Инструменты веб-скрапинга (web scraping) разрабатываются для извлечения данных с веб-сайтов. Эти инструменты бывают полезны тем, кто пытается получить данные из Интернета. Веб-скрапинг — это технология, позволяющая получать данные без необходимости открывать множество страниц и заниматься копипастом. Эти инструменты позволяют вручную или автоматически извлекать новые или обновленные данные и сохранять их для последующего использования. Например, с помощью инструментов веб-скрапинга можно извлекать информацию о товарах и ценах из интернет-магазинов.
Возможные сценарии использования инструментов веб-скрапинга:
- Сбор данных для маркетинговых исследований
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.) с разных сайтов для создания собственных списков поставщиков, производителей или любых других лиц, представляющих интерес.
- Загрузка решений со StackOverflow (или других подобных сайтов с вопросами-ответами) для возможности оффлайн чтения или хранения данных с различных сайтов — тем самым снижается зависимость от доступа в Интернет.
- Поиск работы или вакансий.
- Отслеживание цен на товары в различных магазинах.
Существует большое количество инструментов, позволяющих извлекать данные из веб-сайтов, не написав ни одной строчки кода «10 Web Scraping Tools to Extract Online Data». Инструменты могут быть самостоятельными приложениями, веб-сайтами или плагинами для браузеров. Перед тем, как писать собственный веб-скрапер, стоит изучить существующие инструменты. Как минимум, это полезно с той точки зрения, что многие из них имеют очень даже неплохие видео руководства, в которых объясняется, как все это работает.
Веб скрапер можно написать на Python (Web Scraping с помощью python) или R (Еще примеры использования R для решения практических бизнес-задач).
Я буду писать на C# (хотя, полагаю, что применяемый подход не будет зависеть от языка разработки). Особое внимание я постараюсь уделить тем досадным ошибкам, которые я допустил, поверив, что все будет работать легко и просто.
Зачем я это сделал и как я это использовал, можно прочитать здесь:
- Загрузка данных с сайта открытых данных data.gov.ru
- Анализ наборов данных с портала открытых данных data.gov.ru
- Использование наборов данных с портала открытых данных России data.gov.ru
Итак, я хочу извлечь информацию о наборах данных с портала открытых данных России data.gov.ru и сохранить для последующей обработки в виде простого текстового файла формата csv. Наборы данных выводятся постранично в виде списка, каждый элемент которого содержит краткую информацию о наборе данных.

Чтоб получить более подробную информацию, необходимо перейти по ссылке.
Таким образом, для того, чтобы получить информацию о наборах данных, мне необходимо:
- Пройти по всем страницам, содержащим наборы данных.
- Извлечь краткую информацию о наборе данных и ссылку на страницу с полной информацией.
- Открыть каждую страницу с полной информацией.
- Извлечь из страницы полную информацию.
Чего я делать не буду, так это самостоятельно загружать страницу с помощью HttpClient или WebRequest, самостоятельно парсить страницу.
Я воспользуюсь фреймворком ScrapySharp. ScrapySharp имеет встроенный веб-клиент, который может эмулировать реальный веб-браузер. Также, ScrapySharp позволяет легко парсить Html с помощью CSS селекторов и Linq. Фреймворк является надстройкой над HtmlAgilityPack. В качестве альтернативы можно рассмотреть, например, AngleSharp.
Чтобы начать использовать ScrapySharp, достаточно подключить соответствующий nuget пакет.
Теперь можно воспользоваться встроенным веб-браузером для загрузки страницы:
//Создать веб-браузер
ScrapingBrowser browser = new ScrapingBrowser();
//Загрузить веб-страницу
WebPage page = browser.NavigateToPage(new Uri("http://data.gov.ru/opendata/"));Страница вернулась в виде объекта типа WebPage. Страница представляется в виде набора узлов типа HtmlNode. С помощью свойства InnerHtml можно посмотреть Html код элемента, а с помощью InnerText — получить текст внутри элемента.
Собственно, чтобы извлечь необходимую информацию, мне необходимо найти нужный элемент страницы и извлечь из него текст.
Вопрос: как посмотреть код страницы и найти нужный элемент?
Можно просто посмотреть код страницы в браузере. Можно, как рекомендуют в некоторых статьях, использовать такой инструмент, как Fiddler.

Но мне показалось более удобным использовать Инструменты разработчика в Google Chrome.

Для удобства анализа кода страницы я поставил расширение XPath Helper для Chrome. Практически сразу видно, что все элементы списка содержат один и тот же класс CSS .node-dataset. Чтобы в этом убедиться, можно воспользоваться одной из функций консоли для поиска по стилю CSS.

