Друзья, сегодня мы предлагаем вашему вниманию перевод третьей части цикла статей одного из докладчиков PG Day'17 Russia Gulcin Yildirim об отказоустойчивости PostgreSQL.
PostgreSQL — это потрясающий проект, который развивается с удивительной скоростью. В этой серии статей мы сфокусируемся на эволюции возможностей отказоустойчивости в PostgreSQL на протяжении всех его версий. Это третья статья серии, и в ней мы поговорим о проблемах timelines и их влиянии на отказоустойчивость и надежность PostgreSQL.

Если вы хотите проследить эволюцию Постгреса с самого начала, прочитайте первые две статьи этой серии:
Timelines
Способность откатывать базу данных до какого-либо из предыдущих состояний создает определенные сложности. Некоторые из них мы изучим, разобрав ситуации failover (Рис. 1), switchover (Рис. 2) и pg_rewind (Рис. 3).
Например, допустим, что в первоначальной истории базы данных вы удалили критическую таблицу в 17:15 во вторник вечером, но осознали свою ошибку только в полдень среды. Не моргнув глазом, вы достаёте резервную копию и откатываетесь до состояния на 17:14 вечера вторника, и всё снова работает. В истории этой вселенной базы данных вы никогда не удаляли таблицу. Но предположим, что позднее вы поняли, что идея была не такая уж хорошая, и хотели бы вернуться к состоянию на утро среды из первоначальной истории. У вас ничего не выйдет, если, после того как база данных снова заработала, она переписала некоторые сегменты WAL, которые вели к тому моменту во времени, в который вы хотели бы вернуться.
Таким образом, чтобы избежать этого, вам необходимо отделить серию записей WAL, сгенерированных после того, как вы совершили восстановление на определенный момент времени, от тех, которые были сделаны в первоначальной истории базы данных.
Для решения этой проблемы в PostgreSQL существует понятие timeline. Всякий раз, когда восстановление архива завершается, создаётся новая timeline для идентификации серии записей WAL, сгенерированных после этого восстановления. Идентификационный номер timeline является частью имён файлов сегментов WAL, так что новая timeline не переписывает данные WAL, сгенерированные предыдущей timeline. То есть можно заархивировать много разных timelines.
Рассмотрим ситуацию, когда вы не уверены, на какой момент времени нужно восстановиться, и вам приходится делать несколько восстановлений, чтобы методом проб и ошибок найти наилучшее место для ответвления от старой истории. Без timelines этот процесс вскоре породил бы неуправляемый беспорядок. А с ними вы можете восстановиться до любого предыдущего состояния, включая состояния в ветках timelines, которые вы забросили ранее.
Каждый раз, когда создаётся новая timeline, PostgreSQL создаёт файл «истории timeline», в котором показано, от какой timeline она ответвилась и когда. Эти файлы-истории необходимы для того, чтобы дать системе возможность выбрать правильные файлы сегментов WAL при восстановлении из архива, содержащего несколько timelines. То есть они хранятся в архиве WAL так же, как и файлы сегментов WAL. Файлы-истории — это просто небольшие текстовые файлы, так что их дёшево и целесообразно хранить неопределенно долго (в отличие от больших файлов сегментов). Если хотите, вы можете добавить комментарии к файлу-истории, чтобы записать свои собственные заметки о том, как и почему эта конкретная timeline была создана. Такие комментарии особенно ценны, когда в результате экспериментов у вас образуется клубок различных timelines.
По умолчанию восстановление происходит по той же timeline, которая была актуальной на момент создания базовой резервной копии. Если вы желаете восстановиться в какую-то дочернюю timeline (то есть вы хотите вернуться к состоянию, которое было сгенерировано после попытки восстановления), вам нужно указать timeline ID в recovery.conf. Вы не можете восстанавливаться в timelines, которые ответвились раньше, чем была создана базовая резервная копия.
Для упрощения концепции timelines в PostgreSQL связанные с ними вопросы в случаях failover, switchover и pg_rewind обобщены и объяснены на рисунках 1, 2 и 3.
