
Под катом расшифровка модуля, и видеозапись для тех, кто не захочет читать длинную расшифровку.
Сейчас мы рассмотрим раздел, посвященный отказоустойчивости, это HA, туда же относится как плановая миграция, так защита от плановых простоев – это функция vMotion и ее новые возможности в текущей версии vSphere и такая функция как Fault Tolerance. Об этом сейчас более подробно.
Это самая распиаренная вещь в vSphere 6. Вы уже могли встречаться уже с этой функцией, сейчас более подробно о ней.
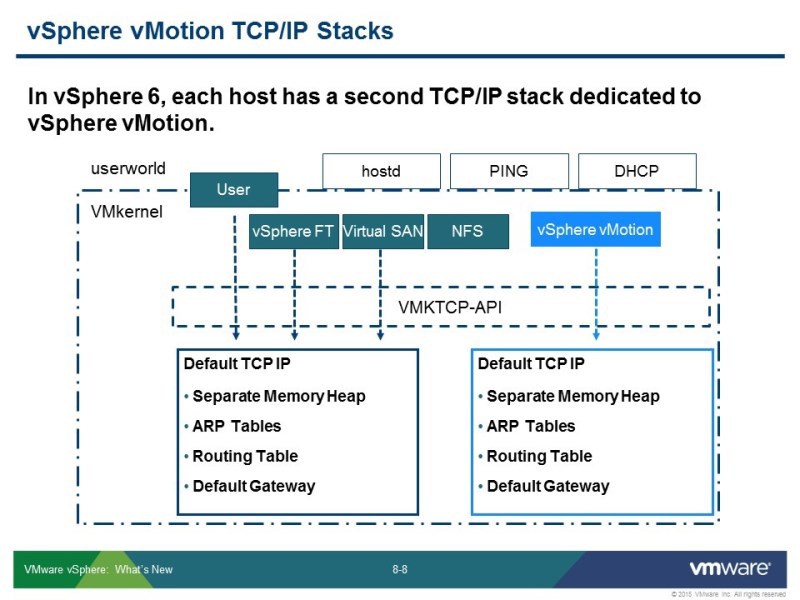
Для того, чтобы это можно было использовать, например, vMotion – миграция виртуальных машин между V-центрами. Для этого нужно было решить одну задачу, которая была архитектурная для подсистемы перенесения виртуальных машин на «горячую». Сеть vMotion – это была L2 сеть, чтобы она работала должен был быть один бродкаст домен, роутинг не поддерживался. Соответственно, чтобы передать на большие расстояние, не было ничего другого, кроме механизма с большими задержками, сейчас эта задержка составляет – 100-150 миллисекунд. Для этого нужно было внести архитектурные изменения в сеть vMotion и в само ядро. Плюс нужно было добавить возможность роутинга в vMotion сеть.
Для этого появилась возможность создания нового ТСР/IP стека, который служит для задач vMotion. На самом деле custom ТСР стек — он поддерживался и в предыдущих версиях, но это был не поддерживаемый вариант, его можно было завести из командной строки, но для того, чтобы узнать как — нужно было порыться с блогах. Теперь эта функция доступна сразу. Второй IP стек по умолчанию есть в системе, и он используется, чтобы использовать все новинки vMotion, которые появились.
Получается, что этот дополнительный стек не нарушает и не изменяет архитектуры vMotion, просто раньше дефолт гейтвей был для внутренней сети, чтобы выйти наружу нужен был другой дефолт гейтвей, там вы настраиваете канал, по которому vMotionы будут общаться. Причем вы ничего не трогаете, что было раньше, просто добавляете новую функцию.

Что это позволяет сделать? Переносить виртуальные машины, для этого используется L3 сеть – это во-первых, а во-вторых, можно переносить машины в большом варианте настроек:
— между свичами
— между V-центрами (не обязательно в рамках одного менеджмент-домена)
Появилась возможность переноса на большие расстояния. Для чего это может послужить:
— для перманентной миграции с площадки на площадку. Например, если есть 2 датацентра, нужно один выключить на обслуживание, значит машины, без остановки, даже без выключения можно перенести на другую площадку.
— это же может использоваться как упреждающее решение от каких-то катастроф разного характера, если ожидаются проблемы подобного рода – disaster recovery solution (например, если есть опасность какой-то бури, то вы можете все перенести в другое место).

