хуже с неодинаковостью времени на разных серверах.
VMichael
10.02.2017 13:33Циклы в БД это зло, порой вынужденное.
Циклы обрабатывают данные построчно.
Циклы работают на порядки медленнее и сильно засаживают производительнось сервера БД.
Циклы в БД это крайний случай, когда без них не получается обойтись.
Это трудно понять, пока вы не работаете с большими массивами данных.
В приведенном вами примере адский геморрой в исходном примере, который вы причесали.
И часто, когда с таким обращаются, когда сервер БД начинает почему то адски тормозить, приходится собирать SQL запрос, или выцеплять его профайлером, потом анализировать его выполнение в инструментарии БД,
потому, что в приложении это сделать просто невозможно,
потом переписывать и отдавать заказчику, который собирает его строку из приложения и ждет очередной засады, потому, что не понимает как работает SQL сервер.
Ну ладно.
Удачи вам в работе ;)jetexe
10.02.2017 14:57Вот вам и предлагают не использовать циклы в бд. После отдачи сырых данных на сервер приложения, БД свободна (за исключением блокировок по клиенту), а циклы будут бегать на сервере приложений, где это не зло а великое благо.
VMichael
11.02.2017 00:03Да, пробегите в цикле по миллиону записей.
Посмотрите время выполнения.mayorovp
11.02.2017 07:46-1Миллион записей — как раз ерунда. Если, конечно же, это раз в день делать, а не раз в секунду.
Вот если записей десяток миллиардов — это уже проблема...
jetexe
11.02.2017 10:52+1по миллиону? да хоть на мобильном телефоне, даже не подлагнет. Самое медленное что сейчас у меня есть в проектах это база банных (UPDATE\INSERT\SELECT -в порядке скорости). Горизонтальный шардинг пока решает проблемы.
В отличии от комментаторов выше хранимки мы используем, но мало, и там где от них вреда нет. В текущем проекте они обновляют ровно одну таблицу и не требовательны к производительности
s-kozlov
07.02.2017 15:39+1У Вас жгучий сарказм, не понимаю почему минусуют.
Да это я чутка толсто потроллил. Конечно, хранимки — штука полезная. Сам их применяю, но редко. Но там должна быть только логика хранения данных, а не бизнес-логика.
Довелось мне как-то работать в проекте, которым руководил ДБАшник. Так вот там ВСЯ бизнес логика была в хранимках. На джаве была только тупая прослойка, которая дергала хранимки и отдавала данные наружу. Даже хуже: прямой доступ к таблицам и вьюшкам нам был запрещен.
Не знаю, чем бы это всё закончилось, если бы остались бабки и проект не умер.QuickJoey
07.02.2017 16:08+1Вы прямо описали мой случай. Очень удобно. По мне так джава и должна была заниматься тем, что предоставлять интерфейс к данным. А хранимые процедуры в данном случае выглядят как API к данным. Всё ж логично.
s-kozlov
07.02.2017 17:29+3Есть несколько разновидностей нарушения ответственности:
1) Программист старается спихнуть с себя ответственность в соседние слои, которыми занимаются другие люди. Мол, проблема на вашей стороне.
2) Программист тянет одеяло на себя, т.е. реализует сам максимум всего, не особо беспокоясь, насколько это разумно. Именно это произошло у нас с тем проектом: ДБАшники всем заправляли и сделали всё в базе.
Что касается бизнес-логики в базе, то у меня есть несколько возражений/вопросов против такого подхода:
1) На сервере приложений я могу использовать свой любимый (или наиболее подходящий) язык программирования, а не PL SQL с синтаксисом и прочими «прелестями» из 60-х или другой вариант из весьма ограниченного списка.
2) Как обстоит дело с горизонтальной масштабируемостью БД? С серверами приложений всё просто: поднял еще пачку при необходимости, ничего не отключая, и всё.
3) Как обстоит дело с обновлением хранимок, особенно когда у нас больше одного сервера?s-kozlov
07.02.2017 17:29И вдогонку: как там дела с тестированием и т.д.?
VMichael
07.02.2017 18:09Горизонтальная масштабируемость.
Классно звучит.
А данные вы в БД не храните?
Т.е. подняли пачку серверов для приложений и все отлично.
А серверы баз данных?
Или у вас на каждом сервере своя БД?oxidmod
07.02.2017 18:38+1ну с бд то пробелм нет, на чтение можно выставить достаточное количество реплик, чтобы распределить нагрузку. А вот на запись то мастер один и его никак не смасштабируешь, и вся логика в нем
VMichael
07.02.2017 19:45-1ну с бд то пробелм нет,
Отличная фраза.
И чего это люди парятся с этими самыми БД?
Придумали там Ораклы всякие да МС Сивелы, транзакции там, да блокировки.
Налепил реплик, и всего делов то, а?
А если вам нужно увидеть остаток по счету, а в это время в БД льются транзакции из разных мест и происходит движение денег по счетам? Тоже реплик наделаете?mayorovp
08.02.2017 08:35И в чем же проблема посмотреть остаток по счету в реплике пока его меняют в мастере?
VolCh
08.02.2017 09:26Посмотреть не проблема. Проблема посмотреть его так, чтобы к моменту когда после просмотра решили обновить, он не изменился. На мастере это относительно (так же как на единственном сервере) легко, заблокировать с реплики мастер вроде невозможно нигде и, кажется, стандартными средствами СУБД нельзя даже понять на реплике, что на мастере началась транзакция, чтобы подождать её окончания.
Bronx
14.02.2017 12:12А если вам нужно увидеть остаток по счету, а в это время в БД льются транзакции из разных мест и происходит движение денег по счетам?
Деньги на этом конкретном счёту перемещаются каждую секунду, и отчёт по остатку должен быть актуален с точностью до секунды? Или всё же допускается увидеть в отчёте «Ваш баланс по состоянию на DD/MM/YYYY hh:mm:ss»?
VolCh
08.02.2017 09:23Ну, если бизнес-логика требует, чтобы операции чтения ждали окончания операции записи, если та уже началась, то стандартные реплики не особо помогут вроде, операции блокировки по репликации вроде нигде из «большой четвёрки» не передаются, только закомиченные транзакции. На реплики обычно ложатся отчёты, для которых милисекунды мало что значат, а операционная деятельность, включая чтение типа SELECT FOR UPDATE, ведётся на мастере.
s-kozlov
08.02.2017 11:38+1Если БД занимается только данными (для чего она и предназначена), а бизнес-логику молотят app servers, то база нагружена меньше, разве нет? И я гораздо позже упрусь в необходимость горизонтального масштабирования DB master, а может вообще не упрусь.
VMichael
08.02.2017 13:57А что есть по вашему бизнес логика?
s-kozlov
08.02.2017 14:24Как-то так: https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D0%B7%D0%BD%D0%B5%D1%81-%D0%BB%D0%BE%D0%B3%D0%B8%D0%BA%D0%B0
VMichael
08.02.2017 14:40Ясно.
Поколение интернета, все в Вики.
Последний пример из бизнеса реального.
Калькулятор стоимости отправки грузоперевозчика.
Клиенту нужно рассчитать стоимость отправки.
Стоимость зависит от маршрута.
От весогабаритных характеристик груза.
От скидки клиента.
Скидка зависит от объема перевезенного в текущем месяце и объема перевезено клиентом в прошлом месяце.
Скидка зависит от оплаченных счетов клиента.
Стоимость также может зависет от наличия других заказов по этому направлению, которые консолидируются и ожидают отправки.
Все это я могу сделать в рамках одной процедуры, подтягивая запросами нужные мне данные.
Т.е. веб приложение обращается к процедуре, внутри процедуры все рассчитывается и выдает на гора ответ.
Теперь вынесите эту логику в апп сервер.
Сколько запросов вам придется оформить и отправить, для получения данных?
И каждый запрос SQL сервер будет компилировать и строить план запроса,
в то время, как хранимая процедура уже откомпилирована и план запроса сохранен для нее.
А время тикает.
И при изменении расчета, например добавилась сезонная скидка, мне нужно изменить одну, единственную процедуру и все сервисы, которым нужно знать расчет тарифа, получат его.
При этом я буду манипулировать данными с помощью языка, предназначенного для манипулирования данными, а значит эффективно.
Ну ладно.
Тут всплывают вопросы религии, споры бесполезны на такой почве.oxidmod
08.02.2017 14:55+3Ваше же пример. Скидка зависит условно от 100 параметров. Какая вермишель будет в вашей процедуре? сколько там будет ветвлений? Вы на 100% уверены что нигде не ошиблись? Ваша процедура покрыта тестами? Сколько времени вам понадобиться, чтобы спустя год чтото в этой процедуре поменять?
В случае приложения это будет набор небольших простых компонентов, которые модифицируют итоговое значение по заложеной в них логике. При требовании изменить процент скидки за предыдущие заказы на 1% нужно будет внести точечное изменение в этот один компонент, который покрыт тестами.
Да, будет больше запросов к бд, но эти запросы будут проще чем зубодробильные каскады джойнов/агрегаций и прочее. (а может и не будет их вовсе, так как к примеру общая сумма заказов клиента вполне может хранится в кеше подсчитанная после последнего заказа).
Я конечно не ДБА, но разве субд строит план запроса каждый раз? как же кеш планов?
И при изменении расчета, например добавилась сезонная скидка, мне нужно изменить одну, единственную процедуру и все сервисы, которым нужно знать расчет тарифа, получат его.
А теперь добавим пару условий когда эта скидка должна применится, кроме очевидного попадания в сезон и изменение одной процедуры становится довольно печальным
s-kozlov
09.02.2017 19:29И при изменении расчета, например добавилась сезонная скидка, мне нужно изменить одну, единственную процедуру и все сервисы, которым нужно знать расчет тарифа, получат его.
Да шо ви говорите! В базе таки себе можно переиспользовать код! А на апп-сервере уже таки и нельзя? А кто мне уполномочен это запретить?
Т.е. веб приложение обращается к процедуре, внутри процедуры все рассчитывается и выдает на гора ответ.
Ага, видел как-то отдачу HTML прямо из базы. Видимо, такие же оптимизаторы делали, которые боятся сделать лишний запрос.
А время тикает.
Дейкстры на вас не хватает, оптимизаторы блин.

sshikov
09.02.2017 19:42Попробуйте повторить в базе скажем drools. А потом сравните.
VMichael
10.02.2017 12:32-1Посмотрел, что такое drools, тут: http://www.ibm.com/developerworks/ru/library/j-drools/index.html
Тот пример, который приведен в статье, как «сложные бизнес правила», он элементарный в реализации. Вообще, не вижу проблем в реализации таких правил в процедурах БД.
