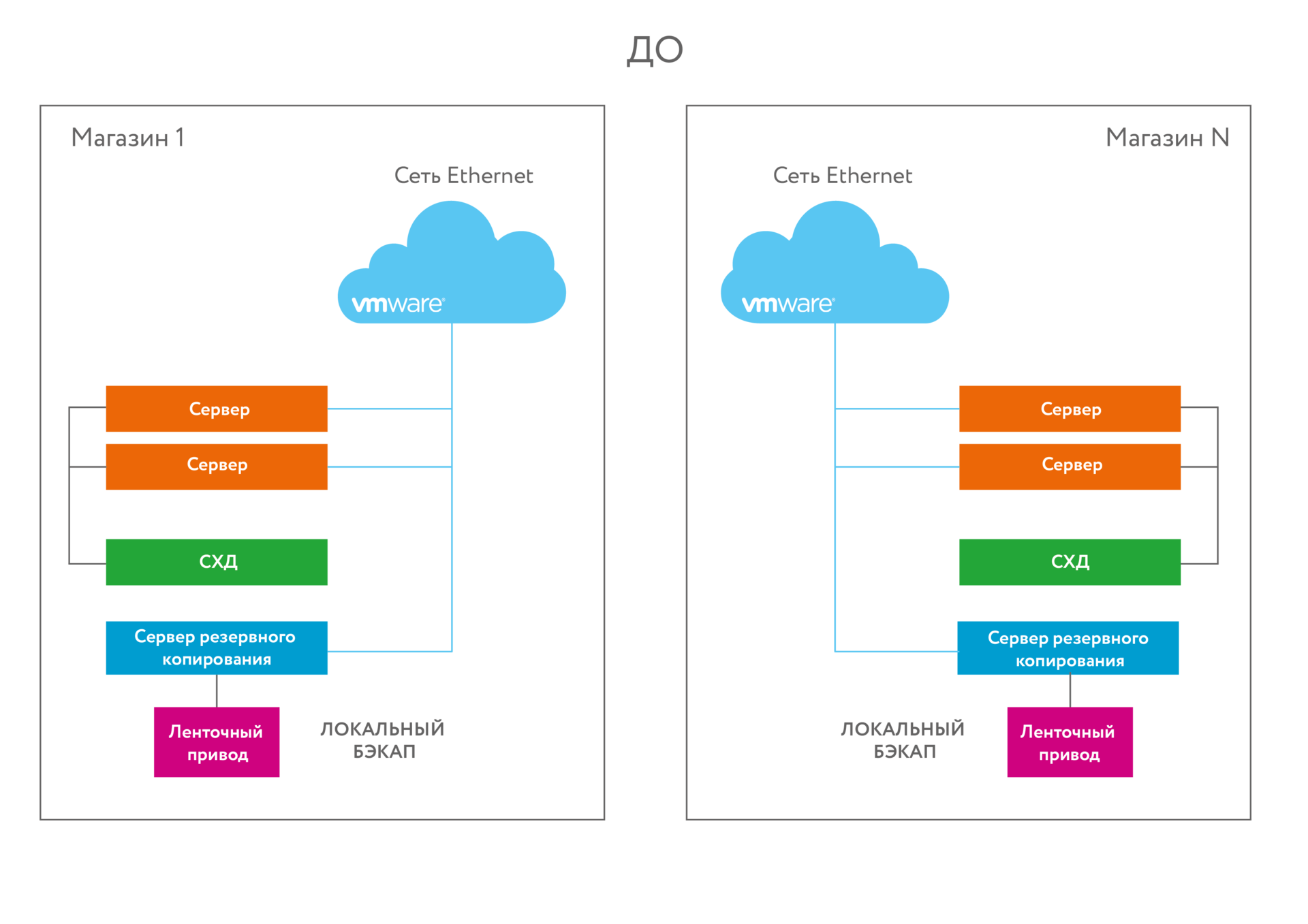
Старая инфраструктура
Есть 8 больших магазинов площадью больше 10 тысяч квадратов каждый. При каждом магазине — офис с юзерами и документооборотом. На каждой точке есть серверный узел — торговые приложения, файл-сервер, домен-контроллер, прочие сервисы. Канал связи — очень тонкий, он определён забугорным корпоративным стандартом. Его хватает ровно для административных действий и синхронизации базы с наработанным за день за целую ночь. Ни о какой синхронной или асинхронной репликации базы с дата-центром речи не идёт — только режим ночной отправки диффа. Бекап на стример. На стене висела инструкция, по которой сотрудники магазинов раз в сутки меняли картриджи.
