
А что, если вам дадут задачу организовать хранение и раздачу статических файлов? Наверняка многие подумают, что тут все просто. А если таких файлов миллиард, несколько сотен терабайт и запросов к ним несколько миллиардов в сутки? Также много разных систем будут отправлять на хранение файлы разных форматов и размеров. Этот квест уже не кажется таким простым. Под катом история о том, как мы решили такую задачу, какие сложности при этом возникли, и как мы их преодолели.
Avito развивался стремительно с первых дней. Например, скорость загрузки новых картинок для объявлений выросла в первые годы в несколько раз. Это требовало от нас на начальном этапе решать вопросы, связанные с архитектурой, максимально оперативно и эффективно, в условиях ограниченных ресурсов. Кроме того, мы всегда отдавали предпочтение простым решениям, требующим мало ресурсов на поддержку. Принцип KISS («Keep it short and simple») — это до сих пор одна из ценностей нашей компании.
Первые решения
Вопрос, как хранить и как отдавать картинки объявлений, возник сразу, так как возможность добавить фото к объявлению, безусловно, является ключевой для пользователей — покупатели хотят видеть то, что они покупают.
В то время Avito умещался менее чем на 10 серверах. Первым и самым быстрым решением было хранение файлов картинок в дереве каталогов на одном сервере и синхронизация по крону на резервный.
Путь до файла определялся исходя из уникального цифрового идентификатора картинок. Поначалу было два уровня вложенности по 100 директорий на каждом.