Что нужно для переноса?
Сами виртуальные машины – это по прежнему сеть L2, потому что во время vMotionа не запускаются у вас дополнительные скрипты, перенастраивающие сетевую подсистему машины. Поэтому IP будет тот же.
Сеть vMotion – это уже L3 сеть. Чтобы работать с такими задержками, нужно подойти бережнее к полосе. Сейчас требования к полосе vMotion – 250 мгбит, это в 3 раза ниже чем в предыдущих версиях – 75% от гигабита использовалось для того, чтобы работал нормально vMotion. Уменьшение к требованию к полосе нужно было соблюсти чтобы запустить эту функцию.
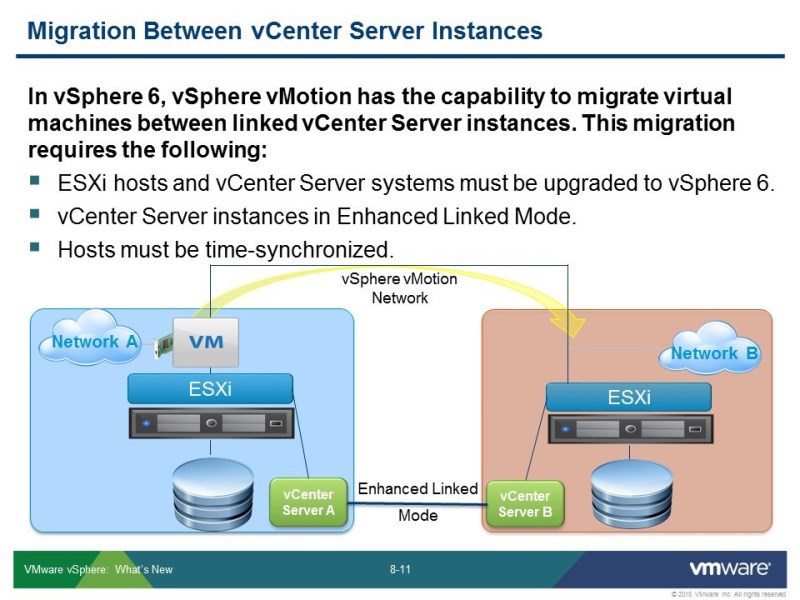
Есть некоторые дополнительные некоторые условия, чтобы это работало:
— все должно быть последней, 6й, версии, где эта функция доступна.
— V-центры должны быть соединены между собой, чтобы могли передавать друг другу нужную информацию. Виртуальная машина переезжает из одной инфраструктуры в другую, и она уже «едет с чемоданом вещей». Например, если она была в каком-то кластере, то есть настройки, касающиеся ее. Например, какие-нибудь правила admission контрола – она переезжает вместе с ними.
— чтобы это все сработало, с учетом криптования канала, нужно чтобы все это было синхронизировано по времени.

Что проверяет vCenter перед миграцией и что сохраняется?
— виртуальная машина переезжает со своими настройками, и нужно проверить чтобы не было конфликта МАС адресов, даже если эти адреса генерятся автоматически vСферой, они все равно могут совпасть, поэтому нужно проверять.
Остальные требования стандарты для vMotionа для обмена не только между хостами но и между vЦентрами:
— чтобы виртмашина не потеряла соединения с продакшн сетью, она не должна быть подключена к свичу, у которого нет аплинка – не должна использовать внутреннюю сеть, сеть, к которой она подключена, должна быть доступна в новой точке в том числе.

Все, абсолютно все, настройки виртуальной машины переезжают вместе с ней. Меняется кластер, соответственно, нужно передать все эти параметры
Функция Fault Tolerance
Эта функция хорошо выглядит на демонстрациях, и хорошо на слух воспринимается, но полезной ее назвать никак было нельзя до вот этой версии реализации. В связи с техническими ограничениями. Эту функцию можно было включить только для одноядерной, однопроцессорной машины, которая не использует больше 16 гиг оперативной памяти.
Напоминаю, что функция НА, чтобы ей воспользоваться, нужно создать кластер, и в рамках его можно включить Fault Tolerance, которая защищает машину постоянно. Переключение с одной копии на вторую происходит мгновенно, не пропадает даже пинг, сетевое взаимодействие не нарушается, и время простоя практически нулевое. Проблема была в том, что ни одну машину таким образом нельзя было защитить.

