
Как говорилось во всеми нами любимом фильме: «Налетай, торопись, покупай живопись». Последняя, конечно, тут ни при чем, а вот «налетать» на новую Бета версию компилятора уже пора. Сегодня я расскажу о том, что нового появилось в пакете Intel Parallel Studio XE 2018 Beta, и в частности, в компиляторной её составляющей. А там действительно много что добавилось, ведь стандарты не стоят на месте — C++14, C++17, Fortran 2008, 2015, OpenMP 4.5 и 5.0, а компилятор должен не только их поддерживать, но и генерировать совершенный, производительный и безопасный код. Кроме этого, новые наборы инструкций AVX512, позволяющие «снимать сливки» с последних процессоров Skylake и KNL, всё больше входят в арсенал современных компиляторов. Но а самое вкусное — новые ключи, которые позволяют получить ещё больше производительности «не напрягаясь». Итак, поехали!
Сразу скажу, что качать Beta версию можно здесь:
Intel Parallel Studio XE 2018 Pre-Beta survey
Всё, о чем я буду говорить, включено в эту версию компиляторов и Update 1, который очень скоро будет доступен. Что потом окажется в финальном продукте – вопрос сложный, но, «вангую», почти всё. Что же мы имеем в новой версии 18.0 Beta?
Безопасность кода
В Microsoft изо всех сил стараются противостоять хакерам и придумывают всё новые и новые технологии. Для начала, они сделали в своём компиляторе С++ дефолтным максимальный уровень защиты стэка через опцию /GS:strong, которая позволяет бороться с переполнением буфера. При этом делается это в ущерб производительности, но безопасность превыше всего. Так как Intel под Windows пытается быть полностью совместимым с компилятором от Microsoft, то начиная с новой версии мы тоже включаем /GS:strong по умолчанию. Ограничить её действие и немного улучшить производительность можно с помощью /GS:partial.
Кроме этого, идёт разработка новой технологии CET (Control-Flow Enforcement Technology), позволяющей бороться с атаками методом возвратно-ориентированного программирования (ROP и JOP-атаками). Одна из идей защиты состоит в том, что появляется ещё один защищенный shadow стэк, в который будет записываться/дублироваться адрес возврата. Когда мы доходим до возврата из функции, происходит проверка корректности возвращаемого процедурой адреса и того адреса, который мы положили в shadow стэк. Кроме этого, добавляется новая инструкция ENDBRANCH для того, чтобы обозначать области в программе, на которые можно делать непрямые переходы через call/jmp.
Реализован конечный автомат, и как только процессор обрабатывает одну из инструкций call/jmp, он переходит из состояния IDLE в WAIT_FOR_ENDBRANCH. Собственно, в этом состоянии следующая инструкция для выполнения должна быть ENDBRANCH. Гораздо больше деталей написано в указанной выше статье, а в компиляторах Intel для С/С++ и Fortran появилась поддержка CET через опцию -cf-protection. По умолчанию, она не включена и, естественно, может влиять на производительность при использовании.
Кто готов протестировать новую защиту? Важное замечание заключается в том, что для полноценной работы CET необходима поддержка ОС и RTL, а её пока нет.
Производительность
Теперь поговорим о новых опциях компиляторов, которые позволят сделать ваши приложения ещё быстрее и производительнее.
Есть такая компиляторная оптимизация, которая называется function splitting (разделение функций). Для того чтобы понять, зачем она нужна, стоить вспомнить про встраивание кода и то, что одним из эффектов является увеличение его размера. Поэтому inlining не имеет смысл при больших размерах самой функции, которую мы хотим встроить в место вызова. Именно в этих случаях разбиение функции и частичный inlining нам поможет не допустить чрезмерного увеличения размера кода, сохранив её плюсы. В итоге наша функция будет разбиваться на две части, одна из которых (hot) будет встроена, а другая (cold) – нет.
На самом деле, эта оптимизация уже долгое время присутствует в 32-битных компиляторах Intel для Windows, при использовании Profile-Guided Optimization (PGO). Вот, кстати, интересный пост про эту оптимизацию в gcc. Идея проста – скомпилировать наше приложение, сделав инструментацию, затем запустить его и собрать данные о том, как оно выполнялось (профиль), и, уже учитывая эти данные из рантайма, пересобрать код ещё раз, применив полученные знания для более мощной оптимизации.
Теперь понятно, почему с PGO было возможно использовать function splitting, ведь мы хорошо знаем для каждой функции, какая её часть сколько времени выполнялась и что нужно инлайнить.
