
Разумеется, при таких объемах дисков ни о какой классической таблице разделов не может идти и речи. Для безопасного проведения работ нам необходимо оценить состояние каждого из накопителей, чтобы выбрать оптимальные методики создания посекторных копий. Для этого анализируем показания SMART, также проверяем состояние БМГ посредством чтения небольших участков каждой из головок в зонах разной плотности. В нашем случае все накопители оказались исправными.
Для оптимизации времени выполнения работ создадим копии по 100 000 000 секторов от начала диска. Эти 50-гигабайтные образы нам потребуются для проведения анализа в то время, как будут создаваться посекторные копии накопителей (создание полных копий – обязательная страховка, хотя порой кажется не таким важным мероприятием, которое только задерживает процедуру восстановления данных).
Необходимо понять, каким образом NAS работает с дисками, и какие средства логической разметки используются. Для этого посмотрим в LBA 0 и 1 каждого из дисков.
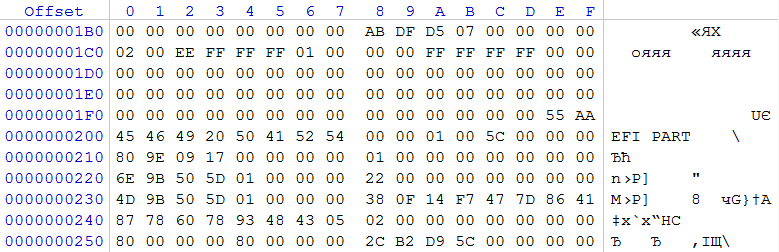
рис. 2
На двух накопителях по 3ТБ по смещению 0x01C2 записан тип раздела 0xEE, берущий начало с LBA 0x00000001 и размер его 0xFFFFFFFF секторов. Данная запись является типичной защитной записью для накопителей, где используется GPT. Полагая, что использовалась GPT, оценим содержимое сектора 1, который в образе берет начало с 0x200. Регулярное выражение 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (в текстовом виде: EFI PART) информирует нас о том, что перед нами заголовок GPT.
В секторе 2 обнаруживаем записи о разделах GPT

рис. 3
В первой записи описан раздел с 0x0000000000000022 сектора по 0x0000000000040021 сектор, который имеет GUID, не соответствующий стандарту. В нем содержится восклицание от разработчика, который в слегка сжатом виде вещает “Hah! I don’t Need EFI“. Метка тома “BIOS boot partition“.
Во второй записи описан раздел с 0x0000000000040022 сектора по 0x0000000000140021, идентификатор этого раздела A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
В третьей записи описана раздел с 0x0000000000140022сектора по 0x000000015D509B4D сектор, которые также имеет GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
Исходя из размеров разделов, можно пренебречь первым и вторым, так как очевидно, что данные разделы созданы для нужд NAS. Третий раздел – это то, что нас на данные момент интересует. Согласно идентификатора имеет признак участника RAID массива, созданного средствами Linux. Исходя из этого, нам необходимо найти суперблок конфигурации RAID. Ожидаемое место его расположения через 8 секторов от начала раздела.
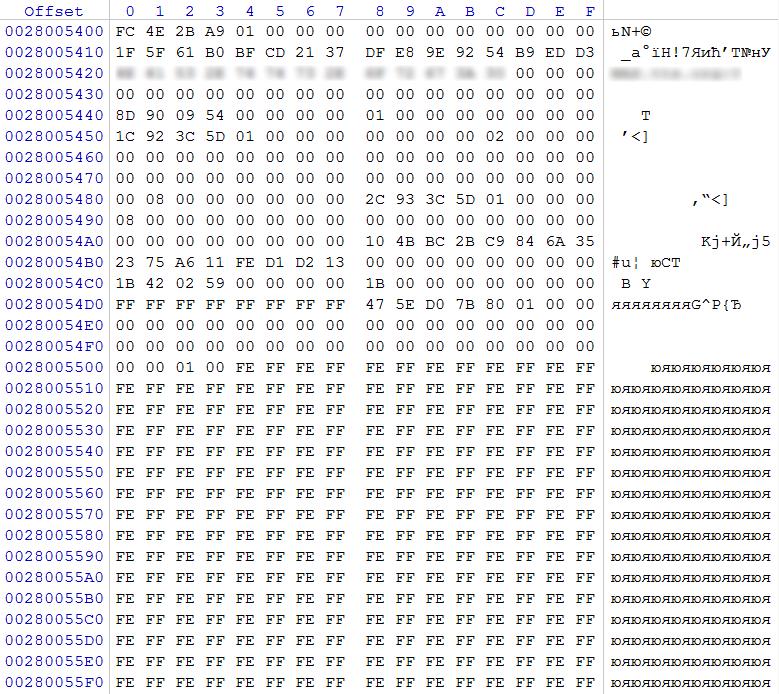
рис. 4
В нашем случае по смещению 0x0 обнаружено регулярное выражение 0xFC 0x4E 0x2B 0xA9, которое является маркером суперблока конфигурации RAID. По смещению 0x48 видим значение 0x00000001, что говорит о том, что в данном блоке описан массив RAID 1 (зеркало), значение 0x00000002 по смещению 0x5C сообщает нам, что в составе данного массива 2 участника. По смещению 0x80 сообщается, что область данных массива начнется через 0x00000800 (2048) секторов (отсчет ведется от начала раздела с суперблоком). По смещению 0x88 в QWORD прописано количество секторов 0x000000015D3C932C (5 859 218 220), которое на данном разделе принимает участие в RAID массиве.
Перейдя к области начала данных находим признак LVM
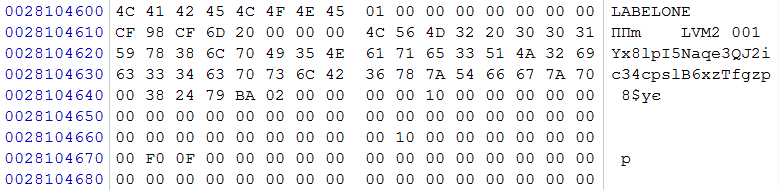
рис. 5
переходим к последней версии конфигурации.
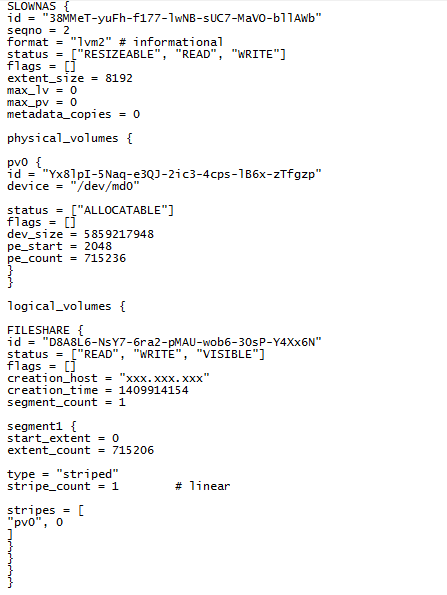
рис. 6
В конфигурации видим, что на данном массиве один том, состоящий из одного сегмента, с именем «FILESHARE», который занимает практически всю емкость массива (количество экстентов*размер экстента=емкость в секторах 715 206*8 192=5 858 967 552. Проверив раздел, описанный в этом томе, обнаруживаем файловую систему Ext4, записи в которой явно свидетельствуют о соответствии имени раздела содержимому.