Заданный стиль встречается на странице 30 раз и точно соответствует элементу списка, содержащего краткую информацию о наборе данных.
Получаю с помощью ScrapySharp все элементы списка, содержащие .node-dataset.
var Table1 = page.Html.CssSelect(".node-dataset")и извлекаю все элементы div, в которых лежит текст.
var divs = item.SelectNodes("div")На самом деле, есть множество вариантов извлечения нужных данных. И я действовал по принципу «если что-то работает, то не надо это трогать».
Например, ссылку на расширенную информацию можно получить из атрибута about
<div rel="dc:hasPart" about="/opendata/1435111685-maininfo" typeof="sioc:Item foaf:Document dcat:Dataset" class="ds-1col node node-dataset node-teaser gosudarstvo view-mode-teaser clearfix" property="dc:title" content="Общая информация об Администрации Главы Республики Саха (Якутия) и Правительства Республики Саха (Якутия)">В ScrapySharp это можно сделать следующим образом:
String link = item.Attributes["about"]?.ValueСобственно, это все, что нужно для извлечения информации о наборе данных из списка.
Казалось бы, все хорошо, но это не так.
Ошибка №1. Я считаю, что данные всегда одинаковые и в них не может быть ошибок (о качестве загруженных данных я уже писал здесь Анализ наборов данных с портала открытых данных data.gov.ru).
Например, для некоторых наборов данных присутствует текст «Рекомендовано». Мне эта информация не нужна. Пришлось добавить проверку:
if (innerText != "Рекомендовано")
{
items.Add(innerText);
}Я сохраняю полученную информацию в обычные списки:
List<string> items = new List<string>()потому что в данных есть ошибки. Если я создам типизированную структуру, то мне сразу придется эти ошибки обрабатывать. Я поступил проще – сохранил данные в csv файл. Что с ними будет дальше, меня сейчас не очень волнует.
Чтобы перебрать все страницы, я не стал изобретать велосипед. Достаточно посмотреть структуру ссылок:
<div class="item-list"><ul class="pager"><li class="pager-first first"><a title="На первую страницу" href="/opendata?query=">« первая</a></li>
<li class="pager-previous"><a title="На предыдущую страницу" href="/opendata?query=&page=32">‹ предыдущая</a></li>
<li class="pager-item"><a title="На страницу номер 30" href="/opendata?query=&page=29">30</a></li>
<li class="pager-item"><a title="На страницу номер 31" href="/opendata?query=&page=30">31</a></li>
…
<li class="pager-item"><a title="На страницу номер 37" href="/opendata?query=&page=36">37</a></li>
<li class="pager-item"><a title="На страницу номер 38" href="/opendata?query=&page=37">38</a></li>
<li class="pager-next"><a title="На следующую страницу" href="/opendata?query=&page=34">следующая ›</a></li>
<li class="pager-last last"><a title="На последнюю страницу" href="/opendata?query=&page=423">последняя »</a></li>
</ul></div> Для перехода к нужной странице можно использовать прямую ссылку:
http://data.gov.ru/opendata?query=&page={0}Конечно, можно было искать ссылку на следующую страницу, но, тогда как я параллельно буду запрашивать страницы? Все что мне нужно, это определить, сколько всего страниц.
WebPage page = _Browser.NavigateToPage(new Uri("http://data.gov.ru/opendata"));
var lastPageLink = page.Html.SelectSingleNode("//li[@class='pager-last last']/a");
if (lastPageLink != null)
{
string href = lastPageLink.Attributes["href"].Value;
…Я использую простой XPath запрос для получения необходимого элемента.
Предварительно я проверил его в консоли инструментов разработчика Chrome.