Сейчас мы уже позволяем разработчикам контролировать эту оптимизацию «ручками», добавляя ключ -ffnsplit[=n] (Linux) или -Qfnsplit[=n] (Windows), который говорит компилятору, что нужно выполнять разбиение функции с вероятностью выполнения блоков равным n или меньше. При этом не важно, включено PGO или нет, но нам обязательно указывать этот параметр n. Если его не указать, то данная оптимизация будет выполняться только при наличии динамической информации от PGO. Значения n могут быть от 0 до 100, но наиболее интересные для нас находятся в первой половине. Скажем, при PGO и 32 битном компиляторе на Windows использовалось значение 5, означающее, что если вероятность выполнения менее 5%, то этот блок не будет инлайнииться.
Если мы заговорили про PGO, то обязательно стоит сказать, что и здесь в новой версии Студии произошли приятные изменения. Раньше эта оптимизация работала только с инструментацией, но теперь возможна работа с использованием сэмплирования из профилировщика VTune. К реализации такой фичи подтолкнула невозможность применения традиционного PGO на real time и embedded системах, где имеются ограничения на размер данных и кода, а инструментация могла его существенно увеличить. Кроме этого, на подобных системах невозможно выполнять I/O операции. Аппаратное сэмлирование из VTune позволяет существенно снизить накладные расходы при выполнении приложения, при этом не происходит увеличения использования памяти. Этот способ даёт статистические данные (при инструментации они точные), но при этом применим на системах, где традиционный PGO «буксует».
Схему работы с новым режимом PGO можно представить в виде диаграммы:
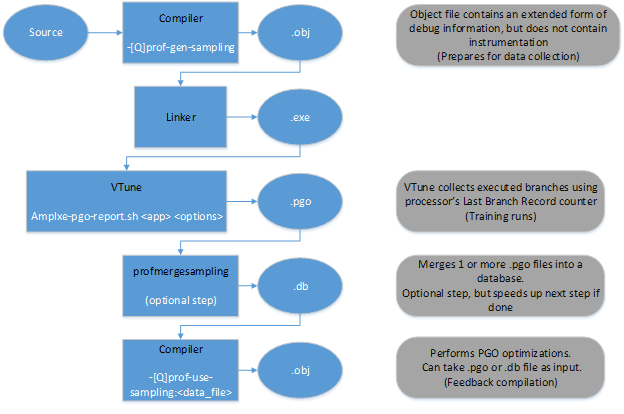
Как и прежде, нам нужно скомпилировать наш код для последующего сбора статистических данных. Только теперь это делается с помощью опции -prof-gen-sampling (Linux) или /Qprof-gen-samplig (Windows).
На выходе мы получим бинарники с расширенной дебаг информацией (что увеличит размер на допустимые 5-10%), но без инструментации. А далее нам понадобится специальный скрипт из VTune для запуска приложения и генерации профиля. После чего (если не нужно мержить несколько профилей), просто пересобираем наш код с полученными данными с ключиком -prof-use-sampling (Linux) или /Qprof-use-sampling (Windows). Для работы с этими опциями нам понадобится VTune, поэтому нужна установка не только компилятора, но и профилировщика. В Beta пакете имеется и то, и другое.
Теперь поговорим о работе с математическими функциями из библиотеки SVML (Short Vector Math Library), предоставляющей векторные аналоги скалярных математических функций.
Сразу несколько изменений коснулись SVML с выходом новой версии. Для того, чтобы убрать накладные расходы при динамическом диспатчинге, теперь на этапе компиляции будет генерироваться прямой вызов необходимой функции, используя заданные значения ключа -x. До этого мы в рантайме проверяли, какой у нас процессор, и вызывали нужную версию функции. И хотя overhead не является большим для обычных функций, при интенсивной работе с математическими функциями (например, экспонентой), он может составлять весомые 10%. Особенно востребованным это будет при вычислениях в финансовом сегменте приложений.
Тем не менее, если нам понадобиться вернуть «старое» поведение компилятора, то нам поможет опция -fimf-force-dynamic-target (Linux) или /Qimf-force-dynamic-target (Windows).
