Свой рассказ я хочу начать с такой вот веселой картинки:

Да, ещё несколько лет назад картинка была актуальной. Но сейчас, с развитием технологий, входящих в эко-систему Hadoop и развитием ETL платформ правомерно утверждать то, что ETL на Hadoop не просто существует но и то, что ETL на Hadoop ждет большое будущее. Далее в статье расскажу про то, как мы строим ETL на Hadoop в Тинькофф Банке.
От задачи к реализации
Перед управлением DWH была поставлена большая задача – анализировать интересы и поведение интернет посетителей сайта банка. У DWH образовалось два новых источника данных, больших данных – это clickstream с портала (www.tinkoff.ru) и RTB (Real-Time Bidding) платформа банка. Два источника порождают колоссальный объём текстовых полуструктурированных данных, что конечно для традиционного DWH, построенного в банке на массивно параллельной СУБД Greenplum, совсем не подходит. В банке был развернут кластер Hadoop, на основе дистрибутива Cloudera, он то и лег в основу целевого хранилища данных, а точнее озера данных, для внешних данных.
Концепция построения озера
Важно было на начальных этапах продумать и зафиксировали концептуальную архитектуру, которой нужно будет придерживаться в ходе моделирования новых структур для хранения данных и работы по загрузке данных. Мы очень не хотели превратить наше озеро в болото данных :) Как и в классическом DWH, мы выделили основные концептуальные слои данных (см. Рис. 1).
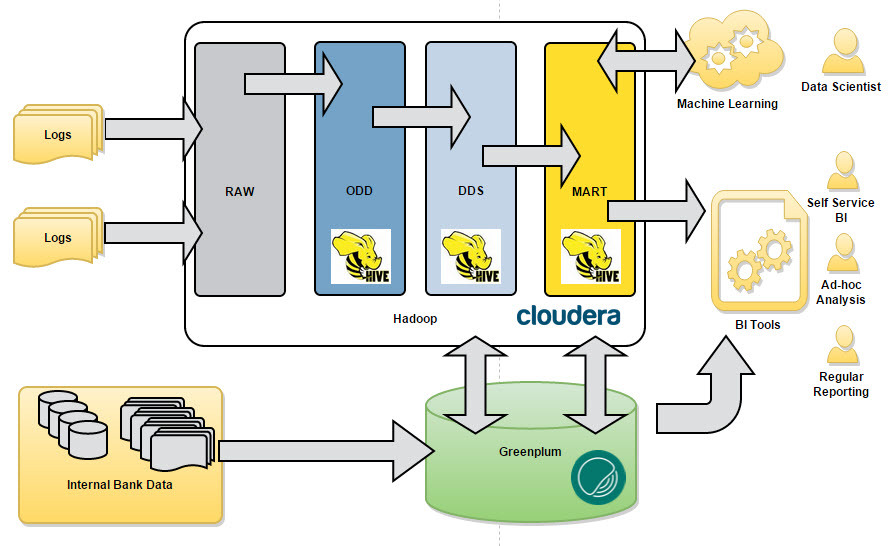
Рис.1 Концепция
- RAW – слой сырых данных, сюда загружаем файлы, логи, архивы. Форматы могут быть абсолютно различные: tsv, csv, xml, syslog, json и т.д. и т.п.;
- ODD — Operational Data Definition. Сюда мы загружаем данные в формате приближенном к реляционному. Данные здесь могут являться результатом предобработки данных из RAW перед загрузкой в DDS;
- DDS — Detail Data Store. Здесь мы собираем консолидированную модель детальных данных. Для хранения данных в этом слое мы выбрали концепцию Data Vault;
- MART – витрины данных. Здесь мы собираем прикладные витрины данных.
Data Vault и как мы его готовим
Почему Data Vault? У этого подхода есть и свои плюсы, и свои минусы.
Плюсы:
- Гибкость моделирования
- Быстрая и удобная разработка ETL процессов
- Отсутствие избыточности данных, а для больших данных это весьма важный аргумент
Минусы:
- Основной минус для нас был обусловлен средой хранения (а точнее и обработки) данных и как следствие производительностью работы join операций. Как известно Hive не очень любит операции join, в силу того, что в итоге всё выливается в медленный map reduce.
Проанализировав тренды развития технологий Hadoop, мы решили использовать этот подход и засучив рукава принялись моделировать Data Vault для выше озвученной задачи.
