
Трем программистам предложили пересечь поле, и дойти до дома на другой стороне. Программист-новичок посмотрел на короткую дистанцию и сказал, «Это не далеко! Это займет у меня десять минут». Опытный программист посмотрел на поле, немного подумал, и сказал: «Я мог бы добраться туда за день». Новичок посмотрел на него с удивлением. Гуру-программист посмотрел на поле и сказал. «Кажется минут десять, но я думаю пятнадцати будет достаточно». Опытный программист рассмеялся.
Программист-новичок двинулся в путь, но в течение нескольких мгновений, начали взрываться мины, оставляя после себя большие ямы. От взрывов он отлетал назад, и ему приходилась начинать сначала снова и снова. У него ушло два дня чтобы достичь цели. К тому же он весь трясся и был ранен, когда пришел.
Опытный программист пополз на четвереньках. Осторожно щупая землю и ища мины, двигаясь только если был уверен, что это безопасно. Медленно и осторожно он пересек поле в течение дня. Только задев пару мин.
Гуру программист пустился в путь, и пошел прямо через поле. Целеустремленно и прямо. Он достиг цели всего за десять минут.
«Как тебе это удалось?» — спросили двое других — «Как ты умудрился не зацепить ни одной мины?»
«Легко.» — ответил он. «Я не закладывал мины на своем пути».
Как ни прискорбно, придется признать – мы сами закладываем себе мины. В первой части я подробно разобрал основные риски в разработке ПО и описал технологические и методологические способы ослабления этих рисков. За прошедший год я получил множество комментариев, основной смысл которых сводился к следующему: «все круто, но с чего начать и как все это будет выглядеть в реальном мире». Действительно, первый текст носит скорее теоретический характер и представляет собой каталог ссылок. В этой статье я постараюсь привести как можно больше примеров.
Программистам, не обладающим достаточным опытом, многие проблемы, описанные в первой статье, могут быть не понятны, ведь они проявляются только в long run’е: нет большой разницы как написан сайт на десять страничек с парой формочек для фильтрации и CRUD-админкой, если весь код можно переписать с нуля за пару дней. Но что произойдет через полтора-два года?
Наш сайт начинает развиваться, появляется новая функциональность, страничек и формочек становится уже несколько десятков, добавляются партнерки с внешними ресурами. Мы дали рекламу в паблике-миллионике «Вконтакте» и главная страница «сложилась» под нагрузкой. Не беда, втыкаем кеш. Теперь нужно побыстрее запартнериться с дружественным сервисом. Копипастим код интеграции с партнером из его кодовой базы, пишем хранимки для синхронизации «наших» и «внешних» данных.
Начинаются изменения в бизнес-правилах, которые приходится дублировать в коде хранимок и в предметной области, кеш главной страницы нужно периодически обновлять, количество багов и конфигурационных проблем в беклоге растет.
Проходит 6-7 итераций изменения бизнес правил, интеграций, оптимизаций производительности и расширения функциональности и вот уже у нас чудовище Франкенштейна, сшитое из примеров кода со Stack Overflow, кода SDK партнеров, костылей и хотпатчей, разнообразных невероятно полезных 3rd party – компонентов и собственных велосипедов.
Основные проблемы, которые мне приходится исправлять в коде 2-3 летней давности
- повторение boiler-plate-кода (всевозможные using, try-catch, log и т.д.): затрудняет внесение изменений в кодовую базу и рефаторинг, незаметно съедает время на написание одинаковых конструкций (секунды в начале проекта, дни — через год-два существования кодовой базы)
- дублирование кода, в т.ч неявное, бездумное создание одинаковых классов Entity, DTO и ViewModel, дублирование Linq-запросов, создание однотипных интерфейсов ITEntityRepository: IRepository<TEntity>, имеющих только одну реализацию
- нарушение SRP: запихивание в Entity свойств из разных контекстов и даже не связанных с домменной моделью, создание разнообразных Manager’ов, Service’ов и Helper’ов с невнятной ответственностью
- нарушение LSP
- NullReferenceException
- ошибки в данных
- создание обратной связи, перемешивание слоев приложения, инфраструктурного кода и кода доменной модели
Обычно оправданием всему этому безобразию служат:
- cжатые сроки релиза
- отсутствие времени на рефакторинг
- отсутствие времени на планирование и проектирование (какая архитектура? фигачить надо!)
В целом, все это правдиво, но нужно признать, что даже опытным разработчикам зачастую не хватает «мат-части», чтобы быстро принимать верные решения. Под верными я понимаю следующее положение вещей: на 80% вы пишете код, выполняющий бизнес-кейс, а на 20% — небольшой задел на будущее, каждый раз угадывая какие именно 20% надо написать (иначе говоря, как изменятся требования). Чтобы угадывать, что захотят стейкхолдеры (как будет изменяться доменная модель приложения) обычно требуется опыт управленческой работы и/или опыт работы в предметной области.
Однако есть ряд требований, возникающих во многих растущих проектах:
- многопользовательский доступ (печально известный хабра-эффект), подсчет просмотра показов, лайков и т.д.
- аналитика и персонализация (построение воронок продаж, анализ пользовательских предпочтений с целью предложить более релевантный контент)
- полнотекстовый поиск
- выполнение отложенных задач и задач по расписанию
- фильтрация, преобразование и постраничный вывод данных
- логирование, система нотификаций, мониторинг, само-диагностика, само-восстановление после сбоев и обработка ошибок
В этой статье я подробно остановлюсь на отделение домена (бизнес-правил) от инфраструктуры приложения. Всякое AOP, динамическую компиляцию и прочую магию оставим на следующий раз.