Анализируя содержимое второго накопителя емкостью 3ТБ, обнаруживаем наличие идентичных структур и полное соответствие в области данных для RAID 1, что подтверждает, что этот диск также был в составе данного массива. Зная, что файлообменник с именем FILESHARE был доступен пользователям, исключаем эти два диска из дальнейшего рассмотрения.
Переходим к анализу накопителей емкостью 4ТБ. Для этого рассмотрим содержимое нулевого сектора каждого из накопителей на предмет наличия защитной таблицы разделов.

рис. 7
Но вместо этого обнаруживаем некое мусорное содержимое, которое не может претендовать на звание таблицы разделов. Аналогичная картина с 1 по 33 секторы. Признаки таблицы разделов (защитной MBR) и GPT отсутствуют на всех дисках. При анализе RAID 1, описанном выше, мы получили информацию, какие области этот NAS отводит для служебных целей, на основании этого мы предполагаем, с какого смещения может начинаться раздел с областью, участвующей в другом массиве с пользовательскими данными.
Выполним поиск суперблоков конфигурации RAID (по регулярному выражению 0xFC 0x4E 0x2B 0xA9) на данных накопителях в окрестностях смещения 0x28000000. На каждом из дисков находится суперблок по смещению 0x28101000 (адрес несколько отличается от того, что на первой паре дисков, вероятно из-за того, что в данном случае было учтено, что данные 4ТБ диски с физическим сектором 4096 байт с эмуляцией 512 байтного сектора).
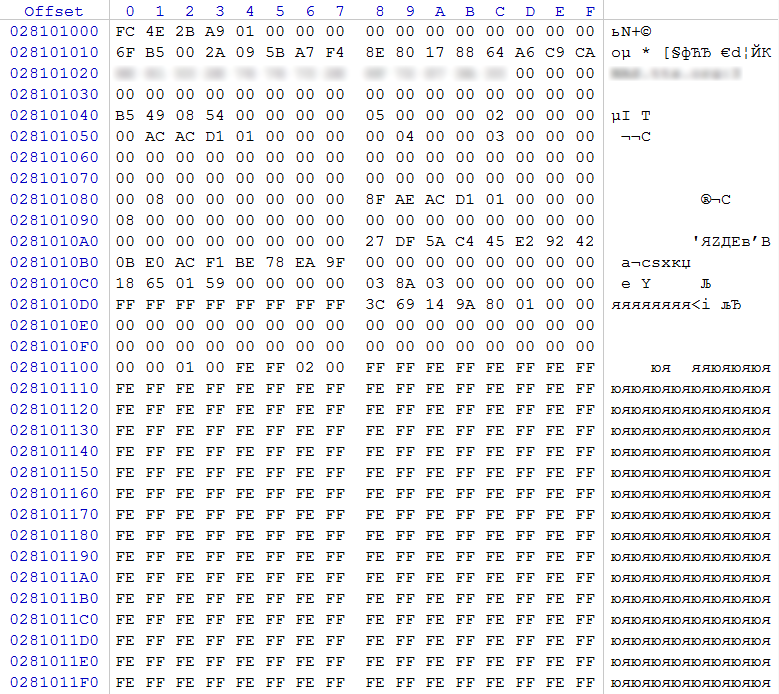
рис. 8
По смещению 0x48 значение 0x00000005 (RAID5)
По смещению 0x58 значение 0x00000400 (1024) – размер блока чередования 1024 сектора (512КБ)
По смещению 0x5C значение 0x00000003 – количество участников в массиве. Учитывая, что дисков с одинаковыми суперблоками 4, а, согласно записи, участвует 3 диска, можно сделать вывод, что одному из дисков отведена роль диска горячей замены (hot spare). Также уточняем, что данный массив был RAID 5E.
По смещению 0x80 значение 0x0000000000000800 (2048) – количество секторов от начала раздела до области, принимающей участие в массиве.
По смещению 0x88 значение 0x00000001D1ACAE8F (7 812 722 319) секторов – размер области, принимающей участие в массиве.
Если накопитель, задействованный в качестве диска горячей замены, не вступил в работу, и не была произведена операция rebuild, то его содержимое будет сильно отличаться от содержимого остальных трех дисков. В нашем случае при пролистывании дисков в hex редакторе легко обнаруживается практически пустой накопитель. Его также исключаем их рассмотрения.
Полагая, что суперблок конфигурации RAID находился по стандартному смещению от начала раздела, можем получить адрес начала раздела 0x28101000-0x1000=0x208100000. Соответственно, область начала данных с учетом содержимого по смещению:
0x208100000+(0x0000000000000800*0x200)=0x208200000.
Перейдя по данному смещению, видим, что на протяжении 1024 (0x800) секторов на каждом из дисков не обнаруживается ничего похожего на LVM либо какой-то иной вариант логической разметки. При выполнении теста корректности данных со смещения 0x208200000 посредством XOR операции над содержимым трех накопителей стабильно получаем 0, что свидетельствует о целостности RAID 5 и подтверждает, что ни один накопитель не был исключен из массива (и не была проведена операция Rebuild). Исходя из содержимого массива RAID 1 предположим, что и в массиве RAID 5 область 0x100000 в начале, которая на данный момент заполнена мусорными данными, предназначалась для размещения LVM.
Учитывая, что данный RAID является чередующимся массивом с блоком четности, то отступив на 0x100000 от начала массива, нам необходимо на каждом диске переместиться на позицию 0x208280000, предположительно с этого адреса начнется область данных в LVM. Проверим это предположение посредством анализа данных по этому смещению. Если это не том, используемый для свопа, то должны быть признаки либо какой-то логической разметки внутри раздела, описанного в LVM, либо признаки какой-либо файловой системы.