Я могу пройти по всем страницам и извлечь краткую информацию о наборах данных и получить ссылки на страницы с полной информацией (паспорт набора данных).
Ошибка №2. Сервер всегда возвращает нужную страницу.
Наивно полагать, что все будет работать так, как задумано. Может пропасть интернет соединение, последняя страница может быть удалена (у меня так было), сервер может решить, что это DDOS атака. Да, в какой-то момент сервер перестал мне отвечать – слишком много запросов.
Чтобы победить ошибку, я использовал следующую стратегию:
- Если сервер не вернул страницу, повторять n раз (не до бесконечности, страницы уже может не быть).
- Если сервер не вернул страницу, не запрашивать ее сразу, а сделать таймаут на k миллисекунд. И при следующей ошибке для этой же страницы увеличивать его.
- Запрашивать не сразу все страницы, а с небольшой задержкой.
И только так я действительно смог получить все страницы.
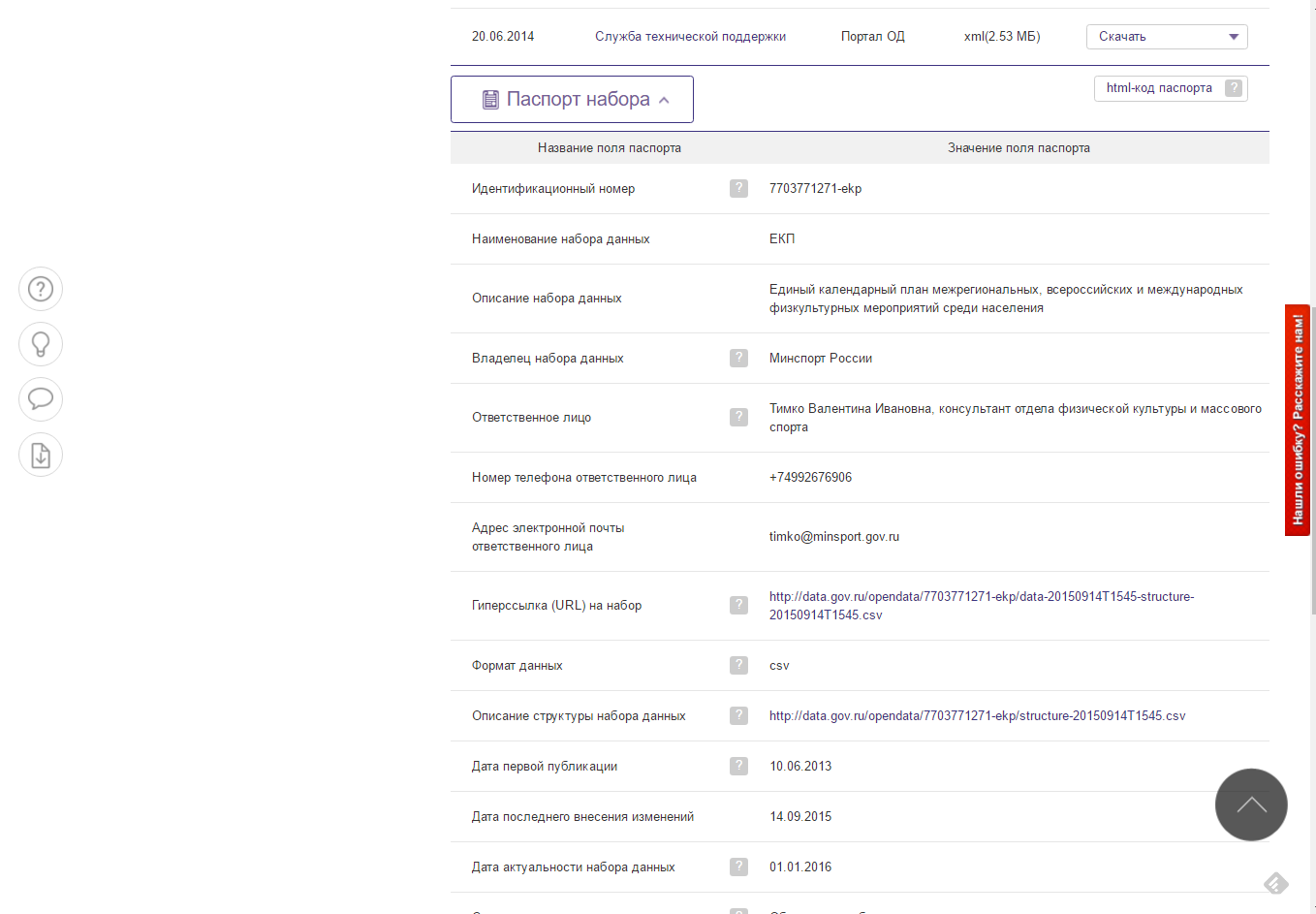
Получение паспорта набора данных оказалось простой задачей. Вся информация лежала в таблице. И мне надо было просто извлечь текст из нужной колонки.
List<string> passport = new List<string>();
var table = page.Html.CssSelect(".sticky-enabled").FirstOrDefault();
if (table != null)
{
foreach (var row in table.SelectNodes("tbody/tr")) {
foreach (var cell in row.SelectNodes("td[2]")) {
passport.Add(cell.InnerText);
}
}
}
У каждого набора данных есть оценка, которая определяется голосованием пользователей портала. Оценка расположена не в таблице, а в отдельном теге p.
Для извлечения оценки надо найти тег p с классом .vote-current-score.
var score = PageResult.Html.SelectSingleNode("//p[@class='vote-current-score']");Задача решена. Данные извлечены. Можно сохранить их в текстовый файл.
Для полноценного тестирования полученного веб-скрапера я завернул его в простой REST сервис, внутри которого запускаю фоновый процесс загрузки.

