
В этой, третьей по счету, статье о создании GraphQL сервера с graphql-php я расскажу о том как бороться с проблемой N+1 запросов.
Предисловие
Я продолжу изменять код, полученный по окончании предыдущей статьи. Также его можно посмотреть в репозитории статьи на Github. Если вы еще не читали предыдущие статьи, то рекомендую ознакомиться с ними прежде чем продолжать.
Также я закомментирую две строки в graphql.php, добавляющие ограничение на максимальную глубину и сложность запроса, так как при разработке они не очень нужны, а могут лишь вызывать проблемы отладки:
// DocumentValidator::addRule('QueryComplexity', new QueryComplexity(6));
// DocumentValidator::addRule('QueryDepth', new QueryDepth(1));Проблема N+1 запросов
Проблема
Легче всего объяснить в чем заключается проблема N+1 запросов на примере. Допустим вам надо запросить список статей и их авторов. Не долго думая можно сделать это так:
$articles = DB::table('articles')->get();
foreach ($articles as &$article) {
$article->author = DB::table('users')->where('id', $article->author_id)->first();
}Как правило
DB::table('articles')->get() в итоге посылает в базу данных один, примерно такой, запрос:SELECT * FROM articles;И затем в цикле отправляется еще N запросов в БД:
SELECT * FROM users WHERE id = 1;
SELECT * FROM users WHERE id = 2;
SELECT * FROM users WHERE id = 3;
SELECT * FROM users WHERE id = 4;
SELECT * FROM users WHERE id = 5;
...
SELECT * FROM users WHERE id = N;Где N — количество полученных в первом запросе статей.
Например мы выполняем один запрос, который возвращает нам 100 статей, и затем для каждой статьи мы выполняем еще по одному запросу автора. В сумме получается 100+1=101 запрос. Это является лишней нагрузкой на сервер БД и называется проблемой N+1 запросов.
Решение
Самый распространенный метод решения этой проблемы — это группировка запросов.
Если переписать тот же пример используя группировку запросов, то мы получим примерно такой код:
$articles = DB::table('articles')->get();
$authors_ids = get_authors_ids($articles);
$authors = DB::table('users')->whereIn('id', $authors_ids)->get();
foreach ($articles as &$article) {
$article->author = search_author_by_id($authors, $article->author_id);
}То есть мы делаем следующее:
- Запрашиваем массив статей
- Запоминаем id всех авторов данных статей
- Запрашиваем массив пользователей по этим id
- Вставляем авторов в статьи из массива пользователей
При этом, сколько бы статей мы ни запросили, в БД отправится всего два запроса:
SELECT * FROM articles;
SELECT * FROM users WHERE id IN (1, 2, 3, 4, 5, ..., N);Проблема N+1 запросов в GraphQL
Теперь давайте вернемся к нашему GraphQL серверу в том состоянии, котором он находится после предыдущей статьи, и обратим внимание на то, как реализован запрос количества друзей пользователя.
Если мы запрашиваем список пользователей с указанием количества друзей каждого, то сначала GraphQL сервер запросит все записи из таблицы пользователей:
'allUsers' => [
'type' => Types::listOf(Types::user()),
'description' => 'Список пользователей',
'resolve' => function () {
return DB::select('SELECT * from users');
}
]А затем для каждого пользователя запросит у базы данных количество его друзей:
'countFriends' => [
'type' => Types::int(),
'description' => 'Количество друзей пользователя',
'resolve' => function ($root) {
return DB::affectingStatement("SELECT u.* FROM friendships f JOIN users u ON u.id = f.friend_id WHERE f.user_id = {$root->id}");
}
]Как раз тут и проявляется проблема N+1 запросов.
Чтобы решить эту проблему методом группировки запросов graphql-php предлагает нам откладывать выполнение ресолверов таких полей до тех пор, пока не будут получены значения всех остальных (не отложенных) полей.
Идея проста: вместо результата, функция «resolve» поля должна возвращать объект класса GraphQL\Deferred, в конструктор которого передается функция для получения того самого результата.
То есть теперь мы можем подключить класс Deferred:
use GraphQL\Deferred;И отложить выполнение, переписав ресолвер поля «countFriends» следующим образом:
'countFriends' => [
'type' => Types::int(),
'description' => 'Количество друзей пользователя',
'resolve' => function ($root) {
return new Deferred(function () use ($root) {
return DB::affectingStatement("SELECT u.* FROM friendships f JOIN users u ON u.id = f.friend_id WHERE f.user_id = {$root->id}");
});
}
]Но просто отложив выполнение запроса мы не решим проблему N+1. Поэтому нам надо создать буфер, который будет накапливать в себе id всех пользователей, для которых надо запросить количество друзей, и в дальнейшем сможет вернуть результаты по всем пользователям.