В таких условиях мы внедряли Симпливити — один из первых проектов по внедрению решений такого класса в России. Запрос пришёл не в виде «подскажите решения», а в виде конкретной задачи «Есть столько мощности, нужен такой объём». Дальше получался либо набор из пяти дорогих железок, либо из двух дорогих, но на малознакомой шаманской Симпливити. Выбрали второе. Получилась единая инфраструктура с единым пространством и таким медленным обменом между площадками. Очень странная штука.
Сейчас расскажу, что шайтан-система делает. Забегая чуть вперёд — там и модная гиперконвергентность и главная фишка — глобальная дедупликация.

В каждом магазине работают 4–5 виртуальных машин. Часть из них относится к инфраструктуре: домен-контроллер, файловый сервер. Часть — специфичные приложения для торговли: управление весами, печать ценников и плакатов, сервисы аналитики. Все эти задачи уместились на маленькую систему из двух узлов SimpliVity OmniCube CN-1400.
Как видите, в данном проекте SimpliVity OmniCube — это кластеры из двух нод. На кластер ставится ВМваре, в каждом сервере — внутренние диски. Пространство дисков выдаётся на виртуальную машину. Полезное пространство объединяется в единую систему хранения — и отдаются обратно на сервера. SDS как ScaleIO или RAIDIX, только функционал рассчитан немного на другое. Основное — не надо иметь отдельную систему хранения данных, только диски серверов.
Узлы соединены между собой по сети 10 GbE напрямую, поэтому не нужны дорогие 10-гигабитные коммутаторы в магазинах. ПО виртуализации — VMware vSphere. Получился типовой комплект инфраструктуры для нового магазина «в коробке». При открытии нового магазина не нужно заново ломать голову насчёт серверного оборудования, достаточно взять пару кубиков SimpliVity. Кластеры SimpliVity в разных магазинах видят друг друга и управляются централизованно. Резервные копии ВМ делаются раз в день и хранятся две недели. Одна резервная копия хранится локально, чтобы быстро поднять данные при их случайном удалении или логическом повреждении. Вторая хранится на SimpliVity в соседнем магазине. Хранилище второго кластера не зависит от первого.
Это довольно дорого из расчёта на одно внедрение (можно сделать аналогично дешевле на других решениях), но если считать вместе со временем работы админа, охлаждением, энергией, стоимостью поддержки и её продления в будущем, и учесть, что всё это добро заменяет весь традиционный стек/инфраструктуру, то получается очень даже прилично и красиво. Дело в том, что тут «всё в одном», очень простой набор компонентов. Нужно всего поладмина со знаниями ВМвары. Решение легко масштабируется на любое количество узлов. Главное, чтобы не было мегажирной базы данных, для такого у совсем больших пацанов есть all-flash массивы. Главный кейс — филиалы и фермы терминалов пользователей. В процессе тестирования также открылось, что очень приятно эта штука работает с плохими каналами — благодаря встроенной оптимизации каналов связи и встроенной дедупликации на лету.
В итоге магазины открываются по несколько штук в год в дополнение к тем восьми, что уже есть. Это по размерам типа Метро. Офисы в них на 30 активных пользователей. Выбрали они типовое решение по ИТ-инфраструктуре для локальных приложений. Планировалось открытие новых магазинов, а в существующих нужно было менять устаревшее железо. Так как ИТ-специалисты занимаются не только инфраструктурой, решение должно быть максимально простым и управляться централизованно. В идеале заказчик искал одну готовую коробку, которую можно растиражировать по магазинам и вообще забыть о том, что в них есть ИТ-инфраструктура.
Второе требование — хранить резервные копии данных магазина на удалённой площадке. Передавать бекапы по каналу связи не имело смысла, так как получалось долго. Данные же должны храниться на разных геоточках, и админы это прекрасно понимали.
Тестирование
Вот отчёт с наших тестов решения (прошлогодний отчёт перед внедрением). Пациентом был двухнодовый SimpliVity CN-3400.
Каждая нода представляет собой двухюнитовый rack-сервер Dell R720 с фирменной лицевой панелью SimpliVity и особой PCIe карточкой внутри — OmniStack accelerator card (OAC). В каждом сервере установлено 2 проца E5-2680v3, 24 планки 16GB DDR3 и 24 диска (4 SSD 400GB, 20 HDD 1TB 7,2k SAS).