Следите за мыслью, спокойно, не спешно.
Речь идет о бизнес приложениях, не беру в пример игры или еще какие то.
Приложения, которые активно работают с данными (продажи, перевозки, склады, денежные транзакции).
Чтобы обработать логику обработки данных, сначала нужно получить данные из БД.
В БД посылаются запросы.
Получив исходные данные их по некоему алгоритму изменяют, результат сохраняют в БД.
Когда правила в АПП, для этих двух операций используют обертки, орээмы, еще х.з. что, которые в итоге делают запросы в БД в виде нативного запроса в БД (другие запросы БД не поймет, на выходе всей этой радости — нативные запросы в БД).
Когда это в процедурах БД, это все делается сразу нативными запросами в БД.
Полученные данные обрабатываются в процедуре и далее сразу нативными запросами в БД сохраняется.
Все. Без оберток, ореэмов и прочих методов.
А бизнес логика в виде «если — то», какая хрен разница на каком языке напечатаны эти операторы?
То, что программисты некоторые не понимают язык множеств, на котором оперируют реляционные БД и поэтому им некомфортно работать с БД, ну это да, проблема некоторых программистов.
Есть приложения, на которых удобнее делать все в приложении, наверняка, с этим вопросом не спорю.
Но говорить, что бизнес-логика в БД, это боль для всех случаев, очевидная глупость.
Некоторое отвлечение.
В бытность мою начальником управления программного обеспечения, мы рассматривали различные варианты реализации.
Устраивали сравнения и соревнования.
В 100% случаев реализация БД в приложениях (для наших задач, примеры я приводил тут в комментариях) по скорости разработки и скорости внесения изменений проигрывала.
У меня не было и нет предпочтений, какие технологии использовать, какие компоненты выбирать.
Когда программисты начинали спорить, какой путь лучше и мне было не очевидно, я говорил, не вопрос.
Вот задача, делайте.
Посмотрим, что лучше.
Обычно после реализации становилось очевидно.
Могу я быть конечно упоротым апологетом, но я работал во многих организациях, не везде руководителем, где очень разумные люди пришли к тому же подходу.
Приходят люди на собеседовании, и говорят, да вы что, ведь лучше же так.
Если человек, по общению разумный, говоришь ему, хорошо, не вопрос, вот вам машина, реализуйте некую простую вещь, покажите, как это классно.
Затраты времени в разы больше, а порой на порядки.
Увы.sshikov
10.02.2017 13:23Давайте начнем с простого. Понятно что бизнес логику в базе вообще делать можно — это очевидно. Делают же. И даже иногда легко — при одном простом условии, что она работает с данными внутри базы. И при этих же условиях обычно будет довольно быстро.
У логики в базе просто есть явные и довольно сильные ограничения, связанные с интеграцией вовне. Я их уже в другом комменте подробно излагал, и не вижу, чтобы это вызвало сильные возражения, так что не стану повторяться.
Ну т.е. для меня лично слова про боль и страдания — они как правило верны именно в этих случаях, когда вы не можете остаться внутри базы, и вынуждены интегрироваться.
michael_vostrikov
10.02.2017 13:23Когда правила в АПП, для этих двух операций используют обертки, орээмы, еще х.з что
Орээмы делаются не для выполнения операций, а для организации кода. Чтобы можно было работать с 10 объектами, в которых по 10 связанных с ними методов, а не с 10 массивами и 100 процедурами.
Когда это в процедурах БД, это все делается сразу нативными запросами в БД.
Когда логика в приложении, в базу идут только простые запросы вида SELECT/INSERT/UPDATE/DELETE, которые можно сгенерировать автоматически.
Когда логика в базе, в базу идут сложные запросы вида "SELECT some_function(...)", где some_function имеет произвольное имя и произвольное количество параметров, и все это надо прописывать вручную, и которые помимо этого сами посылают простые запросы вида SELECT/INSERT/UPDATE/DELETE. И семантика не очень, когда для внесения изменений надо делать "SELECT".
В 100% случаев реализация БД в приложениях (для наших задач, примеры я приводил тут в комментариях) по скорости разработки и скорости внесения изменений проигрывала.
Естественно, если рассматривать толстый десктопный клиент с логином в БД, то вносить изменения будет проще в базу. А вот тонкий десктопный клиент с подключением к серверному приложению, тут уже не так все однозначно.
говоришь ему, хорошо, не вопрос, вот вам машина, реализуйте некую простую вещь, покажите, как это классно. Затраты времени в разы больше, а порой на порядки.
А вот скажите и нам тоже. Только не в общих словах, а конкретную задачу с конкретными требованиями, по которой можно построить прототип. Вот и оценим затраты.
VolCh
12.02.2017 14:43Орээмы делаются не для выполнения операций, а для организации кода. Чтобы можно было работать с 10 объектами, в которых по 10 связанных с ними методов, а не с 10 массивами и 100 процедурами.
Орээмы делаются для изоляции объектной модели от базы данных. Чтобы не писать вручную скул запросы, а потом не пеобразовывать из результаты в обхекты и наоброт.michael_vostrikov
12.02.2017 15:15Согласен, это просто другая сторона. Я имел в виду, что "когда правила в АПП", то ORM применяются не "для этих двух операций", а по другой причине. Потому что эти операции можно и без них сделать.
sshikov
10.02.2017 13:26Да, суть drools конечно же не в таком примере, как обычно приводят. А в том, что правила а) отдельно от кода, в том числе в базе б) имеют доступ к справочным данным, как из базы, так и где-то еще (веб сервис) в) пишутся более чем на одном гибком языке.
Я даже верю, что на PL/SQL можно написать аналог Business Rules Engine — но дело в том, что как правило это выйдет настолько непрактично, что этим будет невозможно пользоваться.
VolCh
12.02.2017 14:41А бизнес логика в виде «если — то», какая хрен разница на каком языке напечатаны эти операторы?
В теории — никакой. На практике для тех или иных видов логики одни языки гораздо удобнее других.
Все. Без оберток, ореэмов и прочих методов.
Вот только логика почти вся на реляционной модели построена. Как показывает практика, обычно бизнес ставит задачи, оперируя терминами которые гораздо лучше ложатся на объектную модель, которая если в РСУБД и есть, то сбоку к реляционной пришита. Не будет бизнес ставить задачу в терминах реляций и кортежей, таблиц и строк, а вот в терминах сущностей и операций над ними — вполне.
Но говорить, что бизнес-логика в БД, это боль для всех случаев, очевидная глупость.
Обычно, когда так говорят, имеют в виду, что боль — это процесс разработки, особенно итеративной, ну и поддержки. Ну нет ещё для SQL РСУБД инструментов разработки сравнимых по удобству с современными инструментами для классических ЯП. Каждый раз матерюсь, когда нужно менять логику, которую был вынужден помещать в БД по соображениям быстродействия или большой сложности реализации другими путями. Более-менее нормально только добавлять что-то новое линейно. Изменения, особенно на нижних уровнях зависимостей — боль, проще для новой задачи повторить с небольшими модификациями нужные зависимости старой, чем немного их и старую задачу поправить. Банально переименовать процедуру в одной схеме, используемую в десятке мест, когда имеется такая же в другой, но используемая в сотне мест — куча ручной работы, автоматических инструментов либо нет, либо за ними вычищать дольше, чем вручную сделать.
В 100% случаев реализация БД в приложениях (для наших задач, примеры я приводил тут в комментариях) по скорости разработки и скорости внесения изменений проигрывала.
Ну, реализовывать БД в приложениях, конечно, не очень разумная идея. Данные в базах, логика в приложении. Если данные из базы попадают в приложение в адаптированном для приложении виде, теряя по дороге свою реляционную природу (да, я про ОРМ), а не программист либо адаптирует вручную, либо так и работает с реляцонными в непредусмотренной для этого среде, то непонятно в чём затык.
Fesor
09.02.2017 19:56+2Сколько запросов вам придется оформить и отправить, для получения данных?
Вообще-то столько же сколько и вам. Просто появляется намного больше пространства для маневра в плане архитектуры приложения. Так же если логика реально сложная мы снижаем стоимость введение нового разработчика и в целом увеличиваем поддерживаемость системы.
И каждый запрос SQL сервер будет компилировать и строить план запроса,
в то время, как хранимая процедура уже откомпилирована и план запроса сохранен для нее.план запросов хэшируется вне зависимости от того был ли это просто запрос или он выполнен их хранимки (во всяком случае в postgresql) и это логично. Что до разбора запроса — это занимает настолько мало времени что в целом им можно пренебречь.
А время тикает.
и вот тут в дело вступает возможност делать запросы паралельно. Например такие параметры как:
- стоимость маршрута
- весогабаритные характеристики груза
- объем перевезенных грузов с агрегацией по календарным месяцам
- проверяем статус других заказов которые ожидают отправки
мы можем произвести все эти операции одновременно так как они не зависят между собой. Далее мы просто в скриптике за миллисекунду что-то вычисляем и вперед.
А еще есть кэширование на стороне приложения и другие веселые радости. Ну или может нам для расчета маршрута надо по графу пройтись и тут проще вынести это добро в отдельную базу.
VolCh
08.02.2017 14:27Если БД занимается только данными (для чего она и предназначена)
Глядя на средства, предоставляемые современными SQL СУБД, я бы уже не говорил так уверенно для чего они предназначены. Мощные языки описания процедур, триггеров и т. д., как встроенные, так и с возможностью подключать языки общего назначения типа Python или C#mayorovp
08.02.2017 14:30+1Увы, но возможность подключения языков общего назначения зачастую преувеличена. То нельзя, это нельзя, сюда не ходи...
Например, в MS SQL Server внешнюю функцию нельзя использовать в качестве первичного ключа в индексированном представлении.
VolCh
08.02.2017 14:38«Мы работаем над этим» :) А если серьезно, то налицо, по-моему, желание производителей чтобы их клиенты пользовались СУБД не только как быстрыми и надежными хранилищами данных, но и запихивали в них бизнес-логику.
sshikov
10.02.2017 10:34Понимаете какая штука… Производители могут этого сколько угодно хотеть, но чтобы это реально свершилось, нужно чтобы СУБД имела внутри что-то типа контейнера для приложений. Ну примерно как JavaEE. Или как Hadoop с его YARN.
И чтобы контейнер этот управлял ресурсами, которые может потребить хранимая процедура aka приложение. А иначе криво написанная процедура на .Net выжрет всю память, займет все ядра процессора ненужной фигней, залочит какие-то нужные всем прочие ресурсы, и все к черту сломает.
Вот такого внутри баз данных пока нет. И пока этого нет — они могут и дальше продолжать над этим работать, но приложения все равно будет проще разворачивать снаружи.