Со временем место на сервере стало подходить к концу, и с этим нужно было что-то делать. На этот раз мы выбрали использование сетевого хранилища, примонтированного на несколько серверов. Сетевое хранилище нам до этого в тестовом режиме предоставлял сам дата-центр, как услугу, и по нашим тестам-замерам на тот момент оно работало удовлетворительно. Но с ростом нагрузки оно стало тормозить. Оптимизация хранилища силами дата-центра не помогала кардинально и не всегда была оперативной. Наши возможности повлиять на то, как оптимизируют хранилище, были ограничены и мы не могли быть уверены, что возможности таких оптимизаций рано или поздно не исчерпаются. Парк серверов к тому времени у нас заметно увеличился и стал исчисляться десятками. Была предпринята попытка быстро поднять распределенный glusterfs. Однако он работал удовлетворительно только под небольшой нагрузкой. Как только выводили на полную мощность, кластер «разваливался», либо все запросы к нему «зависали». Попытки подстроить его не увенчались успехом
Мы поняли, что нам нужно что-то другое. Были определены требования к новой системе хранения:
- максимально простая
- построенная из простых и проверенных компонентов
- не отнимающая много ресурсов на поддержку
- максимально возможный и простой контроль за тем, что происходит
- хороший потенциал для масштабирования
- очень быстрые сроки реализации и миграции с текущего решения
- допустима недоступность части картинок на время ремонта сервера (серверы нам чинили более-менее оперативно)
- допускается потеря небольшой части картинок в случае полного уничтожения одного из серверов. Надо сказать, что за все время существования Avito такого ни разу не было. 3*Тьфу.
Новая схема
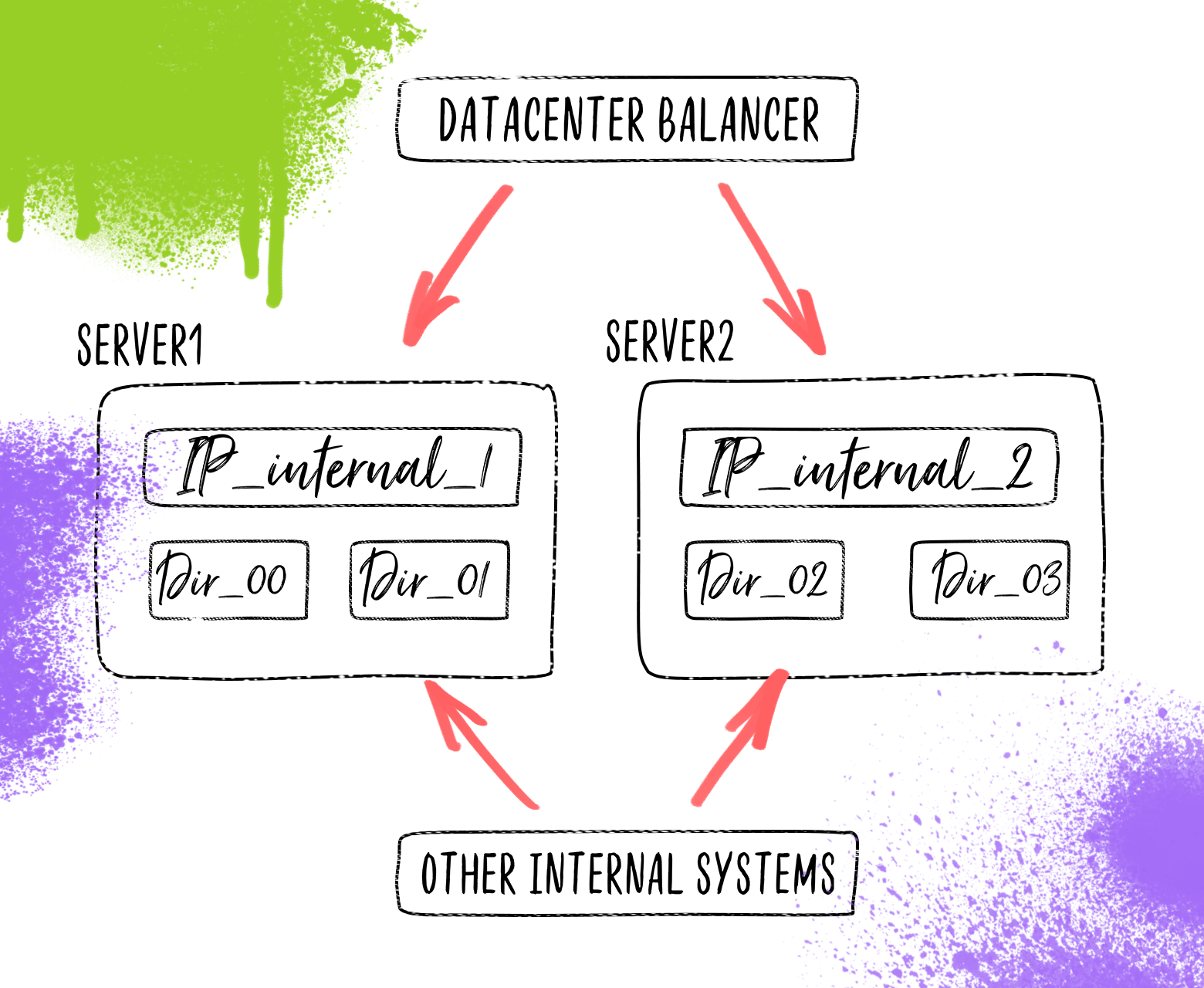
На изображении для упрощения показаны только четыре ноды на двух серверах.
В ходе обсуждения пришли к такой схеме. Файлы будут храниться в таком же дереве каталогов, но каталоги верхнего уровня распределены по группе серверов. Нужно сказать, что к тому времени у нас скопились сервера с одинаковой дисковой конфигурацией, диски на которых «простаивали». Отдаются файлы все тем же nginx. На каждом сервере подняты IP, которые соответствуют определенной директории верхнего уровня, находящейся на сервере. На тот момент мы не задумывались о балансировке трафика, так как за нас это делал дата-центр. Логика балансировки была в том, что в зависимости от домена, на который пришел запрос (всего было 100 доменов) отправлять запрос на внутренний IP, который уже был на нужном сервере.
Возник вопрос, как же код сайта будет загружать картинки в хранилище, если оно к тому же распределено по разным серверам. Логично было использовать тот же http протокол, по которому файл и пришел к нам от пользователя. Начали искать, что мы можем использовать в качестве сервиса, который будет принимать файлы на стороне сервера, который хранит файлы. Взор упал на открытый модуль nginx для аплоада файла. Однако, в ходе его изучения выяснилось, что логика его работы не укладывается в нашу схему. Но ведь это open source, а у нас есть опыт программирования на С. В течение недолгого времени, в перерывах между другими задачами, модуль был доработан и теперь, работая в составе nginx, принимал файлы и сохранял их в нужную директорию. Забегая вперед, скажу, что в процессе работы в production выявилась утечка памяти, которую на первых порах лечили перезапуском по ночам, а после, когда было время, нашли причину и исправили.
