Всем привет! Недавно познакомился с замечательной штукой как OpenMP, на просторах есть много
описаний тут или тут, но нет красивых графиков которые бы показывали эффективность этой технологии. В этом посте я постараюсь наглядно показать эффективность работы с OpenMP на различных платформах. Кому интересно добро пожаловать!
В современном мире существует множество различных ОС и новых мощных процессоров, позволяющих производить сложные вычисления с относительно небольшими затратами времени. Данное исследование проводилось с целью выяснить в какой среде эффективнее всего производить трудоемкие вычисления, а также способы уменьшения затрат времени на вычисления.
Для проведения исследования был выбран алгоритм — вычисления числа ПИ с помощью интегральной формулы поскольку данный алгоритм хорошо поддаётся распараллеливанию и достаточно трудоёмкий с точки зрения вычислений.
Для распараллеливания алгоритма было решено использовать технологию openMP. Данная технология позволяет эффективно писать одинаковый код для разных сред выполнения, минимизируя погрешности, которые вносятся при написании кода программистом с использованием p_threads или Windows Threads, в ОС Linux и Windows, соответственно.
Для сравнения были выбраны 3 среды выполнения:
- Windows 10
- Windows Subsystem For Linux
- Linux дистрибутив Ubuntu 16.10 LTS
Тесты были проведены на компьютере с процессором.
Intel Сore i7-4771
Если про первые две системы слышали многие, WSL еще малоизвестна. WSL — фича, которая появилась в Windows 10 сравнительно недавно. Ядро ubuntu 14.04 было встроено в ядро Win10. Эта система позволяет запускать linux приложения, работая в Windows, более того пользователю доступно практически полное рабочее окружение использовать которое так-же просто, как открыть проводник. Прочитать про неё можно например тут .
Теперь графики
Данные представленные на графиках усреднённые, было выполнено по 5 прогонов теста для каждой ОС. По оси ординат на графиках время в секунду, значения делений оси абсцисс приведены в таблице
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 6 | 8 | 10 | 12 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
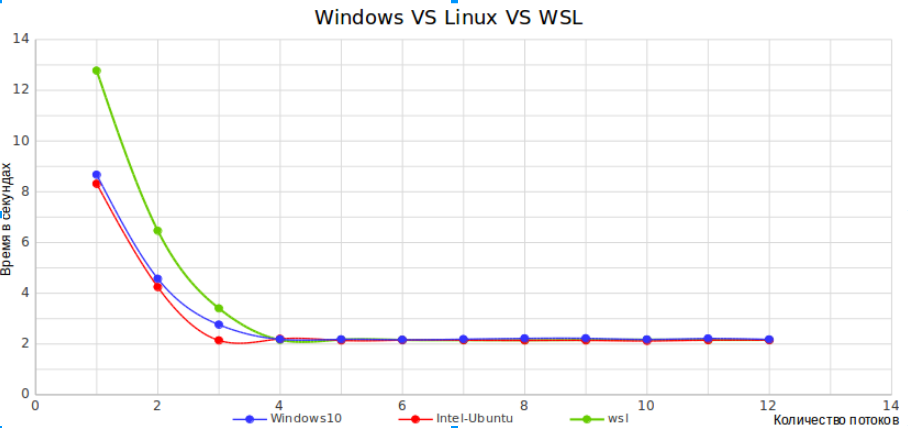

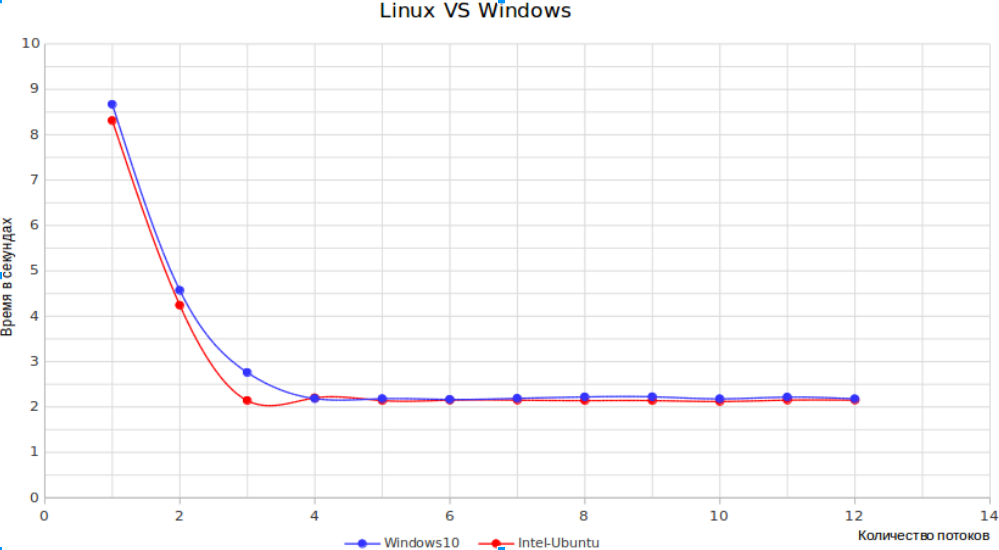
Выводы
- openMP — технология, которая позволит решить проблему скорости разработки многопоточного приложения, но не избавит от других проблем.
- Многопоточность — сложная и важная тема, неправильное использование несомненно приведёт к ухудшению результата работы.
- Linux VS Windows — дают практически одинаковые результаты, а значит использовать стоит ту платформу которая предоставляет нужный стек технологий и позволяет минимальными усилиями решить поставленную задачу.
Спасибо за внимание.
Комментарии (8)

