Не секрет, что курс рубля напрямую зависит от стоимости нефти (и от кое-чего еще). Этот факт позволяет строить довольно интересные модели. В своей статье о линейной регрессии я коснулся некоторых вопросов, посвященных диагностике модели, а за кадром остался такой вопрос: есть ли более эффективная, но не слишком сложная альтернатива линейной регрессии? Традиционно используемый метод наименьших квадратов прост и понятен, но есть и другие подходы (не такие понятные).
Данные и диагностика МНК
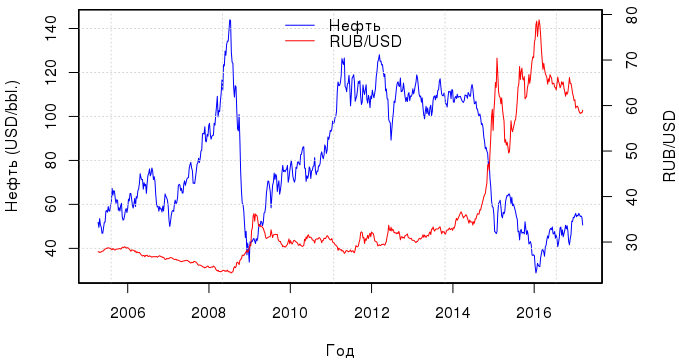
В этой статье мы сравним несколько линейных по своей сути моделей, используя в качестве наглядного пособия зависимость курса рубля от стоимости нефти. Помните этот замечательный пост? Спустя два года настало время обновить графики. Свежие данные загрузим с Quandl: за кодом "EIA/PET_RBRTE_D" скрывается спотовая цена на нефть марки Brent в $, а за "BOE/XUDLBK69" — стоимость 1 доллара в российских рублях.
library(Quandl)
library(zoo)
library(dplyr)
oil.ts <-Quandl("EIA/PET_RBRTE_D", trim_start="2005-04-03", trim_end="2017-03-10", type="zoo", collapse="weekly")
usd.ts <-Quandl("BOE/XUDLBK69", trim_start="2005-04-03", trim_end="2017-03-10", type="zoo", collapse="weekly")Временной промежуток — с апреля 2005 по март 2017 года. И вот какая динамика наблюдается за этот период, если выразить стоимость рубля в долларах:

Если судить по графику, то связь между кривыми стоимости рубля и нефти прослеживалась постоянно, но после 2012 г. она стало особенно тесной. В принципе, нет особого смысла строить одну регрессию МНК за все эти года, т.к. в связи с резкими колебаниями цен остатки регрессии будут иметь мультимодальное распределение, и получится модель, которая все плохо описывает. Поэтому рассмотрим период с марта 2015 г. по декабрь 2016 г. — это будет обучающая выборка; данные за 2017 г. используем для тестирования.
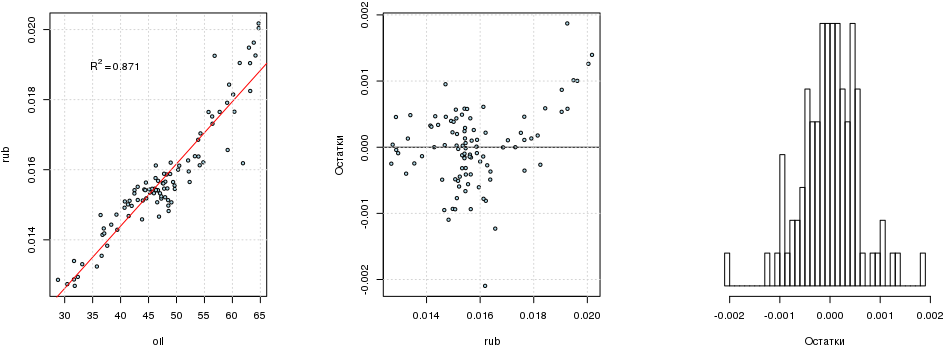
Характер связи с 2015 г. не изменился, и линейная регрессия rubi=a+b·oili, построенная с помощью МНК статистически значима:
tr.s <- "2015-03-01"; tr.e <- "2016-12-31"
train <- data.frame(oil=as.vector(window(oil.ts, start=tr.s, end=tr.e)),
rub=as.vector(window(rub.ts, start=tr.s, end=tr.e)),
date=index(window(oil.ts, start=tr.s, end=tr.e))) %>%