Busla
09.02.2017 13:35-1То, что вы пишите — это оксюморон. Причём дважды.
VolCh
09.02.2017 13:52+1Доводы?
Busla
10.02.2017 16:31Первичный ключ традиционно определяет способ хранения — физический порядок размещения данных. В свою очередь функция предполагает динамическую природу: сегодня один порядок, завтра — другой; а представление не хранится.
mayorovp
10.02.2017 17:18Поздравляю вас с выходом из криосна!
Busla
11.02.2017 00:48Спасибо!
Если я что-то опустил, подскажите: что такого делает первичный индекс, что не может «обычный»?mayorovp
11.02.2017 07:39Первичный ключ (точнее — кластерный индекс, но обычно это одно и то же) делает представление, собственно, индексированным. Пока в представления не создан первичный ключ — на него нельзя вешать другие индексы.
QuickJoey
16.02.2017 10:12Далеко не обычно. В больших таблицах кластерный индекс (например по дате операции) ещё и определяет схему секционирования (в MSSQL). И никак не связан с первичным ключём, который определяет уникальность записи.
mayorovp
16.02.2017 10:48+1Вы привели достаточно редкую ситуацию. Если сделать запрос
create table (id primary key)— то индекс по первичному ключу будет кластерным. Это — поведение по умолчанию.
Пожалуйста, не придирайтесь к словам. Кластерный индекс — специфичное для MS SQL понятие, вот я его и заменил на более понятное тем, кто работает с другими СУБД, рассчитывая что специалисты по MS SQL поймут что я имел в виду.
VMichael
11.02.2017 02:17Не совсем верно.
Первичный ключ определяет уникальность записи, потому он и ключ.
Порядок хранения определяет кластерный индекс, если он есть (для MS SQL).
Как использовать внешнюю функцию в качестве первичного ключа?
Могу понять, когда с помощью внешней функции вычисляется ключ при сохранении, редактировании записи и потом записывается в поле, служащее первичным ключом.
Не могу понять, как (и для чего) нужно делать изменяющийся динамически первичный ключ.
Если меняется ключ, определяющий уникальность записи, придется пересчитывать ключи каждой записи и перестраивать индекс.
Тяжелая операция.
Если делать это при выборке — прощай производительность.
Мало мальски большой набор записей и вы будете часами ждать окончания вашей выборки.
Fesor
09.02.2017 15:36ох уж эти извечные холивары между DBA и бэкэндщиками...
VMichael
10.02.2017 12:11Замечено (мною), что холивары возникают там, где вопрос не однозначен.
Я говорю, может быть и привожу примеры бизнес логики, легко реализуемые в БД и быстро работающие.
Мне в ответ, нет, только в АПП и нигде больше, в БД это боль, но не привели ни одного примера бизнес привил, которые можно реализовать в АПП и нигде больше.
P\S: DBA это не разработчик БД, это администратор БД, это разные роли и функции.Fesor
10.02.2017 12:57но не привели ни одного примера бизнес привил, которые можно реализовать в АПП и нигде больше.
категоричность это не очень хорошо, согласен. Для хранимых процедур есть вполне валидные сценарии.
Но все сводится к банальной экономике. С точки зрения скорости разработки, стоимости поддержки и расширяемости решений процедурки выходят дороже. Вот и весь спор. Не говоря уже о таких вещах когда простой расчет стоимости или каких-то скидок не выйдет сделать на CPU за необходимое время (CUDA). Например у меня недавно приходил реквест на разработку системы, которая на основе координат точек рассчитывает необходимое количество материала. Материал и все параметры хранятся в базе но считать все в базе будет слишком сложно.
VMichael
10.02.2017 13:11С точки зрения скорости разработки, стоимости поддержки и расширяемости решений процедурки выходят дороже.
Мой опыт, говорит обратное.
Например у меня недавно приходил реквест на разработку системы, которая на основе координат точек рассчитывает необходимое количество материала. Материал и все параметры хранятся в базе но считать все в базе будет слишком сложно
Вполне допускаю, хотя не знаю подробностей, что данную задачу лучше считать в приложении.Fesor
10.02.2017 13:41+2Мой опыт, говорит обратное.
А мой опыт говорит что хранимки это скорее исключение из правил. Когда есть специфические требования например связанные с безопасностью данных.
Когда подобные вещи лежат в хранимках вы полностью завязываетесь на инфраструктуре и это лишает вас гибкости. Да, в подавляющем большинстве случаев это ок, но и плюсы от хранимок в подавляющем большинстве случаев не столь значительны.
Ну и в целом из моего опыт найти разработчиков с вашим опытом работы с базами данных весьма и весьма сложно. Не говоря про стоимость разработчиков которые смогут это нормально организовать.
В целом спор выходит пустым. Мое мнение — впадать в крайности не очень хорошо. Хранимые процедуры лишь один из вариантов как делать дела и брать этот вариант по умолчанию так себе идея. Точно так же как никогда не допускать использования хранимок.
QuickJoey
07.02.2017 19:00Всё-таки не любят веб-программисты SQL, замечал уже не раз, без обид.
Вроде бы логично использовать для манипуляциями с данными, язык, специально для этого предназначенный.
Что мешает горизонтально масштабировать сервера БД?
И с обновлением процедур примерно так же, если есть репликация, например master-slave.s-kozlov
08.02.2017 11:42> Что мешает горизонтально масштабировать сервера БД?
Не подскажете, как это безболезненно сделать на PostgreSQL? Допустим, у нас есть один сервер БД, нужно подключить slave и асинхронно реплицировать. Как это сделать, не выключая master? Вы бы нам очень помогли.QuickJoey
08.02.2017 16:24Допустим, у нас есть один сервер БД, нужно подключить slave и асинхронно реплицировать. Как это сделать, не выключая master?
Не знаю, таких задач у меня пока не было. Только по-моему, сервер приложений гораздо быстрее положит сервер БД, и вам всё равно его придётся масштабировать.
Вообще глядя на две длинные ветки обсуждения, я для себя сделал вывод, что хороши оба подхода, вместе, а не по отдельности. Потому что то, что генерят некоторые ORM не лезет ни в какие ворота.mayorovp
08.02.2017 16:51Потому что то, что генерят некоторые ORM не лезет ни в какие ворота.
Открою вам еще один секрет :)
ORM генерируют запросы не из вредности — а потому что им на вход запрос пришел. И то, что подается ORM на вход, обычно точно так же поддается оптимизации.
Хотя, конечно же, ее пределы более ограничены нежели пределы оптимизации SQL-запросов.
s-kozlov
09.02.2017 19:41-1ORM генерит говно, потому что построена на насквозь дырявой абстракции. Причем абстракции там бывают очень и очень толстые, обобщая всё настолько, что эффективно работают, по сути, только очень простые запросы.
Знаете, что делает этот метод? Достает объекты из базы только для того, чтобы потом их удалить.sshikov
09.02.2017 21:15Кто вам сказал, что достает? По вашей ссылке этого не написано.
s-kozlov
10.02.2017 07:24Кто вам сказал, что достает?
Опыт :-(sshikov
10.02.2017 10:26Ну, опыт… Мне вот опыт говорит, что по вашей ссылке вообще интерфейс, и он ничего доставать или не доставать не может — по определению )))
А если реально — то когда метод delete что-то достает из базы, прежде чем это удалить — это тривиально баг. Абстракции тут не при чем, ни дырявые, ни какие либо другие.
Я согласен, что ORM может такие абстракции содержать, по разным причинам — но данный пример кажется неудачным.mayorovp
10.02.2017 10:44Не совсем так. Тут не баг реализации — а принципиальное ограничение архитектуры, и интерфейс его хорошо иллюстрирует.
Посмотрите что метод принимает — он принимает последовательность объектов. Именно поэтому и говорится, что в ORM перед удалением записи ее надо сначала вытянуть из базы. Если не вытянуть — то и передавать в
deleteбудет нечего.
Обходные пути, конечно же, существуют. Если известные первичные ключи объектов — можно создать "пустышки", присоединить их к контексту ORM — а потом удалить.
И еще всегда можно сделать "сырой" SQL-запрос к базе.
sshikov
10.02.2017 11:04Да нету тут никаких ограничений архитектуры, о чем вы?
void delete(ID id) вот вам метод удаления по id, он на пол-страницы выше.
а то о чем вы толкуете — это метод для удаления сущностей, которые вы уже ранее загрузили.
Зачем вы их загрузили — это ваше дело, например чтобы показать пользователю, который нажмет кнопку Del.
При чем тут архитектура, если вы невнимательно изучили список методов?s-kozlov
10.02.2017 11:10void delete(ID id) вот вам метод удаления по id, он на пол-страницы выше.
Ниже ответил насчет этого метода.
s-kozlov
10.02.2017 11:06-1Блин, сорри, не тот метод привел в пример. Вот: SimpleJpaRepository#delete(ID)
s-kozlov
10.02.2017 11:04ОК, не интерфейс, а http://docs.spring.io/spring-data/jpa/docs/current/api/org/springframework/data/jpa/repository/support/SimpleJpaRepository.html
А смотреть лучше исходники, а не джавадоки. Код врать не будет.sshikov
10.02.2017 11:06Ну и вам тоже повторю:
void delete(ID id)
пользуйтесь этим, если у вас есть id, и вам не нужно смотреть на данные, прежде чем их удалять. Делать какие-то выводы из того, что есть еще и другой метод, довольно странно.s-kozlov
10.02.2017 11:09А вы видели, как SimpleJpaRepository реализует этот метод? Я видел.
А еще можно глянуть там же на исходники deleteAllmayorovp
10.02.2017 11:12Блин, приведите уже ссылку на исходники! Нам не интересно гуглить всякую фигню.
sshikov
10.02.2017 11:25Я уже ответил сразу, что я думаю по этому поводу. Это не проблема архитектуры — тут ее нет. Если генерируется что-то отличное от тупого DELETE — то это баг реализации.
Если у вас есть id, и вы знаете маппинг полей объекта на колонки таблицы — то вы можете сгенерировать просто DELETE. Тут нет никаких текущих абстракций в этом месте.
Если же вы о чем-то другом — то давайте уточним, о чем конкретно?s-kozlov
10.02.2017 11:28Если у вас есть id, и вы знаете маппинг полей объекта на колонки таблицы — то вы можете сгенерировать просто DELETE. Тут нет никаких текущий абстракций в этом месте.
У них там толстые абстрации и неуемное желание переиспользовать существующий код, пусть и ценой огромных потерь производительности.sshikov
10.02.2017 11:38Не, ну если вы про этот конкретный код — то никаких вопросов и нет. Я не до конца понимаю, почему тут сделано так, но в целом с вашими выводами согласен. Просто это не относится к ORM по сути — а только к конкретной реализации.
s-kozlov
08.02.2017 14:25+1Всё-таки не любят веб-программисты SQL
Я «люблю» SQL, но «не люблю» PL SQL.