10 слоев приложения должны быть достаточно каждому
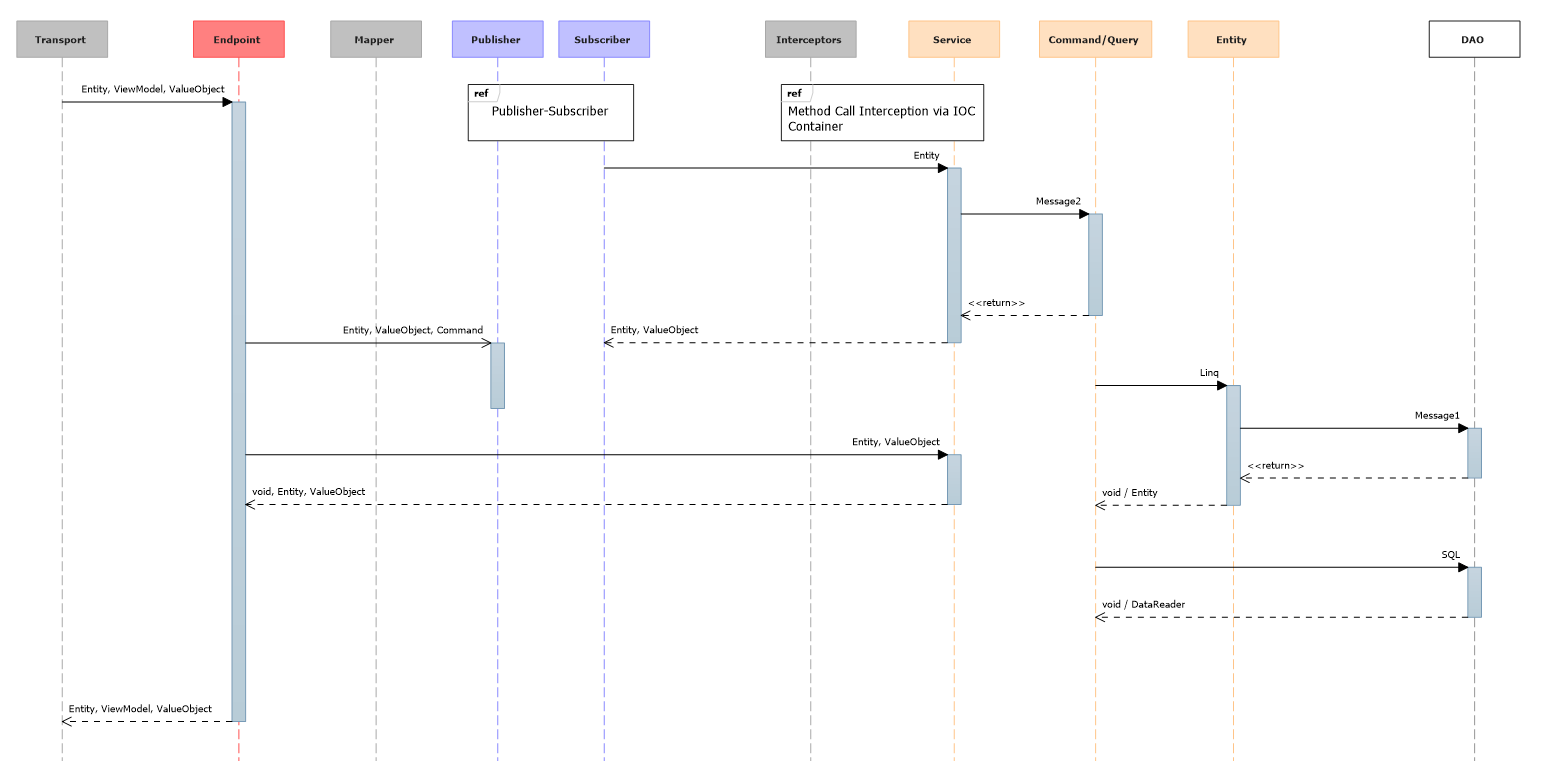
Для «обычного веб-приложения в вакууме» я насчитал максимум 10 слоев. Много это или мало? Учитывая, что можно «срезать углы» и обойтись классическими тремя, думаю, что в самый раз. Выносим за скобки эндпоиты, дейта-маппер, паблишер-сабскрайбер, интрецепторы. Остались:
- Сервисы
- Command/Query
- Entity
- DAO
Для того, чтобы расставить все по местам начнем с самого простого случая веб-приложения – лендинг пейдж.
Целевая страница (англ. «landing page») — веб-страница, построенная определенным образом, основной задачей которой, является сбор контактных данных целевой аудитории. Используется для усиления эффективности рекламы, увеличения аудитории...
У нас есть одна страничка и она собирает «лидов». У лида должен быть email. Необязательными полями на форме будут телефон и имя. Создадим класс «лида»:
public interface IEntity
{
string GetId();
}
public class Lead : IEntity
{
public static Expression<Func<Lead, bool>> ProcessedRule = x => x.Processed;
private string _email;
[Key, Required, Index("IX_Email", 1, IsUnique = true)]
public string Email
{
get { return _email; }
set
{
if (string.IsNullOrEmpty(value))
{
throw new ArgumentNullException("email");
}
_email = value;
}
}
public string Phone { get; set; }
public bool Processed { get; set; }
public DateTime CreatedDate { get; set; }
[Obsolete("Only for model binders and EF, don't use it in your code", true)]
internal Lead()
{
}
public Lead([NotNull] string email, string phone = null)
{
Email = email;
Phone = phone;
CreatedDate = DateTime.Now;
}
public bool IsProcessed()
{
return this.Is(ProcessedRule);
}
public string GetId()
{
return Email;
}
}
Entity, Rich Domain Model и защитное программирование (aka инкапсуляция)
Полемика: samolisov.blogspot.ru/2012/10/anemic-domain-model.htmlЯ сторонник богатой доменной модели (Rich Domain Model) и не люблю анемичную, поэтому Lead обладает правильным конструктором и не дает перевести себя в несогласованное состояние (нарушить инвариант). Современные ORM-фреймворки, чьи предки породили анемичные модели, уже позволяют соблюдать принципы инкапусляции (ну почти). На помощь приходит модификатор доступа internal. Специально для тех, кто не моет руки и внутри домменной сборки использует конструктор по-умолчанию есть атрибут [Obsolete]. Второй параметр сломает билд при попытке использовать этот конструктор в явном виде, при этом ваши ORM и ModelBinder спокойно воспользуется этим конструктором.
[Obsolete("Only for model binders and EF, don't use it in your code", true)]
internal Lead()
{
}
public Lead([NotNull] string email, string phone = null)
{
Email = email;
Phone = phone;
CreatedDate = DateTime.Now;
}
Гарантии, что джуниор не уберет его конечно нет, но такие вещи можно решить в ходе код-ревью.
Свойства в .NET придумали не только для того, чтобы мапить их на бд. При такой организации кода вы упадете именно в том месте, где попытаетесь установить не верный email, а не при сохранении в БД, которое может быть очень далеко от момента простановки значения, особенно при массовых операциях.
[Key, Required, Index("IX_Email", 1, IsUnique = true)]
public string Email
{
get { return _email; }
set
{
if (string.IsNullOrEmpty(value))
{
throw new ArgumentNullException("email");
}
_email = value;
}
}
В конструкторе также используется свойство Email, так что инвариант надежно защищен.
Мне так работать проще, отсюда вытекает правило – Code First. Сначала я пишу модель предметной области, а потом создаю авто-миграцию (поэтому использую Entity Framework) и выполняю ее.
С моей точки зрения, нет ничего зазорного в том, чтобы заменить доступ конструктору без параметров на публичный (public) и писать так, не создавая лишних однотипных DTO и ViewModel:
[HttpPost]
public ActionResult Index(Lead lead)
{
if (!ModelState.IsValid)
{
return View(lead);
}
//…
}
При выполнении условий:
- класс Lead не является корнем аггрегации
- форма заявки имеет отображение на класс лида один к одному
- конструктор без параметров защищен атрибутом Obsolete
В противном случае, следует создать DTO и/или ViewModel и использовать DataMapper.