Собственно, хочу рассказать несколько концептов, которые мы используем. Например, в загрузке визитов интернет-пользователей по страницам мы не сохраняем каждый раз URL визита. Все URL-ы мы выделили, в терминах Data Vault, в отдельный хаб (см. Рис. 2). Такой подход позволяет значительно сэкономить место в HDFS и более гибко работать с URL-ами на этапе загрузки и дальнейшей обработки данных.
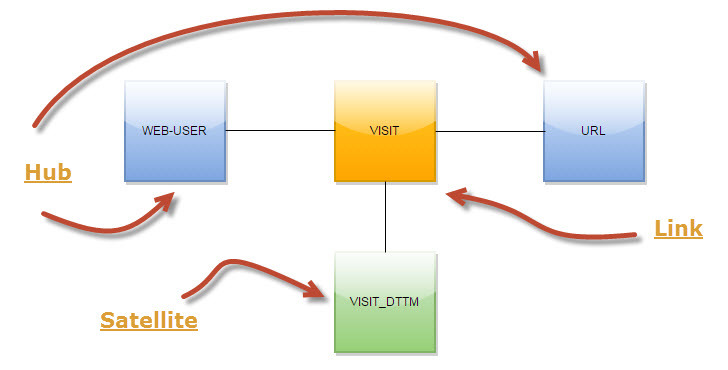
Рис.2 Data Vault для визитов
Ещё один концепт относится к области загрузки интернет пользователей. Мы не получаем на этапе загрузки в DDS единого интернет пользователя, а загружаем данные в разрезе систем источников. Таким образом загрузки в Data Vault из разных источников не зависят друг от друга.
Важно было сразу предусмотреть физическую структуру хранения данных в Hadoop, т.е. сразу хорошо продумать DDL таблиц в Hive. На этом этапе мы зафиксировали два соглашения:
- Использование партиционирования в HDFS;
- Эмуляция дистрибьюции по ключу в HDFS.
В результате каждый объект (таблица) Data Vault в своем DDL содержит:
PARTITIONED BY (ymd string, load_src string)и
CLUSTERED BY (l_visit_rk) INTO 64 BUCKETSРеки ETL в озере данных
Вот и подошли к самому интересному. Концепцию продумали, моделирование провели, создали структуры данных, теперь хорошо бы было бы это все наполнить данными.
Для того что бы обеспечить стабильный поток данных (файлов) в слой RAW мы используем Apache Flume. Для обеспечения отказоустойчивости и независимости от кластера Hadoop мы разместили Flume на отдельном сервере – получили такой как бы File Gate, перед кластером Hadoop. Ниже приведу пример настройки агента Flume для передачи портального syslog:
# *** Clickstream PROD syslog source ***
a3.sources = r1 r2
a3.channels = c1
a3.sinks = k1
a3.sources.r1.type = syslogtcp
a3.sources.r2.type = syslogudp
a3.sources.r1.port = 5141
a3.sources.r2.port = 5141
a3.sources.r1.host = 0.0.0.0
a3.sources.r2.host = 0.0.0.0
a3.sources.r1.channels = c1
a3.sources.r2.channels = c1
# channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
# sink
a3.sinks.k1.type = hdfs
a3.sinks.k1.channel = c1
a3.sinks.k1.hdfs.path = /prod_raw/portal/clickstream/ymd=%Y-%m-%d
a3.sinks.k1.hdfs.useLocalTimeStamp = true
a3.sinks.k1.hdfs.filePrefix = clickstream
a3.sinks.k1.hdfs.rollCount = 100000
a3.sinks.k1.hdfs.rollSize = 0
a3.sinks.k1.hdfs.rollInterval = 600
a3.sinks.k1.hdfs.idleTimeout = 0
a3.sinks.k1.hdfs.fileType = CompressedStream
a3.sinks.k1.hdfs.codeC = bzip2
# *** END ***
Таким образом, мы получили стабильный поток данных в слой RAW. Дальше нужно разложить эти данные в модель, наполнить Data Vault, ну короче нужен ETL на Hadoop.
Барабанная дробь, гаснет свет, на сцену выходит Informatica Big Data Edition. Не буду в красках и много рассказывать про этот ETL инструмент, постараюсь коротко и по делу.
Лирическое отступление. Хочется сразу отметить, что Informatica Platform (в которую входит BDE), это не та всем знакомая Informatica PowerCenter. Это принципиально новая платформа интеграции данных от корпорации Informatica, на которую сейчас постепенно переносят весь тот большой набор полезных функций из старого и всеми любимого PowerCenter.
