В последнее время имена GridGain и Apache Ignite нередко мелькают в интернетах. Однако, судя по комментариям (например, здесь), мало кто понимает, что же это за продукт и с чем его едят.
В этой статье я попытаюсь доступным языком объяснить, и на примерах кода показать, что умеет Apache Ignite.

Ignite vs GridGain
Краткий ликбез: компания GridGain выпустила первую версию одноимённого продукта в 2007 году. В 2014 году GridGain пожертвовала большую часть кода в пользу Apache Software Foundation, в результате чего родился проект Apache Ignite. GridGain предоставляет платную поддержку и дополнительную функциональность в виде плагина.
Важно понимать: Apache Ignite не принадлежит GridGain и является свободным программным обеспечением под лицензией Apache 2.0.
Отличие от "обычных" open-source проектов (расположенных на GitHub, например) здесь в том, что нет возможности "передумать", закрыть код, поменять лицензию, и так далее.
Ignite принадлежит Apache Software Foundation.
Ignite.NET
Ignite написан на Java, а так же предоставляет API на .NET и C++. В данной статье будет идти речь именно о .NET API, в котором есть примерно 90% функционала жавовского АПИ, плюс свои собственные плюшки (LINQ).
Что это такое и зачем?
Самый простой и ёмкий ответ — это база данных. В основе которой — хранилище "ключ-значение"; грубо говоря, ConcurrentDictionary, в котором данные расположены на нескольких машинах.
При этом поддерживаются распределённые транзакции, SQL с индексами, полнотекстовый поиск Lucene, map-reduce вычисления, и многое другое. Но обо всём по порядку.
Как запустить?
В одну строчку! Это самая простая в установке и использовании база данных, которую я знаю.
Плохая новость: нам потребуется установленный Java Runtime 7+. Хорошая новость: с этого момента про Java можно забыть.
Создадим в Visual Studio простой Console Application, установим NuGet пакет Apache.Ignite, добавим в метод Main одну строчку Ignition.Start();. Готово, можно запускать. Через пару секунд в консоли появится "Topology snapshot [ver=1, servers=1". Запустим программу ещё раз и увидим в обеих консолях "Topology snapshot [ver=2, servers=2". Распределённая база данных запущена на двух узлах.
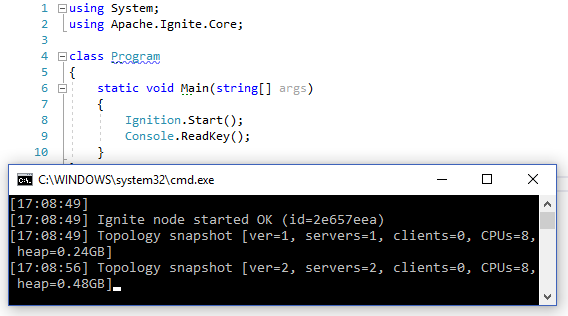
- Узел или Нода — это результат команды
Ignition.Start(). Можно запустить несколько узлов на одной машине или даже в одном процессе. - Кластер — набор нод, соединённых между собой. Ноды видят или не видят друг друга в зависимости от конфигурации. Таким образом, можно запустить несколько отдельных кластеров даже в пределах одного процесса.
Работа с данными
Хорошо, базу данных мы стартовали, теперь неплохо бы создать таблицы и наполнить их.
Таблица в Apache Ignite — это кэш, ICache<K, V>. Работа идёт напрямую с пользовательскими типами данных, так что у нас здесь и ORM в одном флаконе (хотя есть возможность работать с данными напрямую, без маппинга в объекты).
class Car
{
public string Model { get; set; }
public int Power { get; set; }
public override string ToString() => $"Model: {Model}, Power: {Power} hp";
}
static void Main()
{
using (var ignite = Ignition.Start())
{
ICache<int, Car> cache = ignite.GetOrCreateCache<int, Car>("cars");
cache[1] = new Car {Model = "Pagani Zonda R", Power = 740};
foreach (ICacheEntry<int, Car> entry in cache)
Console.WriteLine(entry);
}
}Как видим, базовая работа с кэшем ничем не отличается от всем знакомого Dictionary<,>. При этом данные немедленно доступны на всех узлах кластера.
Эту часть функционала можно сравнивать с Redis.
SQL
Данные можно добавлять и запрашивать через SQL. Для этого требуется явно указать, какие поля объекта принимают участие в запросах (атрибут [QuerySqlField]), и указать типы ключа и значения в конфигурации кэша:
class Car
{
[QuerySqlField] public string Model { get; set; }
[QuerySqlField] public int Power { get; set; }
}
...