Монада Maybe
Пока Visual Studio 2015 с новыми операторами выходит из CTP, эта монада помогает поддерживать код читабельным. Использование Maybe в паре с JetBrains.Annotations и Possible NullReferenceException as error в R# гарантирует отсутствие NullReferenceException в вашем коде. Фактически, это реализация паттерна NullObject в функциональном стиле.Разделение бизнес-логики и инфраструктуры (DDD)
Основная полемика вокруг DDD крутится вокруг следующих тезисов:- cлишком мало публично-доступных примеров с DDD в сети, не понятно, что это вообще такое
- что считать доменом, а что инфраструктурой
- DDD – очень долго и дорого, по сравнению с методологией «оп-оп, готов код»
Прочтение книги Эванса стало для меня вторым крутым поворотом в понимании кода, после The Art of Unit Testing. За 10 лет в разработке ПО, я успел насмотреться на большое количество кодовых баз. Слава богу, уже на всех платформах есть базовая платформа (фрейморк) и пакетный менеджер и никому не приходит в голову писать свой MVC-фреймворк с блекджеком и куртизанками.
Однако, бизнес-логику можно найти в самых разнообразных местах приложения: в хранимых процедурах, helper’ах, manager'ах, service'ах, теле контроллеров, репозиториях, linq-запросах. В отсутствии четкого регламента каждый разработчик будет организовывать бизнес-логику в соответствии со своими представлениями о прекрасном. Это создает целую кучу проблем:
- непонятно где искать бизнес-правило
- невозможно внятно ответить на вопрос, каково покрытие тестами кода доменной модели,
- код тяготеет к процедурному стилю, нарушается инкапсуляция
- есть опасность продублировать бизнес-правило в двух или более местах (например, в c#-коде и коде хранимой процедуры. При изменении требований с большой вероятностью вспомнят поменять правило только в одном месте. В итоге расхождение останется и может всплыть через несколько месяцев. Разбираться с проблемой будут уже другие люди и не факт, что они знают, как «должно быть правильно». Кроме этого, manager’ы и helper’ы – классы с невнятной ответственностью, с большой вероятностью превращающиеся со временем в God-object’ы
- никак не регламентируются зависимости между сборками. Классы доменных моделей с легкой руки junior’а запросто могут начать зависеть от веб-контекста и сборки Common.Web
На более высоком уровне это выливается в:
- замедление темпов разработки, вплоть до состояния, когда вся команда фулл-тайм занята поддержкой и ликвидацией багов
- постоянный багфиксинг и костылинг
- необходимость выделения дополнительных ресурсов на поддержку и устранения ошибок в базе данных приложения
Для меня DDD Эванса – это способ стандартизировать работу с бизнес-логикой. DDD предлагает набор паттернов для этого. Давайте рассмотрим основные из них. Заодно «поженим» их с еще одной «модной» концепцией – CQRS.
Как это связано с DDD?
DDD говорит намEntity
public interface IEntity
{
string GetId();
}
Сущностью называется все что угодно, обладающее уникальным идентификатором. Два гвоздя в мешке – не Entity, потому что нельзя отличить один от другого. С точки зрения домена они идентичны. А вот Вася и Петя для нашей налоговой – Entity. У них есть ИНН (идентификационный номер налогоплательщика).
В современных приложениях в качестве Id чаще всего выступает автоинкрементируемое целочисленное значение или GUID. Не смотря на распространенность этого подхода, в ряде случае он может создавать ситуации, требующие специальной обработки. Если вы когда-нибудь покупали авиабилеты у аггрегатора, то знаете, что номер бронирования аггрегатора может не совпадать с номером бронирования авиаперевозчика. Это происходит из-за того, что у перевозчика своя ИТ-система, а у аггрегатора – своя.
Вернемся к примеру с лендинг пейдж и лидом. Моя реализация IEntity наиболее абстрактная – это метод, возвращающий Id в виде строки. Я намеренно использую метод, а не свойство. Все свойства класса Lead мапятся на поля БД. Это поможет избежать неоднозначности и необходимости подсматривать в маппинг. Первичным ключом выступает Email, а не Id. Если бы я реализовал Id свойством, мне бы пришлось явно указывать, что свойство Id мапится на поле Email в БД, кроме этого, это бы создало проблемы с первичными ключами других типов (целочисленными и guid’ами)
public class Lead : IEntity
{
private string _email;
[Key, Required, Index("IX_Email", 1, IsUnique = true)]
public string Email
{
get { return _email; }
set
{
if (string.IsNullOrEmpty(value))
{
throw new ArgumentNullException("value");
}
_email = value;
}
}
public string Phone { get; set; }
public bool Processed { get; set; }
public DateTime CreatedDate { get; set; }
// IEntity Implementation
public string GetId()
{
return Email;
}
Я уже говорил, что использую в качестве основновной, но не единственой, ORM Entity Framework. Основные причины:
- автоматическая генерация миграций (экономит кучу времени и освобождает от написания рутинного кода)
- лучшая в .NET поддержка linq
- развивается быстрее, чем NHibernate
- поддерживает DataAnnotation-атрибуты для маппинга данных и создания миграций
Fluent mapping VS Atribute mapping
На вкус и цвет все фломастеры конечно разные. Fluent mapping чище и позволяет не тащить EF в зависимости доменной сборки, но мне не нравится его многословность и необходимость поддерживать 2 класса: сущности и маппинга. Кто-то может сказать, дескать это нарушение SRP. Мое мнение – атрибуты не императивный код и такое сравнение не корректно. Я вижу разницу лишь в форме записи и лишней зависимости от EF, которая, впрочем, легко выпиливается при необходимости.Persistance ignorance
Итак, у нас есть доменные сущности и их нужно создавать, обрабатывать, сохранять, фильтровать, получать из какого-то источника данных и удалять. В простонародье это называется CRUD-операциями. Создать сущность мы можем с помощью оператора new, не забывая о том, что использовать нужно «правильный» конструктор, не нарушающий инвариант объекта. Конструктор по-умолчанию мы объявили только для поддержки ORM и защитились от грязных рук атрибутом [Obsolete].Как мы можем сохранить объект и получить из источника данных? В современных фреймворках используется два подхода: Active Record(AR) и Unit of Work(UoW). Я категорический противник Active Record’а. Возможно, что в интерпретируемых ЯП AR и дает преимущества, но не в компилируемых. AR самым безобразным образом нарушает SRP, добавляя всем Entity метод Save. Задача Entity – реализация бизнес-логики и инкапсуляция данных, а никак не сохранение себя в БД. Поэтому, мой выбор – UoW.
public interface IUnitOfWork: IDisposable
{
void Commit();
void Save<TEntity>(TEntity entity)
where TEntity : class, IEntity;
void Delete<TEntity>(TEntity entity)
where TEntity : class, IEntity;
}
Для EF реализацией UoW будет DataContext вашего приложения. Однако, сам DataContext торчать в доменные сборки не будет. Во-первых, зачем нам тут зависимость от EF? Во-вторых достаточно часто требуется реализовать Bounded Context, чтобы разделить команды разработчиков, при этом миграции лучше оставить в пределах одного DataContext, чтобы исключить вариант рассинхронизации схемы данных.