Сценарий failover:
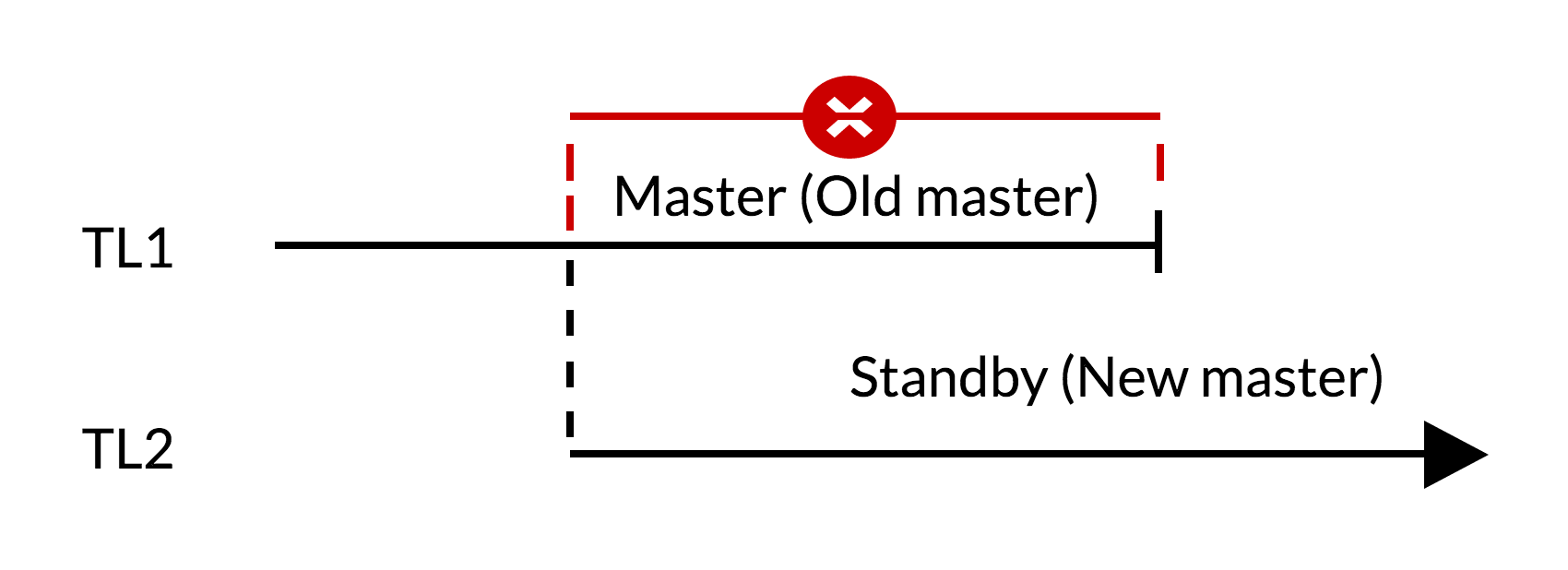
Сценарий switchover:
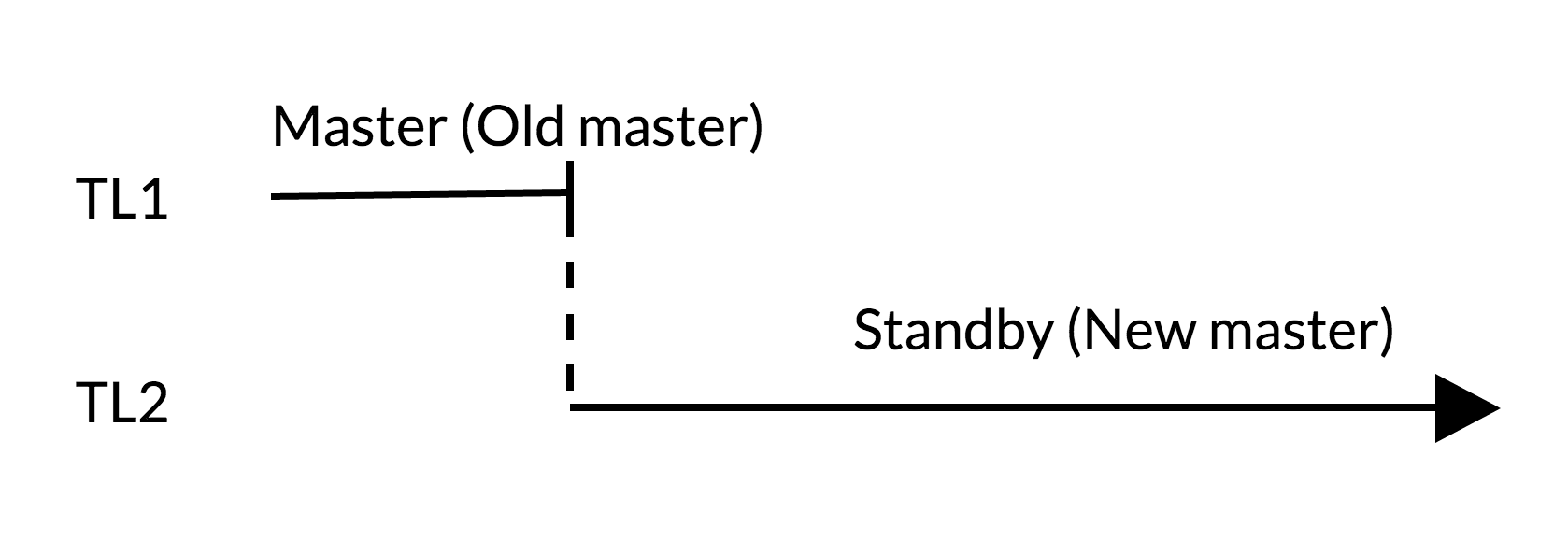
Сценарий pg_rewind:
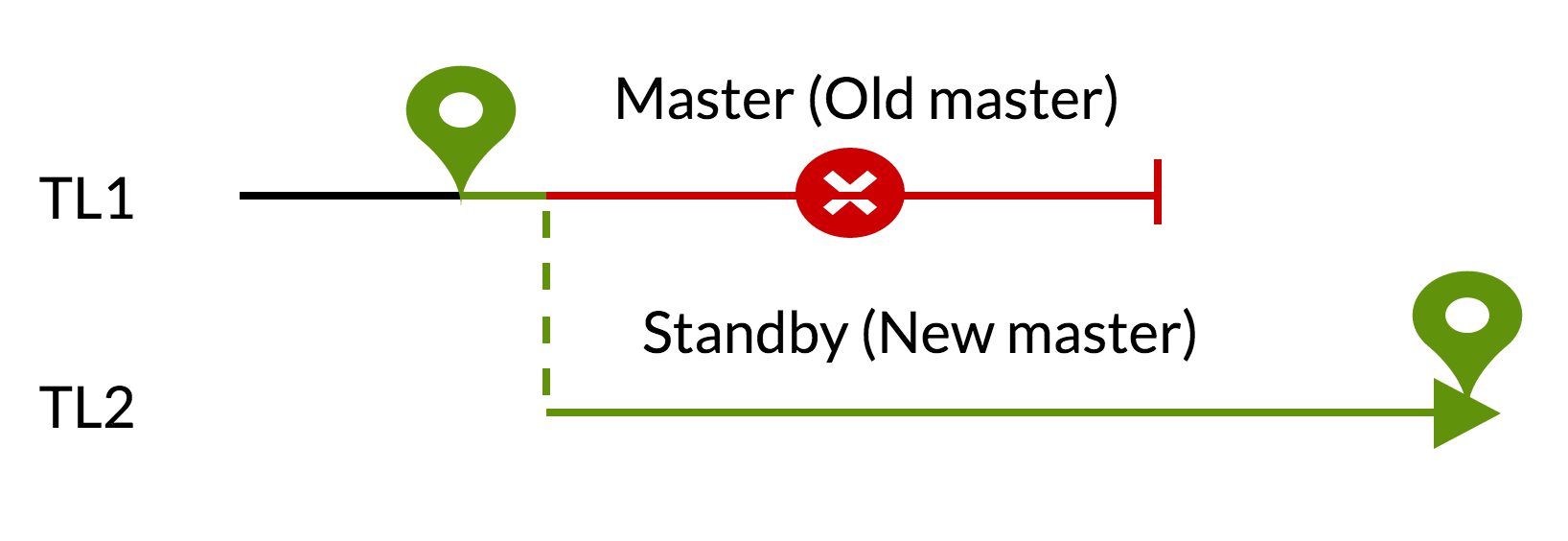
pg_rewind
pg_rewind — это инструмент для синхронизации кластера PostgreSQL с другой копией того же кластера после того, как timelines кластеров разошлись. Типичный сценарий: после аварийного переключения старый основной сервер снова поднимается в качестве standby к новому основному.