mutate(month=factor(format(date, "%m")),
date=NULL)
te.s <- "2017-01-01"; te.e <- "2017-03-15"
test <- data.frame(oil=as.vector(window(oil.ts, start=te.s, end=te.e)),
rub=as.vector(window(rub.ts, start=te.s, end=te.e)),
date=index(window(oil.ts, start=te.s, end=te.e))) %>%
mutate(month=factor(format(date, "%m")),
date=NULL)
fit1 <- lm(rub ~ oil, data=train)
summary(fit1)
##
## Call:
## lm(formula = rub ~ oil, data = train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.096e-03 -3.265e-04 4.510e-06 3.491e-04 1.871e-03
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 7.284e-03 3.396e-04 21.45 <2e-16 ***
## oil 1.777e-04 7.009e-06 25.35 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.0005883 on 94 degrees of freedom
## Multiple R-squared: 0.8724, Adjusted R-squared: 0.871
## F-statistic: 642.7 on 1 and 94 DF, p-value: < 2.2e-16Если убрать свободный член, то R2 будет почти равен единице. Этому есть объяснение. Как бы это ни было заманчиво, но просто так обнулять свободный член нельзя (разве что исследуемый процесс гарантирует, что линия регрессии проходит через начало координат): кому интересно, можно почитать здесь. Не стоит зацикливаться на R2 — этот критерий достаточно формален. Что касается остатков модели, то они распределены в целом неплохо, но, похоже, бимодально:
library(lmtest)
dwtest(fit1)
##
## Durbin-Watson test
##
## data: fit1
## DW = 0.49421, p-value < 2.2e-16
## alternative hypothesis: true autocorrelation is greater than 0
resettest(fit1)
##
## RESET test
##
## data: fit1
## RESET = 13.999, df1 = 2, df2 = 92, p-value = 4.924e-06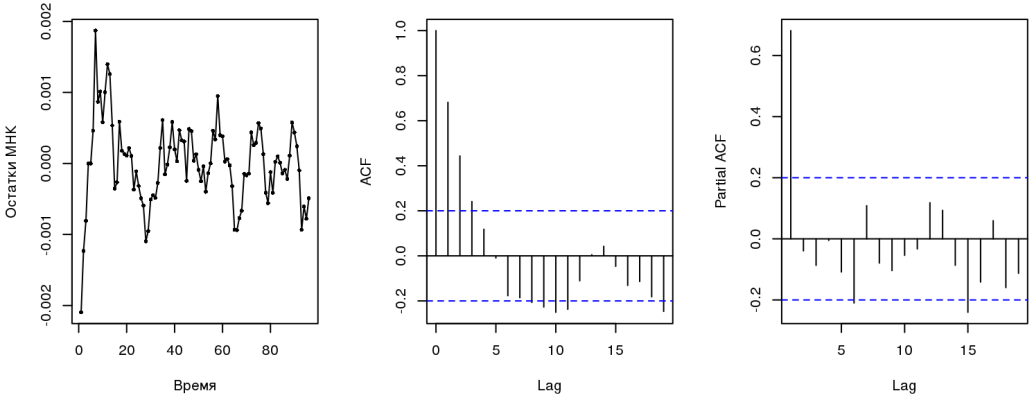
Тест Дарбина-Уотсона говорит о наличии (кто бы мог подумать) автокорреляции; коррелограммы остатков указывают на процесс типа AR(1) (об этом мы поговорим ниже). RESET-тест свидетельствует о пропущенных переменных, что логично, т.к. на курс влияет множество факторов (либо МНК — не самая подходящая модель). Все это вместе нарушает предпосылки, которые лежат в основе МНК. Тот, кто занимается эконометрикой, скажет, что пользоваться такой регрессией надо осторожно, т.к. все оценки смещенные и несостоятельные, нельзя строить доверительные интервалы. Из всех свойств сохраняется только линейность.