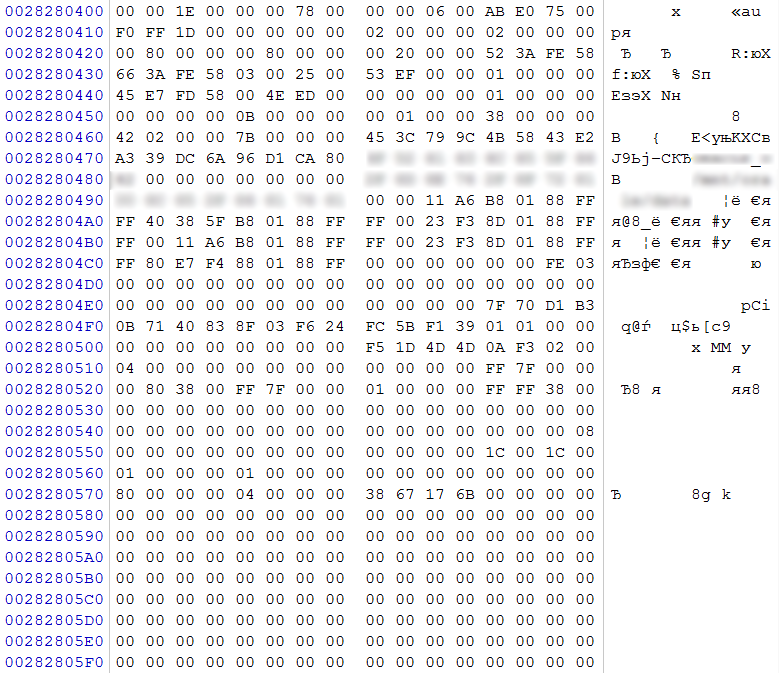
рис. 9
По характерному смещению 0x0400 на одном из дисков (согласно нумерации клиента – №2) обнаруживаем суперблок Ext4. В нем по смещению 0x04 DWORD – количество блоков в данной файловой системе, по смещению 0x18 в неявном виде указывается размер блока (для вычисления размера блока необходимо возвести 2 в степень (10+Х), где Х – значение по смещению 0x18). На основании этих значений выполним расчет размера раздела, с которым оперирует данная файловая система 0x00780000*0x1000=0x780000000 байт (30ГБ). Видим, что размер раздела существенно меньше емкости массива. Полагаем, что это лишь один из разделов, который был описан в LVM, и, исходя из смещения относительно начала массива, можем полагать, что он начинался с нулевого экстента.
Хоть и первичные предположения о расположении данных оказались верны, но для сборки массива мы не будем использовать информацию из суперблока конфигурации RAID, а проведем анализ данных внутри раздела и на основании этого установим параметры массива. Данный метод позволит нам подтвердить корректность параметров в суперблоке конфигурации RAID применительно к этому массиву или опровергнуть и установить правильные.
Для определения размера блока и параметров чередования блока четности удобно использовать монотонно возрастающие последовательности. На разделах Ext2, Ext 3, Ext 4 их можно найти в Group Descriptors (не во всех случаях). Возьмем удобную область для каждого из дисков:

рис. 10 (HDD 2)

рис. 11 (HDD 1)

рис. 12 (HDD 0)
Листая в hex редакторе c шагом 0x1000 каждый из дисков, заметим, что возрастание чисел по внутрисекторным смещениям 0x00, 0x04, 0x08 и т.д. идет на протяжении 1024 секторов или 0x80000 байт (справедливо только для блоков с данными, но не для блоков с результатами XOR операции), что достаточно явно подтверждает размер блока, описанный в суперблоке конфигурации RAID.
Глядя на рис. 10, рис. 11, рис. 12, легко определим роли дисков на данном месте и порядок их использования. Для построения полной матрицы будем пролистывать образы всех дисков с шагом 0x80000 и вписывать значения со смещений 0x00 в таблицу. Для заполнения таблицы использования дисков впишем названия дисков согласно возрастанию значений, вписанных нами в первую таблицу.
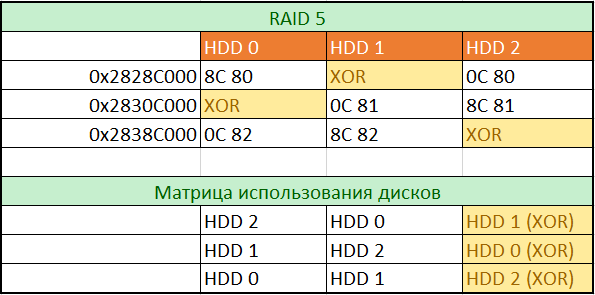
рис. 13
Согласно матрице использования дисков, проведем сбор массива RAID 5 с 0x28280000 в рамках первых 30 ГБ. Этот адрес был выбран, исходя из отсутствия LVM и того, что начало обнаруженного нами EXT4 раздела приходится на это смещение. В полученном образе мы сможем полностью проверить файловую систему и соответствие типов файлов, описанных в ней, фактически размещенным данным. В нашем случае эта проверка не выявила каких-либо недостатков, что подтверждает корректность всех предыдущих выводов. Теперь можно приступить к полному сбору массива.
Из-за отсутствия LVM нам предстоит процедура поиска разделов в собранном массиве. Для разделов, состоящих из одного сегмента, эта процедура не будет ничем отличаться от поиска разделов на обычном накопителе с очищенной таблицей разделов (MBR) или GPT. Все сведется к поиску признаков начала разделов различных файловых систем и таблиц разделов.
В случае же томов, которые принадлежали утерянной LVM, и состоящих из 2 и более фрагментов, потребуется дополнительный комплекс мероприятий:
– построение карты логических томов, состоящих из одного сегмента посредством записи диапазона секторов, занимаемых томом на разделе;
– построение карты разделов первых сегментов фрагментированных томов. Предстоит точно определить место обрыва раздела. Эта процедура намного проще, если известен точный размер экстента, используемого в утерянной LVM. Порядок размера экстента можно предположить, исходя из местоположения начала томов. К сожалению, данная методика не всегда применима.
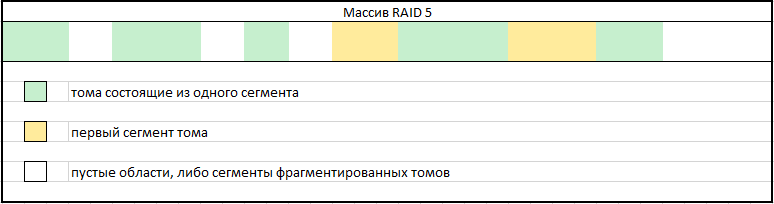
Рис. 14
В пустых участках карты предстоит поиск сегментов, которые необходимо приращивать к первому сегменту какого-либо из фрагментированных томов. Следует обратить внимание, что таких фрагментов томов может быть достаточно много. Проверять корректность приращений можно посредством анализа файловых записей в файловой системе тома с сопоставлением фактическим данным.
Выполнив весь комплекс мероприятий, получим все образы логических томов, находившихся в RAID массиве.
Также обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить некоторые этапы работ.
> Предыдущая публикация: Восстановление файлов после трояна-шифровальщика
Комментарии (49)

Miss_Nika
06.05.2017 17:22Спасибо огромное за данную статью! Вы ответили на вопрос, который я задавала в комментарии к прошлой Вашей статье!

hddmasters
06.05.2017 17:24+1Пожалуйста. Буду рад, если вы найдете в ней для себя что-то, что поможет вам решить проблему.
Обращаю внимание, всех читателей, что в комментариях вы можете оставлять свои пожелания, на предмет тем будущих статей. По мере возможностей будут рассматриваться интересующие вас случаи восстановления данных.