Теперь требования упростились. Эту функцию можно использоваться и в продакшене – до 4 процессоров, до 64 гиг оперативки – может быть для машины, для которой можно включить vMotion.
Во-вторых, сам алгоритм работы поменялся. Используются другие протоколы, и немного иначе все это работает, проще, но есть некоторые моменты. Часть требований ужесточилась: например, требования к сети, потому что больше данных нужно передать. С другой стороны, часть требований упростилось: теперь не нужно, как раньше, все настраивать на полную производительность. Если в предыдущей версии vSphere, вы включали Fault Tolerance, то у вас тонкие диски раздвигались в толстые – только они использовались, память устанавливалась на максимальный резерв. Теперь это все не обязательно, теперь, по крайней мере все тонкие диски остаются такими же тонкими.
И теперь другой алгоритм синхронизации (изображен на слайде).
— без потери данных
— без простоя
— без потери сетевого соединения
То есть практически мгновенное переключение на запасную копию.
Функция также работает и в рамках кластера, и здесь используется как механизм, который сигнализирует о сбое хоста. Эта функция защищает и от обратного сбоя. В случае сбоя основного хоста, происходит мгновенное перебрасывание на запасной хост.

Вот сравнение, как было в предыдущих версиях, и как в этой версии.
— процессоры — до 4
— не обязателен один гомогенный кластер, определенный набор проверок происходит, но менее строгие требования
— используются некоторые функции новых процессоров, в частности, должна быть поддержка аппаратной виртуализации 2 версии
— диски могут быть любые, не нужно их раздвигать
VMDK redun – о чем идет речь. Если раньше, машина, которую защищает Fault Tolerance, должна лежать на shared хранилище (происходит копирование только памяти хоста и состояния процессора) – это две виртуальные машины, которые считаются на 2 хостах, которые должны быть максимально близки по параметрам. То теперь машина может целиком лежать на одном хосте, на втором хосте целая ее копия в оперативной памяти, и файлы на дисках. Наличие шары обязательно, но не для хранения виртуальной машины. Синхронизация происходит как данных на дисках, так и оперативной памяти. Естественно, за это придется расплачиваться – чтобы это включилось, нужно 10 гигабит. Законы физики не нарушить – чем больше данных нужно передать, тем больше нужна пропускная способность сети.
Количество машин на хост не изменилось – до 4-х, всего 4. Высокоуровневая архитектура не поменялась: есть основная машина, и та, которая защищается, соответственно их может не больше 4 на хост, здесь ничего не изменилось.
vSphere DRS – пока не полностью поддерживается. Старая функция Fault Tolerance поддерживала DRS, можно было и сделать vMotion для любой машины, primary-secondary и DRS умел с этим работать, то теперь vMotion сохранился, но кластер пока не научился с этим работать. Это опять же, логично, с учетом того, что теперь in-share стореджи и здесь работает что-то похожее на аналог Enhanced vMotion, а он не работает для кластеров, поэтому DRS не используется.

НА в любом случае нужно настраивать, потому что он используется до сих пор как механизм, который скажет о том, что произошла проблема с хостом. И отработает стандартный механизм, который перезапускает машину, и отработает механизм Fault Tolerance, который просто переключает на запасную, на копию.
DRS о таких настройках Fault Tolerance знает, и при включении будет учитывать что primary и secondary должны быть на разных хостах. В любом случае НА и DRS будут разбрасывать машины по разным хостам. Как я уже сказал раньше: высокоуровневая архитектура не поменялась.