// Конфигурируем кэш для работы с SQL:
var queryEntity = new QueryEntity(typeof(int), typeof(Car));
var cacheConfig = new CacheConfiguration("cars", queryEntity);
ICache<int, Car> cache = ignite.GetOrCreateCache<int, Car>(cacheConfig);
// Вставка данных (_key - предопределённое поле):
var insertQuery = new SqlFieldsQuery("INSERT INTO Car (_key, Model, Power) VALUES " +
"(1, 'Ariel Atom', 350), " +
"(2, 'Reliant Robin', 39)");
cache.QueryFields(insertQuery).GetAll();
// Запрос данных:
var selQuery = new SqlQuery(typeof(Car), "SELECT * FROM Car ORDER BY Power");
foreach (ICacheEntry<int, Car> entry in cache.Query(selQuery))
Console.WriteLine(entry);Эти два подхода, key-value и SQL, можно смешивать по вкусу. Получить или вставить одно значение проще и быстрее через cache[key], а обновить множество значений по условию — через SQL.
LINQ
Запрос из примера выше можно переписать на LINQ (потребуется NuGet пакет Apache.Ignite.Linq):
var linqSelect = cache.AsCacheQueryable().OrderBy(c => c.Value.Power);
foreach (ICacheEntry<int, Car> entry in linqSelect)
Console.WriteLine(entry);Этот запрос будет транслирован в SQL, в чём можно убедиться, приведя тип linqSelect к ICacheQueryable.
Обратите внимание на AsCacheQueryable() — это важно! Забыв этот вызов, мы превратим распределённый SQL запрос в LINQ-To-Objects, который приведёт к загрузке всех данных на локальный узел, чего мы обычно не хотим.
Как это работает?
По умолчанию кэши в Ignite работают в Partitioned режиме, в котором данные равномерно распределяются между узлами. SQL запрос отсылается на каждый узел и выполняется, результаты затем агрегируются на вызывающей ноде. Каждый узел параллельно с другими обрабатывает только свою часть данных. Добавляя больше узлов в кластер мы можем увеличить производительность и объём хранимых данных.
Для обеспечения отказоустойчивости можно указать одну или несколько резервных копий, то есть количество узлов, хранящих каждый элемент данных.
В некоторых случаях имеет смысл Replicated режим, где каждый узел хранит полную копию всех данных.
Map-Reduce, Locks, Atomics...
Предположим, нам необходимо перевести огромный текст, или распознать большое количество изображений. Такие задачи можно легко распараллелить между несколькими серверами:
class Translator : IComputeFunc<string, string>
{
public string Invoke(string text) => TranslateText(text);
}
...
IEnumerable<string> pages = GetTextPages();
ICollection<string> translated = ignite.GetCompute().Apply(new Translator(), pages);Синхронизировать различные процессы между узлами можно при помощи распределённых блокировок. Функционал аналогичен lock {} / Monitor, с той лишь разницей, что распространяется на весь кластер:
var cache = ignite.GetOrCreateCache<int, int>("foo");
using (ICacheLock lck = cache.Lock(1))
{
lck.Enter();
// делай дело
lck.Exit();
}Знакомы с классом Interlocked? Ignite предоставляет аналогичный неблокирующий функционал, только операции атомарны в пределах всего кластера.
var atomic = ignite.GetAtomicLong(name: "myVal", initialValue: 1, create: true);
atomic.Increment();
atomic.CompareExchange(10, 20);Эту группу фич можно сравнивать с Akka.
Заключение
Я работаю в GridGain, но пишу этот пост от лица контрибьютора Apache Ignite. Мне кажется, продукт заслуживает внимания. Особенно в .NET мире, где вся тема Big Data и распределенных вычислений слабо раскрыта. Мало таких проектов нормально поддерживают .NET, ещё меньше на нём написано.
Ignite.NET действительно легко попробовать, он запускается даже в LINQPad (примеры кода для LINQPad включены в NuGet!). Способов использования может быть масса. Есть интеграция с ASP.NET (output cache, session state cache), с Entity Framework (second level cache). Можно использовать как платформу для (микро)сервисов. В любом проекте, где требуется более одного сервера, Ignite может тем или иным образом облегчить жизнь.
Да, есть другие проекты, которые имеют ту или иную фичу Ignite, но нет другого проекта, где всё это объединено и интегрировано в один продукт.