Skyroger2
06.05.2017 19:29+1Спасибо за статью
А можете рассказать по шагам как у вас происходит взаимодействие с заказчиком? Можно взять для примера мою недавнюю ситуацию — сгорел RAID-контроллер и остались пять дисков, которые жили на этом контроллере, объединённые в RAID-5. Встал вопрос, что можно спасти. Все организации, которые я нашел, предлагали одно и то же — присылайте диски с курьером, мы посмотрим, что можно сделать, и объявим цену. На этом этапе настораживало уже то, что в RAID-5 важен порядок дисков, а им никто не интересовался. Да и название контроллера не помешало бы узнать, а об этом тоже никто не спрашивал. Допустим, всё удалось восстановить. Что дальше? Вы пересобираете RAID и отдаёте информацию обратно на тех же дисках (если они исправны)?hddmasters
06.05.2017 19:48+4Взаимодействие с клиентом происходит следующим образом:
Предоставляются накопители для анализа. Порядок дисков необязателен, так как все равно посредством аналитических мероприятий предстоит его установить как и все параметры массива. Но при выборе компании будьте осторожны, не попадите в руки универсальных сервисов, которые кроме автопилота в программах автоматического восстановления больше ничего не знают.
После анализа озвучивается стоимость работ. Если клиента все устроит, тогда переходим к выполнению.
Нами создаются посекторные копии дисков клиентов. Сбор массива ведется на отдельный накопитель (или массив). После этого из собранного массива можно скопировать данные пользователя. Записать данные можно на любой накопитель достаточной емкости предоставленный со стороны заказчика. Оригинальные накопители мы оставляем без изменений. Если конечно клиент желает, чтобы на них информация была записана как на разрозненные диски, то можно поступить и таким образом. (страховочные посекторные копии некоторое время хранятся у нас. Срок хрения обсуждается с заказчиком).
akrupa
07.05.2017 00:13-1сгорел RAID-контроллер
В статье описан «сложный случай». Сложность обусловлена тем, что таблица LVM была утеряна. Проблему со сгоревшим контроллером можно попробовать сначала решить при помощи программ умеющих автоматически реконструировать RAID. Таких программ очень много, и шансы, что они сработают в данном случае, — высоки. Если нет — всегда можно обратиться к специалистам.
П.С. Обязательно сделайте образы дисков.hddmasters
07.05.2017 18:27Проблему со сгоревшим контроллером можно попробовать сначала решить при помощи программ умеющих автоматически реконструировать RAID. Таких программ очень много, и шансы, что они сработают в данном случае, — высоки.
Могут сработать, при условиях:
1. Массив начинался с LBA 0, либо вы точно зададите смещения с которого начинать сбор (многие контроллеры в начале диска могут размещать свои метаданные).
2. RAID контроллер не создавал буферных зон в середине LBA диапазона каждого из дисков.
3. На дисках был организован один массив.
Со всяким автоматическим ПО остро встанет вопрос определения диска с неактуальными данными, который необходимо исключить при сборе и недостающие данные компенсировать за счет избыточных.
Как показывает практика в RAID 5, 5E, 5EE, 6, 50, 60 и прочих чуть сложнее страйпа (RAID 0) с автоматическим ПО получить качественный результат несколько проблематично.
П.С. Обязательно сделайте образы дисков.
Также свою лепту вносит неумение многими пользователями и системными администраторами адекватно оценивать состояние жестких дисков, которые при попытках создания посекторной копии (посредством линейного чтения) усугубляют его состояние вплоть до невозможности извлечения данных.
Современные накопители с проблемами, как правило, требуют вмешательства в работу микропрограммы (например отключение оффлайн сканирования, отключение SMART, запрет процедур автореаллокации). Также требуется локализация крупных дефектообразование по каждой поверхности с последующей вычиткой стабильных зон и лишь в последнюю очередь читать проблемные зоны, так как при их вычитке высоки риски деградации как поверхностей так и БМГ.
akrupa
08.05.2017 00:461. Массив начинался с LBA 0, либо вы точно зададите смещения с которого начинать сбор (многие контроллеры в начале диска могут размещать свои метаданные).
Это не проблема. Программы умеют искать смещения «регулярками». Но, это работает только если искомая область не повреждена. Если повреждена, — это как раз «сложный случай»
2. RAID контроллер не создавал буферных зон в середине LBA диапазона каждого из дисков.
Это, и, включенный кэш на запись — показания сразу нести диски к специалистам. Но, скорее всего, контроллер используемый «в домашних условиях» этого делать не будет. Если условия не «домашние», то лучше сразу к специалистам идти.
3. На дисках был организован один массив.
Даже если массивов несколько — это может сработать. Программы часто умеют читать стандартные способы разбивки MatrixRaid/MD/LVM и т.п., как и большинство комбинаций. Но, метаданные должны быть на месте.
Со всяким автоматическим ПО остро встанет вопрос определения диска с неактуальными данными, который необходимо исключить при сборе и недостающие данные компенсировать за счет избыточных.
Это верно. Но, при сгоревшем контроллере скорее всего сильного расхождения не будет. А если случай немного другой, даже тогда, иногда, можно решить автоматически. В худшем случае, можно по-очереди исключать при сборке разных участников и проверять содержимое. AKA метод грубой силы. Острым становится вопрос если ни в одной комбинации у не получается восстановить данные. Такое тоже бывает, но реже.
Также свою лепту вносит неумение многими пользователями и системными администраторами адекватно оценивать состояние жестких дисков, которые при попытках создания посекторной копии (посредством линейного чтения) усугубляют его состояние вплоть до невозможности извлечения данных.
В случае сгоревшего контроллера, — скорее всего диски живы. Есть много статей о том как осторожно снимать посекторнее образы с дисков, и, часто, программы для восстановления умеют делать это самостоятельно. Если диск проявил малейшие признаки неисправности — не надо диск насиловать. Это как раз случай где упорство вредно. Возможно, этот диск не понадобится для сборки массива. Лучше сосредоточиться на живых. Если живых дисков недостаточно — это задача для специалистов.
Любое действие предпринимаемое самостоятельно это риск. Но, иногда, этот риск оправдан. Иногда, обратиться к специалистам это тоже риск, особенно, когда специалисты далеко, а, единственный способ доставки дисков — почта. Или, как было сказано, специалисты не проверены. Транспортировать неисправные диски, в конце концов, — тоже вредно.akrupa
08.05.2017 01:29Раз уж тут в комментариях зашла речь о ПО, то для восстановления своего массива при сгоревшем контроллере использовал:
UFS Explorer
hddmasters
08.05.2017 09:43Это не проблема. Программы умеют искать смещения «регулярками». Но, это работает только если искомая область не повреждена. Если повреждена, — это как раз «сложный случай»
Из моего личного теста в 2014 году, автоматического ПО могу сказать, что самостоятельно определить размер метаданных RAID контроллера в начале LBA диапазона и найти область с которой начинался единственный массив затруднилось все тестируемое ПО.
Даже если массивов несколько — это может сработать. Программы часто умеют читать стандартные способы разбивки MatrixRaid/MD/LVM и т.п., как и большинство комбинаций. Но, метаданные должны быть на месте.
в 2014 году в авторекаверилках с разбором LVM была мрачная картина (полное отсутствие разбора). В лучшем случае был разбор LDM для «динамичесикх дисков» в Windows.
Есть много статей о том как осторожно снимать посекторнее образы с дисков, и, часто, программы для восстановления умеют делать это самостоятельно. Если диск проявил малейшие признаки неисправности — не надо диск насиловать.
