Статья по мотивам выступления на конференции РИФ+КИБ 2017.
Neural Machine Translation: почему только сейчас?
Про нейронные сети говорят уже давно, и, казалось бы, что одна из классических задач искусственного интеллекта – машинный перевод – просто напрашивается на то, чтобы решаться на базе этой технологии.
Тем не менее, вот динамика популярности в поиске запросов про нейронные сети вообще и про нейронный машинный перевод в частности:
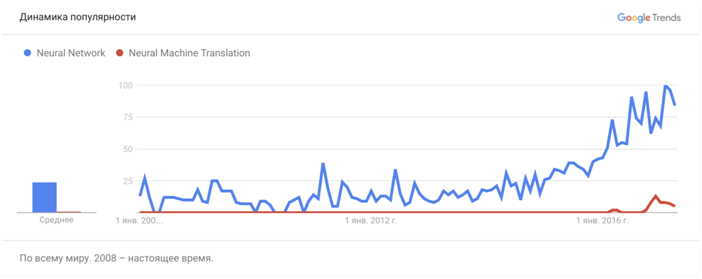
Прекрасно видно, что на радарах вплоть до недавнего времени нет ничего про нейронный машинный перевод – и вот в конце 2016 года свои новые технологии и системы машинного перевода, построенные на базе нейронных сетей, продемонстрировали сразу несколько компаний, среди которых Google, Microsoft и SYSTRAN. Они появились почти одновременно, с разницей в несколько недель или даже дней. Почему так?
Для того, чтобы ответить на этот вопрос, необходимо понять, что такое машинный перевод на базе нейронных сетей и в чем его ключевое отличие от классических статистических систем или аналитических систем, которые используются сегодня для машинного перевода.
В основе нейронного переводчика механизм двунаправленных рекуррентных нейронных сетей (Bidirectional Recurrent Neural Networks), построенный на матричных вычислениях, который позволяет строить существенно более сложные вероятностные модели, чем статистические машинные переводчики.
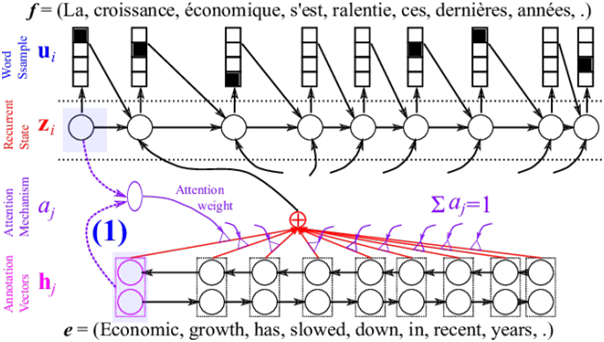
Как и статистический перевод, нейронный перевод требует для обучения параллельные корпуса, позволяющие сравнить автоматический перевод с эталонным «человеческим», только в процессе обучения оперирует не отдельными фразами и словосочетаниями, а целыми предложениями. Основная проблема в том, что для тренировки такой системы требуется существенно больше вычислительных мощностей.
Для ускорения процесса разработчики используют GPU от NVIDIA, а Google также и Tensor Processing Unit (TPU) – чипы собственной разработки, адаптированные специально для технологий машинного обучения. Графические чипы изначально оптимизированы под алгоритмы матричных вычислений, и поэтому выигрыш в производительности составляет 7-15 раз в сравнении с CPU.
Даже при всем этом тренировка одной нейронной модели требует от 1 до 3 недель, тогда как статистическая модель примерно того же размера настраивается за 1-3 дня, и с увеличением размера эта разница увеличивается.
Однако не только технологические проблемы были тормозом для развития нейронных сетей в контексте задачи машинного перевода. В конце концов, обучать языковые модели можно было и раньше, пусть и медленнее, но принципиальных препятствий не было.
Свою роль сыграла в том числе и мода на нейронные сети. Разработки внутри себя вели многие, но заявлять об этом не спешили, опасаясь, возможно, что не получат того прироста качества, которое общество ожидает от словосочетания Neural Networks. Этим можно объяснить тот факт, что сразу несколько нейронных переводчиков были анонсированы один за другим.