VMichael
07.02.2017 16:43Работал с не одним проектом с такой логикой.
Все отлично работают и развиваются.
Такая архитектура довольно таки распространена среди бизнес приложений.
В одной из контор было десктопное приложение.
Потом понадобилось сделать веб морду к нему.
Да вообще, не вопрос.
Процедуры уже готовы, нарисовали клиента и вперед.
Изменилась логика (например правила расчета тарифа), изменили процедуру, клиенты (десктоп и веб, вообще трогать не нужно.
Мир разнообразен, разные подходы существуют.michael_vostrikov
07.02.2017 16:50С приложением на сервере будет точно так же. Изменили код расчета на сервере, а клиенты, которые к нему коннектятся, менять не надо. Только можно использовать ООП, внешние библиотеки, систему контроля версий, и другие полезные вещи типа пошаговой отладки.
oxidmod
07.02.2017 16:51Чем изменили процедуру отличается от изменили код в API?
VolCh
08.02.2017 09:31+1Для изменения кода на апп-серверах создано множество отличных инструментов, полноценных аналогов которых для серверов БД нет. По крайней мере бесплатных или близких к тому, порядка сотни долларов за год.
sshikov
09.02.2017 19:38+3Давайте я попробую рассказать.
Итак, для начала — есть случаи, когда разных типов баз много. В этом случае вариант логики в хранимках воообще практически отпадает, потому что написать что-то одинаковое не на чем, а написать три-четыре разных варианта для оракла, ms sql и postgresql — неподъемная задача.
Во-вторых, берем скажем MS SQL для определенности. Натыкаемся на то, что T-SQL как язык разработки достаточно примитивен, если не сказать прямо убог.
Ну например, из функций вообще ничего делать нельзя, из процедур можно — но скажем набор возвращаемых процедурой типов данных весьма ограничен (по сути — сводится к таблицам). Если мне нужно что-то более сложное — скажем дерево, то все, капец.
Вернуть из процедуры что-либо нетривиальное — боль и страдания. Передать в нее что-то нетривиальное — боль и страдания. Посмотрите для примера, во что выливается разбор JSON в T-SQL — для этого просто нет приличных слов.
Дальше — если из приложения я могу развернуть наружу скажем веб-сервисы, как RESTJson, так и например SOAP, или слушать сокеты и работать по TCP/IP, или webcocket, например, или поднять полноценный web сервер и отдавать html, и сделать web GUI, или если очень нужно, отдавать наружу какую-нибудь Corba — то попробуйте сделать это внутри T-SQL. У вас либо просто нифига не выйдет, либо вы будете вынуждены деплоить процедуры на .Net, что само по себе боль и страдания.
В случае оракла все чуть-чуть легче, потому что внутри базы живет JVM, и можно что-то написать на Java — но опять же, это боль и страдания — потому что преимущества дает весьма сомнительные, и сделать все тоже самое вне базы обычно намного проще.
Ну и последнее, уже озвученное — как правило, языки разработки вне базы намного более продвинутые и удобные, нежели те, что встроены в СУБД. Это не факт — это больше чем факт, так оно и было на самом деле (с)VMichael
12.02.2017 12:41-1О, нашелся наконец человек, который смог " на пальцах" объяснить свое понимание.
Итак, поясню терминологию.
Схема следующая.
Есть данные, хранящиеся в БД.
На самом деле, это ценность для бизнеса.
Есть логика обработки данных.
Это один блок.
Есть механизмы передачи данных (входных или выходных, с обработками между ними) — веб сервисы, TCP/IP, SOAP и прочее и прочее.
Это второй блок.
Есть механизмы ввода данных или результатов обработки для пользователя html, web GUI, декстопные приложения.
Это третий блок.
Никто (я) не предлагает делать второй и третий блоки в БД. Это ерунда какая то.
В БД лежат данные и правила работы с данными (процедуры).
Абстрагируйтесь от своих сокетов и джава машин.
Посмотрите для чего все это?
Мне видится, для того, что бы взять, обработать, сохранить и затем выбрать, передать, отобразить некие данные до пользователя.
Ключ ко всему данные.
Вы можете важные данные (например вашего счета в банке) донести на бумажке, написанные ручкой или фото бумажное показать.
Без всякой интернет лабуды.
Данные, основа бизнес приложений.
А дальше навешиваются интерфейсы передачи данных, отображения и прочее.
Но работа с данными мне видится логичнее в БД.
И, замечу, не просто видится, а есть успешно реализованные проекты, поддерживаемые замечу не мной одним, а командами программистов независимых от меня, что подтверждает мое мнение.
А если вы пытаетесь средствами БД делать вещи, для БД не предназначенные, конечно получите боль и весь сопутствующий геморрой.
sshikov
12.02.2017 14:32>Никто (я) не предлагает делать второй и третий блоки в БД. Это ерунда какая то.
Не, ну это я надеюсь мы все понимаем одинаково. Моя мысль заключалась скорее в том, если мы уже делаем что-то (обычно эта штука называется сервер приложений) для взаимодействия и пр., то сделать там же и бизнес логику обычно является логичным решением. И там как правило удобнее.
Что же до данных — то вы попробуйте тоже абстрагироваться от своего видения, и представить, что данные изначально бывают и не в базе, и возможно никогда туда не попадают вообще. А живут в виде сообщений где-нибудь в шине, где и логичнее их обрабатывать. Не говоря уже о том, что бывают базы и других видов, отличных от оракла, где просто не на чем писать бизнес логику вообще.
И опять же, главная мысль была в том, что вне базы для обработки обычно намного больше всяких хороших вариантов.
VolCh
12.02.2017 15:13-1Вы можете важные данные (например вашего счета в банке) донести на бумажке, написанные ручкой или фото бумажное показать.
Без всякой интернет лабуды.
Данные, основа бизнес приложений.
Противоречите сами себе. Основа бизнес-приложений — это логика обработки данных. Данные могут быть в базе, в обычных файлах, на веб-сервисах, на бумажках и т. п. Бизнес-логика их обработки не должна зависеть от формы их хранения. То же начисление процентов — вполне можно представить приложение, в котором ночью люди сначала инсталлируют софт на машину, потом достают карточки счетов, вводят в формы всех операции по счёту, получают результат начисления, записывают его в карточку, а потом форматируют машину. Зачем мне размещать логику начисления в базе в таком случае? Я размещаю её в приложении и пишу адаптеры для всяких разных источников данных, включая базы. Завтра придёт директор и скажет, что хранить в своей базе слишком дорого (трехкратное резервирование, пять стратегий резервного копирования, 24/7 дежурство персонала) и он нашел облако, которое все дешево хранит и отдает по рест-лайк интерфейсу. Я просто напишу новый адаптер. Перехожу с MySQL на PostgreSQL — даже писать не надо, просто заменю один чужой адаптер на другой чужой. Вот, кстати, уже больше чем на год у нас затянулся переход с MySQL на PostgreSQL — бизнес-логика от базы независима, но вот отчёты писались на raw SQL и их логику никто объяснить не может, а единственный кто может её разобрать — я. Ни того, кто ставил задачу нет уже в нашей фирме, ни того, кто реализовывал, но отчётами все пользуются. Но у меня в работе куча прямых бизнес-задач — новая функциональность, адаптация под оптимизированные бизнес-процессы и изменяющееся законодательство и т. д. и просто нет времени разбираться в логике, реализованной на MySQL и переносить её на PostgreSQL. И это просто SELECT запросы по сути, а не процедуры. Но в MySQL нет оконных функций, но есть пользовательские переменные в SQL, а в Postgres наоборот.VMichael
12.02.2017 17:00+1Хорошо, бог с вами, реализуйте логику, где вам удобно.
По вашим сообщениям, как мне показалось, у вас некоторые проблемы с организацией разработки.
1. Переключатся по десять раз на дню, в разные (по времени) версии ПО и БД и что то там дописывать, потом сливать, странно. Приходит в голову, что вы поддерживаете десятки различных версий одной программы, возможно для различных клиентов. Ваша программа разрослась десятком версий, при таком варианте очень сложно поддерживать архитектуру.
2. Необходимость постоянно переименовывать процедуры в БД. Там, где я работал, это крайне редкая операция. Если вы постоянно вынужденны заниматься таким, что то не так с проектированием.
3. На вас лично навешено много всего, у вас нехватка ресурсов времени, это обычно приводит к невозможности продумать архитектуру, что приводит к пунктам 1 и 2 выше.
4. Если проект затянулся на год, он не проект, а хотелка без ресурсов. Значит у него нет заказчика, готового за него платить. Закройте такой проект и не отвлекайтесь на него.
.
Кроме того, есть некоторая противоречивость в примерах.
Перехожу с MySQL на PostgreSQL — даже писать не надо, просто заменю один чужой адаптер на другой чужой.
И тут же:уже больше чем на год у нас затянулся переход с MySQL на PostgreSQL
Оконные функции и прочие примочки, обычно применяют, что бы вытянуть производительность.
Может статься, что в приложении у вас это не выйдет. Отчеты — страшная сила.
Это часто бывает.
Вот все классно, но отчеты, зараза, не желают почему то быстро работать.
Все, все.
Не буду больше раздражать просвещенную публику, удалюсь в свою СУБД :)VolCh
12.02.2017 19:191. Переключатся по десять раз на дню, в разные (по времени) версии ПО и БД и что то там дописывать, потом сливать, странно. Приходит в голову, что вы поддерживаете десятки различных версий одной программы, возможно для различных клиентов. Ваша программа разрослась десятком версий, при таком варианте очень сложно поддерживать архитектуру.
Нет, программа одна для одного заказчика. Задач в работе может быть несколько. Ну и принимаю задачи от всех остальных разработчиков. Сначала проверить задачу в его ветке, потом слить её в общую ветку, потом проверить что общая осталась рабатоспособной.
Необходимость постоянно переименовывать процедуры в БД. Там, где я работал, это крайне редкая операция. Если вы постоянно вынужденны заниматься таким, что то не так с проектированием.
Мелкий рефакторинг неотъемлемая часть разработки у меня. А переименование одна из частых процедур в рефакторинге.
Если проект затянулся на год, он не проект, а хотелка без ресурсов. Значит у него нет заказчика, готового за него платить. Закройте такой проект и не отвлекайтесь на него.
Проекту 6 лет, переход на Постгрес — лишь одна из задач в нём.
Кроме того, есть некоторая противоречивость в примерах.
