
Большинство людей, которые тестируют виртуальные среды в первый раз, делают это неправильно, причем до такой степени, что компания VMware ввела в пользовательское лицензионное соглашение запрет на публикацию материалов подобного тестирования без согласования с VMware. И все потому, что им обязательно нужно оценить методологию теста.
Действительно, какой подход первым приходит в голову? Создаем виртуальную машину, ставим в нее популярный софт для теста диска, памяти, процессора и видеокарты. И уже его результаты будем сравнивать, например, с физической системой или другой виртуальной машиной.
Такой подход, хотя и не без оговорок, имеет право на жизнь, если мы говорим о ноутбуке или рабочей станции, когда виртуальная машина почти всегда одна, и от нее хочется получить максимум — запустить игру или офисное приложение «без тормозов».
Увы, когда речь идет о серверах, где много виртуальных машин, такая методика совершенно бесполезно, потому что на ее основании нельзя сделать практически никаких выводов.
Почему?
Во-первых, никто не использует сервер, чтобы запускать одну виртуальную машину, их почти всегда много; и если например у одной оказывается высокая производительность в ущерб другой (такое вполне возможно при плохо работающем планировщике задач), платформа в принципе очень плоха – но тест этого не покажет!
Во-вторых, у виртуальной машины на сервере почти всегда ограничены ресурсы – и речь идет не о 90%, а зачастую лишь о единицах процентов ресурсов сервера. При этом две разные платформы на одной, пяти или десяти виртуальных машинах виртуализации могут показать одинаковые результаты. Значит ли это, что системы одинаково хороши или плохи? Совершенно не обязательно! Ведь разные решения могут по-разному работать с памятью, использовать процессорное время или виртуализировать дисковые операции. И до тех пор, пока на сервере есть свободные ресурсы, разница между различными платформами будет незаметна. Но ресурсы всегда заканчиваются, ведь по сути в том и есть смысл виртуализации, чтобы использовать ресурсы по максимуму. И решение, у которого они закончатся раньше, в реальной жизни покажет результаты хуже, но изложенным методом мы не сможем этого узнать.
В-третьих, у гипервизоров есть свой набор «ахиллесовых пят» — определенных шаблонов нагрузки, при которых каждый из них покажет особенно плохие результаты. В зависимости от того, насколько много нагрузки по подобным шаблонам подразумевает тестирование, результаты могут отличаться в разы. Несложно подобрать или написать тест, который покажет «нужные» результаты – хорошие либо плохие – и куда сложнее сделать тест, который выдаст результаты полезные и объективные.
Как тестировать будем, господа?
Впрочем, виртуализации на базе архитектуры Intel уже почти 20 лет, и для людей, работающих в этой сфере, тема benchmarking совершенно не нова. За прошедшие годы уже выработался некий «золотой стандарт» подобного тестирования. Опуская некоторые детали, подход можно сформулировать следующим образом:
• Создать систему из нескольких виртуальных машин с типичными серверными приложениями (туда обычно включается сервер с базой данных, сервер какого-нибудь тяжелого Java приложения, почтовый сервер, файловый сервер и прочее),
• Получить от этих приложений интегральные очки-баллы, характеризующие производительность каждой из таких систем.
• Добавляя новые подобные системы, складывать баллы
• Оценивать решение по сумме баллов при равных конфигурациях (когда разнице только в одном параметре – в самой системе виртуализации).
Такое тестирование безусловно не дает ответов на все вопросы. Например, потому что набор эталонных нагрузок может сильно отличаться от того, что реально нужно клиенту – и реальные нагрузки могут дать совсем другие результаты (вспомним «ахиллесовы пяты» средств виртуализации). Но это все-таки гораздо лучше, чем тот «подход в лоб», который мы обсудили в самом начале.
Мы, в компании Virtuozzo, имеем дело в основном с облачными сервисами и знаем, что об этом думают клиенты, а не только поставщики услуг (которые выбирают производителя платформы виртуализации). Им часто все равно, какая система виртуализации была использована, так как ему важна лишь производительность того виртуального сервера, который он купил. А уж как она достигнута – при помощи более производительного гипервизора, более производительного железа или просто размещением меньшего количества клиентов на каждом сервере – заказчику совсем не важно.
С точки зрения клиента «десктопный» подход имеет право на существование — те самые процессорные, дисковые и прочие «попугаи», которые намеряют подобные тесты, – они и показывают насколько купленный сервер стоит своих денег. Получается, что поставщику услуг нужно одно, а потребителю – другое.
Золотая середина?
Но не так давно у нас запустился небольшой проект с компанией-партнером Cloud Spectator, где нам пришлось разобраться – а можно ли сделать тест, который протестирует серверную виртуализацию, но с точки зрения клиента? Как нам кажется, мы нашли подход – если и неидеальный, то вполне имеющий право на существование.