Этот слайд про то, что машина не обязательна должны бать на shared хранилище. Происходит синхронизация всех файлов виртуальной машины: vmdk-файлов и конфигурационных файлов. Можно защищать с помощью Fault Tolerance виртуальную машину, которая лежит на локальном хранилище. Понятно, что количество данных при этом будет передаваться больше – это еще одна из причин, зачем нужно 10 гигабит, но зато shared сторедж нужен исключительно для конфигурационных целей.
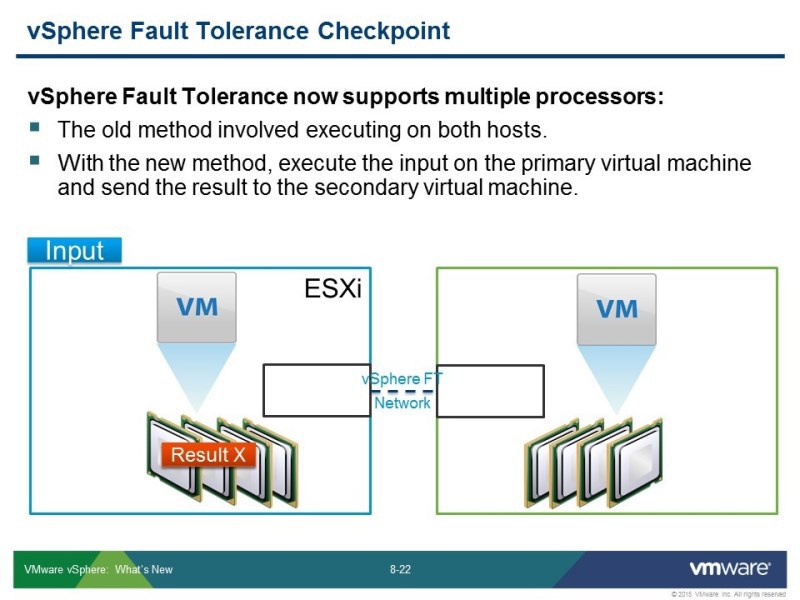
Изменился сам подход в работе алгоритмов. В предыдущей версии, это была синхронизация двух работающих, считающих процессоров на двух хостах. Теперь все происходит на основной (primary) машине, расчеты делает один хост, и с небольшим промежутком времени данные передаются на дополнительную (secondary) машину. Что с точки зрения человека выглядит как синхронная, одновременная передача. То есть не нужно синхронизировать состояние процессора, это по сути instant vMotion получается. Вы запускаете vMotion, при этом у вас не удаляется исходник, и он постоянно синхронизирует данные на одном хосте и на втором. При этом он синхронизирует и состояние оперативной памяти и состояние vmdk файлов.

Вот графически показано как используется этот алгоритм. Во втором Fault Tolerance было что-то похожее, но там был специальный протокол для синхронизации расчетов, то теперь это специфическое использование функции vMotion. Во время этой процедуры, через определенные промежутки времени, копируются страницы памяти с одного хоста на другой, которые отмечены в таблице как либо «не использующиеся в текущий момент времени» либо «наименее часто использующиеся». Если же они за момент копирования изменились, запускается процесс докопирования.

