Примечание переводчика: В нашем блоге мы уже рассказывали об инструментах для создания торговых роботов и даже анализировали зависимости между названием биржевого тикера компании и успешностью ее акций. Сегодня мы представляем вашему вниманию перевод интересной статьи, авторой которой разрабатывал систему, которая анализирует изменения цен на акций в прошлом и с помощью машинного обучения пытается предсказать будущий курс акций.
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.
Авторы предлагают фреймворк для извлечения векторов признаков из неформатированного журнала ордеров, который может использоваться как набор входных данных для метода классификации (например, метода опорных векторов или построения дерева решений), чтобы предсказать изменение курса ценных бумаг (вырастет, снизится, не изменится). На основании набора тестовых данных с присвоенными им метками (изменение цены) алгоритм классификации строит модель, которая помещает новые экземпляры в одну из предопределенных категорий.
В таблице каждая строка представляет собой торговую операцию, которая отражает поступление ордера, отмену ордера или его исполнение. Время прибытия отсчитывается от полуночи в секундах и наносекундах, цена указана в американских долларах, а объем – в количестве акций. Ask означает, что я продаю и прошу за свою часть акций указанную стоимость, Bid же означает, что я хочу купить по указанной цене.
Из этого журнала очень легко восстановить состояние портфеля ордеров после каждой совершенной операции. Вы можете узнать больше о портфеле ордеров (order book) и портфеле лимитных ордеров в Investopedia. Я не буду углубляться в детали. Общая идея очень проста и понятна.
Это электронный список ордеров на продажу и покупку для конкретной ценной бумаги или финансового инструмента, отсортированный по уровню цен.
После того, как портфели ордеров восстановлены из журнала ордеров, мы можем извлечь атрибуты и сформировать векторы признаков, которые будут использоваться в качестве входных данных для
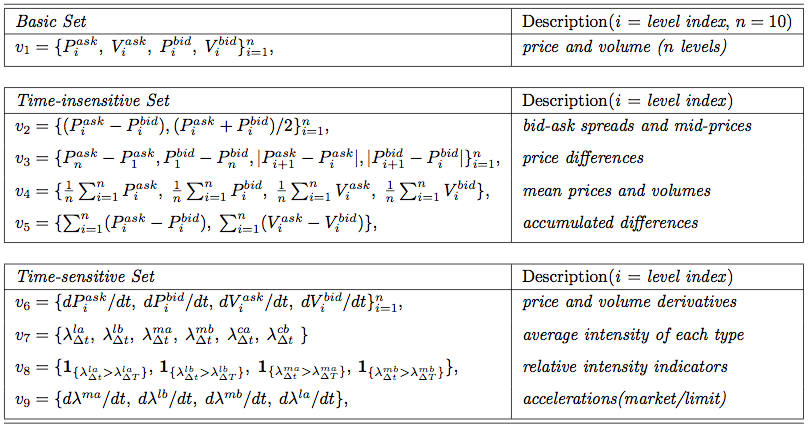
Атрибуты делятся на три категории: базисные, нечувствительные ко времени и чувствительные ко времени. Каждая из категорий может быть рассчитана напрямую на основании полученных данных. Базисные атрибуты – это цены и объемы, как с флагом ask, так и с флагом bid, в количестве n = 10 различных уровней (представляют собой уровни цен портфеля ордеров в заданный момент), которые могут быть напрямую получены из портфеля ордеров. Нечувствительные ко времени атрибуты легко рассчитать в единичный момент времени по атрибутам базисного набора. Сюда входят bid-ask спред и средняя цена спреда, ценовые диапазоны, а также средняя цена и объем на различных ценовых уровнях, которые вычисляются в наборах признаков
Подготовка тестовых данных для машинного обучения требует маркировки каждого момента времени, в рамках которого наблюдается изменение стоимости акций (1 секунда, к примеру). Это простая задача, которая требует только двух портфелей ордеров: текущего портфеля ордеров и портфеля ордеров, сформированного по прошествии некоторого времени.
Я буду использовать метку
Я буду использовать журналы ордеров NYSE TAQ OpenBook и парсить их с помощью библиотеки Scala OpenBook. Бесплатный набор данных для двух торговых дней доступен для скачивания на NYSE FTP – его очень просто получить.
Базы данных TAQ (Trades and Quotes) предоставляют изменяющиеся во времени значения стакана цен в базисе T+1 для закрытых рынков. Результаты обработки данных TAQ используются при разработке и тестировании торговых стратегий, анализе рыночных трендов на реальных данных и исследовании рынков с целью контроля или проведения аудита.
