Каждого представляет Джеральд Брофловски, адвокат из Саус Парка, который рассчитывает получить неплохую комиссию. Противоположную сторону каждого представляет… Джеральд Брофловски! Кажется, папу Кайла ждут нехилые бабосы независимо от исхода дела.
South Park, серия 306, «Панда—сексуальное домогательство»
Smug Alert!
Не так давно наши коллеги рассказали на конференции HighLoad++ о решении задачи балансировки нагрузки в облаках Google и Amazon, а также DNS-балансировки с использованием сервиса gdnsd. Это отличное введение в тему, с которым стоит познакомиться всем, кого жизнь уже заставила завести несколько фронтендов. И практическое руководство, если вы вынуждены иметь дело с облачным хостингом.
К счастью, бывают случаи, когда вы можете позволить себе удовольствие работать с реальным оборудованием, а не с облаками. Автор этих строк обожает реальное оборудование и готов часами рассказывать про его плюсы:
- Вас не грабят на трафике. Погигабайтная оплата трафика — любимая статья доходов облачных систем, избалованных вниманием стартапов. Жизнь «железных» провайдеров проходит в жесточайшей конкуренции за более прижимистого потребителя, и для них нормально предлагать большой пакет трафика бесплатно. Есть и «пакетные» облака, такие как Linode, однако в них вы будете ограничены мощностью предлагаемых инстансов и, скорее всего, с грустью обнаружите, что для постройки мало-мальски серьёзного сервиса они вам нужны в огромных количествах — и, таким образом, облако возьмёт с вас за трафик другим способом.
- Вы можете предсказуемо докупать серверы. Например, описание лимитов AWS занимает три десятка страниц A4. Внезапно натыкаясь на каждый лимит, вы будете доказывать Амазону потребность в его увеличении, а Амазон будет решать, достойны ли вы этого. Челобитные мелких клиентов рассматриваются минимум 3 дня, чаще — неделю. Тем временем лучшие dedicated-провайдеры предоставляют железо сразу или на следующий день, их волнует только ваша аккуратность в оплате счетов и законопослушность.
- Жизнь на «железе» заставляет вас использовать проверенный open source, а не фирменные сервисы с загадочными свойствами, которые вы не можете изменить, если они плохи, или починить, если они сломались. Эта проблема отлично раскрыта в двух последних разделах упомянутого доклада.
- Некоторые штуки вообще нормально работают только на тщательно подобранном оборудовании. Хорошим примером является наша любимая СУБД Aerospike. Количество проблем с ней прямо пропорционально возрасту SSD-дисков, поэтому мы не просто требуем настоящие железные SSD, но ещё и совершенно новые. А переход на интерфейсы NVMe там, где это возможно, поднял наше аэроспайководческое хозяйство в экзосферу, снизив нагрузку впятеро. Пользователи Aerospike в облаках в этом месте могут только грустно улыбнуться и пойти передёргивать кластер, который опять рассыпался.
Многие dedicated-провайдеры научились объединять серверы в виртуальные сети, и расширение ферм в них не представляет проблемы. Популярное исключение — Hetzner, где по-прежнему нужно резервировать юниты и планировать место, но я надеюсь, что он тоже разродится умной коммутацией. А вот с балансировкой дела обстоят хуже.
Там, где вообще есть смысл обсуждать с провайдером балансировку, вам предложат современного потомка чего-то такого:

Железо это штучное, стоить оно будет, разумеется, оскорбительных денег, а для конфигурирования требовать специальных знаний.
И тут самое время вспомнить, что…
Chef, что у нас сегодня на обед?
Ваши фермы наверняка уже работают с применением одного из средств автоматизации, а это значит, что массовые изменения дёшевы. А в качестве HTTP-фронтенда с большой вероятностью используется nginx на тех же серверах, что и обслуживают приложение. Это позволяет легко построить схему балансировки «каждый с каждым» — каждый сервер будет балансером, и он же захостит приложение, отвечающее на запрос.