Нагрузки растут
Со временем мы стали использовать это хранилище не только для картинок, но и для других статических файлов, гибко настраивая с помощью nginx параметры, влияющие на производительность и доступ к файлам.
По мере роста количества запросов и объема данных мы сталкивались (а иногда и предвидели заранее) с рядом проблем, которые в условиях высоких нагрузок требовали принятия быстрых и эффективных решений.
Одной из таких проблем стала балансировка, которую нам предоставлял дата-центр, на F5 Viprion load balancer. Мы решили убрать его из пути обработки трафика с помощью выделения 100 внешних IP (по одному на каждую ноду). Так мы убрали узкое место, ускорили доставку данных и повысили надежность.
Количество файлов в одной директории все возрастало, что влекло за собой замедление компонентов из-за увеличившегося времени чтения содержимого директорий. В ответ мы добавили еще один уровень из 100 директорий. Мы получили 100^3 = 1M директорий на каждую ноду хранения и возросшую общую скорость работы.
Мы очень много экспериментировали с оптимальной настройкой nginx и параметров дискового кэша. По той картине, что мы наблюдали, у нас было впечатление, что дисковый кэш не дает полной отдачи от кеширования, а кеширование с nginx в tmpfs работает лучше, но очистка его кэша заметно нагружает систему в пиковые часы. Первым делом мы включили логирование запросов nginx в файл и написали свой демон, который поздно вечером считывал этот файл, очищал его, выявлял наиболее актуальные файлы, и очищал из кэша остальные. Таким образом мы ограничили очистку кэша ночным периодом, когда нагрузка на систему не велика. Это работало вполне успешно какой-то период, до определенного уровня нагрузки. Построение статистики и очистка кэша перестали укладываться в ночной интервал, к тому же было видно, что место на дисках в скором будущем подойдет к концу.
Решили организовать второй уровень хранения данных, аналогичный первому, но с некоторым отличиями:
- раз в 50 больше размер дисковой подсистемы на каждом сервере; при этом скорость дисков может быть меньше.
- на порядок меньшее количество серверов
- внешний доступ к файлам возможен только посредством проксирования через первый уровень
Это дало нам возможности:
- более гибко настраивать параметры кэширования
- использовать более дешевое оборудование для хранения основной части данных
- еще проще масштабировать систему в будущем
Однако это потребовало некоторого усложнения конфигурации системы и кода по загрузке новых файлов в систему хранения.
На схеме ниже показано, как могут размещаться две ноды хранилища (00 и 01) на двух уровнях хранения, используя один сервер на первом уровне и один на втором. Понятно, что можно размещать разное количество нод на сервере, и кол-во серверов на каждом уровне хранения может быть от одного до ста. Все ноды и серверы на схеме не показаны для упрощения.

