

Добрый день! На написание этого материала меня вдохновил HunterXXI в своей статье Два провайдера одновременно или Dual ISP with VRF на Cisco. Я заинтересовался, изучил вопрос и применил на практике. Хотел бы поделится своим опытом в реализации Dual ISP на Cisco с реальным использованием одновременно двух ISP и, даже, балансировкой нагрузки.
Демо схема:
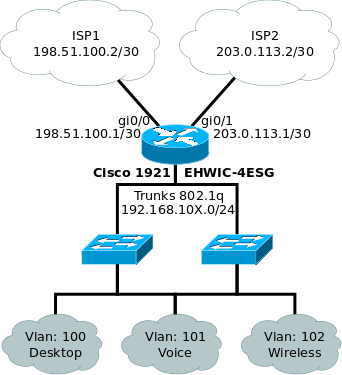
Описание:
Все действия выполняются на Cisco 1921 IOS Version 15.5(3)M3 с установленным модулем EHWIC-4ESG.
- Порты GigabitEthernet0/0 и GigabitEthernet0/1 задействованы для подключения ISP.
- Порты GigabitEthernet0/0/0 и GigabitEthernet0/0/1 сконфигурированы в TRUNK и подключены к коммутаторам.
- Для работы с локальной сетью используются VLAN интерфейсы.
- В данной схеме предусматривается три локальных IP сети 192.168.100.0/24 для VLAN 100, 192.168.101.0/24 VLAN 101 и 192.168.102.0/24 VLAN 102.
- В данном примере VLAN 100 и 101 будут иметь связь между собой но 101 будет без доступа к Интернету, а VLAN 102 будет иметь выход только в интернет.
Так задумано что бы показать возможности импорта/экспорта между VRF.
Оставшиеся физические порты не задействованы, но Вам ничто не мешает их использовать по собственному усмотрению.
Настройка Gi0/0/0 и Gi0/0/1
interface GigabitEthernet0/0/0
description TRUNK=>sw-access-1
switchport mode trunk
no ip address
end
interface GigabitEthernet0/0/1
description TRUNK=>sw-access-2
switchport mode trunk
no ip address
endКонфигурация VRF
Технология Cisco Express Forwarding (CEF) — должна быть включена для работы VRF.
Настройка VRF для ISP
ip vrf isp1
description ISP1
rd 65000:1
route-target export 65000:1
route-target import 65000:100
route-target import 65000:102
ip vrf isp2
description ISP2
rd 65000:2
route-target export 65000:2
route-target import 65000:100
route-target import 65000:102
Обратите внимание, что в конфигурации нет импорта 65000:101 который будет закреплен за VLAN 101. Таким образом виртуальные маршрутизаторы isp1 и isp2 не будут иметь маршрутов в сеть 192.168.101.0/24
Настройка VRF для VLAN
ip vrf 100
description VLAN_Desktop
rd 65000:100
route-target export 65000:100
route-target import 65000:1
route-target import 65000:2
route-target import 65000:101
ip vrf 101
description VLAN_Voice
rd 65000:101
route-target export 65000:101
route-target import 65000:100
ip vrf 102
description VLAN_Wireless
rd 65000:102
route-target export 65000:102
route-target import 65000:1
route-target import 65000:2
Снова обратите внимание на VRF 101, который не обменивается маршрутами c ISP но обменивается с VRF 100.
На своём опыте я убедился, что название VRF для ISP удобно использовать как isp1 и isp2, название VRF для VLAN должно соответствовать номеру VLAN, всё что идентифицирует VRF — description. Это связано с тем, что если, например, у Вас поменяется один из провайдеров то вся реконфигурация сведется к изменению IP адреса интерфейса и description-а.
Конфигурация интерфейсов
Применять команду ip vrf forwarding на интерфейсе нужно до назначения IP адреса. В противном случае IP адрес будет удалён и его придётся назначать заново.
