Предыстория
Уже много лет мы помогаем нашим клиентам отправлять потребителям хорошие, информативные и человеческие письма. В них вместо сухого “Добрый день” мы пишем “Здравствуйте, Никита!”, а вместо “Ваш баланс пополнился” сообщаем “вы получили 25 баллов”. Но маркетологи становятся все изобретательнее, и современное письмо от интернет-магазина должно выглядеть так:
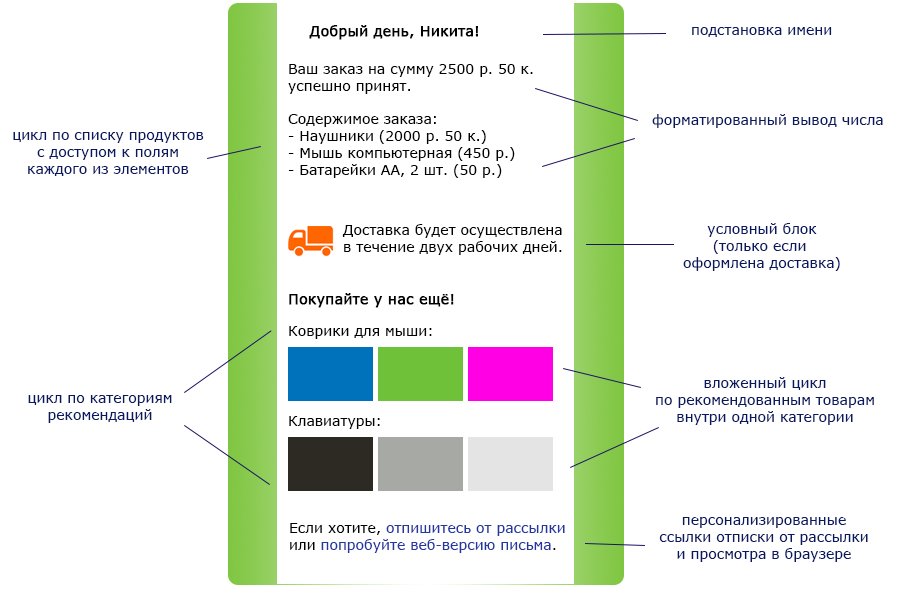
И мы хотим уметь генерировать такие письма автоматически.
Наш старый, проверенный временем шаблонный движок умеет вставлять в нужные места письма параметры, подставлять вместо отсутствующего значения что-то по умолчанию и писать “1 рубль, 2 рубля, 5 рублей”, причем делает это хорошо. Но он не предназначен для сложных ветвлений, циклов и любой другой сложной логики. Поэтому для формирования сложных писем как на картинке нам приходилось прибегать к коду на C#, и выглядело это так:

Мы оказались в не очень приятной вселенной, где желание клиента выделить курсивом слово в письме приводит к тикету на программиста и выкладке на продакшн. Мы в этой вселенной задерживаться не хотели, и стало понятно, что нам нужен новый шаблонный движок, который должен уметь:
- вывод простых параметров
- вывод сложных многоуровневых параметров (Recipient.Address.City.Name)
- условия
- циклы
- арифметические операции
И это только бизнес-требования, основанные на реальных сценариях. А поскольку мы хотим, чтобы при заведении рассылки менеджеру было легко заводить рассылки и сложно ошибиться, нам нужны еще:
- внятные сообщения об ошибках
- валидация используемых в шаблоне параметров
- расширяемость (возможность добавлять свои функции)
А поскольку мы иногда шлем миллионы писем в час, нам необходима хорошая производительность, а значит:
- прекомпиляция шаблона
- возможность переиспользования шаблона и потокобезопасность
Мы рассмотрели несколько доступных шаблонных движков, начиная Liquid и заканчивая Mustache, и все они немного со странностями. Кто-то при ошибке не падает с исключением, а просто рендерит пустую строку. Где-то синтаксис такой, что мы, будучи программистами, не смогли понять, как написать условие. Мы всерьез подошли к безумной идее использовать близкий и понятный нам Razor для формирования писем, но отказались от неё из-за досадной мелочи: получалось, что составитель шаблона рассылки мог выполнять произвольный .NET-код в процессе, отправляющем письмо.
И конечно же, в итоге мы решили написать свой шаблонный движок. Со статической типизацией и цепочками фильтров.
Дизайн языка
Практически сразу мы приняли решение отказаться от совместимости с чем-либо. Отказались от обратной совместимости с предыдущим шаблонным движком: синтаксис должен быть таким, чтобы можно было органично расширять язык пять лет в будущем, а не подстраиваться под то, что разработано за пять лет в прошлом. Отказались от совместимости с каким-то стандартом де-факто, по которому все верстают шаблоны писем: его просто нет. Мы оказались перед абсолютно белой доской, на которой нужно было нарисовать синтаксис нашего языка, и сразу начали придумывать себе рамки, в которых можно творить.
Во-первых, язык должен встраиваться в HTML, а значит, должен предусматривать escape-последовательности, отделяющие блоки нашего кода от остальной разметки.
Мы остановились на таком варианте:

Идея разделять выводящие инструкции ${ … } и не выводящие, служебные инструкции @{ … } навеяна имплицитными и эксплицитными выражениями из Razor. Попробовали посмотреть, как это будет выглядеть в реальной HTML-вёрстке, и да, так оказалось лучше и нагляднее.
Позже вспомнили, что такой же синтаксис используется в TypeScript для string interpolation (а в C# – другой, но тоже похожий). Стало приятно: если Андерс Хейлсберг посчитал это хорошим синтаксисом, то мы на верном пути.
Во-вторых, мы подумали, кто будет пользоваться нашим языком шаблонов. С большой вероятностью вёрстку письма будет делать верстальщик, которому близок и понятен javascript. С другой стороны, дорабатывать вёрстку по мелочам и править мелочи в логике скорее всего будет менеджер, который не знает javascript, но знает английский язык и здравый смысл. Поэтому наш синтаксис в итоге получился больше похож на Паскаль, с нормальными человеческими словами and, or, not вместо закорючек и амперсандов.
В итоге остановились на таком синтаксисе:

Осталось всего ничего: сдуть пыль с “книги дракона” и реализовать лексический разбор, синтаксический анализ, семантический анализ, а потом обеспечить генерацию выходного результата – письма.
Парсинг и ANTLR
Всем должно быть очевидно, что придуманный нами язык по классификации Хомского описывается контекстно-свободной LL-грамматикой, для разбора которой, соответственно, достаточно реализовать LL(*)-парсер. И тут же мы столкнулись с небольшой проблемой: мы почти ничего в этом не понимаем и не умеем.
Мы хорошо умеем делать сложный веб-фронтенд с большим количеством javascript, делать сложную серверную валидацию, работать с терабайтными базами данных и решать проблемы производительности и многопоточности в условиях тысяч транзакций в минуту. А вот языковые грамматики – не совсем наша компетенция. А на разработку шаблонного движка у нас в идеале две недели.
На этом месте мы пошли и ввели в гугле в строку поиска чит-код: ANTLR. Эффект не был мгновенным, но после пары дней, потраченных на чтение документации и эксперименты, мы получили такой прогресс, на который при ручной разработке ушло бы несколько недель. Итак, что такое Antlr и что он берет на себя?
ANTLR (ANother Tool for Language Recognition) – открытая библиотека, написанная Терренсом Парром, преподавателем университета Сан-Франциско и автором десятка с лишним научных статей о формальных грамматиках и их разборе. Её понемногу используют для задач парсинга ребята из Google, Oracle и Microsoft (например, в ASP.NET MVC). Antlr полностью берёт на себя лексический и синтаксический разбор текста, руководствуясь формальным описанием грамматики языка.
Конечно, не всё было безоблачно. При близком знакомстве Antlr оказался java-утилитой, которую нужно запускать из командной строки, пытаясь подобрать правильные аргументы из противоречащих друг другу статей документации, чтобы она сгенерировала C#-код, на который будет ругаться StyleCop. Документация нашлась, но не всё, что реализовано в утилите, описано в документации, и – вот это было ударом – не всё, что описано в документации (официальной книге от автора библиотеки) уже реализовано в утилите. Поддержка C# оказалось не такой полной, как поддержка Java, а из работающих вспомогательных инструментов мы нашли только плагин к эклипсу.
На всё это можно смело закрывать глаза, потому что после того, как мы заставили эту дурацкую штуку работать, мы получили код, который принимает поток с текстом, а возвращает полностью готовое синтаксическое дерево и классы для его обхода.
Мы не стали писать парсер шаблона и никогда не планируем этим заниматься в будущем. Мы описали грамматику языка, доверив Antlr решение скучных бытовых проблем, связанных с его парсингом, себе оставили интересные и неожиданные проблемы, связанные со всем остальным.
Грамматика языка: лексические правила
Описание грамматики ANTLR складывается из набора рекурсивных правил. Любому, кто на первом-втором курсе познакомился с БНФ, диаграммами Вирта или другими способами описания формальных языков, эта идея будет близка и понятна.
Точно так же нам близка идея максимального отделения лексического разбора от синтаксического анализа. Мы с радостью воспользовались возможностью разнести по разным файлам правила, определяющие терминалы и примитивные токены языка, от синтаксических правил, описывающих более сложные составные и высокоуровневые конструкции.
Взялись за правила лексера. Самая важная задача – сделать так, чтобы мы распознавали наш язык только внутри блоков ${ ... } и @{ .... }, а остальной текст письма оставляли неизменным. Иными словами, грамматика нашего языка – островная грамматика, где текст письма – неинтересный для нас “океан”, а вставки в фигурных скобках – интересные “острова”. Блок океана для нас абсолютно непрозрачен, мы хотим его видеть одним крупным токеном. В блоке острова мы хотим максимально конкретный и мелкий разбор.
К счастью, Antlr поддерживает островные грамматики из коробки благодаря механизму лексических режимов. Сформулировать правила, по которым мы делим текст на “океан” и “острова” было не совсем тривиально, но мы справились:

Эти правила переводят парсер в режим “внутри инструкции”. Их два, потому что ранее мы решили иметь немного различный синтаксис для управляющих инструкций и инструкций вывода.
В режиме “внутри инструкции” симметричное правило, которое при встрече с закрывающей фигурной скобкой возвращает парсер в основной режим.

Ключевые слова “popMode” и “pushMode” намекают нам, что есть у парсера есть стек режимов, и они могут быть вложенными с какой-то внушительной глубиной, но для нашей грамматики достаточно переходить из одного режима в другой и потом возвращаться обратно.
Осталось описать в “океане” правило, которое будет описывать всё остальное, весь текст, который не является входом в режим инструкций:

Это правило воспримет как Fluff (ерунда, шелуха, незначительный мусор) любую цепочку символов, не содержащую @ и $, либо ровно один символ $ или @. Цепочку токенов Fluff потом можно и нужно склеить в одну строковую константу.
Важно понимать, что лексер пытается применять правила максимально жадно, и если текущий символ удовлетворяет двум правилам, всегда будет выбрано правило, захватывающее наибольшее число следующих символов. Именно поэтому, когда в тексте встретится последовательность ${, лексер воспримет её как OutputInstructionStart, а не как два токена Fluff по одному символу.
Итак, мы научились находить “острова” нашей грамматики. Это стерильное и контролируемое пространство внутри шаблона, где мы решаем, что можно, а что нельзя, и что означает каждый символ. Для этого понадобятся другие лексические правила, которые работают внутри режима инструкции.
Мы не пишем компилятор Python и хотим разрешать ставить пробелы, табуляции и переносы строк везде, где это выглядит резонным. К счастью, и это тоже Antlr позволяет:

Такое правило, конечно же, может существовать только в режиме “острова”, чтобы мы не вырезали пробелы и переносы строк в тексте письма.
Остальное несложно: смотрим на утвержденный пример синтаксиса и методично описываем все лексемы, которые в нем встречаем, начиная с DIGIT

и заканчивая ключевыми словами (IF, ELSE, AND и другие):

Регистронезависимость выглядит страшновато, но в документации резонно написано, что лексический разбор – штука точная и подразумевающая максимально явное описание, и эвристике по определению регистра во всех алфавитах мира там не место. Мы не стали с этим спорить. Зато у нас else if воспринимается как один токен (что удобно), но при этом он не elsif и не elseif, как это бывает в некоторых языках.
Откуда-то из глубин воспоминаний о первом и втором курсе, растревоженных словами про БНФ и диаграммы Вирта, всплывает понимание, как описать IDENTIFIER так, чтобы идентификатор мог начинаться только с буквы:

Еще несколько десятков не самых сложных правил, и можно вынырнуть на уровень выше – в синтаксический разбор.
Грамматика языка: синтаксические правила
Структура любого письма в нашем шаблонизаторе проста и напоминает зебру: статические блоки вёрстки чередуются с динамическими. Статические блоки – это куски вёрстки с подстановкой параметров. Динамические – это циклы и ветвления. Мы описали эти основные блоки таким набором правил (приведен не полностью):

Синтаксические правила описываются таким же образом, как и лексические, но базируются они не на конкретных символах (терминалах), а на описанных нами лексемах (с большой буквы) или других синтаксических правилах (с маленькой буквы).
Разобрав текст этим набором правил, получили что-то подобное:
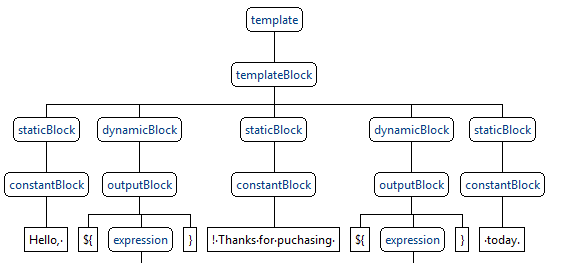
В статических и динамических блоках может быть набор инструкций произвольной сложности, начиная выводом одиночного параметра и заканчивая сложным ветвлением по результатам выполнения арифметических операций внутри цикла. Всего у нас получилось порядка 50 синтаксических правил такого вида:

Здесь мы описываем сложное условное высказывание, в котором обязателен блок if, может быть несколько блоков else if и может быть (но не обязательно) один блок else. В блоке If внутри знакомый нам templateBlock – тот самый, который может быть чем угодно, в том числе другим условием.
Где-то на этом месте наша грамматика начала быть по-настоящему рекурсивной, и стало жутковато. Поставив последнюю закрывающую фигурную скобку, мы сгенерировали при помощи ANTLR код парсера нашей грамматики, подключили его к нашему проекту и задумались, что со всем этим делать.
От дерева к дереву
Результат работы Antlr начиная с 4 версии – парсер, который превращает текст в так называемое concrete syntax tree, оно же парсерное дерево. Под concrete подразумевается, что дерево содержит в себе всю информацию о синтаксисе, каждое служебное слово, каждую фигурную скобку и запятую. Это полезное дерево, но не совсем то, которое нужно для наших задач. Основные его проблемы – слишком сильная связанность с синтаксисом языка (который неизбежно будет меняться) и совершенная неосведомленность о нашей предметной области. Поэтому мы решили обходить это дерево ровно один раз и строить на его основе своё дерево, которое ближе к abstract syntax tree и удобнее в дальнейшем использовании.
Требования к дереву такие:
- не должно содержать подробностей синтаксиса (нам важно, что идёт ветвление на три ветки, а слова
if,else ifиelseне интересны) - должно поддерживать все типовые сценарии обхода (рендеринг письма с подстановкой значений параметров, получение списка параметров и их типов)
Упрощенный интерфейс вершины нашего дерева в итоге выглядит примерно так (набор потомков и логика их обхода слишком разные для разных узлов, поэтому в общем интерфейсе их нет):
internal interface ITemplateNode
{
void PerformSemanticAnalysis(AnalysisContext context);
void Render(StringBuilder resultBuilder, RenderContext renderContext);
}Вдохновившись рассказами создателей Roslyn о красно-зелёных деревьях, решили, что наше дерево будет полностью immutable. Во-первых, с таким кодом просто удобнее и проще работать, не задаваясь вопросами о состоянии и последовательности изменений. Во-вторых, это самый простой способ обеспечить потокобезопасность, а значит – возможность использовать один прекомпилированный шаблон письма для отправки во многих потоках. В общем, красота, осталось его построить.
Обходить парсерное дерево, сгенерированное Antlr, предлагается при помощи паттерна Visitor. Сам Antlr предоставляет интерфейс визитора, а также базовую реализацию, которая обходит все вершины дерева в глубину, но ничего при этом не делает.
Конечно, есть вариант сделать один гигантский визитор, в котором будет реализован обход всех наших правил, которых вроде и не так много, а вроде как почти 50. Но гораздо удобнее оказалось описать несколько разных визиторов, задача каждого из которых – сконструировать одну вершину нашего результирующего дерева.
Например, для обхода условий внутри @{ if } … {else if } … {else } .. @{ end if } мы используем специальный визитор:
internal class ConditionsVisitor : QuokkaBaseVisitor<ConditionBlock>
{
public ConditionsVisitor(VisitingContext visitingContext)
: base(visitingContext)
{
}
public override ConditionBlock VisitIfCondition(QuokkaParser.IfConditionContext context)
{
return new ConditionBlock(
context.ifInstruction().booleanExpression().Accept(
new BooleanExpressionVisitor(visitingContext)),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
public override ConditionBlock VisitElseIfCondition(QuokkaParser.ElseIfConditionContext context)
{
return new ConditionBlock(
context.elseIfInstruction().booleanExpression().Accept(
new BooleanExpressionVisitor(visitingContext)),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
public override ConditionBlock VisitElseCondition(QuokkaParser.ElseConditionContext context)
{
return new ConditionBlock(
new TrueExpression(),
context.templateBlock()?.Accept(
new TemplateVisitor(visitingContext)));
}
}Он инкапсулирует в себе логику создания объекта ConditionBlock из фрагмента синтаксического дерева, описывающего ветку условного оператора. Поскольку внутри условия может быть произвольный кусок шаблона (грамматика-то рекурсивная), управление для разбора всего внутри снова передается универсальному визитору. Наши визиторы связаны рекурсивно примерно так же, как и правила граммматики.
На практике с такими маленькими визиторами легко и удобно работать: в них определен обход только тех элементов языка, которые мы ожидаем увидеть в каждом конкретном месте, а их работа заключается либо в инстанцировании новой вершины дерева, которое мы строим, либо в передаче управления другому визитору, который занимается более узкой задачей.