Можно провернуть еще такой трюк: возможно, зависимость не линейная, а включает и полиномиальные члены. Как выбрать более-менее оптимальную модель? Придется воспользоваться либо перекрестной проверкой, либо информационным критерием типа AIC. Для линейной модели последний мне больше нравится, тем более, что в асимптотике результаты AIC и CV сходятся. Код, приведенный ниже, как раз выполняет то, что нужно: строятся полиномиальные регрессии со степенью от 1 до 5, и на основании минимума критерия AIC определяется оптимальная модель. Функция poly() строит ортогональные полиномы, и именно их надо использовать при регрессии.
which.min(sapply(1:5, function(i) AIC(lm(rub ~ poly(oil, i), data=train))))
## [1] 3Таким образом, получается, что модель может иметь и такой вид:
Временные ряды и ошибки
О временных рядах можно рассуждать бесконечно и с переменным успехом. Нам же надо знать вот что. И курс рубля, и стоимость нефти являются временными рядами, и не учитывать это нельзя (отсюда и возникают проблемы с ошибками в МНК). Некоторые же процессы можно описать с помощью простой авторегрессионной модели первого порядка. Это означает, что следующее значение во временном ряду хорошо описывается предыдущим плюс небольшая ошибка:
где ?t - белый шум.
Построим модель ARIMA с дополнительным регрессором:
library(forecast)
fit2 <- auto.arima(train$rub, xreg=train$oil)
summary(fit2)
## Series: train$rub
## Regression with ARIMA(1,0,0) errors
##
## Coefficients:
## ar1 intercept train$oil
## 0.9123 0.0108 1e-04
## s.e. 0.0417 0.0004 0e+00
##
## sigma^2 estimated as 1.274e-07: log likelihood=626.46
## AIC=-1244.91 AICc=-1244.47 BIC=-1234.65
##
## Training set error measures:
## ME RMSE MAE MPE MAPE
## Training set 1.424521e-05 0.000351317 0.0002580076 0.02303551 1.610766
## MASE ACF1
## Training set 0.7766594 0.02983604Из информации об этой модели можно узнать, что при регрессии rubi=a+b·oili + ui ошибки ui имеют автокорреляционную структуру ARIMA(1, 0, 0), т.е. как раз и представляют собой авторегрессионную модель первого порядка AR(1).
Т.к. теперь структура ошибок приблизительно известна, попробуем обобщенный метод наименьших квадратов (GLS). В GLS используется простая идея, которая заключается в следующем. Если при решении системы y=Xb+? методом наименьших квадратов коэффициенты при регрессорах и ковариационная матрица находятся из уравнений
то при использовании GLS соответствующие уравнения будут иметь такой вид:
Тут ? — ковариационная матрица ошибок, которую можно оценить, зная их структуру. В теории такая модель дает несмещенные, эффективные, состоятельные и асимптотически нормальные оценки ( теорема Айткена).
