
Представили себе это? Да, дух захватывает. Тем не менее это обычные будни разработчиков Единой Фронтальной Системы Сбербанка. Две сотни команд одновременно занимаются развитием платформы, ежедневно решая сложные и нетривиальные задачи, направленные на оптимизацию и синхронизацию процессов.
О синхронизации и оптимизации можно говорить долго, эта тема заслуживает отдельной книги. В данной статье мы затронем лишь небольшую часть – оптимизацию разработки интеграционного взаимодействия, поделимся своим опытом и расскажем, как интегрироваться с сотней систем и никого не ждать.
Вопрос, который нас волнует в первую очередь — как всем командам, каждая из которых зависит от множества других команд, успеть сделать свою разработку качественно, с соблюдением всех сроков, и чтобы при стыковке со смежными системами на интеграционном полигоне получить ожидаемый результат?
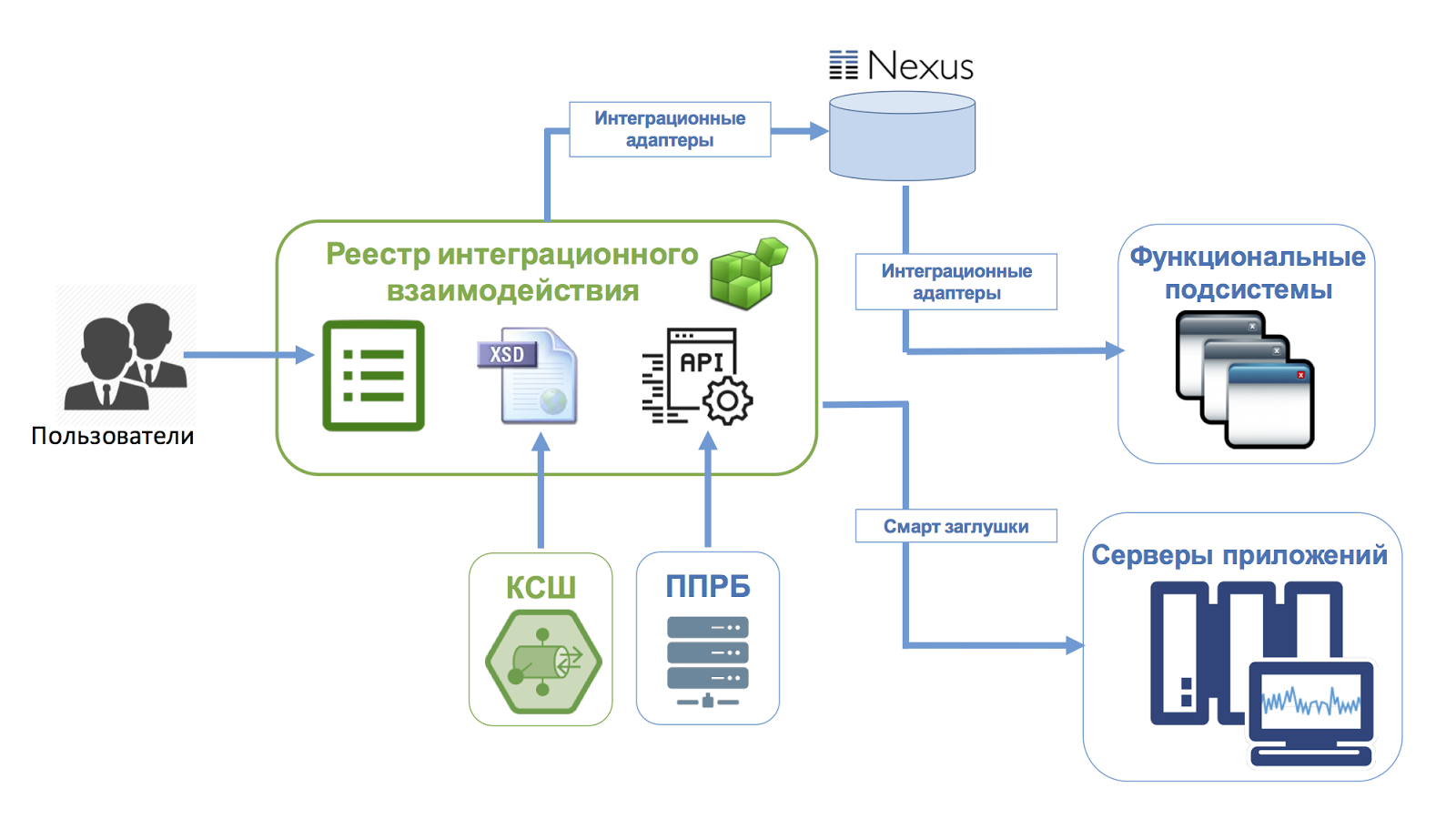
И мы нашли два ответа на него: единое информационное пространство и максимальная автоматизация разработки и развертывания.
