Вот уже более полугода в компании используется единая система для проведения A/B-экспериментов. Одной из самых важных частей этой системы является процедура проверки качества, которая помогает нам понять, насколько мы можем доверять результатам A/B-тестов. В этой статье мы подробно опишем принцип работы процедуры проверки качества в расчете на тех читателей, которые захотят проверить свою систему A/B-тестирования. Поэтому в статье много технических деталей.
Несколько слов про A/B-тестирование
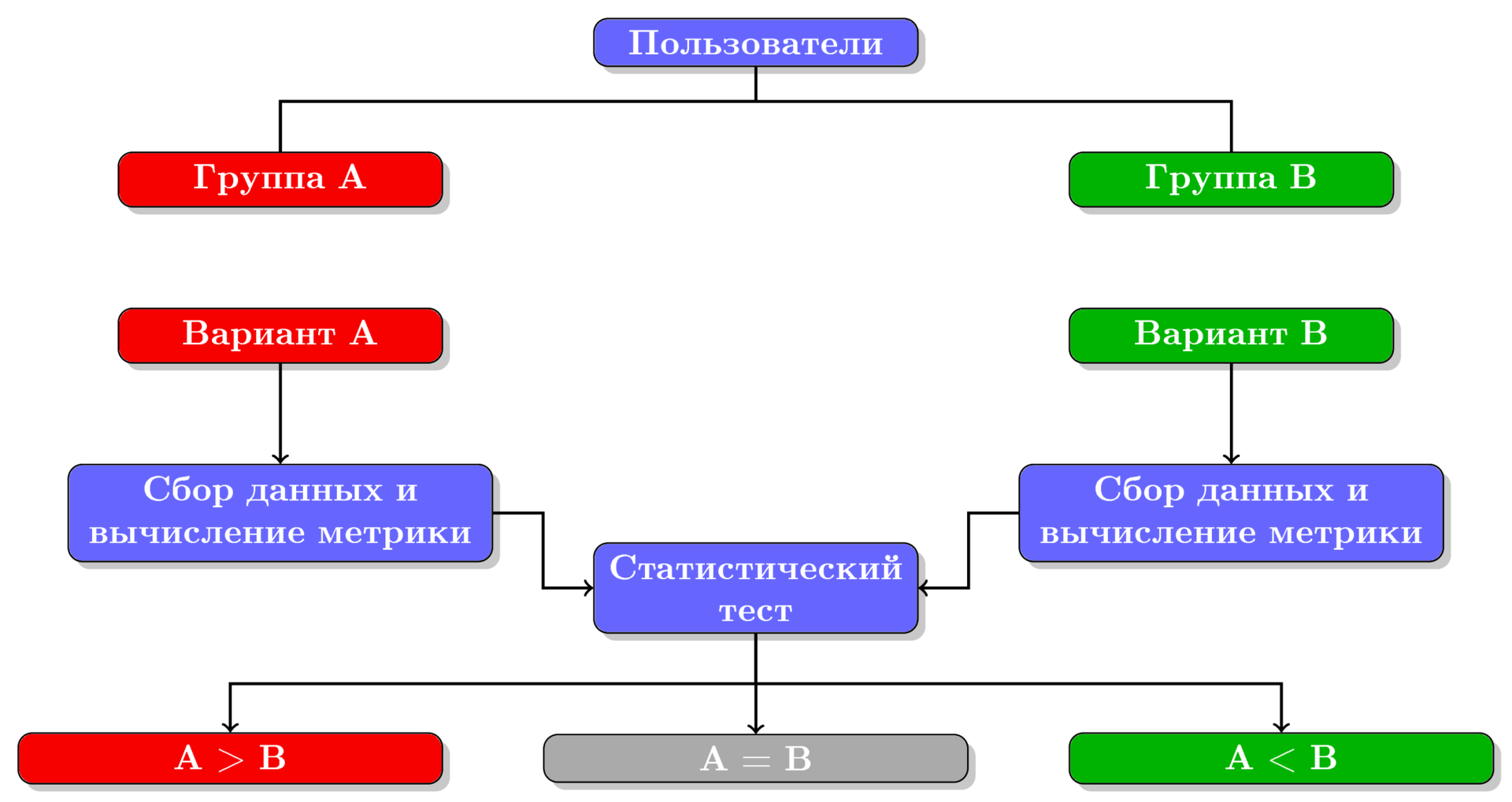
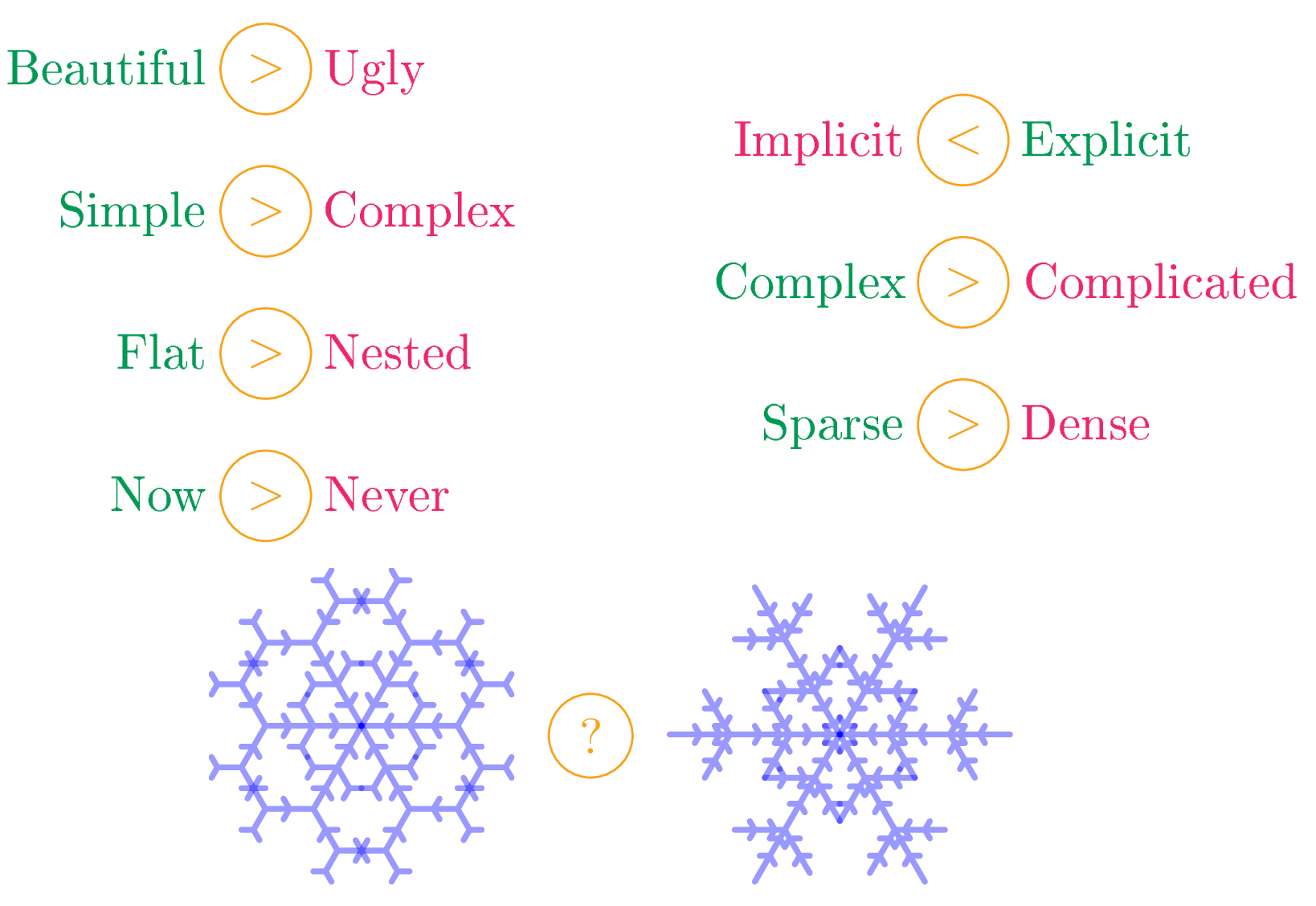
Рисунок 1. Схема процесса A/B-тестирования.
В целом процесс A/B-тестирования можно разделить на следующие шаги (показанные на рисунке):
- Распределение пользователей по двум группам A и B.
- Представление двум группам пользователей двух различных вариантов.
- Сбор данных и вычисление значения метрики для каждой группы.
- Сравнение с помощью статистического теста значений метрики в обеих группах и принятие решения, какой из двух вариантов выиграл.
В принципе, с помощью A/B-тестов можно сравнивать любые два варианта, но мы, для определенности, будем считать, что группе A показывается текущий вариант, работающий в продакшене, а группе B — экспериментальный вариант. Таким образом, группа A — контрольная группа, а группа B — экспериментальная. Если пользователям в группе B показывается такой же вариант, как и в группе A (то есть между вариантами A и B нет никакой разницы), то такой тест называют A/A-тестом.
Если в A/B-тесте победил один из вариантов, то говорят, что тест прокрасился.