программы автоматического восстановления в настраиваются в лучшем случае на прыжок в случае дефекта, без каких-либо возможностей вычитки участка после создания основного образа. Если ставить большие прыжки, то на проблемном месте будет много недочитанных мест, если ставить маленький, то будет попытка убийства диска с дефектами. Никакого контроля времени операции чтения, никакого контроля состояния диска и того, что он отдает.
Транспортировать неисправные диски, в конце концов, — тоже вредно.
в принципе не более вредно, чем и исправные. При правильной упаковке и использовании служб курьерской доставки не так все страшно.
Любое действие предпринимаемое самостоятельно это риск. Но, иногда, этот риск оправдан.
Вопрос лишь в ценности данных. Когда пользователь играется с собственным массивом, где он 100% владелец информации и готов с нею расстаться в случае неудачи, то это конечно его дело. Но в случае, когда системный администратор не обладая должной квалификацией начинает экспериментировать с дисками из RAID массива компании, где находится результат труда многих людей, то тут пора вовремя остановиться во избежание наступления необратимых последствий.

CactusKnight
06.05.2017 19:49И во сколько это, если не секрет, обошлось заказчик?
hddmasters
06.05.2017 19:52В договоре с клиентом прописано, что информация заказчика, включая информацию о заключенном с ним договоре, не передается третьим лицам. Конкретная стоимость услуг является элементом договора.
Если Вы хотите обратиться за услугой, то в нашей лаборатории бесплатная диагностика, на основании которой оцениваются трудозатраты, согласно технического задания, и формируется стоимость услуги. Учитывая различную сложность задач и нюансы технических заданий стоимость может варьироваться в очень широком диапазоне. Кроме этого на стоимость влияет время выполнения. Будет это дневное время будних дней или круглосуточный режим в выходные дни.
osipov_dv
06.05.2017 20:29Бэкапы? Зачем, ведь есть же RAID!
Когда же подобные одмины закончатся…
dartraiden
06.05.2017 20:37Да ещё и RAID-5.
Почему RAID-5 — «mustdie»?
В интернете легко можно найти истории, когда сравнительно небольшой 4-6 дисковый RAID-5 из 500GB дисков восстанавливал данные на новый диск в течении суток, и более.
С использованием же терабайтных и двухтерабайтных дисков приведенные цифры можно смело умножать в 2-4 раза!
И вот тут начинаются страсти.
Дело в том, и это надо себе трезво уяснить, что на время ребилда RAID-5 вы остаетесь не просто с RAID лишенным отказоустойчивости. Вы получаете на все время ребилда RAID-0.
kvaps
06.05.2017 20:50Использую RAID-Z (аналог RAID-5) на трех 2TB дисках в домашних условиях.
Полный ребилд массива занимает порядка 20 часов.
Бекапы конечно делаются.
gmelikov
06.05.2017 23:34Raidz не является полным аналогом raid5, он не "must die", но для резервирования рекомендуется использовать минимум raidz2.
gmelikov
06.05.2017 23:36+1в частности, при ребилде raidz записывает только данные, в то время как классический raid5 не знает о данных, и обязан реплицировать весь объём.
hddmasters
06.05.2017 20:50+3Если RAID 5 в руках системного администратора, который обладает базовыми знаниями согласно организации хранения данных в массиве, то особо бояться будет нечего. Потому как банально у него будут резервные копии всего нужного. Перед ребилдом он сделает еще одну копию важных данных.
RAID 10, так же при отказе в зоне риска, что если возникнут затруднения чтения на единственной копии диска, оставшейся в массиве, то точно также случится остановка массива.
Более явное преимущество имеет RAID 6.

Kwisatz
07.05.2017 09:11А еще в интернете когда задаешь вопросы касательно рейда то народ сразу теряется или говорит что все по дефолту:
— Журнал рейда на самом рейде
— Размер страйпа наугад выбран
— Размер и смещение блоков ФС тоже какие то странные
итд итп
hddmasters
06.05.2017 20:37+1Резервные копии баз были, но двухнедельной давности. Но как оказалось ценность имели не только базы, но и полностью сконфигурированные виртуальные машины. В связи с чем заказчик предпочел не начинать с чистого листа, а получить актуальные копии баз и рабочие виртуальные машины.

YMax
08.05.2017 17:54Бэкапы? Нет, не слышал… Так бы в худшем случае потерял небольшой промежуток данных — не более того. Но ведь да, есть RAID, он же надёжный…
Кстати, RAID 5 в продакшн? Серьёзно? Ни за что.hddmasters
08.05.2017 18:11+1Бэкапы? Нет, не слышал… Так бы в худшем случае потерял небольшой промежуток данных — не более того. Но ведь да, есть RAID, он же надёжный…
в комментариях сказано про наличие бэкапов.
Кстати, RAID 5 в продакшн? Серьёзно? Ни за что.
Вы так говорите, будто бы Вас тут намерено заставляют использовать RAID 5.
RAID 5 хорош, когда использован к месту. Не для всех задач он подходит. Всего-лишь стоит обозначить, где его можно применить, где нет без категоричных заявлений.
gmelikov
06.05.2017 23:38+2Бекапы конечно всегда обязательны, но после знакомства с ZFS я ни ногой в другие ФС, а про raid5 вообще и говорить не стоит.
hddmasters
07.05.2017 18:54а про raid5 вообще и говорить не стоит.
Поговорить можно, если без эмоций оценивать его недостатки и достоинства.
но после знакомства с ZFS я ни ногой в другие ФС
После случая «падения» данной файловой системы вы несколько измените свое мнение (поверьте, она тоже падает по тем же причинам, что и другие файловые системы). Тем более большинство преимуществ данной файловой системы весьма не очевидны, например для домашних пользователей и малых офисов.gmelikov
07.05.2017 20:08Поговорить можно, если без эмоций оценивать его недостатки и достоинства.
Извиняюсь за излишнюю эмоциональность, но это не отменяет явных недостатков raid5 на дисках большого объёма хотя бы из-за BER. Да, он работает, но при сбое вероятность потерь меня очень смущает.
После случая «падения» данной файловой системы
Я не утверждал, что она не падает, к сожалению всё может в какой-то момент дать сбой. Наоборот, как раз сторонники ZFS наиболее яро пропагандируют эту идею, в частности только они явно выделяют рекомендации по ECC памяти.
преимуществ данной файловой системы весьма не очевидны, например для домашних пользователей и малых офисов.
Не хочу спорить, лично для меня это вопрос из разряда «мыши плакали, кололись, но продолжали есть кактус». Я понимаю, что у каждой ФС свои плюсы.
Кстати, у вас уже был опыт восстановления ZFS?
Также очень интересно было бы узнать ваши предпочтения по ФС.
hddmasters
07.05.2017 20:52Извиняюсь за излишнюю эмоциональность, но это не отменяет явных недостатков raid5 на дисках большого объёма хотя бы из-за BER. Да, он работает, но при сбое вероятность потерь меня очень смущает.