Качество перевода: чей BLEU score толще?
Попробуем понять, соответствует ли рост качества перевода накопленным ожиданиям и тому росту затрат, которые сопровождают разработку и поддержку нейронных сетей для перевода.
Google в своем исследования демонстрирует, что нейронный машинный перевод дает Relative Improvement от 58% до 87%, в зависимости от языковой пары, по сравнению с классическим статистическим подходом (или Phrase Based Machine Translation, PBMT, как его еще называют).

SYSTRAN проводит исследование, в котором качество перевода оценивается путем выбора из нескольких представленных вариантов, сделанных различными системами, а также «человеческого» перевода. И заявляет, что его нейронный перевод предпочитают в 46% случаев переводу, сделанному человеком.

Качество перевода: есть ли прорыв?
Несмотря на то, что Google заявляет об улучшении на 60% и даже выше, в этом показателе есть небольшой подвох. Представители компании говорят о «Relative Improvement», то есть насколько им удалось с нейронным подходом приблизится к качеству Human Translation по отношению к тому, что было в классическом статистическом переводчике.

Эксперты отрасли, анализирующие результаты, представленные Google в статье «Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation», достаточно скептически относятся к представленным результатам и говорят, что фактически BLEU score удалось улучшить только на 10%, а существенный прогресс заметен именно на достаточно простых тестах из Wikipedia, которые, скорее всего, были использованы и в процессе обучения сети.
Внутри PROMT мы регулярно проводим сравнение перевода на различных текстах наших систем с конкурентами, и поэтому под рукой всегда есть примеры, на которых мы можем проверить, действительно ли нейронный перевод так превосходит предыдущее поколение, как заявляют производители.
Исходный текст (EN): Worrying never did anyone any good.
Перевод Google PBMT: Не беспокоясь не делал никому ничего хорошего.
Перевод Google NMT: Беспокойство никогда никому не помогало.
Кстати, перевод той же фразы на Translate.Ru: «Волнение никогда не приносило никому пользы», можно заметить, что он был и остался таким же и без использования нейронных сетей.
Microsoft Translator в этом вопросе тоже не отстает. В отличие от коллег из Google они даже сделали сайт, на котором можно сделать перевод и сравнить два результата: нейронный и донейронный, чтобы убедиться, что утверждения о росте в качестве не голословны.

На этом примере мы видим, что прогресс есть, и он действительно заметный. На первый взгляд, похоже, что заявление разработчиков о том, что машинный перевод практически догнал «человеческий» — правда. Но так ли это на самом деле, и что это значит с точки зрения практического применения технологии для бизнеса?
В общем случае перевод с применением нейронных сетей превосходит перевод статистический, и у этой технологии есть огромный потенциал для развития. Но если внимательно подойти к вопросу, то мы сможем убедиться, что прогресс не во всем, и не для всех задач можно применять нейронные сети без оглядки на саму задачу.
Машинный перевод: в чем задачи
От автоматического переводчика всю историю его существования – а это уже более 60 лет! – ждали некой магии, представляя его как машинку из фантастических фильмов, которая мгновенно переводит любую речь в инопланетный свист и обратно.
На самом деле, задачи бывают разного уровня, один из которых подразумевает «универсальный» или, если можно так выразится, «бытовой» перевод для повседневных задач и облегчения понимания. С задачами этого уровня прекрасно справляются онлайн-сервисы по переводу и множество мобильных продуктов.
К таким задачам можно отнести:
• быстрый перевод слов и коротких текстов для различных целей;
• автоматический перевод в процессе общения на форумах, в социальных сетях, мессенджерах;
• автоматический перевод при чтении новостей, статей Wikipedia;
• переводчик в путешествиях (mobile).
Все те примеры роста качества перевода с использованием нейронных сетей, которые мы рассматривали выше, как раз и относятся к этим задачам.
Однако с целями и задачами бизнеса в отношении машинного перевода все обстоит несколько иначе. Вот, например, некоторые требования, которые предъявляются к корпоративным системам машинного перевода:
• перевод деловой переписки с клиентами, партнерами, инвесторами, иностранными сотрудниками;
• локализация сайтов, интернет-магазинов, описаний продуктов, инструкций;
• перевод пользовательского контента (отзывы, форумы, блоги);
• возможность интеграции перевода в бизнес-процессы и программные продукты и сервисы;
• точность перевода с соблюдением терминологии, конфиденциальность и безопасность.