Я использую инструмент
Как было определено в исходной статье, мы имеем три набора признаков. Значения первых двух из них вычисляются на основе данных
а вот так выглядит расчет признаков:
Чтобы извлекать маркированные данные из ордеров, я использую
а вот так он может быть улучшен с помощью билдера:
В «реальном» приложении я использую 36 признаков из всех 3 наборов. Тесты запускаются с примерами данных, скачанных с NYSE FTP:
Результаты классификации методом построения дерева решений для отдельно взятого тикера
Как вы можете видеть, эта довольно простая модель смогла успешно классифицировать примерно 70% данных.
Замечание: Несмотря на то, что модель очень хорошо работает, это не означает, что она может успешно применяется для построения прибыльной автоматизированной трейдинговой стратегии. Во-первых, я не проверяю, предсказывает ли моя модель любые изменения цен с точностью в среднем в 70% с 95%-ной вероятностью. Модель не измеряет «интенсивность» динамики курсов ценных бумаг, кроме того, в реальности модель должна работать достаточно эффективно для покрытия операционных издержек. Не говоря уже о других мелочах, имеющих значение для построения реальной торговой системы.
На самом деле, можно сделать очень многое в плане улучшения системы и проверки результатов. К сожалению, очень сложно получить достаточное количество данных: данных по двум торговым дням не достаточно, чтобы сделать выводы и начать создавать систему, способную заработать все деньги в мире. Однако я думаю, что это довольно хорошая отправная точка.
Я относительно легко провел довольно сложный исследовательский проект в большем масштабе, чем тот, что описан в исходной статье.
Последние технологии в сфере больших данных позволяют создавать модели с использованием всей доступной информации без применения выборок. Использование всей информации помогает создать наилучшие модели и выделить все детали из полного набора данных.
Краткий обзор
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.
Архитектура модели
Авторы предлагают фреймворк для извлечения векторов признаков из неформатированного журнала ордеров, который может использоваться как набор входных данных для метода классификации (например, метода опорных векторов или построения дерева решений), чтобы предсказать изменение курса ценных бумаг (вырастет, снизится, не изменится). На основании набора тестовых данных с присвоенными им метками (изменение цены) алгоритм классификации строит модель, которая помещает новые экземпляры в одну из предопределенных категорий.
Time(sec) Price($) Volume Event Type Direction
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
34203.011926972 598.68 10 submission ask
34203.011926973 594.47 15 submission bid
34203.011926974 594.49 20 submission bid
34203.011926981 597.68 30 submission ask
34203.011926991 594.47 15 execution ask
34203.011927072 597.68 10 cancellation ask
34203.011927082 599.88 12 submission ask
34203.011927097 598.38 11 submission ask
В таблице каждая строка представляет собой торговую операцию, которая отражает поступление ордера, отмену ордера или его исполнение. Время прибытия отсчитывается от полуночи в секундах и наносекундах, цена указана в американских долларах, а объем – в количестве акций. Ask означает, что я продаю и прошу за свою часть акций указанную стоимость, Bid же означает, что я хочу купить по указанной цене.
Из этого журнала очень легко восстановить состояние портфеля ордеров после каждой совершенной операции. Вы можете узнать больше о портфеле ордеров (order book) и портфеле лимитных ордеров в Investopedia. Я не буду углубляться в детали. Общая идея очень проста и понятна.
Это электронный список ордеров на продажу и покупку для конкретной ценной бумаги или финансового инструмента, отсортированный по уровню цен.
Извлечение векторов признаков и подготовка тестовых данных
После того, как портфели ордеров восстановлены из журнала ордеров, мы можем извлечь атрибуты и сформировать векторы признаков, которые будут использоваться в качестве входных данных для
классификационной модели.Атрибуты делятся на три категории: базисные, нечувствительные ко времени и чувствительные ко времени. Каждая из категорий может быть рассчитана напрямую на основании полученных данных. Базисные атрибуты – это цены и объемы, как с флагом ask, так и с флагом bid, в количестве n = 10 различных уровней (представляют собой уровни цен портфеля ордеров в заданный момент), которые могут быть напрямую получены из портфеля ордеров. Нечувствительные ко времени атрибуты легко рассчитать в единичный момент времени по атрибутам базисного набора. Сюда входят bid-ask спред и средняя цена спреда, ценовые диапазоны, а также средняя цена и объем на различных ценовых уровнях, которые вычисляются в наборах признаков
v2, v3 и v5 соответственно. Набор v5 нужен, чтобы отслеживать накапливающуюся разницу в цене и объеме акций между ask и bid. Затем, учитывая значение данных в предыдущих периодах, мы рассчитываем параметры чувствительной ко времени категории. Больше о вычислениях признаков можно почитать в исходной статье. Разметка тестовых данных
Подготовка тестовых данных для машинного обучения требует маркировки каждого момента времени, в рамках которого наблюдается изменение стоимости акций (1 секунда, к примеру). Это простая задача, которая требует только двух портфелей ордеров: текущего портфеля ордеров и портфеля ордеров, сформированного по прошествии некоторого времени.