На передней части под лицевой панелью установлены 24 диска — 4 SSD и 20 2,5-дюймовых SAS-дисков. С обратной стороны два разъёма питания, пять сетевых портов, сервисный порт карты OAC и два системных HDD 300GB 10K SAS.

SimpliVity CN-3400, вид сзади


Omnistack Acccelerator Card с двух сторон
В типовом случае, каждый сервер подключается двумя 10 Гбит соединениями к сети данных, двумя 1 Гбит к сети управления и один интерфейс требуется для консоли управления сервером IPMI (iDRAC). Это лишь один из вариантов подключения. Можно не подключать в гигабитную сеть, а использовать 10GbE как для кластерной сети, так и для трафика ВМ. Также можно добавить сетевые карты и выделить несколько дополнительных портов. В случае двухнодовой конфигурации в организации 10-гигабитной сети вообще нет необходимости — достаточно подключить ноды напрямую друг к другу двумя DAC-кабелями.
После каблирования питания, сети и настройки IP-адреса на IPMI-консоли можно приступать к первичной настройке системы и интеграции решения в vCenter.
В нашем случае vCenter был установлен на выделенный Windows Server. vCenter Server Appliance так же поддерживается.
Нам удалось протестировать несколько способов инициализации системы. Это связанно с тем, что предоставленный комплект мы тестировали первыми в России (напомню, тест был в прошлом году). И на нём была установлена версия системы поколения 2.x. В случае данной версии процедура была следующей. Установленный vCenter требует дополнительной подготовки: необходимо добавить нового пользователя svtuser и сконфигурировать виртуальные коммутаторы. Все настройки описаны в брошюре, приложенной к системе.
После выполнения рекомендаций по подготовке существующей инфраструктуры, следует задать IP-адреса системы, произвести подключение нод к vCenter, создать федерацию SimpliVity и инициализировать VMware cluster. Всё выполняется при помощи простого мастера, идущего в комплекте вместе с системой на обычной флешке. Во время настройки будет установлен арбитр, предназначенный для выбора главной ноды в случае сплитбрейна. Его можно установить, как на хост vCenter, так и на отдельный сервер.
После обновления системы до актуальной версии (3.5.x), мы попробовали выполнить инициализацию системы заново. В последних версиях установка делается с помощью Deployment Manager, ему нужен только доступ к vCenter, всё остальное он делает сам.
На этом предварительная настройка заканчивается и во вкладке vCenter — SimpliVity federation можно создавать необходимые датасторы, расписания резервного копирования и использовать остальной функционал.
В целом настройка системы довольно простая и при верном соблюдении приложенной инструкции трудностей не вызывает. Если нет необходимости обновлять поставленную систему (заранее подготовлены IP-адреса и настроен vCenter), то разворачивание системы, включая монтаж в стойку, коммутацию и первичную настройку, займёт около 30 минут.
В разделе SimpliVity Federation в vCenter можно мониторить производительность, физическую/логическую ёмкость, коэффициенты дедупликации и компрессии, управлять политиками резервного копирования.
По интерфейсу бекап похож на снепшоты, но на техническом уровне мы имеем единое дедуплицированное пространство, и при создании резервной копии у нас происходит форк виртуальной машины. Существуют модули интеграции резервных копий с SQL и Exchange.
Коэффициент дедупликации, на наш взгляд, система подсчитывает не совсем информативно для первичной копии. Для остальных уже более-менее адекватно.
После создания снепшота из него можно восстановить как целую ВМ, так и отдельный файл (с гранулярностью до файлов восстанавливаются только виртуальные машины с ОС Windows). При восстановлении виртуальной машины можно выбрать «заменить существующую виртуальную машину» или «создать новую». При этом, любую резервную копию можно вручную восстановить в любом удалённом ЦОД.
Все базовые функции отрабатывают корректно и без ошибок. SimpliVity незаметно и плотно интегрируется в клиент vSphere, и найти ту или иную функцию не составляет труда.
Производительность
Для замера производительности использовался VMware IO Analyzer 1.6.4 с параметрами виртуальной машины: VM version: 7, vCPU: 1. Memory: 2 ГБ, VD: 16 ГБ; OS: SUSE Linux Enterprise 11. В среднем получили результат 7 560 IOPS при нагрузке (8K, 50/50w/r, NoRandom), 20 352 IOPS для AllRandom. Это всё мимо кеша.