Нет противоречивости. Там, где логика расчётов осталась в приложении, там переход не составляет практически никаких проблем, просто переключить адаптер и несколько строк подправить, там, где использовали специфичные для мускуля фичи типа CAST AS UNSIGNED в сортировке, а в Postgres надо AS INTEGER. Там, где логика перенесена на сторону СУБД — начинаются проблемы.
Fesor
12.02.2017 20:37И, замечу, не просто видится, а есть успешно реализованные проекты, поддерживаемые замечу не мной одним, а командами программистов независимых от меня, что подтверждает мое мнение.
Если вам удобно и команде которая поддерживает ваши решения тоже удобно — значит все хорошо. Но опять же интересна специфика проектов. Предметная область. Нагрузки и количество данных. В целом ваш подход весьма интересен и я бы хотел хоть одним глазком глянуть на подобный проект, для расширения кругозора скажем. Но вот вам мои мысли исходя из моего опыта.
Есть данные, хранящиеся в БД.
На самом деле, это ценность для бизнеса.
…
Данные, основа бизнес приложений.
Ключ ко всему данные.Несомненно данные важны, но они бесполезны без некой логики обработки этих самых данных. И вот это уже представляет основную ценность для бизнеса. А как вы это реализуете — бизнесу плевать. Гдавное что бы это работало, работало стабильно, и реализация позволяла относительно быстро вносить изменения. И вот тут самое интересное.
В БД лежат данные и правила работы с данными (процедуры).
В моем представлении "процедуры" имеют доступ ко всем данным, то есть данные как бы лежат в глобальной области видимости. Глобальное состояние. Меня интересует как вы подходите к изоляции данных для процедур и изоляции сайд эффектов. К примеру.
У нас есть данные и процедуры для работы с этими данными. Данные лежат отдельно, процедуры — отдельно. То есть старое доброе процедурное программирование. Данные для процедур доступны глобально, так что любая процедура может в любой момент времени что-то сделать. Есть ли у вас тут какая-то изоляция? Ибо подавляющее большинство разработчиков на проекте больше среднего уже скорее всего превратят все в кашу и отследить что кто меняет уже будет мягко скажем затруднительно.
И еще момент. У нас есть какие-то данные и есть инварианты этих данных. Далеко не все инварианты можно покрыть средствами которые дает SQL (хотя тут возможно отсутствие опыта играет свою роль). Можете чуть объяснить как вы проверяете например такие вещи как "пользователь не может купить продуктов более чем на 120% от покупок за предыдущий календарный месяц"? Ну то есть… вы делаете для этого отдельную процедуру? или проверку на тригеры вешаете? Как вы поступаете?
VMichael
12.02.2017 21:25Могу привести в пример два проекта.
ИТ система крупного логистического оператора (доставка от двери до двери, складское хранение грузов), входит в тройку крупных на рынке России.
В системе крутится вся деятельность компании за исключение кадров и бухгалтерии
У компании 60 филиалов.
Обмен данными репликация мерж, с динамической фильтрацией.
По объему данных.
5 лет назад в день вводилось до 60 000 накладных об отправках, содержавших n-позиций грузов.
До 6000 заказов в день на услуги курьеров (пеших и авто).
Учет клиентов.
Прием заказов.
Расчет тарифов.
Учет маршрутной сети.
Автоматизированное распределение заказов по курьерам, по маршрутов.
Отслеживание движения грузов/отправлений путем сканирования штрих кодов.
Складские операции. Прием, комплектация, хранение, отгрузка.
Пересыл авиа, авто, жд. транспортом.
Выставление счетов.
Учет оплаты.
Обмен данными с 1С.
Сайт. Калькулятор (это не сложно, расчет тарифов уже есть). Личный кабинет клиента.
Клиентское приложение, скачиваемое с сайта, позволяющее клиенту самому формировать накладные на отправку и обмен данными с системой компании (на 5 лет назад 250 инсталляций).
Обмен данными с ИТ системами клиентов/партнеров (несколько сотен интеграций).
Посещаемость до 100 тыс. уников в день.
И конечно туча различной отчетности, без которой отделы компании не могут жить.
БД MS SQL сервер.
Клиент десктоп на Дельфях.
Веб PHP Zend.
Объем базы в ГБ не помню уже. Меньше терабайта точно.
Команда разработчиков (5 лет назад) — 2 базовика (включая начальство), 4 дельфиста (включая начальство) (все умеют работать с БД), тестировщик, веб программист.
ИТ система банка (тут я не архитектор был, просто разработчик).
Объем базы около 2 ТБ.
Ядро системы создавалось гениальными программистами (на мой взгляд конечно).
Реализован документооборот с правилами продвижения документов по маршруту.
Изначально была на интербейс, затем перевели на MS SQL.
Данные о числе клиентов, подключений, уникальных посетителей не скажу, моя роль тут другая уже была, общую статистику не смотрел.
Сильный крен в сторону безопасности.
Тут уже средствами СУБД было сделано предоставление прав на каждую процедуру и контроль прав.
Доступ из приложения строго через процедуры.
Число разработчиков порядка 30 человек.
В обоих случая для процедур данные доступны глобально.
Есть логическое именование процедур, префиксы определяют область работы процедуры.
В банковской системе процедур порядка 5 000.
В обоих системах логирование запросов.
В обоих случаях перед развертывание версии есть тестирование (в банке многоуровневое). с ревью кодом.
В кашу не превратили.
В обоих случаях процедуры хранятся в виде файлов в системе контроля версий, и отследить, кто что внес легко.
Т.е. схема работы следующая:
Нужно изменить процедуру — создаешь ветку, берешь процедуру, работаешь с ней, коммитишь.
Также как и с обычным кодом.
В случае с банком обновления идут через специальное ПО, пакетами.
И кто, что добавил в пакет, тоже логируется.
Ваш пример, очень простой.
Как вы в приложении определяете сумму покупок за прошлый месяц?
Вы посылаете запрос в базу.
Вопрос на каком этапе вы желаете сделать данную проверку.
В момент сохранения заказа, в момент логирования клиента или еще когда.
Если данное условие ни счем не связано, создам отдельную процедуру, которая вернет мне сумму заказов за прошлый месяц (можно функцию).
Что для этого сделать, проссумировать заказы за прошлый месяц или взять сохраненные данные из регистра, не суть.
Вариант выдать уже готовый ответ «Да/нет». Зависит от общей логики.
Что еще.
Об изоляции.
Процедуры сами по себе ничего не делают.
Так же вы можете вызывать SQL код из вашего приложения, который сделает из ваших данных кашу.
Тут не вижу разницы.
Более того.
На каждую процедуру можно навесить правила доступа (что я видел в банковском приложении).
А вот когда вы вызываете SQL запросы из приложения, контролировать правила доступа труднее.
Т.е. если вы дали приложению права на исполнение SQL запросов, запросы практически могут быть любыми.
Ну, как то так.
Не говоря уже об удобстве отладки SQL запросов в специально предназначенной для этого среде.
Я смотрел построители запросов в различных средах.
Это немного убого, по сравнению с иструментарием MS SQL.
С Ораклом работал давно и мало.
У Оракла синтаксис менее лаконичный, что после Transact SQL несколько раздражает (чур не пинать, если народу нравится, то так оно и есть, чудесный синтаксис :)).QuickJoey
16.02.2017 10:23Вот, очень похоже на то, как я себе вижу логику работы и разработки. Всё логично.
VMichael
12.02.2017 12:49P\S: Да, если вы разрабатываете универсальное приложение, которое должно работать с любой СУБД, вам может быть выгоднее все операции с данными генерировать внутри вашего приложения.
При этом вам приходится жертвовать особенностями работы каждой из СУБД, теряя эффективность обработки или держать куски обработки отдельно для каждой базы, переключаясь на них по параметру, что увеличивает трудоемкость. Это работает до определенных объемов. Переход через какой то пороговый объем данных, вынуждает переходить на конкретную СУБД и затачивать ее работу, используя ее особенности.
sshikov
12.02.2017 14:33+2Да, разумеется. Причем чем больше — тем больше шансов, что СУБД превратится во что-то очень специальное, типа Teradata или Greenplum, вообще никуда не переносимое.
VMichael
07.02.2017 12:50+1Было бы интересно узнать, в чем боль проваленного проекта, немного конкретнее, в чем была «неправильная» парадигма, к чему она привела.
И как это исправилось при применении «правильной» парадигмы.
На пальцах, на примерах.cobiot
08.02.2017 05:14если совсем кратко то как раз в том что пытались применять MVC, где M — данные а C — логика всего на свете. И контроллер постепенно втягивал в себя все больше и больше кода… в нем на самом деле перемешивалась бизнес логика и логика визуализации данных. И его поддержание превратилось в ад. Причем в этом аду приходилось все время «копаться» потому что программа была живая, с ней работали и давали ценную обратную связь где и что нужно поменять и доработать, какие новые фичи прикрутить. Тут хотелось бы новых программистов нанять но никак потому как Контроллер был центром и вся программа через него была завязана в узел… любое изменение отражалось почти на всем. То есть было нереально выделить отдельные независимые модули которые можно было бы раскидать по нескольким программистам. И пришел момент когда стало понятно что все… оно не способно дальше меняться. Нужно все переписывать нафиг. И вот тогда фасады (не в теории а на практике) и прочие техники для уменьшения связанности стали действительно откровением и волшебной «палочной»
cobiot
08.02.2017 07:45+1а да Модель конечно же была независимой. Только толку от независимости тонкой модели не было никакого
VolCh
08.02.2017 09:32в нем на самом деле перемешивалась бизнес логика и логика визуализации данных.
То есть вырожденными были и представления, не только модель?cobiot
08.02.2017 15:44+1да! Это ведь к сожалению весьма распостраненное мнение что Вид ни в коем случае не должен содержать логику. Опять таки у Фаулера на эту тему есть интересный пример… он показывает что иногда в результате «состояние и логика Вида» могут пробраться даже не в контроллер а в доменную модель

realbtr
07.02.2017 13:43Про Модель — очень качественно разложено и подано. Пожалуйста, продолжайте про мифы и ошибки в проектировании Контроллера.
reforms
07.02.2017 14:36За статью спасибо, читается залпом.
Отдельное спасибо за качество следопыта в Вас, когда разбираешься, пока истина не покажет свое лицо. Люблю таких людей

cobiot
07.02.2017 18:22+2Прошу прощения за запоздалый ответ. Нахожусь в другом часовом поясе и тут только наступило утро.