Если рассмотреть типичные условия: диски куплены в одно время и на них создан массив. Условия эксплуатации одинаковые, как по времени, так и по нагрузке. Если были какие-то внешние воздействия, то они касались всех дисков в этом массиве. Исключение первого диска из массива обычно намекает, что с ним есть проблемы. В такой ситуации кроме стандартного бекапного плана стоит переместить актуальные данные на другой сервер/массив (максимально безболезненно для пользователей), а уж потом заниматься реанимацией массива в надежде, что из одинаково «уставших» дисков вылет одного чистая случайность. Обращая внимание на вероятности возникновения ошибок в HDD стоит разве что в дорогих системах, где в первую очередь продумана система бесперебойного питания начиная с батарей, заканчивая несколькими блоками питания, где используется ОЗУ с ЕСС, где должным образом экранированы корпуса, где продумана система охлаждения, как в самом устройстве, так и в помещении, где оно находится и многие другие факторы.
сторонники ZFS наиболее яро пропагандируют эту идею, в частности только они явно выделяют рекомендации по ECC памяти.
но кроме ОЗУ с ЕСС надо учитывать и остальные компоненты, как написано выше.
Говоря о дорогой серверной системе, где все учтено, что написано выше, я бы согласился, что в качестве элемента дополнительной надежности можно рассмотреть ZFS и местами даже нужно. В случае же NAS для дома и малых офисов дополнительная надежность ZFS звучит как издёвка.
Не хочу спорить, лично для меня это вопрос из разряда «мыши плакали, кололись, но продолжали есть кактус». Я понимаю, что у каждой ФС свои плюсы.
Именно у каждой свои плюсы. Во многих случаях ZFS тот же кактус.
Кстати, у вас уже был опыт восстановления ZFS?
был.
Также очень интересно было бы узнать ваши предпочтения по ФС
«родные» файловые системы для ОС в которой они используются. пример: MS Windows — NTFS
gmelikov
08.05.2017 10:53В случае же NAS для дома и малых офисов дополнительная надежность ZFS звучит как издёвка.
Именно в этом случае и не соглашусь, ZFS создавалась с упором на ненадёжность носителей, что прямо относится к недорогим HDD, взять хотя бы подсчёт контрольных сумм всех данных. В отличии от него, другие ФС отдадут то, что выдал HDD, без проверки.
И уж если мы заговорили о надёжности железа, то оно от ФС не зависит.
«родные» файловые системы для ОС в которой они используются. пример: MS Windows — NTFS
Извиняюсь, что не уточнил — в Linux, для Windows вариантов особо и нет :) Для Linux понятия родной ФС в вашем случае можно заменить на наиболее используемую, видимо это ext4.
Также интересно узнать, есть ли у вас какое-то мнение по поводу надёжности файловых систем, что лучше или хуже?hddmasters
08.05.2017 11:28Именно в этом случае и не соглашусь, ZFS создавалась с упором на ненадёжность носителей, что прямо относится к недорогим HDD, взять хотя бы подсчёт контрольных сумм всех данных. В отличии от него, другие ФС отдадут то, что выдал HDD, без проверки.
В случае отказа HDD, например проблемы с буферным ОЗУ на его плате, в накопитель запишутся как и битые данные, так и битые контрольные суммы для этих данных. Т.е. совершенно не спасет. Кроме этого при проблемах в иных компонентах ПК в накопитель будут записаны битые данные или недописаны.
В исправном накопителе, есть процедуры контроля целостности данных при поступлении информации по интерфейсу. Контроль целостности в ОЗУ, есть биты четности, при записи на пластину и чтении хороший контроль в виде БЧХ кодов (ЕСС). Да и результаты нагрузочного тестирования на новых недорогих винтах показывают, что случайно искажение данных по вине накопителя — это то, чего нужно опасаться меньше всего (если рассматривать систему в комплексе).
Нагрузочное тестирование велось следующим образом: Несколько накопителей 500Гб. Запись случайно сформированным паттерном, потом чтение (в рамках всего LBA диапазона) для проверки записанного. 3 часа один цикл. за сутки 8 циклов то есть 4Тб данных. за месяц 30 дней 120Тб. Продолжать эксперимент получилось примерно до одного Петабайта. (дальше последовало длительное отключение электроэнергии и возможностей ИБП не хватило и тест был прерван). Отловить хоть одну ошибку не удалось. Более полугода такого тестирования — это многие годы работы в условиях малого офиса или дома.
И уж если мы заговорили о надёжности железа, то оно от ФС не зависит.
говоря о сохранности данных и анализируя случаи их повреждения, мы лишь констатируем, что наличие ZFS практически бесполезно при других ненадежных элементах системы. Но вот в случае аварии и повреждения ZFS для домашнего пользователя или малого офиса процедура восстановления данных будет существенно усложнена. Стоит ли закладывать себе «мину» в виде ZFS, зная что другие компоненты системы в плане надежности оставляют желать лучшего?
Также интересно узнать, есть ли у вас какое-то мнение по поводу надёжности файловых систем, что лучше или хуже?
Если говорить о различных случаях повреждений файловых систем и возможностей восстановления данных и рассматривать например Ext (2,3,4), XFS, VMFS, ExFAT, FAT32, NTFS, HFS+
то самой живучей по итогу окажется NTFS. Место аутсайдера займет ExFAT c VMFS
gmelikov
08.05.2017 12:34Сразу уточню, что я говорю только о Linux и Unix мире, т.к. ваша статья была о нём, и в контексте надёжности.
В случае отказа HDD, например проблемы с буферным ОЗУ на его плате, в накопитель запишутся как и битые данные, так и битые контрольные суммы для этих данных. Т.е. совершенно не спасет.
И это естественно. Контрольная сумма (даже неверная) сработает при чтении, что спасёт от использования искажённых данных, а также спасёт от дальнейших потерь.То есть ZFS гарантирует в первую очередь проверку на корректность, такие данные в любом случае потеряны, если нет резервирования (а при использовании любого резервирования ZFS просто восстановит такой блок на проблемный носитель, хотя это является первым признаком возможного сбоя носителя в будущем).
случайно искажение данных по вине накопителя — это то, чего нужно опасаться меньше всего (если рассматривать систему в комплексе).
Но этот фактор нельзя просто отбрасывать, если данные всё-таки нам дороги (всё же производители не просто так предоставляют информацию о BER). Тут скорее идёт речь о балансе надёжности к стоимости/производительности.
наличие ZFS практически бесполезно при других ненадежных элементах системы
Только ZFS отреагирует на проблемы с оборудованием (речь про искажение информации), другие ФС будут работать уже с некорректными данными, т.к. контрольные суммы они не считают.
в случае аварии и повреждения ZFS для домашнего пользователя или малого офиса процедура восстановления данных будет существенно усложнена
Можете уточнить точный сценарий, при котором ZFS сложнее восстановить?
Предполагая, что значительная часть данных с диска сохранена, и резервирование не используется — ZFS перетягивается тем же dd на другой диск, проводится штатный scrub, который выявляет все проблемы с данными, а неповреждённые блоки будут и дальше прекрасно работать (а метаданные всегда дублируются в нескольких частях диска).