На изображении для упрощения показаны только две ноды на двух серверах
Вывод
Что мы получили в итоге? Систему хранения статических файлов, в которой может без труда разобраться специалист среднего уровня, построенную на надежных, проверенных открытых элементах, которые при необходимости можно заменить или доработать небольшой ценой. При этом система может выдавать пользователям десятки PB данных в сутки и хранить сотни терабайт данных.
Минусы тоже есть. Например, отсутствие репликации данных, полной защищенности от отказа оборудования. И хотя первоначально, при проектировании системы, это было сразу определено и согласовано в соответствии с оценкой рисков, мы имеем набор дополнительных средств, которые позволяют нивелировать эти минусы (система бэкапов, скрипты для тестирования, восстановления, синхронизации, перемещения и т.п.)
В дальнейших планах добавить возможность гибко настраивать репликацию для части файлов, скорее всего через некую отложенную очередь.
Я сознательно не углублялся в детали реализации, логики работы (о кое-чем совсем не сказано), нюансы настройки, чтобы не затягивать статью и донести главную мысль: если хотите построить хорошую крепкую систему, то одним из правильных путей может быть использование открытых проверенных продуктов, связанных в относительно простую и надежную схему. Нормально делай, нормально будет!
Комментарии (67)

ilyaplot
16.05.2017 14:11-3Странный у вас подход. Мне кажется, что картинка в объявлении важнее, чем все остальное. А вы совершенно не боитесь их потерять.

zver_tmn
16.05.2017 14:23+5Вы правда думаете чем все остальное? Даже чем например данные о балансах пользователей?
Мы не боимся их потерять потому что у нас есть система бэкапов. Перед созданием системы возможные риски были оценены и согласованы. Я об этом упоминал в статье.

thelongrunsmoke
16.05.2017 18:43+3Картинка в объявлении — короткоживущий ресурс. Вероятность потери за месяц-два востребованности исчезающе мала.
nerudo
16.05.2017 14:21+5Вот уж воистину полный kiss — невозможность фильтрации даже по цене, не говоря уж о более сложных фильтрах просто убивает. Меня до сих пор удивляет как с таким сервисом компания оказалась практически монополистом. Чудо, что к разделу недвижимости карту прикрутили…
Pakos
17.05.2017 10:44+1Мне довелось увидеть раздел "работа" в самом начале (со стороны поиска кандидатов) — вот где мрак был, большинство объявлений с темой "ищу работу" и таким же содержанием. Как говорится, шортее и симплее некуда, выделить что-то осмысленное или отфильтровать не представлялось возможным.

NINeOneone
17.05.2017 12:09+2Фильтрация вообще ужасная. Пытался там бу авто поискать — плюнул на второй минуте и ушел на auto.ru.

Acuna
23.05.2017 18:44Не ожидал, что будет возможность оставить отзывы прямо на Хабре) Отправлял письмо со списком пожеланий, уж благодарили-благодарили, но безрезультатно, что было бы, вообще-то, намного большей благодарностью. В том числе помню, что лично для меня просто принципиален поиск сразу на главной (кто бы мог подумать, правда?) ), а не через дополнительные клики по карте с выбором своего региона. И доходит до парадокса: приходится выбирать любой регион, а потом поиск осуществлять по всем. ибо я так и мотивировал свое предложение тем, что лично для меня регион практически никогда не принципиален. Например, винтажную аудиотехнику все-равно приходится искать по всей России, старые журналы все-равно в регионе отсутствуют. Да я хоть бритву могу в другом регионе заказать, если меня именно этот вариант устроит, все-равно пересылка почтой копеешная, а на время доставки соседний регион все-равно не влияет. Но нет. В итоге каждый раз захожу и прямо вымораживает это, и, если честно, желание пользоваться постепенно пропадает. Последний раз что-то покупал пол года назад, после этого даже не заходил ни разу, увы( Но кого это волнует, все-равно пользоваться же будут, ибо больше банально нечем, вот и я, проглатываю каждый раз просто, а что поделать? Хотя кроме разве что банального вообще не заходить. Буду рад, если коммент возымеет какое-либо действие, но верится с трудом уже…