Целью статьи вовсе не являлось сказать что «original MVC» единственно правильный. Именно поэтому вначале дан обзор и приведены почти все основные схемы и варианты. Каждый может выбрать что ему больше подходит…
Лично для меня было очень полезно узнать с чего «все начиналось». Мне хотелось показать что исходный MVC с одной стороны был намного сложнее и богаче чем большинство упрощенных схем, которые нам обычно преподносятся в качестве MVC, а с другой — он довольно прост, логичен и буквально «выводится» из архитектурных принципов. Поэтому понимая суть можно его граммотно варьировать и адаптировать под свои нужды. Например у нас тоже не используется шаблон Наблюдатель просто потому что синхронизация приложения идет по таймеру. Но от этого MVC не перестает быть MVC.
Вопросы связанные с проектированием базы данных и логики приложения… Дело в том что тут двоякая ситуация. По большому счету база+логика это та самая доменная модель. И MVC не дает и не может дать вам ответ как лучше проектировать доменную модель. Он лишь говорит как организовать взаимодействие этой самой модели с пользовательским интерфейсом (лучше через фасад). Поэтому когда вам говорят что вы не так спроектировали потому что MVC… то это конечно же не правда. Но!!! к мнению и советам коллег стоит очень внимательно прислушаться потому как именно Вебщики постоянно сталкиваются с проектированием базы и сервера, знают что там за засады и какие решения лучше применять. Так что предложение вынести веб в в отдельную тему оно очень даже разумно.
А вот по поводу проектирования пользовательского интерфейса MVC есть что сказать. Конечно же интерфейс вовсе не обязан быть тупым, и современный веб наглядное этому подверждение. Главный вопрос — как же сделать его умным и при этом не смешивать логику GUI с графическими компонентами? Собственно об этом и будет вторая часть
ЗЫ на самом деле всем спасибо за терпимость. мне казалось что в столь «религиозной» теме за нетрадиционность подхода меня сразу закидают камнями

ruzzz
08.02.2017 01:59+2Просто крутая статья. Прочитал и что-то щелкнуло «Вот оно». Последняя точка поставлена. То к чему дошел на своем опыте, теперь обрело форму нескольких лаконичных правил.
По своему опыту я всегда не мог согласиться с MVC, которые диктует тот или иной фреймворк. В первую очередь, не потому что фреймворк плох (смотри ниже второе), а потому что его пользователи, мои коллеги, отталкивались в своих спорах от этого фреймворка. Поясню. У меня всегда было стойкое ощущение, что споры об MVC не от того правильно или неправильно кто-то использует конкретный фреймворк. А от непонимания, что данный конкретный фреймворк разработан со своим видением MVC. Да, все банально, но часто происходит так: Что такое MVC? А вот он в этом фреймворке. И далее гадание на кофейной гуще и ориентация на мнение авторитетов или собственные эксперименты. Т.е. нужно разделять: «Ты работаешь не так как принято с этим фреймворком» и «Ты не понимаешь принципы MVC».
Второе, а так ли я готов согласиться с моделью конкретного фреймворка, нужно обсуждать только после того как понял и принял первое. И уже здесь приходит понимание, что нужны четкие формализованные правила, с помощью которых можно рассмотреть все основные реализации MVC на предмет «удобно или не удобно» работать. И в статье сразу же бросается в глаза:
- Модель с точки зрения реализации — это интерфейс к бизнес логике. Просто в точку.
- Разделение на контроллер лежит на следующей уровне иерархии после разделение на «Модель предметной области» и «Взаимодействие с пользователем».
cobiot
08.02.2017 03:39Спасибо… Вы прям из моего подсознания вытащили… у меня тоже всегда было ощущение что нужно разделять понимание MVC и умение работать с тем или иным фреймворком. Только у меня не получалось это так четко сформулировать…
Hitsuzen
08.02.2017 03:29Огроменное спасибо за то, что написали эту статью. Это самое подробное и понятное объяснение MVC, которое я когда-либо читал. Уже пару лет пишу на PHP и постоянно не покидает ощущение, что всё делается через ж***, а как по-человечески — я просто не знаю.
ddd329
08.02.2017 07:22Спасибо большое за статью, очень интересно написано и слог хороший. Я понимаю что доменная модель предназначена для реализации бизнес-логики. Если я правильно понял, Вы предлагаете использовать над ней некий ФАСАД упрощающий отображение во View. Но вот самый простой пример, я использую DDD (Domain Driven Design), и у меня есть АГРЕГАТ Person (человек), который состоит еще из пяти объектов. Нужно отобразить список Ф.И.О. 10 человек, 1 человек = 5 объектов, как-то нелогично тянуть из БД 50 объектов, чтоьы отобразить такой простой список.
cobiot
08.02.2017 07:35Если я правильно понимаю вашу задачу, то мне кажется что у фасада просто должен быть метод наподобе этого:
String[] getFIO();
клиент должен получить готовый список из 10 строк с Ф.И.О. людей…
А формироваться этот список должен внутри доменной модели, котороя знает как наиболее оптимальным образом вытащить эти данные из базы или еще откуда. В крайнем случае этот список может формировать фасад… но вообще это опасная дорожка по направлению к тому что фасад начнет реализовывать бизнесс-логику. Просто в вашем примере только база и фасад и мне пока не очень понятно где там находится бизнесс-логика
VolCh
08.02.2017 09:39+1«Православное» скрещивание MVC и DDD заключается, по-моему, в объединении понятий Application Service из DDD и Model из MVC. А тянуть из базы полный агрегата со всеми зависимостями или только корень можно решать на уровне репозитория.
Fesor
08.02.2017 10:24как-то нелогично тянуть из БД 50 объектов, чтоьы отобразить такой простой список.
Потому часто разделяют модель чтения и записи. То есть что бы отобразить данные 10-ти человек вы грузите не 10 агрегатов (это как-то противоестественно в терминах DDD так как вы должны работать с одним агрегатом в рамках бизнес-транзакции), а делаете один SQL запрос который выбирает нужные данные. Эта выборка будет не в репозитории (поскольку он возвращает корень агрегата).
mayorovp
08.02.2017 10:29SQL-запрос к базе, сделанный из фасада или, упаси боже, из контроллера, противоречит всем принципам разбиения приложения на слои!
VolCh
08.02.2017 11:03Не о том речь. А о создании полностью параллельной модели ( в рамках MVC). Можно два фасада, можно за одним фасадом спрятать модели записи и чтения, но дальше они пересекутся только на уровне СУБД. Запросы, требующие записи будут работать с полноценной объектной доменной моделью, а запросы требующие только чтения могут вообще полноценных объектов не создавать, возвращая, например, ассоциативные массивы.
mayorovp
08.02.2017 11:12Да, так делать можно. Лишь бы только это не было преждевременной оптимизацией или трудным в поддержке костылем.
Fesor
08.02.2017 14:00+2Лишь бы только это не было преждевременной оптимизацией или трудным в поддержке костылем.
Если проще. Вместо одного класса который бы занимался и записью и чтением у вас будет два класса. Один отвечает за запись данных, а другой за выборки которые мы используем для формирования UI. С точки зрения single responsibility это лучше поскольку причины для изменений у этих классов будут несколько разные. Но количество кода остается одинаковым. Иногда даже существенно уменьшается. И существенно снижается сложность самой системы.
mayorovp
08.02.2017 14:19Зато появляется неявная зависимость между классами, к тому же невидимая для инструментов рефакторинга.
oxidmod
08.02.2017 14:30О какой зависимости вы говорите?
mayorovp
08.02.2017 14:31Если будем менять схему БД — надо будет переписывать не только репозитории, но и все отчеты, которые для изменяемых таблиц насоздавали.
oxidmod
08.02.2017 15:03а если не разделять read/write модели, то нужно будет просто все єти фиксі делать в одном классе условно. Изменений то будет тоже количество
mayorovp
08.02.2017 15:05Но при этом больше шансов углядеть необходимость переделывания запросов еще до принятия решения о переделывании схемы БД :)
Fesor
08.02.2017 19:12больше шансов углядеть
шанс проглядеть остается а этого хватает. Но вообще тесты надо писать.
mayorovp
08.02.2017 19:33Тесты сработают только когда схема БД будет уже изменена. А надо бы увидеть сложные выборки еще до того как новую схему начнут делать.
Fesor
08.02.2017 20:04А надо бы увидеть сложные выборки еще до того как новую схему начнут делать.
зачем?
mayorovp
09.02.2017 10:15Чтобы не сделать такую структуру БД, на которой нужные выборки станут невозможными.
Fesor
09.02.2017 15:39+1вы говорили что "тесты сработают только когда схема БД будет уже изменена" и это ровно то что нужно от тестов. Убедиться (не на 100% конечно) что нет регрессий. Обычно все же если мы изменили схему базы то даже на позитивных тест кейсах только можно узнать что все плохо.
Речь же шла о том как минимизировать человеческий фактор.
ddd329
08.02.2017 10:14А формироваться этот список должен внутри доменной модели, котороя знает как наиболее оптимальным образом вытащить эти данные из базы или еще откуда.
Не согласен, потому что доменной модели должно быть все равно на отображение, и оптимальности на этом уровне никакой нет.
В крайнем случае этот список может формировать фасад…
Именно так я и понял из вашей статьи, но фасад скрывает доменную модель, которая содержит данные и бизнес-логику. Если вы знакомы с DDD, то понимаете, что репозиторий PersonRepository, возвращает АГРЕГАТ — Person, а он состоит из 5-ти объектов, следовательно 5 * 10 = 50!cobiot
08.02.2017 17:10Понятно… Вы под тепрмином модель грубо говоря понимаете каждый «объект» в своем приложении. Нет конечно же в статье имелось ввиду что доменная модель это не каждый отдельный объект а именно «приложение» которое реализует некий функционал.
Грубый пример — поисковый робот который бегает по сети и индексирует где и что находится, чтобы, когда вы обратитесь к поисковику, вам информация была выдана быстро и удобно. Роботу, который в этом случае и будет приложением «все равно на отображение» но тем не менее его работа заключается именно в том чтобы сделать доступ к информации быстрой и удобной.
Мне кажется что в вашем случае (и вообще при работе с базами и не базами) все тоже самое только в предельно упрощенном виде — должно быть некое приложение или модуль в приложении (и этот модуль будет относится именно к доменной модели в терминологии MVC) который знает где находится информация и как ее оптимальным образом извлечь и в удобной форме вернуть для дальнейшего использования. Он может ее просто извлекать, или частично кэшировать для быстрого дальнейшего доступа… не суть важно, важно чтобы именно в доменной модели за эту задачу кто-то отвечал.