Ссылки
- Сайт ignite.apache.org
- Код на GitHub github.com/apache/ignite
- Код .NET github.com/apache/ignite/tree/master/modules/platforms/dotnet
- NuGet nuget.org/packages/Apache.Ignite
- Примеры кода на GitHub
P. S. Мы в Apache Ignite всегда рады новым контрибьюторам! Есть множество интересных задач на .NET, C++, Java. Поучаствовать проще, чем кажется!
Комментарии (38)

NikitOS9
16.05.2017 16:21-8>Плохая новость: нам потребуется установленный Java Runtime 7+. Хорошая новость: с этого момента про Java можно забыть.
чтож не вся статья ф таком стиле;
Плохая новость: мы работаем на винде. Хорошая новость: забейте на это и абстрагируйтесь от ос
Плохая новость: мы работаем с .net. Хорошая новость: забейте на это и абстрагируйтесь от vm
Плохая новость: мы работаем x86. Хорошая новость: забейте на это и абстрагируйтесь от железа


verysimplenick
16.05.2017 21:57-1Самое интересное (страшное), что .net ignite запускает jvm внутри себя, и как этот сендвич будет в продакшене работать никакой уверенности нет, в Сбере ж на java его используют, а других компаний использующих его и нет (ну или нет инфы о них)

kefirr
16.05.2017 22:40+2Что значит кроме сбера компаний нет, откуда такие домыслы? Информация в открытом доступе: https://www.gridgain.com/customers/featured-customers
На словах может оно и страшно, две виртуальные машины в одном процессе, но если вдуматься — а что в этом такого? Они никак друг другу не мешают. Зато работает быстро, обмен данными через кусок unmanaged памяти. В продакшене всё хорошо.
Также в планах есть вынесение JVM в отдельный процесс и полноценный тонкий клиент на чистом дотнете.
tyanigor
17.05.2017 18:011) А что дает список компаний? Важно то, для чего они применяют Ignite. Можете сказать какие компании используют Ignite как замену классической СУБД на больших данных и высокой нагрузке?
2) К чему относится Ignite исходя из CAP теоремы, к CP или CA?
devozerov
17.05.2017 19:21+11) Этот вопрос станет актуален, когда выйдет persistence.
2) CPdevozerov
17.05.2017 19:32+1По второму пункту корректнее будет сказать, что оно регулируемо. Можно качнуть в сторону AP, можно в сторону CP.
tyanigor
22.05.2017 17:391) Перепутал, да AP и CP соответственно. А за счет чего достигается AP? При этом гарантируется хотябы консистентность в конечном итоге?
2) Скажите, если у меня есть две кэша на разных нодах Partitioned и включен бэкап. Это будет распределенная транзакция? И будут ли атомарно операции записи в кэш и актуализация бэкапа? Оно работает аналогично синхронной репликации?
verysimplenick
17.05.2017 18:49Ну как минимум 2 неуправляемых кучи, 2 GC, 2 stop the world, куча jvm настроек, которые непонятно как отразятся на работе связки.
Лучше не JVM вытаскивать а порт сделать, тогда комьюнити потянется, а так — скрестили 2 технологии в одном процессе.kefirr
17.05.2017 19:132 кучи, 2 GC
Давайте предметно, какие проблемы вы предвидите?
Обычный .NET код сплошь и рядом дёргает системные API, у которых своя unmanaged куча, и что?
Проблемы тут могут быть в x86 (32 bit), где сильно ограничено адресное пространство. В x64 с этим проблем нет. Но речь идёт о big data, так что 32 бита нас не особо беспокоят.
2 stop the world
Не все GC делают stop the world, это раз. Аллокации в managed heap на стороне Java минимальны, это два. Пользовательские данные хранятся в неуправляемой куче через Unsafe.
порт сделать
Полноценный порт потребует титанических усилий, значительно увеличит затраты на поддержку кода, и приведёт к менее гибкому решению. Смысла мало.
devozerov
17.05.2017 19:19+2Порт — это перенос сотен тысяч строк нетривиального кода, полный отказ от стандартных механизмов сериализации, и удвоение работы по имплементации и поддержке каждого тикета, раздувание штата.
Обертка — это быстрый подъем функционала, отсутствие дупликации. Ценой некоторых потерь в производительности, которые едва ли видны на фоне сетевого взаимодействия.
Это трейдофф, в котором мы выбрали первое, о чем до сих пор ни разу не пожалели. .NET не только в продакшене бегает, его уже другие вендоры эмбедяд в свои продукты.
С точки зрения комьюнити этот выбор достаточно перпенедикулярен.