library(nlme)
fit3 <- gls(rub ~ oil, data=train, correlation=corAR1(value=0.7, form=~1|month))
summary(fit3)
## Generalized least squares fit by REML
## Model: rub ~ oil
## Data: train
## AIC BIC logLik
## -1173.847 -1163.674 590.9237
##
## Correlation Structure: AR(1)
## Formula: ~1 | month
## Parameter estimate(s):
## Phi
## 0.7478772
##
## Coefficients:
## Value Std.Error t-value p-value
## (Intercept) 0.007860934 0.0004055443 19.38366 0
## oil 0.000163683 0.0000081087 20.18601 0
##
## Correlation:
## (Intr)
## oil -0.952
##
## Standardized residuals:
## Min Q1 Med Q3 Max
## -2.96100735 -0.41075284 0.07903953 0.62870157 3.42607023
##
## Residual standard error: 0.0006099571
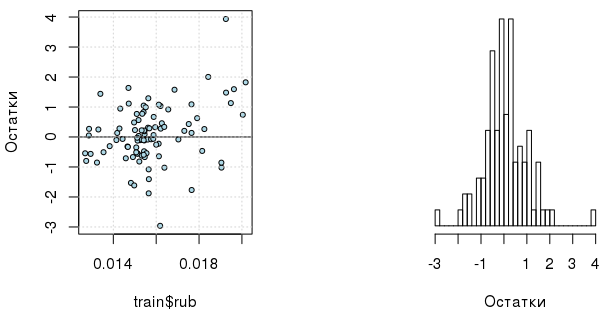
## Degrees of freedom: 96 total; 94 residualМожно еще проверить, получим ли мы какую-либо выгоду от включения полиномиальных членов в GLS согласно критерию AIC:
which.min(sapply(1:5, function(i) {
d <- data.frame(poly(train$oil, i), month=train$month, rub=train$rub)
AIC(gls(rub ~ . - month, data=d, correlation=corAR1(value=0.7, form=~1|month)))
}))
## [1] 1Теперь достаточно регрессора в 1 степени. И, кстати, сами скорректированные ошибки модели распределены интереснее (хотя нельзя не отметить наличие выбросов):
Регрессия Байеса и вероятностный выбор переменных
К этому моменту у нас есть три модели: OLS, ARIMA(1, 0, 0), GLS с ошибками AR(1). Теперь рассмотрим задачу с другой стороны и в иной постановке, задаваясь прежде всего вопросом, нужны ли нам, например, полиномиальные члены:
Тут записано, что переменная yi распределена нормально и линейно зависит от степеней xi. В свою очередь коэффициенты регрессии не просто распределены нормально, но и еще могут "отсутствовать" в уравнении, что обеспечивается идикаторной переменной Ij, которая подчиняется распределению Бернулли с параметром p, т.е. может принимать только значения 0 или 1. Параметр p в свою очередь берется из бета-распределения, а параметры ? и ?b — из гамма. Так мы задали априорные распределения. Откуда известны их точные формы? Вот здесь теория не очень внятная и предлагает опираться либо на наши практические понятия о природе описываемых процессов или интуицию, либо задавать неинформативные априорные распределения. К счастью, чем больше данных доступно, тем меньше вывод зависит от априорных распределений. И это становится понятным, если взглянуть на формулу Байеса, которая представляет собой правило, согласно которому изменяются априорные распределения при наблюдении определенных данных:
Тут p(?|y) — апостериорное распределение, p(y|?) — правдоподобие, p(?) — априорное распределение. Тогда можно записать:
И далее по инерции:
Но все же желательно, чтобы распределения были более-менее осмысленными. Так, если посмотреть на гистограмму yi (у нас это курс рубля), то там можно увидеть кривую, напоминающую нормальное распределение (или логнормальное...). А что касается коэффициентов регрессии, то здесь выбор распределения Гаусса оправдан традиционным ожиданием того, что они распределены нормально.
Конечно, никто не хочет заниматься увлекательным выводом вручную, поэтому нам понадобится библиотека, позволяющая описывать модель в терминах априорных распределений. В R это rjags, и еще функции-обертки из R2jags. Все вышеизложенное запишется в таком виде:
library(R2jags)
model1 <- "model {
for (i in 1:n) {
y[i] ~ dnorm(a + inprod(X[i,], b[]), tau)
}
for (j in 1:p) {
ind[j] ~ dbern(pind)
bT[j] ~ dnorm(0, taub)
b[j] <- ind[j] * bT[j]
}
a ~ dnorm(0, 1e-04)
tau ~ dgamma(1, 1e-03)
taub ~ dgamma(1, 1e-03)
pind ~ dbeta(2, 9)
}"
p <- 5
m.jags1 <- jags(data=list(y=train$rub,
X=poly(train$oil, p),
n=nrow(train),
p=p),
parameters.to.save=c("a", "b", "ind"),
model.file=textConnection(model1),
n.chains=1, n.iter=5000)
m.jags1
## Inference for Bugs model at "5", fit using jags,
## 1 chains, each with 5000 iterations (first 2500 discarded), n.thin = 2
## n.sims = 1250 iterations saved
## mu.vect sd.vect 2.5% 25% 50% 75% 97.5%
## a 0.016 0.000 0.015 0.015 0.016 0.016 0.017
## b[1] 0.011 0.007 0.000 0.006 0.013 0.017 0.023
## b[2] 0.000 0.001 0.000 0.000 0.000 0.000 0.003
## b[3] 0.000 0.001 0.000 0.000 0.000 0.000 0.000
## b[4] 0.000 0.001 0.000 0.000 0.000 0.000 0.000
## b[5] 0.000 0.001 0.000 0.000 0.000 0.000 0.000
## ind[1] 0.764 0.425 0.000 1.000 1.000 1.000 1.000
## ind[2] 0.046 0.210 0.000 0.000 0.000 0.000 1.000
## ind[3] 0.034 0.180 0.000 0.000 0.000 0.000 1.000
## ind[4] 0.031 0.174 0.000 0.000 0.000 0.000 1.000
## ind[5] 0.045 0.207 0.000 0.000 0.000 0.000 1.000
## deviance -848.261 15.731 -876.531 -858.633 -848.740 -838.639 -815.570
##
## DIC info (using the rule, pD = var(deviance)/2)
## pD = 123.7 and DIC = -724.5
## DIC is an estimate of expected predictive error (lower deviance is better).Вывод показывает, что средние значения индикаторных переменных Ij при коэффициентах регрессии b2,...,b5 на порядок меньше I1, а это значит, что такая вероятностная модель дает нам право предположить, что курс рубля линейно зависит от стоимости нефти. Далее запишем простую линейную модель, учитывающую наличие авторегрессии первого порядка в ошибках:
model2 <- "model {