Сейчас нашим центром интеграции является «Единый реестр интеграционного взаимодействия». Реестр содержит информацию по всем подсистемам и сервисам, детали интеграционного взаимодействия, атрибутивный состав, описание источников данных и реестр использования, форматы, протоколы и другие характеристики, необходимые для точного и однозначного описания каждого взаимодействия. Кроме того, он связан с аналогичными реестрами других систем банка. Все это формирует единое информационное пространство.
С единым информационным пространством понятно, что насчет автоматизации? Чем больше кода будет сгенерировано автоматически, тем меньше будет затрат и тем выше качество конечного продукта. Для разработки интеграционного взаимодействия это важно вдвойне, поскольку множество разрабатываемых по отдельности систем должны совместно взаимодействовать и понимать друг друга.
Как вы, наверное, догадались, реестр интеграционного взаимодействия нужен не только для ведения справочной информации. На основании данных реестра происходит автоматическая генерация интеграционных компонентов (интеграционного слоя). Это избавляет команды от дополнительной рутинной разработки, формирует единую интеграционную архитектуру и гарантирует согласованность взаимодействия согласно заявленным контрактам.
Да, действительно удобно, но это еще не все. Команда завела все свои интеграции в реестр, получила сгенерированный интеграционный слой и … стоп. Функциональность разрабатываемых командой модулей зависит от смежных систем, которые сами находятся в процессе разработки. Как быть? К тому же, в конце спринта Владелец продукта (Product owner) захочет увидеть результат работы команды. Возможно, вместе со стейкхолдерами захочет сделать какие-нибудь корректировки бэклога. Agile, как-никак.
Что делать?
Правильно, нужно заглушить отсутствующие интеграционные взаимодействия. И тут все команды кинулись писать свои заглушки.
Времени катастрофически не хватает, есть большой соблазн заглушить взаимодействие, затрачивая минимальные усилия. Например, добавить возвращение результата непосредственно в код вызывающей функции. Не совсем честно, согласны, зато не нужно тратить время на написание отдельных компонентов, разворачивать и настраивать различные брокеры сообщений. Да, на следующем спринте многое придется поменять, да, нет гарантии, что смежные системы будут работать аналогично этой реализации, но времени нет — нужно завершать спринт, тут не до оптимизации затрат.
И тут на помощь снова приходит Единый реестр интеграционного взаимодействия. Если он уже используется для генерации интеграционных компонентов, тогда что мешает сразу сгенерировать соответствующие заглушки, автоматически развернуть их на общей инфраструктуре, доступной из девелоперской и демонстрационной среды. А если добавить к этому отдельный инструмент для создания тестовых сценариев, чтобы их могли писать не только разработчики, но и тестировщики или аналитики, которые как раз детально прорабатывают все взаимодействия и хорошо знают форматы, атрибуты и варианты использования каждого сервиса. А если еще и дополнительно объединить написанные разными командами тестовые сценарии в общий каталог, то тогда мы получим настоящие «умные заглушки».
Умные заглушки ЕФС
Сейчас наши «умные заглушки» поддерживают стандарт обмена сообщениями JMS. Это позволяет обеспечить эмуляцию большинства взаимодействий Единой фронтальной системы со смежными системами. При этом реализована поддержка четырех типов взаимодействия:
- запрос ЕФС/ответ внешняя АС;
- запрос ЕФС/без ответ внешней АС (нотификация);
- запрос от внешней АС/без ответа от ЕФС (нотификация);
- запрос от внешней АС/с ответом от ЕФС.
Для выбора шаблона ответа используются условия на входящие сообщения с применением нотации XPath. Генерация ответов по заданным шаблонам происходит с помощью FreeMarker’a. Поддерживается валидация запроса/ответа по XSD схеме. Все запросы и ответы логируются в базу данных.