Я буду использовать метку
MeanPriceMove, которая может принимать значения Stationary, Up или Down (не изменится, вырастет, снизится).trait Label[L] extends Serializable { label =>
def apply(current: OrderBook, future: OrderBook): Option[L]
}
sealed trait MeanPriceMove
object MeanPriceMove {
case object Up extends MeanPriceMove
case object Down extends MeanPriceMove
case object Stationary extends MeanPriceMove
}
object MeanPriceMovementLabel extends Label[MeanPriceMove] {
private[this] val basicSet = BasicSet.apply(BasicSet.Config.default)
def apply(current: OrderBook, future: OrderBook): Option[MeanPriceMove] = {
val currentMeanPrice = basicSet.meanPrice(current)
val futureMeanPrice = basicSet.meanPrice(future)
val cell: Cell[MeanPriceMove] =
currentMeanPrice.zipMap(futureMeanPrice) {
(currentMeanValue, futureMeanValue) =>
if (currentMeanValue == futureMeanValue)
MeanPriceMove.Stationary
else if (currentMeanValue > futureMeanValue)
MeanPriceMove.Down
else
MeanPriceMove.Up
}
cell.toOption
}
}
Журналы ордеров
Я буду использовать журналы ордеров NYSE TAQ OpenBook и парсить их с помощью библиотеки Scala OpenBook. Бесплатный набор данных для двух торговых дней доступен для скачивания на NYSE FTP – его очень просто получить.
Базы данных TAQ (Trades and Quotes) предоставляют изменяющиеся во времени значения стакана цен в базисе T+1 для закрытых рынков. Результаты обработки данных TAQ используются при разработке и тестировании торговых стратегий, анализе рыночных трендов на реальных данных и исследовании рынков с целью контроля или проведения аудита.
Подготовка тестовых данных
OrderBook представляет собой две отсортированные таблицы, где ключом является цена, а величиной – количество акций.case class OrderBook(symbol: String,
buy: TreeMap[Int, Int] = TreeMap.empty,
sell: TreeMap[Int, Int] = TreeMap.empty)
Наборы параметров
Я использую инструмент
Cell из библиотеки Framian для наглядного представления извлеченных значений признаков: Value, NA или NM.Как было определено в исходной статье, мы имеем три набора признаков. Значения первых двух из них вычисляются на основе данных
OrderBook, последний же требует создания таблицы OrdersTrail, которая по своей сути является неформатированным журналом ордеров, над которым провели оконное преобразование Фурье.sealed trait BasicAttribute[T] extends Serializable { self =>
def apply(orderBook: OrderBook): Cell[T]
def map[T2](f: T => T2): BasicAttribute[T2] = new BasicAttribute[T2] {
def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f)
}
}
sealed trait TimeInsensitiveAttribute[T] extends Serializable { self =>
def apply(orderBook: OrderBook): Cell[T]
def map[T2](f: T => T2): TimeInsensitiveAttribute[T2] = new TimeInsensitiveAttribute[T2] {
def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f)
}
}
trait TimeSensitiveAttribute[T] extends Serializable { self =>
def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T]
def map[T2](f: T => T2): TimeSensitiveAttribute[T2] = new TimeSensitiveAttribute[T2] {
def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T2] = self(ordersTrail).map(f)
}
}
а вот так выглядит расчет признаков:
class BasicSet private[attribute] (val config: BasicSet.Config) extends Serializable {
private[attribute] def askPrice(orderBook: OrderBook)(i: Int): Cell[Int] = {
Cell.fromOption {
orderBook.sell.keySet.drop(i - 1).headOption
}
}
private[attribute] def bidPrice(orderBook: OrderBook)(i: Int): Cell[Int] = {
Cell.fromOption {
val bidPrices = orderBook.buy.keySet
if (bidPrices.size >= i) {
bidPrices.drop(bidPrices.size - i).headOption
} else None
}
}
private def attribute[T](f: OrderBook => Cell[T]): BasicAttribute[T] = new BasicAttribute[T] {
def apply(orderBook: OrderBook): Cell[T] = f(orderBook)
}
def askPrice(i: Int): BasicAttribute[Int] = attribute(askPrice(_)(i))
def bidPrice(i: Int): BasicAttribute[Int] = attribute(bidPrice(_)(i))
val meanPrice: BasicAttribute[Double] = {
val ask1 = askPrice(1)
val bid1 = bidPrice(1)
BasicAttribute.from(orderBook =>
ask1(orderBook).zipMap(bid1(orderBook)) {
(ask, bid) => (ask.toDouble + bid.toDouble) / 2
})
}
}
Маркировка тестовых данных
Чтобы извлекать маркированные данные из ордеров, я использую
LabeledPointsExtractor:class LabeledPointsExtractor[L: LabelEncode] {
def labeledPoints(orders: Vector[OpenBookMsg]): Vector[LabeledPoint] = {
log.debug(s"Extract labeled points from orders log. Log size: ${orders.size}")
// ...