a ~ dt(0, 5, 1)
b ~ dt(0, 5, 1)
phi ~ dunif(-1, 0.999)
tau0 ~ dgamma(1, 1e-03)
tau[1] <- tau0
y[1] ~ dnorm(a + b * x[1], tau[1])
for (i in 2:n){
tau[i] <- tau0 + phi * tau[i-1]
y[i] ~ dnorm(a + b * x[i], tau[i])
}
}"
set.seed(123)
n <- nrow(test)
m.jags2 <- jags(data=list(y=c(train$rub, rep(NA, n)),
x=c(train$oil, test$oil),
n=nrow(train)+n),
parameters.to.save=c("a", "b", "phi", "y"),
model.file=textConnection(model2),
n.chains=1, n.iter=5000)Так выглядят апостериорные распределения параметров модели:
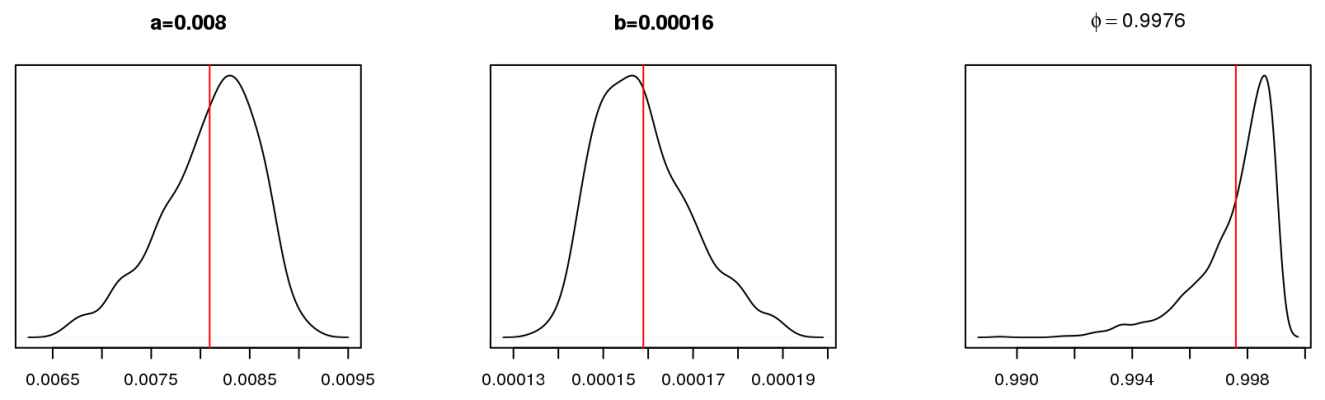
Можно заметить, что они не сильно отличаются от параметров модели GLS. Само уравнение регрессии для средних значений параметров можно записать так:
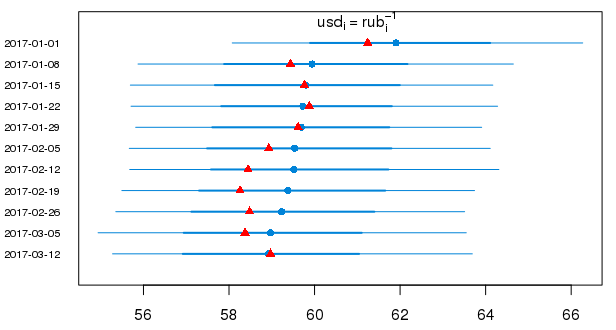
А вот 95% вероятностные интервалы в привычном виде для предсказанных значений курса доллара в 2017 г. (красными треугольниками показаны истинные значения):
Заключение
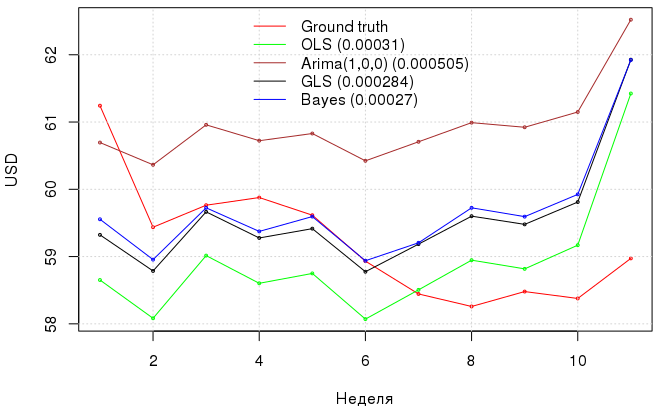
Ниже показан график с предсказаниями курса доллара моделями и их ошибки. Такими вот нехитрыми манипуляциями мы добились уменьшения MAE с 3.1e-04 у OLS до 2.7e-04 при использовании байесовского подхода с учетом авторегрессионного процесса в ошибках модели, причем GLS показал примерно такой же результат, как и байесовский подход, но с меньшими моральными затратами.
Зачем вообще было обращаться к такому выводу, если в итоге мы все равно получили модель, которая не слишком уж и превзошла OLS? Во-первых, теперь формально мы не нарушаем предпосылки к МНК; во-вторых, получили вероятностное подтверждение, что модель все же не включает полиномиальные члены; в-третьих, теперь можно получать вероятностный (а не доверительный!) интервал для интересующей нас величины. Например, если нас интересует, сколько будет стоить доллар в рублях с вероятностью в 95% при стоимости нефти 50.63USD/bbl., то можно получить вот такое распределение:
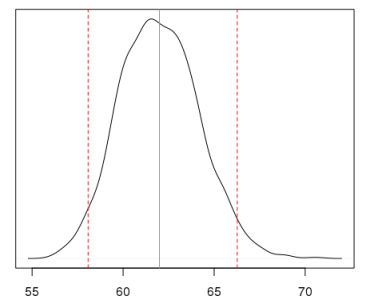
Конечно, такая регрессия с применением вероятностного вывода требует определенных усилий и некоторого опыта. С другой стороны, если надо что-то быстро посчитать, неохота возиться с распределенями, вероятностные интервалы неинтересны, а ошибки модели коррелированы, то стоит обратить внимание на незаслуженно редко используемый обобщенный метод наименьших квадратов (GLS), который позволяет получать более надежные оценки, чем при слепом использовании OLS. Кроме того, не стоит забывать об auto.arima(), которая позволяет быстро оценить корреляционный процесс в остатках модели.
