Хабр, привет! Сложно поверить, но 16 марта мы запустим уже 6 набор нашей программы “Специалист по большим данным”.

На текущий момент у нас уже около 160 выпускников, которые с разной степенью вовлеченности применяют знания и навыки, полученные на программе. Наверное, можно задаться вопросом, нужно ли такое количество кадров. Ответа на это резонное сомнение есть два. Во-первых, мы держим руку на пульсе и периодически проводим анализ рынка. Во-вторых, рынок не является статичной сущностью и растет, причем количество открытых вакансий не является достаточной метрикой для измерения этого спроса.
Два года назад, когда мы запускали программу первый раз, необходимости в таком количестве специалистов не было. Но, как оказалось впоследствии, большая часть наших слушателей не меняют место работы, а используют полученные навыки и знания в своих компаниях. И в большинстве своем эти вакансии не публикуются в открытом доступе, потому что таких позиций даже пока нет.
Компаний, внедряющих технологии больших данных, становится все больше и больше. Именно поэтому мы запустили отдельную программу для руководителей, которые присматриваются сейчас к этой теме и собираются проводить грамотное внедрение этих технологий в будущем.
Если вспомнить кривую распространения инноваций и технологий на рынке, то станет понятно, что этот рост может продолжаться и дальше.
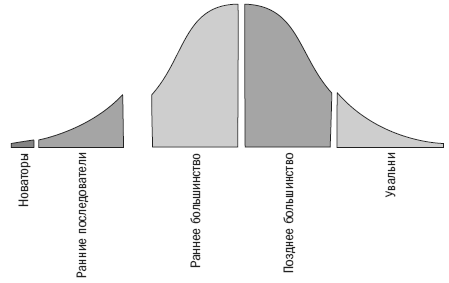
На текущий момент инструменты для работы с большими данными внедрили скорее всего первые два класса: новаторы и ранние последователи, и только начинают подключаться и представители раннего большинства.
Как резюме: оснований полагать, что потребность в специалистах по большим данным уменьшится, нет. Скорее, наоборот, будет расти. Популярная сейчас фраза, что данные — это новая нефть, не совсем верна. Данные лучше, чем нефть. К данным может иметь доступ каждый, если научится их правильно собирать и обрабатывать, чего нельзя сказать о нефти. Так что приходите к нам учиться.
Несмотря на то, что это уже 6 запуск, мы продолжаем работать над продуктом и решили добавить в него кое-что нового.
1) Раньше у нас было 12 лаб: по одной на каждую неделю программы. В этот раз мы решили сделать 10 лаб и 2 “выпускных” проекта, к которым слушатели будут готовиться в течение всего модуля. Один проект будет называться “Прогнозирование пола и возрастной категории пользователя по веб-логам”, а второй — “Построение рекомендательной системы для онлайн-ритейла”. У вас будет достаточно времени поработать над ними и сделать из них нечто такое, чем можно будет гордиться и что можно будет добавить себе в портфолио работ.
2) Периодически нас просили сделать в программе групповые задания. В этот раз часть лабораторных работ предполагают групповую работу. Так что будет повод еще сильнее подружиться друг с другом.
3) В настоящий момент мы оптимизируем работу наших автоматических чекеров лабораторных работ, чтобы проверка занимала минимальное время и “не бесила”. Плюс добавим индикатор прогресса на программе. В любой момент можно будет посмотреть, достаточно ли там баллов для того или иного сертификата или нет.
4) Традиционно на нашем кластере будут стоять все самые современные и актуальные библиотеки и, конечно же, последняя версия Apache Spark. Процентов 80-90 работы в этом инструменте будет проходить на датафреймах. Во время прошлого запуска мы провели миграцию наших учебных материалов с RDD на эту структуру данных.
Ждем вас на программе. Скучно не будет!
На текущий момент у нас уже около 160 выпускников, которые с разной степенью вовлеченности применяют знания и навыки, полученные на программе. Наверное, можно задаться вопросом, нужно ли такое количество кадров. Ответа на это резонное сомнение есть два. Во-первых, мы держим руку на пульсе и периодически проводим анализ рынка. Во-вторых, рынок не является статичной сущностью и растет, причем количество открытых вакансий не является достаточной метрикой для измерения этого спроса.
