От переводчика:
Я подготовил для вас адаптированный перевод с небольшими дополнениями и исправлениями. Я сохранил несколько пропагандистский стиль оригинальной статьи, но, сама по себе, информация в ней интересная, поэтому решил, все же, перевести.
Люди часто спрашивают меня:
Зачем мне вообще использовать RxJava или Reactor, если то же самое можно сделать с помощью Streams, CompletableFutures и Optionals?

Проблема, на самом деле, в том, что большую часть времени вы занимаетесь решением простых задач и вам действительно не нужны эти библиотеки. Но когда все усложняется, вам приходится писать какой-то уродский кусок кода. Затем этот кусок кода становится все более и более сложным и трудно поддерживаемым. В RxJava и Reactor есть много удобных функций, которые будут удовлетворять вашим потребностям еще долгие годы.
Давайте определим 8 критериев, которые помогут нам понять разницу между этими библиотеками и стандартными возможностями Java:
- Composable (Составные)
- Lazy (Отсроченные/Ленивые)
- Reusable (Переиспользуемые)
- Asynchronous (Асинхронные)
- Cacheable (Кэшируемые)
- Push or Pull (Получающие или Берущие)
- Backpressure (Сдерживающие поток)
- Operator fusion (Поддерживающие слияние операторов)
И давайте выберем классы, которые мы будем сравнивать:
- CompletableFuture
- Stream
- Optional
- Observable (RxJava 1)
- Observable (RxJava 2)
- Flowable (RxJava 2)
- Flux (Reactor Core)
Готовы? Собрались, погнали!
Composable
Все эти классы компонуемы и позволяют мыслить функционально (исправлена опечатка автора — прим.пер.). За это мы их и любим.
CompletableFuture — множество .then*() методов, позволяющих построить цепочку, в которой от стадии к стадии передается либо ничто, либо единственное значение + throwable.
Stream — куча сцепляемых операторов, позволяющих преобразовывать входные данные. Может передавать N значений от стадии к стадии.
Optional — пара промежуточных операторов: .map(), .flatMap(), .filter().
Observable, Flowable, Flux — аналогично Stream.
Lazy
CompletableFuture — не ленивый, так как просто хранит асинхронный результат. Такие объекты создаются для представления работы, которая уже началась. (исправлено согласование по числам — прим.пер.) Им ничего не известно о работе, зато известен результат. Таким образом, нет способа перейти вверх по потоку и запустить выполнение цепочки сверху вниз. Очередной этап запускается, когда в CompletableFuture установится значение.
(вывод верный, а вот рассуждения спорны. По сути, CompletableFuture не ленивый, т.к. поиск и установка его значения начинаются еще до того, как мы обращаемся к нему за результатом — прим.пер.)
Stream — все промежуточные операции ленивы. Все завершающие операции запускают вычислительный процесс.
Optional — не ленивый, все операции происходят немедленно.
Observable, Flowable, Flux — ничего не происходит до тех пор, пока не будет подписчика (Subscriber).
Reusable
CompletableFuture — может быть переиспользуемым, так как это просто обертка над значением. Но использовать нужно осторожно, так как это обертка изменяема. Если вы уверены, что у него никто не вызовет .obtrude*(), то это безопасно.
Stream — не переиспользуемый. Как указано в JavaDoc:
Операции над потоком (промежуточные или завершающие) следует выполнять лишь один раз. Реализация потока может выбросить IllegalStateException, если она обнаружит, что поток переиспользуется. Однако, поскольку некоторые операции потока могут вернуть их получателя, а не новый объект класса Stream, то не во всех случаях возможно обнаружить переиспользование.
Optional — полностью переиспользуемый, потому что он неизменяемый и вся работа происходит сразу же.
Observable, Flowable, Flux — спроектированы переиспользуемыми. Все этапы начинают выполняться с начальной точки и только когда есть подписчик.
Asynchronous
CompletableFuture — ну, вся суть этого класса — асинхронно связывать операции. CompletableFuture олицетворяет собой работу, связанную с каким-то Executor-ом. Если явно не указать Executor-а при создании задачи, используется обычный ForkJoinPool. Этот пул может быть получен с помощью ForkJoinPool.commonPool(), и по умолчанию он создает столько потоков, сколько в вашей системе аппаратных потоков (как правило, количество ядер, и вдвое больше, если ядра поддерживают HyperThreading). Однако, вы можете установить количество потоков в этом пуле JVM-параметром
-Djava.util.concurrent.ForkJoinPool.common.parallelism=?