Попробуем понять на примерах, решаемы ли любые задачи бизнеса по переводу с помощью нейронных сетей и как именно.
Кейс: Amadeus
Amadeus — одна из крупнейших в мире глобальных систем дистрибуции авиабилетов. С одной стороны к ней подключены авиаперевозчики, с другой – агентства, которые должны получать всю информацию об изменениях в режиме реального времени и доносить до своих клиентов.
Задача — локализация условий применения тарифов (Fare Rules), формирующихся в системе бронирования автоматически из разных источников. Эти правила формируются всегда на английском языке. Ручной перевод здесь практически невозможен, ввиду того, что информации много и она часто меняется. Агент по продаже авиабилета хотел бы читать Fare Rules на русском языке, чтобы оперативно и квалифицированно консультировать своих клиентов.
Требуется понятный перевод, передающий смысл тарифных правил, с учетом типичных терминов и аббревиатур. И требуется, чтобы автоматический перевод был интегрирован непосредственно в систему бронирования Amadeus.
> Подробно задача и реализация проекта расписаны в документе.
Попробуем сравнить перевод, сделанный через PROMT Cloud API, интегрированный в Amadeus Fare Rules Translator, и «нейронный» перевод от Google.
Оригинал: ROUND TRIP INSTANT PURCHASE FARES
PROMT (Аналитический подход): ТАРИФЫ МГНОВЕННОЙ ПОКУПКИ РЕЙСА ТУДА И ОБРАТНО
GNMT: КРУГЛЫЕ ПОКУПКИ
Очевидно, что тут нейронный переводчик не справляется, и чуть дальше станет понятно, почему.
Кейс: TripAdvisor
TripAdvisor один из крупнейших в мире туристических сервисов, который не нуждается в представлении. По данным статьи, опубликованной The Telegraph, ежедневно на сайте появляется 165,600 новых отзывов о различных туристических объектах на разных языках.
Задача перевод отзывов туристов с английского на русский язык с качеством перевода, достаточным для того, чтобы понять смысл этого отзыва. Основная сложность: типичные особенности user generated content (тексты с ошибками, опечатками, пропусками слов).
Также частью задачи была автоматическая оценка качества перевода перед публикацией на сайте TripAdvisor. Так как ручная оценка всего переводимого контента невозможна, решение по машинному переводу должно предоставить автоматический механизм оценки качества переведенных текстов — confidence score, чтобы дать возможность TripAdvisor публиковать переведенные отзывы только высокого качества.
> Подробнее почитать о проекте можно на сайте компании.
Для решения была использована технология PROMT DeepHybrid, позволяющая получить более качественный и понятный конечному читателю перевод в том числе и за счет статистического постредактирования результатов перевода.
Посмотрим на примеры:
Оригинал: We ate there last night on a whim and it was a lovely meal. The service was attentive without being over bearing.
PROMT (Гибридный перевод): Мы ели там в последний вечер случайно, и это была прекрасная еда. Персонал был внимательным, но не властным.
GNMT: Мы ели там прошлой ночью по прихоти, и это была прекрасная еда. Обслуживание было внимательным, не будучи более подшипников.
Здесь все не так удручающе с точки зрения качества, как в предыдущем примере. И вообще, по своим параметрам эта задача потенциально может быть решена с применением нейронных сетей, и это может еще повысить качество перевода.
Проблемы использования NMT для бизнеса
Как уже говорилось ранее, «универсальный» переводчик не всегда дает приемлемое качество и не может поддерживать специфическую терминологию. Чтобы интегрировать в свои процессы и применять нейронные сети для перевода, нужно выполнить основные требования:
• Наличие достаточных объемов параллельных текстов для того, чтобы иметь возможность обучать нейронную сеть. Часто у заказчика их просто мало или вообще текстов по данной тематике не существует в природе. Они могут быть засекречены или находится в состоянии не очень пригодном для автоматической обработки.