Из той же финансовой области пришло и другое изменение. При работе с математикой важна не только производительность, но и воспроизодимость результатов. Я уже писал о замечательных опциях, позволяющих заботиться об этом -fp-model (Linux) и /fp (Windows). Так вот задавая модель работы с числами с плавающей точкой как precise (-fp-model precise (Linux) или /fp:precise (Windows)), мы лишали себя удовльствия использовать векторные математические функции из SVML, что, конечно, отрицательно сказывалось на производительности, но весьма положительно на воспроизводимость результатов. Теперь разработчики позаботились о том, чтобы производительность не влияла на стабильность численных результатов. С помощью ключика -fimf-use-svml (Linux) или /Qimf-use-svml (Windows) можно сказать компилятору использовать скалярные функции из SVML вместо их вызовов из стандартной библиотеки LIBM. А так как они позаботились о том, чтобы скалярные и векторные версии SVML давали одинаковые результаты, то теперь и при использовании precise модели можно использовать векторные математические функции.
При работе с различными буферами используется большое количество функций, например memcpy, memset и т.д. При наличии их вызовов компилятор использует свою внутреннюю логику и может пойти различными путями: вызывать соответствующую библиотечную функцию, генерировать rep инструкции или развернуть операции в цикл при условии, что он знает размер во время компиляции. Так получилось, что он не всегда правильно угадывает нужный подход, поэтому теперь имеется опция -mstringop-strategy (Linux) или /Qstringop-strategy (Windows), с помощью которой можно сказать компилятору, что делать с такими функциям, работающими с буферами/строками (strings, отсюда и название ключика). Можно указать, соответственно, libcall, rep или const_size_loop в качестве аргумента для опции. Например при компиляции с ключом -Os (заботимся о размере наших бинарников), будет неявно использоваться опция -mstringop-strategy=rep.
Для более производительного кода на системах, поддерживающих AVX-512, появилась опция -opt-assume-safe-padding (Linux) или /Qopt-assume-safe-padding (Windows).
Она позволяет компилятору предполагать, что он может безопасно обращаться к 64 байтам после каждого массива или переменной, выделенной приложением. Ранее данная опция была доступна для KNC, теперь же её можно использовать и для последних архитектур с поддержкой AVX-512. В определённых случаях подобная «вольность» позволит компилятору сгенерировать немаскированные операции загрузки вместо маскированных, например, при использовании G2S (gather to shuffle) оптимизации. Но важно выравнивать данные по 64 байта.
Заключение
Это, пожалуй, наиболее важные из новых «волшебных» опций, которые появились в последней версии компилятора. Но кроме всего этого, была добавлена поддержка почти всего стандарта OpenMP 4.5 (нет только user defined reductions), а так же часть нового поколения OpenMP 5.0 (например, редукции в task’ах).
Стандарты С++11 и С++14 полностью поддерживаются ещё с версии 17.0, а вот полная поддержка Fortran 2008 появилась только сейчас. Да и последний стандарт С++17 будет поддерживаться гораздо в большем объёме, и это учитывая, что он ещё окончательно не принят.
В сухом остатке – мы имеем очередную версию компилятора, дающую нам ещё больше возможностей для оптимизации нашего кода и получения лучшей производительности и безопасности кода, при этом с широкой поддержкой самых последних стандартов. Айда тестить?
Поделиться с друзьями
kostus1974
у вас есть сравнение по gcc (с++) vs intel ps xe (тоже c++)? по той же скорости и компиляции, и исполнения скомпилированного в результате? не идеальные кони в вакууме для измерения, а нечто живое? ну, тот же майнинг. за какое время окупится приобретение вашего компилятора?
ivorobts
Да, это конечно важный вопрос. Показывать насколько хорош в плане производительности компилятор принято на общеизвестных тестах/бенчмарках. Так принято в индустрии. Эти тесты могут быть как «идеальными конями в вакууме», так и более сложными, приближенными к реальной жизни (они разные). Для С++ мы часто ориентируемся на SPEC, и в посте про прошлую версию 17.0 я давал данные по производительности на этой бенчмарке:

На конкретном железе и с данными версиям компилятора выигрыш был ощутимый (порядка 60% с Microsoft и 50 с GNU).
Для 18 версии данные тоже будут подготовлены позднее и, думается, сравнивать будем уже с 2017 версией.
Но если есть желание понять, какой будет прирост на именно вашем приложении (а это то, что обычно интересует разработчиков, а не цифры про «вакуум»), то имеет смысл просто качнуть тестовую бесплатную версию (для этого она у нас и есть) и посмотреть своими глазами. Обычно, поиграв с опциями из этого поста, можно весьма неплохо разогнаться.
kostus1974
есть вопросы:
1. возвращаете ли вы что-нибудь существенное в gcc/llvm регулярно?