Здесь используется похожий подход, но используется механизм fast checkpoint. Эти синхронизации делаются через четкий промежуток времени – через 10 миллисекунд, данные, которые за это время изменились, передаются на вторую машину, на соседний хост, который на соседней машине вертится. Постоянно запущенна эта функция, которая отслеживает эти чекпоинты
Это происходит постоянно, пока включена функция Fault Tolerance. Пару лет назад было превью, вот на такой машине – 4 ядра, 64 гига, с БД средней нагруженности, там трафик Fault Tolerance по сети был порядка 3-4 гигабит. Соответственно от 10 это может «скушать» хороший кусок. Это зависит от данных в виртуальной машине, база данных – это хороший пример, чтобы посмотреть, сколько полосы может уйти на это.
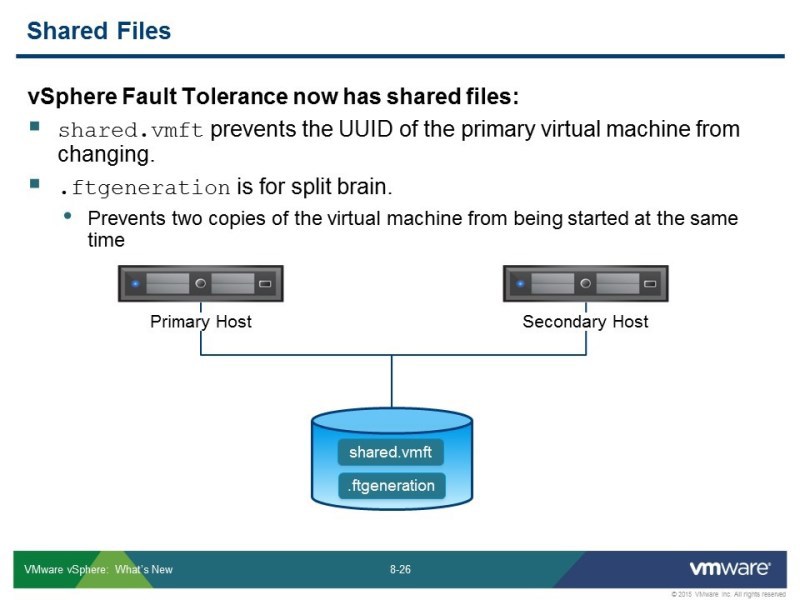
Все-таки shared хранилище нужно – для чего? Чтобы синхронизировать работу этого механизма. Создаются 2 файла: shared.vmft и .ftgeneration – у каждого своя задача. shared.vmft – это передача некоторой конфигурации. Для того чтобы хосту, в случае срабатывания режима НА, сказать где какую машину включить. Ftgeneration – это защита от т.н. «шизофрении» сплит брейна, от стандартной проблемы, которая в разных типах кластера возникает, чтобы не было дублирования сервиса. Чтобы случайно не определился хост как сбойный, и не включились сразу 2 копии машины с одинаковыми IP-адресами, сетевыми настройками – ни к чему хорошему это не приведет. Этот датастор может быть не большой, больших требований по производительности к нему нет, но чтобы это сработало все-таки нужен shared датастор, чтобы положить эти конфигурационные файлы.
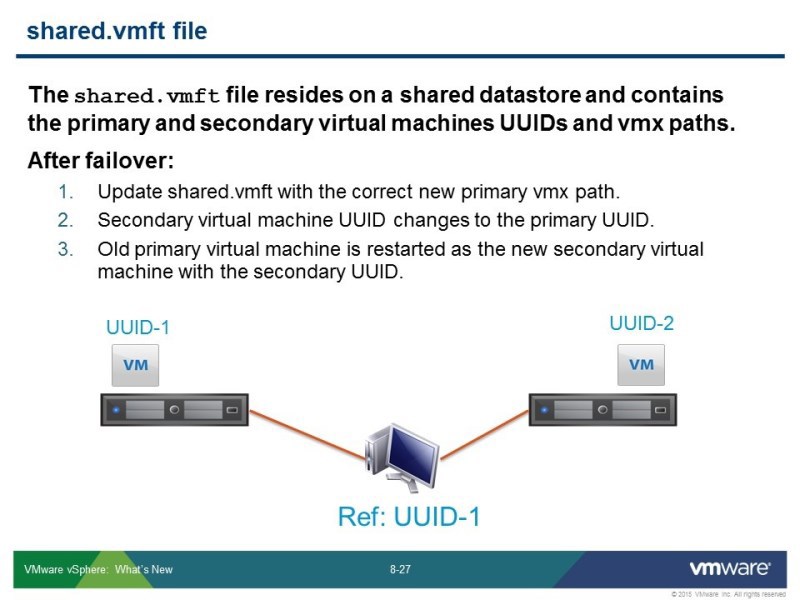
В shared.vmft – находятся информация и ID «виртуалок», и пути в vmx файлах, где в текущий момент находятся виртмашины: какую когда включать. При переезде с хоста на хост, меняется информация в этих файлах.
Если 2 хоста в кластере, то при сбое они просто (как бы) поменяются местами. А если у вас кластер на 10 хостов, то, если у вас ломается хост, на котором была primary машина, у вас переключается работа на secondary – она становится primary, потому что у вас хост не выключен, и он тут же создают автоматическую копию. И защита продолжает работать, пока хватает хостов на это, либо пока хватает ресурсов.
Если у вас 3 хоста – primary машина, secondary машина, если primary хост сломался, то на 3 машине создастся secondary машина, а secondary станет primary и защититься на 3й хост.
Если у вас 2 хоста – при сбое хоста, защита сработает, но дальше, на втором хосте, который был secondary, он стал primary, то уже на него защита не сработает на следующую итерацию. Если первый хост перезагрузился, то он попадет опять в НА, включится Fault Tolerance он станет secondary, а второй останется primary. Стороннему наблюдателю будет казаться, что они поменялись местами, но на самом деле система пересоздалась. Как раз задача файла ftgeneration, чтобы на 2 хостах не запустилась primary машина. Он пробует переименовать файл, если лог живой, то это просто не удастся. В текущий момент времени машина primary использует этот файл под себя и не даст его переименовать – стандартный подход с блокировкой файла. Если машины primary нет, то файл отпустится, по тайм-лизу отпустится лог, или тайм-стампу это можно будет посмотреть и тогда будет понятно, что нужно запускать вторую primary машину.
В нашей виртуальной среде получить 10 гигабит – не проблема. Но явно нужны какие дополнительные ключи, так как требуется второй уровень виртуализации, плюс аппаратная поддержка должна быть второго поколения. Какие-то дополнительные проверки отключаются какими-то ключами через advanced settings, но VMware о них пока ничего не говорит. Для прошлой версии Fault Tolerance – о том, что ее можно запустить в виртуальной среде – информация появилась только спустя какое-то время. Они это явно тестировали, unsupported режим в целях обучения – было удобно, может и здесь появится в следующих релизах, может это принципиально невозможно, дальше будет видно.