Для справки. Cloud Spectator тестирует производительность облачных серверов, и делает это по сути «десктопным» методом – запуская тесты вроде geekbench и fio внутри одной виртуальной машины и собирая их результаты в течение длительного времени (например, полные сутки за один рабочий день). Вы можете почитать подобный отчет, где наилучшую производительность показал один из облачных сервисов от компании 1&1.
Наш эксперимент, в котором мы протестировали две разных платформы виртуализации подобным методом, дал интересные результаты. Нам пришлось сначала вывести тестируемые сервера на «производственную нагрузку» (назовем эту нагрузку «балластной»). Единственная ее цель – загрузить сервера в равной степени, создавая «прочие равные условия».
Сами сервера были вполне типичны для современных провайдеров – не самый high end, но цель была и не в максимальных цифрах, а в получении данных, которые можно сравнивать друг с другом.
CPU: 2 x Intel Xeon E5-2620
RAM: 64GB (4 x 16GB DDR4-2133 ECC REG)
Storage: LSI 9271-8i (8-port SAS2, 1GB) RAID0 over 8 x HGST 450GB 15K RPM
Чтобы создать одинаковую балластную нагрузку на оба сервера, мы воспользовались другим тестом, который у нас уже был сделан ранее. Он эмулирует работу веб сервера, к которому приходят клиенты. Обычно мы используем этот тест для измерения максимально достижимой плотности виртуальных серверов на один физический по следующей методике: добавляя больше и больше виртуальны серверов, мы измеряем скорость ответа, и прекращаем тест, когда 95-й перцентиль превышает 4 секунды, считая максимальную плотность достигнутой.
Вот пример графиков, которые данный тест строит для разных систем виртуализации:
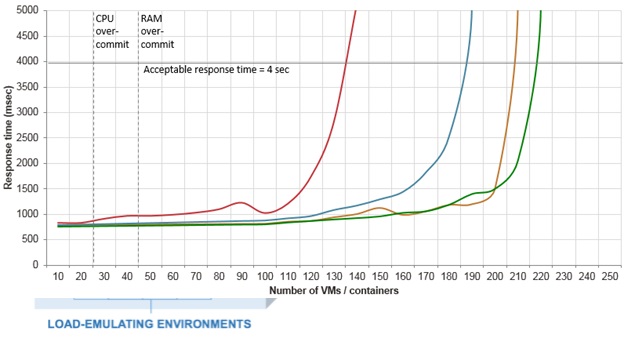
Но сегодня мы решили использовать этот тест по-другому – зафиксировать количество виртуальных серверов, но изменять частоту запросов в секунду.
При подготовке к тестированию мы создали равное количество таких виртуальных серверов (по 50) на обоих хостах и начали загружать их с нескольких клиентов в равной степени, постепенно увеличивая частоту входящих запросов. Когда оба сервера начали показывать степень загрузки CPU близкую к 100%, мы остановились и зафиксировали балластную нагрузку на таком уровне (мотивация – большинство провайдеров хочет загрузить сервера почти на 100% но так, чтобы не страдали клиенты).
Далее, на обоих хостах мы создали 51-й сервер и отдали его Cloud Spectator для того, чтобы протестировать «клиентский взгляд на производительность». То есть тестовый «стенд» выглядел примерно таким образом:
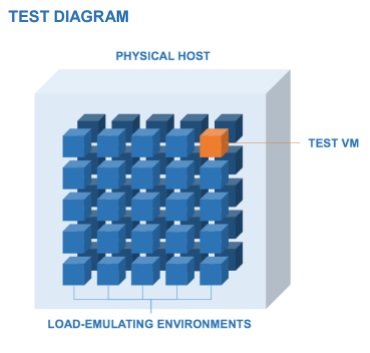
Как вы уже догадались, наша система виртуализации выиграла по результатам теста (полный отчет можно посмотреть вот по этой ссылке), но суть данного поста не в этом. Главное, что у нас получилась методика, которая позволяет провайдеру облачных услуг оценивать, как изменение одного из параметров системы «при прочих равных», отражается на уровне производительности, который получает его клиент.
Интересные факты…
1. Производительность может резко упасть
В ходе теста нам удалось выяснить некоторые любопытные факты. Например, мы узнали, что небольшое изменение «балластной» нагрузки может приводить к сильным провалам производительности у тестового клиента. Причем реально небольшое – порядка 10-15% увеличения приводят к тому, что результаты тестов ухудшаются в разы, потому что существует некий лимит нагрузки, превышение которого приводит к провалу. Вот график производительности geekbench, который мы сняли, подбирая балластную нагрузку.