Теперь по делу. Informatica BDE позволяет достаточно быстро разрабатывать ETL процедуры (маппинги), среда очень удобная и не требует длительного обучения. Маппинг транслируется в HiveQL и выполняется на кластере Hadoop, Informatica обеспечивает удобный мониторинг, последовательность запуска ETL процессов, обработку ветвлений и исключительных ситуаций.
Например, вот так выглядит маппинг, который наполняет хаб интернет юзеров нашего портала (см. Рис. 3).
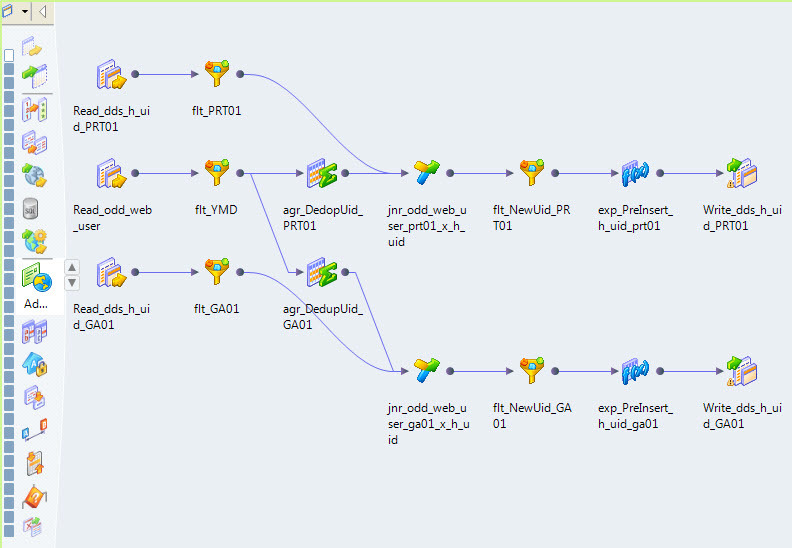
Рис.3 Маппинг
Оптимизатор Informatica BDE транслирует этот маппинг в HiveQL и сам определяет шаги исполнения (см. Рис. 4).

Рис.4 План выполнения
Informatica BDE позволяет гибко управлять параметрами среды выполнения. Например, мы у себя настроили следующие параметры:
mapreduce.input.fileinputformat.split.minsize = 256000000
mapred.java.child.opts = -Xmx1g
mapred.child.ulimit = 2
mapred.tasktracker.map.tasks.maximum = 100
mapred.tasktracker.reduce.tasks.maximum = 150
io.sort.mb = 100
hive.exec.dynamic.partition.mode = nonstrict
hive.optimize.ppd = true
hive.exec.max.dynamic.partitions = 100000
hive.exec.max.dynamic.partitions.pernode = 10000
Маппинги можно объединять в потоки. Например, у нас данные из отдельных систем источников загружаются в отдельных потоках (см. Рис. 5).
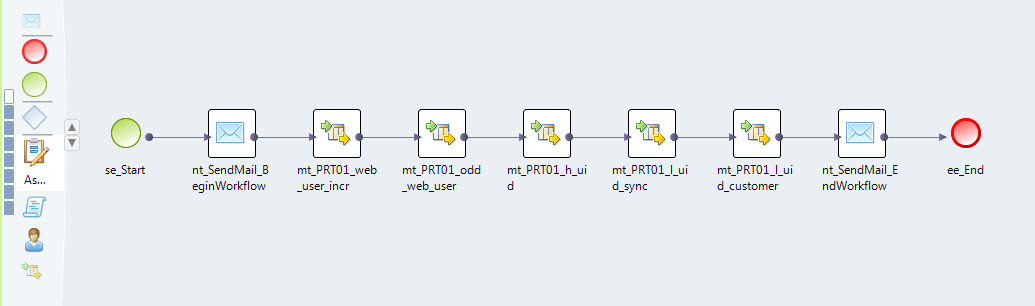
Рис.5 Поток загрузки данных
Informatica BDE обладает удобным инструментом администрирования и мониторинга (см. Рис. 6).