По поводу НА – появилась такая функция как Virtual Machine Component Protection – он научился понимать состояние по хранилищу. НА – может защитить от проблем с подключением к хранилищу, если хранилище пропало – то до 6 версии, он бы не показал это как проблему, которая попробует перезапустить «виртуалку» на другом хосте, то есть хост продолжает работать, но «виртуалка» на нем мертвая, и хост продолжал бы ее поддерживать.
Теперь он эти проблемы отслеживает, и он попробует перезапустить систему на другом хосте, у которого сохранилась связь с хранилищем.
НА – теперь может защитить от большего количества проблем

Кластеры стали больше, соответственно и НА стал больше, и все кластеры стали больше. Теперь до 64 и большее (до 6000) количество машин можно защитить с помощью НА в том числе.
Может работать Virtual Volumes и далее по списку, здесь появился NSX – виртуальные сети, построенные с его помощью – с ними также будет работать НА. Здесь такая проблема – если нет vCenter, нет какого управляющего контроллера, то нужно машину, перезапущенную на другом хосте, когда нет управляющей части, включить в какую-то порт группу – в сеть, которая построена с помощью NSX, то есть виртуальную сеть.
Есть механизм, который позволяет это сделать. Для дистрибьютед свича эта информация на датасторе в папке сохраняется, то для NSX тоже есть способ получить конфигурацию из порт-группы.