И разместил его в Azure.
Чтоб было удобно контролировать процесс добавил простенький интерфейс.

Сервис извлекает данные и сохраняет в виде файлов. Помимо этого, сервис сравнивает извлеченные данные с предыдущей версией и сохраняет информацию о количестве добавленных, удаленных, измененных наборах данных.
Выводы
Создание веб-скрапера не является сверхсложной задачей.
Для создания веб-скрапера достаточно понимать, что из себя представляет Html, как используется CSS и XPath.
Существуют готовые фреймворки, которые существенно облегчают задачу, позволяя концентрироваться непосредственно на извлечении данных.
Инструментов разработчика Google Chrome вполне достаточно для того, чтобы разобраться, что и как извлекать.
Существует множество вариантов, как извлечь данные, и все они правильные, если результат достигнут.
Комментарии (41)

Arepo
04.03.2017 18:00+6Но ведь на главной странице со списком справа вверху есть "Экспорт реестра", где, в т.ч. можно скачать уже готовый CSV со списком и всей доступной информацией по набору

AlexOleynik
04.03.2017 18:11+1Можно. Но ещё вчера там были данные за ноябрь 2016, а xls вообще был пустой

parserme
04.03.2017 18:38+2Прошло десять лет, и придумали ещё несколько умных слов, чтобы обозвать то, чем я занимался))
edogs
04.03.2017 19:21+6Напомнило «редизайн для хипстеров»
как редизайнить упаковки что бы покупали хипстеры и т.д.
и т.д.Ratimir
04.03.2017 20:35Вместо быстрого доступа к хтмл для начала генерируем х-пути тормозными либами
You can't parse [X]HTML with regex
AlexOleynik
04.03.2017 20:51-1Web scaping — термин используемый в Data Science Courses курса Getting and Cleaning Data Johns Hopkins University.
Использование c# — нормальная практика, если остальные части проекта на c#.
Простите, с чего вы решили, что эмуляция «тормозная»? Здесь проблема в скорости ответа сервера.
Если Вы внимательно читали, то могли обратить внимание, что пути генерируются просто добавлением номера страницы к известному адресу http.
И конечно готовый cvs файл с данными, ориентировочно за ноябрь 2016 (10797 записей, а на портале 12708) меня не устраивает.edogs
04.03.2017 21:10+41,2) И что это меняет?
3) В конкретной ситуации — может быть узкое горлышко и не тут, однако в подавляющем большинстве случаев эмуляция избыточна.
4) И?
Речь о том, что если взять статью какого-нибудь 9х года на тему граббинга, то она ничем от этой статьи отличаться не будет, кроме замены старого термина «граббинг» на модный «вебскапинг», использованием другого языка (при чем без каких-либо его ценных особенностей, т.е. опять же просто замена) и набором ненужных наворотов (эмуляции браузера, разбора хтмл на х-пути) потому что это «современно».
Ведь разве в статье упомянуты какие-то вещи отличающие веб-скапинг от граббинга? Нет. Эмуляция браузера зачем-то нужна? Нет. Какие-то особенности С# нужные для решения этой задачи есть? Нет. Разбор хтмл на х-пути вместо обычных регов служит какой-то цели? Нет.
Поэтому мы и отметили, что статья по сути волный пересказ стандартной статьи о граббинге из 90-тых с применением избыточных технологий и использованием модных терминов. Ценность статьи в результате сомнительна, ибо умножение сущностей без необходимости.
Что бы быть конструктивными, ответим на незаданный вопрос — в каком виде эта статья могла бы быть интересна.
Эмуляция браузера была бы интересна, если бы сайт был защищен от тупого граббинга и этой эмуляция была бы необходимой и достаточной, при чем с объяснением почему необходима и почему достаточна. В чем и есть суть и применение эмуляции браузера и отличие оной от банального хттп запроса.