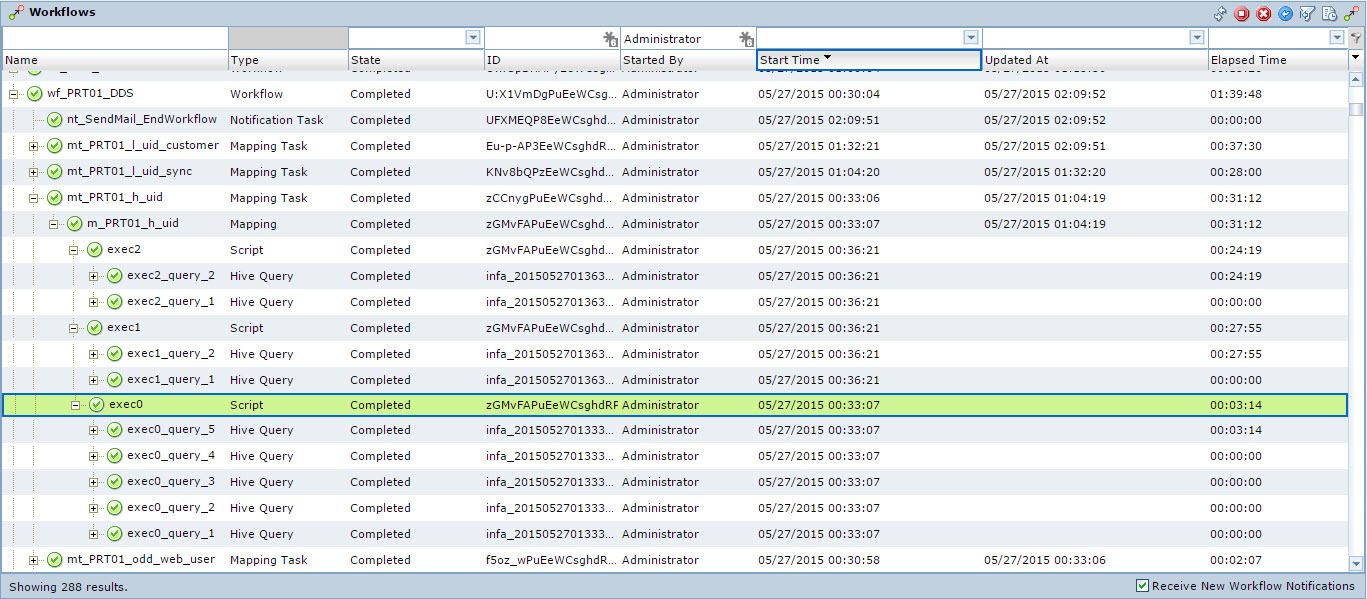
Рис.6 Мониторинг исполнения потока данных
Из преимуществ Informatica BDE можно выделить следующее:
- Поддержка множества дистрибутивов Hadoop: Cloudera, Hortonworks, MapR, PivotalHD, IBM Biginsights;
- Быстрая имплементация в продукт новых фич, разрабатываемых в Hadoop: поддержка новых версий дистрибутивов, поддержка новых версий Hive, поддержка новых типов данных в Hive, поддержка партиционированных таблиц в Hive, поддержка новых форматов хранения данных;
- Быстрая разработка маппингов;
- И ещё один очень важный аргумент в пользу Informatica — это очень тесное сотрудничество и партнерство с лидером рынка дистрибутивов Hadoop, компанией Cloudera. Этот аргумент позволяет определить стратегический выбор в пользу этих двух платформ, если вы решили строить Data Lake.
Из недостатков можно выделить следующее:
- Один большой, но не столь весомый, но все же недостаток – не хватает всего того множества полезных фич, которые есть в старом PowerCenter. Это гибкая работа с переменными и параметрами как внутри маппинга, так и на этапе взаимодействия workflow->mapping-> workflow. Но, новая платформа Informatica развивается и с каждой новой версией становиться более удобной.
В целом инструмент Informatica BDE весьма хорошо показал себя при работе с Hadoop и у нас на него дальше очень большие планы в части ETL на Hadoop. Думаю, в скором времени напишем ещё более предметные статьи о реализации ETL на Hadoop на Informatica BDE.
Результаты
Основной результат, который мы получили на данным этапе — это стабильно работающий ETL, наполняющий DDS. Результат был получен за два месяца, командой из двух ETL разработчиков и архитектора. Сейчас мы ежедневно прогоняем через ETL на Hadoop ~100Gb текстовых логов и получаем в Data Vault примерно на порядок меньше данных, на основе которых собираются витрины данных. Загрузка в модель происходит на ночном регламенте, загружается дневной инкремент данных. Длительность загрузки составляет ~2 часа. С этими данными, выполняя Ad-hoc запросы, работают аналитики через Hue и IPython.