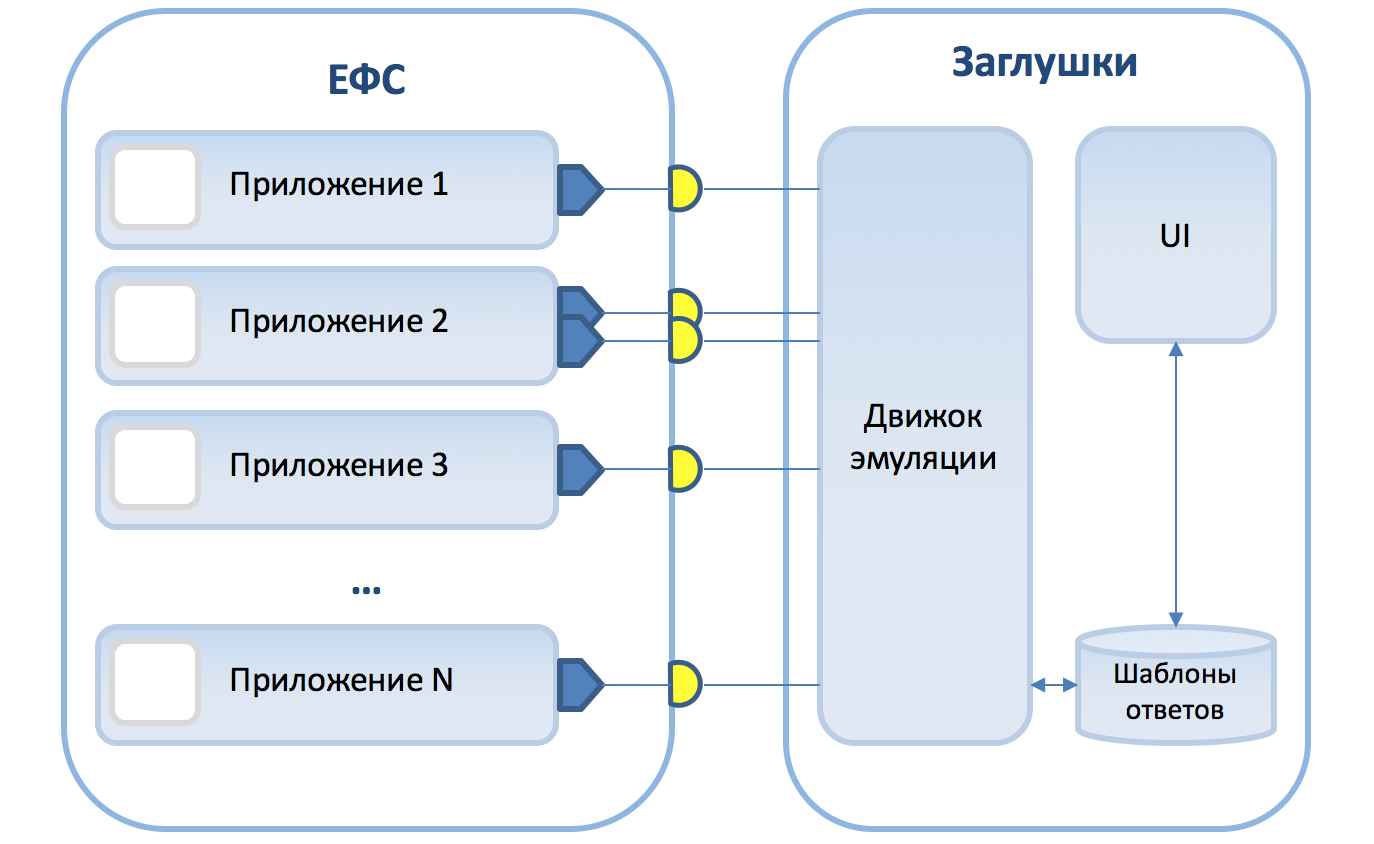
Выше мы упоминали, что основные разработчики заглушек и тестовых сценариев — это тестировщики и аналитики. Аналитики непосредственно занимаются проработкой интеграционных взаимодействий, описывают атрибутивный состав сервисов, варианты использования и последовательности вызовов. Тестировщики формируют тестовые сценарии с учетом пользовательских историй (User Story). С учетом этого все настройки заглушек и написание тестовых сценариев осуществляются через удобный веб-интерфейс, при этом навыки программирования не требуются. Большое внимание уделено работе с логами сообщений: фильтрация, просмотр списка вызовов и детальной информации по каждому вызову. Эта функциональность необходима при разборе работы заглушек и для понимания работы тестовых сценариев.