2. вы же читаете исходники gcc/llvm, анализируете их? так вот: знаете ли вы сами, почему ваш компиллер делает более быстрый код? видите ли вы просчёты в gcc/llvm?
3. за счёт чего такой разрыв в скорости скомпиленных приложений (до полутора раз по вашим словам)? это особенности процессоров интел, которые известны только вам?
или это общие алгоритмы, общие системные решения, которые у вас проработаны лучше?
а может это потому, что gcc/llvm, как открытые системы, основаны на «красивых» решениях, а ваши закрытые компиляторы могут себе позволить… ну, скажем, некрасивый код, и за счёт этого могут получать преимущество?
4. превосходство достигается только на процессорах интел (я только про x86-64) или на процессорах амд тоже? может и для арм ваш компайлер может лучше? (я пока не качал и не пробовал)
ivorobts
Компилятор просто делает ряд оптимизаций лучше, в частности, максимальный прирост даёт векторизация. Если её отключать в нашем компиляторе, то это большой вопрос, будет ли прирост (даже если отключить её для сравнения и в других компиляторах). Векторизатор умеет распознавать достаточно сложные конструкции, и на выходе мы имеем большее число циклов, которые используют регистры по «максимуму», и при этом с использованием последних инструкций. Конечно, и другие оптимизации могут «додавать» производительности, но это ключевая.
Безусловно, у компиляторов Intel есть опции для оптимизации под конкретную микроархитектуру, и здесь мы тоже получим дополнительное преимущество. Тем не менее, возможность сгенерировать код под другие процессоры тоже есть. Возможно, где-то выложены сравнения компиляторов и на других процессорах, мы это не отслеживаем.
В целом, высокая производительность получаемого кода всегда была и остается основным преимуществом Интеловских компиляторов, поэтому сюда и инвестируется много ресурсов/времени.
У gcc есть ряд своих преимуществ, например доступность, открытость кода, поддержка языковых стандартов (появляется чуть раньше, чем у нас).
VaalKIA
Нашумевшая история
Есть-то она есть, но была не хорошая история, когда не зависимо от поддержки процессором векторных инструкций они эмулировались софтово, на платформах отличных от Интел. Даже выпускали патчеры-активаторы, настолько много было на рынке «медленных» бинарников в коммерческих проектах. Как обстоит с этим дело на современном уровне, пруфы, что всё норм есть?
ivorobts
Да, весьма интересно. Начиная с версии компилятора 14.0 (то есть не так уж и давно, точно позднее 2010 года, когда была написана та статья), был изменён диспатчинг. Теперь проверяется не сам процессор, а набор фич, которые процессор поддерживает.
ivorobts
Пардон за много букв. Более короткий ответ — обычно мы не хуже gcc, а если ваш тест покажет обратное — вам точно нужно связаться с нами, и, очень вероятно, это будет исправлено. В поддержке кроется весомое преимущество.
oleg-x2001
Вот пример сходу. Есть такой крошечный тест — рекурсивное вычисление факториала (практической ценности, разумеется, не имеет):
На одном и том же железе (и системе) файл сгенерированный gcc работает 7с, в то время как сгенерированный icc (17.0.4) — 16с. Более чем в два раза медленнее! В обоих случаях использовалась только одна опция, -O3. Если использовать -xHost для icc то результат 14с. Лучше, чем 16, но все равно в два раза медленнее. Пример, конечно, банальный, но разница тоже не маленькая…
ivorobts
Только что протестировал:
$ gcc --version
gcc (GCC) 6.2.0
Copyright © 2016 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ gcc test.c
$ time ./a.out
4807526976
real 0m15.512s
user 0m15.465s
sys 0m0.000s
$ icc -V
Intel® C Intel® 64 Compiler for applications running on Intel® 64, Version 17.0.4.196 Build 20170411
Copyright © 1985-2017 Intel Corporation. All rights reserved.
$ icc test.c
$ time ./a.out
4807526976
real 0m10.567s
user 0m10.529s
sys 0m0.000s
ivorobts
Ну и стоит сказать, что на таких тестах не стоит ожидать большей производительности, векторизации здесь нет.
oleg-x2001
Я тоже только что повторил тест без флагов оптимизации: gcc — 17.8, icc — 14,0. То есть что касается icc то -O3 вообще не оказыват влияния на результат в данном случае, а вот gcc ускоряется почти в три раза. Проведите тест с флагом -O3, как я и писал в самом начале. Для полноты картины:
gcc -O3 fib.c -o fib-gcc
icc -O3 -xHost fib.c -o fib-icc
Да, векторизации тут нет и именно это и интересно — тестируются только самые базовые элементы языка. Я не представляю какие тут вообще возможны варианты кроме уровня оптимизации, и тем не менее разница в два раза.
ivorobts
Магия опций!
ivorobts
Да, с О3 интеловский компилятор уже медленнее. Нужно посмотреть, что делал gcc с O3.