Также в контексте использования на десктопах у ZFS есть возможность дублировать все блоки несколько раз (параметр copies).
Невозможность примонтирования (т.е. полный крах ФС) в счёт не беру, т.к. в этом случае проблемы будут одинаковы для всех ФС. Но и в этом случае ZFS на шаг впереди за счёт CoW (copy on write) — фактически он позволяет откатиться до последней корректной транзакции на диск.
Естественно, что рядовой пользователь не знает, как восстановить данные с любой ФС. Я не предлагаю на каждый ноутбук с Windows прямо сейчас городить ZFS (жаль, что сейчас это и невозможно), но это не значит, что самый распространённый вариант = самый верный.
Шествие ZFS в мире Unix идёт семимильными шагами, он уже используется в *BSD, Solaris, а в Linux будет штатным через 1-2 года, т.к. наконец решены вопросы с лицензией, Debian уже включил его в штатный репозиторий Stretch. Я считаю, что есть множество случаев, когда его использование оправдано.hddmasters
08.05.2017 12:56И это естественно. Контрольная сумма (даже неверная) сработает при чтении, что спасёт от использования искажённых данных, а также спасёт от дальнейших потерь.То есть ZFS гарантирует в первую очередь проверку на корректность, такие данные в любом случае потеряны, если нет резервирования (а при использовании любого резервирования ZFS просто восстановит такой блок на проблемный носитель, хотя это является первым признаком возможного сбоя носителя в будущем).
говоря о данных не забывайте, что речь может идти о повреждении самих структур ZFS и мало проку будет от самих проверок. Говоря о случайных ошибках накопителей прочтите комментарий ниже. К сожалению страховка от сбоев накопителей — это по большей части маркетинговый ход.
Но этот фактор нельзя просто отбрасывать, если данные всё-таки нам дороги (всё же производители не просто так предоставляют информацию о BER). Тут скорее идёт речь о балансе надёжности к стоимости/производительности
именно его пожалуй и стоит отбросить в силу того, что накопитель банально не выдаст вам данных, если возникла некорректируемая ошибка чтения (прочтите комментарий ниже).
Только ZFS отреагирует на проблемы с оборудованием (речь про искажение информации), другие ФС будут работать уже с некорректными данными, т.к. контрольные суммы они не считают.
при сбоях в работе ОЗУ рухнет все, в том числе и процедуры контроля, которые выполняются при R/W операциях и банально будет записан кусок мусора вместо структур и данных. Крах будет примерно одинаковым по последствиям на любой файловой системе. Из реальных плюсов ZFS можно отметить, что при ошибках в файловой системе и пересекающихся записей, проще будет установить, где еще остались целые данные.
Невозможность примонтирования (т.е. полный крах ФС) в счёт не беру, т.к. в этом случае проблемы будут одинаковы для всех ФС. Но и в этом случае ZFS на шаг впереди за счёт CoW (copy on write) — фактически он позволяет откатиться до последней корректной транзакции на диск.
Несколько оптимистичный взгляд на разрушения. Вы скорее говорите о мелких проблемах, которые вызваны аварийным отключением питания. Здесь многие ФС перенесут это без какой-либо существенной потери данных.
Шествие ZFS в мире Unix идёт семимильными шагами, он уже используется в *BSD, Solaris, а в Linux будет штатным через 1-2 года, т.к. наконец решены вопросы с лицензией, Debian уже включил его в штатный репозиторий Stretch. Я считаю, что есть множество случаев, когда его использование оправдано.
продолжается, так как есть некоторые конкурентные преимущества. Но повторюсь в случае дома и малого офиса, они банально не раскроются.
gmelikov
08.05.2017 13:44Вашу позицию по поводу BER я всё-таки не разделяю (предпочитаю быть параноиком), пожелаю лишь нам всем удачи и в дальнейшём отсутствии такой проблемы.
Вы скорее говорите о мелких проблемах, которые вызваны аварийным отключением питания.
Отключение питания вообще не страшно ZFS, она атомарна, недозаписанная информация будет потеряна, но она не приведёт к какой либо ошибке в структуре.
говоря о данных не забывайте, что речь может идти о повреждении самих структур ZFS и мало проку будет от самих проверок
Крах будет примерно одинаковым по последствиям на любой файловой системе.
Говоря о ZFS, стоит в первую очередь понимать, какие отличия у CoW ФС от классических. В случае ZFS даже при успешной записи новых метаданных старые метаданные не затираются в течении нескольких транзакций ZFS, что технически даёт возможность откатиться на последнее стабильное состояние (вот пример, как можно поступить при повреждении структуры).
При всём этом носитель должен быть изрядно поврежден, т.к. метаданные дублируются на разных частях.hddmasters
08.05.2017 13:57Вашу позицию по поводу BER я всё-таки не разделяю (предпочитаю быть параноиком), пожелаю лишь нам всем удачи и в дальнейшём отсутствии такой проблемы.
после ознакомления с АТА стандартом и анализе нескольких микропрограмм накопителей страхи отступят. Ну и экспериментально попробуйте подтвердить, что исправный накопитель при определенных условиях выдаст некорректные данные, а не будет поймана ошибка и взведен флаг ошибки.
Отключение питания вообще не страшно ZFS, она атомарна, недозаписанная информация будет потеряна, но она не приведёт к какой либо ошибке в структуре.
это можно сказать почти о любой относительно современной файловой системе. Но процедуру проверки потребуют все.
Говоря о ZFS, стоит в первую очередь понимать, какие отличия у CoW ФС от классических. В случае ZFS даже при успешной записи новых метаданных старые метаданные не затираются в течении нескольких транзакций ZFS, что технически даёт возможность откатиться на последнее стабильное состояние
в идеальных условиях выглядит чуть ли не панацеей от все бед, но при реальных сбоя и отказах оборудования рушится чуточку поболее, чем хотелось бы. Беря пример в данной заметке — некоторые структуры, на разных дисках оказались уничтоженными на 100% (причем они вообще не должны были перезаписываться при штатной работе). Так и с ZFS при некоторых видах сбоев пострадать может не только самая последняя структура.gmelikov
08.05.2017 14:19Ну и экспериментально попробуйте подтвердить, что исправный накопитель при определенных условиях выдаст некорректные данные
CERN и Amazon точно с вами не согласны, и это только верхушка айсберга.
У ЦЕРН в этом отчёте также есть статистика по RAID5, которая наглядно показывает, почему он ненадёжен. Приведу цитату:
1.Disk errors
…
2.RAID 5 verification
…
Running the verify command for the RAID controller on 492 systems over 4
weeks resulted in the fix of ~300 block problems. The disk vendors claims about
one unrecoverable bit error in 10^14 bits read/written. The 492 systems correspond
to about 1.5 PB of disk space.
…
The first thing to notice is that the verify command stresses the disks 3 times more than the actual physics applications, by just running it once per week.
The second observation is the that we measured about 300 errors while from the mentioned BER (Bit Error Rate) and the usage one would expect about 850 errors. As the vendor BER numbers are normally on the ‘safe’ side the measurement is close to the expectation.
3.Memory errors
…
4.CASTOR data pool checksum verification
All the previously mentioned error will of course result in the corruption of user data.