или использовать новый Executor каждый раз при создании этапа работы.
Stream — нет возможности асинхронной обработки, но может осуществлять вычисления параллельно, создавая распараллеливаемый поток — stream.parallel().
Optional — Неа, это просто контейнер.
Observable, Flowable, Flux — хотя и нацелены на построение асинхронных систем, но синхронные по умолчанию. Методы subscribeOn и observeOn позволяют контролировать регистрацию подписки и получение уведомлений (т.е. какой поток будет вызывать onNext / OnError / OnCompleted у наблюдателя).
С помощью subscribeOn вы решаете, на каком Scheduler-е буть выполняться Observable.create. Даже если вы не вызываете create сами, тому есть внутренний эквивалент. Пример:
Observable
.fromCallable(() -> {
log.info("Reading on thread: " + currentThread().getName());
return readFile("input.txt");
})
.map(text -> {
log.info("Map on thread: " + currentThread().getName());
return text.length();
})
.subscribeOn(Schedulers.io()) // <-- setting scheduler
.subscribe(value -> {
log.info("Result on thread: " + currentThread().getName());
});На выходе:
Reading file on thread: RxIoScheduler-2
Map on thread: RxIoScheduler-2
Result on thread: RxIoScheduler-2С другой стороны, observeOn() управляет тем, какой Scheduler используется для вызова последующих этапов, идущих после observeOn(). Пример:
Observable
.fromCallable(() -> {
log.info("Reading on thread: " + currentThread().getName());
return readFile("input.txt");
})
.observeOn(Schedulers.computation()) // <-- setting scheduler
.map(text -> {
log.info("Map on thread: " + currentThread().getName());
return text.length();
})
.subscribeOn(Schedulers.io()) // <-- setting scheduler
.subscribe(value -> {
log.info("Result on thread: " + currentThread().getName());
});На выходе:
Reading file on thread: RxIoScheduler-2
Map on thread: RxComputationScheduler-1
Result on thread: RxComputationScheduler-1Cacheable
В чем разница между переиспользуемым и кэшируемым? Допустим, у нас есть цепочка A, и мы дважды переиспользуем ее, чтобы создать цепочки B = A + O и C = A + O.
Если B & C завершаются успешно, то класс переиспользуемый.
Если B & C завершаются успешно и каждый этап цепочки A вызывается только один раз, то класс кэшируемый. Чтобы быть кэшируемым, класс должен быть переиспользуемым.
CompletableFuture — такой же ответ, как и для переиспользуемости.
Stream — нет возможности кэширования промежуточного результата до тех пор, пока не будет вызван завершающий оператор.
Optional — «кэшируемый», потому что вся работа происходит сразу же.
Observable, Flowable, Flux — не кэшируются по умолчанию. Но вы можете сделать A кэшируемым, вызвав у него .cache().
Observable<Integer> work = Observable.fromCallable(() -> {
System.out.println("Doing some work");
return 10;
});
work.subscribe(System.out::println);
work.map(i -> i * 2).subscribe(System.out::println);На выходе:
Doing some work
10
Doing some work
20С .cache():
Observable<Integer> work = Observable.fromCallable(() -> {
System.out.println("Doing some work");
return 10;
}).cache(); // <- apply caching
work.subscribe(System.out::println);
work.map(i -> i * 2).subscribe(System.out::println);На выходе:
Doing some work
10
20Push or Pull
Stream & Optional работают по принципу Pull. Результат берется из цепочки путем вызова различных методов (.get(), .collect() и т.д.). Pull часто ассоциируется с блокирующим, синхронным исполнением, и это справедливо. Вы вызываете метод и поток начинает ждать, когда придут данные. До тех пор поток блокируется.
CompletableFuture, Observable, Flowable, Flux работают по принципу Push. На цепочку подписываются, а затем уведомляются, когда нужно что-то обрабатать. Push часто ассоциируется с неблокирующим асинхронным исполнением. Можно делать что угодно, в то время как цепочка выполняется в каком-нибудь потоке. Вы уже описали код для выполнения, поэтому уведомление будет инициировать выполнение этого кода на следующем этапе.
Backpressure
Для того, чтобы уметь сдерживать поток, цепочка должна быть построена по принципу Push.
Сдерживание потока — это ситуация в цепочке, когда некоторые асинхронные этапы не могут обработать значения достаточно быстро и им нужен способ обратиться вверх по цепочке, с просьбой быть помедленнее. Неприемлима ситуация, когда на какой-то стадии произойдет отказ, потому что данных слишком много (сохранена двусмысленность формулировки автора — прим.пер.).