WAN
interface GigabitEthernet0/0
description ISP1
ip vrf forwarding isp1
ip address 198.51.100.1 255.255.255.252
ip nat outside
interface GigabitEthernet0/1
description ISP2
ip vrf forwarding isp2
ip address 203.0.113.1 255.255.255.252
ip nat outside
LAN
interface Vlan100
description VLAN_Desktop
ip vrf forwarding 100
ip address 192.168.100.254 255.255.255.0
ip nat inside
interface Vlan101
description VLAN_Voice
ip vrf forwarding 101
ip address 192.168.101.254 255.255.255.0
ip nat inside
interface Vlan102
description VLAN_Wireless
ip vrf forwarding 102
ip address 192.168.102.254 255.255.255.0
ip nat inside
Не забудьте создать соответствующие VLAN-ы
vlan 100
name Desktop
exit
vlan 101
name Voice
exit
vlan 102
name Wireless
exit
show vlan-switch
VLAN Name Status Ports
---- -------------------------------- --------- -------------------------------
1 default active
100 Desktop active
101 Voice active
102 Wireless active
interface Vlan1
shutdownКонфигурация BGP
router bgp 65000
bgp log-neighbor-changes
address-family ipv4 vrf 100
redistribute connected
maximum-paths 2
exit-address-family
address-family ipv4 vrf 101
redistribute connected
exit-address-family
address-family ipv4 vrf 102
redistribute connected
maximum-paths 2
exit-address-family
address-family ipv4 vrf isp1
redistribute connected
redistribute static route-map BGP_Filter
default-information originate
exit-address-family
address-family ipv4 vrf isp2
redistribute connected
redistribute static route-map BGP_Filter
default-information originate
exit-address-family
Каждый из BGP address-family настраивается отдельно для VRF и перераспределяет подключенные маршруты (redistribute connected). У нас будет два маршрута по умолчанию, один через VRF isp1 и второй через isp2. Параметр maximum-paths 2 позволит импортировать в VRF 100 и 102 оба маршрута по умолчанию.
Это будет выглядеть так:
show ip route vrf 100
B* 0.0.0.0/0 [20/0] via 203.0.112.2 (isp2), 0d01h
[20/0] via 198.51.100.2 (isp1), 0d01hМаршрутизаторы Cisco автоматически балансируют трафик по маршрутам в одном направлении с одинаковой стоимостью.
В VRF isp1 и isp2 необходимо, помимо redistribute connected, разрешить redistribute static и default-information originate, что позволит передать шлюз по умолчанию в другие VRF. Вы можете заметить, что redistribute static делается через route-map BGP_Filter. Это происходит исключительно из соображений эстетического вида таблиц маршрутизации VRF определенных в локальную сеть, что бы маршруты к 8.8.8.8 и 80.80.80.80 не попадали в таблицы маршрутизации VRF 100 и 102.
Настройка маршрутизации
Приступим к настройке маршрутизации. Одной из особенностей работы с VRF, которая усложняет конфигурацию, является необходимость всё определять в конкретный VRF.
ip route vrf isp1 0.0.0.0 0.0.0.0 198.51.100.2 tag 100 track 100
ip route vrf isp2 0.0.0.0 0.0.0.0 203.0.112.2 tag 100 track 200- tag — поможет нам отфильтровать для передачи в локальные VRF только эти маршруты
- track — указывает какой объект отвечает за работоспособность маршрута
route-map BGP_Filter permit 10
description Fix BGP static redistribution
match tag 100Используя этот route-map и применяя его в VRF для ISP перераспределяться будут только маршруты с тэгом, а остальные останутся только внутри ISP VRF.
ip route vrf isp1 8.8.8.8 255.255.255.255 198.51.100.2
ip route vrf isp1 80.80.80.80 255.255.255.255 198.51.100.2
ip route vrf isp2 8.8.8.8 255.255.255.255 203.0.112.2
ip route vrf isp2 80.80.80.80 255.255.255.255 203.0.112.2Отдельные маршруты к хостам 8.8.8.8 и 80.80.80.80 необходимы для того, что когда сработает track и отключит шлюз по умолчанию у нас осталась возможность совершать проверку доступности этих адресов. Так как мы не присваиваем им тэг они не будут подпадать под route-map и перераспределяться.