Для создания модели нужна база, где содержится минимум 100 млн. токенов (словоупотреблений), а чтобы получить перевод более-менее приемлемого качества – 500 млн. токенов. Далеко не каждая компания обладает таким объемом материалов.
• Наличие механизма или алгоритмов автоматической оценки качества получаемого результата.
• Достаточные вычислительные мощности.
«Универсальный» нейронный переводчик чаще всего не подходит по качеству, а чтобы развернуть свою частную нейронную сеть, способную обеспечить приемлемое качество и скорость работы, требуется «маленькое облако».
• Непонятно, что делать с конфиденциальностью.
Не каждый заказчик готов отдавать свой контент для перевода в облако по соображениям безопасности, а NMT – это история в первую очередь облачная.
Выводы
• В общем случае нейронный автоматический перевод дает результат более высокого качества, чем «чисто» статистический подход;
• Автоматический перевод через нейронную сеть – лучше подходит для решения задачи «универсального перевода»;
• Ни один из подходов к МП сам по себе не является идеальным универсальным инструментом для решения любой задачи перевода;
• Для решения задач по переводу в бизнесе только специализированные решения могут гарантировать соответствие всем требованиям.
Мы приходим к абсолютно очевидному и логичному решению, что для своих задач по переводу нужно использовать тот переводчик, который максимально для этого подходит. Не важно, есть внутри нейронная сеть или нет. Понимание самой задачи – важнее.
https://arxiv.org/abs/1609.08144
https://research.googleblog.com/2016/09/a-neural-network-for-machine.html
https://slator.com/technology/nearly-indistinguishable-from-human-translation-google-claims-breakthrough/
https://slator.com/technology/hyperbolic-experts-weigh-in-on-google-neural-translate/
https://translator.microsoft.com/neural/
http://blog.systransoft.com/how-does-neural-machine-translation-work/
http://kv-emptypages.blogspot.ru/2016/09/a-deep-dive-into-systrans-neural.html
https://devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-with-gpus/
https://kv-emptypages.blogspot.ru/2010/03/need-for-automated-quality-measurement.html
http://kv-emptypages.blogspot.ru/2017/04/the-problem-with-bleu-and-neural.html
https://slator.com/technology/alibaba-launches-language-services-unit/
Комментарии (24)

mypallmall
10.06.2017 19:04Не можем сделать лучше конкурентов — будем их очернять!
Вперед! Правильный подход!mypallmall
10.06.2017 20:06Не каждый заказчик готов отдавать свой контент для перевода в облако по соображениям безопасности, а NMP – это история в первую очередь облачная.
Systran 10 раз подчеркивает, что перевод исключительно конфиденциален.
Они б иначе не выжили, учитывая кто их клиенты.mypallmall
10.06.2017 20:19По прошествию трех месяцев, после подключения русского языка к гугл транслейт — появилась ваша статья.
Надо так понимать, что в ближайшее время, скажем до конца 2017 года, нейронный перевод от Промт ждать не стоит?
PS. Хоть все это молодо-зелено, нейронный машинный перевод это NMT (Neural Machine Translation).
NMP это опечатка или несет какую-то смысловую нагрузку?
mypallmall
10.06.2017 21:01
boris_tikhomirov
12.06.2017 11:49На Translate.Ru Вы не найдете перевода, о котором написано в статье, потому, что речь о решении, которое специально настраивалось на клиента. Перевод в Google Translate тоже будет другим, если взять в учет регистр «ROUND TRIP INSTANT PURCHASE FARES», как обычно и пишут в правилах применения тарифов.
boris_tikhomirov
12.06.2017 11:30NMP — это опечатка, конечно. Спасибо, что заметили. Исправил.
Что касается нейронного перевода от PROMT, то он будет использоваться для наших клиентов на тех задачах, где качество сможет быть лучше, чем любой другой подход. Пока мы находимся на таком этапе, что наш подход позволяет более качественно решать конкретные задачи наших клиентов без применения нейронных сетей. Статья как раз об этом.
Но это не значит, что мы не занимаемся исследованиями и разработками в этом направлении.
huwesu
12.06.2017 11:20Не можем сделать лучше конкурентов — будем их очернять!
Вперед! Правильный подход!