На этом же этапе мы избавляемся от некоторых неизбежных артефактов формальной грамматики, таких, как избыточные скобки, конъюнкции и дизъюнкции с одним аргументом и прочие вещи, необходимые для определения лево-рекурсивной грамматики и абсолютно ненужные для прикладных задач.
И в результате получаем из такого дерева
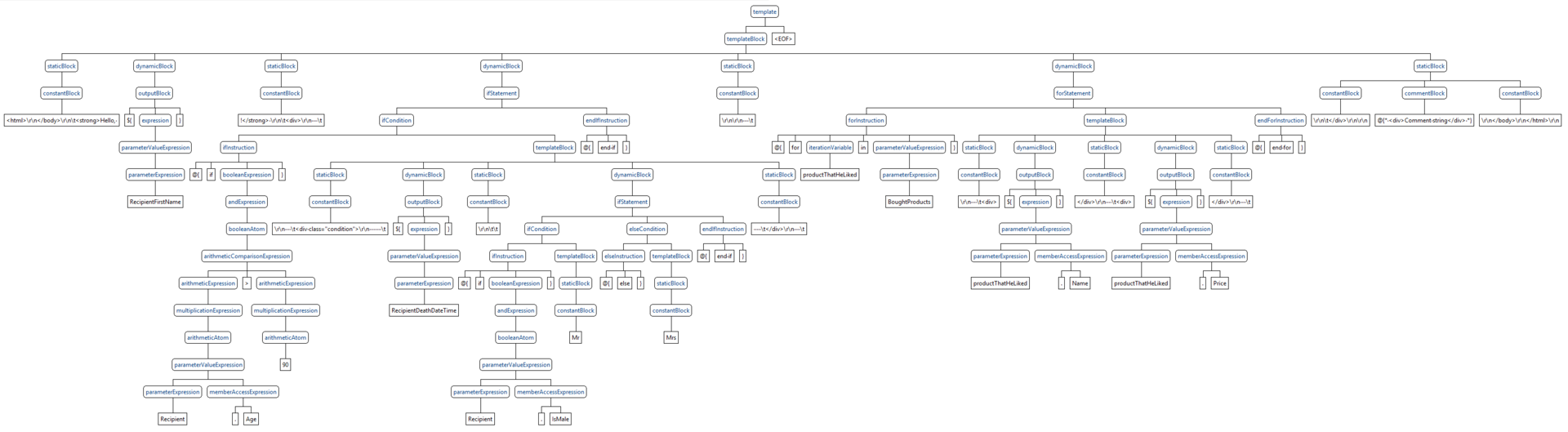
такое

Это дерево гораздо лучше укладывается в голове, не содержит бесполезной информации, его узлы инкапсулируют реализацию конкретных инструкций, и вообще с ним можно работать.
Осталось совсем немного – обойти его несколько раз. И первый, обязательный обход – это обход для семантического анализа.
Получение списка параметров и типизация
Одна из ключевых задач нашего шаблонизатора – умение найти в тексте письма все используемые в нем параметры. Цель понятна: валидировать и не давать сохранить шаблон, в котором встречаются параметры, которые мы не сможем подставить в письмо. Например, Recipient.Email мы знаем, а Recipietn.Eamil – нет. Для нас важно, чтобы отправитель узнал об ошибке в шаблоне сразу при его сохранении, а не при попытке отправить письмо.
Однако это не единственное направление валидации параметров. Хотим ли мы давать написать в письме ${ Recipient.Email + 5 }, зная, что Email у нас в системе – строковое поле? Кажется, нет. Значит, мы должны не только найти все параметры в письме, но и определить их тип. На этом месте мы обдумали типизацию и поняли, что она у нас статическая (что хорошо), но при этом неявная (что удобно пользователю, но неудобно нам). Ощутили мимолетный импульс заставить менеджера декларировать в начале письма все параметры явно, указывая тип. Удобство пользователя победило, импульс подавили. Придется определять тип “на лету” исходя из контекста.
Система типов нашего шаблонизатора выглядит так:
- примитивный тип
- целое число
- дробное число
- логическое значение
- дата-время
- составной тип, содержащий именованные свойства любого типа
- множественный тип (массив, коллекция, список, как угодно), содержащий несколько значений одного определенного типа
Подход к решению задачи простой: для того, чтобы определить тип параметра, входящего в письмо, достаточно найти все его использования в тексте и попытаться определить непротиворечивый тип, удовлетворяющий всем вхождениям или же сообщить об ошибке шаблона. На практике это оказалось не самой простой задачей с кучей особенных случаев, которые надо учесть.
Оказалось, что у переменных цикла есть область видимости. Оказалось, что бывают вложенные циклы по списку списков. Оказалось, что можно проходить в цикле по одному и тому же списку в двух разных местах в шаблоне, и обращаться там к разным полям элементов списка. В общем, понадобился крепкий статический анализ, над которым пришлось как следует подумать, а также несколько десятков юнит-тестов, но результатом мы довольны.

Глядя на этот шаблон, мы можем сказать, что у потребителя должен быть массив продуктов, а каждый продукт имеет цену и массив категорий, а у каждой категории должен быть как идентификатор Id, так и название Name. Теперь достаточно спросить нашу систему, есть ли в ней параметры такой структуры, и никаких сюрпризов при отправке не будет. Или почти никаких.
Рендеринг
Финальное испытание уже не казалось сложным: к моменту отрисовки текста письма у нас на руках вся структура шаблона, и достаточно просто еще раз обойти дерево, предоставляя каждому узлу возможность что-то записать в поток (или вернуть строку).
На практике же пришлось здесь решить еще порцию задачек по программированию для начинающих: булева логика, арифметические вычисления и сравнения, вложенные области определения переменных, приведение типов и обработка ошибок.
Могут ли быть ошибки при рендеринге письма, если мы потратили столько усилий на статическую типизацию параметров и валидацию шаблона еще до отправки письма? К сожалению, да:

Вывод такого значения приведет к ошибке, если B = 0. Заманчивая идея – усилить систему типов для таких случаев, но легко вообразить и такой сценарий, где всё совсем-совсем непредсказуемо:

Мы смирились с тем, что ситуация, когда конкретный набор параметров в письме приводит к ошибке рендеринга, не предотвращается статическим анализом, и стали выбирать между двумя вариантами:
- Иметь reasonable defaults (при выводе null-значения выводить пустую строку, при использовании в условии null-значения возвращать false, при делении на ноль работать с NaN и так далее)
- Соблюдать принцип fail fast
Решили так: отправить кривое письмо гораздо хуже, чем не отправить никакое вообще. Отправленное уже не вернешь, а не отправленное можно исправить и повторить. Поэтому fail fast, понятный, простой и без эвристик, нам подходит гораздо лучше.
Раз мы не боимся ошибок и неудач во время отрисовки письма, теперь можно допустить к этому процессу и других программистов. Можно вообразить несколько десятков полезных функций, которые как-либо преобразуют примитивные значения: вычисление каких-нибудь криптографических хэшей для подстановки в письмо, округления дробей, добавление параметров в ссылку. Львиную долю этих возможностей мы оставили за бортом шаблонизатора, чтобы пользователи библиотеки расширяли его снаружи. К счастью, это не сложно, а типы аргументов и возвращаемого значения строго типизированы:
internal class ToUpperTemplateFunction : ScalarTemplateFunction<string, string>
{
public ToUpperTemplateFunction()
: base(
"toUpper",
new StringFunctionArgument("string"))
{
}
public override string Invoke(string argument1)
{
return argument1.ToUpper(CultureInfo.CurrentCulture);
}
}Остаётся учесть мелкие детали: подставить уникальные ссылки для трекинга кликов и открытий, сгенерировать ссылки отписки и просмотра веб-версии письма, отвалидировать переданные параметры, и письмо готово к отправке.
Итоги
Приняв примерно сотню мелких и больших решений, мы наконец отрендерили своё первое письмо с циклами и условиями. Мы написали свой собственный шаблонный движок, практически с нуля, и в процессе поняли, что синдром Not invented here – плохо, но если правда не находится ничего, что удовлетворяет нашим требованиям, надо брать и делать своё.
Сейчас, отправив с его помощью несколько сотен миллионов сообщений и увидев, как наши менеджеры каждый день верстают письма в десятки раз сложнее, чем это казалось возможным, можно с уверенностью сказать, что он в итоге работает.
Как раз момент для того, чтобы проанализировать проделанную работу, сохранить куда-нибудь файл с несколькими сотнями доработок, которые хочется сделать, описать процесс в блоге и взяться за следующую задачу.
Ссылки:
Комментарии (56)
oxidmod
30.05.2017 14:08Долго думал спрашивать или нет, но все же, чем не устраивает Razor?

ivoninroman
30.05.2017 14:15Ответил здесь: https://habrahabr.ru/company/mindbox/blog/329772/#comment_10241078
oxidmod
30.05.2017 14:22Ну есть же альтернативы… Неужели не нашлось ничего стоящего?
ivoninroman
30.05.2017 14:34В статье есть немножко про исследование альтернатив, не нашлось.
Но если знаете какие-то движки, которые подходят под наши требования, скиньте обязательно, мне интересоoxidmod
30.05.2017 14:37+1Особо не вчитывался, но к примеру вот
Встраивается в html, приятный синтаксисivoninroman
30.05.2017 14:42+1Liquid рассматривали очень плотно, не понравился тем, что почти не поддерживается (видно по гитхабу) и, насколько помню, туго расширяется в тех местах, где нам надо.

Varim
30.05.2017 14:30исходники движка закрыты? имеет смысл делать статьи на технологии недоступные другим?
ivoninroman
30.05.2017 14:39Исходники закрыты на текущей момент, возможность открыть держим в уме, но это требует политических решений и дополнительной работы,.
Смысл статьи — показать процесс разработки крупной фичи от этапа сбора требований до выпуска в продакшн, немного познакомить с ANTLR и просто поделиться опытом. Думаю, кому-то точно может быть интересно.

michael_vostrikov
30.05.2017 15:07-1Вы придумали PHP?)
Нет, серьезно, не рассматривали такую возможность? PHP или PHP+Twig вполне бы подошел. Его тут даже не надо наружу выставлять, просто запускать консольное приложение с параметрами. И к базе он умеет коннектиться.
ivoninroman
30.05.2017 15:22+1Не совсем понятно, как это должно работать. Схема с межпроцессным взамодействием .NET-стека с PHP в условиях десятков тысяч операций в минуту кажется очень странной. В отличие от других альтернатив, которые тут озвучивали, эту мы реально даже не рассматривали.
michael_vostrikov
30.05.2017 16:27Ну что-нибудь типа такого:
sendOrderCompleteEmail(email, orderId) { html = executeCommand("php orderComplete.html orderId=" + orderId); sendEmail(email, html); // или так order = findOrder(orderId); stdinContent = jsonEncode(order); html = executeCommand("php orderComplete.html", stdinContent); sendEmail(email, html); }
Или демона поднять и данные через порт слать.
ivoninroman
30.05.2017 17:05Понимаю идею, но всё равно не могу пожалеть, что мы так не сделали. Впрочем, возможно, для каких-то задач это подходит, почему нет.
michael_vostrikov
30.05.2017 17:18Ок. Подскажите еще пожалуйста, как в шаблоне выглядит вывод словоформ (1 товар, 2 товара)? И можно ли задавать, экранировать или нет вывод тега
${}?ivoninroman
30.05.2017 17:32Словоформы — через функцию-расширение:
${ forms(ProductCount, 'Товар', 'Товара', 'Товаров') }
Настройкой экранирования не заморочились пока, поскольку
- крайне редкие последовательности в любом из известных видов текста (не случайно выбрано два символа, а не один)
- основной медиум — html, где доступно энкодирование через амперсанд-значения, если очень приспичит.
michael_vostrikov
30.05.2017 20:54Ну да, я про второе. То есть у вас при выводе значения переменной знаки "< >" автоматически заменяются на "
< >"? Или надо вручную функцию вызывать?ivoninroman
30.05.2017 22:49Автоматически html не экранируем, хотя концептуально хотим.
Одно из препятствий — наличие у клиентов старых рассылок, где, собственно, куски вёрстки подставляются параметром. Это не нравится и ставит под вопрос смысл шаблонизатора для этих рассылок, так что пытаемся это изжить.

hVostt
30.05.2017 15:24+1Не нужен тут PHP, движков под C# предостаточно. Также ребята получили опыт и в случае чего расширят свой шаблонизатор именно так, как им надо. Самый наихудший вариант это прикрутить для проекта на C# PHP, хуже что-то придумать сложно.

knekrasov
30.05.2017 16:00Ой, а я даже давным-давно делал парсер PHP как раз на ANTLR. Кстати, решал проблемы, схожие с описанными в статье. Если кому интересно — велкам.
ivoninroman
30.05.2017 17:02Прочитал, интересно, и боль знакомая местами прямо сквозит. Нам повезло в том плане, что сами придумывали грамматику и сразу в очень формальном виде, это свело неприятности на этапе общения с ANTLR к минимуму.