Настройка NAT
Для работы NAT необходимо обозначить inside, outside интерфейсы. В качестве outside мы определяем интерфейсы в которые подключены ISP, командой ip nat outside. Все остальные интерфейсы, которые относятся к LAN обозначаем как inside командой ip nat inside.
Необходимо создать два route-map-а в которых определяются интерфейсы isp1 и isp2
route-map isp1 permit 10
match interface GigabitEthernet0/0
route-map isp2 permit 10
match interface GigabitEthernet0/1Правила NAT необходимо указывать для каждого VRF через каждый ISP. Так как в нашем условии Vlan 101 не имеет доступа к сети Интернет то правила для него указывать нет необходимости, а даже если их указать — работать не будет, потому что нет маршрутизации.
ip nat inside source route-map isp1 interface GigabitEthernet0/0 vrf 100 overload
ip nat inside source route-map isp2 interface GigabitEthernet0/1 vrf 100 overload
ip nat inside source route-map isp1 interface GigabitEthernet0/0 vrf 102 overload
ip nat inside source route-map isp2 interface GigabitEthernet0/1 vrf 102 overloadНемного теории NAT
У Cisco есть много разновидностей NAT. В терминологии Cisco, то что мы используем называется Dynamic NAT with Overload или PAT.
Что нужно для того что бы NAT работал?
В простой конфигурации NAT достаточно создать access-list в котором определить локальную сеть и применить правило трансляции.
Таким образом мы указываем, что/во что и включаем трансляцию, то есть выполняем все необходимые требования.
Это настройка простой конфигурации, она очевидна и понятна без дополнительных подробностей.
Правило которое мы применяем в нашей конфигурации уже не так очевидно. Как мы помним, route-map isp1 определяет интерфейс GigabitEthernet0/0. Перефразируя команду получается нечто подобное
Получается нужно транслировать трафик source которого GigabitEthernet0/0?
Для того что бы это понять необходимо погрузится в механизм прохождения пакета внутри маршрутизатора.
Что нужно для того что бы NAT работал?
- Определить внутренний и внешний интерфейсы
- Указать, что мы хотим транслировать
- Указать, во что мы хотим транслировать
- Включить трансляцию
В простой конфигурации NAT достаточно создать access-list в котором определить локальную сеть и применить правило трансляции.
ip access-list extended NAT
permit ip 192.168.0.0 0.0.0.255 any
ip nat inside source list NAT interface GigabitEthernet0/0 overloadТаким образом мы указываем, что/во что и включаем трансляцию, то есть выполняем все необходимые требования.
Это настройка простой конфигурации, она очевидна и понятна без дополнительных подробностей.
Правило которое мы применяем в нашей конфигурации уже не так очевидно. Как мы помним, route-map isp1 определяет интерфейс GigabitEthernet0/0. Перефразируя команду получается нечто подобное
ip nat inside source GigabitEthernet0/0 interface GigabitEthernet0/0 overload in vrf 100Получается нужно транслировать трафик source которого GigabitEthernet0/0?
Для того что бы это понять необходимо погрузится в механизм прохождения пакета внутри маршрутизатора.
- Трафик который приходит на интерфейс который помечен как inside не подвергается трансляции. Он маркируется как возможно транслируемый.
- Следующим шагом обработки этого трафика является его маршрутизация согласно таблице маршрутизации или PBR.
- Если согласно таблице трафик попадает на интерфейс который отмечен как outside происходит его трансляция.
- Если трафик попадает на не outside интерфейс трансляции не происходит.
Ошибочно можно подумать, что можно делать route-map LAN match interface Vlan100. Применять этот как ip nat inside source route-map LAN и т.д.Спасибо IlyaPodkopaev NAT на Cisco. Часть 1
Во избежание этой мысли нужно понять, что это правило трансляции срабатывает тогда, когда трафик уже находится на outside интерфейсе и match интерфейса где этого трафика уже нет ни к чему не приведет.