И если удобная форма это просто набор строк… То значит этот модуль не должен тащить объекты а должен с помощью SQL запроса извлечь из базы лишь нужные вам строки и вернуть (как и написал Volch). А уж что вы с этими строками будете делать дальше это уже ваше дело — можете отображать, можете для какой-нибудь аналитики или отчетов использовать.
cobiot
09.02.2017 03:03Для наглядности. Если нет ограничения по ресурсам то сначала делаем стандартную реализацию (1) согласно идеологии DDD и не важно что тянутся лишние объекты.
Когда (и если) возникла необходимость в оптимизации можно перейти к чему-то подобному (2)
Поскольку интерфейс фасада в обоих случаях будет одинаков то на клиенте переход от 1 к 2 никак не отразится. Именно в этом и заключается смысл фасада — можно менять конкретную реализацию бизнесс модели а клиент этого даже не заметит


Catrinblaidd
08.02.2017 21:41Огромное Вам спасибо за проведённые изыскания и статью. Вы спасли меня от хождения по граблям. Наконец-то в моей голове всё более-менее встало на место. Отдельное спасибо комментаторам, особенно VolCh.
allter
09.02.2017 13:26+2Спасибо за отличный анализ, жду вторую часть про контроллеры. :)
Сам не вытерпел и решил посмотреть, «как же было в оригинале». Нашёл статью некоего S. Burbeck: http://www.math.sfedu.ru/smalltalk/gui/mvc.pdf 1992 года.
По результату прочтения несколько моментов.
В вашей статье есть какой-то акцент на применении Facade для реализации Модели. Burbeck же пишет, что Моделью может быть любой объект Smalltalk, просто при использовании «тупых объектов» — т.н. «пассивной Модели» мы не получаем функционал оповещения Вида при изменениях.
То есть по факту, разделение объектов на Модель-Вид-Контроллер в Smalltalk довольно тонко заточено именно под тамошнюю оконно-графическую модель. И Модель в отрыве от виджета (который состоит из пары Вид-Контроллер) не несёт никакого особого смысла — это просто объект Smalltalk (возможно, составной).
Соответственно, получается, что разделение UI на Вид и Контроллер в отрыве от соответствующей графической (точнее, UI-) библиотеки бессмысленно. А в рамках конкретной библиотеки может существовать другое деление, в т.ч. на бОльшее количество компонентов. Насколько я понял из вышеприведённой, в контексте Smalltalk это разделение позволяло повторно использовать одинаковые Контроллеры разными Видами, причём основной функционал Контроллера, кроме примитивной маршрутизации событий в стандартизованные сообщения, заключался в трансляции экранных координат мыши в локальные оконные — путём опроса соответствующих Видов. Этот функционал похож у многих виджетов, поэтому логично было выделить его из кода, описывающего конкретный UI.
Ещё интересная тема — иерархический MVC (HMVC — он же PAC), где контроллер выделяется как маршрутизатор всех событий компонента, а не только UI`шных.Busla
09.02.2017 13:51в 1992 году еще не придумали паттерн «фасад». Но если некий объект обладает всем необходимым чтобы быть Моделью, то он довольно похож на «фасад». В таком случае почему не использовать актуальный термин для старой идеи?
VolCh
09.02.2017 13:57+1Burbeck же пишет, что Моделью может быть любой объект Smalltalk
Не для всех доменных моделей нужен фасад. Фасад применяют обычно когда нужно обеспечить единую высокоуровневую точку доступа к сложным графам объектом. Если такового графа нет или он не сложный для внешнего потребителя (например, вся модель — это агрегат из DDD), то и фасад не нужен.Busla
09.02.2017 14:34-1Вы слишком буквально трактуете предложение:
Necessarily, any object can be a model.
Отчасти в силу того, что на момент написания не было подходящей устоявшейся терминологии и идеологии. Эта фраза из середины объяснения Бурбека, что такое вообще модель. Заканчивает объяснение он как раз «фасадом»:
Because any object can play the role of model, the basic
behavior required for models to participate in the MVC paradigm is inherited from class
Object which is the class that is a superclass of all possible models.
Fesor
09.02.2017 15:40в 1992 году еще не придумали паттерн «фасад».
Не придумали названия, сам паттерн существовал задолго до этого. Не забывайте что GoF вышедший в 94-ом году содержал лишь названия и обобщения для решений которые существовали уже давно. Ну это я так, брюзжу.
Busla
09.02.2017 19:56решения существовали, но не как массовый типовой приём разработки
поэтому брюзжание ваше не к месту: не было это паттерном
Fesor
09.02.2017 15:44+1То есть по факту, разделение объектов на Модель-Вид-Контроллер в Smalltalk довольно тонко заточено именно под тамошнюю оконно-графическую модель.
Рекомендую почитать: Thing-Model-View-Editor — это ма й 79-ого года. Первое упоминание MVC было вроде как в декабре. Словом можете глянуть что Тругве думал по этому поводу. Там особое внимание уделяется UI. У меня валяется кусок перевода этой статьи, если посчитаете этот материал полезным могу опубликовать перевод.
cobiot
09.02.2017 17:19да! вы нашли самое начало… Только читается очень тяжело. Я во второй части ее довольно подробно разберу и постараюсь дать немного пояснений чтобы было легче читать. У меня тоже валяются переводы. Так что если у народа будет интерес то можно объединить усилия и выложить
Fesor
09.02.2017 18:05+1Только читается очень тяжело.
У меня была безумная идея сделать что-то типа музея, мол старые публикации с пояснениями и обновленной графикой, вроде этой публикации. В частности хотел запихнуть туда "goto considered harmful" (ибо это письмо очень хорошо отвечает на вопрос почему глобальные переменные это не очень удобно) и т.п. Что-то типа "почему в программировании все так как сейчас и как все начиналось". Но на это надо времени убить кучу...
cobiot
10.02.2017 00:09+1это да… меня тоже это останавливает. Угрузившись в «историю» начинаешь связи видеть, понимать откуда ноги у современности растут и вообще там многое нагляднее что-ли… и при этом «красиво». Но пока нет уверенности что это кому-то надо, а без этого… времени и так в обрез. Поэтому выкладывается только самое «выстраданое»
VMichael
13.02.2017 18:25+1Но пока нет уверенности что это кому-то надо
Конечно надо, многие будут признательны.
cobiot
09.02.2017 17:14про иерархический MVC действительно инетерсная тема… здорово что вы на нее вышли. Мы пока решили ее не затрагивать чтобы не перегружать.
По поводу Модели… Вы правы, если читать лишь описания то и у Барбека и у Краснера действительно написано что модель это доменный объект (любой объект Smalltalk) как вы верно и заметили. А вот на практике всегда был «фасад» между ними. И специальный объект Model от которого наследовались все модели был выделен особо, а это значит что опять таки на практике не любой объект Смоллтолк мог быть моделью. Это то и есть самое интересное. Предполаю что связано это с тем что тогда действительно не было шаблонов, они были «первопроходцами», поэтому практика опережала «теорию». Кстати у Реенскауга в описании фасад тоже появился позже…
А вот насчет бессмысленности разделения UI на вид и контроллер в отрыве от библиотеке… Тут с вами не соглашусь пока. Во второй части попробую показать что это штука довольно универсальная и существующая не только в программах а вообще почти в любом интерфейсеallter
13.02.2017 12:07С нетерпением жду!
По поводу Модели-Фасада: понятно, что любой более-менее нетривиальный UI-компонент имеет достаточно сложный «бэкэнд», что бы его можно было реализовать одним пассивным объектом.
Тут ещё другой момент, который я имел в виду:
Методы Модели-Фасада для того или иного компонента могут возвращать сложные объекты. Так вот, архитектурная проблема: имеют ли право методы Фасада возвращать ссылки на объекты, доступные из других фасадов, который этот Фасад скрывает (и в конце концов, ссылки на конкретные пассивные объекты, которые содержат данные)? Или Фасад должен возвращать только объекты-Прокси для доступа к реальным объектам? Или ещё как-то?Fesor
13.02.2017 12:21+1Если мы берем сферический вакуум, то по хорошему каждый метод фасада должен возвращать только DTO которое нужно в этом конкретном случае. Есть конечно ситуации при которых вы хотите что-то реюзать, но тут надо больше про связанность и зацепление думать нежели о MVC. Ну то есть банальные принципы разбиения на модули и слои.
cobiot
14.02.2017 03:56Мне кажется вы задаете очень интересный вопрос, но нет уверенности что правильно вас понимаю, поэтому если «мимо» то извините. Мне кажется что фасад не должен давать клиенту ссылки на доменные объекты. Фасад всегда дает клиенту объекты-заглушки. Если есть возможность то это могут быть объекты-прокси, но иногда без копирования не обойтись (например как в вебе) и тогда данные например из доменного объекта Post, который обращается к базе данных и берет из нее данные будут копирваться в клиентский объект PostInfo (с точно такими же полями), который собственно и будет возвращен клиенту
VolCh
14.02.2017 09:45Должен или не должен определяется требованиями и выделенными ресурсами. Введение дополнительных уровней изоляции увеличивает как трудоемкость разработки приложения, так и ресурсы, потребляемые ею в рантайме.
А хороший фасад является ещё и адаптером (вообще сложно бывает провести между ними разницу), не тупо возвращает копии или прокси (прокси, кстати, копируют интерфейс проксируемого объекта, включая его мутаторы, что не является изоляцией по сути), а адаптирует их к нуждам клиента. MVC-приложению часто для большинства операций не нужно полное представление доменного объекта, запрошенного у модели и достаточно передать урезанную версию, зачастую даже в структуре отличной от доменной, например, приложение интересует только ФИО клиента и остаток на его счету, ему не нужны все данные клиента и список всех операций по счёту. Модель в этом случае может отдать контроллеру или представлению плоский DTO (а то и массив) из четырех полей, не просто пряча данные модели от остального приложения, но пряча и структуру модели. Что хорошо как с точки зрения защиты данных от НСД, так и с точки зрения защиты VC от изменений в M, а внутренностей M (доменной модели, инфраструктуры и т. д. ) от изменений требований VC, если они реализуемы без изменения модели, например потребовалось выводить не только итоговый баланс, но и разбивать его на доходную и расходную часть. С одной стороны, вроде, это функция вью по полному списку операций составить их баланс, а, с другой, для простого отображения итогов вью потребуется слишко много знаний о внутренней структуре доменной модели и связь вью-модель станет слишком хрупкой,
powerman
14.02.2017 23:58Должен или не должен определяется требованиями и выделенными ресурсами. Введение дополнительных уровней изоляции увеличивает как трудоемкость разработки приложения, так и ресурсы, потребляемые ею в рантайме.