История A/B-тестирования в компании
A/B-тестирование в компании HeadHunter началось, можно сказать, стихийно: команды разработчиков произвольно делили аудиторию на группы и проводили эксперименты. При этом общего пула проверенных метрик не было — каждая команда вычисляла свои собственные метрики из логов действий пользователей. Общей системы определения победителя тоже не было: если один вариант сильно превосходил другой, то он признавался победителем; если разница между двумя вариантами была небольшой, то для определения победителя применялись статистические методы. Хуже всего было то, что разные команды могли проводить эксперименты на одной и той же группе пользователей, тем самым влияя на результаты друг друга. Стало понятно, что нам нужна единая система для проведения A/B-тестов.
Такая система была создана и запущена в июле 2016 года. С помощью этой системы в компании уже проведено 77 экспериментов. Количество A/B-экспериментов по месяцам показано на рисунке 2.
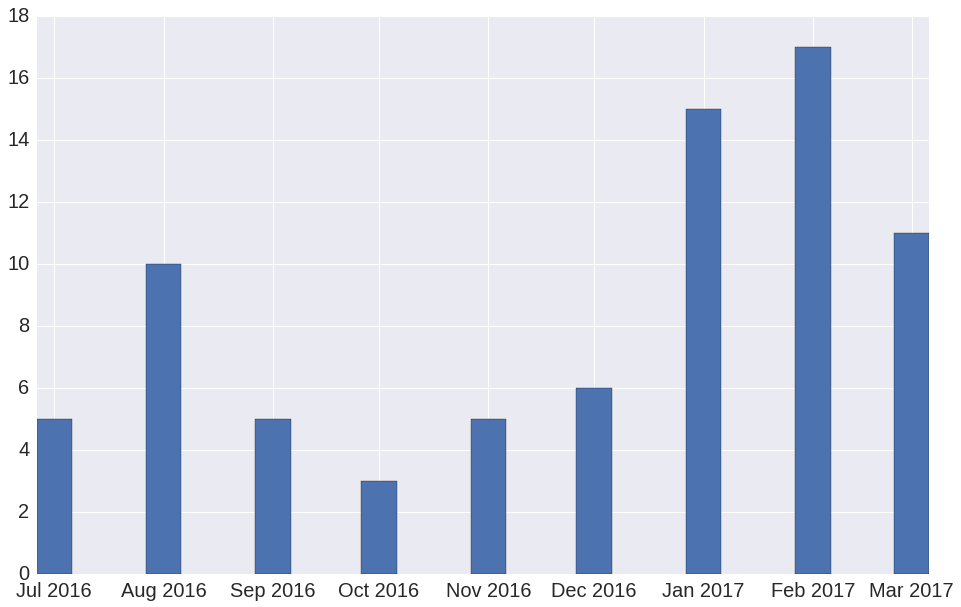
Рисунок 2. Число A/B-экспериментов по месяцам с момента запуска системы A/B-тестирования. Число экспериментов за март 2017 неполное, т.к. на момент публикаций этот месяц еще не закончился.
При создании системы A/B-тестирования мы уделили наибольшее внимание статистическому тесту. В первую очередь нас интересовал ответ на следующий вопрос:
Как убедиться в том, что статистический тест нас не обманывает и мы можем доверять его результатам?
Вопрос вовсе не праздный, поскольку вред от некорректных результатов стат. теста может быть даже больше, чем от отсутствия результатов.
Почему у нас могут быть причины не доверять стат. тесту? Дело в том, что статистический тест предполагает вероятностную интерпретацию измеряемых величин. Например, мы считаем, что у каждого пользователя есть «вероятность» совершить некое успешное действие (успешными действиями могут быть регистрация, покупка товара, лайк и т. д.). При этом мы считаем действия разных пользователей независимыми. Но изначально мы не знаем, насколько хорошо действия пользователей соответствуют вероятностной модели стат. теста.
Чтобы оценить качество системы A/B-тестирования, мы проводили большое количество A/A-тестов и измеряли процент прокрасившихся тестов, то есть процент случаев, в которых стат. тест ошибался, утверждая о статистически значимом превосходстве одного варианта над другим. О пользе A/A-тестов можно прочитать, например, здесь. Измеренный процент ошибок стат. теста сравнивался с заданным теоретическим значением: если они примерно совпадали, значит, все хорошо; если измеренный процент ошибок сильно меньше или сильно больше теоретического, значит, результаты такого стат. теста ненадежны.
Чтобы рассказать подробнее о методе оценки качества системы A/B-тестирования, следует сначала рассказать про уровень значимости и про другие понятия, возникающие при проверке статистических гипотез. Читатели, знакомые с данной темой, могут пропустить следующий параграф и перейти к параграфу Оценка качества системы A/B-тестирования.