DustCn
31.03.2017 17:19+2Кода нет… Непонятно что сравнивается.
Настроек OpenMP нет — значит by default, статический шедулинг.
И что мы меряем? Время создания пула потоков?
rafuck
31.03.2017 18:42Да даже банально компиляторы не указаны. По алгоритму, автор указал, что вычисляет число ПИ. Скорее алгоритм заключается в реализации составной квадратурной формулы для вычисления определенного интеграла по отрезку.
andrejev
31.03.2017 17:26Спасибо автору за статью. Было бы интересно посмотреть на сам код и понять, что скрывается за секункдами в данном примере (GB/s, GFlops).
Буквально 2 месяца назад занимался сравнение скорости работы библиотек thrust (TBB, OpenMP, CUDA) и bohrium (OpenMP, OpenCL) с реализацией в CUDA. Тестировали базовые вещи: reduce, transpose и stencil. Reduce считает сумму элементов, transpose транспонирует матрицу, про stencil лучше почитать тут.
Результаты reduce: Х ось - количество элементов, Y ось - GB в секунду

Anton_Menshov
01.04.2017 03:52+2Уважаемый автор статьи, приятно читать на Хабре, что люди интересуются параллельными вычислениями и OpenMP в частности. Однако, это все, что можно сказать положительного о вашей статье. Вы делаете очень резкие и громкие выводы без всяких на то оснований в виде фактических данных. Конкретнее (повторю некоторые из вещей, сказанных другими комментаторами выше):
1) Без конкретного кода, указанных настроек OpenMP разговора о каких-то выводах речи быть не может.
2) Без указания модели компилятора и параметров компиляции — то же самое. Кроме того, не стоит забывать, что даже один и тот же компилятор на одном и том же коде может вести себя по-разному на разных ОС на одной и той же машине.
3) Когда мы говорим об OpenMP — эта парадигма не ограничивается простым #pragma omp parallel for. В OpenMP разных спецификаций очень много инструкций, которые позволяют делать крутые вещи. В том числе, распараллеливать довольно трудный для параллельных вычислений код.
4) Процессор, на котором вы тестировали код имеет 4 ядра и 8 потоков. Для простого для распараллеливания кода (такого как вычисления числа пи) не имеет никакого смысла идти дальше 8 потоков. А, скорее всего, и четырех — ваши графики это собственно и показывают.
5) Такие графики необходимо строить в логарифмическом масштабе по оси времени (y) — будет гораздо понятнее. И очень сложно воспринимать графики, так как у вас WSL меняет цвет (красный и зеленый на первом и втором графике)
To sum it up: выводы должны основываться на фактах, а не на мнении. Ибо и мнение должно быть обосновано фактами. Особенно, если это мнение довольно противоречивое и ОБЩЕЕ.
Akon32
Ээ… Неинформативно как-то.
Обычно на графиках коэффициент ускорения в зависимости от числа потоков рисуют, и делают выводы.
Часто ещё полезно видеть коэффициент ускорения в зависимости от размера задачи (технологии параллелизма начинают быть эффективными только от некоторого размера).
tawr1097
Добрый день, согласен с Вашими замечаниями, но статья писалась в первую очередь для того, что бы показать, что сейчас все платформы практически одинаково справляются с многопоточными задачами решаемыми с применением OpenMP. На просторах часто ставился вопрос о применении OpenMP в разных ОС, а люди просили графики сравнения, отвечая на эти вопросы была написана данная статья.
exaw
Ну уж не «все платформы» конечно. а Win и Lin на Intel с неизвестным компилятором по вашей статье. Операционным системам, технологиям процессора, компиляторам и Open MP десятки лет. Как минимум, было бы странно, если бы этот стек не смог бы амортизировать на синтетической задаче всего лишь несколько потоков.
На реальной задаче может быть крайне трудным отжимать эффективность потоков по разным причинам, статья не должна вводить в заблуждение. И уж точно результаты не стоит масштабировать на реальные задачи или системы с сотнями потоков.
Удачи Вам в HPC исследованиях.
Akon32
Но ведь из графиков следует, что WSL как раз справляется хуже, чем просто Windows.