Один из ключевых моментов, которые делают микросервисную архитектуру реально полезной и работающей — как раз эта изоляция. Именно ради этой изоляции выдвинуто требование, что у каждого микросервиса должна быть собственная БД, куда нет доступа другим микросервисам. А для передачи данных между двумя частями приложения приходится их сериализовывать и передавать по сети. Что, безусловно, заметно жрёт ресурсы и увеличивает трудоёмкость. Но, тем не менее, это окупается тем, что нарушить слой изоляции между микросервисами невозможно при всём желании.
Теоретически, безусловно, можно обеспечить ровно такую же изоляцию между двумя модулями/пакетами/объектами в рамках одного физического приложения, не разделяя его на несколько независимых микросервисов. Но ключевое слово здесь — теоретически. А на практике абсолютное большинство разработчиков не в состоянии удерживаться от нарушения этих "виртуальных" границ, более того, зачастую они даже не дают себе труд понять где эти границы проходят и почему их категорически нельзя нарушать. Ведь всегда кажется, что если нарушить их совсем чуть-чуть — то это как-бы и не нарушение вовсе… зато можно намного быстрее и не включая голову сделать нужную фичу.
Мне очень хочется найти какой-то подход, доступный большинству разработчиков, который бы решил эту проблему, и сделал реальной разработку больших монолитных приложений с жёстким соблюдением границ между их внутренними модулями/пакетами/объектами.
Но реально и на практике я такое видел только в одном месте — в языке Limbo, который работает только под OS Inferno. Там сама OS обеспечивает необходимый уровень изоляции — по сути, там можно отдельные библиотеки или части приложения (функции, по сути) запускать в отдельном лёгком потоке работающем в собственном уникальном окружении (а-ля продвинутый chroot), при этом доступ в память есть только к тем объектам, которые этому потоку передали параметрами при запуске или позднее прислали по типизированному каналу. В результате получается, что у каждого такого модуля (или даже функции) программист описывает интерфейс, к чему него есть доступ, и после запуска ни этот модуль не может получить доступ к чему-либо выходящему за рамки этого интерфейса, ни кто-то другой не может получить доступ к внутренностям этого модуля если он заранее не предоставил к этим внутренностям соответствующий интерфейс.
mayorovp
15.02.2017 09:18Язык Limbo вы сюда зря привели. Он ну никак не помешает "нарушать границы" неаккуратному программисту — ведь это делается без всяких хитрых трюков с памятью.
VolCh
15.02.2017 10:13Один из ключевых моментов, которые делают микросервисную архитектуру реально полезной и работающей — как раз эта изоляция.
В контексте этого топика, говоря об MVC и фасадах к доменной модели в качестве модели приложения, мы говорим об изоляции в рамках одного микросервиса, построенного по MVC паттерну. Контроллер принимает от клиентов микросервиса запросы, обращается к фасаду и сериализует ответ фасада в ответе клиенту. От клиентов микросервиса доменная модель и так изолирована как минимум сериализацией (сериализатор — вью по сути), особо большого смысла изолировать сущности домена от контроллера часто нет. Фасадом сложность доменной модели просто прячется от контроллера, но формировать специально для контроллера отдельный DTO часто не имеет смысла на практике, особенно когда «тупые» контроллеры (запрос к фасаду, сериализация ответа) пишет тот же человек, который пишет фасад и всё это в рамках одной задачи. Да, это красиво, правильно, но трудоемко при добавлении нового свойства в модель повторять его не дважды (в самой модели и в сериализаторе), а трижды (между моделью и сериализатором).
Именно ради этой изоляции выдвинуто требование, что у каждого микросервиса должна быть собственная БД, куда нет доступа другим микросервисам.
Это не требование, а часто используемая практика. В конце-концов, СУБД тоже своего рода микросервис, которому никто не запрещает иметь несколько клиентов в рамках системы.powerman
15.02.2017 15:38В контексте этого топика, говоря об MVC и фасадах к доменной модели в качестве модели приложения, мы говорим об изоляции в рамках одного микросервиса, построенного по MVC паттерну.
Э… почему это? В рамках этого топика мы говорим о разработке приложения, например веб-сайта, бэкенд которого вполне может быть построен по микросервисной архитектуре, и один (или несколько) из микросервисов вполне могут реализовывать этот самый интерфейс фасада, избавляя веб-интерфейс или мобильные клиенты от необходимости делать запросы напрямую в микросервисы реализующие доменную модель.
В самих микросервисах внутри тоже может быть MVC, явно или неявно (как Вы описали), но зачастую в микросервисах полезного кода строк 50-100, шансов что он будет активно усложняться и развиваться практически нет (а если и будет — проще сделать новый микросервис), и заморачиваться там какой-либо архитектурой вообще нет смысла.
VolCh
15.02.2017 16:27Я не понимаю о чём вы говорите, о каком-то распределенном MVC, в котором модель MVC (ака фасад к доменной модели DDD) на одном хосте, контроллер на другом, а вью на третьем? Я говорю об отдельном серверном приложении (грубо, отдельном процессе ОС), построенном по MVC архитектуре, где вся триада взаимодействует средствами IPC. Какую роль играет этот сервис в рамках всей распределенной (как минимум, клиент-серверной) системы, монолитный бэкенд, реализующий ERP международной коропорации, или микросервис, реализующий, например, простейший CRUD над единственной сущностью, не имеет значения.
powerman
15.02.2017 16:51MVC это архитектурный подход. Его можно применять внутри какого-то модуля/библиотеки, строить по нему отдельное приложение (процесс ОС), и ровно так же строить по нему распределённое приложение состоящее из десятков микросервисов.
Мой изначальный коммент был про то, что когда у нас MVC в рамках одного процесса ОС, то соблюдать границы (не лазить в модель мимо фасада, не пропускать через фасад наружу исходные объекты доменной модели через которые опять же можно узнать лишние детали реализации модели и даже изменять модель мимо фасада, etc.) становится очень сложным т.к. язык/ОС не помогают соблюдать границы и это становится вопросом внутренней дисциплины разработчиков.
VolCh
15.02.2017 17:00Так я про то же. И что чаще всего не имеет смысла в рамках одного процесса изолировать от контроллера/вью объекты доменной модели, возвращаемые моделью-фасадом. Кто захочет достанет их и минуя фасад.
Fesor
15.02.2017 19:42+1но зачастую в микросервисах полезного кода строк 50-100
микро в микросервисах не выражается в количестве кода. Микросервис на 10К строк — норм покуда он отвечает за одну область ответственности бизнеса. А не микро он становится когда начинает работать в пределах двух областей ответственности и более.
powerman
15.02.2017 20:03Конечно, но мы же здесь не микросервисы обсуждаем, а MVC. Если в микросервисе 10К строк — без какой-то архитектуры (может и MVC) внутри этого микросервиса, в большинстве случаев, будет очень неуютно. А если в нём 50-100 строк, то часто можно архитектурой не заморачиваться.
Fesor
16.02.2017 09:05+1MVC не архитектура всего приложения, это лишь способ отделения UI логики и логики обработки данных. На этом собственно можно и закончить.
А если в нём 50-100 строк, то часто можно архитектурой не заморачиваться.
Собственно тогда можно чуть по другому сказать, без привязки к микросервисам. Если вы можете разделить систему на изолированные модули адекватно, то не важно как и что там внутри этого изолированного модуля. Но чтобы так сделать придется сильно много думать об архитектуре. А микросервисы лишь налагают физические ограничения на эти модули. Так что если не думать об этой самой архитектуре боль будет точно и ее будет много.
powerman
15.02.2017 15:55+1Это не требование, а часто используемая практика. В конце-концов, СУБД тоже своего рода микросервис, которому никто не запрещает иметь несколько клиентов в рамках системы.
Это именно что требование. Как только у микросервисов появляется общая БД и начинаются философские рассуждения о том, что формально СУБД это тоже сервис (на микро он, вообще-то, не тянет) — то "Хьюстон, у нас проблема".
Общая СУБД — это, по сути, аналог громадной и сложной глобальной переменной, с которой одновременно работает куча разных кусков кода. Обложившись блокировками, транзакциями и версионированием схемы БД чтобы всё это хоть как-то работало.
Суть микросервисного подхода в том, что пока стабильно работают API сторонних микросервисов и стабильно работает API этого микросервиса — мы можем делать что угодно и как угодно в самом микросервисе, и это гарантированно ничего не сломает в других местах. Поэтому несовместимых изменений API стараются избегать из всех сил, потому что это единственное, что может поломать что угодно и где угодно. Хотя СУБД это безусловно сервис, но у этого сервиса нет стабильно работающего API — я имею в виду достаточно высокоуровневого API, которое бы гарантировало что сделав вот такой запрос в базу я получу нужные мне данные в корректном формате — потому что изменение схемы БД или ошибка в коде изменяющем данные всё это ломают.
На практике, безусловно, общие БД у сервисов встречаются. Но чтобы это более-менее нормально работало приходится относится к схеме БД как к публичному API — документировать его, стараться не изменять несовместимым образом, добавлять в саму БД функции контролирующие корректность записываемых значений и целостность данных… и работает это довольно паршиво. Потому что БД — это, всё-таки, не фасад а модель, возвращаясь к теме топика. И, по хорошему, перед такой общей БД надо вешать отдельный микросервис, который даст API к этой БД в стиле фасада и терминах бизнес-логики приложения, и скроет саму БД от всех остальных микросервисов.
aso
Я когда-то для своих целей разработки, безотносительно пользовательских интерфейсов — изобрёл для себя модель, которую потом стал называть условно «MVC», хотя это, скорее, «MVDC» — модель-вид-данные-контроллер.
В ней «Модель» — это данные в ОЗУ, объект, скорее всего составной, возможно содержащий в себе множество объектов (список, коллекцию).
«Вид» — умеет отображать на экране «Модель», берёт некое «стандартное представление» и отрисовывает его на экране.
«Данные» — занимаются вводом/выводом из/в файлов, умеет преобразовывать файл в «стандартное представление модели» и наоборот,
При этом общение все трёх компонентов идёт через интерфейсы, которые, собственно, и оказываются наиболее «неподвижной» частью приложения.
При этом все три указанные части являются пассивными — а единственной активной частью программы становится Контроллер.
Контроллер сам не имеет внутренней памяти, не имеет состояний, за исключением «системных» — например, если приложение может работать в нескольких режимах — и занимается только вызывает соотв. методы интерфейсов прочих компонентов.
mayorovp
В силу того, что сказано в посте, надо бы вам определения M и D поменять местами :)
aso
Я бы сказал, что у меня было MCVD. ))
(Т.е. программы я привык выстраивать вокруг данных в памяти + контроллер, пристраивая остальное «вокруг» этой сладкой парочки. вплоть до того, что контроллер мог сливаться с моделью — в ООП это будет означать, что «Модель» — это поля корневого объекта данных, а «Контроллер» — это его методы. ))