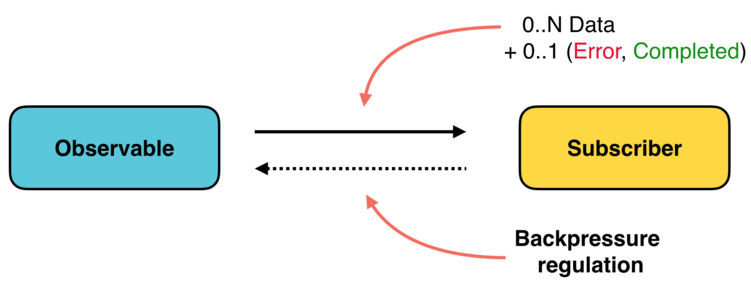
- Stream & Optional не поддерживают этот механизм, так как они построены по принципу Pull.
- CompletableFuture не нужно решать эту проблему, так как он выдает 0 или 1 в качестве результата.
Observable (RxJava 1), Flowable, Flux — решают эту проблему. Основными стратегиями являются:
- Буферизация — сохранение всех значений
onNextв буфер до тех пор, пока они не потребуются ниже по цепочке. - Отбрасывание новых — последнее значение
onNextотбрасывается в случае, если следующий элемент цепи не справляется. - Хранение последнего — предоставление только последнего значения
onNext, с перезаписью любого предыдущего значения, если следующий элемент цепи не справляется. - Без сдерживания —
onNextсобытия записываются без буферизации или отбрасывания. - Исключение — выбрасывается исключение, если следующий элемент цепи не справляется.
Observable (RxJava 2) — не решает эту проблему. Многие пользователи RxJava 1 использовали Observable для событий, которые неразумно сдерживать, или не использовали никаких стратегий, что вызывало появление неожиданных исключений. Поэтому в RxJava 2 есть четкое разделение между сдерживаемыми (Flowable) и несдерживаемыми (Observable) классами.
Operator Fusion
Идея заключается в том, чтобы изменять цепочку в различные моменты всего жизненного цикла, чтобы уменьшить сложность, созданную архитектурой библиотеки. Все эти оптимизации сделаны внутри, так что для конечного пользователя все остается понятным.
Лишь RxJava 2 & Reactor поддерживают слияние операторов, но несколько по-другому. В общем, есть 2 вида оптимизаций:
- Macro-fusion — замена 2+ идущих друг за другом операторов на один оператор.

- Micro-fusion — операторы, у которых в конце выходная очередь, и операторы, начинающие работу с передней очереди, могут использовать один и тот же экземпляр очереди. В качестве примера, вместо вызова request(1) и последующей обработки onNext()...

… подписчик может запрашивать значение у родительского Observable:

Более подробную информацию можно найти здесь: Часть 1 & Часть 2
Заключение
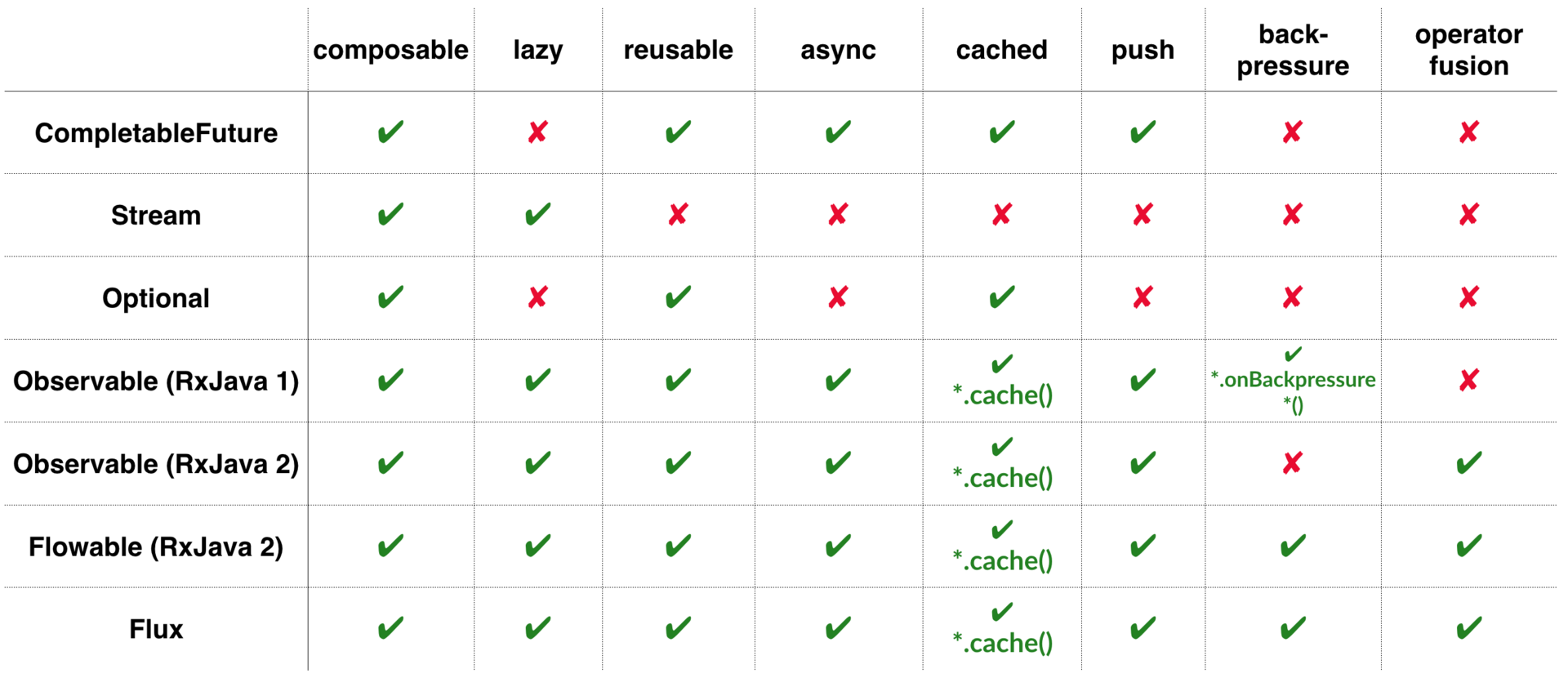
Stream, CompletableFuture и Optional были созданы для решения определенных задач. И они действительно хороши в решении этих задач. Если их хватает, чтобы удовлетворить ваши потребности, то вперед.