Статистический тест, доверительные интервалы и уровень значимости
Давайте для начала рассмотрим простой пример. Пусть у нас всего 6 пользователей и мы разбили их на 2 группы по 3 человека, провели A/B-тест, подсчитали значение метрики для каждого отдельного пользователя и получили в результате такие таблицы:
| Пользователь |
Значение метрики |
|---|---|
| А. Антонов | 1 |
| П. Петров | 0 |
| С. Сергеев | 0 |
| Пользователь |
Значение метрики |
|---|---|
| Б. Быстров | 0 |
| В. Вольнов | 1 |
| У. Умнов | 1 |
Среднее значение метрики в группе A равно , в группе B — , а среднее значение разности между двумя группами равно . Если мы ограничимся только средними значениями, то получается, что вариант, показанный группе B, выиграл (т. к. разность больше нуля). Но в каждой группе только 3 значения — значит, истинное значение разности мы оценили по 6 числам, то есть с большой погрешностью. Поэтому полученный результат может быть случайным и может ровным счетом ничего не значить.
То есть, кроме разности средних значений метрики в двух группах, нам еще хотелось бы оценить и доверительный интервал для истинного значения разности , то есть интервал в котором, «скорее всего», лежит истинное значение. Фраза «скорее всего» имеет интуитивное значение. Чтобы его формализовать, используют понятие уровня значимости . Уровень значимости связан с доверительным интервалом и отражает степень нашей уверенности, что истинное значение находится внутри данного доверительного интервала. Чем меньше уровень значимости, тем мы более уверены.
Представить себе, что означает уровень значимости, можно так. Если мы много раз будем повторять A/A-тест, то процент случаев, в которых A/A-тест прокрасится, будет примерно равен . То есть в случаев мы отклоняем гипотезу о равенстве вариантов, хотя оба варианта действительно равны (иными словами, в случаев мы совершим ошибку первого рода). Мы выбрали уровень значимости равным .
Собственно, статистический тест как раз и занимается оценкой доверительного интервала для разности при заданном уровне значимости. Если доверительный интервал известен, то процедура определения победителя проста:
- Если обе границы доверительного интервала больше 0, значит, выиграл вариант B.
- Если 0 внутри интервала, значит, ничья — ни один из вариантов не выиграл.
- Если обе границы меньше 0, значит, выиграл вариант A.
Например, предположим, что мы как-то смогли узнать, что для уровня значимости доверительный интервал для разности в нашем примере равен . То есть, истинное значение разности скорее всего лежит внутри интервала . Ноль принадлежит этому интервалу — значит, у нас нет оснований предполагать, что один из вариантов лучше, чем другой (в действительности один из вариантов может быть лучше, чем другой, у нас просто недостаточно данных, чтобы утверждать об этом с уровнем значимости 5%).
Нам осталось понять, как статистический тест из уровня значимости и экспериментальных данных оценивает доверительные интервалы для разности значений метрики между группами A и B.
Определение доверительных интервалов
Рисунок 3. Оценка доверительных интервалов для разности с помощью бутстрэпа (левый график, 10 000 итераций бутстрэпа) и аналитически (правый график). Зеленой линией показаны границы доверительного интервала, черной линией — положение нуля. На среднем графике оба способа совмещены для сравнения.
Для определения доверительных интервалов мы пользовались двумя способами, показанными на рисунке 3:
- Аналитически.
- С помощью бутстрэпа.
Аналитическая оценка доверительных интервалов
В аналитическом подходе мы опираемся на утверждение центральной предельной теоремы (ЦПТ) и ожидаем, что разность средних значений метрик в двух группах будет иметь нормальное распределение, с параметрами и . Точных значений и мы не знаем, но можем подсчитать приближенные оценки и :
Где средние значения () и дисперсии средних значений () вычисляются
по стандартным формулам.
Зная параметры нормального распределения и уровень значимости, мы можем вычислить доверительные интервалы. Формулы для вычисления доверительных интервалов мы не приводим, но идея показана на рисунке 3 на правом графике.
Одним из минусов такого подхода является тот факт, что в ЦПТ случайные величины предполагаются независимыми. В реальности это предположение часто нарушается, в частности, из-за того, что действия одного пользователя зависимы. Например, пользователь «Амазона», купивший одну книгу, скорее всего, купит и еще одну. Будет ошибкой считать две покупки одного пользователя независимыми случайными величинами, потому что мы можем в результате получить слишком оптимистичную оценку на доверительный интервал. А это означает, что в реальности процент ложно прокрасившихся A/A-тестов может быть в разы больше, чем заданное значение. Именно это мы и наблюдали на практике. Поэтому мы попробовали другой метод оценки доверительных интервалов, а именно бутстрэп.
Оценка доверительных интервалов с помощью бутстрэпа
Бутстрэп — это один из методов непараметрической оценки доверительных интервалов, в котором не делается никаких предположений о независимости случайных величин. Применение бутстрэпа для оценки доверительных интервалов сводится к следующей процедуре:
- Повторять раз:
- выбрать с помощью бутстрэпа случайные подвыборки значений из групп A и B;
- подсчитать разность средних значений в этих подвыборках;
- Упорядочить по возрастанию значения, полученные на каждой итерации
- С помощью упорядоченного массива определить доверительный интервал так, чтобы точек лежали внутри интервала. То есть, левой границей интервала будет число с индексом
, а правой границей — число с индексом в упорядоченном массиве.