Bonus
Есть еще интересная и вполне очевидная корреляция — между курсом рубля и международными резервами:
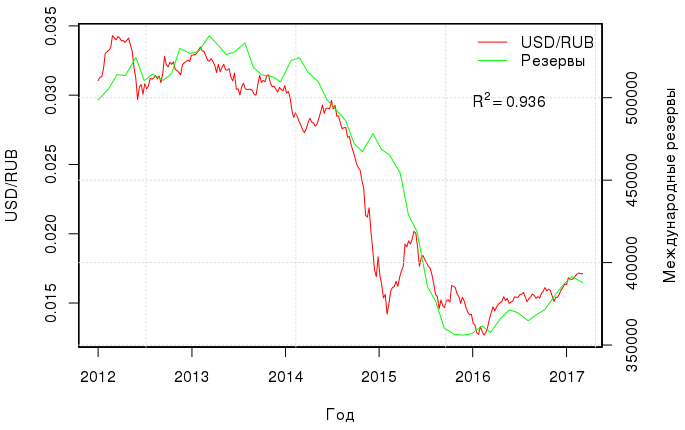
Если построить линейную регрессию между этими двумя величинами, то коэффициент детерминации будет равен аж 0.936. Модель с двумя регрессорами (нефть и резервы) имеет R2adj=0.98, и, что самое приятное, RESET-тест Рамсея подтверждает, что в этой регрессии нет пропущенных переменных, т.е. курс рубля вполне себе объясняется стоимостью нефти и международными резервами:
или, если отмасштабировать переменные:
Комментарии (21)
S_A
05.04.2017 11:18+1R крут. Сначала думал спросить как с с.д.у. в R, но глядя на R2 = 0.98, я думаю наверное бы и не стал искать добра от добра. 0.98 (страшно подумать же) видимо значит что подавляющее большинство сделок в абсолютном выражении у нас нефтяные, поскольку интервенции ЦБ — это не продуктовые сделки (и двух переменных достаточно для объяснения).
kxx
05.04.2017 11:24+1Что интересно, такой явной зависимости курса от, например, уровня инфляции или процентной ставки нет, хотя макроэкономическая наука на это намекает. Есть еще интересные графики по прямым иностранным инвестициям, но я сходу не нашел подробных открытых данных на эту тему.

atikhonov
05.04.2017 13:19Курс балансирует платежный баланс, поэтому и такая явная зависимость от курса нефти, которая вносит значительный вклад в счет текущих операций.
Инфляция и процентная ставка конечно могут как-то влиять, но однозначных зависимостей там нет априори. Прямые иностранные инвестиции, и еще много чего, есть на сайте Банка России и/или Росстата.kxx
05.04.2017 13:41На сайте ЦБ РФ таблицы по тем же инвестициям поквартальные. Если брать в разрезе последних 3-4 лет, то совсем мало данных выходит.
atikhonov
05.04.2017 14:09Да, подавляющее большинство таких данных квартальные, но платежный баланс есть и помесячный, и инвестиции можно вытащить оттуда — сальдо финансового счета.
vasya1946
05.04.2017 12:47OLS для нестационарных рядов?
kxx
05.04.2017 12:52В качестве «посмотреть на данные» такой подход имеет место быть (особенно, если не нужны доверительные интервалы). Выше я написал что предпосылки к OLS в таком случае нарушаются, но все же линейное отношение между величинами сохраняется.

Juggler
05.04.2017 15:44Посчитал по последним двум формулам. Получились странные результаты… ЧЯДН?
Данные по курсам, ценам на нефть и резервам.
Таблица расчета
kxx
05.04.2017 21:21+1В чем именно сложность? Например, для первой строчки из вашей таблицы курс доллара будет такой:
1/(-0.008712954+0.000145824*52.83+0.000000046*397334)
[1] 57.90961
Если верить cbr.ru, официальная стоимость доллара на 01.03.2017 57.96 руб.

charypopper
06.04.2017 11:46Добрый день. В ссылках на инвестинг(brent) — вы используете цену открытия:
Март '16 39,60 36,60 42,54 35,95
В ценах с cbr.ru (usd/rub) — используете цену закрытия(месяца)
31.03.2016 1 67,6076
К резервам есть пояснение — "Ежемесячные значения на начало отчетной даты" => это тоже — цена открытия.atikhonov
06.04.2017 12:20+1да и еще в итоге все подставляется в формулу для совершенного других зависимостей.