Все наши любимые краш-тесты с выдиранием дисков на ходу, прерыванием интерконнектов и отключением нод система тоже успешно пережила и при возвращении компонентов корректно восстанавливала своё состояние. Влияние на производительность системы при всех наших издевательствах была минимальна, не считая отключение интерконнекта. Он помог ускорить систему в 2 раза! (Но лишившись синхронной репликации между нодами).
Вывод: железка интересная, так как даёт возможность заменить практически все элементы традиционной архитектуры ЦОД набором rack-серверов и коммутаторов. Система хорошо справляется с распределёнными нагрузками, но плохо подходит для консолидированных. Никаких однопоточных приложений или больших баз.
Результат в магазине
Внедрение заняло 2 дня, по дню на площадку. Проработка решения и тестирование заняли полгода. Большую часть времени делали поставку оборудования и обкатывали тесты. Заказчик рассматривал различные продукты, которые обещают «инфраструктуру в коробке»: гиперконвергентные системы и модульную платформу. Остановились на SimpliVity, потому что не нужен отдельный софт для бекапа, все машины видно из единого центра — там вообще всё управление, а не россыпь консолей, очень хорошее отношение к отстойному каналу из-за продвинутой дедупликации. Например, при ежедневном полном бекапе ВМ с 220 ГБ использованной ёмкости по каналу связи пролетает 570 МБ. А полный бекап всей инфраструктуры завершается за 2-3 часа. Для админов это звучало как фантастика, но это работает по факту теперь.
ИТ-отдел небольшой, выделенных специалистов по виртуализации или по резервному копированию, как в больших компаниях, нет. Поэтому сотрудникам приходится заниматься всем: от работы с накладными до сопровождения касс. На изучение всех тенденций и нюансов СХД, SAN, серверов, софта бекапа ресурсов нет. В итоге заказчик стандартизовал инфраструктуру и упростил себе жизнь. Вместо закупки, настройки и поддержки серверов, СХД и бекапа в каждом магазине, он ставит туда уже готовый «кубик», который просто умеет запускать, эффективно хранить и бекапить виртуалки. Одной задачей в ИТ стало меньше. В этом и есть смысл гиперконвергенции.
Итог: в магазин ставится два сервера, за 5 минут настраивается бекап. Всё.
P.S. Спасибо «Марвел Дистрибуция» за предоставленное оборудование для тестов. Они же поставляли боевые системы для заказчика.
Комментарии (10)

The_Alex
28.04.2017 16:08+2Михаил, по Вашим данным за прошедшее время в России много внедрений таких решений для удаленных офисов? Из прочитанного могу сделать вывод, что это весьма дорогое решение для филиала в 30 пользователей и 4-5 ВМ, причем эти ВМ должны быть не требовательны к вводу-выводу. Вырисовывается портрет заказчика — хипстера, для которого фиансовый вопрос стоит на последнем месте).

MikeKostsov
28.04.2017 22:01+1Заказчики которые выбирают гиперконвергенцию для филиалов обычно руководствуются задачей упрощения администрирования на месте и возможностью резервного копирования между филиалами (в случае Simplivity). Им нравится что все из одной консоли, причем эта консоль может быть в центральном офисе. На месте не требуется высококвалифицированный сотрудник и решение закрывает сразу несколько задач. Такую задачу можно закрыть по другому и дешевле, но придется пойти на компромисс. Можно привести в пример поездку на работу. Есть несколько вариантов: Общественный транспорт, своя машина или велосипед. Все варианты решают задачу за разные деньги и с разной скоростью. Нельзя сказать что какой-то вариант не правильный. Гиперконвергенция это один из способов решения. Для некоторых это закрытие всех задач сразу, а кто-то наймет выделенного человека, купит писюк с бесплатным гипервизором и будет бекапить скриптами. Все зависит от уровня развития компании.

mickvav
28.04.2017 23:11А на proxmox+drbd вы такое не собирали? А то идейно вроде бы получается примерно та же схема, и интерфейс управления в вебмордочке и бэкапчики и т.п.
MikeKostsov
02.05.2017 16:33Пока руки не дошли. Хотя у нас даже было пару запросов за прошлый год на proxmox. Но собирали нечто похожее на Red Hat OpenStack Platform + Ceph. Нельзя назвать такой набор полноценной гиперконвергенцией. Но OpenStack платформа дает большие возможности для творчества. И можно прикрутить кучу других сервисов при желании.
alexq2
02.05.2017 16:28Здравствуйте!