Результат эквивалентен замене целевого каталога данных исходным. Все файлы копируются, включая конфигурационные. Преимуществом pg_rewind по сравнению со снятием новой базовой резервной копии или такими инструментами, как rsync, является то, что pg_rewind не требует чтения всех неизменённых файлов в кластере. Поэтому этот способ гораздо быстрее, особенно в тех случаях, когда база данных большая, а отличаются между кластерами лишь небольшие ее части.
Как это работает?
Основная идея в том, чтобы скопировать из нового кластера в старый всё, кроме блоков, о которых известно, что они не менялись.
Примечание: параметр wal_log_hints должен быть настроен в postgresql.conf, чтобы pg_rewind мог работать. Этот параметр может быть настроен только при запуске сервера. Значение по умолчанию — off.
Заключение
В этой статье мы обсудили timelines в Постгресе и то, как мы обрабатываем ситуации failover и switchover. Также мы поговорили о том, как работает pg_rewind и его вкладе в отказоустойчивость и надежность Постгреса. В следующей статье мы продолжим тему обсуждением синхронных коммитов.

Gulcin приедет на PG Day'17 и лично ответит на вопросы участников, а также расскажет более подробно об автоматизации апгрейдов Постгреса в облаке. Как решить проблему апгрейда до мажорных версий, используя функциональность логического декодирования, доступную в версиях 9.4+? Ответ лежит в использовании pglogical. И, в качестве бонуса, автоматизация предлагаемого решения с помощью Ansible. Регистрируйтесь и готовьте свои вопросы!
PostgreSQL — это потрясающий проект, который развивается с удивительной скоростью. В этой серии статей мы сфокусируемся на эволюции возможностей отказоустойчивости в PostgreSQL на протяжении всех его версий. Это третья статья серии, и в ней мы поговорим о проблемах timelines и их влиянии на отказоустойчивость и надежность PostgreSQL.
Если вы хотите проследить эволюцию Постгреса с самого начала, прочитайте первые две статьи этой серии:
Timelines
Способность откатывать базу данных до какого-либо из предыдущих состояний создает определенные сложности. Некоторые из них мы изучим, разобрав ситуации failover (Рис. 1), switchover (Рис. 2) и pg_rewind (Рис. 3).
Например, допустим, что в первоначальной истории базы данных вы удалили критическую таблицу в 17:15 во вторник вечером, но осознали свою ошибку только в полдень среды. Не моргнув глазом, вы достаёте резервную копию и откатываетесь до состояния на 17:14 вечера вторника, и всё снова работает. В истории этой вселенной базы данных вы никогда не удаляли таблицу. Но предположим, что позднее вы поняли, что идея была не такая уж хорошая, и хотели бы вернуться к состоянию на утро среды из первоначальной истории. У вас ничего не выйдет, если, после того как база данных снова заработала, она переписала некоторые сегменты WAL, которые вели к тому моменту во времени, в который вы хотели бы вернуться.
Таким образом, чтобы избежать этого, вам необходимо отделить серию записей WAL, сгенерированных после того, как вы совершили восстановление на определенный момент времени, от тех, которые были сделаны в первоначальной истории базы данных.
Для решения этой проблемы в PostgreSQL существует понятие timeline. Всякий раз, когда восстановление архива завершается, создаётся новая timeline для идентификации серии записей WAL, сгенерированных после этого восстановления. Идентификационный номер timeline является частью имён файлов сегментов WAL, так что новая timeline не переписывает данные WAL, сгенерированные предыдущей timeline. То есть можно заархивировать много разных timelines.
Рассмотрим ситуацию, когда вы не уверены, на какой момент времени нужно восстановиться, и вам приходится делать несколько восстановлений, чтобы методом проб и ошибок найти наилучшее место для ответвления от старой истории. Без timelines этот процесс вскоре породил бы неуправляемый беспорядок. А с ними вы можете восстановиться до любого предыдущего состояния, включая состояния в ветках timelines, которые вы забросили ранее.