1. Статья интересна и полезна по сути. В отличие от вашего комментария.
2. Это блог фирмы — они имеют право здесь писать про себя хорошо.
boris_tikhomirov
12.06.2017 11:45Никто никого не очерняет. Мы пишем, что нейронный переводчик Google лучше как универсальный переводчик. Тема секции на РИФе, где был этот доклад, была про нейронные сети в бизнесе, и обсуждался вопрос стоит ли бросаться и применять нейронки везде без разбору. Наш подход в том, что каждой задаче — своя технология.
eiennohito
11.06.2017 04:52+1В статье никак не отражено, что с приходом NMT системы машинного перевода стали гораздо _проще_ по внутренней структуре. И несмотря на это оно работает и показывает приличные результаты.
А так вообще — был бы корпус внутри домена — будет роскошный перевод.boris_tikhomirov
14.06.2017 10:55Не очень понятно, что именно Вы подразумеваете под «проще». Мне сложно что-то ответить. Тот факт, что в нейронной сети тренируется одна модель, а в статистическом движке и rule based может быть настройка нескольких компонентов, не делает нейронный переводчик более простым.
Тренировка нейронного переводчика требует больше ресурсов, чем статистический, и не только вычислительных, но и человеческих, иначе сложно сделать что-то приличное. Именно поэтому качественного результата тут по сути достиг пока только Google, у которых много корпусов, много ресурсов, и даже при этом они потратили несколько лет прежде, чем перейти со статистики на нейронку.eiennohito
14.06.2017 11:12Проще на мой взгляд как в плане кода (не нужно убиваться с экспоненциальным взрывом количества гипотез в декодере, например), так в плане того, что меньше компонентов. Статистические модели так же гораздо хуже работали для сильно непохожих друг на друга языков без использования всяких безумных моделей типа tree-to-tree/tree-to-string (английский-японский из близкого мне, например). Как пример, у нас в лаборатории группа машинного перевода за пару месяцев написали движок для нейросетевого перевода с нуля за пару месяцев и он работал сильно лучше старого статистического, который разрабатывали много лет.
То, что для нейросетей требуется больше текста — это конечно да. И что у него есть свои болячки — это тоже факт. Гугл же, насколько я понимаю его внутреннюю кухню, смог выпустить нейросетевой перевод в машинное плавание когда у них вычислительные ускорители стали доступны в большом количестве. В железо это дело сильно упирается и на обычных серверах выехать очень тяжело.
Но корпуса-то в любом случае собирать (и открывать) нужно.

iroln
11.06.2017 23:30Взял простое предложение из документации одного известного языка программирования.
The file must be kept open until the fault handler is disabled
PROMT:
Файл должен быть сохранен открытым, пока укладчик ошибки не искалечен
Google Translate:
Файл должен быть открыт до тех пор, пока не будет отключен обработчик ошибок
Не знаю ребята, чем вы там в Promt занимаетесь, какие у вас сейчас алгоритмы, но ваш перевод — отстой.
very-smarthome
12.06.2017 19:02Извините за тупость, но есть впечатление, что все раскрученные методы перевода идут не в особо том направлении. Все оценивают понятия слов с точки зрения компьютера, а что если попробовать встать на позицию человека?
Если сначала описать ситуацию, в которой происходит общение двух не понимающих друг друга пиплов. Например, дядя с тетей — туристы в прачечной беседуют про политику. Причем один из них англичанин.
Вот я как гомосапиенс сразу могу сказать, какие фразы будут употребляться и о чем. И в каком значении из 100 возможных будет стоять слово come on. И даже какой диалект лондонского англичанина будет непонятен русскому профессору с кафедры иностранных языков.
Мне кажется, надо в начало перевода серьезного текста сначала закладывать ту человекообразную среду, в которой осуществляется перевод.
Staratel20
12.06.2017 22:31Кто там вверху Промт ругал? ).