Однако разные проблемы имеют разную сложность и некоторые из них требуют новых подходов. RxJava & Reactor являются универсальными инструментами, которые помогут вам решать ваши задачи в декларативном стиле, вместо того, чтобы создавать «хаки» с помощью инструментов, которые не были предназначены для решения таких задач.

lany
Неочевидно, кому нужен operator fusion. Stream API разрабатывали ребята из JDK и параллельно шли допилы виртуальной машины с тем, чтобы дополнительный какой-то явный fusion был не нужен. Крайне редко вы напоретесь на ситуацию, когда два подряд идущих map или filter будут медленнее, чем один.
Ну и сравнение, понятно, производится по пунктам, интересным авторам сравнения. К примеру, RxJava 1 боксит просто нереально много и тормозит из-за этого. RxJava 2 уже умнее, но всё равно прямой поддержки небоксированных типов нету. Где колонка с примитивной специализацией? Не хотелось ставить крестик в строчке с RxJava? Пользы в плане быстродействия от неё существенно больше, чем от operator fusion.
Artem_zin
Это спорный момент, часто гоняете примитивы по стримам по сравнению с ссылочными типами? Operator fusion улучшает большУю часть кейсов использования, а примитивная специализация — частные случаи.
Ну и самое важное — добавление примитивной специализации в RxJava это сотни часов работы, контрибьютить туда всегда было сложно, куча вариантов, которые придется поддерживать только усложнят это, учитывая насколько оно все композируемо.
lany
Ну так я говорю не в смысле "бегом побежали добавлять", а в смысле что сравнивать надо беспристрастнее. Если добавление примитивов в RxJava — сотни часов работы, значит, не надо в табличку галочку про примитивы ставлять?
Параллелизм опять же. Позволяет ли RxJava разбивать источник на части и обрабатывать их независимо? Насколько я понимаю, у них только producer-consumer модель. Производительность может быть существенно разной. В общем, картина неполная и выглядит ангажировано.
Artem_zin
С такой постановкой вопроса я согласен :) Но с "Пользы в плане быстродействия от неё существенно больше, чем от operator fusion." не очень.
Это всегда можно было сделать руками через кастомный оператор или композицию существующих операторов, но было не очень тривиально и композиция могла снизить производительность.
В 2.0.5 добавлен ParallelFlowable, который позволяет делать часть операций (map/filter/etc) параллельно.
Вот тут не согласен, статья одна из самых точных по всем перечисленным технологиям, обычно на подобные тексты без слез не взглянешь.