Но опять таки — без векторизации не стоит ожидать чудес от компилятора.
oleg-x2001
Сам по себе этот пример, конечно, малореалистичный, но все-таки разница в два раза это как-то слишком. Просто интересно за счет чего — как я уже говорил, тут используются уж очень базовые элементы языка, вроде бы никаких вариаций быть не должно, но тем не менее разница в два раза.
Сам я, к сожалению, не обладаю достаточной квалификацией чтобы быстро прояснить эту ситуацию, так что если кто доступно объяснит — было бы любопытно узнать )
kostus1974
а в дизассемблере что? не может быть, чтобы такой простой код рождал какие-то сильно разные инструкции. профилировать? может просто долгий старт или долгое завершение?
ivorobts
Ну дизассемблер нам не нужен, раз у нас в руках компилятор есть. Можно сразу посмотреть ассемблер. Быстро глянул, и заметил, что в случае с дефолтными опциями оба компилятора генерят примерно одинаковый код для main, вызывая fib. А вот c O3 gcc придумал что-то поинтереснее — он там организовал цикл для вызова fib:
main:
.LFB12:
subq $8, %rsp
.LCFI15:
movl $45, %esi
xorl %r8d, %r8d
.p2align 4,,10
.p2align 3
.L46:
cmpq $1, %rsi
jbe .L47
leaq -2(%rsi), %rdx
xorl %ecx, %ecx
.p2align 4,,10
.p2align 3
.L45:
movq %rdx, %rdi
call fib
subq $1, %rdx
addq %rax, %rcx
cmpq $-1, %rdx
jne .L45
addq $1, %rcx
.L44:
subq $1, %rsi
addq %rcx, %r8
cmpq $-1, %rsi
jne .L46
leaq 1(%r8), %rsi
movl $.LC0, %edi
xorl %eax, %eax
call printf
xorl %eax, %eax
addq $8, %rsp
.LCFI16:
ret
А по дефолту это выглядело так:
main:
.LFB1:
pushq %rbp
.LCFI4:
movq %rsp, %rbp
.LCFI5:
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
movl $47, %edi
call fib
movq %rax, %rsi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.LCFI6:
ret
В icc похожее на дефолтное у gcc. Нужно взять VTune и посмотреть более детально, могу даже пост про это написать. Но мне думается, что мы просто похуже работаем с рекурсиями, потому что они не очень то востребованы — только в образовательных целях.
ivorobts
icc делает всё «в лоб», то есть
a0 = fib(43);
a1 = fib(42);
a2 = fib(43);
a3 = fib(44);
a4 = fib(45);
А можно было бы оптимизировать так:
a0 = fib(43);
a1 = fib(42);
a2 = a0
a3 = a2 + a1;
a4 = fib(45);
a4 = a3 + a0
ivorobts
Собственно, подобное и делает gcc, и кэширует часть вычислений. Возможно, что в 18 версии (не Бета) на этом примере мы тоже сделаем подобное, ведь не просто так я копался сидел.
oleg-x2001
Спасибо за объяснение! Конечно, такой пример сам по себе вряд ли встретится в реальном коде, но подобная оптимизация может быть полезна для целого класса более реалистичных алгоритмов. Я это расхождение между gcc и icc заметил давно, просто руки не доходили об этом написать, но вот сегодня наткнулся на этот пост… Меня это всегда удивляло — тут ничего не распараллеливается, ничего не векторизуются, тут просто нет опций которые можно комбинировать и смотреть что получится. Оказывается, все не так уж загадочно )
ivorobts
И ещё одно замечание «вдогонку». В вопросе так же был интерес в самом времени компиляции, а не только выполнении. И вот тут у нас должен быть ощутимый прогресс в 18 версии, поскольку было пофикшено несколько подобных проблем (как в сравнении с gcc, так и с Visual C++, когда мы существенно дольше собирали код).
Но это всегда оборотная сторона медали — если хочешь, чтобы компилятор хорошо (читай как дольше) оптимизировал код, а приложение потом хорошо (читай как быстро) исполнялось — придётся где-то тратить больше времени (или на этапе компиляции, или выполнения).