Планы на будущее
- Переход на CDH 5.4 (сейчас работаем на 5.2) и пилотирование Hive 0.14 и технологию Hive on Spark;
- Обновление Informatica 9.6.1 Hotfix2 до Hotfix3. И конечно ждем Informatica 10;
- Разработка маппингов, собирающих витрины для работы машинного обучения и data scientist-ов;
- Развитие ILM в Hadoop/HDFS.
Комментарии (37)

BigD
30.05.2015 18:54+1Informatica BDE — это on premises или SaaS/Cloud?

yuryemeliyanov Автор
31.05.2015 09:33Спасибо за вопрос. Informatica BDE — это on premises. Но у Informatica есть реализация облачной платформы интеграции — Informatica Cloud.

yusman
30.05.2015 20:27+1Спасибо, интересно!
Читаю ваши статьи и поражаюсь тому как все быстро и просто у вас все получается
Скажите Informatica platform умеет так же «пушдаунить» трансформации на green plum?
Если да, то зачем вообще Hadoop нужен?yuryemeliyanov Автор
31.05.2015 09:49Спасибо за вопрос. Ну не так уже и быстро и просто, работы много, но мы стараемся :)
Новая Informatica пока пушдаунить на Greenplum не умеет, с этой задачей хорошо справляется Informatica Power Center.
Про зачем нужен Hadoop — ну например вопрос стоимости хранения, в Hadoop хранить данные в 7-9 раз дешевле чем в Greenplum. При этом Greenplum у нас остаётся, мы можем строить в Hadoop витрины с агрегатами или различные сегментации и поднимать их в Greenplum. Ещё важный аргумент в сторону использования Hadoop — это не только среда хранения и но платформа работы с данными, т.е. мы не разрываем эти два понятия и наши аналитики работают, строят модели и исполнят их в Hadoop.yusman
31.05.2015 17:50+1Вот насчет последнего…
Мне сложно представить как например связывать большие таблицы если мы не понимаем как они хранятся в hadoop, тем более у вас data vault где таблицы по умолчанию как бы «в нормализованном виде». Hadoop не разложит их так, что они будут очень не эффективно вязаться и скорость работы будет еще хуже чем при традиционных СУБД??
А не смотрели в сторону postgre-xl? Бесплатно, работает, можем контролировать то как таблица размазывается по кластеру…yuryemeliyanov Автор
31.05.2015 18:38Да, согласен. Но мы то как раз следим за тем как мы загружаем данные в Data Vault. Мы раскладываем все данные по партициям и используем кластаризацию и бакетирование. Это позволяет нам снизить обмен по сети когда мы строим какие либо запросы на таблицах в Data Vault. И конечно же простое использование Data Vault не очень то эффективно, а вот построение прикладных витрин на Data Vault даёт возможность повысить эффективность запросов. Postgre XL не пробовали, у нас GreenPlum есть :)

Tutufa
30.05.2015 20:52+2Платили за какие либо лицензии или подписки, если да, то зачем, почти все опенсорсное, какие преимущества у платных версий? Если так много данных, то почему не Apache Storm?
yuryemeliyanov Автор
31.05.2015 16:10+1Да, Informatica это платное удовольствие :) Apache Storme — это потоковая обработка данных, нам же нужен был батч процесс, ETL, т.к. несколько источников данных, а одна из задач это построение консолидированного представления данных по этим источникам. Ничего не имеем против опенсорса, иначе бы не пошли в сторону Hadoop. Преимуществ у Informatica несколько — это продукт, а не фреймворк, это наличие метаданных, это уже реализованный мониторинг и администрирование, это удобная и не сложная среда разработки, это, что не мало важно, среда разработки и реализации разделены со средой исполнения. Пример по последнему пункту очень простой. Представьте что у вас есть уже написанные батч процессы на mr, на java и тут выходит spark и вы начинаете это всё переписывать, и всё что из этого вытекает, на spark… Когда у вас продукт, в нашем случае Informatica, мы не занимаемся переписыванием всего написанного.