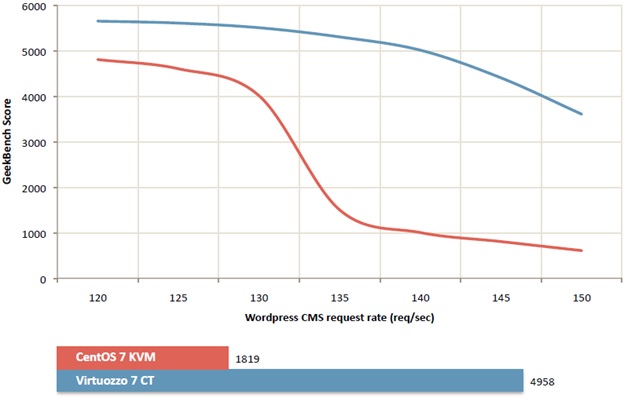
Как видите, при увеличении количества клиентских запросов на балластной нагрузке примерно от 125 до 135 запросов в секунду, производительность тестируемого окружения на «первой сдавшейся» платформе падает в несколько раз. Такое падение невозможно воспроизвести при повышении нагрузки на одного или нескольких клиентов – ресурсная изоляция виртуализации не позволит им израсходовать все ресурсы. Но если это произойдет на многих или на всех клиентах одновременно, подобное падение производительности вполне возможно.
Отсюда напрашивается вывод: если вы используете облачный сервер и ваш вебсайт сильно тормозит в определенные часы – возможно, ваш провайдер создал слишком много клиентов на одном сервере – и это было незаметно только «до поры — до времени».
2. Хотите производительность? Ее нужно постоянно измерять!
Это нужно делать и провайдеру, который хочет, чтобы его клиенты не жаловались, и самому клиенту. В реальной жизни нагрузка на физический сервер отличается в разное время суток, поэтому обычно Cloud Spectator тестирует сервер непрерывно в течение 24 часов, чтобы охватить полный суточный цикл работы. Для однократного тестирования этого может быть достаточно (если конечно эти 24 часа не выпадут на выходные), но в реальной жизни ситуация может измениться и в более длительной перспективе. Ваш виртуальный сервер может попасть на физический сервер в числе первых – и все будет «летать» пока там не создадут сервера для остальных клиентов. Вокруг вас могут оказаться «пустые» облачные сервера, которые заполнятся реальными нагрузками через месяц или два. В конце концов, производительности может хватать до тех пор, пока не наступит сезон онлайн покупок перед праздниками.
3. Ну и последнее – «быстро и дешево» не бывает.
Оборудование, сеть, дата-центры, электричество – все стоит денег. «Стандартные» средства оптимизации расходов вроде использования оборудования с максимальным соотношением производительности/цена применяют почти все провайдеры, но тут много не выжать. Единственный способ продавать свои сервисы дешевле рынка и при этом не уходить в минус – запускать больше клиентов на одном сервере. Но такой подход всегда идет в ущерб производительности – или сейчас, или в скором будущем. Поэтому, если для вас важна производительность облачного сервиса, цена не должна быть единственным фактором при выборе поставщика услуг.
Комментарии (10)

moruga
04.03.2017 01:00C player/Workstation сравнивать не очень полезно. Это не серверная платформа — она не расчитана на запуск и управление множеством машин на одном сервере, у нее основные оптимизации производительности вокруг других вещей (вроде виртуальной графики), из за этих вещей она заведомо покажет плохие результаты для серверных приложений. Никто серьезно не рассматривает этот продукт для серверов.
С ESX история чуть сложнее — как кстати и написано в статье, по EULA VMware результаты бенчмаркинга нельзя публиковать без согласования с VMware. Мы на самом деле меряли их платформу, но результаты были не очень интересные (не было никаких сюрпизов, производительность отличалась от KVM только в деталях), поэтому решили не тратить ресурсы на эти согласования и убрали их упоминания из финального отчета

mrobespierre
04.03.2017 01:51+1ну мы же все понимаем, чего стоят графики без оглашения всех настроек libvirt/qemu/kvm? я, например, могу настроить последние так, что openvz окажется в 300 раз быстрее…
moruga
06.03.2017 20:58У нас не было целей «испортить» конкурентов, мы точно не применяли никаких настроек чтобы сделать их хуже. Вроде бы у инженера который ставил систему есть аккаунт на хабре — я попрошу его зайти и прокомментировать от своего имени

Amet13
04.03.2017 16:38+1Ожидал тут увидеть графики повнушительнее.
Например как сравнение старого OpenVZ: https://vz-tutorial.ru/#vz7moruga
06.03.2017 22:27Там другая методология, она дает другие результаты.