Для этого я создам небольшой класс, который будет иметь три простых статических метода:
add— Добавление id пользователя в буферload— Загрузка количества друзей из БД для всех пользователей в буфереget— Получение количества друзей пользователя из буфера
Этот класс вы также можете реализовать любым удобным вам способом, я лишь приведу его код для конкретного примера:
App/Buffer.php
<?php
namespace App;
/**
* Class Buffer
*
* Пример реализации буфера
*
* @package App
*/
class Buffer
{
/**
* Массив id пользователей
*
* @var array
*/
private static $ids = array();
/**
* Массив результатов запроса количества друзей для пользователей
*
* @var array
*/
private static $results = array();
/**
* Загрузка количества друзей из БД для всех пользователей в буфере
*/
public static function load()
{
// Если данные уже были получены, то ничего не делаем
if (!empty(self::$results)) return;
// Иначе получаем данные из БД и сохраняем в буфер
$rows = DB::select("SELECT u.id, COUNT(f.friend_id) AS count FROM users u LEFT JOIN friendships f ON f.user_id = u.id WHERE u.id IN (" . implode(',', self::$ids) . ") GROUP BY u.id");
foreach ($rows as $row) {
self::$results[$row->id] = $row->count;
}
}
/**
* Добавление id пользователя в буфер
*
* @param int $id
*/
public static function add($id)
{
// Если такой id уже есть в буфере, то не добавляем его
if (in_array($id, self::$ids)) return;
self::$ids[] = $id;
}
/**
* Получение количества друзей пользователя из буфера
*
* @param $id
* @return int
*/
public static function get($id)
{
if (!isset(self::$results[$id])) return null;
return self::$results[$id];
}
}Теперь подключим наш буфер в UserType.php:
use App\Buffer;И снова перепишем ресолвер для поля «countFriends»:
'countFriends' => [
'type' => Types::int(),
'description' => 'Количество друзей пользователя',
'resolve' => function ($root) {
// Добавляем id пользователя в буфер
Buffer::add($root->id);
return new Deferred(function () use ($root) {
// Загружаем результаты в буфер из БД (если они еще не были загружены)
Buffer::load();
// Получаем количество друзей пользователя из буфера
return Buffer::get($root->id);
});
}
],Готово. Теперь при выполнении запроса:

Количество друзей для всех пользователей будет получаться из базы данных только один раз. Причем запрос данных о количестве друзей будет выполняться всего один раз даже при таком запросе GraphQL:
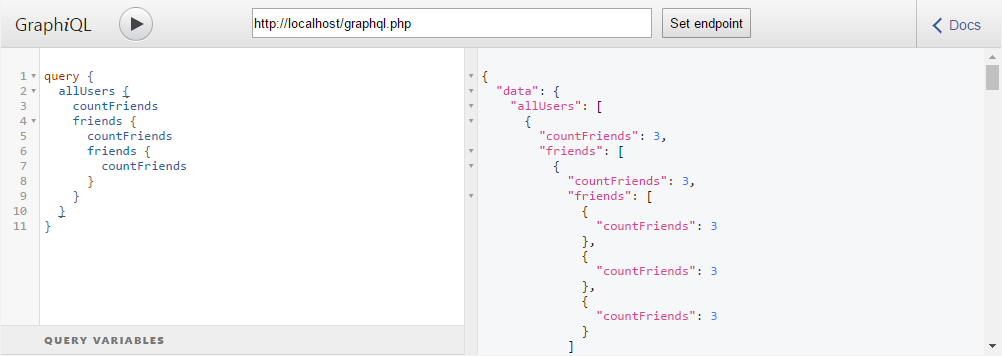
Конечно в таком виде наш буфер очень узкоспециализированный. Получается что для другого поля нам понадобится создавать другой буфер. Но это лишь пример и ничего не мешает нам сделать универсальный буфер, который, например, будет хранить данные для разных полей по их ключам, а также принимать в качестве аргумента функцию для получения результатов. При этом данные буфер может получать не только из БД, а еще от какого-нибудь API.
Заключение
На этом все. Предлагайте свои варианты решения подобных проблем и задавайте вопросы если они возникнут.