Как сохранять, редактировать и удалять понятно. Осталась функция получения данных. Традиционно эта функция реализуется с помощью репозиториев. И традиционно реализуется «коряво». Подробно проблемы описаны в статье «проблемный шаблон репозиторий».
Если коротко, сначала вы делаете так:
public interface IRepository<T>
{
T GetById(int id);
IEnumerable<T> GetAll();
bool Add(T entity);
bool Remove(T entity);
}
В итоге получается так:
class AccountRepository : IRepository<Account>
{
public Account GetByName(string name);
public Account GetByEmail(string email);
public Account GetByAge(int age);
public Account GetByNameAndEmail(string name, string email);
public Account GetByNameOrEmail(string name, string email);
// ...
public Account GetByAreYouFuckingKiddingMe(SomeCriteria c);
}
Вы выходите из положения вот так (вариант с extension-методами я не рассматриваю, по причинам, изложенным ниже):
public interface IRepository<T>
{
T GetById(int id);
//во имя луны
IQueryable<T> Query();
bool Add(T entity);
bool Remove(T entity);
}
Но обламываетесь вот так:
// было такое бизнес-правило
repo.Query().Where(a => a.IsDeleted = false);
// а стало такое, ищите теперь эти лямбды по всему приложению
repo.Query().Where(a => a.IsDeleted = false && a.Balance > 0);
// runtime error
repo.Query().Where(a => a.CreationDate < getCurrentDate());
В последнем примере первые два linq-запроса иллюстрирует изменения бизнес-правила «активный аккаунт». Сначала мы считали активными не удаленные, а потом добавилось требование «баланс должен быть больше нуля». Так как linq-запросы очень легко писать с большой вероятностью они будут скопипащены в десятке мест кодовой базы. Почти наверняка где-то поменяют, а где-то забудут.
Третий пример отлично скомпилируется, но грохнется на этапе выполнения, потому что ORM не поймет как транслировать вашу функцию getCurrentDate в SQL. Если время поджимает, а таск достался junior’у, он быстренько «допилит» код напильником вот так:
repo.Query().ToEnumerable().Where(a => a.CreationDate < getCurrentDate());
И все 3 миллиона аккаунтов поднимутся в оперативную память.
Есть еще неявные проблемы с предоставлением IQueryable наружу:
- IQueryable «протекает» и явно нарушает LSP. Единственная реализация IQueryable, которая «переварит» любые экспрешны, которые вы ей скормите – это in-memory. Но для in-memory у вас есть linq2object, что лишает IQueryable всякого смысла. Любой Where-запрос – потенциальная точка отказа вашего кода
- Не все источники данных поддерживают linq. В какой-то момент вам захочется полнотекстового поиска, а с ним Sphinx’а или Elastic’а. Я сомневаюсь, что предложения «давайте напишем свой linq-провайдер» найдут отклик у менеджмента (и правильно, кстати). Полнотекстом дело не ограничивается, данные могут прийти по сети, храниться на диске, в облачной файловой системе и еще много где
- Даже если в качестве источника данных выступает база данных, возможно в целях производительности часть данных находятся в денормализованном виде или перенесена в NOSQL-решение. Возможно, что придется писать запросы руками и тюнить все по-максимуму, в т.ч. маппинг объектов
Первая проблема не решается в принципе. Это заложено в linq by-design. И грех жаловаться, linq – это очень удобно. Пункты два и три как-бе намекают, что IQueryable — не подходит в качестве абстракции на все случаи жизни, потому что в реальном мире еще не все .NET-разработчики с пол-пинка разбирают деревья выражения и в течение дня пишут свой linq-провайдер на любой источник данных.
Хорошо, что все уже придумали за нас
Specification aka Filter
public interface ISpecification<in T>
where T:IEntity
{
bool IsSatisfiedBy(T o);
}
public interface IRepository<T>
{
T GetById(int id);
//во имя луны
IEnumerable<T> GetBySpecification(ISpecification<T> spec);
bool Add(T entity);
bool Remove(T entity);
}
Спецификация – это бизнес-правило фильтрации. Всего один метод, либо объект удовлетворяет условию, либо – нет. В текущем виде спецификация решает проблему дублирования кода: теперь у вас нет Linq и на каждое правило фильтрации придется написать свой класс спецификации.
Но, позвольте, зачем это нужно? Мы не можем транслировать IsSatisfiedBy в SQL, а значит, снова придется поднимать все записи из БД и фильтровать по ним. Теперь нам нужно писать спецификацию на каждый чих, а значит создавать множество классов, используемых ровно один раз (в том месте интерфейса, где нужно отфильтровать данные определенным образом).
Действительно, ведется целая дискуссия, дескать паттерн «спецификация» устарел с появлением linq.
Первое, что предлагают астронавты архитектуры:
public interface IExpressionSpecification<T> : ISpecification<T>
where T:class,IEntity
{
Expression<Func<T, bool>> Expression { get; }
}
public interface IRepository<T>
{
T GetById(int id);
//во имя луны
IEnumerable<T> GetBySpecification(IExpressionSpecification<T> spec);
bool Add(T entity);
bool Remove(T entity);
}
Не нужно обладать сверх-способностями, чтобы увидеть те-же яйца, вид в профиль с дополнительной ненужной прослойкой в виде спецификации. Тем более, что проблему дублирования linq-запросов в коде можно изящно решить вот так:
public class Account : IEntity
{
[BusinessRule]
public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0;
}
В итоге
- репозиторий не получится эффективно использовать в качестве базовой абстракции для всех источников данных
- linq – это очень удобно, но подходит не везде по экономическим причинам или ограничениям производительности
CQ[R]S – Command, Query [Responsibility] Segregation
Или по-русски разделение чтение и записи. Наибольшее применение принцип нашел в нагруженных системах. Классический пример – фид в социальных сетях: необходимо вытащить данные из кучи таблиц для всех ваших друзей и не забыть учесть как все лайкают и репостят ваши фоточки. Классическая реализация для этой задачи не подходит – слишком много джоинов и блокировок чтения/записи.Обычное решение – разделить чтение и запись, чтобы избежать блокировок. Стратегии деноромализации могут быть разные, но основной смысл сводится к:
- избавится от джоинов, читать плоские данные
- избегать блокировок чтение/запись
- синхронизировать данные «в фоне», накапливая изменения
Таким образом, классический репозиторий разделяется на два интерфейса: Command и Query.