}
}
а вот так он может быть улучшен с помощью билдера:
val extractor = {
import com.scalafi.dynamics.attribute.LabeledPointsExtractor._
(LabeledPointsExtractor.newBuilder()
+= basic(_.askPrice(1))
+= basic(_.bidPrice(1))
+= basic(_.meanPrice)
).result(symbol, MeanPriceMovementLabel, LabeledPointsExtractor.Config(1.millisecond))
}
Extractor подготовит помеченные точки, используя MeanPriceMovementLabel с тремя признаками: запрашиваемая стоимость (ask price), установленная цена (bid price) и средняя цена (mean price).Запуск классификационной модели
В «реальном» приложении я использую 36 признаков из всех 3 наборов. Тесты запускаются с примерами данных, скачанных с NYSE FTP:
EQY_US_NYSE_BOOK_20130403 для обучения модели и EQY_US_NYSE_BOOK_20130404 для проверки правильности работы.object DecisionTreeDynamics extends App with ConfiguredSparkContext with FeaturesExtractor {
private val log = LoggerFactory.getLogger(this.getClass)
case class Config(training: String = "",
validation: String = "",
filter: Option[String] = None,
symbol: Option[String] = None)
val parser = new OptionParser[Config]("Order Book Dynamics") {
// ....
}
parser.parse(args, Config()) map { implicit config =>
val trainingFiles = openBookFiles("Training", config.training, config.filter)
val validationFiles = openBookFiles("Validation", config.validation, config.filter)
val trainingOrderLog = orderLog(trainingFiles)
log.info(s"Training order log size: ${trainingOrderLog.count()}")
// Configure DecisionTree model
val labelEncode = implicitly[LabelEncode[MeanPriceMove]]
val numClasses = labelEncode.numClasses
val categoricalFeaturesInfo = Map.empty[Int, Int]
val impurity = "gini"
val maxDepth = 5
val maxBins = 100
val trainingData = trainingOrderLog.extractLabeledData(featuresExtractor(_: String))
val trainedModels = (trainingData map { case LabeledOrderLog(symbol, labeledPoints) =>
log.info(s"$symbol: Train Decision Tree model. Training data size: ${labeledPoints.count()}")
val model = DecisionTree.trainClassifier(labeledPoints, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
val labelCounts = labeledPoints.map(_.label).countByValue().map {
case (key, count) => (labelEncode.decode(key.toInt), count)
}
log.info(s"$symbol: Label counts: [${labelCounts.mkString(", ")}]")
symbol -> model
}).toMap
val validationOrderLog = orderLog(validationFiles)
log.info(s"Validation order log size: ${validationOrderLog.count()}")
val validationData = validationOrderLog.extractLabeledData(featuresExtractor(_: String))
// Evaluate model on validation data and compute training error
validationData.map { case LabeledOrderLog(symbol, labeledPoints) =>
val model = trainedModels(symbol)
log.info(s"$symbol: Evaluate model on validation data. Validation data size: ${labeledPoints.count()}")
log.info(s"$symbol: Learned classification tree model: $model")
val labelAndPrediction = labeledPoints.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val trainingError = labelAndPrediction.filter(r => r._1 != r._2).count().toDouble / labeledPoints.count
log.info(s"$symbol: Training Error = " + trainingError)
}
}
}
Ошибки обучения
Результаты классификации методом построения дерева решений для отдельно взятого тикера
ORCL:ORCL: Train Decision Tree model. Training data size: 64064
ORCL: Trained model in 3740 millis
ORCL: Label counts: [Stationary -> 42137, Down -> 10714, Up -> 11213]
ORCL: Evaluate model on validation data. Validation data size: 54749
ORCL: Training Error = 0.28603262160039455
Как вы можете видеть, эта довольно простая модель смогла успешно классифицировать примерно 70% данных.