Настройка SLA
ip sla auto discovery
ip sla 10
icmp-echo 198.51.100.2
vrf isp1
frequency 5
ip sla schedule 10 life forever start-time now
ip sla 11
icmp-echo 8.8.8.8
vrf isp1
frequency 5
ip sla schedule 11 life forever start-time now
ip sla 12
icmp-echo 80.80.80.80
vrf isp1
frequency 5
ip sla schedule 12 life forever start-time now
ip sla 20
icmp-echo 203.0.112.2
vrf isp2
frequency 5
ip sla schedule 20 life forever start-time now
ip sla 21
icmp-echo 8.8.8.8
vrf isp2
frequency 5
ip sla schedule 21 life forever start-time now
ip sla 22
icmp-echo 80.80.80.80
vrf isp2
frequency 5
ip sla schedule 22 life forever start-time nowНичего особенного в конфигурации нет, проверятся доступность по ICMP узлов 8.8.8.8 80.80.80.80 и маршрутизаторов провайдера из каждого ISP VRF.
Настройка track
track 100 list boolean and
object 101
object 110
track 101 ip sla 10 reachability
delay down 20 up 180
track 102 ip sla 11 reachability
delay down 20 up 180
track 103 ip sla 12 reachability
delay down 20 up 180
track 110 list boolean or
object 102
object 103
track 200 list boolean and
object 201
object 210
track 201 ip sla 20 reachability
delay down 20 up 180
track 202 ip sla 21 reachability
delay down 20 up 180
track 203 ip sla 22 reachability
delay down 20 up 180
track 210 list boolean or
object 202
object 203
track 1000 stub-objectЛогика работы:
В таблице маршрутизации есть маршрут ip route vrf isp1 0.0.0.0 0.0.0.0 198.51.100.2 tag 100 track 100 который завязан на track 100.
- Если track 100 в состоянии UP то маршрут в таблице есть.
- Объект 100 это boolean and, что означает, что UP он будет считаться если все его объекты в состоянии UP.
- Если любой из объектов 100 DOWN то весть объект 100 будет DOWN.
- Он содержит объекты 101 и 110.
- Объект 101 соответствует SLA 10 — проверяет шлюз провайдера.
- Объект 110 объединяет 102 и 103 как boolean or, что означает, что он будет UP если хотя бы один из его объектов UP.
- Объекты 102 и 103 проверяют 8.8.8.8 и 80.80.80.80 соответственно, их нужно два для исключения ложных срабатываний.
Таким образом получается, что если отвечает шлюз по умолчанию провайдера и хотя бы один из внешних адресов то связь считается рабочей.
track 1000
track 1000 stub-object
default-state downЭтот объект умолчанию имеет состояние DOWN.
В данной конфигурации этот объект необходим для того, что бы принудительно отключить одного из ISP и не подключать его. Для этого track 1000 нужно добавить в объект 100 или 200. Исходя из boolean and, если один из объектов DOWN то весь объект считается DOWN.
Настройка EEM
EEM — Embedded Event Manager позволяет автоматизировать действия в соответствии с определенными событиями.
В нашем случае, когда один из ISP перестанет работать, он будет исключен из таблицы маршрутизации. Но правила трансляции NAT будут оставаться. Из-за этого, уже установленные пользовательские соединения зависнут до того момента пока трансляции NAT не очистится по тайм-ауту.
Для того, что бы ускорить этот процесс нам необходимо очистить таблицу NAT командой clear ip nat translation * и лучше всего сделать это автоматически.
event manager applet CLEANNAT-100
event track 100 state down
action 10 cli command "enable"
action 20 cli command "clean ip nat translation *"
event manager applet CLEANNAT-200
event track 200 state down
action 10 cli command "enable"
action 20 cli command "clean ip nat translation *"Если объекты 100 или 200 перейдут в состояние DOWN то будут выполнены команды action по порядку.
tips and tricks
Хочу отметить ещё несколько особенностей работы с VRF.