vCloud Air – это облако VMware, у него достаточно непростая судьба, VMware – одна из первых компаний, которая выпускала публичное облако, это было лет 5 назад, тогда еще Амазон только развивался. Было пару неудачных запусков, не получилось у них с нагрузкой, потом была пауза, облако переименовывали. Сейчас снова ребрендинг – vCloud Air. За это время конкуренты ушли вперед. У облака VMware – определенная ниша. С выходом на рынок у них вышла задержка. Компания сравнительно небольшая, по сравнению с тем же Амазоном, они не строили свои датацентры, находили подходящие, арендовали мощности – и поэтому долго выходили на международный рынок. Для нас это стало актуально несколько месяцев назад, когда VMware анонсировало открытие дата-центра в Германии, от нас это уже недалеко, и это уже можно рассматривать как вариант облака, где можно покупать ресурсы. Покупка поинта, в котором можно пользоваться vCloud Air – есть в любом канале, у любого дистрибьютора. Тамже где вы покупаете продукты VMware, там можно купить паки vCloud Air, здесь вы можете использовать свои балы.
Подключение со стороны платформы. C помощью веб-клиента, там есть закладка «подключить vCloud Air», если у вас там есть аккаунт, можно, пользуясь привычными инструментами, использовать привычное облако. Это модный, нынче, тренд – построение гибридных облаков, когда часть ресурсов у вас есть локально, часть арендуется в публичном облаке. При этом это облако построено на тех технологиях, такое же в управлении, это гораздо более удобно, по крайней мере на уровне администратора. Чем использование «неродного», с точки зрения технологии, облака, потому что до тонких настроек там не добраться. С точки зрения пользователя – все равно, какой вы портал используете, то администратору, чтобы управлять немного глубже чем включить-выключить виртуальную машину, гораздо удобнее использовать однотипные технологии.
У VMware есть продажа продуктов – то, чем все мы с вами пользуемся, и есть аренда продуктов, чтобы можно было построить свое облачное решение – называлась эта программа раньше VSPP, сейчас она называется vCloud Air Network. Можно купить продукт, а можно взять его в аренду. Можно также все эти варианты объединить. Если у вас есть свое локальное облако и есть свой датацентр, построенные на базе технологий VMware, и vCloud Air Network – такое же облако, которое управляется админами VMware, с единым окном суппорта.
Что касается vCloud Air. В плане менеджмента – это веб-клиент и коннектор (который вы можете скачать – чтобы коннектор заработал в веб-клиенте). Что касается финансовой части – это все из My VMware. Вы можете покупать поинты по стандартному каналу, в My VMware они у вас будут отдельным пунктом, и вы можете отслеживать их использование. Если какая-то проблема – вы размещаете тикет через My VMware – в этом плане все однотипно.
Например, для того чтобы стать клауд провайдером есть отдельная программа. Есть стандартная программа продажи продуктов – партнерский канал: дистрибьюторы, ресселлеры и конечные пользователи, а есть канал на для аренды ПО – это отдельные компании-агрегаторы, не дистрибьюторы, которые предоставляют по программе vCloud Air Network своим клиентам позволяет строить свое решение на арендуемом ПО, там есть такая непростая схема.
Основное то, что все этим, как гибридным облаком, можно воспользоваться из стандартного инструмента менеджмента, [гибридные облака такого типа] гибкое использование ресурсов, сейчас эта тема — основной тренд.
У вас это просто другой датацентр, в котором, вы, конечно, до уровня хоста доберетесь, но «виртуалки» вы можете делать из того же веб-клиента. У вас будет выделен какой-то кусок в виде пула ресурсов, и можете в рамках его что-то делать, также как вы это делаете в своем локальном облаке, где вы администратор.
Насколько я знаю vCloud Air сейчас построен на vCloud директоре, как и большинство публичных облаков VMware, но постепенно все это перейдет на те технологии, которые сейчас актуальны. vCloud Director остался как актуальная технология для провайдеров, потому что там не так важна интеграция с другими облаками, там важно предоставление технологии VMware как облачного ресурса, поэтому там замкнутость этого решения не так сильно влияет на что-то. Для конечников он уже не продается, так как здесь важно обеспечить текущий тренд мультиплатформенности, поэтому предлагается решения VMware Lise Automation или вариант на open stack, платформа VMware – там один из выборов. Для энд-юзеров это более гибкий подход. В 6 сфере вместо директора – VMware Lise Automation, директор еще будет некоторое время поддерживаться, но купить его уже нельзя.
В рамках этого модуля – всё.
Запись стрима:
UPD по просьбам читателей: презентация
Дистрибуция решений VMware в Украине, Беларуси, Грузии, странах СНГ
Учебные курсы VMware
Наши ближайшие курсы в Киеве:
15-19 июня, VMware vSphere 5.5: Fast Track
1-3 июня, Managing 3PAR Disk Arrays
4-5 июня, Мanaging HP 3PAR Disk Arrays: Replication and Performance
8-10 июня, ITIL® V3 Foundation: Основы ITIL для управления ИТ-услугами
Комментарии (4)

navion
04.06.2015 00:45Можете что-нибудь рассказать про изменения в VCP6?
В бета-экзамене была куча хардкорных вопросов уровня VCAP, а в рекомендациях указан курс O&S. При этом учебник ICM V6 остался на том же неглубоком уровне и по нему невозможно подготовиться к экзамену.
Muk Автор
02.07.2015 15:26Ответ инструктора: «Куча хардкорных вопросов уровня VCAP» — это фраза с двумя не очень конкретизированными утверждениями — куча это сколько и как вы определяете уровень вопроса? На курсах я всегда говорю что к сдаче экзамена нужно готовится отдельно, есть блюпринты с описанием групп вопросов и курсы не закрывают все на 100% — VMware это нигде не утверждала, что вы после курса можете сдать экзамен на следующий день (в рекомендациях написано иметь не менее полугода практического опыта). Кроме того с 6ки сертификация меняется — вместо VCAP будет VCIX, есть вероятность, что в базовую сертифкацию переедет часть вопросов из адвансед, кроме того суть беты экзамена — собрать отзывы и релизный экзамен вполне может оказаться проще беты. ICM любой версии всегда считался базовым курсом для тех, кто видит сферу впервые.
gotch
Не могли бы вы добавить ссылку на слайды оригинальной презентации?
Muk Автор
Добавили.