daggert
24.05.2017 00:57Плюсую ваш отзыв. Тоже ищу как правило по всей России и ужасно не удобно каждый раз это делать.
Acuna
25.05.2017 06:58-1Благодарю за поддержку) Вообще, я уже давно понял, что секрет успеха любого продукта — пользование опытом Запада, который продвинулся далеко вперед во всех отношениях, что бы там не говорило бы РосТВ. Примеров куча: Яндекс-Гугл, Вконтакт-Фейсбук. Хотел вспомнить что-нибудь из разряда «Мерседес...», но понял, что идея провальна, так как страна слишком «крута» для этого. Что поделать, если нам дается только веб-разработка… Однако этим и нужно пользоваться, но если идти тут своим путем не оглядываясь ни на кого — мы будем иметь что имеем, как с тем же Авито, например, которым пользуются потому-что альтернативы просто нет. Это как с правительством… Ладно, что-то меня в политоту все тянет…

onyxmaster
16.05.2017 15:00+2А можете озвучить порядки количества объектов и их объёма (без избыточности)?
Например "~10^9 объектов, ~500ТБ чистого места".
Dmitry_4
16.05.2017 15:08+4И картиночки грузятся неспеша, секунды через две после загрузки объявления.
PS поиск, который считает товары похожими не по одинаковому описанию, а по схожести категорий и равной цене, писал м… к
martovskiy
18.05.2017 00:21Примеры PS пришлите.
Можно в личкуDmitry_4
18.05.2017 05:31+1например:
martovskiy
23.05.2017 12:59Это не совсем поиск.
Тут достаточно древний и тупой алгоритм, по поиску похожих.
В этом году планируется заменить его там, где он работает плохо на новый более умный вариант.
В старый алгоритм, внесли изменения, чтобы больше внимание было ключевым словам, в ближайшее время выкатим.
P.S. спасибо за фидбек.Acuna
23.05.2017 18:20Я, возможно, что-то не понимаю, однако что в этом алгоритме тупого? Как раз корректно ищет объявления с ошибками в написании (или в поисковом запросе). Во всяком случае насколько я это понял из скриншота ТС выше.

NickyX3
16.05.2017 15:09Я так понял — при потере сервера целиком «в мясо, кровь, кишки и т.п.» — вы смиряетесь с потерей части картинок?
zver_tmn
16.05.2017 15:44Да, в таком случае небольшая часть картинок что была создана после крайнего ежесуточного бэкапа и что не осела в промежуточных кешах будет утеряна.
Meridian2012
16.05.2017 16:01+6Приятно, когда такой вещи, как картинки, уделятся должное внимание.
Осталось пожелать разработчикам, чтобы они обратили внимание на функционал, отличающий анонимную барахолку от серьезного торгового посредника. Методы мошенничества на Авито уже вошли в легенду, в то время как наши западные (Ebay) и восточные (Ali) партнеры успешно эти проблемы решают — валидация, отзывы, рейтинги и т.д.Ugrum
16.05.2017 16:53+7Методы мошенничества на Авито уже вошли в легенду
О дааа, особо доставляет, что 8-9 из 10 предложений в разделе «сдам жильё» следует читать, как: "ищу лохапредоставлю информационно-консультационные услуги по подбору жилья в аренду".
daggert
16.05.2017 16:55А как вы себе представляете вариант защиты, без финансового посредничества?

MMgo
16.05.2017 20:09Указанные примеры выше — это площадки, с полным циклом контроля (контроль доставки, платежей, споры, отзывы, итд)
И представляют они из себя совсем не доски объявлений, а вполне-себе площадки для электронной коммерции.daggert
16.05.2017 20:35Ну я это и имел ввиду — тут надо переделывать систему целиком. Хотя сейчас есть доставка авито и мне весьма нравится такой вектор развития.