В нашей методике на обоих тестовых виртуалках стоят сравнимые ресурсные ограничения (разница только в имплементации на конкретной платформе). до тех пор пока ресурсов хватает — виртуалка показывает в основном их, а не «остаточную производительность» сервера
Спасибо кстати за ссылку, интересно
lexore
04.03.2017 20:31+1Боюсь, в своем методе тестирования вы просто поменяли местами переменные.
Грубо говоря, на первом графике видно уравнение:время = запросы * число_виртуалок
А на втором графике что-то типа:score = запросы / время
Переделаем:
время * score = запросы
время = запросы / score
Если приравнять с первым уравнением (не учитывая коэффициенты), получим
запросы / score = запросы * число_виртуалок
1 / score = число_виртуалокилиscore = 1 / число_виртуалок
Т.е. чем меньше виртуалок, тем больше score, что в общем-то логично :)
Поэтому ваш метод тестирования дает график на третьей картинке, примерно как на первой картинке, только перевернутый по оси X.
Т.е. есть некоторый уровень уровень качества и в каком-то месте он резко падает, даже от малого приращения нагрузки.
Об этом говорит и теория очередей (про которую хорошо рассказано в этой статье).
Как вы уже догадались, наша система виртуализации выиграла по результатам теста (полный отчет можно посмотреть вот по этой ссылке)
По какой ссылке, простите?
moruga
06.03.2017 22:15Боюсь, в своем методе тестирования вы просто поменяли местами переменные.
Грубо говоря, на первом графике видно уравнение: время = запросы * число_виртуалок
Не совсем так, там другой механизм роста времени (отклика).
До тех пор пока ресурсов хватает, это время отклика в основном определяется суммой latency различных процессов — прохождение запроса по сети, его анализ-обработка, формирование ответа, отсылка ответа и прохождение его по сети.
Анализ, обработка, формирование ответа — эти процессы последовательны по отношению друг к другу, конкретные обработчики как правило однотредовые (таких обработчиков может быть много, но один запрос обрабатывается одним тредом). В результате горизонтальное скалирование ресурсов помогает ему мало — то есть если добавить еще CPU сокетов — время почти не упадет; если увеличить тактовую частоту CPU в два раза — время обработки упадет (почти) в два раза (за вычетом фиксированных latency вроде сетевой).
Поэтому время ответа почти не отличается в ситуациях используется ли 30% или 70% CPU — то есть на начальном этапе нет линейного роста времени ответа с добавлением виртуалок — и на первом графике это видно, скажем при росте от 10 до 80 контейнеров время отклика остается в пределах 0.8 секунды (на KVM за это время растет примерно с тех же 0.8 до 1.1 секунды — опять же, совсем не линейно
Т.е. чем меньше виртуалок, тем больше score, что в общем-то логично :)
Там есть ограничение которое делает график нелинейным — на всех виртуалках стоят ресурсные ограничения сверху. То есть тестируемая виртуалка никогда не покажет производительности сервера целиком. в идеальном мире ее производительность вообще не будет меняться до определенного количества «балластных соседей» (в реальности чуть падает, но нелинейно). И только когда общие ресурсы заканчиваются — на ней это становится заметно.
По поводу зависимости score от количества виртуалок — вот в этой статье есть интересный график
https://virtuozzo.com/performance-expectations-containers/
это vConsolidate (SPECvirt ведет себя аналогично). Его общий score растет (с ростом к-ва VM) пока есть CPU/disk IO ресурсы. Когда они кончаются — score перестает расти и остается относительно линейным. Когда кончается память — score начинает падать из того что система начинает тратить значительно больше ресурсов на resource management (складывание-доставание из swap — типичный пример)
Поэтому ваш метод тестирования дает график на третьей картинке, примерно как на первой картинке, только перевернутый по оси X.
Да, вот это наблюдение очень похоже на правду. Хотя механизмы формирования нагрузок и снятия параметров по сути очень разные — в первом случае мы добавляем соседей и меряем их среднюю производительность; во втором мы плавно увеличиваем «аппетит» соседей, их производительность не меряем но смотрим на производительность одной виртуалки
Но при этом важный для нас параметр — это «эластичность» системы при росте нагрузки. Если нагрузки на всех соседях выросли например на 30% от «рабочей» — насколько упала производительность эталонной системы? это позволяет понять насколько сервера готовы к пиковым или сезонным нагрузкам.
Тут есть параметр который зависит от конкретной системы — то что в статье которую вы привели описано как «борьба с перегрузками». Чем позже наступает момент когда эта борьба становится ресурсоемкой задачей — тем более эластична система по отношению к росту нагрузки
По какой ссылке, простите?
Прошу прощения, ссылку потеряли когда из драфта перетаскивали статью. Поправим. Вот ссылка

alexmay
Кстати, а где результаты и сравнение с VMWare ESXi или Player/Workstation?