Revkov
16.05.2017 23:18+1Мы используем Ignite в крупном проекте на Java. Статья совсем не информативная. Это не просто база данных. А in memory data grid (база данных в памяти, не персистент!). Плюс его можно использовать просто как кеш (JCache, Hibernate L2 cache и др. как Hazelcast например). В общем чтобы рассказать про Ignite надо несколько статей и намного другого содержания.
kefirr
16.05.2017 23:34чтобы рассказать про Ignite надо несколько статей
Именно поэтому в данной статье я попытался упрощённо донести суть дела.
Формально да, БД — не точное определение, но "in-memory data fabric (grid)" мало кому о чём-то говорит, проверено.
его можно использовать просто как кеш
Про это в статье есть, и не один раз.
Otaka
17.05.2017 11:01+1Этот Ignite вроде бы всем хорош. Но вот только прежде чем интегрировать его в свой проект, нужно хорошо его потестить, насколько он будет выполнять поставленные задачи вашего проекта.
У нас на проекте была необходимость динамически создавать таблицы разной структуры, а Ignite как я понял обязательно требует класс который будет исполнять роль table definition, так вот у меня не завелось никак кроме как созданием класса в рантайме с помощью javassist, и после этого начинаются пляски с бубном — при старте в локальном режиме оно работает прекрасно, и sql запросы выполняются хорошо, а вот в распределенном режиме вылетают разные ошибки где-то внутри его ядра.
Так же не нашел решения проблемы, когда при создании кеша нужно указать какие типы он будет содержать, а у меня ведь рантайм… опять же обходной путь — создавать новый кеш на каждую новую таблицу/тип. Но после этого sql запросы приходится писать так:
selet * from "mydb".mydb
Так как джава классы создаются динамически, то удалить их динамически уже так просто не получится, что так же создает еще одну проблему.
Но в проекте, где таблицы известны на этапе разработки, ignite работает прекрасно как hibernate кеш.
Вывод: требует времени на решение проблем, которых нет в более привычных базах данных. Так что он не серебряная пуля, как мне показалось после прочтения доки, а инструмент для определенных задачdevozerov
17.05.2017 17:37+1По поводу классов — уже ответили ниже, они не требуются. Что касается динамического создания таблиц и более удобного использования схем — такой функционал появится в версии 2.1 в середине июня.
kefirr
17.05.2017 11:09Ignite как я понял обязательно требует класс который будет исполнять роль table definition
Это не так, через
BinaryObjectAPI можно работать с кэшем, делать SQL запросы без единого класса.
Пример на C#: BinaryModeExample.cs
BinaryObjectподдерживает добавление и удаление полей в любой момент.
Единственное ограничение связано сейчас с SQL: требуется пересоздание кэша, если нужно поменять SQL столбцы или индексы. Но классы по прежнему не нужны, всё делается без каких-либо хаков.

centur
17.05.2017 14:15+1Есть несколько вопросов —
- Вы не упомянули, но на офф сайте написано, что это все in-memory — т.е. выключили машинку — потеряли базу, правильно?
- А как ноды общаются и синхронизируются между собой, ну например, у меня 3 VM, на каждом запущено по Apache Ignite — какие порты открывать, какой протокол, как и через что делается node discovery? Или это только для одного сервера ?
- Если я добавляю ноду — насколько быстро она получит нужные данные в Replicated режиме? Будет ли она собирать c каждого инстанса по отдельному диапазону или просто с одной из реплик качнет все что нужно?
- Я правильно понимаю что для запуска нужен только наггет пакет? т.е. там внутри и jar для базы и обертка на.нет чтобы его стартовать?
kefirr
17.05.2017 14:49+1Персистенс возможен через Cache Store. Другой вариант — настройка реплик (
CacheConfiguration.Backups), то есть только одновременный выход нескольких узлов приведёт к потере данных.
Общаются по TCP, находить друг друга могут по-разному, есть multicast discovery, есть static (указать IP в конфиге). Порты по умолчанию
47500~47600для discovery и47100~47200для коммуникации. Это НЕ для одного сервера. Предполагается кластер из некоторого числа серверов.
Будет собирать с нескольких узлов. Данные разбиваются на партиции (1024 по умолчанию), партиции распределяются между узлами. За это всё отвечает Affinity Function. При входе нового узла каждая партиция запрашивается со случайного узла из тех, на которых она есть (в Partitioned режиме с Backups > 0 таких узлов тоже несколько).