nochkin
17.05.2017 06:41eBay ведь тоже не в первый день стал таким, каким он есть сейчас. Постепенно эти возможности начинаются появляться в зависимости от важности на данный момент.
Уверен, что и Авито к этому идёт.
EviGL
16.05.2017 21:03Авито писался не по идее Ebay, а по идее Craigslist. И тут уж сложно упрекнуть Авито в скорости развития, на Craigslist я вообще не уверен что изменилось со дня основания :)
Всё же целевая аудитория очень разная. Я никогда не пойду продавать свою микроволновку на Ebay: слишком много проверок, регистраций, ответственности, обязательство доставки и т.д.
Локальная доска объявлений это просто другой продукт, со своими плюсами и минусами.
Про методы мошенничества на Авито кстати предупреждают, с подробным описанием всех типичных, так что с проблемой работают.Meridian2012
17.05.2017 11:38Я про Craigslist вообще ничего не слышал. Как ни крути, Avito — лидер на российском рынке. И для ресурса, оцененного в конце 2015 года в $2,38 млрд., некоторые вещи смотрятся диковато и непростительно.
Если бы половину сил, затраченных на реализацию подсистемы хранения картинок (она мне нравится), направить на затыкание очевидных дыр в функционале, то результаты были бы впечатляющи. Но проблема картинок сама «стучалась в двери», ей решили.
Считаю текущий функционал Avito репутационным провалом. В 2015 году дваджы писал на compliance@avito.ru с предложениями — ни ответа, ни привета :)EviGL
17.05.2017 15:51+1Ну вот, а craigslist лидер на американском рынке. А теперь зайдите на сайт http://www.craigslist.com :)
Ну да ладно, развиваться всегда есть куда. Ну а по своему опыту понимаю, что у популярного ресурса нету возможности слушать все предложения всех пользователей.Meridian2012
17.05.2017 17:04+1Не думаю, что стоит приводить примеры по принципу «Есть гораздо хуже и ничего». Я могу привести пример американской компании с мировым именем по производству витаминов, в которой партионный учет продукции ведется на Excel, а учетная система написана 15 лет назад.
Если ресурс работает в России и стоит больше двух ярдов зеленых, то должен соответствовать определенному уровню функционала. Я по своему опыту знаю, насколько важно слушать все предложения всех пользователей и делать выводы.MMgo
18.05.2017 11:31Вы наверняка имеете список функций, отсутствие которых является «репутационным провалом»
Поделитесь пожалуйста.Meridian2012
18.05.2017 12:01Не вижу смысла здесь обсуждать такие вещи. IMHO, развернутое обсуждение здесь функционала — офф-топик. Я надеялся привлечь внимание людей, работающих в Авито, к этой проблеме. Если потребуется, я продублирую им свое письмо 2015 года с предложениями. Если для обсуждения этих вопросов будет предложена публичная площадка, с удовольствием там поучаствую и Вас приглашу.
Acuna
23.05.2017 18:29+1Считаю «репутационным провалом» отсутствие отзывов и защищенных транзакций через саму площадку, что, очевидно, является просто рассадником мошенничества, что, вне всяческих сомнений, несет откровенный репутационный урон.
Acuna
23.05.2017 18:26-1Вот-вот, тоже когда впервые зашел на Авито — был реально в шоке, узнав об отсутствии отзывов (!) и проведения платежей не через них (!!). На самом деле, я считаю, что это все проистекает из-за общей российской терпимости ко всему, когда просто при банальном отсутствии альтернатив приходится пользоваться чем есть и не жаловаться. А зачем, идти-то все-равно некуда( Это как со властью: что толку жаловаться, они что, возьмут и уйдут всей гурьбой при отсутствии замены? А менять сложно и дорого, да и зачем, все-равно пользоваться будут, ибо… (смотри по рекурсии).
adasoft
16.05.2017 17:00+1Интересная тема… раньше, когда требовалось хранить значительное количество бинарных данных, то использовали solid файл, где доступ к конкретной записи осуществлялся по смещению и размеру (можно закодировать хоть в имени файла). Конечно не было таких нагрузок, как у авито, но вопросы чтения, добавления (пишем в конец файла), бэкапа не стояли остро при полностью устраивающей нас производительности. Конечно, замена конкретного файла обходился дорого (или дырка в solid или пересборка всего файла), но эта операция (замена) была нужна чисто теоретически, так как «хранилось всё».