Замечание: Несмотря на то, что модель очень хорошо работает, это не означает, что она может успешно применяется для построения прибыльной автоматизированной трейдинговой стратегии. Во-первых, я не проверяю, предсказывает ли моя модель любые изменения цен с точностью в среднем в 70% с 95%-ной вероятностью. Модель не измеряет «интенсивность» динамики курсов ценных бумаг, кроме того, в реальности модель должна работать достаточно эффективно для покрытия операционных издержек. Не говоря уже о других мелочах, имеющих значение для построения реальной торговой системы.
На самом деле, можно сделать очень многое в плане улучшения системы и проверки результатов. К сожалению, очень сложно получить достаточное количество данных: данных по двум торговым дням не достаточно, чтобы сделать выводы и начать создавать систему, способную заработать все деньги в мире. Однако я думаю, что это довольно хорошая отправная точка.
Результаты
Я относительно легко провел довольно сложный исследовательский проект в большем масштабе, чем тот, что описан в исходной статье.
Последние технологии в сфере больших данных позволяют создавать модели с использованием всей доступной информации без применения выборок. Использование всей информации помогает создать наилучшие модели и выделить все детали из полного набора данных.
Код приложения на Гитхабе
Оффтоп: продолжается конкурс для разработчиков от ITinvest и команды проекта StockSharp — создавайте дополнения или исправления к системе StockSharp на Гитхабе, и получайте денежное вознаграждение за каждый принятый коммит.
Комментарии (12)

reality
08.06.2015 22:23+7Черт возьми это успех когда твою статью на английском переводят и публикуют на Хабре ;) (p.s. я автор оригинала)
Самое забавное что бурение насчет того можно ли предсказывать цены было в английском интернете, только статья совсем не про это, статья про то что с помощью Spark можно делать очень клевые вещи с очень большими данными, ну а дальше все зависит от той математической модели которую придумали.
Можно торговать на бирже, можно оптимизировать рекламу а можно и искать лекарство от рака

questor
Невозможно предсказывать котировки. Даже нобелевские лауреаты говорят о том, что на текущем уровне развития науки это пока невозможно.
Когда же каждый первый
чистильщик обувипродаёт тебе торговых роботов, говоря, что он может предсказывать котировки…itinvest Автор
Если бы вы прочитали статью (судя по комменту, просто вы где-то на названии остановились), то поняли бы, что здесь не идет речь о том, что «чистильщик обуви предлагает предсказывать котировки», а это просто интересная математическая задача. И никто никого не призывает нести последние деньги куда бы то ни было и покупать на них какие-то акции.
questor
Напротив, я прочитал статью до конца. Более того, прекрасно помню вашу статью про внутреннюю кухню Форекс и другие статьи. Что такое машинное обучение — я представляю. Господа минусущие не согласны, что на текущем уровне развития экономики невозможно предсказать будущее?
itinvest Автор
Ну в этой статье не написано, что можно предсказать будущее. Конечно, будущее предсказывать не умеет никто, но есть математическая задача по выявлению различных закономерностей и моделированию. Не совсем просто понятно, вы предлагаете не заниматься подобными вопросами или что?
zone19
Параллельно с вами торгуют миллионы роботов, которые тоже настроены на адаптирующихся моделях и меняют свое поведение в соответствии с новыми поступающими данными.
itinvest Автор
Конкретно в этой статье вообще, кстати, не говорится о том, что пишется робот, который может использоваться для торговли. Там есть вполне понятная сноска на этот счет:
Короче говоря, спор ни о чем, поскольку то, с чем вы пытаетесь спорить не является темой статьи, и все с вами согласны о невозможности предсказания будущего и подобных магических вещах.
Donskoy
А как в этом поможет развитие экономики? Это текущий уровень развития машинного обучения и вычислительной техники не позволяет достоверно предсказывать будущее, обучив правильный алгоритм на пространстве всех возможных признаков.
dezconnect
Даже на основе объема и «стакана», можно предсказывать периодику определенных рынков, уж не надо тут утрировать.
dyadyaSerezha
Полностью предсказывать котировки на бирже не возможно в принципе, это не зависит от уровня развития науки, а зависит от сути биржи — это реактивный объект, то есть, реагирующий на внешние события (новости про фирмы и вообще любые новости в мире).
Другое дело, можно ли попытаться предсказывать хоть что-то, хоть в минимальной степени, достаточной для зарабатывания бабок.
Alexey_mosc
2 questor. С вашим возмущением могу горячо согласиться.
Однако котировки можно предсказывать и зарабатывать на этом более или менее регулярно. Но не так, как описано в статье. Любой метод «в лоб» даст ноль или минус в практическом смысле.
Нобелевские лауреаты лукавят.