Command реализует добавление, изменение и удаление, а Query – чтение данных.
public interface IQuery<TEntity, in TSpecification>
where TEntity : class, IEntity
where TSpecification : ISpecification<TEntity>
{
IQuery<TEntity, TSpecification> Where([NotNull] TSpecification specification);
IQuery<TEntity, TSpecification> OrderBy<TProperty>(
[NotNull] Expression<Func<TEntity, TProperty>> expression,
SortOrder sortOrder = SortOrder.Asc);
IQuery<TEntity, TSpecification> Include<TProperty>([NotNull] Expression<Func<TEntity, TProperty>> expression);
[NotNull]
TEntity Single();
[CanBeNull]
TEntity FirstOrDefault();
[NotNull]
IEnumerable<TEntity> All();
[NotNull]
IPagedEnumerable<TEntity> Paged(int pageNumber, int take);
long Count();
}
public interface ICommand
{
void Execute();
}
public interface ICommand<in T>
{
void Execute(T context);
}
public interface IPagedEnumerable<out T> : IEnumerable<T>
{
long TotalCount { get; }
}
public class CreateEntityCommand<T> : UnitOfWorkScopeCommand<T>
where T: class, IEntity
{
public override void Execute(T context)
{
UnitOfWorkScope.GetFromScope().Save(context);
UnitOfWorkScope.GetFromScope().Commit();
}
public CreateEntityCommand([NotNull] IScope<IUnitOfWork> unitOfWorkScope)
: base(unitOfWorkScope)
{
}
}
public class DeleteEntityCommand<T> : UnitOfWorkScopeCommand<T>
where T: class, IEntity
{
public DeleteEntityCommand([NotNull] IScope<IUnitOfWork> unitOfWorkScope)
: base(unitOfWorkScope)
{
}
public override void Execute(T context)
{
UnitOfWorkScope.GetFromScope().Delete(context);
UnitOfWorkScope.GetFromScope().Commit();
}
}
Основная обязанность Query транслировать спецификацию (доменное правило фильтрации) в запрос к источнику данных (инфраструктура). Query предоставляет абстракцию от источника данных – нам не важно откуда мы получаем данные, а спецификация – это своеобразный linq+. Для источников данных, поддерживающих linq можно использовать ExpressionSpecification. В случаях, когда использование linq затруднено (нет провайдера, например как в случае с Elastic Search), выкидываем Expression’ы и используем свою спецификацию.
public interface IExpressionSpecification<T> : ISpecification<T>
where T:class,IEntity
{
Expression<Func<T, bool>> Expression { get; }
}
public static IQuery<TEntity, IExpressionSpecification<TEntity>> Where<TEntity>(
this IQuery<TEntity, IExpressionSpecification<TEntity>> query,
Expression<Func<TEntity, bool>> expression)
where TEntity : class, IEntity
{
return query.Where(new ExpressionSpecification<TEntity>(expression));
}
Для фильтрации данных в оперативной памяти можно использовать экземпляр спецификации, а трансляция спецификации в запрос к источнику данных ложиться на Query.
ICommandFactory, IQueryFactory
Создание большого количества маленьких объектов command и query может быть утомительным занятием, логично зарегистрировать их в IOC-контейнере по конвеншнам. Чтобы не тащить ваш контейнер во все сборки и не создавать ServiceLocator, возложим эту обязанность на фабрики. public interface ICommandFactory
{
TCommand GetCommand<TEntity, TCommand>()
where TCommand : ICommand<TEntity>;
T GetCommand<T>()
where T : ICommand;
CreateEntityCommand<T> GetCreateCommand<T>()
where T : class, IEntity;
DeleteEntityCommand<T> GetDeleteCommand<T>()
where T : class, IEntity;
}
public interface IQueryFactory
{
IQuery<TEntity, IExpressionSpecification<TEntity>> GetQuery<TEntity>()
where TEntity : class, IEntity;
IQuery<TEntity, TSpecification> GetQuery<TEntity, TSpecification>()
where TEntity : class, IEntity
where TSpecification : ISpecification<TEntity>;
TQuery GetQuery<TEntity, TSpecification, TQuery>()
where TEntity : class, IEntity
where TSpecification: ISpecification<TEntity>
where TQuery : IQuery<TEntity, TSpecification>;
}
Тогда работа с query будет выглядеть так
_queryFactory.GetQuery<Product>()
.Where(Product.ActiveRule) // это статический экспрешн, как в примере с Account. Используется ExpressionSpecification
.OrderBy(x => x.Id)
.Paged(0, 10) // получаем 10 продуктов для первой страницы
// Мы решили подключить полнотекстовый поиск и добавили ElasticSearch, не вопрос:
_queryFactory.GetQuery<Product, FullTextSpecification>()
.Where(new FullTextSpecification(«зонтик»))
.All()
// Или EF тормозит и мы решили переделать на хранимую процедуру и Dapper
_queryFactory.GetQuery<Product, DictionarySpecification, DapperQuery>()
.Where(new DictionarySpecification (someDirctionary))
.All()
Во всех случаях мы используем один и тот-же код, а конструкция _queryFactory.GetQuery<Product, DictionarySpecification, DapperQuery>() явно указывает нам на то, что это оптимизация. Эта строчка появилась в коде только в ходе эволюционного рефакторинга, потому что сначала мы писала на ORM, ради скорости разработки. Если в команде есть человек, хорошо разбирающийся в деревьях выражений, постепенно можно перевести все запросы на linq (хотя в реальной жизни это почти невозможно по экономическим соображениям).
В случае с _queryFactory.GetQuery<Product, FullTextSpecification>() мы указываем «полнотекстовую спецификацию», однако доменный код ничего не знает о том, что возвращаемый экземпляр – ElasticSearchQuery. Для него это просто правило фильтрации «полнотекстовый поиск».
Полемика на тему: habrahabr.ru/post/125720
Немного синтаксического сахара
Вернемся к примеру:public class Account : IEntity
{
[BusinessRule]
public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0;
bool IsActive()
{
// как не дублировать код здесь???
}
}
Бизнес-правило «активный аккаунт» находится в логичном месте и переиспользуется. Не нужно бояться, разбросанных по всему проекту лямбд.