Строчка популярной некогда песни, прошу ввести в гугл и убедиться, потому как не очень пока разобрался как вставлять картинки(или скажем — куда их заливать чтобы ссылки через пару дней не оказались битыми):
You've might been hurt babe
Перевод(на 12.06.17):
Возможно, вы были больны младенцем
Staratel20
13.06.2017 09:39… или вот — из той же оперы(гугл):
pan fry industry
перевод:
сковородаmypallmall
14.06.2017 16:29Вы считаете Промт лучше? :)
pan fry industry — жареная промышленность кастрюли
You've might been hurt babe — У Вас есть сила малыш вреда
Гугл признает, что переводчик делает ошибки, которые человек в жизни бы не совершил.
Проверим качество через годик скажем.
Что, сильно огорчило, судя по статье — Промт еще даже не принял решения подключать NMT.
Такое сложилось впечатление, после статьи. Надеюсь ошибаюсь.
Просветите, pan fry industry — это что такое?
Поиск ничего внятного не выдал pan fry industryRom77
14.06.2017 22:52Просветите, pan fry industry — это что такое?
Поиск ничего внятного не выдал pan fry industry
+1. Тоже интересно.
Кстати, казалось бы невинное изменение первой буквы на заглавную или добавление в конец этой фразы разных посторонних символов с клавиатуры, ведет к невероятным метаморфозам перевода у гугла.
boris_tikhomirov
14.06.2017 23:00Мы приняли решение не использовать NMT без разбору везде, где только ни появится задача перевода. Наш подход в том, что каждой задаче — своя технология. Мы сейчас используем активно rule based перевод, статистический перевод или технологию Deep Hybrid — в зависимости от задач клиента. И на тех задачах, где нейронные сети будут давать выигрыш в качестве, будем использовать их. Исследования в эту сторону тоже идут.
Staratel20
17.06.2017 02:02Должен извинится что несколько ввел народ в заблуждение — на самом деле French fry industry — взято из аудиокурса по английскому Effortless English, топик Eat your vegetables(кстати курс весьма неплох на мой взгляд). В памяти вместо French почему то отложилось pan )). Но с заменой результат не намного лучше, — перевод Гугл:
Французская жаркая промышленность
а как правильно мне и самому интересно. По тексту там понятно что это промышленность которая занимается обжаркой овощей [а потом продает их как свежие]. вообще смысл текста весьма любопытный, рекомендую послушать))
ЗЫ: пусть не покажется что я качу бочку на движок перевода Гугл. несмотря на все косяки он часто очень выручает, и я понимаю сколько труда стоит за тем, чтобы создать нечто подобное(к Промту это тоже относится). а критиковать как известно — дело нехитрое.
mypallmall
14.06.2017 16:35И вообще, на данном этапе речь о литературном (художественном) переводе не идет.
cepera_ang
Измерять популярность чего-либо только по трендам гугл — это сильная натяжка. Надо полагать что исследователи не гуглят темы своих работ, а наоборот, поиски в гугле появляются только после публикаций, особенно в обычной популярной прессе.
Теперь к вопросу качества перевода:
> ROUND TRIP INSTANT PURCHASE FARES
> КРУГЛЫЕ ПОЕЗДКИ МГНОВЕННЫЕ ПОКУПКИ
О боже, ужас! ПЕРЕВОД НИКУДА НЕ ГОДИТСЯ.
> Round trip instant purchase fares.
> Билеты на рейс в оба конца.
Ой, что это, небольшое изменение формы и приведение её к более подходящей для нейросети даёт кардинально отличный результат, как же так?
> Round trip instant purchase fares
> Тарифы за мгновенную оплату в оба конца
Хм, если убрать точку, то форма становится какой-то корявой, но смысл передан довольно неплохо.
cepera_ang
We ate there last night on a whim and it was a lovely meal. The service was attentive without being over bearing.
== Мы ели там прошлой ночью по прихоти, и это была прекрасная еда. Служба была внимательной, не будучи чрезмерной.
Никаких подшипников, у вас точно тот гугл транслейт?
Shortki
Элементарно! Нейронная сеть обучаема — google прочёл этот пост и оперативно внес исправления.
kryvichh
Вы все правильно пишете. В соответствии с правилами русского языка, с заглавных букв пишутся только аббревиатуры, а в конце предложения ставится точка. Если исходный текст не соответствует этим правилам, нужно делать какой-то препроцессор, и уже потом скармливать текст Гугл Транслейту.