Каждый раз, когда создаётся новая timeline, PostgreSQL создаёт файл «истории timeline», в котором показано, от какой timeline она ответвилась и когда. Эти файлы-истории необходимы для того, чтобы дать системе возможность выбрать правильные файлы сегментов WAL при восстановлении из архива, содержащего несколько timelines. То есть они хранятся в архиве WAL так же, как и файлы сегментов WAL. Файлы-истории — это просто небольшие текстовые файлы, так что их дёшево и целесообразно хранить неопределенно долго (в отличие от больших файлов сегментов). Если хотите, вы можете добавить комментарии к файлу-истории, чтобы записать свои собственные заметки о том, как и почему эта конкретная timeline была создана. Такие комментарии особенно ценны, когда в результате экспериментов у вас образуется клубок различных timelines.
По умолчанию восстановление происходит по той же timeline, которая была актуальной на момент создания базовой резервной копии. Если вы желаете восстановиться в какую-то дочернюю timeline (то есть вы хотите вернуться к состоянию, которое было сгенерировано после попытки восстановления), вам нужно указать timeline ID в recovery.conf. Вы не можете восстанавливаться в timelines, которые ответвились раньше, чем была создана базовая резервная копия.
Для упрощения концепции timelines в PostgreSQL связанные с ними вопросы в случаях failover, switchover и pg_rewind обобщены и объяснены на рисунках 1, 2 и 3.
Сценарий failover:
- на старом master есть непримененные на standby изменения (TL1);
- рост timelin отражает новую историю изменений (TL2);
- изменения из старой timeline не могут быть воспроизведены на серверах, переключившихся на новую timeline;
- старый master не может стать репликой нового.
Сценарий switchover:
- в старом master нет неприменённых на standby изменений (TL1);
- рост timeline отражает новую историю изменений (TL2);
- старый master может стать standby для нового.
Сценарий pg_rewind:
- незафиксированные изменения будут удалены с помощью данных из нового master (TL1);
- старый master может стать standby для нового (TL2).
pg_rewind
pg_rewind — это инструмент для синхронизации кластера PostgreSQL с другой копией того же кластера после того, как timelines кластеров разошлись. Типичный сценарий: после аварийного переключения старый основной сервер снова поднимается в качестве standby к новому основному.
Результат эквивалентен замене целевого каталога данных исходным. Все файлы копируются, включая конфигурационные. Преимуществом pg_rewind по сравнению со снятием новой базовой резервной копии или такими инструментами, как rsync, является то, что pg_rewind не требует чтения всех неизменённых файлов в кластере. Поэтому этот способ гораздо быстрее, особенно в тех случаях, когда база данных большая, а отличаются между кластерами лишь небольшие ее части.
Как это работает?
Основная идея в том, чтобы скопировать из нового кластера в старый всё, кроме блоков, о которых известно, что они не менялись.
- Сканируется список WAL старого кластера, начиная с последнего checkpoint перед моментом, когда история timeline нового кластера ответвилась от старого. Для каждой записи WAL делается пометка о том, какие блоки данных были затронуты. Это создает список всех блоков данных, которые были изменены в старом кластере после того, как новый кластер ответвился.
- Все эти измененные блоки копируются из нового кластера в старый.
- Копируются все остальные файлы, такие как clog и конфигурационные файлы, из нового кластера в старый. Всё, кроме файлов relation.
- Применяются WAL от нового кластера, начиная с checkpoint, созданной в момент аварийного переключения. (Строго говоря, pg_rewind не применяет WAL, а просто создает файл-ярлык резервной копии, указывающий, что при запуске PostgreSQL начнет воспроизводиться с этой точки отсчета и применит все требуемые WAL.)
Примечание: параметр wal_log_hints должен быть настроен в postgresql.conf, чтобы pg_rewind мог работать. Этот параметр может быть настроен только при запуске сервера. Значение по умолчанию — off.
Заключение
В этой статье мы обсудили timelines в Постгресе и то, как мы обрабатываем ситуации failover и switchover. Также мы поговорили о том, как работает pg_rewind и его вкладе в отказоустойчивость и надежность Постгреса. В следующей статье мы продолжим тему обсуждением синхронных коммитов.
Gulcin приедет на PG Day'17 и лично ответит на вопросы участников, а также расскажет более подробно об автоматизации апгрейдов Постгреса в облаке. Как решить проблему апгрейда до мажорных версий, используя функциональность логического декодирования, доступную в версиях 9.4+? Ответ лежит в использовании pglogical. И, в качестве бонуса, автоматизация предлагаемого решения с помощью Ansible. Регистрируйтесь и готовьте свои вопросы!
Поделиться с друзьями