Если не ошибаюсь, когда HPE купили SimpliVity они говорили, что хотят выпилить Omnistack Acccelerator Card и перенести все в софт. Кластер можно создать из двух нод? На картинке в статье медь 10Г? Зачем нужна интеграция с vcenter? Что будет если один диск SDD\HDD умрет? Если будет потеряна одна нода? Долго ли ребилд будет в этих случаях? Из маркетинга понятно, что все будет хорошо. А с технической точки зрения, какие механизмы включатся? Зачем нужна интеграция с vcenter? Какие версии vcenter поддерживаются. Сколько нужно отдать вычислительных мощностей для SimpliVity? У ребят в филиале по две ноды, сколько нод в ЦО? Будет ли деградация производительности при большом количестве снапшотов? К примеру в сумме 15 ВМ общим объёмом 1,5 Тб. Нужно будет держать бэкап глубиной в 30 дней, бэкап проходит раз в сутки в ночное время. Компрессия и дедуп на лету проходят или отложенный механизм? Поддерживается ли реплика многие к одному? Интегрируется это решение со сторонними средствами бэкапов и планируется ли?MikeKostsov
02.05.2017 17:00Если не ошибаюсь, когда HPE купили SimpliVity они говорили, что хотят выпилить Omnistack Acccelerator Card и перенести все в софт. Кластер можно создать из двух нод? -Да. Фактически, можно из одной, если использовать конфигурацию 2+1, где две на основной площадки бэкапятся на одну на второй. На картинке в статье медь 10Г? — 10Gb между нодами в одном кластере. Между площадками плохой канал провайдера. Зачем нужна интеграция с vcenter? — для единой консоли управления всей инфраструктурой. Чтобы не плодить консоли. Что будет если один диск SDD\HDD умрет? — HDD восстановится, у нас ссд в рейде, отказ обрабатывается как для диска на уровне контроллера. Если будет потеряна одна нода? — все останется работать на второй. Долго ли ребилд будет в этих случаях? — зависит от используемого объёма. По сути пока не за синхронизируются все данные. Из маркетинга понятно, что все будет хорошо. А с технической точки зрения, какие механизмы включатся? — обычного восстановления RAID или синхронизации нод. Зачем нужна интеграция с vcenter? Какие версии vcenter поддерживаются. — 5.5, 6.0, 6.5. Сколько нужно отдать вычислительных мощностей для SimpliVity? — от 50 ГБ оперативной памяти и больше, зависит от конфигурации. У ребят в филиале по две ноды, сколько нод в ЦО? — тоже две. Будет ли деградация производительности при большом количестве снапшотов? — нет. К примеру в сумме 15 ВМ общим объёмом 1,5 Тб. Нужно будет держать бэкап глубиной в 30 дней, бэкап проходит раз в сутки в ночное время. — можно. Компрессия и дедуп на лету проходят или отложенный механизм? — на лету. Поддерживается ли реплика многие к одному? — да. Интегрируется это решение со сторонними средствами бэкапов и планируется ли? — интегрируется с любым, кто может бэкапить с VMware.
Shaz
Мне кажется или это обработанные напильником серверы Dell? И к примеру чем оно будет лучше по сравнению с Dell VRTX?
MikeKostsov
Серверы могут быть любые. В данном случае делл, сейчас hpe. Фишка не в серверах, а в софте, который на них работает. В этом и идея гиперконвергенции. Симпливити умеет общее хранилище с дедупликацией и компрессией из локальных дисков, быстрый бэкап между сайтами, DR, централизованное управление. На обычных серверах с локальными дисками. А vrtx — это классические железки
The_Alex
К фишкам софта стоит добавить и аппаратные чудо-карты).
А не сравнивали, случайно, стоимость этих кубиков с классическим решением (стоечные сервера, СХД)? Было бы интересно посмотреть итоговую разницу в % стоимости. Ведь до этого ж заказчик на чем-то работал…
MikeKostsov
Если сравнивать со стоимостью Сервера+СХД+Сеть хранения+бекап то выходит выгоднее. К примеру в случае с Simplivity дедупликация позволяет понизить требования к дисковой подсистеме в плане производительности. Понадобится меньше шпинделей для получения целевых показателей. Но иногда выходит дороже. Тогда мы предлагаем заказчику классическое решение с выделенной СХД стартового уровня или SDS. По опыту можно сказать что разброс цен ± 30%. Были случаи когда гиперконвергенция была чуть дороже но заказчик все равно ее выбирал так как ему нравилась простота. Чаще всего во всех проектах у нас нет ультимативности, мы предлагаем заказчикам несколько вариантов на выбор и описываем плюсы и минусы.