Исходный код из статьи на Github.
Другие части данной статьи:
- Установка, схема и запросы
- Мутации, переменные, валидация и безопасность
- Решение проблемы N+1 запросов
Поделиться с друзьями
SerafimArts
Т.к. вы используете
webonyx— четвёртым аргументом анонимочки оного идёт ResolveInfo объект, так что простым редьюсером по полям, которые возвращает$info->getFieldSelection()можно получить список всех релейшенов и полей отдельно, остаётся просто построить запрос, вида (т.к. судя по коду у вас Eloquent):DB::table('articles')->with($info->relations())->...и можно получить жадную связь на месте почти без лапши в коде.SerafimArts
С другой стороны можно воспользоваться подходом "единой точки входа", как делал у себя я и разбить связи на элементы корутины, делая что-то вроде:
ну к примеру… Тоже самое касается и аргументов типов.
XAHTEP26
Идея интересная, но к сожалению реализация мне не совсем понятна. Наверное мой уровень знания PHP недостаточно велик. ) Не могли бы вы привести пример использования данного класса? Или еще лучше было бы посмотреть код какого-либо проекта с использованием вашего подхода целиком, если такой есть в открытом доступе разумеется.
SerafimArts
Как раз этот пункт с подобными запросами в данный момент прорабатываю, так что привести пример будет проблематично, т.к. его просто нет. Но в целом, некоторое ядро с небольшим описанием готово. Не знаю что из этого может быть интересно, но вдруг: https://github.com/SerafimArts/Railgun (там есть неполная документация с примерами).
XAHTEP26
Спасибо.
Я смотрю у вас любопытная библиотека готовится. Буду следить. )
XAHTEP26
В данной статье я решил не использовать какой-либо конкретный фреймворк, поэтому то, что похоже на Eloquent скорее является псевдокодом и сделано так, чтобы на мой взгляд было проще понять проблему.
А вот уже на реальных проектах ваш совет будет очень полезен, про ResolveInfo я знаю, но таким образом его не использовал. Спасибо, возьму на вооружение. )
Kostiantyn
Попробую внести замечание:
А самый правильный — это JOIN двух таблиц — один запрос и оптимизатор СУБД сделает всю работу за Вас.
Я же надеюсь Вы с SQL Injection боретесь при помощи плейсхолдеров в запросе и передачи параметров отдельно, а не кучей HTML/XML/SQL-encode-ров над строкой в которую конкатенируете параметры от пользователя?
XAHTEP26
В двух предыдущих статьях я делал оговорку, что для простоты примера я не заморачиваюсь с безопасностью, в этой же решил не повторять ее в третий раз. И видимо зря. ) Разумеется на живом проекте так делать ни в коем случае нельзя.
Разумеется вы можете написать более сложный запрос в ресолвере поля «allUsers», добавив в него JOIN. И тогда вам даже не надо будет писать ресолвер для поля «countFriends».
Я же намеренно усложнил себе задачу, чтобы «искусственно» создать себе проблему, в которой можно будет рассказать про Deferred. Главное вы знаете что делать если в один запрос уложиться не получается, а все остальное в ваших руках.
Kostiantyn
ОК. Если была цель «сотворить искусственную проблему» что бы показать возможность другого инструмента или алгоритма- то тогда в учебно-демонстративных целях принимается ;)
menelion_elensule
Извините, может, я чего не понимаю, но почему не использовать подготовленный (prepared) запрос, который в цикле просто выполняется (execute) с параметром, соответствующим айдишнику статьи? правильности джоина это не отменяет, просто не понял, почему нет этого решения в статье :).
XAHTEP26
В качестве основы для статьи я взял код написанный в предыдущих частях статьи. И там все делалось примерно так как вы написали. В этой же статье я постарался изменить код, чтобы уменьшить количество запросов (количество выполнений execute). В цикле для запроса данных о 30 пользователях вы бы отправили 30 запросов, а после описанных мною манипуляций вы бы сделали это за 1 запрос.
А нужно это для того чтобы снизить нагрузку на сервер БД и уменьшить время выполнения. Так как выполнить 1 запрос быстрее чем 30.
shagrag
Спасибо за статью. Мы используем deffered вот так:
lokki7
Не сразу понял фразу «отлаживать выполнение ресолверов». Думал, это что-то связанное с отладкой. Пожалуйста, поменяйте на «откладывать»
XAHTEP26
Спасибо. Поправил и даже дополнил немного.