arachno
17.05.2017 06:23мое мнение сработает только на SSD при большом размере read buffer
в других случаях будет
1. слишком много перескоков по диску
2. кеш не будет знать что ему держать у себяadasoft
17.05.2017 07:20+12. кэш диска оперирует с файлами? так нет же, с блоками самого диска. С файлами работает кэш приложения
1. перескоков не больше, если не меньше, чем при чтении из файловой системы. К тому же солид контейнер можно создать заранее (в том числе разместив как RAW) избежав проблемы дефрагментации полностью.
Конечно имплементация может изменить многое, если не всё :)
Pakos
17.05.2017 10:51А что с безопасностью? Если я передам имя 0000 вместо 12345, то считаю что-то интересное? Или юзер не может повлиять на формирование имени "файла", доставаемого из хранилища?
adasoft
17.05.2017 11:14пользователь не имеет прямого доступа к контейнеру, только приложение-прокладка, которая транслирует запрашиваемый id картинки к серверу -> к контейнеру (может быть несколько, на разных дисках) -> к блоку данных (сразу несколько картинок, для помещения их в кэш) -> конкретная_картинка

perfect_genius
16.05.2017 17:40У вас количество подаваемых объявлений растёт, что не успевают удаляться старые, или старые вообще не удаляются?
zver_tmn
16.05.2017 19:59Скорость удаления ненужных картинок крайне мала по сравнению с добавлением новых.
perfect_genius
16.05.2017 20:16А сжимать сильнее, например в WebP?
zver_tmn
16.05.2017 21:28он не поддерживается рядом браузеров, к тому же AFAIR требует заметно больших ресурсов на сжатие.

majesty
16.05.2017 17:46Когда Ceph был не продакшн-рэди уже существовал как минимум Openstack Swift. Не самое быстрое, конечно, решение, но всё же. На дворе 2017 год и Ceph уже давно вполне годен для продакшна. Мы у себя решили похожую проблему как-то так https://www.youtube.com/watch?v=Y8JHEb1BkGQ
o_serega
17.05.2017 00:00Все хорошо, но вопрос: бэкапите ли вы данные из вашего ceph кластера (тут сразу вопрос куда)), если не бэкапите — то как собираетесь вытаскивать данные, когда кластер рассыпется.
majesty
17.05.2017 04:35Пишем параллельно асинхронной 2 ceph-кластера в разных ЦОДах и в AWS S3 в качестве бэкапа для «самого ужасного случая»
viiy
17.05.2017 06:25Вы шутите? Swift на питоне, хорошо если он на 2 порядка меньше нагрузку выдержит по сравнению с единичным nginx-ом. По Ceph, с одной стороны круто, с другой — его еще правильно приготовить надо, при всей его кажущейся простоте. При внимательном изучении простота пропадает мигом. А потом ловить такие баги, после которых придется весь кластер пересобирать, после недели бессонных ночей. Я наоборот хотел ребят похвалить — решение простое, не используются технологии которые явно не нужны (читающие наверное 3 раза шардирование смоделировали, редисом приправили и микросервисами). Технично, элегантно. Яркий пример как надо решать задачи, а не смотреть на модные технологии. Спасибо
majesty
17.05.2017 06:28Сравнивать object storage и веб-сервер… Okay…

tiandrey
17.05.2017 13:22+1Тут надо сравнивать не абстрактную функциональность разных решений, а их эффективность в решении конкретной задачи. Если Swift решает нашу задачу менее эффективно, чем nginx, то нам как бы по барабану, что он до кучи может ещё и крестиком вышивать.
majesty
17.05.2017 13:37Nginx не решает вашу задачу. Nginx — это фронтенд вашего объектного хранилища. Swift (либо Ceph) — это объектное хранилище, решающее задачи шардинга и репликации. И к нему тоже нужен фронтенд и тоже с кэшем и это тоже может быть nginx, либо что-то ещё, что хорошо ложится в инфраструктуру и решает задачу. Swift не будет и не может быть быстрее, поскольку это инструмент для совсем другой задачи. Зато там есть репликация, шардинга, отказоустойчивость.