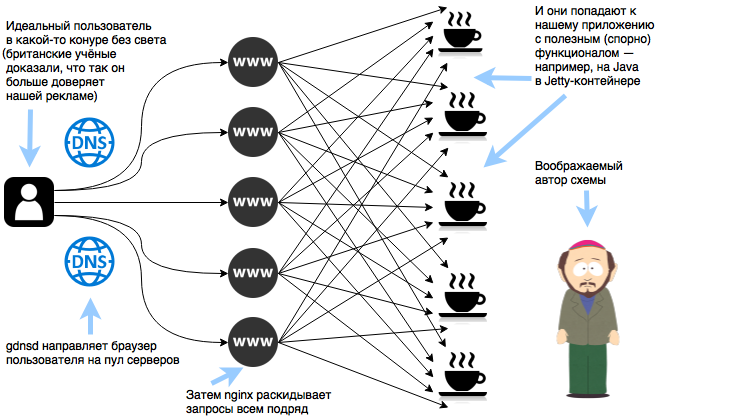
Конфигурируем пул серверов в gdnsd:
; Проверяем отдельно написанной командой, жив ли
; сервер с таким IP-адресом
service_types => {
adserver => {
plugin => extmon,
cmd => ["/usr/local/bin/check-adserver-node-for-gdnsd", "%%IPADDR%%"]
down_thresh => 4, ; Не ответил 4 раза на тест? Этот сервер лежит.
ok_thresh => 1, ; Хоть раз ответил нормально? Жив!
interval => 20, ; Проверяем каждые 20 секунд
timeout => 5, ; Тупку более 5 секунд считаем отсутствием ответа
} ; adserver
} ; service_types
plugins => {
multifo => {
; Если живы менее 1/3 хостов, то DNS будет возвращать весь список
; серверов, потому что явно происхоит что-то не то — например, общая
; перегрузка приложения, и отключение «сломанных» только усугубляет
; ситуацию
up_thresh => 0.3,
adserver-eu => {
service_types => adserver,
www1-de => 192.168.93.1,
www2-de => 192.168.93.2,
www3-de => 192.168.93.3,
www4-de => 192.168.93.4,
www5-de => 192.168.93.5,
} ; adserver-eu
} ; multifo
} ; pluginsИспользуем полученную конфигурацию в файле DNS-зоны:
eu.adserver.sample. 60 DYNA multifo!adserver-euДелаем для nginx пул серверов и раскатываем конфигурацию по ферме:
upstream adserver-eu {
server localhost:8080 max_fails=5 fail_timeout=5s;
server www1-de.adserver.sample:8080 max_fails=5 fail_timeout=5s;
server www2-de.adserver.sample:8080 max_fails=5 fail_timeout=5s;
server www3-de.adserver.sample:8080 max_fails=5 fail_timeout=5s;
server www4-de.adserver.sample:8080 max_fails=5 fail_timeout=5s;
server www5-de.adserver.sample:8080 max_fails=5 fail_timeout=5s;
keepalive 1000;
}Если в ротации больше 25 серверов, не забудьте разбить их на группы по 25 штук под единым именем и динамически выбирать в gdnsd синонимы (DYNC) вместо A-записей.
Список серверов при желании можно заполнять автоматически по данным gdnsd или системы автоматизации. Например, у нас в компании используется puppet, и специальный крон-скрипт поддерживает в актуальном состоянии списки серверов разных типов, зарегистрированных на пуппетмастере. Строка с localhost защищает от ситуации, когда список окажется пустым из-за ошибки — в этом случае каждый nginx будет обслуживать только свой фронтенд и катастрофы не произойдёт.
Зажигаем, пацаны, зажигаем!
Итак, что получилось:
- Великолепная отказоустойчивость. Риски сводятся к сетевым (это решается распределением приложения по нескольким регионам с независимым электропитанием и сетью) и конфигурационным (никто не мешает вам запулить в конфигурацию nginx или gdnsd изменение, которое быстро всё сломает — и рецепты борьбы с этим тоже известны).
- Проблемы «прогрева» пула и проблемы недостатка мощностей не существует. Ваше веб-приложение гарантированно умрёт от нагрузки первым.