Don_Eric
31.05.2015 19:46+1А если не секрет, какая примерно стоимость этого удовольствия (сервера, лицензии...)? Десятки или сотни тысяч долларов в месяц?
yuryemeliyanov Автор
31.05.2015 20:38В совокупности конечно же сотни. В совокупность входит: инфраструктура Hadoop, инфраструктура ETL, инфраструктура Flume. Это не считая инфраструктуру традиционного DWH, о котором тоже упоминал в статье.

CBuH
31.05.2015 12:59DWH, ETL, WTF и т.д сначала бы расшифровали эти аббревиатуры потм писали, в гугле не забанили, но это как то не правильно

skullodrom
02.06.2015 17:24>Как и в классическом DWH, мы выделили основные концептуальные слои данных
Ну если уж совсем придерживаться концепции слоев то RAW это STG, ODD это ODS, а DDS в принципе тоже правильно, но я обычно использую DWH.
>Apache Flume.
Что всегда удивляет, так это никогда не повторяющееся сочетания софта и технологий, они всегда новые =) Нет стабильности в мире BigData =)
На счет того что существует Informatica BDE большой респект! не знал это она есть. Но сразу могу вам дать совет вопрос:
> не хватает всего того множества полезных фич, которые есть в старом PowerCenter
А вы можете его использовать тоже, просто target будет сперва РСУБД, а потом уже Hadoop. Но опять же вопрос, на сколько PowerCenter подходит для ваших данных и ETL.
>Hive
Я не знаток NoSQL технологий, но разве стандартный Hive+Hadoop не тормозной? Слышал что все переходят на parquet, storm, Impala, Drill и т.д. Почему именно остановились на Hive+Hadoop?yuryemeliyanov Автор
02.06.2015 19:40Спасибо за комментарии.
Нет стабильности в мире BigData
Я бы сказал иначе — в мире BigData все течет, все изменяется :) Технологии развиваются, становятся более стабильными, BigData медленно но верно движется в сегмент Enterprise.
на сколько PowerCenter подходит для ваших данных и ETL
PowerCenter не умеет делать PDO на Hadoop.
Hive+Hadoop не тормозной
Hadoop со своей экосистемой развивается и в направлении операционной аналитики, а значит и запросы на Hive и сам Hive становится более производительным. Parquet — это колоночный формат хранения данных в HDFS, с которым также работает Hive. Storm, писал выше, это потоковая обработка данных, нам же нужен был батч процесс. Impala — используем для ad-hoc, PDO на Impala Informatica BDE делать не умеет. Drill не используем.
Надеюсь ответил на ваши вопросы.skullodrom
03.06.2015 02:18Вполне!
Статья хорошая, но требует продолжения.
Например, производительность запросов на вышей системе?
Давайте я буду сторонником традиционных подходов и уверен, что на ваших объемах Оракл и Терадата уделают вас в производительности запросов в 10 раз, а вы будите отстаивать противоположную точку зрения? =)
Иначе я пока сомневаюсь в целесообразности использование не стандартных подходов, точно ли у вас конечный формат данных, характер запросов и объемы данных лучше укладываются в стек технологий Big Data нежели традиционные DWH? Я в этом не уверен и не вижу ответа в статьи!
DIegoR
04.06.2015 00:03Ну, у них же там есть Greenplum — наверное можно спихивать туда то, что уже проструктурировали. Это как бы маленькая Терадата.
А так, для не очень еще понятной информации хадуп наверное в 100 раз дешевле Терадаты в пересчете на Гигабайт места (особенно при апгрейде).yuryemeliyanov Автор
04.06.2015 10:59Да, все верно, можно какие-нибудь агрегаты/витрины поднимать в Greenplum.
Это как бы маленькая Терадата
спорное утверждение, когда GreenPlum кластер из 16 серверов :)
Вопрос стоимости хранения гигабайтов очень важный! skullodrom Oracle и Teradata под одну гребенку не нужно. Здесь скорей всего по стоимости хранения будет следующий порядок, по убыванию:
- Oracle
- MPP
- Hadoop
При этом цены будут различаться примерно в порядок.skullodrom
04.06.2015 13:47>спорное утверждение, когда GreenPlum кластер из 16 серверов :)
смотря какие сервера :)
Стандартная Терадата 2750 года полтора назад имела на борту 432 ядра и 432 винта и 6 Тб оперативки. А сколько у вас?
Я бы сказала даже так, по стоимости хранения будет следующий порядок, по убыванию:
Teradata (+ со всеми фичами типа колоночное хранение)
Exadata
Oracle
Другие MPP
Hadoop
>При этом цены будут различаться примерно в порядок.