Иногда это требование нужно в виде Expression<Func<Lead, bool>> — для трансляции в запрос к источнику данных, а иногда в виде Func<Lead, bool>> — для фильтрации объектов в памяти и предоставления свойств, вроде IsActive. Создание класса спецификации на каждый чих не кажется хорошей идеей. Когда можно использовать следующую реализацию:
public static class Extensions
{
private static readonly ConcurrentDictionary<Expression, object> _cachedFunctions
= new ConcurrentDictionary<Expression, object>();
public static Func<TEntity, bool> AsFunc<TEntity>(this object entity, Expression<Func<TEntity, bool>> expr)
where TEntity: class, IEntity
{
if (!_cachedFunctions.ContainsKey(expr))
{
_cachedFunctions[expr] = expr.Compile();
}
return (Func<TEntity, bool>) _cachedFunctions[expr];
}
public static bool Is<TEntity>(this TEntity entity, Expression<Func<TEntity, bool>> expr)
where TEntity: class, IEntity
{
return AsFunc(entity, expr).Invoke(entity);
}
public static IQuery<TEntity, IExpressionSpecification<TEntity>> Where<TEntity>(
this IQuery<TEntity, IExpressionSpecification<TEntity>> query,
Expression<Func<TEntity, bool>> expression)
where TEntity : class, IEntity
{
return query
.Where(new ExpressionSpecification<TEntity>(expression));
}
}
public class ExpressionSpecification<T> : IExpressionSpecification<T>
where T:class,IEntity
{
public Expression<Func<T, bool>> Expression { get; private set; }
private Func<T, bool> _func;
private Func<T, bool> Func
{
get
{
return this.AsFunc(Expression);
}
}
public ExpressionSpecification([NotNull] Expression<Func<T, bool>> expression)
{
if (expression == null) throw new ArgumentNullException("expression");
Expression = expression;
}
public bool IsSatisfiedBy(T o)
{
return Func(o);
}
}
public class Account : IEntity
{
[BusinessRule]
public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0;
bool IsActive()
{
this.Is(ActiveRule);
}
}
А где Service’ы, Manager'ы и Helper’ы?
При правильной организации код, никаких helper’ов в домене у вас нет. Может быть в слое представления что-то такое есть. Manager и Service – суть одно и тоже, поэтому название Manager лучше вообще не использовать. Service – это чисто технический термин. Используйте Service только как постфикс или не используйте вовсе (оставьте только namespace для того, чтобы зарегистрировать по соглашениям в IOC).В реальном бизнесе нет «сервисов», есть «кассы», «проводки», «квоты» и всякое такое. Так что лучше группировать вашу бизнес-логику и именовать классы сообразно домену приложения и создавать только по мере необходимости. Для CRUD-операций не нужны никакие сервисы. Связки UoW+Command+Query+Specification+Validator хватит, чтобы закрыть 90% потребностей учетных систем. Кстати, для этого нужен только один класс контроллера.
Заключение
Подобная архитектура может показаться «перегруженной». Действительно подобный подход накладывает определенные ограничения:- квалификация разработчиков: требуется понимание паттернов программирования и хорошее знание платформы
- первоначальные вложения в код инфраструктуры (мне потребовалось почти 4 дня фулл-тайм для того, чтобы вытащить интерфейсы из своих проектов, отвязать ненужные зависимости и сделать инфраструктуру максимально абстрактной и легковесной, под нож пошло много кода)
- именно эта сборка еще только проходит испытание в реальном проекте, у меня на руках нет метрик и гарантий в том, что данный подход дает выигрыш в производительности за счет стандартизации (хотя субъективно, я в этом уверен на все 100%)
Преимущества
- четкое отделение домена от инфраструктуры
- минимизация объема кода в проекте, устранение дублирования кода, устранение циклических зависимостей, устранение рутины, использование соглашений, вместо избыточных конфигураций
- регламентирование бизнес-логики и общей структуры проекта
- может использоваться в качестве repair-kit для внедрения в чужие кодовые базы
- абстракция от серверной инфраструктуры, поддержка горизонтального масштабирования
Продолжение следует...
Комментарии (19)

vkopachinsky
09.06.2015 11:31+1Добрый день, отмечу объективные минусы Вашей ( наш вариант CQRS ) реализации:
UnitOfWorkScope.GetFromScope().Commit();
Нужно помнить, о том что надо вызывать метод. Проблема решается, если мы будем использовать Dispatcher, который скрывает все эти моменты.
dispatcher.Push(new AddSomeEntityCommand()); dispatcher.Push(s=>{ s.Quote(new Some1Command()); s.Quote(new Some2Command()); }); // share transaction
Тем более, что проблему дублирования linq-запросов в коде можно изящно решить вот так:
public class Account : IEntity { [BusinessRule] public static Expression<Func<Lead, bool>> ActiveRule = x => x.IsDeleted && x.Ballance > 0; }
Мне кажется, более универсально (а так же к тестированию пригодно) разбить Where на 2 части, а сами expression упаковывать в классы
new LeadOnlyDeletedWhere().And(new LeadGreaterBalance(0))
__queryFactory.GetQuery<Product>() .Where(Product.ActiveRule) // это статический экспрешн, как в примере с Account. Используется ExpressionSpecification .OrderBy(x => x.Id) .Paged(0, 10) // получаем 10 продуктов для первой страницы
Наш, пример с specifications.
Repository.Query(whereSpecification: new ProductByFullTextWher("test") .And(new ProductBySomethingElseWhere("some"), orderSpecification:new ProductByNameOrder(), paginatedSpecification:new PaginatedSpecification(current,size))
Отмечу, основные плюсы:
1. Можно делать StubQuery, в рамках теста и потом отдельно тестировать specification.
2. Specification, позволяют скрыть логику, к примеру ProductByRangeWhere(start,end)
ICommandFactory и IQueryFactory
Те же static helper, по этому я бы посоветовал двигаться в сторону использования Command/Query повсеместно, к примеру SendEmailCommand(), GetConnectionStringQuery и т.д.
Плюсы?
— Больше не надо, выдумывать ManagerHelper,CoreService,CommandHelper,FileBuilder and etc
— Command/Query помогают бороться с появление GOD object в проекте, потому что они атомарные и делают только одно действие ( иногда смежно AddOrEdit, но это скорее исключение, чем правило)
-Повторно можно использовать, в рамках других Command/Query (к примеру BulkAddProduct, который в foreach использует AddProduct, что бы не дублировать логику)
public class GroupEncounterRedFlagCommand : CommandBase { public Guid EncounterId { get; set; } public Guid RedFlagGroupId { get; set; } public string Value { get; set; } public override void Execute() { foreach (var redFlag in Repository.GetById<RedFlagGroup>(RedFlagGroupId).RedFlags) { Dispatcher.Push(new ChangeEncounterRedFlagCommand() { EncounterId = EncounterId, RedFlagId = redFlag.Id, Value = Value }); } } }
-Проще навигация по проекту, ищем действие, что проще чем CommandFactory.Add, так что лучше AddGenericCommandT
-Мы даже, вызываем Command/Query по Ajax без controller (MVD)
@model AddAcoGroupCommand <form action="@Url.Dispatcher().Push(new AddAcoGroupCommand())"> @Html.HiddenFor(r=>r.Id) <input type="submit"/> </form>
Проблемы:
— Command/Query должны создавать UnitOfWork, только в момент обращения к Repository, иначе cache внутри будет все равно тратить ресурсы на открытие подключения.