- Верно, NuGet содержит в себе jar файлы, больше ничего не нужно.
centur
17.05.2017 15:08понятно, а в случае если сетка падает\разделяется и восстанавливается — будет 2 Availability кластера да? А по восстановлению они как-то синхронизируются\обмениваются обновившимися данными или это за пределами функционала базы?
Dalamar81
17.05.2017 20:15+1Спасибо за статью.
Хорошо бы ещё обзор в сравнении с Tarantool почитать...kefirr
17.05.2017 20:24Небольшая дискуссия образовалась там: Tarantool как основное хранилище данных для серверных приложений, написанных на .NET.
В Tarantool есть персистенс, но нет SQL, нет нормальной поддержки .NET/С++ и многого другого.
Скоро в Игнайте будет персистенс, и вопрос закроем окончательно.
Dalamar81
17.05.2017 21:10Честно говоря, для Key-Value БД наличие SQL мне кажется больше недостатком, чем преимуществом… Ведь придётся ради его поддержки идти на компромиссы в системе.
devozerov
17.05.2017 23:23+1Я навскидку не могу назвать мест, где нам пришлось пойти на большие компромиссы в других компонентах ради из-за поддержки SQL. Можно перефразировать: если бы SQL не было, другие части системы не претерпели бы существенных архитектурных изменений.
А преимущество SQL очевидно — простой язык, который всем понятен, и через который можно прозрачно интегрироваться с огромным количеством систем.

gojanki
17.05.2017 23:08У меня кейс — есть большой объем данных в оперативной памяти и я хочу запустить новый .NET код на этих данных, так вот, Ignite ругнулся, что класс должен присутствовать в сборке. Пробовал около месяца назад.
То есть получается, что нельзя один раз поднять данные в память, потом компилировать новый код и запускать на данных в гриде. Необходимо после каждой компиляции перезапускать грид.
Планируется ли какое-то решение? Насколько я понимаю в Java такая возможность в GridGain есть.
Спасибо.devozerov
17.05.2017 23:34+2Если это данные в кэше, то подкладывать классы в общем случае не требуется. Если же это исполняемый код (map-reduce, closures, services), то требуется. Сейчас идет работа над описанной вами фичей для Ignite.NET [1], и в каком-то виде она с очень большой вероятностью появится в версии 2.1 в середине июня.
Но скажу прямо, у нас пока остаются неразрешенные вопросы по дизайну этого функционала. Поэтому в первой версии мы скорее всего будем просить ограничиться ее использованием в девелопменте, но не в продакшене. Ключевая проблема — выгрузка динамически подгруженных assembly. Пока решения — один AppDomen, не выгружаем assembly вообще, либо же много доменов. К обоим вариантам есть очевидные замечания. Будем думать дальше. Если хотите — подключайтесь к обсуждению в JIRA.
[1] https://issues.apache.org/jira/browse/IGNITE-2492
proponent
18.05.2017 11:07+1Есть ли (или планируется ли) в Ignite поддержка DataFrames? Мы сейчас активно экспериментируем с GraphFrames и было бы интересно попробовать улучшить перформансе, сохранив граф в интайте-кэше.
kefirr
18.05.2017 11:10Для Spark есть вот такая интеграция: Shared Apache Spark RDDs
Если нужно просто положить инстансы
DataFrameв кэш — с этим не должно быть проблем.proponent
18.05.2017 12:01+1Нет, вопрос, скорее, не просто про сохранение инстансев, а именно про "прозрачную" поддержу API DataFrames.
Как я вижу, Spark Shared RDD использует свой собственный тип IgniteRDD, а значит просто передать его на вход GraphFrames не получится, придется сначала создать DataFrames. Похоже, вот тут (https://issues.apache.org/jira/browse/IGNITE-3084) обсуждается тема поддержки DataFrames и, судя по статусу Unresolved, задача еще не реализована.
varnav
19.05.2017 13:12+1А чем он лучше Redis?
devozerov
19.05.2017 13:58+1Это совершенно разные продукты. Общее сравнение лучше-хуже не является корректным.
kefirr
20.05.2017 08:05-1Я бы не сказал, что это "совершенно разные продукты". Как раз таки в основе своей они одинаковые — распределённый кэш.
У Ignite богаче функционал самого кэша, и много других фич.
xonix
Советую в подобных статьях вот это "Самый простой и ёмкий ответ — это база данных. В основе которой — хранилище "ключ-значение"; грубо говоря, ConcurrentDictionary, в котором данные расположены на нескольких машинах." помещать в шапку. Жутко бесит когда сперва идет простыня о продукте, но даже не понятно о каком :)
В остальном, спасибо.