Например конфигурация NTP:
ntp server vrf isp1 132.163.4.103Из-за использования VRF любые сетевые операции нужно относить к виртуальному маршрутизатору, это связано с тем, что когда Вы настроите эту конфигурацию и выполните show ip route вы не увидите ни одной записи в таблице маршрутизации.
ping vrf isp1 8.8.8.8Будьте внимательны.
К преимуществам этой конфигурации я хотел бы отнести её гибкость. Можно с легкостью вывести один VLAN через одного ISP, а другой через второго.
К недостаткам, и это вопрос к уважаемой публике, когда отваливается один из ISP то команда clear ip nat translations * обрывает все соединения, включительно с работающим ISP. Как показала практика, в тех случаях когда отваливается провайдер — пользователи не замечают этот «обрыв» или он не является критичным.
Если кто-то знает как очищать таблицу трансляций частично — буду благодарен.
P.S>
Не забудьте запретить NAT трансляцию в приватные подсети.
ip access-list extended NO_NAT
deny ip any 192.168.0.0 0.0.255.255
deny ip any 172.16.0.0 0.15.255.255
deny ip any 10.0.0.0 0.255.255.255
permit ip any anyroute-map isp1 permit 10
match ip address NO_NAT
match interface GigabitEthernet0/0Поделиться с друзьями
Комментарии (7)

ksg222
11.03.2017 20:06+1Если кто-то знает как очищать таблицу трансляций частично — буду благодарен.
Можно поробовать так: clear ip nat translation vrf isp1 *
Из-за этого, уже установленные пользовательские соединения зависнут до того момента пока трансляции NAT не очистится по тайм-ауту.
Я бы не согласился с этим утверждением. Действительно, соединения подвисают, так как пакеты в рамках открытой сессии используют текущие записи NAT, которые ссылаются на адреса отказавшего провайдера. Но таймаут NAT для TCP равен 24 часа. Ждать его окончания было бы слишком долго.
Обычно клиентская сторона намного раньше разрывает соединение. Например, может использоваться механизм TCP Keep-alive. Или пользователь самостоятельно инициирует установку нового соединения (например, принудительно обновив страницу в браузере).
Магия «clear ip nat translation» заключается в том, что как только вы вводите эту команду, маршрутизатор отправляет пакет с флагом RST для всех TCP сессий. Из-за чего внутренние ПК завершают текущую сессию и при необходимости открывают новую. А новая уже прекрасно работает, так как создаются новые NAT записи, использующие адреса второго провайдера.

Pave1
13.03.2017 09:40В голове не укладывается, зачем в дизайне SMB нужна такая сложная конфигурация…
cagami
спасибо за статью
но мне не понятно, зачем для работы vrf cef?
(или это фигура речи такая?)
я понимаю что cef нужен для sla,track но не для vrf
если я не прав, поясните пожалуйста
main
Попробую объяснить так:
Elordis
Для полноценных VRF (с использованием BGP и MPLS) CEF нужен, потому что MPLS циска (насколько мне известно) умеет только через CEF. Насчет VRF-lite не уверен.
Тут вопрос в другом: зачем вообще VRF в этом случае? На мой взгляд, получается наркоманско-шизофренический конфиг, который никто кроме автора поддерживать не сможет. Хотя job-security, да, хороший.
Единственное, что этот конфиг дает — разграничение доступа, но в лоб, с использованием ACL, получится проще и понятнее.
main
Насчет «кроме автора никто не сможет поддерживать» не согласен. Я основывался на статье автора которую указал. Я разобрался — ничего сложного. По поводу ACL — вы правы, но статья не о том, и то что в данном случае, в определенных ситуациях ACL не нужен это скорее фича.
ksg222
Как раз для IP SLA технология CEF не нужна. Пакеты генерирует само устройство (используется process switching).
А вот VRF в качестве пререквизита требует CEF. Изначально VRF появился для работы MPLS VPN. При этом MPLS опирается на логику CEF и обязательно требует его включения. VRF обеспечивает изоляцию за счёт разных таблиц RIB и FIB для каждого инстанса.