На рисунке 3 на левом графике показаны гистограмма для массива значений разности, полученного после 10 000 итераций бутстрэпа, и доверительные интервалы, вычисленные по описанной здесь процедуре.
Оценка качества системы A/B-тестирования
Итак, мы разбили всех пользователей на групп, подготовили статистический тест и выбрали метрику, которую хотим улучшать. Теперь мы готовы оценивать качество системы A/B-тестирования. В HeadHunter нас интересовало, как часто стат. тест будет совершать ошибку первого рода, то есть какой процент A/A-тестов будет прокрашиваться (обозначим эту величину ) при фиксированном уровне значимости .
Вычислить мы можем проведя много A/A-тестов. В итоге мы можем получить три варианта:
- Если , то либо стат. тест, либо выбранная метрика слишком консервативны. То есть у A/B-тестов заниженная чувствительность («стойкий оловянный солдатик»). И это плохо, т. к. в процессе эксплуатации такой системы A/B-тестирования мы будем часто отклонять изменения, которые действительно что-то улучшили, т. к. мы не почувствовали улучшения (т. е. мы будем часто совершать ошибку второго рода).
- Если , то либо стат. тест, либо выбранная метрика слишком чувствительны («принцесса на горошине»). Это тоже плохо, т. к. в процессе эксплуатации мы будем часто принимать изменения, которые в действительности ни на что не влияли (т. е. мы будем часто совершать ошибку первого рода).
- Наконец, если , значит, стат. тест вместе с выбранной метрикой показывают хорошее качество и такой системой можно пользоваться для проведения A/B-тестирования.
 |
 |
| (а) Перебираем все возможные пары | (б) Случайно разбиваем на непересекающиеся пары |
| Рисунок 4. Два варианта разбиения 4 групп пользователей (, , , ) на пары. | |
Итак, нам нужно провести много A/A-тестов, чтобы лучше оценить процент ошибок стат. теста . Для этого нам нужно большое число пар групп пользователей. Но откуда можно взять большое число пар, если все пользователи распределены по небольшому числу групп (мы распределяли пользователей по 64 группам). Первое, что приходит в голову, — это составить всевозможные пары групп. Если число групп пользователей у нас равно , то мы сможем из них составить различных пар (схема разбиения на пары для 4 групп показана на рисунке 4 (a)).
Однако такой подход обладает серьезным недостатком, а именно: мы получаем большое число зависимых пар. Например, если в одной группе среднее значение метрики очень мало, то большинство A/A-тестов для пар, содержащих эту группу, прокрасится. Поэтому мы остановились на подходе, показанном на рисунке 4 (б), в котором все группы разбиваются на непересекающиеся пары. То есть число пар равно . Пар получилось значительно меньше, чем в первом способе, но зато теперь они все независимы.
Результаты применения A/A-теста к 64 группам пользователей, которые разбились на 32 независимые пары, показаны на рисунке 5. Из этого рисунка видно, что из 32 пар прокрасились только 2, то есть .

Рисунок 5. Результаты A/A-тестов для 64 групп пользователей, случайно разбитых на 32 пары. Доверительные интервалы вычислялись с помощью бутстрэпа, уровень значимости — 5%.
Гистограммы значений , полученных бутстрэпом, показаны синим для непрокрасившихся пар, желтым для прокрасившихся; распределение Гаусса с вычисленными аналитически параметрами показано красным. Черная линия показывает положение нуля.
В принципе, на этом можно было бы и остановиться. У нас есть способ вычислить реальный процент ошибок стат. теста. Но в этом способе нас смущало небольшое число A/A-тестов. Кажется, что 32 A/A-теста — это маловато для надежного измерения величины . Значит, нам осталось ответить на следующий вопрос:
Если число пар невелико, то как нам надежно измерить ?
Мы использовали такое решение: давайте много раз случайно перераспределять пользователей по группам. И после каждого перераспределения мы сможем измерять процент ошибок . Среднее всех измеренных значений даст оценку величины .
В итоге мы получили следующую процедуру для оценки качества системы A/B-тестирования:
- Повторять раз:
- Случайно распределить всех пользователей по группам;
- Случайно разбить групп на пар;
- Для всех пар провести A/A-тест и вычислить процент прокрасившися пар на данной -ой итерации
- вычислить как среднее по всем итерациям:
Если в процедуре оценки качества системы A/B-тестирования мы зафиксируем стат. тест (например, всегда будем использовать бутстрэп) и поверим, что сам стат. тест непогрешим (или незаменим), то у нас получится система оценки качества метрик.