KvanTTT
30.05.2017 19:55+1Читал вашу статью. К сожалению, у вас грамматика была под ANTLR 3. Мы в Positive Technologies написали собственную под ANTLR 4 с более лаконичным синтаксисом, поддержкой островных конструкций, интерполяции строк, левой рекурсией. Хотя все равно не обошлось без вставок кода, т.к. язык сложен для обработки.
KvanTTT
30.05.2017 19:51+2Мы рассмотрели несколько доступных шаблонных движков
А StringTemplate рассматривали? Он тоже на ANTLR 4 построен, правда развивается не так активно, как хотелось бы.
При близком знакомстве Antlr оказался java-утилитой, которую нужно запускать из командной строки, пытаясь подобрать правильные аргументы из противоречащих друг другу статей документации, чтобы она сгенерировала C#-код, на который будет ругаться StyleCop.
Регистронезависимость выглядит страшновато, но в документации резонно написано, что лексический разбор – штука точная и подразумевающая максимально явное описаниеЯ бы рекомендовал все же использовать фрагментные лексемы, чтобы грамматика не выглядела так ужасно. Если язык полностью регистронезависимый, то лучше использовать свой регистронезависимый поток. Это описано в соответствующей секции в моей статей "Теория и практика парсинга исходников с помощью ANTLR и Roslyn". В ней описаны и другие полезные советы.
Конечно, есть вариант сделать один гигантский визитор, в котором будет реализован обход всех наших правил, которых вроде и не так много, а вроде как почти 50.
Можно использовать partial классы, и тогда гиганский визитор будет разделен на несколько файлов.
Но гораздо удобнее оказалось описать несколько разных визиторов, задача каждого из которых – сконструировать одну вершину нашего результирующего дерева.
А мы в Swiftify наоборот отказались от такого разбиения и пришли как раз к гиганскому визитору. Код упростился, а также избавился от лишних аллокаций других визиторов как у вас:
public override ConditionBlock VisitIfCondition(QuokkaParser.IfConditionContext context) { return new ConditionBlock( context.ifInstruction().booleanExpression().Accept( new BooleanExpressionVisitor(visitingContext)), context.templateBlock()?.Accept( new TemplateVisitor(visitingContext))); }
Кстати, один визитор получается и более детерминированным. У нас реализован интерфейс
IParserVisitorвместо абстрактного классаParserBaseVisitor, а поэтому в нем переопределены все методыVisit. Если известно, что метод никогда не вызывается, то внутри прописывается что-то типаthrow new ShouldNotBeVisitedException(context). А у вас, например, используется реализация по-умолчаниюVisitChildrenдля непереопределенных методов. Об этом можно почитать в другой моей статье.
А так вообще в целом статья понравилась. Welcome в наш репозиторий грамматик grammars-v4 :)
ivoninroman
30.05.2017 22:25+3Спасибо за комментарий, приятно обсудить всё это с кем-то предметно.
Я бы рекомендовал все же использовать фрагментные лексемы, чтобы грамматика не выглядела так ужасно. Если язык полностью регистронезависимый, то лучше использовать свой регистронезависимый поток
Регистронезависимый поток не нравится тем, что когда захочется вывести ошибку с именем переменной или, тем более, использовать строковую константу — они будут не в том виде, в котором написал автор шаблона. Собственно, как у вас и написано — сложно сделать выборочную регистронезависимость.
Насчет фрагментных лексических правил — тут, наверное, дело вкуса. Мне это кажется сильным усложнением, и на диаграммах выглядит страшненько, и вообще. Возможно, если бы было очень много буквенных лексем, стоило бы задуматься.
Код упростился, а также избавился от лишних аллокаций других визиторов как у вас
Ну, насчет аллокаций мы особо не паримся, потому что каждый инстанс визитора очень легковесный, а время его жини очень короткое, и даже при сложном дереве шаблона это всё абсолютно теряется на фоне кусков "payload" — собственно html-вёрстки, которая внутри блоков.
Да и в принципе вопрос перформанса на этапе компиляции шаблона для нас пока не стоит, потому что у нас режим работы "одна компиляция, миллионы рендеров".
А мы в Swiftify наоборот отказались от такого разбиения и пришли как раз к гиганскому визитору. Код упростился
Интересно! Но попробую отстоять свой подход:
- наши визиторы больше про single responsibility principle — согласитесь, что partial class это не совсем то
- один визитор не даёт возможности по-разному разбирать одно синтаксическое правило в разных контекстах (без введения какого-то состояния или обращения к parent разбираемого нода)
- пожалуй, самое важное — все методы визитора возвращают один тип. Это значит, что результат придётся рано или поздно кастить, а это, мы же понимаем, потенциальная ошибка в рантайме. В вашей статье так и написано —
var first = (Expression)VisitExpression(context.expression(0));. А у нас визитор, разбирающий выражения, возвращаетIExpression, визитор про вызову функций —FunctionCallExprsession. При этом никаких кастов не требуется, и неправильное использование визиторов просто не компилируется. Это, пожалуй, и есть ключевой принцип, по которому я решаю, отдельный это визитор или нет: какой тип он должен в итоге возвращать.
Про опасность
VisitChildren(равно как и дефолтногоAggregateResult) мы в курсе, это, пожалуй, самое неприятное поведение в базовой реализации. У меня есть желание в нашем базовом визиторе переопределить их, чтобы бросали исключение — тогда мы гарантируем, что всё. что есть в грамматике, покрыто набором визиторов. Пока руки не дошли.
Жалко, что вашей статьи не было на момент, когда писалась львиная доля описанного в статье, очень бы пригодилась при разработке. Про внутренний кэш antlr runtime, кстати, узнал только сейчас — очень любопытно. Попробую замерить эффект от него у нас на продакшне.
KvanTTT
30.05.2017 23:06Регистронезависимый поток не нравится тем, что когда захочется вывести ошибку с именем переменной или, тем более, использовать строковую константу — они будут не в том виде, в котором написал автор шаблона.
В ошибке то корректный регистр будет отображаться, не нормализованный. Смотрите комментарий в гисте CaseInsensitiveInputStream.java:
a case-insensitive lookahead stream causes the ANTLR lexer to behave as though the input contained only lowercase letters, but messaging and other getText() methods return data from the original input string.
Насчет фрагментных лексических правил — тут, наверное, дело вкуса. Мне это кажется сильным усложнением, и на диаграммах выглядит страшненько, и вообще.
На какой диаграмме? Почему усложнение? По-моему наоборот упрощение: нужно просто описать алфавит из 26 букв и использовать как-то так:
ABC: A B C. Фрагменты в лексере преобразуются в литералы, так что на уровне обработки вообще разницы не будет.
Да и в принципе вопрос перформанса на этапе компиляции шаблона для нас пока не стоит, потому что у нас режим работы "одна компиляция, миллионы рендеров".