- Равномерный расход трафика и распределение сетевой нагрузки. Принять 5 Гбит/с трафика на 10 серверов с гигабитом? Нет проблем, только не забудьте увести трафик между балансерами и приложениями во внутреннюю сеть, а также убедиться, что провайдер не продаёт вам на эти 10 серверов коммутатор с 1 Гбит/с общего аплинка в интернет.
- «Плавные» деплои. При использовании только DNS-балансировки мы сталкивались с тем, что многим нашим партнёрам (SSP) «рвало крышу» поочерёдное пропадание наших серверов из пула. Ситуация осложнялась тем, что наши Java-приложения при инициализации подгружают в память массу необходимых им данных и это занимает время. Перекрёстная балансировка позволила сделать процесс практически незаметным для другой стороны.
Обида мистера Прутика
За бесплатную балансировку нужно платить, и жертвой являются sticky-сессии. Тем не менее, бесплатный вариант nginx предлагает балансировку по хешам IP, а современные NoSQL-базы, такие как Aerospike, могут быть использованы как надёжное общее хранилище сессий с быстрым временем ответа, которое вы можете использовать в своих приложениях. Наконец, можно, хоть это и непатриотично, перейти на HAProxy, который умеет маршрутизовать пользователей на нескольких балансерах по единому правилу. В общем, когда нам понадобятся sticky-сессии, мы будем бороться за них имеющимися средствами.
Цифры
Сейчас каждый из наших 20-ядерных серверов обрабатывает до 15 000 запросов в секунду, что близко к практическому потолку нашего Java-приложения. По всем кластерам мы балансируем и обрабатываем в пике больше полумиллиона запросов в секунду, 5 Гбит/с входящего и 4 Гбит/с исходящего трафика, за исключением CDN. Да, специфика DSP — это превышение входящего над исходящим, аукционных предложений значительно больше, чем содержательных ответов на них.
Автор статьи — igors
Комментарии (16)

chemistmail
19.05.2017 08:37Сколько ядер терминируют трафик из htts в http, на 15000 запросов в секунду?
У меня на 15k запросов входящего трафика получается 200 — 250 Мбит/с.
Трафик тоже бид реквесты.
igors
19.05.2017 16:29Возможно, дело в сжатии? Некоторые SSP и, например, обменник BidSwitch умеют присылать сжатый POST. Мы используем сжатие там, где оно поддерживается. http/2 тоже экономит трафик несколькими способами.
По ядрам — раньше мы никак не распределяли их между nginx и Java, а потом обнаружили, что если выдать nginx четверть всех ядер и включить worker_cpu_affinity, результат будет лучше. Но в целом наше узкое место не https, а логика.chemistmail
19.05.2017 19:06Логика это понятно, у меня на тоже самое количество запросов java потребляет порядка 12 аналогичных ядер, еще 6 уходит на терминацию. Так что по большому счету цифры выходят аналогичные.

kt97679
19.05.2017 18:03У вас в конфиге написано:
down_thresh => 4,; Не ответил 4 раза на тест? Этот сервер лежит.
ok_thresh => 1,; Хоть раз ответил нормально? Жив!
interval => 20,; Проверяем каждые 20 секунд
timeout => 5,; Тупку более 5 секунд считаем отсутствием ответа
Правильно ли я понимаю, что если балансировочный nginx падает gdnsd от 20 до 40 секунд будет продолжать направлять на него запросы?igors
19.05.2017 20:37Да, и в жизни всё ещё хуже — DNS-ресолвер закеширует ответ, и сам клиент тоже. При переездах видно, что остатки трафика продолжают капать на старое место ещё целыми днями, несмотря на TTL меньше минуты.
Но сейчас практически все браузеры умеют перебирать пул и искать в нём работающие веб-серверы, так что ничего страшного не будет даже в случае тупого round robin.