Разбор на х-пути был бы интересен, если бы там был поистинне сложный и/или генерящийся на js хтмл код, который невозможно было бы втупую разобрать регами. В чем и есть суть и применение х-путей и их отличия от регов.
Веб-скапинг вместо граббинга был бы уместен, если бы извлекаемая структура данных собиралась бы из разных источников, отчасти структурированных отчасти грязных и имела бы результатом стройную базу данных. В чем и есть суть веб-скапинга и его отличия от граббинга.
C# был бы интересен, опять же, если бы там была какая-нибудь уникальная либа помогающая решать какую-то конкретную проблему.
Ну и так далее. Куча современных и модных наворотов, но бессмысленных в применении к конкретной задаче. (тут должна быть картинка с троллейбусом)AlexOleynik
04.03.2017 21:39+1Спасибо за конструктивную критику.
Не вижу смысла спорить по поводу терминологии.
Я понимаю, что Вы профессионал в данном вопросе с большим опытом (я действительно так считаю, без каких либо задних мыслей).
Но предлагаю посмотреть на все немного под другим углом: мне нужны данные, но API и готовый файл мне не подходят. Задача для меня не совсем профильная. В данном случае я занимаюсь анализом данных. В статье я пытаюсь показать простой и наименее затратный путь, максимально используя готовые решения, который помогает решить мою конкретную проблему. И при этом встроить решение в общий проект.grigor
04.03.2017 23:45Поддерживаю пользователя edogs. У меня 1-в-1 комментарии по статье возникли. Видимо, это ваш первый парсер, но задача решена, а это главное. В будущем рассмотрите для аналогичных целей PHP/Python с использованием regex (регулярный выражений). Самому недавно пришлось на работе переписывать на C# парсер финансовой аналитики, который я писал неделей ранее на PHP. Переписал на C# с HttpRequest и Regex, но ощущение было, будто из пушки по воробьям стреляю. За ссылку на ScrapySharp спасибо, кстати.
AlexOleynik
05.03.2017 01:02Можно сказать, что первый. И неизвестно когда понадобится еще. Статья — способ капитализации знаний. Комментарии — возможность получить совет профессионального сообщества.
buzzi888
05.03.2017 17:52В целом, согласен.
Вместо быстрого получения контента по хттп, используем тормозную эмуляцию браузера.
для простых сайтов — да, а что делать с динамикой? по хттп вы получите index.html для любого роута и всё.edogs
05.03.2017 18:28Динамика с Вашей точки зрения не по хттп ходит?
buzzi888
05.03.2017 18:59Я про динамический контент. Динамика ходит, только тот же JS исполнять Вы на чем будете? Просто html, понятно, можно и регулярочкой распарсить или в dom-парсер засунуть( и как белый человек, юзать jquery).
А так, phantomjs и прочие браузерные движки без самого браузера — наше всё.edogs
05.03.2017 19:18А так, phantomjs и прочие браузерные движки без самого браузера — наше всё.
Гуглу это расскажите:)
Во-первых, на грамотном сайте будет версия работающая без js, более того, нормальный аяксовый сайт будет адресную строку подменять на актуальную даже работая полностью по аякс.
Во-вторых, браузерные движки на js что делают по правильному? Берут чистые данные по хттп аякс запросом и распихивают их по хтмл слоям, т.е. сэмулировав тот же аякс запрос по хттп граббер получит чистые данные (а не неоднозначный хтмл с кучей мусора). Чуть больше времени на анализ аяксовых хттп запросов в итоге окупается более простым разбором данных.
Безусловно, Вы правы в том, что на некоторых динамических сайтах эмуляция браузера будет нужна, но наличие на сайте динамики автоматически само по себе не требует эмуляции. Напротив, скорее это редкий вариант ввиду двух вышеупомянутых вещей.