Ну ок, просто у нас такой вопрос стоит — файлы могут быть очень большими, с глубокими рекурсивными выражениями (например, конкатенация). Как раз недавно оптимизировали как скорость парсера (обновили до ANTLR 4.6, упростили грамматики), так и скорость конвертера (убрали лишние аллокации, сделали мемоизацию).
наши визиторы больше про single responsibility principle — согласитесь, что partial class это не совсем то
Соглашусь. Однако мы от этого не страдаем)
один визитор не даёт возможности по-разному разбирать одно синтаксическое правило в разных контекстах (без введения какого-то состояния или обращения к parent разбираемого нода)
Тут я не очень понял. Да, можно использовать состояние, а можно передавать контекст у визиторов, в котором и будет состояние. Приведите пример, в котором в вашем случае состояние не будет использоваться, а в случае большого визитора — будет. И чем обращение к parent плохо?
пожалуй, самое важное — все методы визитора возвращают один тип. Это значит, что результат придётся рано или поздно кастить, а это, мы же понимаем, потенциальная ошибка в рантайме.
Да, этого иногда не хватает при одном визиторе. Хотя можно наверное как-то с помощью аннотаций или xml комментов сделать проверки. Ну т.е. если известно, что какой-то визитор возвращает всегда определенный тип, то обозначать это в комменте или аннотации, чтобы в других использующих его методах эта информация учитывалась.
Хотя в Swiftify данная проверка вообще оказалась не актуальной, потому в итоге для всех визиторов используется дефолтный визитор по-умолчанию
Visitor, в котором естьtry catchблок для обработки потенциальных ошибок.
У меня есть желание в нашем базовом визиторе переопределить их, чтобы бросали исключение — тогда мы гарантируем, что всё. что есть в грамматике, покрыто набором визиторов.
Правильно — если реализовать интерфейс, то так или иначе придется реализовать все методы
Visit.
Жалко, что вашей статьи не было на момент, когда писалась львиная доля описанного в статье, очень бы пригодилась при разработке.
Как это не было? Они уже примерно год существуют. Или статья писалась два года? :)
ivoninroman
30.05.2017 23:22+1Разработка движка — осень 2015-го, потом первые 90% статьи случились зимой 2016-го, потом "я включил Алдан и немножко поработал", и вот мы в весне 2017-го.
Тогда еще не было Antlr.Runtime как nuget-пакета, и приходилось его как dll подкладывать, книжка не совсем соответствовала реализации ANTLR 4.5, ну и по мелочи радости. И статей вроде вашей вот находилось гораздо меньше.
KvanTTT
31.05.2017 11:12Вроде NuGet версия существует с середины 2013 года: Antlr4.Runtime. А стабильная — с середины 2014. Это стандартный рантайм появился в конце 2016. Последний быстрее обновляется, но менее производительный.
ivoninroman
31.05.2017 11:30Вроде, NuGet тогда сильно запаздывал: antlr был уже 4.6, а пакет еще 4.5.x или что-то такое. Не самое важное, в общем, но точно помню, что не могли использовать пакет.
KvanTTT
31.05.2017 12:55Это да, он запаздывает, но зато стабильный. В ANTLR 4.6 появилась очень важная оптимизация, которая сокращает время парсинга до 100 раз для некоторых файлов с глубокой рекурсией.
ivoninroman
30.05.2017 23:55+2Про регистронезависимый стрим осознал, записал себе попробовать в пресловутовый список доработок, спасибо, полезно.
Тут я не очень понял. Да, можно использовать состояние, а можно передавать контекст у визиторов, в котором и будет состояние. Приведите пример, в котором в вашем случае состояние не будет использоваться, а в случае большого визитора — будет. И чем обращение к parent плохо?
Я называю этот паттерн
parent.parent.parent.parent, думаю, он каждому разработчику на WinForms/javascript знаком, как и удовольствие от поддержки такого кода. Это не совсем тот случай, но мне кажется идеологически правильным, чтобы разбор правила был контекстно-независимым, как и грамматика.
Сложно привести пример, не углубляясь в нашу специфику — скорее всего, не для каждой грамматики это актуально. Предположим, у нас есть правило, описывающее доступ к переменной, что-то вроде
variable { Identifier }. В зависимости от контекста это может быть логическим выражением (в конструкцииA and B) или арифметическим выражением (A + B). Удобно вArithmeticExpressionVisitorиBooleanExpressionVisitorиметь по правилу,VisitVariable, которые обернут использование переменных в соответствующие классы для работы с выражениями нужного типа.
Тут, наверное, всё упирается в специфику грамматики и использований результата разбора. Как минимум, наш подход тоже отлично работает и имеет плюсы. По ощущениям — очень понятно, атомарно и логично так работать (плюс за типизацию я сильно топлю, и generic-проверки на этапе компиляции котирую выше обработок исключений). Думаю, кому-то может эта идея пригодиться.
На какой диаграмме? Почему усложнение? По-моему наоборот упрощение: нужно просто описать алфавит из 26 букв и использовать как-то так: ABC: A B C. Фрагменты в лексере преобразуются в литералы, так что на уровне обработки вообще разницы не будет.
Мы генерируем синтаксические диаграммы как дополнительную документацию о грамматике, получается наглядно. Надо проверить, как это отразится на них, но почти уверен, что как-нибудь эти лишние кусочные псевдоправила и лишний уровень сложности в описании лексем будет виден. Если нет — прекрасно, но в любом случае, подход со стримом больше понравился.
KvanTTT
31.05.2017 11:08Про внутренний кэш antlr runtime, кстати, узнал только сейчас — очень любопытно. Попробую замерить эффект от него у нас на продакшне.
Кстати, по этому поводу рекомендую также обратить внимание и на подход, предложенный Sam Harwell (см.
issue на гитхабе). Я пока что не пробовал.
И в целом под C# существует два рантайма: Antlr4.Runtime и Antlr4.Runtime.Standard. Рекомендую использовать первый — он быстрее и автор (как раз Sam Harwell) вызывает больше доверия.
ivoninroman
31.05.2017 11:33Мы используем Standard, и вообще-то у него же владелец — сам создатель Antlr (https://www.nuget.org/profiles/parrt), куда еще больше доверия-то? Да и Харвеллд в авторах там тоже есть.
Я так понимаю, Харвелловский рантайм подходит, если использовать alternate C# target от него же, а мы исторически на стандартном.
Есть где-то почитать про сравнение таргетов? Это всегда интересовало, хотя сейчас уже, конечно, сложно представить мотивацию перейти с одного на другой.
KvanTTT
31.05.2017 12:54Он просто владелец, а не разработчик. Ну и к тому же он больше по Java рантайму. Разработчиком является ericvergnaud и с ним не всегда приятно общаться, а в рантайме было много ошибок. При переходе скорее всего ничего не изменится — мы в Swiftify перешли без проблем (используется для открытой грамматики Objective-C).
Про сравнение видимо пока нигде не почитать. :) Хотя можно попробовать поискать. Скорее всего если у вас небольшие файлы, то разницы не будет.
ivoninroman
30.05.2017 22:28StringTemplate прошёл под радарами, кажется, до начала собственной разработке. Но вообще, мы пришли к выводу, что статического разбора переменных из шаблона вообще нигде нет, и нужно своё делать. Сложность-то не в том, чтобы в строку параметры подставить.