У автора:
спот нефти
курс с Англии
резервы с quandle
А здесь:
фьючерс нефти
курс ЦБ, который с суточным лагом
резервы с сайта ЦБ.
Так что какую-то общую оценку такой пример, конечно покажет, но смещенную и несостоятельную.
Модель и ее использование должно быть самосогласованное, если модель была на инструментах с ценами с quandl, то и моделировать надо на тех же принципах: спот, Англия, и внимательно смотреть на даты, начало, конец дня, месяца и прочее.
Juggler
06.04.2017 12:21Да, спасибо. Я ошибся в параметре 0.000000046. Курсы брал на конец месяца, то что в первой колонке стоит первое число — тоже ошибка.

cehkmop
05.04.2017 19:39+1Спасибо за любопытную статью. У меня, однако, есть ряд комментариев.
Я был бы осторожней с интерпретацией результатов статистических гипотез. Фраза «RESET-тест Рамсея подтверждает, что в этой регрессии нет пропущенных переменных» вообще-то неверна. «не отвергать» гипотезу и «подтверждать» это таки разные вещи… К тому же тест Рамсея не является истиной в последней инстанции. То есть, если вы гипотезу в этом тесте не смогли отклонить, это не значит, что пропущенных переменных нет.
Но, как мне кажется, более важный вопрос здесь — это с какой целью строится модель. Анализ параметров? Прогнозирование курса? Просто поиграться? Ещё что-нибудь? В зависимости от цели, будут и разные акценты на том, что использовать, чему отдавать предпочтение и чего добиваться. Так какова же цель? :)
И последнее, вы же сами говорите о том, что R2 — это достаточно формальная величина. Зачем тогда приводите его в самом конце? К тому же, сравнивать две регрессии по R2 — моветон :). Можно, сравнить по AIC или F-тест провести… На худой конец сравнить по R2-Adj.kxx
05.04.2017 21:03Насчет RESET-теста согласен. А модели на самом деле я сравнивал по AIC и loglik, просто R2 в контексте линейной регрессии понятнее, ну и почему-то его любят разные аналитики из финансовой сферы. И в статье приведен R2adj.
Сравнениеfit_1 <- gls(rub.h ~ oil.h, method="ML") fit_2 <- update(fit_1, rub.h ~ res.h + oil.h) anova(fit_1, fit_2) Model df AIC BIC logLik Test L.Ratio p-value fit_1 1 3 -542.0719 -536.1050 274.0360 fit_2 2 4 -583.3291 -575.3731 295.6645 1 vs 2 43.25711 <.0001cehkmop
05.04.2017 21:13R2 любят потому что его относительно легко интерпретировать, но это приводит к различным проблемам и ошибкам (типичная — "чем выше R2, тем лучше моя модель", без относительно того, какова цель модели). Как мне кажется, опускаться до уровня "разных аналитиков из финансовой сферы" не стоит :).
За сравнение респект!
kxx
05.04.2017 21:36R2 любят еще и потому, что он хоть что-то объясняет — в отличие от сферического AIC. Но выбирать надо по CV/AIC/BIC или хотя бы LogLik.
cehkmop
05.04.2017 22:22R2 легко интерпретировать, но именно из-за этого же его и неправильно используют.
AIC не интерпретируем, но пользу в моделировании несёт большую.
LogLik для выбора моделей использовать нельзя, из-за того, что он смещён. Все эти информационные критерии как раз нужны для того, чтобы скорректировать это смещение.
gotch
Отличная работа, спасибо, очень интересно.
kxx
Спасибо. Думаю, часть про международные резервы надо будет подробнее рассмотреть.
aamonster
Обязательно. Как минимум — обдумать/исследовать тот факт, что визуально график резервов сдвинут вправо по отношению к графику курса, т.е., очевидно, резервы определяются курсом, а не наоборот.
atikhonov
и курс лучше брать наш, или с биржи какой-то фиксинг или ЦБшный (только не забыть про суточный лаг),
а то Вы берете курс с банка Англии который непонятно как определяется (и не бьется ни с одним нашим фиксингом, ни с курсом ЦБ), и сравниваете с нефтью или нашими резервами.