yurikgl
04.03.2017 22:28Насколько вижу, у них API есть:
http://data.gov.ru/pravila-i-rekomendacii
http://data.gov.ru/api-portala-otkrytyh-dannyh-rf-polnoe-rukovodstvo
rockin
05.03.2017 09:07+1Парсер как он есть, и несильно сложнее парсить курлом, да немодно
Куда моднее взять приблуду, изучить приблуду и сделать тож самое, что сделали б пять строчек курла, обёрнутых в foreach
Тут, как становится ясно, важен не конечный результат, а именно фреймворк.
Микроскопом вы гвозди забиваете, сэр.AlexOleynik
05.03.2017 11:58Микроскопом гвозди)))
Сколько людей — столько мнений.
Микроскоп большой удобно в руке лежит — одно удовольствие гвозди забивать (и при этом микроскопы под ногами валяются, а за молотком еще идти надо).
Конкретно здесь важен результат — за пару часов инструмент, позволяющий переодически мониторить изменения и извлекать данные (при этом легко интегрируясь с остальными частями).
Сколько бы заняло времени: поиск программиста, согласование требований, ожидание выполнения работ, приемка? Какова вероятность не «попасть на поддержку»?
Оценивая риски и выбирая вариант купить или сделать самому, я выбрал второй.
И никаких трудностей не испытал. Скорее это оказалось намного легче, можно было предположить.
Я честно напмсал, что вариантов может быть много.
Если Вы знаете как сделать быстрее и лучше — кидайте ссылки.
За это Вам только спасибо скажут
mikhovr
05.03.2017 15:46Извините, но какой поиск программиста? Какое согласование требований?
Я очень рад, что Вы справились с этим упражнением. Я иногда пишу парсеры, просто когда мне лень копировать какую-нибудь ужасно свёрстанную информацию со страницы. Но зачем тащить это на хабр? Как инструкцию для новичков? ИМХО, тогда нужна какая-то универсальная, без упоминаний шарпа и хрома.

Forbidden
05.03.2017 10:48Можно изобретать велосипеды, а можно взять A-Parser и получить из коробки многопоточность, работу с regex и XPath, сложные парсеры можно целиком писать на JavaScript(ES6)
AlexOleynik
05.03.2017 12:01Спасибо за информацию.
А его можно взять?
По ссылке предлагают его купить.
andrrrrr
05.03.2017 11:04не всем сайтам нравиться что у них перелопачивают все страницы подряд, и они выдают капчу…
wikipro
05.03.2017 11:14Спасибо за статью, для меня было очень познавательно.
Возможно вы встречали, сесть ли какое либо ПО / скрипты на питоне, для выборочного копирования статей с одной вики в другую? Pywikibot насколько я понял предназначен только для модификации конкретной вики.
ibudda
05.03.2017 11:42+1Мир не стоит на месте, домохозяйки обзавелись смартфонами, скрапбукинг уступил место веб-скрапингу
AlexOleynik
05.03.2017 12:31Точно так. А еще домохозяйки на своих смартфонах используют нейронные сети для обработки фотографий…
mikhovr
05.03.2017 15:42Как говорилось в одном очень известном кейсе на StackOverflow:
You can't parse [X]HTML with regex. Because HTML can't be parsed by regex. Regex is not a tool that can be used to correctly parse HTML. <...>
oPOCCOMAXAo
05.03.2017 16:48ну не скажите, регулярками парсить легко, да и работают они в разы быстрее, чем парсинг всей страницы построение DOM
Novosedoff
05.03.2017 16:51Довольно бессмысленная статья с учетом того, что автор не обозначил смысл извлечения данных с гос.портала. Данные на гос.портале в помойном виде, лишенном по большой чести всякого смысла.
AlexOleynik
05.03.2017 16:58Пожалуйста, обратите внимание, в начале статьи три ссылки на другие мои публикации, в которых я объясняю зачем мне нужны открытые данные и что я с ними делаю.
Novosedoff
05.03.2017 17:23Я внимательно посмотрел ваши ссылки. В одной из них Вы сами признаете, что, цитирую, «Всего около 3 % наборов данных с гос.портала реально кому-то интересны.» Что лишь подтверждает тезис об из мусорном характере. На самом деле Вы невиноваты, что не можете ответить на мой вопрос. Потому что из статей следует, что Вы смотрите на мир и свою работу сугубо техническим взглядом «вытащить-распарсить». А вопрос «зачем это нужно?» Вам даже не приходит, потому что Вам сказали что делать, вот Вы и делаете. Пусть даже бессмысленную работу.
AlexOleynik
05.03.2017 18:13Вам не кажется странным, что на портале открытых данных России «мусорные данные»?
Кого-нибудь это волнует?
А мне интересно: почему так получается.
И именно этому я уделяю внимание.
Можно сказать, что данные «мусорные».
А можно разобраться в вопросе и наглядно убедиться так это или нет.
Конечно приходится решать и технические задачи.
Анализ данных это в большей степени техническая задача.
Задачи мне никто не ставит — это целиком и полностью мое, скажем, хобби.
Не считаю, что то, что я делаю бессмысленно.
Открытые данные, тем более на официальном портале, не должны быть мусорными.

Permyakov
VisualWebRipper наше все.
namwen
Тогда уж ScrapingHub (https://scrapinghub.com)