Holms
31.05.2017 01:27+1Как насчет кода на гитхабе? Или не ожидается? :))
Я пока использую Razor, но то что вы написали мне понравилось, хотелось бы по использовать.
Спасибо
ivoninroman
31.05.2017 15:28Исходники на гитхабе, просто в приватном репозитории!
Если коротко — выход в опен-сорс это дополнительные затраты, и разовые, и фоновые. Вроде и клёво, а вроде и пока не готовы. Но смотрим в этом направлении.
Если будем опенсорсить — разумеется, напишем здесь
Holms
31.05.2017 20:30ну как вариант, можно мне получить доступ? буду бета тестером ))
ivoninroman
31.05.2017 20:49Приходите к нам работать, когда будем нанимать разработчиков, и это будет одним из приятных бонусов

caballero
31.05.2017 12:14Где-то синтаксис такой, что мы, будучи программистами, не смогли понять, как написать условие.
это про mustashe что ли? Ну попросили бы разобраться кого то из непрограмистов.
А если серьезно — формирую письма этим шаблонизатором — не вижу ни малейшей проблемы с ним.
ivoninroman
31.05.2017 13:57Да, про него! На самом деле, конечно, потом я разобрался. Но есть ощущение, что не зная хорошо синтаксиса и фиолософию, ничего в шаблоне по мелочи подправить/дополнить простому смертному нельзя.
caballero
31.05.2017 14:34там просто полностью декларативная разметка
как то ж смертные разбираются в таких декларативных штуках как например sql
ivoninroman
31.05.2017 15:26Смертные, когда нужно сделать что-то минимально сложное и из реальной жизни, в sql пишут
if exists () begin...
Я понимаю мысль, да. Но клиенты приходят и говорят "мы хотим иметь в письмах условия Если-Иначе, и циклы". Наш язык даёт им это в таких терминах, а Mustashe требует форматирования мозга для начала.
Но в любом случае, красота, понятность и прочие хараектеристики синтаксиса бесконечно далеки от объективности, так что тут спора интересного не выйдет.

AlexSys
31.05.2017 13:58Расскажите, пожалуйста, чем не подошел Mustache
ivoninroman
31.05.2017 13:58Инопланетный синтаксис и отсутствие возможности исследования параметров в шаблоне, как и везде

vba
31.05.2017 15:09А вы F# не рассматривали для этой задачи?
ivoninroman
31.05.2017 15:22В процессе, когда выработались паттерны, я понял, что F# подходит идеально примерно для 80% того, что надо написать!
Но факторы типа сжатых сроков разработки, отсутствия опыта написания enterprise-кода на F# и того, что у нас вся разработка на C#, победили, увы
kekekeks
Вообще говоря с Razor-ом можно было подружиться посредством верификации перечня подключенных к сборке типов по белому списку. Есть подозрение, что это было бы более простой задачей.
ivoninroman
Не нашли такой возможности, скиньте ссылку, если под рукой, интересно!
В любом случае, в разоре прилично всего напрягало, когда обсуждали решения. Во-первых, когда при написании вьюх возникает ошибка, мне иногда приходится ковыряться в исходниках MVC, чтобы понять, что имеется в виду. Во-вторых, если не изменяет память — он рендерил что-то с использованием то ли временного каталога на диске, то ли еще какой-то грязи. В-третьих — он всё-таки для программистов совсем.
По итогу просто было ощущение, что будем пытаться использовать инструмент для задачи, под которую он не заточен.
kekekeks
Берёте на выбор Mono.Cecil/dnlib/
System.Reflection.Metadataи загружаете полученную от Razor-а сборку. Дальше просто анализируете набор импортированых токенов типов и методов, ибо чтобы вызвать хоть что-то, нужно на него сначала сослаться, даже для работы dynamic нужен специальный набор типов и методов, которые можно в белый список не включать.Временный каталог Razor-у (старому, который не в ASP .NET Core) нужен для сохранения шарповых исходников, которые тот скармливает
csc.exeи полученных на выходе dll-ок. Они-то вам и нужны.ivoninroman
Я правильно понимаю, что каждому шаблону соответствует отдельная dll?
В принципе, звучит работоспособно, но:
А нового разора, когда анализировали существующие варианты, по-моему, вообще ещё не существовало.
В общем, не топлю за то, что однозначно Razor плохо, просто вот по совокупности много всем стало казаться, что слишком много "но".
aftertherainbow
https://github.com/Antaris/RazorEngine а на этот проект смотрели?
ivoninroman
Нет, впервые вижу такой. Возможно, изучили бы плотнее, хотя выглядит так, что многие проблемы Razor он в себя включает.
Писал в других комментариях: чуть ли не ключевой в итоге критерий, по которому решили писать своё — возможность обнаружения всех используемых параметров на этапе компиляции шаблона. Мы их валидируем на наличие в системе, соответствие типов и всё такое, и для нас это очень полезно.