Два года назад, когда мы запускали программу первый раз, необходимости в таком количестве специалистов не было. Но, как оказалось впоследствии, большая часть наших слушателей не меняют место работы, а используют полученные навыки и знания в своих компаниях. И в большинстве своем эти вакансии не публикуются в открытом доступе, потому что таких позиций даже пока нет.
Компаний, внедряющих технологии больших данных, становится все больше и больше. Именно поэтому мы запустили отдельную программу для руководителей, которые присматриваются сейчас к этой теме и собираются проводить грамотное внедрение этих технологий в будущем.
Если вспомнить кривую распространения инноваций и технологий на рынке, то станет понятно, что этот рост может продолжаться и дальше.
На текущий момент инструменты для работы с большими данными внедрили скорее всего первые два класса: новаторы и ранние последователи, и только начинают подключаться и представители раннего большинства.
Как резюме: оснований полагать, что потребность в специалистах по большим данным уменьшится, нет. Скорее, наоборот, будет расти. Популярная сейчас фраза, что данные — это новая нефть, не совсем верна. Данные лучше, чем нефть. К данным может иметь доступ каждый, если научится их правильно собирать и обрабатывать, чего нельзя сказать о нефти. Так что приходите к нам учиться.
Несмотря на то, что это уже 6 запуск, мы продолжаем работать над продуктом и решили добавить в него кое-что нового.
1) Раньше у нас было 12 лаб: по одной на каждую неделю программы. В этот раз мы решили сделать 10 лаб и 2 “выпускных” проекта, к которым слушатели будут готовиться в течение всего модуля. Один проект будет называться “Прогнозирование пола и возрастной категории пользователя по веб-логам”, а второй — “Построение рекомендательной системы для онлайн-ритейла”. У вас будет достаточно времени поработать над ними и сделать из них нечто такое, чем можно будет гордиться и что можно будет добавить себе в портфолио работ.
2) Периодически нас просили сделать в программе групповые задания. В этот раз часть лабораторных работ предполагают групповую работу. Так что будет повод еще сильнее подружиться друг с другом.
3) В настоящий момент мы оптимизируем работу наших автоматических чекеров лабораторных работ, чтобы проверка занимала минимальное время и “не бесила”. Плюс добавим индикатор прогресса на программе. В любой момент можно будет посмотреть, достаточно ли там баллов для того или иного сертификата или нет.
4) Традиционно на нашем кластере будут стоять все самые современные и актуальные библиотеки и, конечно же, последняя версия Apache Spark. Процентов 80-90 работы в этом инструменте будет проходить на датафреймах. Во время прошлого запуска мы провели миграцию наших учебных материалов с RDD на эту структуру данных.
Ждем вас на программе. Скучно не будет!
Поделиться с друзьями
Комментарии (5)

Tatikoma
16.02.2017 12:49Несколько смущает ценник.
Может кто-то поделиться соображениями по вопросу соответствия цены — результату?
kirilldaniluk
16.02.2017 13:39В чём выражается результат? В плане получения хардкорных доменных знаний — разумеется, их не будет, времени не хватит. Математики не будет. Но в плане нетворкинга, общения с профессионалами и широты охвата (data science + data engineering) курс отличный (я выпускник).
Курс дорогой, потому что, помимо всего прочего, для вас поднимают кластер с hadoop, spark, питоновским data-стеком и разрешают всем этим неограниченно пользоваться в течение всего курса.
longclaps
количество открытых вакансий не является достаточной метрикой для измерения этого спроса
Вот отсюда поподробнее, пожалуйста — а возникает чувство, будто нас дурят )
andybelo
Никто вас не дурит, вы же видите, как много комментариев.
a-pichugin
Целиком спрос на тех или иных специалистов — это открытые вакансии, это корпоративное обучение и это аутсорсинг. В зависимости от зрелости рынка, процентное соотношение этих частей различается.
Мысль была в том, что есть зрелые рынки труда — как рынок бухгалтеров, есть молодые рынки — как рынок data scientists. На рынке бухгалтеров все четко понимают чего хотят и если нужен бухгалтер, то просто открывают вакансию. Ни у кого нет даже мысли в таком случае отправлять кого-то из текущих сотрудников, чтобы сделать из него бухгалтера.
С data science не совсем так. Работодатель еще до конца не понимает, чего он хочет и как это развивать. Он берет отправляет своего CTO или разработчика на обучение, чтобы тот посмотрел, что со всем этим можно сделать в их компании, и стал драйвером изменений. После этого конечно уже могут появиться вакансии в компании.