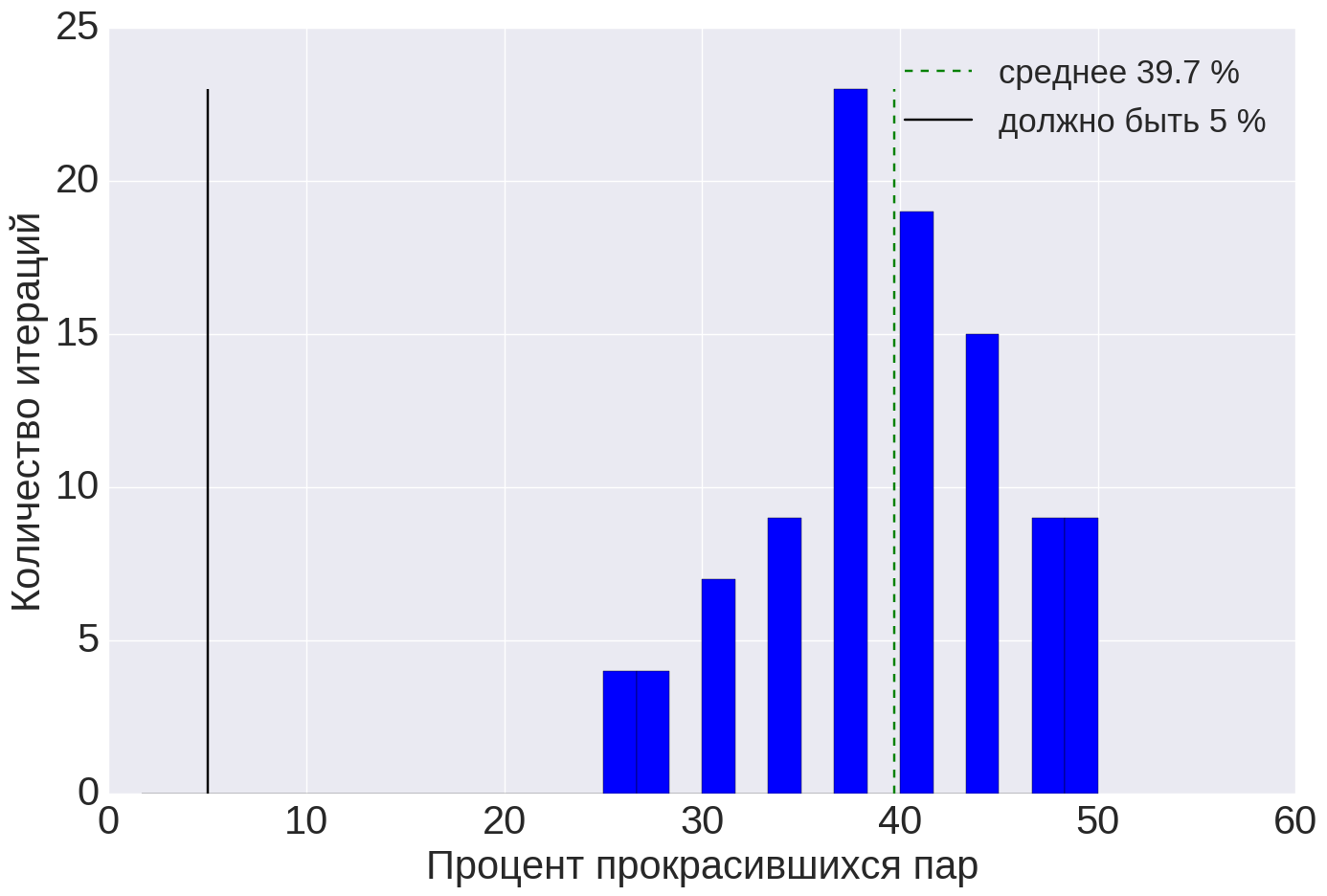
Пример оценки качества одной из метрик показан на рисунке 6. Из этого графика видно, что средний процент ошибок стат. теста (т.е. значение ) практически идеально совпадает с заданным значением . Стоит отметить, что такое хорошее совпадение мы видели нечасто. Мы считаем хорошим совпадением, если .

Рисунок 6. Результат оценки качества для метрики успешных действий пользователей. Синим показана гистограмма для массива чисел , зеленым — среднее значение массива, черным — заданный уровень значимости для бутстрэпа (число итераций бутстрэпа — 10 000). Количество пар групп пользователей равно 32. Число итераций процедуры оценки качества .