…
Честно, я очень хотел бы с вами согласиться.hddmasters
08.05.2017 14:29Результаты данного тестирования вызывают больше вопросов, чем дают ответов. На основании собственных экспериментов и анализе протоколов передачи, могу подозревать, что в том тестирование под проблемы накопителей списано множество иных проблем.
hddmasters
08.05.2017 14:04Стоит еще отметить, что мире много стандартов принятых на основании чьих-то страхов. Причем совершенно необоснованных, но позволяющих освоить немалые средства. Например возьмем требование некоторых стандартов перед утилизацией диск многократно перезаписывать разными паттернами, во избежание возможности восстановить с него данные. Хотя достаточно одной перезаписи всего LBA диапазона, чтобы уничтожить данные безвозвратно. Эксперименты в области магнитно-силовой микроскопии это подтвердят.

al_ace
11.05.2017 17:45+3Можете уточнить точный сценарий, при котором ZFS сложнее восстановить?
Есть целая куча сценариев, которую можно отнести к человеческому фактору. Сюда относятся всякие переформатирования, переинициализации, удаление файлов по ошибке и тому подобное.
Преимущество NTFS в таких сценариях в том, что она хорошо изучена и ее поддерживают все основные инструменты для восстановления данных (кто-то хуже, а кто-то лучше, но поддерживают), а у специалистов по восстановлению данных уже скопился большой опыт. А вот с ZFS все сейчас находится только в развитии.
Если проводить очень грубую аналогию с автомобилями, то NTFS — она как жигули, а ZFS — как тесла. Тесла вроде как должна быть надежней, заранее сообщать о поломках и прочее. Но если вы дадите ее погонять подросткам в деревню, они точно найдут способ ее сломать. И починить ее сможет один лишь Илон Маск. А вот жигули вам вам смогут починить в той же деревне и за дешево.
hddmasters
08.05.2017 12:41Возьмем спецификацию на недорогой современный HDD
найдем пугающую строчку Nonrecoverable Read Errors per Bits Read, Max 1 per 10E14, но стоит это понимать так: что при попытке чтения может возникнуть ситуация, что сектор будет прочитан с ошибкой и емкости ЕСС не хватит для коррекции. Но в этом случае накопитель не отдаст битых данных. Будет банально взведен флаг ошибки чтения. Если речь шла о случайной ошибке, то при повторном чтении, все прочитается. Также стоит учесть, что по умолчанию микропрограмма такой сектор в современном накопителе попытается перечитать и не раз и не два. Например во многих десктопных версиях сигейтов по умолчанию 20 попыток чтения.
В общем не стоит бояться случайных ошибок. Дефектообразование на пластинах это несколько другой род проблем и не относится к этому пункту спецификации.

Aytuar
07.05.2017 23:58+1Хм. У меня падала zfs и восстановление было автоматом. Типа check disk, но на 2ТБ дисках в raidz2 он был долгий, точно уже не помню, но точно больше 2 часов.
hddmasters
08.05.2017 00:15Хм. У меня падала zfs и восстановление было автоматом. Типа check disk, но на 2ТБ дисках в raidz2 он был долгий, точно уже не помню, но точно больше 2 часов.
Разве ж это падение? Так мелкая проблема, которая легко поправляется штатными средствами.
А время проверки зависит от размера метаданных, корректность которых необходимо проверить.
Под падением будет подразумевать случаи, где штатные средства ничем не могут помочь.
DRDOS
07.05.2017 19:25А можете дать рекомендации :)) Как подстраховаться, для автоматического восстановления!
Что бы можно было к «вам» не обращаться.
Когда мне заломили цену за восстановление информации с 1гб диска в нашем городе.
Дешевле было весь бизнес с нуля начать :(hddmasters
07.05.2017 19:49Когда мне заломили цену за восстановление информации с 1гб диска в нашем городе.
Дешевле было весь бизнес с нуля начать :(
Или бизнес весь совсем ничего не стоил или обратились не в профильную компанию, которая формировала цену непонятно из чего. Стоимость восстановления данных с неисправных дисков по странам СНГ обычно от нескольких десятков, до нескольких сотен евро. Исключение могут составлять случаи с сильно поврежденными накопителями, требующих большое количество донорских затрат и случаи с восстановлением фрагментированных файлов без опоры на файловую систему.
А можете дать рекомендации :)) Как подстраховаться, для автоматического восстановления!
Что бы можно было к «вам» не обращаться.
Продумайте и внедрите систему резервного копирования. Учитывайте различные события, которые могут повлиять на целостность и наличие ваших данных. Ищите меры противодействия. При продуманной системе резервного копирования услуги компаний по восстановлению данных не потребуются.
DRDOS
07.05.2017 23:00Да сумма была за 1000 б. но это было 4 года назад.
Недавно была
проблема с резервным копированием, основной сервер имел раид 0, на одном из дисков стали сыпаться сектора. При этом делались резервные копии, на сервер резервного копирования.
В результате когда все грохнулось, оказалось, что повреждено всё.
Дело в том, что к основным файлам, обращаются ооооочень редко, а пользуются их сжатой копией, но когда понадобилось, оказалось все плохо.
hddmasters
07.05.2017 23:22Да сумма была за 1000 б. но это было 4 года назад.
в профильной компании такая цена могла быть разве что за диск с очень серьезными повреждениями на поверхностях и неисправными головками, где бы потребовалось множество доноров. Если же речь идет о рядовых дефектообразования и проблемах с микропрограммой, то стоимость даже в самых дорогих городах РФ в профильных компаниях в несколько раз ниже, чем озвученная Вами.
Недавно была
проблема с резервным копированием, основной сервер имел раид 0, на одном из дисков стали сыпаться сектора. При этом делались резервные копии, на сервер резервного копирования.
В результате когда все грохнулось, оказалось, что повреждено всё.
Дело в том, что к основным файлам, обращаются ооооочень редко, а пользуются их сжатой копией, но когда понадобилось, оказалось все плохо.
здесь вы допустили ошибки
1. Использовали уровень массива без избыточности (RAID 0 — чередование)
2. Копии складывали на этот массив.
Итог Вы сами вскоре и ощутили. Но если накопитель с дефектами не довели до запилов, то как правило получить данные не будет большой сложностью.
hddmasters
09.05.2017 11:02Да сумма была за 1000 б. но это было 4 года назад.
Когда мне заломили цену за восстановление информации с 1гб диска в нашем городе.
Дешевле было весь бизнес с нуля начать :(
Полагаю, что накопитель был емкостью 1Тб
ingumsky
А причину сбоя выяснить не удалось? Интересно, почему это случилось (может с вами заказчик поделился какими-то итогами своего расследования)?
PS Ваши статьи читаются, как детектив. Спасибо!
hddmasters
Все расследование заказчика закончилось на уровне формулировки «Сбой оборудования». Перед нами не стояла задача проводить комплекс исследований и пытаться создать условия при которых бы повторился сбой. Посему, кроме ответа на вопрос «Как восстановить данные?» я ничего больше не смогу сказать по данному случаю.