miolini
24.05.2017 05:43Если ложится один из серверов, то клиенты какое-то время не смогут получать сервис, обращаясь к его публичному IP из кэша DNS. Это время легко может достигать 24ч, особенно если упавший сервер заменен новым с иным IP.
igors
24.05.2017 20:42Как я уже написал выше, механизм client retry решает проблему во всех современных браузерах. Вот чувак оттестировал всё, до чего дотянулся: https://blog.engelke.com/tag/client-retry/
А почему именно 24 часа?
dcheklov
24.05.2017 15:07Отличная статья, хорошо, когда коллеги по цеху делятся опытом. Есть пару вопросов:
1. Вы пишите про использование Aerospike на NVMe дисках. У вас при этом гибридная схема хранения? Просто если все в RAM, то не понятно, какой прирост дает NVM?
2. Как синхронизируете Aerospike в разных локациях: родную синхронизацию или еще как?igors
24.05.2017 20:541. Да, смысл Аэроспайка в том, чтобы использовать дешёвый SSD вместо дорогой оперативки, которая при больших объёмах начинает стоить совершенно неразумных денег. RTB это данные о пользователях, и это десятки терабайт.
Переход с простых SSD на NVMe SSD снизил нам load average впятеро. А с Редиса на Аэроспайк мы переезжали, когда альтернативой было взять сервер с 256 GB RAM.
2. Не синхронизируем — считаем, что в США и России у нас разные пользовательские базы, и гоняться за пользователем не надо. Вряд ли он в Штатах захочет пойти в Юлмарт за новым айфоном. :-)dcheklov
25.05.2017 13:31А есть информация по тому, какой rps и на каком датасете дает оптимальные результаты при работе с NVMe на одном сервере. Объясню, в нашем случае, когда работаем с RAM, мы вообще не паримся с количеством инстансов, ограничение по сути — это слоты оперативной памяти, и мы ни разу не упирались в rps, запас по нагрузке в десятки раз больше, чем есть.
igors
25.05.2017 20:19NVMe у нас есть только в Германии, где Hetzner даёт его на базе «бытовых» материнок (PX61-NVMe). В США, где нормальные серверы, на NVMe интересных цен не получается. Текущие цифры такие: кластер из 4 серверов работает с 2 ТБ данных, над которыми делает 2К чтений, 15К записей, выполняет 30К UDFs и 25K batch reads. У нас довольно развесистые UDF, скрывающие несколько операций, поэтому прикидка довольно условная.
robert_ayrapetyan
А сколько всего ядер в сумме трудится над 5гбит/с?
igors
Сервер на расчётные 15К/сек — это 2 x E5-2630v4, то есть 20 ядер, принимает он 100 и отдаёт 80 Мбит/с. То есть 1000 ядер должно хватить. Ну, у нас где-то 800.
Наша специфика — bid requests, это очень мелкие сетевые пакеты. Нормального трафика можно обработать в несколько раз больше.
Как в любом живом проекте, это война со множеством переменных:
— нам нужно стараться не превышать 25 ТБ на сервер — дальше трафик не сильно, но платный, и выгоднее добирать серверы
— поэтому, когда мы приближаемся к красной отметке, находим фиксированные куски и утаскиваем на CDN — трафик снижается
— а в это время разработка делает новые фичи и усложняет логику — QPS и трафик на сервер ещё снижается
— чтобы это поправить, логику в Java оптимизируем и утаскиваем в user-defined functions в Aerospike — трафик растёт
— но впадают в задумчивость аэроспайки — теперь настало время усиливать их ферму.
Ну и так далее.
robert_ayrapetyan
Хм, спасибо. У нас просто аналогичные 5Гб\с и ДСП\ССП, но все на С++ и в разы меньше ядер поэтому…
Не думали о переезде на колокейшн?
igors
У нас сейчас 4 локации. На восточном побережье США, например, мы сменили за 2 года 3 хостинговые компании и 5 серверных платформ. Вот вырастем раз в 100, стабилизируем софт, и тогда обязательно окопаемся. :-)
robert_ayrapetyan
Очень знакомы все эти метания… Аналогично сменили 3 хостинга, но за 5 лет )