Результаты оценки качества метрик
 |
 |
 |
| (a) |
(б) |
(в) |
| Рисунок 7. Результаты оценки качества для метрики успешности поисковых сессий: (а) — для исходной метрики и бутстрэпа по значениям, (б) — для исходной метрики и бутстрэпа по пользователям, (в) — для модифицированной метрики и бутстрэпа по значениям. |
||
Когда мы применили процедуру оценки качества к метрике успешности поисковых сессий, то получили такой результат, как на рисунке 7 (а). Стат. тест в теории должен ошибаться в 5% случаев, а в реальности ошибается в 40% случаев! То есть, если мы будем использовать данную метрику, то 40% A/B-тестов будут прокрашиваться, даже если вариант А ничем не отличается от варианта Б.
Данная метрика оказалась «принцессой на горошине». Однако мы все же хотели использовать эту метрику, так как ее значение имеет простую интерпретацию. Поэтому мы стали разбираться, в чем может быть проблема и как с этим можно справиться.
Мы предположили, что проблема может быть связана с тем, что от одного пользователя в метрику попадает несколько значений, которые зависимы. Пример ситуации, когда от одного пользователя (Иван Иванович) в метрику попадает два числа, показан в таблице 3.
| Пользователь |
Значение метрики |
|---|---|
| Иван Иванович | 0 |
| Иван Никифорович | 0 |
| Антон Прокофьевич | 1 |
| Иван Иванович | 1 |
Ослабить влияние зависимости значений одного пользователя мы можем либо модификацией стат. теста, либо изменением метрики. Мы попробовали оба этих варианта.
Модификация стат. теста
Поскольку значения от одного пользователя зависимы, то мы выполняли бутстрэп не по значениям, а по пользователям: если пользователь попал в бутстрэпную выборку, то используются все его значения; если не попал, то не используется ни одно из его значений. Применение такой схемы привело к значительному улучшению (рисунок 7 (б)) — реальный процент ошибок стат. теста на 100 итерациях оказался равным , что очень близко к теоретическому значению .
Модификация метрики
Если нам мешает, что от одного пользователя в метрику попадает несколько зависимых значений, то можно сначала усреднить все значения внутри пользователя, чтобы от каждого пользователя в метрику попадало бы только одно число. Например, таблица 3 после усреднения значений внутри каждого пользователя перейдет в следующую таблицу:
| Пользователь |
Значение метрики |
|---|---|
| Иван Иванович | 0.5 |
| Иван Никифорович | 0 |
| Антон Прокофьевич | 1 |
Результаты оценки качества метрики после данной модификации показаны на рисунке 7 (в). Процент случаев, в которых стат. тест ошибался, оказался почти в 2 раза ниже теоретического значения . То есть, для данной метрики и неидеально совпадают, но это гораздо лучше, чем исходная ситуация на рисунке 7 (а).
Какой из двух подходов лучше
Мы применяли оба подхода (модификация стат. теста и модификация метрики) для оценки качества различных метрик, и для подавляющего большинства метрик оба подхода показывали хорошие результаты. Поэтому использовать можно тот способ, который проще реализовать.
Выводы
Главный вывод, который мы сделали при оценке качества системы A/B-тестирования: нужно обязательно выполнять оценку качества системы A/B-тестирования). Перед тем как использовать новую метрику, ее нужно проверить. Иначе A/B-тесты рискуют превратиться в одну из форм гадания и повредить процессу разработки.
В этой статье мы постарались, насколько это возможно, привести всю информацию о устройстве и принципах работы процедуры оценки качества системы A/B-тестирования, используемой в компании. Но если у Вас остались вопросы, не стесняйтесь задавать их в комментариях.
P.S.
Я хотел бы выразить благодарность lleo за систематизацию процесса A/B-тестирования в компании и за проведение proof-of-concept экспериментов, развитием которых является данная работа, и p0b0rchy за передачу опыта, терпеливые многочасовые разъяснения и за генерацию идей, которые легли в основу наших экспериментов.
Поделиться с друзьями
TimurGilfanov
Спасибо за статью! Она помогла понять, что нужно собирать сырые данные данные теста и проверять вероятность ошибки false positive для метрики.
Могут ли быть нежелательные эффекты при ААБ–тесте: по А1 и А2 проверим вероятность ошибки false positive, а по А1 и Б делать выводы, если вероятность нас устаивает?
Имеет ли практический смысл проверять вероятность ошибки false negative?
eteresh
Мы проводим AAБ-тесты именно так. Но нежелательный эффект здесь все-таки есть. Предположим, что вероятность false-positive очень высока, например, 70%. Но нам "повезло": между группами A1 и A2 нет статистически значимой разницы. Но между группами A1 и B она, скорее всего, возникнет. И мы не поймем, что проблема с метрикой, пока не проведем достаточно большое число экспериментов, и не заметим, что A1A2-тест прокрашивается слишком часто. То есть, мне кажется, лучше совмещать подход, описанный в этой статье с ААБ-тестом: сначала проверить, что ошибка false-positive для метрики имеет разумное значение, а затем, с помощью ААБ-теста контроллировать, что ничего сильно не испортилось.