-Command/Query должны иметь разный тип транзакций, ReadUncommited для query и ReadCommited для Command
и ещё много других нюансов, которые я нашел в процессе написания Incoding Framework.
lair
09.06.2015 11:49+1Command/Query должны иметь разный тип транзакций, ReadUncommited для query и ReadCommited для Command
Вам настолько плевать на консистентность данных?
marshinov Автор
09.06.2015 12:04+1Скорее всего vkopachinsky описывает ситуацию с нагруженными ресурсами и речь идет как раз о все-возможных ViewCount'ах, CommentCount'ах и Like'ах, которые потом «задним числом» в фоне приводятся к консистентному состоянию
lair
09.06.2015 12:09+1Во-первых, я бы для таких значений использовал неблокирующее чтение и обновление.
Во-вторых, это же локальные правила, для конкретного Command и конкретного Query нужны такие настройки — но не для всех.vkopachinsky
09.06.2015 12:50Во-вторых, это же локальные правила, для конкретного Command и конкретного Query нужны такие настройки — но не для всех.
Можно добавить возможность переопределять, но lock таблицу при чтение (без записи) это не лучший вариант в плане perfromance
Во-первых, я бы для таких значений использовал неблокирующее чтение и обновление.
Вот, для Query ReadUncommited и используется.
Можно долго рассуждать о тонких настройках, но я опираюсь все же более часто встречаемые сценарии и по этому придерживаюсь однотипности решений.lair
09.06.2015 12:53Можно добавить возможность переопределять, но lock таблицу при чтение (без записи) это не лучший вариант в плане perfromance
А читать данные, которые другая транзакция еще не объявила консистентными — лучший вариант? Не нравятся локи — используйте lock-free примитивы.
Вот, для Query ReadUncommited и используется.
Вы про SNAPSHOT и READ_COMMITTED_SNAPSHOT не слышали?
Можно долго рассуждать о тонких настройках, но я опираюсь все же более часто встречаемые сценарии и по этому придерживаюсь однотипности решений.
Неплохо отдавать себе отчет в том, к чему ведут ваши «однотипные» решения.vkopachinsky
09.06.2015 13:03-1Вы про SNAPSHOT и READ_COMMITTED_SNAPSHOT не слышали?
Отвык я от Ваших умных комментариев, понятно откуда мне это знать )))
А читать данные, которые другая транзакция еще не объявила консистентными — лучший вариант?
Это вариант, а лучший или нет, то скорей всего надо решать по ситуация, если Вам он не подходит, то скорей всего задача другая.
Неплохо отдавать себе отчет в том, к чему ведут ваши «однотипные» решения.
ух, какая конкретика ))) Уже пошел код свой удалять, после такого аргументов…
marshinov Автор
09.06.2015 12:07Command/Query должны создавать UnitOfWork, только в момент обращения к Repository, иначе cache внутри будет все равно тратить ресурсы на открытие подключения.
Я вообще отказался от репозиториев. По остальным моментам, думаю что у нас примерно, разница в основном во вкусовщине.
Все-возможные диспетчеры меня пугают тем, что пролезают зависимостью по всему приложению. Мне это не нравится.vkopachinsky
09.06.2015 12:54Я думаю, после того, как пару раз пропустите вызов метода Commit или появится необходимость одновременно расширить функционал Command/Query, Вы придете к варианту централизованного вызова.
На данную проблему делал акцент lair
повторение boiler-plate-кода (всевозможные using, try-catch, log и т.д.)
P.S. кстати, не заметил вызова Rollback ( сорри если пропустил )
marshinov Автор
09.06.2015 13:13повторение boiler-plate-кода (всевозможные using, try-catch, log и т.д.)
Кросскатинг конёрнс (AOP).
vkopachinsky
09.06.2015 14:18+1Я сторонник богатой доменной модели (Rich Domain Model) и не люблю анемичную, поэтому Lead обладает правильным конструктором и не дает перевести себя в несогласованное состояние (нарушить инвариант).
Замечу пару моментов, который сам усвоил при использование DDD:
1. CTOR — смотрится очень хорошо в рамках объекта с 2 — 5 полями, но крайне не читабельный при усложнение, когда у Вас 15, так что более лучшим решением будет new T() { Name = «value»,Name2=«value2»}.
примечание: что бы так же поддерживать обязательность заполнения всех полей, лучше писать Unit Test и Equal weak
2. Красивые названия методов HasRule, Verify и т.д, очень скоро делают из Entity обычный GOD object, по этому лучше реализовывать логику в рамках Query/Command.
Пример, такого Query
public class GetTaskNameFromAppointmentQuery : QueryBase<string> { public Appointment Appointment { get; set; } protected override string ExecuteResult() { var user = Dispatcher.Query(new GetCurrentUserQuery()); var sb = new List<string>(); sb.Add(string.Format("Appointment Reminder - {0} Appointment:", Appointment.Status.Name)); if (Appointment.Type != null) sb.Add(string.Format("{0}", Appointment.Type.Name)); if (Appointment.Type == null && !string.IsNullOrWhiteSpace(Appointment.Professional)) sb.Add(string.Format("With")); if (!string.IsNullOrWhiteSpace(Appointment.Professional)) { string value = Appointment.Professional; if (Appointment.ProfessionalCareId.HasValue) { var profCare = Dispatcher.Query(new GetDetailForAppointmentNameQuery() { Id = Appointment.ProfessionalCareId }); value = profCare.Name; } sb.Add(value); } if (Appointment.Date.HasValue) sb.Add(string.Format("on {0}", Appointment.Date.ToDisplayString())); if (Appointment.Date.HasValue && Appointment.Time.HasValue) { sb.Add(string.Format("at {0}", user.ConvertFromUTC(Appointment.Date.Add(Appointment.Time.Value)) .GetTime() .ToTimeString())); } return string.Join(" ", sb); } }
примечание: в примере, видно user.ConvertFromUTC который как метод, но куда лучше использовать отдельный Query
Пример использования
var taskCommand = new UpdatePatientTaskCommand() { Priority = PatientTask.TaskPriority.Normal, Status = Status, AssignedTo = assignedTo.GetValueOrDefault(), Task = Dispatcher.Query(new GetTaskNameFromAppointmentQuery() { Appointment = appointment }) }; Dispatcher.Push(taskCommand);
3. Пример с Query (выше) показал, то что в рамках Query/Command можно использовать Repository/Dispatcher, а вот в рамках Entity Вы очень ограничены.