Более или менее согласен
Юрия, а вы выбрали Hadoop именно по причине низкой стоимости за Гб или были другие причины?
А почему выбрали Greenplum, а не Vertica, Netezza?
Кстати у Терадаты есть свой Hadoop, называется AsterData, вроде как там стоимость хранения более чем на порядок дешевле, не рассматривали ее?

yuryemeliyanov Автор
04.06.2015 14:19по причине низкой стоимости за Гб или были другие причины?
и это тоже. Где как не в Hadoop предлагаете хранить гигантские объемы неструктурированных данных?
А почему выбрали Greenplum, а не Vertica, Netezza?
на тот момент когда выбирали Netezza была морально устаревшей, а Vertica сыроватой. Выбирали бы сейчас, с большой долей вероятности выбрали бы Vertica.
называется AsterData
все эти сборки хадупов от больших вендоров (PivotalHD, IBM Biginsights, AsterData...) развиваются медленней. Нам интересен Spark по этому Cloudera. Хотя вот у PivotalHD есть замечательный HAWQ, который по производительности работы запросов показывает себя очень и очень хорошо…

gtbear
Конечно это все круто, но что вы с этими данными делаете? Какой конечный профит кроме того что все просто работает?
yuryemeliyanov Автор
Очень ожидаемый вопрос, спасибо. Основная цель сейчас — на этих данных начать прорабатывать архитектуру и работу нашего озера, накапливать данные, делать Ad-hoc-и на этих данных, строить исследовательские модели в IPython. В дальнейшем будем строить профиль клиента 360, на основе алгоритмов машинного обучения. Также есть в планах построение маркетинговой системы, скорее всего, на технологии Drools.
gtbear
это все равно не то о чем хотелось бы узнать. Вот вы что, будете рекомендовать что-то пользователям? или будете антифрауд с этим облаком интегрировать? бизнес задача какая стоит?
просто настроить data lake и сказать какие мы молодцы или все таки решить какую то проблему клиентов/бизнеса.
yuryemeliyanov Автор
А по полученному профилю клиента, читай как сегментацию, нельзя можно будет рекомендовать что-то? Конечно можно. Бизнес задача у нас есть и не одна. Тинькофф Банк это не НИИ, здесь любые начинания в технологиях должны ориентироваться на получение бизнес результата. И да, это не облако, bigdata кластер как и другая инфраструктура банка находится в дата-центре.
ALIron
Клиент 360 имеется ввиду подход «Customer 360» в традиционном смысле?
Есть ли связка пусть и опосредованная клиент банка (счет) — активность в соц. сети?
yuryemeliyanov Автор
Да, речь идет об этом подходе. Конкретно такой связки у нас нет. Есть другие :)
ALIron
Тогда где Data quality часть? или все на прямом сравнении?
yuryemeliyanov Автор
Не понял про «все на прямом сравнении», это про что?
DQ часть Greenplum, в Hadoop пока только проектируем.
ALIron
Для того чтобы понять что вот этот ID с куками и клиент №324 Иванов Иван это одно и то же лицо нужно сравнить реквизиты которые доступны.
А так как качество данных всегда не идеально часть данных отваливается по несовпадению каких то атрибутов.
Или пока главное свести хотя бы 80%? Остальные 20 будем допиливать в процессе?
yuryemeliyanov Автор
80% — довольно хороший результат, качество данных будем улучшать :)
ALIron
Так то да.
Для аналитики трендов «третий сорт — не брак», а вот включать в бизнес-процесс и тем более принимать решения на основе 80% довольно смело.
Можно конечно вспомнить про Парето, но проводить аналогию всё более неуместно.
Вы же не будете рады если хирург учтёт только 80% диагноза.
Так и в аналитике. Конечная цель — принятие решения, а конкуренция заставляет сужать дельту недостаточности информации всё больше.
Jabher
Вообще Data Lake — это как раз парадигма «сохраняем все-все данные, авось потом пригодится», так что это скорее задел на будущее
yuryemeliyanov Автор
Да, согласен. Но хочу дополнить, должен быть некий рациональный баланс. Если мы для какой либо задачи, бизнес задачи, поняли, что надо собирать какие то данные, то мы не замарачиваеся на начальном этапе анализом этих данных — начинаем собирать/сохранять все.