TimurGilfanov
То есть мы проводим ААБ тесты, по АБ части делаем выводы, а АА часть накапливаем и по нескольким десяткам последних для этой метрики проверяем, что он срабатывает (окрашивается) в рамках заданной вероятности false positive.
eteresh
Да, примерно так. Но конкретно мы в компании смотрим пока что не на десятки, а на несколько АА-экспериментов. То есть, мы не пытаемся точно измерить false-positive по этим АА-тестам, а скорее проверяем, что нет сильных ухудшений. Например, если false-positive был равен 5% и вдруг увеличился в 5 раз и стал равен 25% (например, что-то сломалось и часть данных перестала логироваться), то на нескольких АА-тестах мы это заметим. Если false-positive изменился несильно и стал равен, скажем, 8%, то вряд ли мы такое заметим даже на нескольких десятках АА-тестах.
eteresh
Вообще, спасибо за интересные вопросы!
Наибольшее обсуждение, в том числе, и внутри нашей команды вызвал вопрос про
ошибки второго рода (false-negative). В предыдущем комментарии я привел интуитивные соображения.
Здесь я постараюсь дать чуть более обоснованный ответ для Вас, для моих коллег и для всех читателей, кому это может быть интересно.
Итак, я хочу сказать, что ошибка первого рода, измерению которой и посвящена статья, несет в себе информацию и об ошибке второго рода.
Конечно, если стат. тест и метрика не являются какими-то экзотическими.
Рассуждения у меня такие. Давайте на секундочку забудем, что мы выполняем проверку стат. гипотез, и перенесемся в мир машинного обучения.
У нас есть размеченная выборка, например, в виде такой таблицы:
номер пары|разность метрик, X| есть ли разница между двумя группами пары, Y|
1 | 0.005 | 0 |
2 | 0.100 | 1 |
3 | 0.070 | 0 |
...
А роль стат. теста у нас выполняет алгоритм, который на вход принимает разность значений метрики между двумя группами (величину X)
и выдает ответ a(X) — есть ли, по мнению алгоритма, разница между группами А и Б.
Причем, пока что, никаких ограничений на выборку и на алгоритм мы не накладываем.
Алгоритм может быть любым. Он может давать ответ никак не учитывая выборку (например, в качестве алгоритма можно взять осминога Пауля).
Тогда, охарактеризовать качество алгоритма на размеченной выборке мы можем с помощью двух чисел: false-positive и false-negative.
Все остальные стандартные харакеристики: true-positive, true-negative, точность, полнота, F-мера
вычисляются из размеченной выборки и из этих двух чисел (из false-positive и false-negative).
В общем случае, false-positive и false-negative никак между собой не связаны. Алгоритм может очень редко ошибаться, предсказывая 1,
и очень часто ошибаться, предсказывая 0; а может редко ошибаться для 0, и часто ошибаться для 1.
А теперь давайте вспомним, что мы выполняем проверку стат. гипотез. Стат. тест, как алгоритм, обладает особенностью: если для
какой-то разности X_0 стат. тест предсказал 1, то для всех |X| > |X_0| стат. тест также будет предсказывать 1.
Размеченная выборка тоже обладает особенностью: X и Y сильно коррелированны. Чем больше модуль X,
тем чаще в Y будут встречаться 1.
Из того, что в при проверке стат. гипотез у нас накладываются ограничения на алгоритм и на выборку, следует, что
false-positive и false-negative становятся кореллированными величинами. То есть, возможны уже не любые пары значений
false-positive и false-negative.
Насколько сильно они скореллированны мне сложно сказать.
Конечно, степень коррелированности зависит от распределения значения метрики в группе.
Если предположить, что значение метрики в группе имеет мультимодальное распределение (например, двухгорбое), или,
что в этом распределении тяжелые хвосты (например, много сильных выборосов),
то корреляция между false-positive и false-negative уже не так очевидна.
Но часто значение метрики в группе — это среднее значение по всем пользователям в группе.
Мне сложно представить, чтобы среднее значение имело бы какое-то страшное распределение.
А если у значения метрики в группе хорошее одногорбое распределение с легкими хвостами,
то, мне кажется, что false-positive будет нести информацию и о false-negative.
То есть, по измеренной ошибке первого рода, можно делать вывод о качестве системы A/B-тестирования.
p0b0rchy
В общем случае это, если я правильно понял утверждение, неверно. Статтесты (многие, во всяком случае) учитывают не только величину разности, но и свойства выборки. Т.е. можно себе представить ситуацию, когда при меньшей по модулю разности средних между A и B тест говорит, что изменения значимы, а при большей по модулю разности между тем же A и неким C тот же тест скажет, что значимой разницы нет.
Поэтому ошибку второго рода надо проверять всё-таки отдельно.