А теперь представим, что часть смежных систем уже готова, некоторые выпускаются в текущем спринте, а что-то будет разработано позже. Централизованный выпуск интеграционного слоя позволяет управлять конфигурацией адаптеров и заглушек из единой Системы управления параметрами (СУП). Настройка адаптеров на работу с реальными системами или заглушками осуществляется через СУП, при этом переключение происходит в реальном времени без перезапуска и тем более без пересборки приложений.
С учетом того, что умные заглушки предоставляются по сервисной модели, и командам не нужно развертывать собственную инфраструктуру (искать сервера, что-то устанавливать и настраивать), новые заглушки можно создать и начать использовать в несколько кликов. Согласитесь, в условиях сжатых сроков это большая помощь.
Упрощение разработки заглушек — это, конечно, хорошо. Но можно ли при этом совсем обойтись без каких-либо затрат? Как ни странно, но да. Чем больше заглушек разрабатывается, тем выше вероятность их переиспользования. Для упрощения поиска реализованных заглушек у нас есть отдельный реестр. Прежде чем разрабатывать собственную заглушку мы ищем в реестре по мастер-системе и по сервису все тестовые сценарии, уже написанные для этого взаимодействия. И если нужные заглушки уже разработаны, то мы просто используем их без каких-либо затрат. Если нет, то либо что-то дорабатываем в текущих сценариях, либо формируем новые заглушки. Все раздельные области тестирования можно использовать, это очень удобно, поскольку позволяет избежать взаимного влияния:

И напоследок
Внедрение единого информационного пространства интеграционного взаимодействия ЕФС вместе с автоматизацией разработки и развертывания интеграционного слоя и умных заглушек позволило существенно сократить затраты, повысить качество и согласованность интеграционного взаимодействия, а также обеспечило возможность вести синхронную разработку множеству команд с использованием гибкой (Agile) методологии.
Сделано уже много, но судя по запросам команд и по сформированному roadmap’у это только начало. В ближайших планах:
- Расширение поддерживаемых протоколов и форматов: http, kafka, json.
- Поддержка комплексных тестовых сценариев, включающих несколько вызовов, и сохранение промежуточных результатов в контексте единого тестового сценария.
- Возможность вызовов внешних сервисов и запись реальных ответов для последующего использования в заглушках.
- Поддержка плагинов для расширения возможностей эмуляции.
Задач много, и все нужно сделать вчера. Поэтому у нас поощряется совместная разработка. Каждая команда может доработать функциональность умных заглушек или реестра. Сделав необходимую доработку для себя, команда реализует это для всех остальных. Совместное развитие инструментария позволяет существенно ускорить развитие продуктов и сроки реализации roadmap'a.
А что вы думаете об этом? Если вам близка и интересна тема интеграции, будем рады побеседовать в комментариях к посту.
Комментарии (5)


antirek
09.06.2017 08:14+1Единый реестр интеграционного взаимодействия!
Чтобы добавить описание интеграционного взаимодействия в Единый реестр интеграционного взаимодействия заполните бланк, который вы можете получить в Едином репозитории документов и бланков, согласно Единого регламента заполнения документов и бланков. После процедуры утверждения описаний интеграционного взаимодействия из Единого регламента процедур и регламентов описание будет доступно в Единой фронтальной системе.
Шутка. Монолитные приложения все еще в голове.
vrakhmanov
09.06.2017 21:01-1Единая фронтальная система (ЕФС) – это как раз шаг от монолита в сторону микросервисов, а реестр интеграционного взаимодействия — это Design-time API Registry. В обширном и разнообразном интеграционном ландшафте банка это must have. Про управление API в design-time и run-time напишем отдельно – это тоже интересная тема.
QDeathNick
"В прошлом году мы сделали 40 тысяч заглушек в нашей системе в год. Если посмотреть на другие банки, мы в шоколаде. Но если смотреть на Amazon, Google, мы ужасно отстаем. Amazon делает 10 тысяч заглушек в своей системе в день" — Герман Греф, президент «Сбербанка»
Шутка. По факту скорее всего без переиспользованных заглушек никак.