4. Удобство тестирования, дело в том, что Mock для Entity можно сделать только, если Вы получаете её через метод, что позволяет Вам её подменить, но не когда делает new T()
P.S. Я не говорю, что мне открылась истина и DDD это не лучший подход, но я столкнулся с аргументами, которые вынудили сделать такой вывод )))marshinov Автор
09.06.2015 17:291. Если у вас 18 полей, то либо это песец какая сложная предметная область, либо legacy и 80% полей — мусор, либо не верно декомпозированы сущности, либо это «плоские» данные из аггегата. Я согласен, что такие конструкторы чудовищны, но с большой вероятностью проблема в проектировании этой Entity
2. Verify, HasRule и прочее не надо сувать в один доменный объект. Не все объекты предметной области вообще должны мапиться на модель и ничего не мешает внутри SaleRule использовать Validator и т.п. С моей точки зрения код, который вы привели в пример имеет много проблем (как раз из серии перемешивания бизнес-правил и построения строчки). Я не знаю деталей вашего приложения, но такая организация кода мне не нравится. Самое простое — ваш код можно «разломать» не передав Appointment. Вам не хватает второго параметра — типа спецификации.
Меня удивляет, что вы противопоставляете DDD и CQRS. Моя цель, наоборот, использовать полезные элементы обоих подходов. В рамках Repository я не мог решить проблему с generic-спецификацией, поэтому решение «переехать» на Query пришло само собой. Термин «команда», достаточно простой, чтобы использовать его в рамках единого языка при коммуникации с заказчиком.
Для меня DDD — способ писать код, близкий к DSL, лучше составлять спецификацию, уменьшить затраты на коммуникацию и «костыли». CQRS — способ безболезненно «рулить» инфраструктурой. Другой вопрос, что вот прям богатая модель нужна для сложных мест из предметной области (там где действительно важно и не понятно, что происходит).
Тупой CRUD можно писать на чистом CQRS и не париться.vkopachinsky
09.06.2015 17:46Если у вас 18 полей, то либо это песец какая сложная предметная область, либо legacy и 80% полей — мусор, либо не верно декомпозированы сущности, либо это «плоские» данные из аггегата. Я согласен, что такие конструкторы чудовищны, но с большой вероятностью проблема в проектировании этой Entity
public class PatientTask : ActiveHistoryEntityBase<PatientTask>, IPatient { public virtual DateTime? StartDate { get; set; } public virtual DateTime? DueDate { get; set; } public virtual string Task { get; set; } public virtual User AssignedTo { get; set; } public virtual Patient Patient { get; set; } public virtual TaskStatus Status { get; set; } public virtual TaskPriority Priority { get; set; } public virtual string Notes { get; set; } }
Какие поля тут мусор? Просто, очень странно, что Вы не сталкивались с длинными форма регистрации и т.д.
Verify, HasRule и прочее не надо сувать в один доменный объект.
Даже, пара методов могут быть очень громоздкими.
Не все объекты предметной области вообще должны мапиться на модель и ничего не мешает внутри SaleRule использовать Validator и т.п.
Очень сложно придумывать названия данным агрегатам, куда проще строить блоки из готовых глаголов ( GetLastUserQuery,ChangeUserStatusCommand and etc). Validator, прекрасно работает на Command/Query, потому что именно они, а не DDD передаются из форм приложения.
С моей точки зрения код, который вы привели в пример имеет много проблем (как раз из серии перемешивания бизнес-правил и построения строчки).
А построение строчки это не бизнес правило?
Самое простое — ваш код можно «разломать» не передав Appointment.
Для этого пишутся Unit Test, на тот код который вызывает данный Query.
Другой вопрос, что вот прям богатая модель нужна для сложных мест из предметной области (там где действительно важно и не понятно, что происходит).
По DDD, что Вы будете делать если Вам надо получить доступ к Repository/Query из метода Domain?
примечание: для метода ChangeStatus из класса User, требуется получить доступ к стороннему сервису банка, что бы проверить платеж.
Тупой CRUD можно писать на чистом CQRS и не париться
По мне вызов методов DDD, возможен только через Command/Query (ну это в рамках моей концепции)
Плюс, который я вижу в повсеместно использование CQRS, в том что Вы не привязаны к шаблонам (определенной модели) и у Вас нету ограничений, потому что каждый Query/Command обладает одинаковым набором доступных инструментов (Repository/Dispatcher).marshinov Автор
09.06.2015 18:19Я бы с удовольствием продолжил эту дискуссию с вами где-нибудь на берегу океана со стаканчиком коктейля, плодить дальшие комменатрии не вижу смысла Я думаю, мы примерно одни задачи решаем, примерно одним способом. По крайней мере, мне понятен ход ваших мыслей. Каков поп, таков и приход: кому больше юнитов, кому — инкапсуляции :)
lair
И как же вы это исправляете? В примерах ничего нет.
А как же валидация на клиенте? Эксепшн-то вы получили, но как вам получить список невалидных полей? (и это мы еще не затрагиваем сохранение драфтов)
… и как же потом по нему искать? Ваш репозиторий принимает на вход целочисленный id. Поздравляю вас, вы только что нарушили целостность.
И при этом ваш следующий абзац называется Persistence Ignorance. Нет, серьезно? Собственно, именно поэтому как раз про ignorance у вас нет ни слова, только про persistence.
Так где же реальные примеры, зачем это надо? Абстрактные «соцсети» — это не пример, там можно и на OLTP/OLAP сделать. И нет ни слова про то, как же, собственно достигается консистентность всего этого цирка.
(Собственно, про консистентность и ее границы у вас тоже нет ни слова)
И самое интересное: хотя вы и сторонник Rich Model, в примерах команд у вас только CRUD. Это означает, что либо у вас на самом деле доменная модель анемичная, либо вы выполняете бизнес-операции мимо CQRS. Так как же оно на самом деле? Опишите хотя бы тот же пример с лайками.
А где валидатор-то в вашем примере?
marshinov Автор
Опять-же не понял. Уберите аттрибты, добавьте FluentValidation и классы паммингов. Сам объект не содержит никаких данных о том, как он хранится.
Это не абстрактные соц.сети, а конкретные фиды в VK и Facebook
Здесь вы правы, примеры не привел, спасибо. Поищу и добавлю попозже.
lair
Представьте себе, что вы заполняете на клиенте сложную сущность, и вам надо сохранить промежуточное состояние. Оно не валидно per se, его нельзя пускать в бизнес-процесс, но его нужно сохранить. Ваш сценарий это не поддерживает.
Вот только у вас не атрибут
Requiredстоит на свойствеEmail, а проверка в коде (еще и не через Code Contracts). Я же специально пример вашего кода привел.Вы бы хоть смотрели, на что именно я отвечал — а отвечал я на вашу риторику «почему атрибуты лучше маппинг-классов».
И много людей, читающих эту статью, разрабатывает конкретные фиды в ВК и ФБ? Кстати, а у вас есть first-hand knowledge, что там именно CQRS? Так что нет, это очень отвлеченный пример.