astec
16.05.2017 18:03+1Посмотрите https://github.com/golang/groupcache — на golang от создателя LJ & memcached Brad Fitzpatrick.
Создавался для dl.google.com — задача чем то похожая на вашу.

kelevra
16.05.2017 20:10-1Надо сказать прямо, что сайт ваш по внешнему виду и функционалу выглядит таким же написанным студентами на коленке как и ваша «система хранения». Вариантов хранения и раздачи кучи редко меняющихся данных — вагон и маленькая тележка. Но нет, сэкономим и будем изобретать велосипед, это так типично для русского бизнеса.
zver_tmn
16.05.2017 21:13+4«Каждый мнит себя стратегом, видя бой со стороны» (с)
На самом деле в тексте статьи есть объяснение почему выбран такой вариант, попробуйте внимательней прочитать.
greenlogles
16.05.2017 21:13А вы не думали воспользоваться чем-то готовым типа GlusterFS (распределенный1 реплицируемый волюм)?
zver_tmn
16.05.2017 21:14+1Про это есть в статье.
greenlogles
16.05.2017 21:27Прошу прощения, не сразу заметил.
Последнее релизы более стабильные. Лично не замечал саморазваливания и зависания при стабильно работающем оборудовании. Вероятно вопрос в специфике работы приложения и нагрузокo_serega
17.05.2017 00:05У гластерфс, как и у любой фс спроектированной на основе DHT есть проблема, очень медленные операции по рекурсивному обходу каталога, помноженное на количество объектов в нем, ну и добьет его — мелкие файлы. Хотя, ситуацию с мелкими файлами, иногда, nfs доступ сглаживает, но не сильно. У меня на одном месте работы был самописный модуль nginx работающий через libgfapi.

el777
17.05.2017 01:24Вопрос: рассматривали вариант использовать S3 как хранилище и свой набор машин как кеш для отдачи?
Мы у себя реализовали похожую схему — только вместо S3 использовали свою наработку, которая размещается ближе и работает лучше.
Работает отлично, масштабируется только в путь. При необходимости, можно легко сделать модификацию картинок — уменьшение, обрезка и пр.
2PAE
17.05.2017 07:12Вот кстати вопрос. У вас каждая картинка имеет уникальное имя? Или же он привязаны к объявлению?
adasoft
17.05.2017 11:16насколько я помню из попыток парсинга авито id картинки привязано к объявлению через внутрение структуры системы, недоступные конечному пользователю. Т.е. из урла картинки получить само объявление у меня не получилось, хотя может только у меня.


batment
Не считали, насколько выгоднее такое решение получается, чем, допустим, Amazon S3? С учетом разработки и поддержки, конечно же.
zver_tmn
Точно не просчитывали, но зависимость от внешних систем как правило не несет в себе ничего хорошего. Использовали Amazon S3 для других задач в самом начале, помню что результаты по скорости нас не радовали.
MMgo
Конкретно AmazonS3 для РФ не сильно подходит.
onyxmaster
На мой взгляд, основная проблема с S3 и прочими подобными системами это цена egress-трафика.
Даже с контрактными условиями под NDA (я его, к счастью, не подписывал, хотя и предлагали), которые составляют около 60% при 400+ТБ egress в месяц, это слишком дорого. Просто (относительно конструирования своего хранилища), да, но дорого.
Есть конечно промежуточное решение — пара/тройка кэширующих серверов в локальном ДЦ, но тут эффективность кэширования сильно зависит от типа сайта. У нас 1:8-1:10, но у того же Avito может быть совершенно другое соотношение.